很多的集群管理项目(比如 Yarn、Mesos,以及 Swarm)所擅长的,都是把一个容器,按照某种规则,放置在某个最佳节点上运行起来。这种功能,我们称为“调度”。
Kubernetes 项目所擅长的,是按照用户的意愿和整个系统的规则,使用声明式api,完全自动化地处理好容器之间的各种关系。这种功能,就是我们经常听到的一个概念:编排。
所以说,Kubernetes 项目的本质,是为用户提供一个具有普遍意义的容器编排工具。
架构
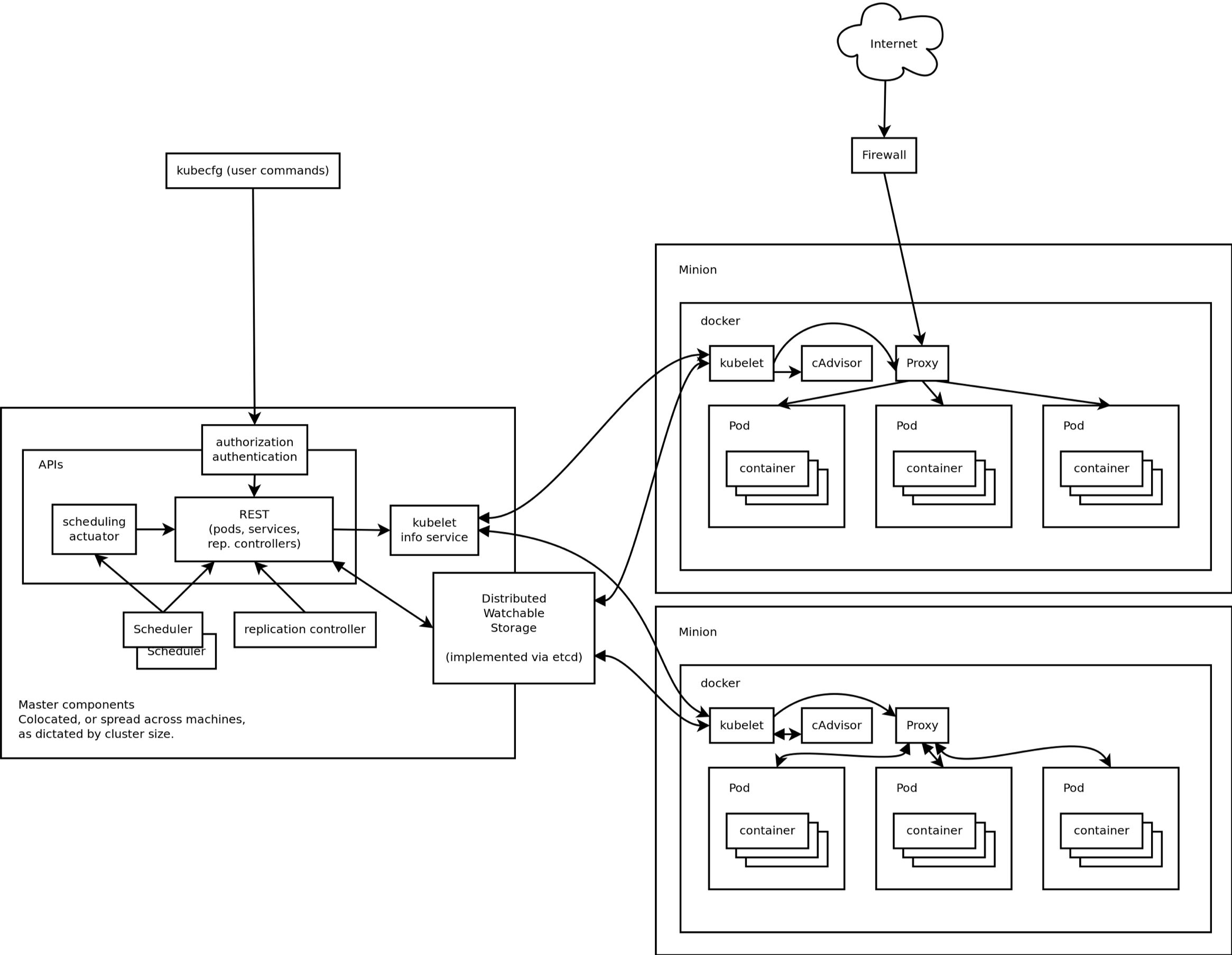
核心组件
master
- apiserver: 提供了资源操作的唯一入口,并提供认证、授权、访问控制(可以实现envoy的默认注入,使用Dynamic Admission Control,也叫作:Initializer)等机制,可以说是k8s的内部交互的网关总线。
- controller manager: 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;是控制器的管理者,负责很多的控制器。
- scheduler: 负责资源的调度,按照(预选优选)调度策略将Pod调度到相应的机器上;
node
- kubelet: 负责和docker进行交互,创建容器,负责维护容器的生命周期。
- kubelet 还通过 gRPC 协议同一个叫作 Device Plugin 的插件进行交互。这个插件,是 Kubernetes 项目用来管理 GPU 等宿主机物理设备的主要组件,也是基于 Kubernetes 项目进行机器学习训练、高性能作业支持等工作必须关注的功能。
- kubelet 的另一个重要功能,则是调用网络插件和存储插件为容器配置网络和持久化存储。这两个插件与 kubelet 进行交互的接口,分别是 CNI(Container Networking Interface)和 CSI(Container Storage Interface)。
- kube-proxy: 负责为Service提供cluster内部的服务发现和负载均衡;提供了一种网络模式。
- docker engine: docker引擎,负责docker的创建和管理,containerd已经快速崛起了。
数据库
- etcd: 保存了整个集群的状态;
网络
- fannel: 实现pod网络的互通
除了核心组件,还有一些推荐的插件Add-ons:
- kube-dns负责为整个集群提供DNS服务,主要用于解决igress的负载均衡策略,如何找到相关的容器。从 Kubernetes v1.12 开始,CoreDNS 是推荐的 DNS 服务器,取代了kube-dns。
- Ingress Controller为服务提供外网入口,负载均衡。
- kube-state-metrics提供资源监控,主要是状态。
- Dashboard提供GUI,友好的界面。
分层架构
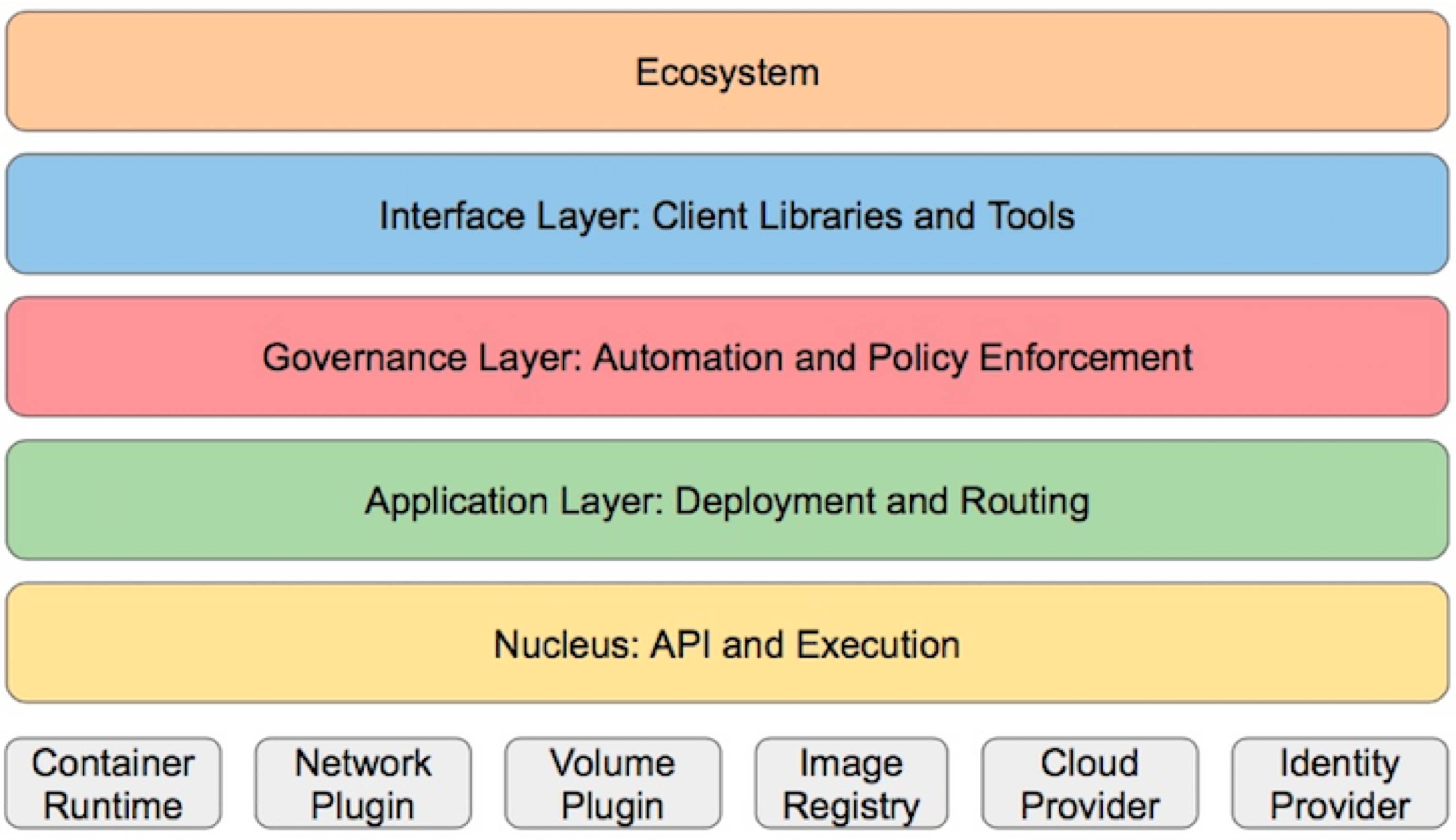
根据作用可以将对应的功能进行分层
- 基础设施层:container runtime、网络、存储等
- 核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境。
- 应用层:部署(无状态、有状态应用、Job等)和路由(服务发现、负载均衡等)
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)
- 接口层:kubectl 命令行工具、客户端 SDK 以及集群联邦
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴。
- Kubernetes 外部:日志、监控、配置管理、CI、CD、Workflow等
- Kubernetes 内部:CRI、CNI、CSI、镜像仓库、Cloud Provider、集群自身的配置和管理等。
其实这个层面更加能看出paas的不同的建设方向。
详细说明
kubernetes架构是master/node,下面我们对每个节点上的组件进行了解.
master
k8s组件系列(三)—- controller-manager详解
node组件
数据库
存储
网络
核心插件
基本概念
pod
思想
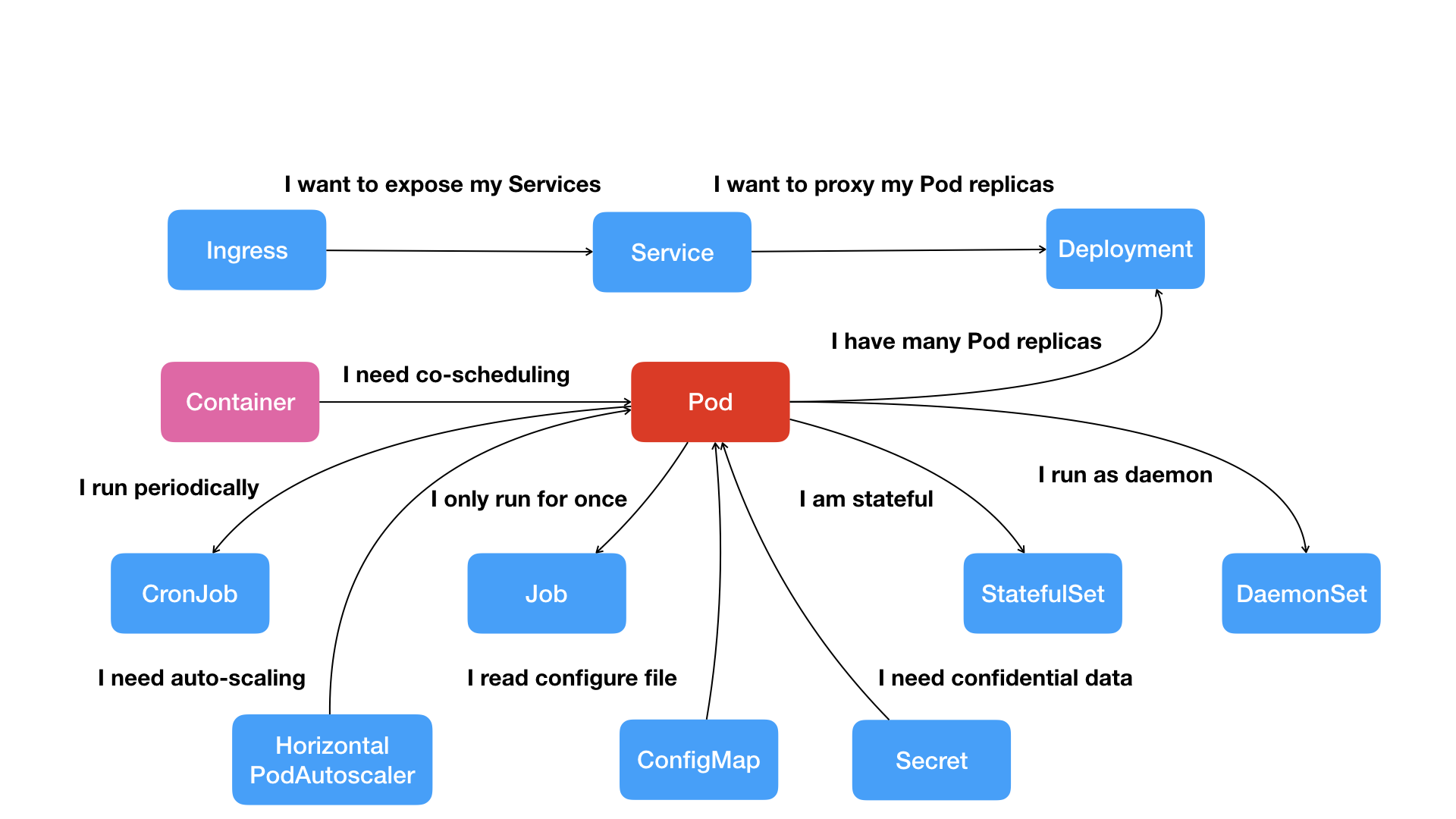
按照这幅图的线索,我们从容器这个最基础的概念出发,首先遇到了容器间“紧密协作”关系的难题,于是就扩展到了 Pod;有了 Pod 之后,我们希望能一次启动多个应用的实例,这样就需要 Deployment 这个 Pod 的多实例管理器;而有了这样一组相同的 Pod 后,我们又需要通过一个固定的 IP 地址和端口以负载均衡的方式访问它,于是就有了 Service,然后我们的服务需要对外网提供服务,就有了ingress,这是一条完整的路线,还有针对不同的场景有着不同资源的抽象,都可以在图中展现出来。
所以说k8s的思想很先进,经验很多,直接在上层就做好的架构设计,对于其他的paas简直就是降维打击,所以k8s得天下是必然的。
pod
1、pod是什么?
Pod,其实是一组共享了某些资源(网络,存储)的容器。
pod是kubernetes定义的一种操作单位。
pod的只是一个逻辑概念,Kubernetes 真正处理的,还是宿主机操作系统上 Linux 容器的 Namespace 和 Cgroups,而并不存在一个所谓的 Pod 的边界或者隔离环境。
2、pod实现原理
在 Kubernetes 项目里,Pod 的实现需要使用一个中间容器,这个容器叫作 Infra 容器。在这个 Pod 中,Infra 容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起。
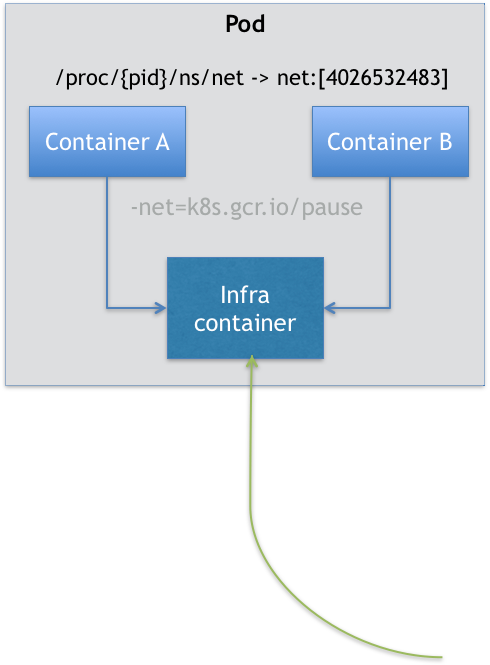
在 Kubernetes 项目里,Infra 容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作:k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有 100~200 KB 左右。而在 Infra 容器“Hold 住”Network Namespace 后,用户容器就可以加入到 Infra 容器的 Network Namespace 当中了。所以,如果你查看这些容器在宿主机上的 Namespace 文件,它们指向的值一定是完全一样的。
这也就意味着,对于 Pod 里的容器 A 和容器 B 来说:
- 它们可以直接使用 localhost 进行通信;
- 它们看到的网络设备跟 Infra 容器看到的完全一样;
- 一个 Pod 只有一个 IP 地址,也就是这个 Pod 的 Network Namespace 对应的 IP 地址;
- 当然,其他的所有网络资源,都是一个 Pod 一份,并且被该 Pod 中的所有容器共享;
- Pod 的生命周期只跟 Infra 容器一致,而与容器 A 和 B 无关。
3、为什么需要pod?
- pod作为k8s原子调度单位,主要解决超亲密关系的批调度的问题,主要解决需要调度到一个节点上的conrainer能够分配到全部符合要求的资源。
符合容器设计模式也就是超亲密关系的容器设计思想,实际上就是希望,当用户想在一个容器里跑多个功能并不相关的应用时,应该优先考虑它们是不是更应该被描述成一个 Pod 里的多个容器。
亲密关系可以通过调度来解决,超亲密关系可以通过原子单位来解决
4、pod和容器的关系
pod和container之间的关系类似于进程和进程组。容器本质就是进程,pod就是容器组也就是进程组。
其实我们经常将容器对比虚拟机,其实这根本就不是一个对等的关系,容器的本质是进程,所以这样对比很容易造成容器化的困难,因为本身就是不对等的,如果需要一个对比的话,pod更加适合对比成虚拟机,如果把pod对比成虚拟机,那么很多pod上的思想就很容易理解了,凡是调度、网络、存储,以及安全相关的属性,基本上是 Pod 级别的。凡是跟容器的 Linux Namespace 相关的属性,也一定是 Pod 级别的。 这些属性的共同特征是,它们描述的是“机器”这个整体,而不是里面运行的“程序”。比如,配置这个“机器”的网卡(即:Pod 的网络定义),配置这个“机器”的磁盘(即:Pod 的存储定义),配置这个“机器”的防火墙(即:Pod 的安全定义)。更不用说,这台“机器”运行在哪个服务器之上(即:Pod 的调度)。
你就可以把整个虚拟机想象成为一个 Pod,把这些进程分别做成容器镜像,把有顺序关系的容器,定义为 Init Container。这才是更加合理的、松耦合的容器编排诀窍,也是从传统应用架构,到“微服务架构”最自然的过渡方式。
5、pod的特性
- 你很少会直接在kubernetes中创建单个Pod。因为Pod的生命周期是短暂的,用后即焚的实体。
- Controller可以创建和管理多个Pod,提供副本管理、滚动升级和集群级别的自愈能力。例如,如果一个Node故障,Controller就能自动将该节点上的Pod调度到其他健康的Node上。
状态
pod的五种状态,主要定义的status.phase
- pending pod已经创建,yaml资源已经被存储到etcd中,但是内部镜像还没有完全创建
- running 容器已经创建,至少有一个容器处于运行状态
- succeeded pod内容器都成功并且终止,且不会重启,一般在job这种一次性任务中出现
- failed 所有容器已经退出,至少有一个是因为发生错误而退出
- Unkown:由于某中原因apiserver无法获取到Pod的状态。通常是由于Master与pod所在的主机失去连接了,也就是kubelet出现问题了。
还有一下更加细分的状态,在condition中
Unschedulable,这就意味着它的调度出现了问题。
Ready 这个细分状态非常值得我们关注:它意味着 Pod 不仅已经正常启动(Running 状态),而且已经可以对外提供服务了。
CrashLoopBackOff: docker container在运行start之后很快容器退出,kubelet正在将它重启
InvalidImageName: 无法解析镜像名称
ImageInspectError: 无法校验镜像
ErrImageNeverPull: 策略禁止拉取镜像
ImagePullBackOff: 正在重试拉取
RegistryUnavailable: 连接不到镜像中心
ErrImagePull: 通用的拉取镜像出错
CreateContainerConfigError: 不能创建kubelet使用的容器配置
CreateContainerError: 创建容器失败
m.internalLifecycle.PreStartContainer 执行hook报错
RunContainerError: 启动容器失败
PostStartHookError: 执行hook报错
ContainersNotInitialized: 容器没有初始化完毕
ContainersNotReady: 容器没有准备完毕
ContainerCreating:容器创建中
PodInitializing:pod 初始化中
DockerDaemonNotReady:docker还没有完全启动
NetworkPluginNotReady: 网络插件还没有完全启动
Terminating: 退出中
一般遇到这些错误的时候,我们可以使用describe和logs查看启动错误日志,做相应的处理。
pod的使用
基本使用
- 一般很少会直接在kubernetes中创建单个Pod,而是使用k8s控制器,因为Pod的生命周期是短暂的,用后即焚的实体。
- Controller可以创建和管理多个Pod,提供副本管理、滚动升级和集群级别的自愈能力。例如,如果一个Node故障,Controller就能自动将该节点上的Pod调度到其他健康的Node上,一般这是一个创建删除的过程。
yaml
其实就是我们声明式操作的资源配置清单,具体参数详解可以查看k8s权威指南的第二章第四节。
其实我们很少用pod来创建,一般都是用资源来控制,这边主要说几个重点的字段
NodeSelector:是一个供用户将 Pod 与 Node 进行绑定的字段,意味着这个 Pod 永远只能运行在携带了类似“disktype: ssd”标签(Label)的节点上;否则,它将调度失败。
NodeName:一旦 Pod 的这个字段被赋值,Kubernetes 项目就会被认为这个 Pod 已经经过了调度,调度的结果就是赋值的节点名字。所以,这个字段一般由调度器负责设置,但用户也可以设置它来“骗过”调度器,当然这个做法一般是在测试或者调试的时候才会用到。
HostAliases:定义了 Pod 的 hosts 文件(比如 /etc/hosts)里的内容,在这个 Pod 的 YAML 文件中,我设置了一组 IP 和 hostname 的数据。这样,这个 Pod 启动后,会写入/etc/hosts 文件的内容,在 Kubernetes 项目中,如果要设置 hosts 文件里的内容,一定要通过这种方法。否则,如果直接修改了 hosts 文件的话,在 Pod 被删除重建之后,kubelet 会自动覆盖掉被修改的内容。
apiVersion: v1 kind: Pod ... spec: hostAliases: - ip: "10.1.2.3" hostnames: - "foo.remote" - "bar.remote" ...共享namespace,比如我定义了共享宿主机的 Network、IPC 和 PID Namespace。
apiVersion: v1 kind: Pod metadata: name: nginx spec: hostNetwork: true hostIPC: true hostPID: true containers: - name: nginx image: nginx - name: shell image: busybox stdin: true tty: trueContainers是对容器的定义,Init Containers 的生命周期,会先于所有的 Containers,并且严格按照定义的顺序执行。Kubernetes 项目中对 Container 的定义,和 Docker 相比并没有什么太大区别。 Image(镜像)、Command(启动命令)、workingDir(容器的工作目录)、Ports(容器要开发的端口),以及 volumeMounts(容器要挂载的 Volume)都是构成 Kubernetes 项目中 Container 的主要字段。不过在这里,还有这么几个属性值得你额外关注。
- ImagePullPolicy 字段。它定义了镜像拉取的策略。上面已经介绍
- Lifecycle 字段。它定义的是 Container Lifecycle Hooks。顾名思义,Container Lifecycle Hooks 的作用,是在容器状态发生变化时触发一系列“钩子”。上面已经介绍
Pod 生命周期的变化,主要体现在 Pod API 对象的 Status 部分,这是它除了 Metadata 和 Spec 之外的第三个重要字段。其中,pod.status.phase,就是 Pod 的当前状态,上面已经介绍。
volume主要是卷的挂载。
podTemplate
控制器通常使用 Pod 模板(Pod Template) 来替你创建 Pod 并管理它们。我们通过实例来看一下模板的使用
apiVersion: batch/v1 kind: Job metadata: name: hello spec: template: # 这里是 Pod 模版 spec: containers: - name: hello image: busybox command: ['sh', '-c', 'echo "Hello, Kubernetes!" && sleep 3600'] restartPolicy: OnFailure # 以上为 Pod 模版这边要注意pod模板的修改并不会对已经存在的pod进行更新,新创建的pod是按照新的模板来创建,对应已经存在pod,每个控制器都是有自己的控制逻辑,大部分都是会删除旧的pod,然后创建新的pod来代替,比如deployment就是这样处理的。
安全性上下文(securityContext)
安全上下文(Security Context)定义 Pod 或 Container 的特权与访问控制设置。 安全上下文包括但不限于:
- 自主访问控制(Discretionary Access Control):基于 用户 ID(UID)和组 ID(GID). 来判定对对象(例如文件)的访问权限。
- 安全性增强的 Linux(SELinux): 为对象赋予安全性标签。
- 以特权模式或者非特权模式运行。
Linux 权能: 为进程赋予 root 用户的部分特权而非全部特权。
AppArmor:使用程序框架来限制个别程序的权能。
Seccomp:过滤进程的系统调用。
AllowPrivilegeEscalation:控制进程是否可以获得超出其父进程的特权。 此布尔值直接控制是否为容器进程设置
no_new_privs标志。 当容器以特权模式运行或者具有CAP_SYS_ADMIN权能时,AllowPrivilegeEscalation 总是为 true。readOnlyRootFilesystem:以只读方式加载容器的根文件系统。
以上条目不是安全上下文设置的完整列表 – 请参阅 SecurityContext 了解其完整列表。
关于在 Linux 系统中的安全机制的更多信息,可参阅 Linux 内核安全性能力概述。我们常用的就是为Pod 或 Container设置访问权限和linux权能。
1、为pod或者container设置安全上下文
直接使用实例查看
apiVersion: v1 kind: Pod metadata: name: security-context-demo spec: securityContext: runAsUser: 1000 runAsGroup: 3000 fsGroup: 2000 volumes: - name: sec-ctx-vol emptyDir: {} containers: - name: sec-ctx-demo image: busybox command: [ "sh", "-c", "sleep 1h" ] volumeMounts: - name: sec-ctx-vol mountPath: /data/demo securityContext: allowPrivilegeEscalation: false在配置文件中,
runAsUser字段指定 Pod 中的所有容器内的进程都使用用户 ID 1000 来运行。runAsGroup字段指定所有容器中的进程都以主组 ID 3000 来运行。 如果忽略此字段,则容器的主组 ID 将是 root(0)。 当runAsGroup被设置时,所有创建的文件也会划归用户 1000 和组 3000。 由于fsGroup被设置,容器中所有进程也会是附组 ID 2000 的一部分。 卷/data/demo及在该卷中创建的任何文件的属主都会是组 ID 2000。如果在container级别设置将会覆盖pod级别,比如
apiVersion: v1 kind: Pod metadata: name: security-context-demo-2 spec: securityContext: runAsUser: 1000 containers: - name: sec-ctx-demo-2 image: gcr.io/google-samples/node-hello:1.0 securityContext: runAsUser: 2000 allowPrivilegeEscalation: false对应的uid就是2000。
2、为container设置权能
使用 Linux 权能,你可以 赋予进程 root 用户所拥有的某些特权,但不必赋予其全部特权。 要为 Container 添加或移除 Linux 权能,可以在 Container 清单的
securityContext节 包含capabilities字段。比如apiVersion: v1 kind: Pod metadata: name: security-context-demo-4 spec: containers: - name: sec-ctx-4 image: gcr.io/google-samples/node-hello:1.0 securityContext: capabilities: add: ["NET_ADMIN", "SYS_TIME"]
重启策略
pod的重启策略:kubelet将根据RestartPolicy的设置来进行相应的操作
- Always: 当容器失效时, 由kubelet自动重启该容器,这个是默认值
- OnFailure: 当容器终止运行且退出码不为0时, 由kubelet自动重启该容器
- Never: 不论容器运行状态如何, kubelet都不会重启该容器
镜像拉取策略
支持三种ImagePullPolicy
- Always:不管镜像是否存在都会进行一次拉取。默认值
- Never:不管镜像是否存在都不会进行拉取
- IfNotPresent:只有镜像不存在时,才会进行镜像拉取。
注意:
- 默认为IfNotPresent,但:latest标签的镜像默认为Always。
- 不加标签也是默认为Always。
- 拉取镜像时docker会进行校验,如果镜像中的MD5码没有变,则不会拉取镜像数据。
- 生产环境中应该尽量避免使用:latest标签,而开发环境中可以借助:latest标签自动拉取最新的镜像。
资源限制
spec.containers[].resources.limits.cpu:CPU上限,可以短暂超过,容器也不会被停止
spec.containers[].resources.limits.memory:内存上限,不可以超过;如果超过,容器可能会被停止或调度到其他资源充足的机器上
spec.containers[].resources.requests.cpu:CPU请求,可以超过
spec.containers[].resources.requests.memory:内存请求,可以超过;但如果超过,容器可能会在Node内存不足时清理
cpu是以千分之一c为最小单位m,一般设置0.3核就是300m
limit是上限,如果应用超过limit,会kill掉
request给调度用的 调度在选择pod调度到那个node上,会看node上已经调度的pod所声明的request。你如果设置最小需求,那么你node上可能会被调度很多pod, 但是业务大的时候,会使得node的压力比较大,所以设置为正常的时候的需求,request不应该是一个下线值,而是一个运行参考值。
钩子
容器生命周期钩子(Container Lifecycle Hooks)监听容器生命周期的特定事件,并在事件发生时执行已注册的回调函数。支持两种钩子:
- postStart: 容器启动后执行,注意由于是异步执行,它无法保证一定在ENTRYPOINT之后运行,也就是不一定在容器程序之后完成,可能在之前就完成了。如果失败,容器会被杀死,并根据RestartPolicy决定是否重启
- preStop:容器停止前执行,常用于资源清理。如果失败,容器同样也会被杀死
而钩子的回调函数支持两种方式:
- exec:在容器内执行命令
- httpGet:向指定URL发起GET请求
postStart和preStop钩子示例:
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"]
扩缩容
Pod 水平自动伸缩(Horizontal Pod Autoscaler)和垂直扩展(Vertical Pod Autoscaler)以及CA( cluster-autoscaler)特性,可以说是很实用的特性,完全自动化实现了资源的充分利用,所以单独拿出来说说,具体可以查看k8s autoscaler。。
限制带宽
可以通过给Pod增加kubernetes.io/ingress-bandwidth和kubernetes.io/egress-bandwidth这两个annotation来限制Pod的网络带宽
apiVersion: v1
kind: Pod
metadata:
name: qos
annotations:
kubernetes.io/ingress-bandwidth: 3M
kubernetes.io/egress-bandwidth: 4M
spec:
containers:
- name: iperf3
image: networkstatic/iperf3
command:
- iperf3
- -s
pod的配置管理
configmap,下面有详解的使用说明。
健康检查
Kubelet使用liveness probe(存活探针)来确定何时重启容器。例如,当应用程序处于运行状态但无法做进一步操作,liveness探针将捕获到deadlock,重启处于该状态下的容器,使应用程序在存在bug的情况下依然能够继续运行下去(谁的程序还没几个bug呢)。
Kubelet使用readiness probe(就绪探针)来确定容器是否已经就绪可以接受流量。只有当Pod中的容器都处于就绪状态时kubelet才会认定该Pod处于就绪状态。该信号的作用是控制哪些Pod应该作为service的后端。如果Pod处于非就绪状态,那么它们将会被从service的load balancer中移除。
一、探测
liveness probe
两种探测都有三种方式
1、基于命令的探测
实例
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
image: gcr.io/google_containers/busybox
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
该配置文件给Pod配置了一个容器。periodSeconds 规定kubelet要每隔5秒执行一次liveness probe。 initialDelaySeconds 告诉kubelet在第一次执行probe之前要的等待5秒钟。探针检测命令是在容器中执行 cat /tmp/healthy 命令。如果命令执行成功,将返回0,kubelet就会认为该容器是活着的并且很健康。如果返回非0值,kubelet就会杀掉这个容器并重启它。
容器启动时,执行该命令:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
在容器生命的最初30秒内有一个 /tmp/healthy 文件,在这30秒内 cat /tmp/healthy命令会返回一个成功的返回码。30秒后, cat /tmp/healthy 将返回失败的返回码。
创建Pod:
kubectl create -f https://k8s.io/docs/tasks/configure-pod-container/exec-liveness.yaml
在30秒内,查看Pod的event:结果显示没有失败的liveness probe:
kubectl describe pod liveness-exec
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
24s 24s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "gcr.io/google_containers/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "gcr.io/google_containers/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e
启动35秒后,再次查看pod的event:在最下面有一条信息显示liveness probe失败,容器被删掉并重新创建。
kubectl describe pod liveness-exec
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
37s 37s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "gcr.io/google_containers/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "gcr.io/google_containers/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e
2s 2s 1 {kubelet worker0} spec.containers{liveness} Warning Unhealthy Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
再等30秒,确认容器已经重启:从输出结果来RESTARTS值加1了。如果你注意到 RESTARTS 字段从 0 到 1 的变化,就明白原因了:这个异常的容器已经被 Kubernetes 重启了。在这个过程中,Pod 保持 Running 状态不变。Kubernetes 中并没有 Docker 的 Stop 语义。所以虽然是 Restart(重启),但实际却是重新创建了容器。这个功能就是 Kubernetes 里的 Pod 恢复机制,也叫 restartPolicy。它是 Pod 的 Spec 部分的一个标准字段(pod.spec.restartPolicy),默认值是 Always,即:任何时候这个容器发生了异常,它一定会被重新创建。但一定要强调的是,Pod 的恢复过程,永远都是发生在当前节点上,而不会跑到别的节点上去。事实上,一旦一个 Pod 与一个节点(Node)绑定,除非这个绑定发生了变化(pod.spec.node 字段被修改),否则它永远都不会离开这个节点。这也就意味着,如果这个宿主机宕机了,这个 Pod 也不会主动迁移到其他节点上去。而如果你想让 Pod 出现在其他的可用节点上,就必须使用 Deployment 这样的“控制器”来管理 Pod,哪怕你只需要一个 Pod 副本。
kubectl get pod liveness-exec
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m
2、基于HTTP请求
我们还可以使用HTTP GET请求作为liveness probe。下面是一个基于gcr.io/google_containers/liveness镜像运行了一个容器的Pod的例子http-liveness.yaml:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
args:
- /server
image: gcr.io/google_containers/liveness
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
该配置文件只定义了一个容器,livenessProbe 指定kubelet需要每隔3秒执行一次liveness probe。initialDelaySeconds 指定kubelet在该执行第一次探测之前需要等待3秒钟。该探针将向容器中的server的8080端口发送一个HTTP GET请求。如果server的/healthz路径的handler返回一个成功的返回码,kubelet就会认定该容器是活着的并且很健康。如果返回失败的返回码,kubelet将杀掉该容器并重启它。
任何大于200小于400的返回码都会认定是成功的返回码。其他返回码都会被认为是失败的返回码。
最开始的10秒该容器是活着的, /healthz handler返回200的状态码。这之后将返回500的返回码。
http.HandleFunc("/healthz", func(w http.ResponseWriter, r *http.Request) {
duration := time.Now().Sub(started)
if duration.Seconds() > 10 {
w.WriteHeader(500)
w.Write([]byte(fmt.Sprintf("error: %v", duration.Seconds())))
} else {
w.WriteHeader(200)
w.Write([]byte("ok"))
}
})
容器启动3秒后,kubelet开始执行健康检查。第一次健康监测会成功,但是10秒后,健康检查将失败,kubelet将杀掉和重启容器。
创建一个Pod来测试一下HTTP liveness检测:
kubectl create -f https://k8s.io/docs/tasks/configure-pod-container/http-liveness.yaml
After 10 seconds, view Pod events to verify that liveness probes have failed and the Container has been restarted:
10秒后,查看Pod的event,确认liveness probe失败并重启了容器。
kubectl describe pod liveness-http
3、基于TCP liveness探针
第三种liveness probe使用TCP Socket。 使用此配置,kubelet将尝试在指定端口上打开容器的套接字。 如果可以建立连接,容器被认为是健康的,如果不能就认为是失败的。
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: gcr.io/google_containers/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
如您所见,TCP检查的配置与HTTP检查非常相似。 此示例同时使用了readiness和liveness probe。 容器启动后5秒钟,kubelet将发送第一个readiness probe。 这将尝试连接到端口8080上的goproxy容器。如果探测成功,则该pod将被标记为就绪。Kubelet将每隔10秒钟执行一次该检查。
除了readiness probe之外,该配置还包括liveness probe。 容器启动15秒后,kubelet将运行第一个liveness probe。 就像readiness probe一样,这将尝试连接到goproxy容器上的8080端口。如果liveness probe失败,容器将重新启动。
4、使用命名的端口
可以使用命名的ContainerPort作为HTTP或TCP liveness检查:
ports:
- name: liveness-port
containerPort: 8080
hostPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
readiness probe
1、定义readiness探针
有时,应用程序暂时无法对外部流量提供服务。 例如,应用程序可能需要在启动期间加载大量数据或配置文件。 在这种情况下,你不想杀死应用程序,但你也不想发送请求。 Kubernetes提供了readiness probe来检测和减轻这些情况。 Pod中的容器可以报告自己还没有准备,不能处理Kubernetes服务发送过来的流量。
Readiness probe的配置跟liveness probe很像。唯一的不同是使用 readinessProbe而不是livenessProbe。
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
Readiness probe的HTTP和TCP的探测器配置跟liveness probe一样。
Readiness和livenss probe可以并行用于同一容器。 使用两者可以确保流量无法到达未准备好的容器,并且容器在失败时重新启动。
二、配置Probe
Probe 中有很多精确和详细的配置,通过它们你能准确的控制liveness和readiness检查:
initialDelaySeconds:容器启动后第一次执行探测是需要等待多少秒。
periodSeconds:执行探测的频率。默认是10秒,最小1秒。
timeoutSeconds:探测超时时间。默认1秒,最小1秒。
successThreshold:探测失败后,最少连续探测成功多少次才被认定为成功。默认是1。对于liveness必须是1。最小值是1。
failureThreshold:探测成功后,最少连续探测失败多少次才被认定为失败。默认是3。最小值是1。
HTTP probe 中可以给 httpGet设置其他配置项:
host:连接的主机名,默认连接到pod的IP。你可能想在http header中设置"Host"而不是使用IP。
scheme:连接使用的schema,默认HTTP。
path: 访问的HTTP server的path。
httpHeaders:自定义请求的header。HTTP运行重复的header。
port:访问的容器的端口名字或者端口号。端口号必须介于1和65535之间。
对于HTTP探测器,kubelet向指定的路径和端口发送HTTP请求以执行检查。 Kubelet将probe发送到容器的IP地址,除非地址被httpGet中的可选host字段覆盖。 在大多数情况下,你不想设置主机字段。 有一种情况下你可以设置它。 假设容器在127.0.0.1上侦听,并且Pod的hostNetwork字段为true。 然后,在httpGet下的host应该设置为127.0.0.1。 如果你的pod依赖于虚拟主机,这可能是更常见的情况,你不应该是用host,而是应该在httpHeaders中设置Host头。
PodPreset
开发人员只需要提交一个基本的、非常简单的 Pod YAML,Kubernetes 就可以自动给对应的 Pod 对象加上其他必要的信息,比如 labels,annotations,volumes 等等。而这些信息,可以是运维人员事先定义好的。这么一来,开发人员编写 Pod YAML 的门槛,就被大大降低了。所以,这个叫作 PodPreset(Pod 预设置)的功能 已经出现在了 v1.11 版本的 Kubernetes 中。
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
role: frontend
spec:
containers:
- name: website
image: nginx
ports:
- containerPort: 80
作为 Kubernetes 的初学者,你肯定眼前一亮:这不就是我最擅长编写的、最简单的 Pod 嘛。没错,这个 YAML 文件里的字段,想必你现在闭着眼睛也能写出来。可是,如果运维人员看到了这个 Pod,他一定会连连摇头:这种 Pod 在生产环境里根本不能用啊!所以,这个时候,运维人员就可以定义一个 PodPreset 对象。在这个对象中,凡是他想在开发人员编写的 Pod 里追加的字段,都可以预先定义好。比如这个 preset.yaml:
apiVersion: settings.k8s.io/v1alpha1
kind: PodPreset
metadata:
name: allow-database
spec:
selector:
matchLabels:
role: frontend
env:
- name: DB_PORT
value: "6379"
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}
在这个 PodPreset 的定义中,首先是一个 selector。这就意味着后面这些追加的定义,只会作用于 selector 所定义的、带有“role: frontend”标签的 Pod 对象,这就可以防止“误伤”。然后,我们定义了一组 Pod 的 Spec 里的标准字段,以及对应的值。比如,env 里定义了 DB_PORT 这个环境变量,volumeMounts 定义了容器 Volume 的挂载目录,volumes 定义了一个 emptyDir 的 Volume。接下来,我们假定运维人员先创建了这个 PodPreset,然后开发人员才创建 Pod:
$ kubectl create -f preset.yaml
$ kubectl create -f pod.yaml
这时,Pod 运行起来之后,我们查看一下这个 Pod 的 API 对象:
$ kubectl get pod website -o yaml
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
role: frontend
annotations:
podpreset.admission.kubernetes.io/podpreset-allow-database: "resource version"
spec:
containers:
- name: website
image: nginx
volumeMounts:
- mountPath: /cache
name: cache-volume
ports:
- containerPort: 80
env:
- name: DB_PORT
value: "6379"
volumes:
- name: cache-volume
emptyDir: {}
这个时候,我们就可以清楚地看到,这个 Pod 里多了新添加的 labels、env、volumes 和 volumeMount 的定义,它们的配置跟 PodPreset 的内容一样。此外,这个 Pod 还被自动加上了一个 annotation 表示这个 Pod 对象被 PodPreset 改动过。需要说明的是,PodPreset 里定义的内容,只会在 Pod API 对象被创建之前追加在这个对象本身上,而不会影响任何 Pod 的控制器的定义。比如,我们现在提交的是一个 nginx-deployment,那么这个 Deployment 对象本身是永远不会被 PodPreset 改变的,被修改的只是这个 Deployment 创建出来的所有 Pod。这一点请务必区分清楚。
如果你定义了同时作用于一个 Pod 对象的多个 PodPreset,会发生什么呢?实际上,Kubernetes 项目会帮你合并(Merge)这两个 PodPreset 要做的修改。而如果它们要做的修改有冲突的话,这些冲突字段就不会被修改。
secret
Secret解决了密码、token、密钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者Pod Spec中,也可以使用挂载的方式来解决灵活配置的问题。
我们先通过一个简单的实例了解一下secret:
$ cat ./username.txt
admin
$ cat ./password.txt
c1oudc0w!
$ kubectl create secret generic user --from-file=./username.txt
$ kubectl create secret generic pass --from-file=./password.txt
其中,username.txt 和 password.txt 文件里,存放的就是用户名和密码;而 user 和 pass,则是我为 Secret 对象指定的名字。而我想要查看这些 Secret 对象的话,只要执行一条 kubectl get 命令就可以了:
$ kubectl get secrets
NAME TYPE DATA AGE
user Opaque 1 51s
pass Opaque 1 51s
当然,除了使用 kubectl create secret 指令外,我也可以直接通过编写 YAML 文件的方式来创建这个 Secret 对象,比如:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
user: YWRtaW4=
pass: MWYyZDFlMmU2N2Rm
可以看到,通过编写 YAML 文件创建出来的 Secret 对象只有一个。但它的 data 字段,却以 Key-Value 的格式保存了两份 Secret 数据。其中,“user”就是第一份数据的 Key,“pass”是第二份数据的 Key。需要注意的是,Secret 对象要求这些数据必须是经过 Base64 转码的,以免出现明文密码的安全隐患,这也是我说的最好是使用文件命令行进行secret的创建,避免转码的麻烦,当然这个转码操作也很简单,比如:
$ echo -n 'admin' | base64
YWRtaW4=
$ echo -n '1f2d1e2e67df' | base64
MWYyZDFlMmU2N2Rm
解码
$ echo -n 'YWRtaW4=' | base64 -d
admin
$ echo -n 'MWYyZDFlMmU2N2Rm' | base64 -d
1f2d1e2e67df
创建好secret之后,有两种方式来使用它:
1、以Volume方式
将Secret挂载到Volume中
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
你还可以指定 Secret 将拥有的权限模式位。如果不指定,默认使用 0644。 你可以为整个 Secret 卷指定默认模式;如果需要,可以通过defaultMode为每个密钥设定重载值。比如
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
volumes:
- name: foo
secret:
secretName: mysecret
defaultMode: 256
当已经存储于卷中被使用的 Secret 被更新时,被映射的键也将终将被更新。 组件 kubelet 在周期性同步时检查被挂载的 Secret 是不是最新的。使用 Secret 作为子路径卷挂载的容器 不会收到 Secret 更新。
2、以环境变量方式
将Secret导出到环境变量中
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: wordpress-deployment
spec:
replicas: 2
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: wordpress
visualize: "true"
spec:
containers:
- name: "wordpress"
image: "wordpress"
ports:
- containerPort: 80
env:
- name: WORDPRESS_DB_USER
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
对应的环节变量就获取了secret对应的值。
在上面我们可以看到Secret有一个type,都是使用的Opaque,其实type有很多类型:
| 内置类型 | 用法 |
|---|---|
Opaque |
用户定义的任意数据,base64编码格式的Secret,用来存储密码、密钥等; |
kubernetes.io/service-account-token |
服务账号令牌 |
kubernetes.io/dockercfg |
~/.dockercfg 文件的序列化形式 |
kubernetes.io/dockerconfigjson |
~/.docker/config.json 文件的序列化形式,用来存储私有docker registry的认证信息。 |
kubernetes.io/basic-auth |
用于基本身份认证的凭据 |
kubernetes.io/ssh-auth |
用于 SSH 身份认证的凭据 |
kubernetes.io/tls |
用于 TLS 客户端或者服务器端的数据 |
bootstrap.kubernetes.io/token |
启动引导令牌数据 |
Opaque
- 当 Secret 配置文件中未作显式设定时,默认的 Secret 类型是
Opaque。 当你使用kubectl来创建一个 Secret 时,你会使用generic子命令来标明 要创建的是一个Opaque类型 Secret。
- 当 Secret 配置文件中未作显式设定时,默认的 Secret 类型是
kubectl create secret generic empty-secret
kubernetes.io/service-account-token- 类型为
kubernetes.io/service-account-token的 Secret 用来存放标识某 服务账号的令牌。使用这种 Secret 类型时,你需要确保对象的注解kubernetes.io/service-account-name被设置为某个已有的服务账号名称。Kubernetes 在创建 Pod 时会自动创建一个服务账号 Secret 并自动修改你的 Pod 以使用该 Secret。该服务账号令牌 Secret 中包含了访问 Kubernetes API 所需要的凭据。
- 类型为
其他类型可以在使用的时候到官方文档查询,很详细。
configmap
最常用的两种配置模式,一种就是正常的配置configmap,另外一种就是加密的secret,在上已经说过,我们来看看configmap。
configmap
1、ConfigMap 在设计上不是用来保存大量数据的,在 ConfigMap 中保存的数据不可超过 1 MiB。如果你需要保存超出此尺寸限制的数据,你可能希望考虑挂载存储卷 或者使用独立的数据库或者文件服务。
2、ConfigMap 使用 data 和 binaryData 字段。这些字段能够接收键-值对作为其取值。data 和 binaryData 字段都是可选的。data 字段设计用来保存 UTF-8 字节序列,而 binaryData 则 被设计用来保存二进制数据作为 base64 编码的字串。data 或 binaryData 字段下面的每个键的名称都必须由字母数字字符或者 -、_ 或 . 组成。在 data 下保存的键名不可以与在 binaryData 下 出现的键名有重叠。
3、ConfigMap 的名字必须是一个合法的 DNS 子域名。
4、从 v1.19 开始,你可以添加一个 immutable 字段到 ConfigMap 定义中,创建 不可变更的 ConfigMap。
5、你可以写一个引用 ConfigMap 的 Pod 的 spec,并根据 ConfigMap 中的数据 在该 Pod 中配置容器。这个 Pod 和 ConfigMap 必须要在同一个 名字空间 中。
configmap的作用
应用部署的一个最佳方案是将应用所需的配置信息与程序进行分离,这样可以使应用程序被更好的复用,通过不同的配置也能实现更灵活的功能,Kubernetes 1.2开始提供了这样一种统一的应用配置管理方案-configMap。
configmap的基本用法
以一个简单的例子开始我们的使用说明
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# 类属性键;每一个键都映射到一个简单的值
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
# 类文件键
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
可见在我们的data字段中有着不同的用法,可以是keyvalue的键值对,也可以是file。我们可以用多种方法将这个cm配置到pod中去,其实也就是我们下面要说的典型使用场景,我们先简单的看一下yaml配置:
apiVersion: v1
kind: Pod
metadata:
name: configmap-demo-pod
spec:
containers:
- name: demo
image: alpine
command: ["sleep", "3600"]
env:
# 定义环境变量
- name: PLAYER_INITIAL_LIVES # 请注意这里和 ConfigMap 中的键名是不一样的
valueFrom:
configMapKeyRef:
name: game-demo # 这个值来自 ConfigMap
key: player_initial_lives # 需要取值的键
- name: UI_PROPERTIES_FILE_NAME
valueFrom:
configMapKeyRef:
name: game-demo
key: ui_properties_file_name
volumeMounts:
- name: config
mountPath: "/config"
readOnly: true
volumes:
# 你可以在 Pod 级别设置卷,然后将其挂载到 Pod 内的容器中
- name: config
configMap:
# 提供你想要挂载的 ConfigMap 的名字
name: game-demo
# 来自 ConfigMap 的一组键,将被创建为文件
items:
- key: "game.properties"
path: "game.properties"
- key: "user-interface.properties"
path: "user-interface.properties"
下面我们通过典型场景来详细说明各种基本用法。
configmap典型场景
ConfigMap供容器使用的典型用法如下:
- 生成为容器内的环境变量
- 设置容器启动命令的启动参数(需设置为环境变量)
- 以volume的形式挂载为容器内部的文件或者目录
1、configMap编写变量注入pod中
比如我们用configmap创建两个变量,一个是nginx_port=80,一个是nginx_server=192.168.254.13
[root@master ~]# kubectl create configmap nginx-var --from-literal=nginx_port=80 --from-literal=nginx_server=192.168.254.13
configmap/nginx-var created
查看configmap
[root@master ~]# kubectl get cm
NAME DATA AGE
nginx-var 2 5s
[root@master ~]# kubectl describe cm nginx-var
Name: nginx-var
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
nginx_port:
----
80
nginx_server:
----
192.168.254.13
Events: <none>
然后我们创建pod,把这2个变量注入到环境变量当中
[root@master ~]# cat test2.yaml
apiVersion: v1
kind: Service
metadata:
name: service-nginx
namespace: default
spec:
type: NodePort
selector:
app: nginx
ports:
- name: nginx
port: 80
targetPort: 80
nodePort: 30080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mydeploy
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
name: web
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- name: nginx
containerPort: 80
volumeMounts:
- name: html
mountPath: /user/share/nginx/html/
env:
- name: TEST_PORT
valueFrom:
configMapKeyRef:
name: nginx-var
key: nginx_port
- name: TEST_HOST
valueFrom:
configMapKeyRef:
name: nginx-var
key: nginx_server
volumes:
- name: html
emptyDir: {}
执行pod文件
[root@master ~]# kubectl create -f test2.yaml
service/service-nginx created
查看pod
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mydeploy-d975ff774-fzv7g 1/1 Running 0 19s
mydeploy-d975ff774-nmmqt 1/1 Running 0 19s
进入到容器中查看环境变量
[root@master ~]# kubectl exec -it mydeploy-d975ff774-fzv7g -- /bin/sh
# printenv
SERVICE_NGINX_PORT_80_TCP_PORT=80
KUBERNETES_PORT=tcp://10.96.0.1:443
SERVICE_NGINX_PORT_80_TCP_PROTO=tcp
KUBERNETES_SERVICE_PORT=443
HOSTNAME=mydeploy-d975ff774-fzv7g
SERVICE_NGINX_SERVICE_PORT_NGINX=80
HOME=/root
PKG_RELEASE=1~buster
SERVICE_NGINX_PORT_80_TCP=tcp://10.99.184.186:80
TEST_HOST=192.168.254.13
TEST_PORT=80
TERM=xterm
KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1
NGINX_VERSION=1.17.3
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
KUBERNETES_PORT_443_TCP_PORT=443
NJS_VERSION=0.3.5
KUBERNETES_PORT_443_TCP_PROTO=tcp
SERVICE_NGINX_SERVICE_HOST=10.99.184.186
SERVICE_NGINX_PORT=tcp://10.99.184.186:80
SERVICE_NGINX_SERVICE_PORT=80
KUBERNETES_SERVICE_PORT_HTTPS=443
KUBERNETES_PORT_443_TCP=tcp://10.96.0.1:443
KUBERNETES_SERVICE_HOST=10.96.0.1
PWD=/
SERVICE_NGINX_PORT_80_TCP_ADDR=10.99.184.186
可以发现configMap当中的环境变量已经注入到了pod容器当中
这里要注意的是,如果是用这种环境变量的注入方式,pod启动后,如果在去修改configMap当中的变量,对于pod是无效的,如果是以卷的方式挂载,是可的实时更新的,这一点要清楚。
2、用configMap以存储卷的形式挂载到pod中
上面说到了configMap以变量的形式虽然可以注入到pod当中,但是如果在修改变量的话pod是不会更新的,如果想让configMap中的配置跟pod内部的实时更新,就需要以存储卷的形式挂载,在1.19中提供了不可变的configmap,应对新的需求。
[root@master ~]# cat test2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mydeploy
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
name: web
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- name: nginx
containerPort: 80
volumeMounts:
- name: html-config
mountPath: /nginx/vars/
readOnly: true
volumes:
- name: html-config
configMap:
name: nginx-var
执行yaml文件
[root@master ~]# kubectl create -f test2.yaml
deployment.apps/mydeploy created
查看pod
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mydeploy-6f6b6c8d9d-pfzjs 1/1 Running 0 90s
mydeploy-6f6b6c8d9d-r9rz4 1/1 Running 0 90s
进入到容器中
[root@master ~]# kubectl exec -it mydeploy-6f6b6c8d9d-pfzjs -- /bin/bash
在容器中查看configMap对应的配置
root@mydeploy-6f6b6c8d9d-pfzjs:/# cd /nginx/vars
root@mydeploy-6f6b6c8d9d-pfzjs:/nginx/vars# ls
nginx_port nginx_server
root@mydeploy-6f6b6c8d9d-pfzjs:/nginx/vars# cat nginx_port
80
root@mydeploy-6f6b6c8d9d-pfzjs:/nginx/vars#
修改configMap中的配置,把端口号从80修改成8080
[root@master ~]# kubectl edit cm nginx-var
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
data:
nginx_port: "8080"
nginx_server: 192.168.254.13
kind: ConfigMap
metadata:
creationTimestamp: "2019-09-13T14:22:20Z"
name: nginx-var
namespace: default
resourceVersion: "248779"
selfLink: /api/v1/namespaces/default/configmaps/nginx-var
uid: dfce8730-f028-4c57-b497-89b8f1854630
修改完稍等片刻查看文件档中的值,已然更新成8080
root@mydeploy-6f6b6c8d9d-pfzjs:/nginx/vars# cat nginx_port
8080
root@mydeploy-6f6b6c8d9d-pfzjs:/nginx/vars#
3、用configMap挂载配置文件
这里以nginx配置文件为例子,我们在宿主机上配置好nginx的配置文件,创建configmap,最后通过configmap注入到容器中
创建nginx配置文件
[root@master ~]# vim www.conf
server {
server_name: 192.168.254.13;
listen: 80;
root /data/web/html/;
}
创建configMap
[root@master ~]# kubectl create configmap nginx-config --from-file=/root/www.conf
configmap/nginx-config created
查看configMap
[root@master ~]# kubectl get cm
NAME DATA AGE
nginx-config 1 3m3s
nginx-var 2 63m
创建pod并挂载configMap存储卷
[root@master ~]# cat test2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mydeploy
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
name: web
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- name: nginx
containerPort: 80
volumeMounts:
- name: html-config
mountPath: /etc/nginx/conf.d/
readOnly: true
volumes:
- name: html-config
configMap:
name: nginx-config
启动容器,并让容器启动的时候就加载configMap当中的配置
[root@master ~]# kubectl create -f test2.yaml
deployment.apps/mydeploy created
查看容器
[root@master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mydeploy-fd46f76d6-jkq52 1/1 Running 0 22s 10.244.1.46 node1 <none> <none>
访问容器当中的网页,80端口是没问题的,8888端口访问不同
[root@master ~]# curl 10.244.1.46
this is test web
[root@master ~]# curl 10.244.1.46:8888
curl: (7) Failed connect to 10.244.1.46:8888; 拒绝连接
接下来我们去修改configMap当中的内容,吧80端口修改成8888
[root@master ~]# kubectl edit cm nginx-config
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
data:
www.conf: |
server {
server_name 192.168.254.13;
listen 8888;
root /data/web/html/;
}
kind: ConfigMap
metadata:
creationTimestamp: "2019-09-13T15:22:22Z"
name: nginx-config
namespace: default
resourceVersion: "252615"
selfLink: /api/v1/namespaces/default/configmaps/nginx-config
uid: f1881f87-5a91-4b8e-ab39-11a2f45733c2
进入到容器查看配置文件,可以发现配置文件已经修改过来了
root@mydeploy-fd46f76d6-jkq52:/usr/bin# cat /etc/nginx/conf.d/www.conf
server {
server_name 192.168.254.13;
listen 8888;
root /data/web/html/;
}
在去测试访问,发现还是报错,这是因为配置文件虽然已经修改了,但是nginx服务并没有加载配置文件,我们手动加载一下,以后可以用脚本形式自动完成加载文件
[root@master ~]# curl 10.244.1.46
this is test web
[root@master ~]# curl 10.244.1.46:8888
curl: (7) Failed connect to 10.244.1.46:8888; 拒绝连接
在容器内部手动加载配置文件
root@mydeploy-fd46f76d6-jkq52:/usr/bin# nginx -s reload
2019/09/13 16:04:12 [notice] 34#34: signal process started
再去测试访问,可以看到80端口已经访问不通,反而是我们修改的8888端口可以访问通
[root@master ~]# curl 10.244.1.46
curl: (7) Failed connect to 10.244.1.46:80; 拒绝连接
[root@master ~]# curl 10.244.1.46:8888
this is test web
4、用作命令行参数
将 ConfigMap 用作命令行参数时,需要先把 ConfigMap 的数据保存在环境变量中,然后通过 $(VAR_NAME) 的方式引用环境变量.
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: gcr.io/google_containers/busybox
command: ["/bin/sh", "-c", "echo $(SPECIAL_LEVEL_KEY) $(SPECIAL_TYPE_KEY)" ]
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.how
- name: SPECIAL_TYPE_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.type
restartPolicy: Never
当 Pod 结束后会输出
very charm
5、使用 subpath 将 ConfigMap 作为单独的文件挂载到目录
在一般情况下 configmap 挂载文件时,会先覆盖掉挂载目录,然后再将 congfigmap 中的内容作为文件挂载进行。如果想不对原来的文件夹下的文件造成覆盖,只是将 configmap 中的每个 key,按照文件的方式挂载到目录下,可以使用 subpath 参数。
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: nginx
command: ["/bin/sh","-c","sleep 36000"]
volumeMounts:
- name: config-volume
mountPath: /etc/nginx/special.how
subPath: special.how
volumes:
- name: config-volume
configMap:
name: special-config
items:
- key: special.how
path: special.how
restartPolicy: Never
root@dapi-test-pod:/# ls /etc/nginx/
conf.d fastcgi_params koi-utf koi-win mime.types modules nginx.conf scgi_params special.how uwsgi_params win-utf
root@dapi-test-pod:/# cat /etc/nginx/special.how
very
root@dapi-test-pod:/#
configmap的实际应用
1、我们经常使用的就是设置pod的环境变量,比如一些IP和端口的设置
[root@001 ~]# kubectl get cm agent-config -n kube-system -o yaml
apiVersion: v1
data:
voyage_agent_exporter_port: "969"
voyage_agent_grpc_port: "966"
voyage_agent_http_port: "968"
voyage_agent_mulit_uplinks: '{"ovs":["service0", "service1"]}'
voyage_agent_netlink_timeout: "10000"
voyage_agent_single_uplinks: service0,service1
voyage_cni_config: |-
{
"cniVersion": "0.3.1",
"name": "voyage-net",
"type": "voyage-cni"
}
voyage_server_grpc_port: "961"
voyage_server_ip_list: 10.243.40.1,10.243.40.2,10.243.40.3
kind: ConfigMap
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","data":{"voyage_agent_exporter_port":"969","voyage_agent_grpc_port":"966","voyage_agent_http_port":"968","voyage_agent_mulit_uplinks":"{\"ovs\":[\"service0\", \"service1\"]}","voyage_agent_netlink_timeout":"10000","voyage_agent_single_uplinks":"service0,service1","voyage_cni_config":"{\n \"cniVersion\": \"0.3.1\",\n \"name\": \"voyage-net\",\n \"type\": \"voyage-cni\"\n}","voyage_server_grpc_port":"961","voyage_server_ip_list":"10.243.40.1,10.243.40.2,10.243.40.3"},"kind":"ConfigMap","metadata":{"annotations":{},"name":"voyage-agent-config","namespace":"kube-system"}}
creationTimestamp: "2020-01-19T18:03:55Z"
name: voyage-agent-config
namespace: kube-system
resourceVersion: "692680451"
selfLink: /api/v1/namespaces/kube-system/configmaps/voyage-agent-config
uid: 0ebf9112-3ae6-11ea-ad4e-6c92bf8d8058
对于这些配置我们设置一个配置中心,然后在每次发布的时候,拉去配置来在yaml设置环境变量,如下,我们更多的是使用env,比如日志采集的环境变量,但是由于这种方式并不是实时的,如果修改还是需要重新发布,所以并不常用。
spec:
containers:
- args:
- --log.file=/opt/logs/app/test1.log
- --log.interval=60s
- --log.lineSize=500
- --log.maxLines=10000000
env:
- name: test_log_app
value: /opt/logs/app/*.log
- name: test_log_app_prefix
value: V1,ldcId,hostgroup,appId,ip,path,lid
- name: appId
value: loggen
- name: test_log_app_brokerlist
value: kafkasit02broker01.cnsuning.com:9092,kafkasit02broker02.cnsuning.com:9092,kafkasit02broker03.cnsuning.com:9092
- name: test_log_app_topic
value: ctdsa_nodejs_sit_njxz
- name: KUBERNETES_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
image: xgharborsit01.sncloud.com/sncloud/loggen:v0.0.1
imagePullPolicy: IfNotPresent
name: loggen
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /opt/logs
name: log
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-gj6mr
readOnly: true
dnsPolicy: ClusterFirst
2、将应用的配置文件挂载,然后给应用程序启动使用,是我们最常用的,比如filebeat的yaml文件。
[root@xgpcc01m010243040001 ~]# kubectl get cm filebeat-config -n kube-system -o yaml
apiVersion: v1
data:
filebeat-k8slog.yml: "filebeat.inputs:\n- type: log\n enabled: true\n close_eof:
false\n close_inactive: 5m\n close_removed: false\n close_renamed: false\n
\ ignore_older: 48h\n clean_inactive: 72h\n clean_removed: true\n paths:\n
\ - \"\"\n fields_under_root: true\n fields:\n brokerlist:\n split: \"
\ \"\noutput.kafka:\n topic: \n version: \"0.8.2.2\"\n codec.format:\n
\ ignoreNotFound: true\n string: 'V1%{[split]}%{[ldc]}%{[split]}%{[hostgroup]}%{[split]}%{[appid]}%{[split]}%{[ip]}%{[split]}%{[path]}%{[split]}%{[lid]}%{[split]}%{[host.name]}%{[split]}%{[host.ip]}%{[split]}%{[@timestamp]}%{[split]}%{[message]}'\n"
filebeat.yml: |
max_procs: 2
queue:
mem:
events: 512
flush.min_events: 256
filebeat.inputs:
- type: log
enabled: false
paths:
- /var/log/filebeat-pause.log
filebeat.config:
inputs:
enabled: true
path: ${path.home}/inputs.d/*.yml
reload.enabled: true
reload.period: 10s
output.kafka:
topic: "%{[topic]}"
version: "0.8.2.2"
codec.format:
ignoreNotFound: true
string: '%{[message]}'
metadata:
retry.max: 2
full: true
kind: ConfigMap
metadata:
creationTimestamp: "2020-04-23T13:58:00Z"
name: filebeat-config
namespace: kube-system
resourceVersion: "654788331"
selfLink: /api/v1/namespaces/kube-system/configmaps/filebeat-config
uid: 7153cf8e-856a-11ea-8bc6-6c92bf977c52
再来看filebeat的资源配置清单filebeat.yaml
[root@xgpcc01m010243040001 ~]# kubectl get ds filebeat -n kube-system -o yaml
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
creationTimestamp: "2020-04-09T17:43:00Z"
generation: 2
labels:
addon: filebeat
app: filebeat
namespace: kube-system
name: filebeat
namespace: kube-system
resourceVersion: "741573898"
selfLink: /apis/extensions/v1beta1/namespaces/kube-system/daemonsets/filebeat
uid: 8e6ee5ef-7a89-11ea-a446-6c92bf8d8058
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
addon: filebeat
app: filebeat
namespace: kube-system
template:
metadata:
creationTimestamp: null
labels:
addon: filebeat
app: filebeat
namespace: kube-system
spec:
containers:
- args:
- --path.home=/opt/filebeats/filebeat
- --path.config=/etc/filebeat
- --httpprof=:6060
command:
- /opt/filebeats/bin/filebeat
env:
- name: ldc
value: DEV
- name: appid
value: APP
- name: envType
value: prd
- name: system_MwType_serviceID
value: APP_filebeat_01
- name: cloudHostGroupId
value: "01"
- name: KUBERNETES_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: HOST_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.hostIP
image: test/filebeat:7.5.2-4
imagePullPolicy: Always
name: filebeat
resources:
limits:
cpu: "3"
memory: 2Gi
requests:
cpu: "1"
memory: 800Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /host/var/lib/kubelet/pods
mountPropagation: HostToContainer
name: kubeletpods
readOnly: true
- mountPath: /opt/filebeats/filebeat
name: k8slog
subPath: filebeats/filebeat
- mountPath: /etc/filebeat
name: config
- args:
- --path.home=/opt/filebeats/filebeat-k8slog
- --path.config=/etc/filebeat
- -c
- filebeat-k8slog.yml
command:
- /opt/filebeats/bin/filebeat
env:
- name: ldc
value: DEV
- name: appid
value: APP
- name: envType
value: prd
- name: system_MwType_serviceID
value: APP_filebeat_01
- name: cloudHostGroupId
value: "01"
- name: KUBERNETES_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: HOST_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.hostIP
image: test/filebeat:7.5.2-4
imagePullPolicy: Always
name: filebeat-k8slog
resources:
limits:
cpu: 250m
memory: 512Mi
requests:
cpu: 125m
memory: 125Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /opt/filebeats/filebeat-k8slog
name: k8slog
subPath: filebeats/filebeat-k8slog
- mountPath: /k8s_log
name: k8slog
- mountPath: /etc/filebeat
name: config
- args:
- --path.base=/host
- --path.template=filebeat.tpl
- --path.filebeat-home=/opt/filebeats/filebeat
- --path.logs=/opt/log-pilot/logs
- --logLevel=debug
- --logPrefix=sn
command:
- /opt/log-pilot/bin/log-pilot
env:
- name: ldc
value: DEV
- name: appid
value: APP
- name: envType
value: prd
- name: system_MwType_serviceID
value: APP_filebeat_01
- name: cloudHostGroupId
value: "01"
- name: KUBERNETES_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
image: test/log-pilot:1.0.2
imagePullPolicy: Always
name: log-pilot
resources:
limits:
cpu: 250m
memory: 512Mi
requests:
cpu: 125m
memory: 125Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /opt/filebeats/filebeat
name: k8slog
subPath: filebeats/filebeat
- mountPath: /opt/log-pilot/logs
name: k8slog
subPath: log-pilot
- mountPath: /host/var/lib/kubelet/pods
mountPropagation: HostToContainer
name: kubeletpods
readOnly: true
- mountPath: /var/run/docker.sock
mountPropagation: HostToContainer
name: docker-sock
readOnly: true
dnsPolicy: ClusterFirst
hostNetwork: true
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
volumes:
- configMap:
defaultMode: 420
name: filebeat-config
name: config
- hostPath:
path: /var/lib/kubelet/pods
type: ""
name: kubeletpods
- hostPath:
path: /var/run/docker.sock
type: ""
name: docker-sock
- hostPath:
path: /k8s_log
type: ""
name: k8slog
templateGeneration: 6
updateStrategy:
rollingUpdate:
maxUnavailable: 25%
type: RollingUpdate
status:
currentNumberScheduled: 128
desiredNumberScheduled: 128
numberAvailable: 128
numberMisscheduled: 0
numberReady: 128
observedGeneration: 2
updatedNumberScheduled: 128
label
label
Label keys的语法
- 一个可选前缀+名称,通过/来区分
- 名称部分是必须的,并且最多63个字符,开始和结束的字符必须是字母或者数字,中间是字母数字和_、-、.。
- 前缀可选,如指定必须是个DNS子域,一系列的DNS label通过.来划分,长度不超过253个字符,“/”来结尾。如前缀被省略了,这个Label的key被假定为对用户私有的。系统组成部分(比如scheduler,controller-manager,apiserver,kubectl),必须要指定一个前缀,Kuberentes.io前缀是为K8S内核部分保留的。
label value语法
- 长度不超过63个字符。
- 可以为空
- 首位字符必须为字母数字字符
- 中间必须是横线、_、.、数字、字母。
主要用于label selector对其他的没有任何意义。
Label选择器
基于相等性或者不相等性的
environment = production
tier != frontend
第一个选择所有键等于 environment 值为 production 的资源。后一种选择所有键为 tier 值不等于 frontend 的资源,和那些没有键为 tier 的label的资源。
要过滤所有处于 production 但不是 frontend 的资源,可以使用逗号操作符
environment=production,tier!=frontend
基于set的条件
基于集合的label条件允许用一组值来过滤键。支持三种操作符: in , notin ,和 exists(仅针对于key符号) 。例如:
environment in (production, qa)
tier notin (frontend, backend)
partition
!partitio
主要使用场景
1、kube-controller进程通过资源对象RC上定义的Label Selector来筛选要监控的pod副本的数量,实现pod数量的自动控制。
2、kube-proxy进程通过service的Label Selector来选择对应的Pod,建立出对应的Pod的转发路由表。
3、通过Node定义的Label,使用NodeSelector实现定向调度。
service
Kubernete Service 是一个定义了一组Pod的策略的抽象,我们也有时候叫做宏观服务,也可以是我们常说的微服务,之前说的pod,rs等就是服务。这些被服务标记的Pod都是(一般)通过label Selector决定的。可见service主要提供了负载均衡和服务发现的功能。
我们已经能够通过ReplicaSet来创建一组Pod来提供具有高可用性的服务。虽然每个Pod都会分配一个单独的Pod IP,然而却存在如下两问题:
- Pod IP仅仅是集群内可见的虚拟IP,外部无法访问。
- Pod IP会随着Pod的销毁而消失,当ReplicaSet对Pod进行动态伸缩时,Pod IP可能随时随地都会变化,这样对于我们访问这个服务带来了难度。
- 一组pod之间需要实现负载均衡的需求。
因此,Kubernetes中的Service对象就是解决以上问题的实现服务发现核心关键。
yaml模版
参考k8s权威指南第二章第五节。
基本使用
Service同其他Kubernetes对象一样,也是通过yaml或json文件进行定义。此外,它和其他Controller对象一样,通过Label Selector来确定一个Service将要使用哪些Pod。一个简单的Service定义如下:
apiVersion: v1
kind: Service
metadata:
labels:
run: nginx
name: nginx-service
spec:
ports:
- port: 80
protocol: TCP
targetPort: 81
selector:
app: nginx
type: ClusterIP
解析
1、通过spec.selector字段确定这个Service将要使用哪些Label。在本例中,这个名为nginx的Service,将会管理所有具有app: nginxLabel的Pod。
2、spec.ports.port: 80表明此Service将会监听80端口,并将所有监听到的请求转发给其管理的Pod。spec.ports.targetPort: 81表明此Service监听到的80端口的请求都会被转发给其管理的Pod的81端口,此字段可以省略,省略后其值会被设置为spec.ports.port的值。
3、type: ClusterIP表面此Service的type,有如下几种
- ClusterIP。默认值。给这个Service分配一个Cluster IP,它是Kubernetes系统自动分配的虚拟IP,因此只能在集群内部访问。
- NodePort。将Service通过指定的Node上的端口暴露给外部。通过此方法,访问任意一个NodeIP:nodePort都将路由到ClusterIP,从而成功获得该服务。
- LoadBalancer。在 NodePort 的基础上,借助 cloud provider 创建一个外部的负载均衡器,并将请求转发到
:NodePort。此模式只能在云服务器(AWS等)上使用。 - ExternalName。将服务通过 DNS CNAME 记录方式转发到指定的域名(通过 spec.externlName 设定)。需要 kube-dns 版本在 1.7 以上。
实例
1、假如有3个app: nginx Pod运行在3个不同的Node中,那么此时客户端访问任意一个Node的30001端口都能访问到这个nginx服务。
apiVersion: v1
kind: Service
metadata:
name: nginx-service
labels:
run: nginx
spec:
selector:
app: nginx
ports:
- port: 80
nodePort: 30001
type: NodePort
2、如果云服务商支持外接负载均衡器,则可以通过spec.type=LoadBalancer来定义Service
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
clusterIP: 10.0.171.239
loadBalancerIP: 78.11.24.19
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 146.148.47.155
创建
kubectl apply -f service.yaml
查看service
kubectl discribe service
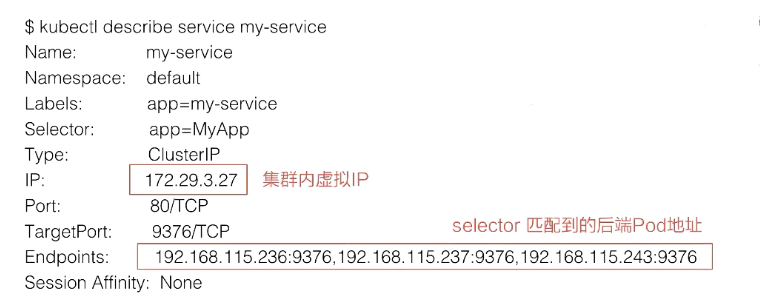
这个 IP 地址就是 service 的 IP 地址(clusterIP),这个 IP 地址在集群里面可以被其它 pod 所访问,相当于通过这个 IP 地址提供了统一的一个 pod 的访问入口,以及服务发现。
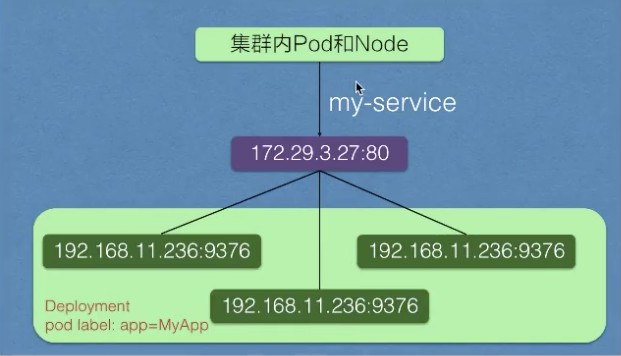
实际的架构如上图所示。在 service 创建之后,它会在集群里面创建一个虚拟的 IP 地址以及端口,在集群里,所有的 pod 和 node 都可以通过这样一个 IP 地址和端口去访问到这个 service。这个 service 会把它选择的 pod 及其 IP 地址都挂载到后端。这样通过 service 的 IP 地址访问时,就可以负载均衡到后端这些 pod 上面去。
当 pod 的生命周期有变化时,比如说其中一个 pod 销毁,service 就会自动从后端摘除这个 pod。这样实现了:就算 pod 的生命周期有变化,它访问的端点是不会发生变化的。
在上图中,被 selector 选中的 Pod,就称为 Service 的 Endpoints,你可以使用 kubectl get ep 命令看到它们。只有处于 Running 状态,且 readinessProbe 检查通过的 Pod,才会出现在 Service 的 Endpoints 列表里。并且,当某一个 Pod 出现问题时,Kubernetes 会自动把它从 Service 里摘除掉。
$ kubectl get endpoints hostnames
NAME ENDPOINTS
hostnames 10.244.0.5:9376,10.244.0.6:9376,10.244.0.7:9376
访问service
集群内
1、首先我们可以通过 service 的虚拟 IP 去访问,比如说刚创建的 my-service 这个服务,通过 kubectl get svc 或者 kubectl discribe service 都可以看到它的虚拟 IP 地址是 172.29.3.27,端口是 80,然后就可以通过这个虚拟 IP 及端口在 pod 里面直接访问到这个 service 的地址。
2、第二种方式直接访问服务名,依靠 DNS 解析,就是同一个 namespace 里 pod 可以直接通过 service 的名字去访问到刚才所声明的这个 service。不同的 namespace 里面,我们可以通过 service 名字加“.”,然后加 service 所在的哪个 namespace 去访问这个 service,例如我们直接用 curl 去访问,就是 my-service:80 就可以访问到这个 service。
3、第三种是通过环境变量访问,在同一个 namespace 里的 pod 启动时,K8s 会把 service 的一些 IP 地址、端口,以及一些简单的配置,通过环境变量的方式放到 K8s 的 pod 里面。在 K8s pod 的容器启动之后,通过读取系统的环境变量比读取到 namespace 里面其他 service 配置的一个地址,或者是它的端口号等等。比如在集群的某一个 pod 里面,可以直接通过 curl $ 取到一个环境变量的值,比如取到 MY_SERVICE_SERVICE_HOST 就是它的一个 IP 地址,MY_SERVICE 就是刚才我们声明的 MY_SERVICE,SERVICE_PORT 就是它的端口号,这样也可以请求到集群里面的 MY_SERVICE 这个 service。
集群外
1、NodePort 的方式就是在集群的 node 上面(即集群的节点的宿主机上面)去暴露节点上的一个端口,这样相当于在节点的一个端口上面访问到之后就会再去做一层转发,转发到虚拟的 IP 地址上面,就是刚刚宿主机上面 service 虚拟 IP 地址。
举个例子
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
type: NodePort
ports:
- nodePort: 8080
targetPort: 80
protocol: TCP
name: http
- nodePort: 443
protocol: TCP
name: https
selector:
run: my-nginx
在这个 Service 的定义里,我们声明它的类型是,type=NodePort。然后,我在 ports 字段里声明了 Service 的 8080 端口代理 Pod 的 80 端口,Service 的 443 端口代理 Pod 的 443 端口。当然,如果你不显式地声明 nodePort 字段,Kubernetes 就会为你分配随机的可用端口来设置代理。这个端口的范围默认是 30000-32767,你可以通过 kube-apiserver 的–service-node-port-range 参数来修改它。那么这时候,要访问这个 Service,你只需要访问:<任何一台宿主机的IP地址>:8080就可以访问到某一个被代理的 Pod 的 80 端口了。
在 NodePort 方式下,Kubernetes 会在 IP 包离开宿主机发往目的 Pod 时,对这个 IP 包做一次 SNAT 操作,这条规则设置在 POSTROUTING 检查点,也就是说,它给即将离开这台主机的 IP 包,进行了一次 SNAT 操作,将这个 IP 包的源地址替换成了这台宿主机上的 CNI 网桥地址,或者宿主机本身的 IP 地址(如果 CNI 网桥不存在的话)。
client
\ ^
\ \
v \
node 1 <--- node 2
| ^ SNAT
| | --->
v |
endpoint
当一个外部的 client 通过 node 2 的地址访问一个 Service 的时候,node 2 上的负载均衡规则,就可能把这个 IP 包转发给一个在 node 1 上的 Pod。这里没有任何问题。而当 node 1 上的这个 Pod 处理完请求之后,它就会按照这个 IP 包的源地址发出回复。可是,如果没有做 SNAT 操作的话,这时候,被转发来的 IP 包的源地址就是 client 的 IP 地址。所以此时,Pod 就会直接将回复发给client。对于 client 来说,它的请求明明发给了 node 2,收到的回复却来自 node 1,这个 client 很可能会报错。所以,在上图中,当 IP 包离开 node 2 之后,它的源 IP 地址就会被 SNAT 改成 node 2 的 CNI 网桥地址或者 node 2 自己的地址。这样,Pod 在处理完成之后就会先回复给 node 2(而不是 client),然后再由 node 2 发送给 client。
当然,这也就意味着这个 Pod 只知道该 IP 包来自于 node 2,而不是外部的 client。对于 Pod 需要明确知道所有请求来源的场景来说,这是不可以的。所以这时候,你就可以将 Service 的 spec.externalTrafficPolicy 字段设置为 local,这就保证了所有 Pod 通过 Service 收到请求之后,一定可以看到真正的、外部 client 的源地址。而这个机制的实现原理也非常简单:这时候,一台宿主机上的 iptables 规则,会设置为只将 IP 包转发给运行在这台宿主机上的 Pod。所以这时候,Pod 就可以直接使用源地址将回复包发出,不需要事先进行 SNAT 了。这个流程,如下所示:
client
^ / \
/ / \
/ v X
node 1 node 2
^ |
| |
| v
endpoint
当然,这也就意味着如果在一台宿主机上,没有任何一个被代理的 Pod 存在,比如上图中的 node 2,那么你使用 node 2 的 IP 地址访问这个 Service,就是无效的。此时,你的请求会直接被 DROP 掉。
2、也可以直接把容器的port直接映射到node上,hostNetWork=true
3、LoadBalancer 类型就是在 NodePort 上面又做了一层转换,刚才所说的 NodePort 其实是集群里面每个节点上面一个端口,LoadBalancer 是在所有的节点前又挂一个负载均衡。比如在阿里云上挂一个 SLB,这个负载均衡会提供一个统一的入口,并把所有它接触到的流量负载均衡到每一个集群节点的 node pod 上面去。然后 node pod 再转化成 ClusterIP,去访问到实际的 pod 上面。
从外部访问 Service 的第二种方式,适用于公有云上的 Kubernetes 服务。这时候,你可以指定一个 LoadBalancer 类型的 Service,如下所示:
---
kind: Service
apiVersion: v1
metadata:
name: example-service
spec:
ports:
- port: 8765
targetPort: 9376
selector:
app: example
type: LoadBalancer
在公有云提供的 Kubernetes 服务里,都使用了一个叫作 CloudProvider 的转接层,来跟公有云本身的 API 进行对接。所以,在上述 LoadBalancer 类型的 Service 被提交后,Kubernetes 就会调用 CloudProvider 在公有云上为你创建一个负载均衡服务,并且把被代理的 Pod 的 IP 地址配置给负载均衡服务做后端。
其实由于每个 Service 都要有一个负载均衡服务,所以这个做法实际上既浪费成本又高。作为用户,我其实更希望看到 Kubernetes 为我内置一个全局的负载均衡器。然后,通过我访问的 URL,把请求转发给不同的后端 Service。这种全局的、为了代理不同后端 Service 而设置的负载均衡服务,就是 Kubernetes 里的 Ingress 服务。
4、 Kubernetes 在 1.7 之后支持的一个新特性,叫作 ExternalName
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
type: ExternalName
externalName: my.database.example.com
在上述 Service 的 YAML 文件中,我指定了一个 externalName=my.database.example.com 的字段。而且你应该会注意到,这个 YAML 文件里不需要指定 selector。这时候,当你通过 Service 的 DNS 名字访问它的时候,比如访问:my-service.default.svc.cluster.local。那么,Kubernetes 为你返回的就是my.database.example.com。所以说,ExternalName 类型的 Service,其实是在 kube-dns 里为你添加了一条 CNAME 记录。这时,访问 my-service.default.svc.cluster.local 就和访问 my.database.example.com 这个域名是一个效果了。
在理解了 Kubernetes Service 机制的工作原理之后,很多与 Service 相关的问题,其实都可以通过分析 Service 在宿主机上对应的 iptables 规则(或者 IPVS 配置)得到解决。
没有 selector 的 Service
服务最常见的是抽象化对 Kubernetes Pod 的访问,但是它们也可以抽象化其他种类的后端。 实例:
- 希望在生产环境中使用外部的数据库集群,但测试环境使用自己的数据库。
- 希望服务指向另一个 命名空间 中或其它集群中的服务。
- 您正在将工作负载迁移到 Kubernetes。 在评估该方法时,您仅在 Kubernetes 中运行一部分后端。
在任何这些场景中,都能够定义没有 selector 的 Service。 实例:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
由于此服务没有选择器,因此 不会 自动创建相应的 Endpoint 对象。 您可以通过手动添加 Endpoint 对象,将服务手动映射到运行该服务的网络地址和端口:
apiVersion: v1
kind: Endpoints
metadata:
name: my-service
subsets:
- addresses:
- ip: 192.0.2.42
ports:
- port: 9376
访问没有 selector 的 Service,与有 selector 的 Service 的原理相同。 请求将被路由到用户定义的 Endpoint, YAML中为: 192.0.2.42:9376 (TCP)。
ExternalName Service 是 Service 的特例,它没有 selector,也没有使用 DNS 名称代替。
Headless Service
service 有一个特别的形态就是 Headless Service。service 创建的时候可以指定 clusterIP:None,告诉 K8s 说我不需要 clusterIP(就是刚才所说的集群里面的一个虚拟 IP),然后 K8s 就不会分配给这个 service 一个虚拟 IP 地址,它没有虚拟 IP 地址怎么做到负载均衡以及统一的访问入口呢?
它是这样来操作的:pod 可以直接通过 service_name 用 DNS 的方式解析到所有后端 pod 的 IP 地址,通过 DNS 的 A 记录的方式会解析到所有后端的 Pod 的地址,由客户端选择一个后端的 IP 地址,这个 A 记录会随着 pod 的生命周期变化,返回的 A 记录列表也发生变化,这样就要求客户端应用要从 A 记录把所有 DNS 返回到 A 记录的列表里面 IP 地址中,客户端自己去选择一个合适的地址去访问 pod。

可以从上图看一下跟刚才我们声明的模板的区别,就是在中间加了一个 clusterIP:None,即表明不需要虚拟 IP作为”头”,这也是headless的意思。实际效果就是集群的 pod 访问 my-service 时,会直接解析到所有的 service 对应 pod 的 IP 地址,返回给 pod,然后 pod 里面自己去选择一个 IP 地址去直接访问。
如何获取pod_ip,依然是采用Label Selector 机制选择出来的,即:所有携带了 app=myapp 标签的 Pod,都会被这个 Service 代理起来。它所代理的所有 Pod 的 IP 地址,都会被绑定一个这样格式的 DNS 记录,如下所示:
<pod-name>.<svc-name>.<namespace>.svc.cluster.local
这个 DNS 记录,正是 Kubernetes 项目为 Pod 分配的唯一的“可解析身份”(Resolvable Identity)。有了这个“可解析身份”,只要你知道了一个 Pod 的名字,以及它对应的 Service 的名字,你就可以非常确定地通过这条 DNS 记录访问到 Pod 的 IP 地址。至于这条记录原生的DNS会自动维护,就不需要操心了。
service的实现
Service的iptables模式 是由 kube-proxy 组件,加上 iptables 来共同实现的。
一旦service被提交给 Kubernetes,那么 kube-proxy 就可以通过 Service 的 Informer 感知到这样一个 Service 对象的添加。而作为对这个事件的响应,它就会在宿主机上创建这样一条 iptables 规则(你可以通过 iptables-save 看到它),如下所示:
-A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames: cluster IP" -m tcp --dport 80 -j KUBE-SVC-NWV5X2332I4OT4T3
条 iptables 规则的含义是:凡是目的地址是 10.0.1.175、目的端口是 80 的 IP 包,都应该跳转到另外一条名叫 KUBE-SVC-NWV5X2332I4OT4T3 的 iptables 链进行处理。
10.0.1.175 正是这个 Service 的 VIP。所以这一条规则,就为这个 Service 设置了一个固定的入口地址。并且,由于 10.0.1.175 只是一条 iptables 规则上的配置,并没有真正的网络设备,所以你 ping 这个地址,是不会有任何响应的。
我们即将跳转到的 KUBE-SVC-NWV5X2332I4OT4T3 规则,实际上,它是一组规则的集合,如下所示:
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2IHDGP2BOBGZ
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-X3P2623AGDH6CDF3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -j KUBE-SEP-57KPRZ3JQVENLNBR
这一组规则,实际上是一组随机模式(–mode random)的 iptables 链。而随机转发的目的地,分别是 KUBE-SEP-WNBA2IHDGP2BOBGZ、KUBE-SEP-X3P2623AGDH6CDF3 和 KUBE-SEP-57KPRZ3JQVENLNBR。而这三条链指向的最终目的地,其实就是这个 Service 代理的三个 Pod。所以这一组规则,就是 Service 实现负载均衡的位置。需要注意的是,iptables 规则的匹配是从上到下逐条进行的,所以为了保证上述三条规则每条被选中的概率都相同,我们应该将它们的 probability 字段的值分别设置为 1/3(0.333…)、1/2 和 1。这么设置的原理很简单:第一条规则被选中的概率就是 1/3;而如果第一条规则没有被选中,那么这时候就只剩下两条规则了,所以第二条规则的 probability 就必须设置为 1/2;类似地,最后一条就必须设置为 1。
通过查看上述三条链的明细,我们就很容易理解 Service 进行转发的具体原理了,如下所示:
-A KUBE-SEP-57KPRZ3JQVENLNBR -s 10.244.3.6/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-57KPRZ3JQVENLNBR -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.3.6:9376
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -s 10.244.1.7/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.1.7:9376
-A KUBE-SEP-X3P2623AGDH6CDF3 -s 10.244.2.3/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-X3P2623AGDH6CDF3 -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.2.3:9376
这三条链,其实是三条 DNAT 规则。DNAT 规则的作用,就是在 PREROUTING 检查点之前,也就是在路由之前,将流入 IP 包的目的地址和端口,改成–to-destination 所指定的新的目的地址和端口。可以看到,这个目的地址和端口,正是被代理 Pod 的 IP 地址和端口。这样,访问 Service VIP 的 IP 包经过上述 iptables 处理之后,就已经变成了访问具体某一个后端 Pod 的 IP 包了。不难理解,这些 Endpoints 对应的 iptables 规则,正是 kube-proxy 通过监听 Pod 的变化事件,在宿主机上生成并维护的。
以上,就是 Service 使用iptabels最基本的工作原理。ipvs是使用ipvs内核虚拟机在内核实现负载均衡来提高性能的。
总结
一个 iptables 模式的 Service 对应的规则
- KUBE-SERVICES 或者 KUBE-NODEPORTS 规则对应的 Service 的入口链,这个规则应该与 VIP 和 Service 端口一一对应;
- KUBE-SEP-(hash) 规则对应的 DNAT 链,这些规则应该与 Endpoints 一一对应;
- KUBE-SVC-(hash) 规则对应的负载均衡链,这些规则的数目应该与 Endpoints 数目一致;
- 如果是 NodePort 模式的话,还有 POSTROUTING 处的 SNAT 链。
Volume,pv,pvc,StorageClass
基本概念
Kubernetes中存储中有四个重要的概念:[Volume]()、PV(PersistentVolume)、PVC(PersistentVolumeClaim) 、StorageClass。掌握了这四个概念,就掌握了Kubernetes中存储系统的核心。
- Volumes就是存储卷,是最基础的存储抽象,其支持多种类型,包括本地存储、NFS以及众多的云存储,我们也可以编写自己的存储插件来支持特定的存储系统。Volume可以被Pod直接使用,也可以被PV使用。普通的Volume和Pod之间是一种静态的绑定关系,在定义Pod的同时,通过volume属性来定义存储的类型,通过volumeMount来定义容器内的挂载点,这两种属性的具体配置针对每一种存储都不相同,具体实例可以查看官方文档。
- PersistentVolume。与普通的Volume不同,PV是Kubernetes中的一个api资源对象,创建一个PV相当于创建了一个存储资源对象,这个资源的使用要通过PVC来请求。描述的,是持久化存储数据卷。这个 API 对象主要定义的是一个持久化存储在宿主机上的目录,比如一个 NFS 的挂载目录。
- PersistentVolumeClaim。PVC是用户对存储资源PV的请求,根据PVC中指定的条件Kubernetes动态的寻找系统中的PV资源并进行绑定。目前PVC与PV匹配可以通过StorageClassName、matchLabels或者matchExpressions三种方式。描述的,则是 Pod 所希望使用的持久化存储的属性。比如,Volume 存储的大小、可读写权限等等。
- StorageClass就是动态创建pv。
为什么需要pvc/pv?
- 如果不懂得 Ceph RBD 的使用方法,那么这个 Pod 里 Volumes 字段,你十有八九也完全看不懂。
- 这个 Ceph RBD 对应的存储服务器的地址、用户名、授权文件的位置,也都被轻易地暴露给了全公司的所有开发人员,这是一个典型的信息被“过度暴露”的例子。
这也是为什么,在后来的演化中,Kubernetes 项目引入了一组叫作 Persistent Volume Claim(PVC)和 Persistent Volume(PV)的 API 对象,大大降低了用户声明和使用持久化 Volume 的门槛,当然这只是一些表面的原因,还有很多场景需要分离共享来实现,比如:
- pod 重建销毁,如用 Deployment 管理的 pod,在做镜像升级的过程中,会产生新的 pod 并且删除旧的 pod ,那新旧 pod 之间如何复用数据?
- 宿主机宕机的时候,要把上面的 pod 迁移,这个时候 StatefulSet 管理的 pod,其实已经实现了带卷迁移的语义。这时通过 Pod Volumes 显然是做不到的;
- 多个 pod 之间,如果想要共享数据,应该如何去声明呢?我们知道,同一个 pod 中多个容器想共享数据,可以借助 Pod Volumes 来解决;当多个 pod 想共享数据时,Pod Volumes 就很难去表达这种语义;
- 如果要想对数据卷做一些功能扩展性,如:snapshot、resize 这些功能,又应该如何去做呢?
以上场景中,通过 Pod Volumes 很难准确地表达它的复用 / 共享语义,对它的扩展也比较困难。因此 K8s 中又引入了 Persistent Volumes 概念,它可以将存储和计算分离,通过不同的组件来管理存储资源和计算资源,然后解耦 pod 和 Volume 之间生命周期的关联。这样,当把 pod 删除之后,它使用的 PV 仍然存在,还可以被新建的 pod 复用。其实就是一句话,实现隔离,完成持久化的存储。
举个例子,有了 PVC 之后,一个开发人员想要使用一个 Volume,只需要简单的两步即可。第一步:定义一个 PVC,声明想要的 Volume 的属性:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pv-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
可以看到,在这个 PVC 对象里,不需要任何关于 Volume 细节的字段,只有描述性的属性和定义。比如,storage: 1Gi,表示我想要的 Volume 大小至少是 1 GiB;accessModes: ReadWriteOnce,表示这个 Volume 的挂载方式是可读写,并且只能被挂载在一个节点上而非被多个节点共享。
第二步:在应用的 Pod 中,声明使用这个 PVC:
apiVersion: v1
kind: Pod
metadata:
name: pv-pod
spec:
containers:
- name: pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: pv-storage
volumes:
- name: pv-storage
persistentVolumeClaim:
claimName: pv-claim
可以看到,在这个 Pod 的 Volumes 定义中,我们只需要声明它的类型是 persistentVolumeClaim,然后指定 PVC 的名字,而完全不必关心 Volume 本身的定义。这时候,只要我们创建这个 PVC 对象,Kubernetes 就会自动为它绑定一个符合条件的 Volume。可是,这些符合条件的 Volume 又是从哪里来的呢?答案是,它们来自于由运维人员维护的 PV(Persistent Volume)对象。接下来,我们一起看一个常见的 PV 对象的 YAML 文件:
kind: PersistentVolume
apiVersion: v1
metadata:
name: pv-volume
labels:
type: local
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
rbd:
monitors:
# 使用 kubectl get pods -n rook-ceph 查看 rook-ceph-mon- 开头的 POD IP 即可得下面的列表
- '10.16.154.78:6789'
- '10.16.154.82:6789'
- '10.16.154.83:6789'
pool: kube
image: foo
fsType: ext4
readOnly: true
user: admin
keyring: /etc/ceph/keyring
可以看到,这个 PV 对象的 spec.rbd 字段,正是我们前面介绍过的 Ceph RBD Volume 的详细定义。而且,它还声明了这个 PV 的容量是 10 GiB。这样,Kubernetes 就会为我们刚刚创建的 PVC 对象绑定这个 PV。所以,Kubernetes 中 PVC 和 PV 的设计,实际上类似于“接口”和“实现”的思想。开发者只要知道并会使用“接口”,即:PVC;而运维人员则负责给“接口”绑定具体的实现,即:PV。
具体使用可以看k8s存储。
namespace
namespace主要是实现资源的隔离,Namespace是对一组资源和对象的抽象集合,比如可以用来将系统内部的对象划分为不同的项目组或用户组。比如我们将namespace命名为系统名,一个系统一个namespace。
初始化的namespace
在默认情况下,新的集群上有三个命名空间:
- default:向集群中添加对象而不提供命名空间,这样它会被放入默认的命名空间中。在创建替代的命名空间之前,该命名空间会充当用户新添加资源的主要目的地,无法删除。
- kube-public:kube-public命名空间的目的是让所有具有或不具有身份验证的用户都能全局可读。这对于公开bootstrap组件所需的集群信息非常有用。它主要是由Kubernetes自己管理。
- kube-system:kube-system命名空间用于Kubernetes管理的Kubernetes组件,一般规则是,避免向该命名空间添加普通的工作负载。它一般由系统直接管理,因此具有相对宽松的策略。
创建命名空间
方式一
vi ns.yaml
apiVersion: v1
kind: Namespace
metadata:
name: custom-namespace #这是命名空间的名称
kubectl create -f ns.yaml
方式二
kubectl create namespace custom-namespace
Resource Quotas
在 Kubernetes 中,像 CPU 这样的资源被称作“可压缩资源”(compressible resources)。它的典型特点是,当可压缩资源不足时,Pod 只会“饥饿”,但不会退出。而像内存这样的资源,则被称作“不可压缩资源(incompressible resources)。当不可压缩资源不足时,Pod 就会因为 OOM(Out-Of-Memory)被内核杀掉。
Kubernetes 里 Pod 的 CPU 和内存资源,实际上还要分为 limits 和 requests 两种情况,这两者的区别其实非常简单:在调度的时候,kube-scheduler 只会按照 requests 的值进行计算。而在真正设置 Cgroups 限制的时候,kubelet 则会按照 limits 的值来进行设置。
更确切地说,当你指定了 requests.cpu=250m 之后,相当于将 Cgroups 的 cpu.shares 的值设置为 (250⁄1000)*1024。而当你没有设置 requests.cpu 的时候,cpu.shares 默认则是 1024。这样,Kubernetes 就通过 cpu.shares 完成了对 CPU 时间的按比例分配。而如果你指定了 limits.cpu=500m 之后,则相当于将 Cgroups 的 cpu.cfs_quota_us 的值设置为 (500⁄1000)*100ms,而 cpu.cfs_period_us 的值始终是 100ms。这样,Kubernetes 就为你设置了这个容器只能用到 CPU 的 50%。而对于内存来说,当你指定了 limits.memory=128Mi 之后,相当于将 Cgroups 的 memory.limit_in_bytes 设置为 128 * 1024 * 1024。而需要注意的是,在调度的时候,调度器只会使用 requests.memory=64Mi 来进行判断。
QoS 模型
在 Kubernetes 中,根据requests 和 limits 的设置划分不同的 QoS 级别。
- 当 Pod 里的每一个 Container 都同时设置了 requests 和 limits,并且 requests 和 limits 值相等的时候,这个 Pod 就属于 Guaranteed 类别,当这个 Pod 创建之后,它的 qosClass 字段就会被 Kubernetes 自动设置为 Guaranteed。当 Pod 仅设置了 limits 没有设置 requests 的时候,Kubernetes 会自动为它设置与 limits 相同的 requests 值,所以这也属于 Guaranteed 情况。
- 而当 Pod 不满足 Guaranteed 的条件,但至少有一个 Container 设置了 requests。那么这个 Pod 就会被划分到 Burstable 类别。
- 如果一个 Pod 既没有设置 requests,也没有设置 limits,那么它的 QoS 类别就是 BestEffort。
实际上,QoS 划分的主要应用是当宿主机资源紧张的时候,kubelet 对 Pod 进行 Eviction(即资源回收)时需要用到的。具体地说,当 Kubernetes 所管理的宿主机上不可压缩资源短缺时,就有可能触发 Eviction。比如,可用内存(memory.available)、可用的宿主机磁盘空间(nodefs.available),以及容器运行时镜像存储空间(imagefs.available)等等。目前,Kubernetes 为你设置的 Eviction 的默认阈值:
memory.available<100Mi
nodefs.available<10%
nodefs.inodesFree<5%
imagefs.available<15%
当然,上述各个触发条件在 kubelet 里都是可配置的。比如下面这个例子:
kubelet --eviction-hard=imagefs.available<10%,memory.available<500Mi,nodefs.available<5%,nodefs.inodesFree<5% --eviction-soft=imagefs.available<30%,nodefs.available<10% --eviction-soft-grace-period=imagefs.available=2m,nodefs.available=2m --eviction-max-pod-grace-period=600
在这个配置中,你可以看到 Eviction 在 Kubernetes 里其实分为 Soft 和 Hard 两种模式。其中,Soft Eviction 允许你为 Eviction 过程设置一段“优雅时间”,比如上面例子里的 imagefs.available=2m,就意味着当 imagefs 不足的阈值达到 2 分钟之后,kubelet 才会开始 Eviction 的过程。而 Hard Eviction 模式下,Eviction 过程就会在阈值达到之后立刻开始。Kubernetes 计算 Eviction 阈值的数据来源,主要依赖于从 Cgroups 读取到的值,以及使用 cAdvisor 监控到的数据。
当宿主机的 Eviction 阈值达到后,就会进入 MemoryPressure 或者 DiskPressure 状态,从而避免新的 Pod 被调度到这台宿主机上。而当 Eviction 发生的时候,kubelet 具体会挑选哪些 Pod 进行删除操作,就需要参考这些 Pod 的 QoS 类别了。
- 首当其冲的,自然是 BestEffort 类别的 Pod。
- 其次,是属于 Burstable 类别、并且发生“饥饿”的资源使用量已经超出了 requests 的 Pod。
- 最后,才是 Guaranteed 类别。并且,Kubernetes 会保证只有当 Guaranteed 类别的 Pod 的资源使用量超过了其 limits 的限制,或者宿主机本身正处于 Memory Pressure 状态时,Guaranteed 的 Pod 才可能被选中进行 Eviction 操作。
cpuset 的设置
在使用容器的时候,你可以通过设置 cpuset 把容器绑定到某个 CPU 的核上,而不是像 cpushare 那样共享 CPU 的计算能力。这种情况下,由于操作系统在 CPU 之间进行上下文切换的次数大大减少,容器里应用的性能会得到大幅提升。事实上,cpuset 方式,是生产环境里部署在线应用类型的 Pod 时,非常常用的一种方式。
首先,你的 Pod 必须是 Guaranteed 的 QoS 类型;然后,你只需要将 Pod 的 CPU 资源的 requests 和 limits 设置为同一个相等的整数值即可。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
requests:
memory: "200Mi"
cpu: "2"
这时候,该 Pod 就会被绑定在 2 个独占的 CPU 核上。当然,具体是哪两个 CPU 核,是由 kubelet 为你分配的。
资源配额(Resource Quotas)
资源配额(Resource Quotas)是用来限制用户资源用量的一种机制。
它的工作原理为
资源配额应用在Namespace上,并且每个Namespace最多只能有一个ResourceQuota对象
开启计算资源配额后,创建容器时必须配置计算资源请求或限制(也可以用LimitRange设置默认值)
用户超额后禁止创建新的资源
资源配额的启用
首先,在API Server启动时配置ResourceQuota adminssion control;然后在namespace中创建ResourceQuota对象即可。
资源配额的类型
1、计算资源,包括cpu和memory
cpu, limits.cpu, requests.cpu
memory, limits.memory, requests.memory
- Kubernetes 里为 CPU 设置的单位是“CPU 的个数”。比如,cpu=1 指的就是,这个 Pod 的 CPU 限额是 1 个 CPU。当然,具体“1 个 CPU”在宿主机上如何解释,是 1 个 CPU 核心,还是 1 个 vCPU,还是 1 个 CPU 的超线程(Hyperthread),完全取决于宿主机的 CPU 实现方式。Kubernetes 只负责保证 Pod 能够使用到“1 个 CPU”的计算能力。此外,Kubernetes 允许你将 CPU 限额设置为分数,比如在我们的例子里,CPU limits 的值就是 500m。所谓 500m,指的就是 500 millicpu,也就是 0.5 个 CPU 的意思。这样,这个 Pod 就会被分配到 1 个 CPU 一半的计算能力。当然,你也可以直接把这个配置写成 cpu=0.5。但在实际使用时,我还是推荐你使用 500m 的写法,毕竟这才是 Kubernetes 内部通用的 CPU 表示方式。
- 对于内存资源来说,它的单位自然就是 bytes。Kubernetes 支持你使用 Ei、Pi、Ti、Gi、Mi、Ki(或者 E、P、T、G、M、K)的方式来作为 bytes 的值。比如,在我们的例子里,Memory requests 的值就是 64MiB (2 的 26 次方 bytes) 。这里要注意区分 MiB(mebibyte)和 MB(megabyte)的区别。备注:1Mi=1024*1024;1M=1000*1000
2、存储资源,包括存储资源的总量以及指定storage class的总量
requests.storage:存储资源总量,如500Gi
persistentvolumeclaims:pvc的个数
.storageclass.storage.k8s.io/requests.storage
.storageclass.storage.k8s.io/persistentvolumeclaims
3、对象数,即可创建的对象的个数
pods, replicationcontrollers, configmaps, secrets
resourcequotas, persistentvolumeclaims
services, services.loadbalancers, services.nodeports
计算资源示例
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
pods: "4"
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
对象个数示例
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
services.loadbalancers: "2"
LimitRange
默认情况下,Kubernetes中所有容器都没有任何CPU和内存限制。LimitRange用来给Namespace增加一个资源限制,包括最小、最大和默认资源。比如
apiVersion: v1
kind: LimitRange
metadata:
name: mylimits
spec:
limits:
- max:
cpu: "2"
memory: 1Gi
min:
cpu: 200m
memory: 6Mi
type: Pod
- default:
cpu: 300m
memory: 200Mi
defaultRequest:
cpu: 200m
memory: 100Mi
max:
cpu: "2"
memory: 1Gi
min:
cpu: 100m
memory: 3Mi
type: Container
创建limitrange
$ kubectl create -f https://k8s.io/docs/tasks/configure-pod-container/limits.yaml --namespace=limit-example
limitrange "mylimits" created
$ kubectl describe limits mylimits --namespace=limit-example
Name: mylimits
Namespace: limit-example
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Pod cpu 200m 2 - - -
Pod memory 6Mi 1Gi - - -
Container cpu 100m 2 200m 300m -
Container memory 3Mi 1Gi 100Mi 200Mi -
配额范围
每个配额在创建时可以指定一系列的范围
范围 说明
Terminating podSpec.ActiveDeadlineSeconds>=0的Pod
NotTerminating podSpec.activeDeadlineSeconds=nil的Pod
BestEffort 所有容器的requests和limits都没有设置的Pod(Best-Effort)
NotBestEffort 与BestEffort相反
Ingress
所谓 Ingress,就是 Service 的“Service”,其实也是我们常说的七层负载均衡,而对应的service就是属于四层负载均衡了。
Ingress就是为进入集群的请求提供路由规则的集合,如下图所示
internet
|
[ Ingress ]
--|-----|--
[ Services ]
Ingress可以给service提供集群外部访问的URL、负载均衡、SSL终止、HTTP路由等。Ingress 不会公开任意端口或协议。 将 HTTP 和 HTTPS 以外的服务公开到 Internet 时,通常使用 Service.Type=NodePort 或 Service.Type=LoadBalancer 类型的服务,当然也可以使用ClusterIP类型的服务。
集群管理员需要部署一个Ingress controller,仅创建 Ingress 资源本身没有任何效果,控制器可以监听Ingress和service的变化,配置这些Ingress规则,并根据规则配置负载均衡并提供访问入口,其实控制器就是我们正常使用的类似的nginx的代理,生成了对应的配置,然后就是nginx的功能,将请求发送到对应的代理端,所以我们的ingress调试的时候,可以直接将域名解析到一个Ingress controller的pod上,然后本地curl,就能看到对应请求变化了,有问题可以看对应pod上的配置和日志。关于控制器有很多,比如我们经常使用的nginx-ingress-controller,Traefik 等,我们可以在官方提供的 Ingress 控制器 中选择。
这边讲一下L4和L7
- 四层就是基于 IP + 端口的负载均衡;
- 七层就是基于 URL 等应用层信息的负载均衡;
同理,还有基于 MAC 地址的二层负载均衡和基于 IP 地址的三层负载均衡。
4 层负载均衡本质是转发,而 7 层负载本质是内容交换和代理,7层是基于4层的。
Ingress格式
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec:
rules:
- http:
paths:
- path: /testpath
backend:
serviceName: test
servicePort: 80
可见ingress也是一个api对象,每个Ingress都需要配置rules,每个 HTTP 规则都包含以下信息:
可选的
host。在此示例中,未指定host,因此该规则适用于通过指定 IP 地址的所有入站 HTTP 通信。 如果提供了host(例如 foo.bar.com),则rules适用于该host,host支持通配符(*)。路径列表 paths(例如,
/testpath), 在负载均衡器将流量定向到引用的服务之前,主机和路径都必须匹配传入请求的内容。有一个pathType字段来确定支持的类型ImplementationSpecific:对于这种路径类型,匹配方法取决于 IngressClassExact:精确匹配 URL 路径,且区分大小写。Prefix:基于以/分隔的 URL 路径前缀匹配。匹配区分大小写,并且对路径中的元素逐个完成。
backend(后端)是 服务和端口名称的组合。 与规则的host和path匹配的对 Ingress 的 HTTP(和 HTTPS )请求将发送到列出的backend。通常在 Ingress 控制器中会配置
defaultBackend(默认后端),以服务于任何不符合规约中path的请求。还有一种资源后端,将所有入站数据导向带有静态资产的对象存储后端。比如
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ingress-resource-backend spec: defaultBackend: resource: apiGroup: k8s.example.com kind: StorageBucket name: static-assets rules: - http: paths: - path: /icons pathType: ImplementationSpecific backend: resource: apiGroup: k8s.example.com kind: StorageBucket name: icon-assets注意:
Resource与Service配置是互斥的,在 二者均被设置时会无法通过合法性检查。
上面的示例表示请求/testpath时转发到服务test的80端口。
根据Ingress Spec配置的不同,Ingress可以分为以下几种类型:
单服务Ingress
单服务Ingress即该Ingress仅指定一个没有任何规则的后端服务。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec:
backend:
serviceName: testsvc
servicePort: 80
注:单个服务还可以通过设置Service.Type=NodePort或者Service.Type=LoadBalancer来对外暴露。
路由到多服务的Ingress
路由到多服务的Ingress即根据请求路径的不同转发到不同的后端服务上,比如
foo.bar.com -> 178.91.123.132 -> / foo s1:80
/ bar s2:80
可以通过下面的Ingress来定义:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
backend:
serviceName: s1
servicePort: 80
- path: /bar
backend:
serviceName: s2
servicePort: 80
使用kubectl create -f创建完ingress后:
$ kubectl get ing
NAME RULE BACKEND ADDRESS
test -
foo.bar.com
/foo s1:80
/bar s2:80
虚拟主机Ingress
虚拟主机Ingress即根据名字的不同转发到不同的后端服务上,而他们共用同一个的IP地址,如下所示
foo.bar.com --| |-> foo.bar.com s1:80
| 178.91.123.132 |
bar.foo.com --| |-> bar.foo.com s2:80
下面是一个基于Host header路由请求的Ingress:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test
spec:
rules:
- host: foo.bar.com
http:
paths:
- backend:
serviceName: s1
servicePort: 80
- host: bar.foo.com
http:
paths:
- backend:
serviceName: s2
servicePort: 80
注:没有定义规则的后端服务称为默认后端服务,可以用来方便的处理404页面。
TLS Ingress
TLS Ingress通过Secret获取TLS私钥和证书(名为tls.crt和tls.key),来执行TLS终止。如果Ingress中的TLS配置部分指定了不同的主机,则它们将根据通过SNI TLS扩展指定的主机名(假如Ingress controller支持SNI)在多个相同端口上进行复用。
定义一个包含tls.crt和tls.key的secret:
apiVersion: v1
data:
tls.crt: base64 encoded cert
tls.key: base64 encoded key
kind: Secret
metadata:
name: testsecret
namespace: default
type: Opaque
Ingress中引用secret:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: no-rules-map
spec:
tls:
- secretName: testsecret
backend:
serviceName: s1
servicePort: 80
注意,不同Ingress controller支持的TLS功能不尽相同。 请参阅有关nginx,GCE或任何其他Ingress controller的文档,以了解TLS的支持情况。
更新Ingress
可以通过kubectl edit ing name的方法来更新ingress:
$ kubectl get ing
NAME RULE BACKEND ADDRESS
test - 178.91.123.132
foo.bar.com
/foo s1:80
$ kubectl edit ing test
这会弹出一个包含已有IngressSpec yaml文件的编辑器,修改并保存就会将其更新到kubernetes API server,进而触发Ingress Controller重新配置负载均衡:
spec:
rules:
- host: foo.bar.com
http:
paths:
- backend:
serviceName: s1
servicePort: 80
path: /foo
- host: bar.baz.com
http:
paths:
- backend:
serviceName: s2
servicePort: 80
path: /foo
..
更新后:
$ kubectl get ing
NAME RULE BACKEND ADDRESS
test - 178.91.123.132
foo.bar.com
/foo s1:80
bar.baz.com
/foo s2:80
当然,也可以通过kubectl replace -f new-ingress.yaml命令来更新,其中new-ingress.yaml是修改过的Ingress yaml。
基本原理
假如我现在有这样一个站点:https://cafe.example.com。 其中,https://cafe.example.com/coffee, 对应的是“咖啡点餐系统”。而,https://cafe.example.com/tea, 对应的则是“茶水点餐系统”。这两个系统,分别由名叫 coffee 和 tea 这样两个 Deployment 来提供服务。那么现在,我如何能使用 Kubernetes 的 Ingress 来创建一个统一的负载均衡器,从而实现当用户访问不同的域名时,能够访问到不同的 Deployment 呢?上述功能,在 Kubernetes 里就需要通过 Ingress 对象来描述,如下所示:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: cafe-ingress
spec:
tls:
- hosts:
- cafe.example.com
secretName: cafe-secret
rules:
- host: cafe.example.com
http:
paths:
- path: /tea
backend:
serviceName: tea-svc
servicePort: 80
- path: /coffee
backend:
serviceName: coffee-svc
servicePort: 80
在上面这个名叫 cafe-ingress.yaml 文件中,最值得我们关注的,是 rules 字段。在 Kubernetes 里,这个字段叫作:IngressRule。IngressRule 的 Key,就叫做:host。它必须是一个标准的域名格式(Fully Qualified Domain Name)的字符串,而不能是 IP 地址。
IngressRule 规则的定义,则依赖于 path 字段。你可以简单地理解为,这里的每一个 path 都对应一个后端 Service。所以在我们的例子里,我定义了两个 path,它们分别对应 coffee 和 tea 这两个 Deployment 的 Service(即:coffee-svc 和 tea-svc)。通过上面的讲解,不难看到,所谓 Ingress 对象,其实就是 Kubernetes 项目对“反向代理”的一种抽象。
有了 Ingress 这样一个统一的抽象,Kubernetes 的用户就无需关心 Ingress 的具体细节了。在实际的使用中,你只需要从社区里选择一个具体的 Ingress Controller,把它部署在 Kubernetes 集群里即可。然后,这个 Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。目前,业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为 Kubernetes 专门维护了对应的 Ingress Controller。
接下来,我就以最常用的 Nginx Ingress Controller 为例,部署 Nginx Ingress Controller 的方法非常简单,如下所示:
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/mandatory.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: nginx-configuration
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-ingress-controller
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
template:
metadata:
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
annotations:
...
spec:
serviceAccountName: nginx-ingress-serviceaccount
containers:
- name: nginx-ingress-controller
image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.20.0
args:
- /nginx-ingress-controller
- --configmap=$(POD_NAMESPACE)/nginx-configuration
- --publish-service=$(POD_NAMESPACE)/ingress-nginx
- --annotations-prefix=nginx.ingress.kubernetes.io
securityContext:
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
# www-data -> 33
runAsUser: 33
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
- name: http
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- name: http
containerPort: 80
- name: https
containerPort: 443
部署这一个controller,在上述 YAML 文件中,我们定义了一个使用 nginx-ingress-controller 镜像的 Pod。需要注意的是,这个 Pod 的启动命令需要使用该 Pod 所在的 Namespace 作为参数。而这个信息,当然是通过 Downward API 拿到的,即:Pod 的 env 字段里的定义(env.valueFrom.fieldRef.fieldPath)。而这个 Pod 本身,就是一个监听 Ingress 对象以及它所代理的后端 Service 变化的控制器。当一个新的 Ingress 对象由用户创建后,nginx-ingress-controller 就会根据 Ingress 对象里定义的内容,生成一份对应的 Nginx 配置文件(/etc/nginx/nginx.conf),并使用这个配置文件启动一个 Nginx 服务。而一旦 Ingress 对象被更新,nginx-ingress-controller 就会更新这个配置文件。需要注意的是,如果这里只是被代理的 Service 对象被更新,nginx-ingress-controller 所管理的 Nginx 服务是不需要重新加载(reload)的。这当然是因为 nginx-ingress-controller 通过Nginx Lua方案实现了 Nginx Upstream 的动态配置。此外,nginx-ingress-controller 还允许你通过 Kubernetes 的 ConfigMap 对象来对上述 Nginx 配置文件进行定制。这个 ConfigMap 的名字,需要以参数的方式传递给 nginx-ingress-controller。而你在这个 ConfigMap 里添加的字段,将会被合并到最后生成的 Nginx 配置文件当中。
一个 Nginx Ingress Controller 为你提供的服务,其实是一个可以根据 Ingress 对象和被代理后端 Service 的变化,来自动进行更新的 Nginx 负载均衡器。
当然,为了让用户能够用到这个 Nginx,我们就需要创建一个 Service 来把 Nginx Ingress Controller 管理的 Nginx 服务暴露出去,也即是暴露负载均衡的地址,我们可以直接使用nodeport暴露,也可以再接外部的负载均衡。
如果我的请求没有匹配到任何一条 IngressRule,那么会发生什么呢?首先,既然 Nginx Ingress Controller 是用 Nginx 实现的,那么它当然会为你返回一个 Nginx 的 404 页面。不过,Ingress Controller 也允许你通过 Pod 启动命令里的–default-backend-service 参数,设置一条默认规则,比如:–default-backend-service=nginx-default-backend。这样,任何匹配失败的请求,就都会被转发到这个名叫 nginx-default-backend 的 Service。所以,你就可以通过部署一个专门的 Pod,来为用户返回自定义的 404 页面了。
Kubernetes 提出 Ingress 概念的原因其实也非常容易理解,有了 Ingress 这个抽象,用户就可以根据自己的需求来自由选择 Ingress Controller。比如,如果你的应用对代理服务的中断非常敏感,那么你就应该考虑选择类似于 Traefik 这样支持“热加载”的 Ingress Controller 实现。更重要的是,一旦你对社区里现有的 Ingress 方案感到不满意,或者你已经有了自己的负载均衡方案时,你只需要做很少的编程工作,就可以实现一个自己的 Ingress Controller。在实际的生产环境中,Ingress 带来的灵活度和自由度,对于使用容器的用户来说,其实是非常有意义的。
问题处理
一般我们遇到问题都是使用logs或者describe去查看对应pod的日志,ingress也不例外,我们一般回去查看对应的controller的pod对应的日志来解决问题。
DNS
kubernetes 提供了 service 的概念可以通过 VIP 访问 pod 提供的服务,但是在使用的时候还有一个问题:怎么知道某个应用的 VIP?
比如我们有两个应用,一个 app,一个 是 db,每个应用使用 rc 进行管理,并通过 service 暴露出端口提供服务。app 需要连接到 db 应用,我们只知道 db 应用的名称,但是并不知道它的 VIP 地址。
- 最简单的办法是从 kubernetes 提供的 API 查询。但这是一个糟糕的做法,首先每个应用都要在启动的时候编写查询依赖服务的逻辑,这本身就是重复和增加应用的复杂度;其次这也导致应用需要依赖 kubernetes,不能够单独部署和运行。
- 当然如果通过增加配置选项也是可以做到的,但这又是增加复杂度同时,在配置规模变大后难以维护。
- 开始的时候,kubernetes 采用了 docker 使用过的方法——环境变量。每个 pod 启动时候,会把通过环境变量设置所有服务的 IP 和 port 信息,这样 pod 中的应用可以通过读取环境变量来获取依赖服务的地址信息。这种方式服务和环境变量的匹配关系有一定的规范,使用起来也相对简单,但是有个很大的问题:依赖的服务必须在 pod 启动之前就存在,不然是不会出现在环境变量中的。
- 更理想的方案是:应用能够直接使用服务的名字,不需要关心它实际的 ip 地址,中间的转换能够自动完成。名字和 ip 之间的转换就是 DNS 系统的功能,因此 kubernetes 也提供了 DNS 方法来解决这个问题。
DNS具体的实现和原理可以看这里。
原理
服务发现
服务发现是分布式架构里服务治理的重要组成部分,服务发现的的基本原理,可以参考这里。我们这里主要看服务发现的实现之一:k8s的服务发现
在 K8s 里面,服务发现与负载均衡就是通过Service实现。通过下图我们可以看出,K8s Service 向上提供了外部网络以及 pod 网络的访问,即外部网络可以通过 service 去访问,pod 网络也可以通过 K8s Service 去访问。
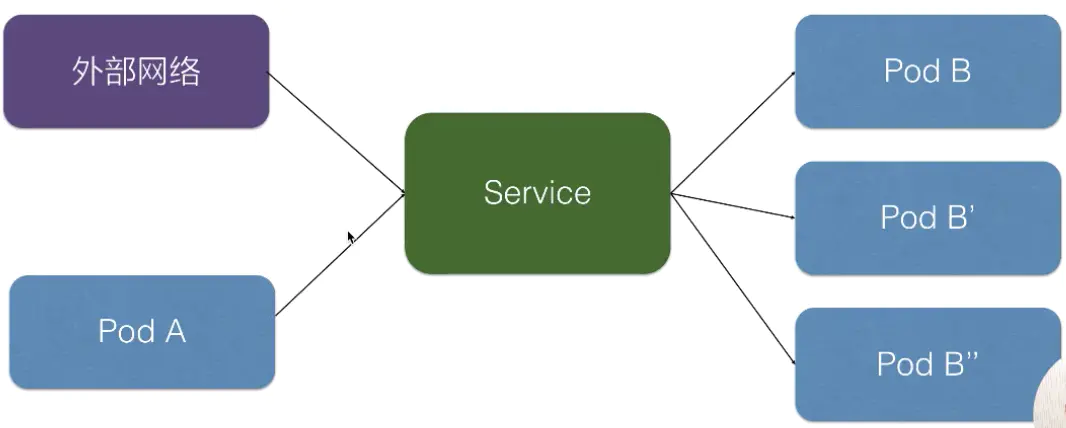
关于service实现的负载均衡和服务发现,主要是以下几个部分
k8s服务注册
1、环境变量: 当你创建一个Pod的时候,kubelet会在该Pod中注入集群内所有Service的相关环境变量。需要注意的是,要想一个Pod中注入某个Service的环境变量,则必须Service要先比该Pod创建。这一点,几乎使得这种方式进行服务发现不可用。
比如,一个ServiceName为redis-master的Service,对应的ClusterIP:Port为10.0.0.11:6379,则其对应的环境变量为:
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
然后pod可以根据对应服务的环境变量来进行调用,可见这种方式需要前置条件,目前已经基本上不使用。
2、直接使用配置来调用,已经不算服务注册与发现了,就是我们正常的配置调用,这个也是有很大的问题的,主要是在k8s集群的规模中配置太过复杂,根本难以配置和维护。
3、k8s提供api查询对应的服务,这也可以解决,但这是一个糟糕的做法,首先每个应用都要在启动的时候编写查询依赖服务的逻辑,这本身就是重复和增加应用的复杂度;其次这也导致应用需要依赖 kubernetes,不能够单独部署和运行。
4、DNS:这也是k8s官方强烈推荐的方式。可以通过cluster add-on的方式轻松的创建KubeDNS来对集群内的Service进行服务发现。核心就是DNS监控服务进行注册,服务调用通过DNS服务器进行解析ip调用,更多关于DNS的内容在上面有说明。
k8s域名解析
Kubernetes 中,域名的全称,必须是 service-name.namespace.svc.cluster.local 这种模式,服务名,就是Kubernetes中 Service 的名称,namespace就是namespace的名称。
然后通过查询DNS服务器来获取对应的ip进行调用。
负载均衡
可以把 Kubernetes Service 理解为前端和后端两部分:
- 前端:名称、IP 和端口等不变的部分。也就是我们前面主要的服务发现的注册和发现
- 后端:符合特定标签选择条件的 Pod 集合。主要是用于后端的负载均衡。
前端是稳定可靠的,它的名称、IP 和端口在 Service 的整个生命周期中都不会改变。前端的稳定性意味着无需担心客户端 DNS 缓存超时等问题。
后端是高度动态的,其中包括一组符合标签选择条件的 Pod,会通过负载均衡的方式进行访问。这里的负载均衡是一个简单的 4 层轮询。
服务发现流程
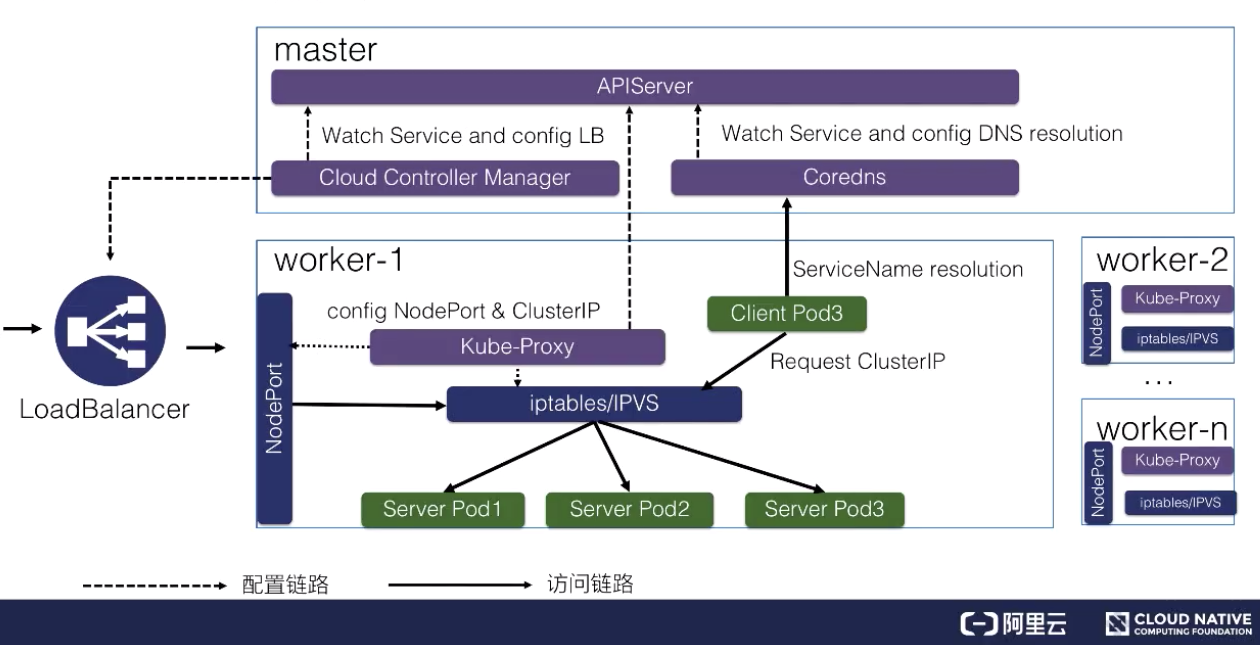
如上图所示,K8s 服务发现以及 K8s Service 是这样整体的一个架构。
在 K8s master 节点里面有 APIServer,就是统一管理 K8s 所有对象的地方,所有的组件都会注册到 APIServer 上面去监听这个对象的变化,比如说我们刚才的组件 pod 生命周期发生变化等这些事件。这里面最关键的有三个组件:
- 一个是 Cloud Controller Manager,负责去配置 LoadBalancer 的一个负载均衡器给外部去访问;
- 另外一个就是 Coredns,就是通过 Coredns 去观测 APIServer 里面的 service 后端 pod 的一个变化,去配置 service 的 DNS 解析,实现可以通过 service 的名字直接访问到 service 的虚拟 IP,或者是 Headless 类型的 Service 中的 IP 列表的解析;
- 然后在每个 node 里面会有 kube-proxy 这个组件,它通过监听 service 以及 pod 变化,然后实际去配置集群里面的 node pod 或者是虚拟 IP 地址的一个访问。
实际访问链路是什么样的呢?比如说从集群内部的一个 Client Pod3 去访问 Service,就类似于刚才所演示的一个效果。Client Pod3 首先通过 Coredns 这里去解析出 ServiceIP,Coredns 会返回给它 ServiceName 所对应的 service IP 是什么,这个 Client Pod3 就会拿这个 Service IP 去做请求,它的请求到宿主机的网络之后,就会被 kube-proxy 所配置的 iptables 或者 IPVS 去做一层拦截处理,之后去负载均衡到每一个实际的后端 pod 上面去,这样就实现了一个负载均衡以及服务发现。
对于外部的流量,比如说刚才通过公网访问的一个请求。它是通过外部的一个负载均衡器 Cloud Controller Manager 去监听 service 的变化之后,去配置的一个负载均衡器,然后转发到节点上的一个 NodePort 上面去,NodePort 也会经过 kube-proxy 的一个配置的一个 iptables,把 NodePort 的流量转换成 ClusterIP,紧接着转换成后端的一个 pod 的 IP 地址,去做负载均衡以及服务发现。这就是整个 K8s 服务发现以及 K8s Service 整体的结构。
安全机制
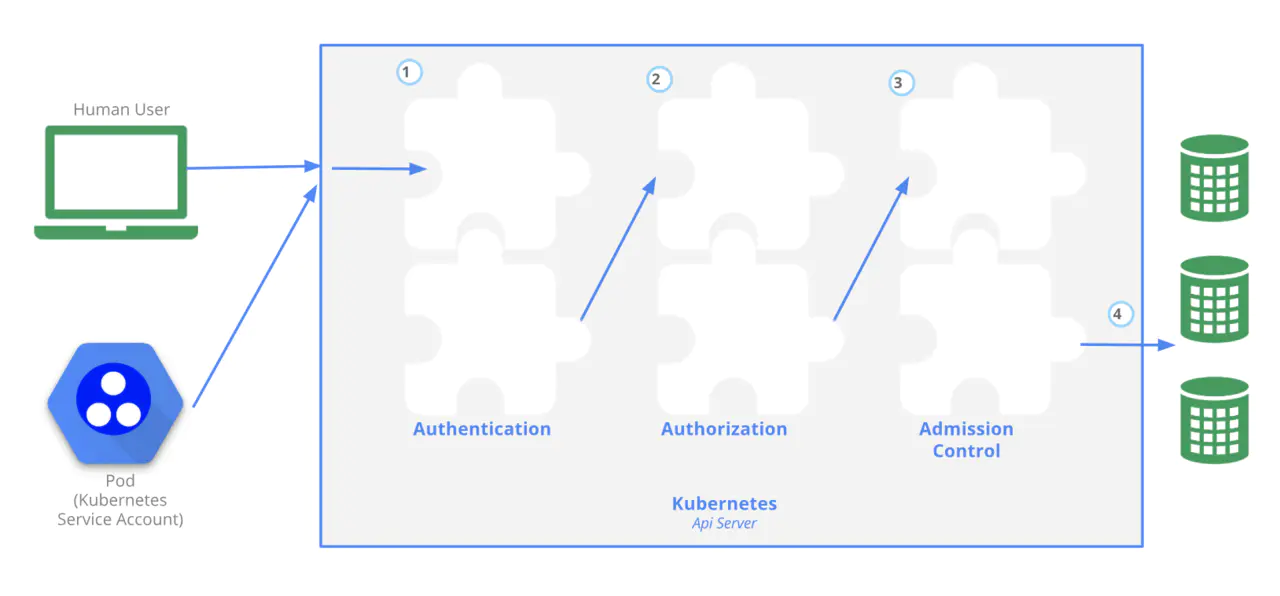
Kubernetes 官方文档给出了上面这张图。描述了用户在访问或变更资源的之前,需要经过 APIServer 的认证机制、授权机制以及准入控制机制。这三个机制(简称3A)可以这样理解,先检查是否合法用户,再检查该请求的行为是否有权限,最后做进一步的验证或添加默认参数。
这一块属于paas的中的安全云的基础,具体我们在安全云中做说明。
k8s的pod创建流程
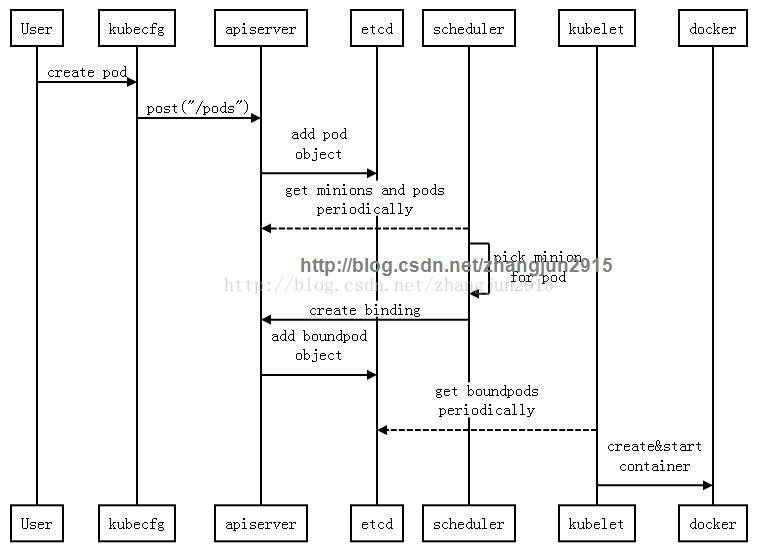
具体的创建步骤包括:
- 客户端提交创建请求,可以通过API Server的Restful API,也可以使用kubectl命令行工具。支持的数据类型包括JSON和YAML。
- API Server处理用户请求,apiserver是提供认证机制的,认证(认证,授权,准入(正常都是使用admin的权限,可以分配不同的sa))通过后,存储Pod数据到etcd。
- 控制器通过apiserver的watch接口,可以发现pod信息的更新,根据资源情况确定创建的pod,并将信息写入到etcd中。
- Scheduler同样通过apiserver的watch接口更新到pod可以被调度,尝试为Pod分配主机。
- 过滤主机 (调度预选):调度器用一组规则过滤掉不符合要求的主机。比如Pod指定了所需要的资源量,那么可用资源比Pod需要的资源量少的主机会被过滤掉。
- 主机打分(调度优选):对第一步筛选出的符合要求的主机进行打分,在主机打分阶段,调度器会考虑一些整体优化策略,比如把容一个Replication Controller的副本分布到不同的主机上,使用最低负载的主机等。
- 选择主机:选择打分最高的主机,进行binding操作,结果存储到etcd中。
- kubelet根据调度结果执行Pod创建操作: 绑定成功后,scheduler会调用APIServer的API在etcd中创建一个boundpod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步boundpod信息,一旦发现应该在该工作节点上运行的boundpod对象没有更新,则调用Docker API创建并启动pod内的容器。
- 调用CNI接口给pod创建pod网络,调用CRI接口去启动容器,调用CSI进行存储卷的挂载。
kubelet创建pod
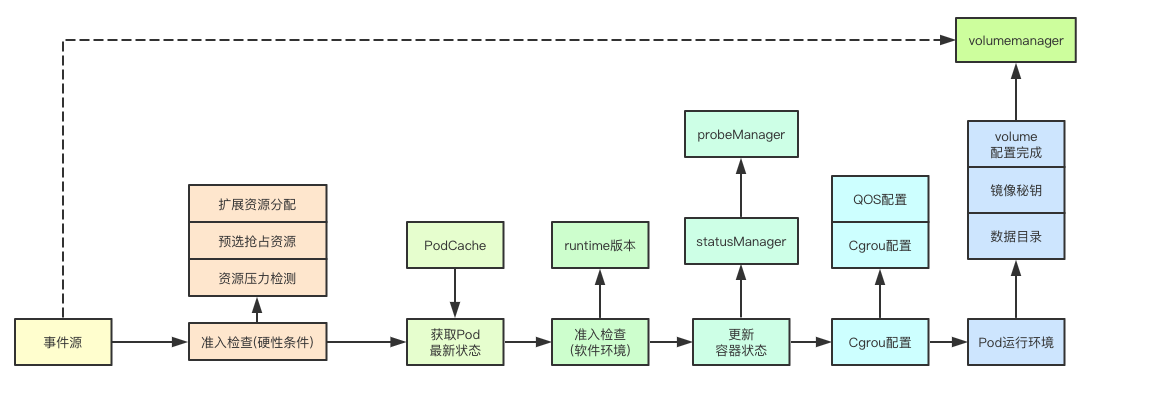
1、获取Pod进行准入检查
kubelet的事件源主要包含两个部分:静态Pod和Apiserver,我们这里只考虑普通的Pod,则会直接将Pod加入到PodManager来进行管理,并且进行准入检查
准入检查主要包含两个关键的控制器:驱逐管理与预选检查驱逐管理主要是根据当前的资源压力,检测对应的Pod是否容忍当前的资源压力;预选检查则是根据当前活跃的容器和当前节点的信息来检查是否满足当前Pod的基础运行环境,例如亲和性检查,同时如果当前的Pod的优先级特别高或者是静态Pod,则会尝试为其进行资源抢占,会按照QOS等级逐级来进行抢占从而满足其运行环境
2、创建事件管道与容器管理主线程
kubelet接收到一个新创建的Pod首先会为其创建一个事件管道,并且启动一个容器管理的主线程消费管道里面的事件,并且会基于最后同步时间来等待当前kubelet中最新发生的事件(从本地的podCache中获取),如果是一个新建的Pod,则主要是通过PLEG中更新时间操作,广播的默认空状态来作为最新的状态
3、同步最新状态
当从本地的podCache中获取到最新的状态信息和从事件源获取的Pod信息后,会结合当前当前statusManager和probeManager里面的Pod里面的容器状态来更新,从而获取当前感知到的最新的Pod状态
4、准入控制检查
之前的准入检查是Pod运行的资源硬性限制的检查,而这里的准入检查则是软状态即容器运行时和版本的一些软件运行环境检查,如果这里检查失败,则会讲对应的容器状态设置为Blocked
5、更新容器状态
在通过准入检查之后,会调用statusManager来进行POd最新状态的同步,此处可能会同步给apiserver
6、Cgroup配置
在更新完成状态之后会启动一个PodCOntainerManager主要作用则是为对应的Pod根据其QOS等级来进行Cgroup配置的更新
7、Pod基础运行环境准备
接下来kubelet会为Pod的创建准备基础的环境,包括Pod数据目录的创建、镜像秘钥的获取、等待volume挂载完成等操作创建Pod的数据目录主要是创建 Pod运行所需要的Pod、插件、Volume目录,并且会通过Pod配置的镜像拉取秘钥生成秘钥信息,到此kubelet创建容器的工作就已经基本完成
8、container创建
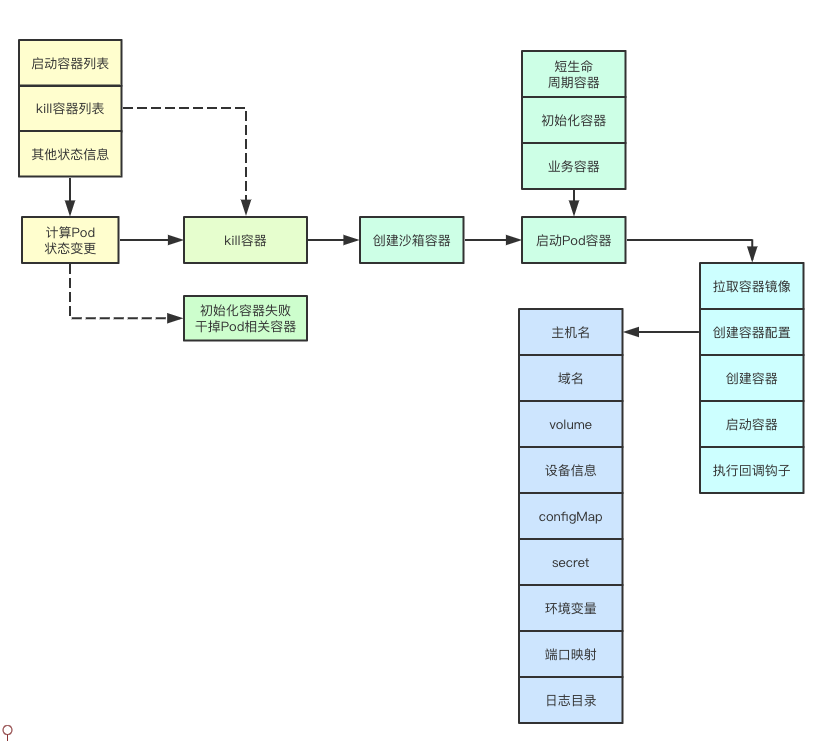
- 计算Pod容器变更 计算容器变更主要包括:Pod的sandbox是否变更、短声明周期容器、初始化容器是否完成、业务容器是否已经完成,相应的我们会得到一个几个对应的容器列表:需要被kill掉的容器列表、需要启动的容器列表,注意如果我们的初始化容器未完成,则不会进行将要运行的业务容器加入到需要启动的容器列表,可以看到这个地方是两个阶段
- 初始化失败尝试终止 如果之前检测到之前的初始化容器失败,则会检查当前Pod的所有容器和sandbox关联的容器如果有在运行的容器,会全部进行Kill操作,并且等待操作完成
- 未知状态容器补偿 当一些Pod的容器已经运行,但是其状态仍然是Unknow的时候,在这个地方会进行统一的处理,全部kill掉,从而为接下来的重新启动做清理操作,此处和3.2只会进行一个分支,但核心的目标都是清理那些运行失败或者无法获取状态的容器
- 创建容器沙箱 在启动Pod的容器之前,首先会为其创建一个sandbox容器,当前Pod的所有容器都和Pod对应的sandbox共享同一个namespace从而共享一个namespace里面的资源,创建Sandbox比较复杂,后续会继续介绍
启动Pod相关容器 Pod的容器目前分为三大类:短生命周期容器、初始化容器、业务容器,启动顺序也是从左到右依次进行,如果对于的容器创建失败,则会通过backoff机制来延缓容器的创建,这里我们顺便介绍下containerRuntime启动容器的流程
检查容器镜像是否拉取 镜像的拉取首先会进行对应容器镜像的拼接,然后将之前获取的拉取的秘钥信息和镜像信息,一起交给CRI运行时来进行底层容器镜像的拉取,当然这里也会各种backoff机制,从而避免频繁拉取失败影响kubelet的性能
创建容器配置 创建容器配置主要是为了容器的运行创建对应的配置数据,主要包括:Pod的主机名、域名、挂载的volume、configMap、secret、环境变量、挂载的设备信息、要挂载的目录信息、端口映射信息、根据环境生成执行的命令、日志目录等信息
调用runtimeService完成容器的创建 调用runtimeService传递容器的配置信息,调用CRI,并且最终调用容器的创建接口完成容器的状态
调用runtimeService启动容器 通过之前创建容器返回的容器ID,来进行对应的容器的启动,并且会为容器创建对应的日志目录
执行容器的回调钩子 如果容器配置了PostStart钩子,则会在此处进行对应钩子的执行,如果钩子的类型是Exec类则会调用CNI的EXec接口完成在容器内的执行
配置和可扩展
Kubernetes 是高度可配置和可扩展的。因此,极少需要分发或提交补丁代码给 Kubernetes 项目,我们的大部分开发也是基于可扩展来进行的。
配置 一般就是更改标志参数、本地配置文件或 API 资源。这个可以参考官方文档各种组件的启动参数的配置,不用详细说明,主要还是高度可扩展的这种设计模式,使得k8s十分灵活。
整个k8s集群的基本各个点都是支持可扩展的,如何扩展,我们可以看官方这幅图:
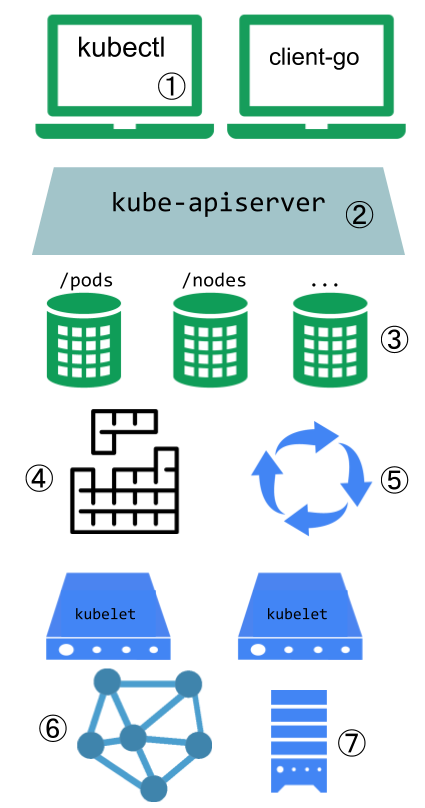
- 用户通常使用 kubectl 与 Kubernetes API 进行交互。kubectl 插件扩展了 kubectl 二进制程序。它们只影响个人用户的本地环境,因此不能执行站点范围的策略。
- apiserver 处理所有请求。apiserver 中的几种类型的扩展点允许对请求进行身份认证或根据其内容对其进行阻止、编辑内容以及处理删除操作。 API 访问扩展。
- apiserver 提供各种内置的资源种类 ,如 pods,由 Kubernetes 项目定义,不能更改。但是可以添加您自己定义的资源或其他项目已定义的资源来进行扩展。自定义资源通常与 API 访问扩展一起使用。
- Kubernetes 调度器决定将 Pod 放置到哪个节点。有几种方法可以扩展调度器。调度器可扩展。
- Kubernetes 的大部分行为都是由称为控制器的程序实现的。自定义控制器通常与自定义资源一起使用来完成扩展。
- kubelet 在主机上运行,并帮助 pod 看起来就像在集群网络上拥有自己的 IP 的虚拟服务器。网络插件让您可以实现不同的 pod 网络的扩展。
- kubelet 也挂载和卸载容器的卷。新的存储类型可以通过存储插件支持扩展。
kubectl 插件扩展
kubectl 插件在 v1.8.0 版本中正式作为 alpha 特性引入。它们已经在 v1.12.0 版本中工作,以支持更广泛的用例,建议使用 1.12.0 或更高版本的 kubectl。
1、安装 kubectl 插件
插件只不过是一个独立的可执行文件,名称以 kubectl- 开头,Kubernetes 不提供包管理器或任何类似于安装或更新插件的东西,所以我们只要将此可执行文件放置到系统路径下就可以
目前无法创建覆盖现有 kubectl 命令的插件,例如,创建一个插件 kubectl-version 将导致该插件永远不会被执行,因为现有的 kubectl-version 命令总是优先于它执行。
2、发现插件
kubectl 提供一个命令 kubectl plugin list,用于搜索系统路径查找有效的插件可执行文件。 执行此命令将遍历路径中的所有文件。任何以 kubectl- 开头的可执行文件都将在这个命令的输出中以它们在路径中出现的顺序显示。 任何以 kubectl- 开头的文件如果不可执行,都将包含一个警告。 对于任何相同的有效插件文件,都将包含一个警告。
3、编写 kubectl 插件
你可以用任何编程语言或脚本编写插件,允许您编写命令行命令,最总就是一个二进制文件,不需要安装插件或预加载,直接执行即可,比如一个插件想要提供一个新的命令 kubectl foo,它将被简单地命名为 kubectl-foo
#!/bin/bash
# optional argument handling
if [[ "$1" == "version" ]]
then
echo "1.0.0"
exit 0
fi
# optional argument handling
if [[ "$1" == "config" ]]
then
echo $KUBECONFIG
exit 0
fi
echo "I am a plugin named kubectl-foo"
4、使用插件
要使用上面的插件,只需使其可执行:
sudo chmod +x ./kubectl-foo
并将它放在你的路径中的任何地方:
sudo mv ./kubectl-foo /usr/local/bin
你现在可以调用你的插件作为 kubectl 命令:
kubectl foo
I am a plugin named kubectl-foo
所有参数和标记按原样传递给可执行文件:
kubectl foo version
1.0.0
5、命名规则
虽然 kubectl 插件机制在插件文件名中使用破折号(-)分隔插件处理的子命令序列,但是仍然可以通过在文件名中使用下划线(-)来创建命令行中包含破折号的插件命令。
# create a plugin containing an underscore in its filename
echo -e '#!/bin/bash\n\necho "I am a plugin with a dash in my name"' > ./kubectl-foo_bar
sudo chmod +x ./kubectl-foo_bar
# move the plugin into your PATH
sudo mv ./kubectl-foo_bar /usr/local/bin
# our plugin can now be invoked from `kubectl` like so:
kubectl foo-bar
对于插件文件名而言还有另一种弊端,给定用户路径中的两个插件 kubectl-foo-bar 和 kubectl-foo-bar-baz ,kubectl 插件机制总是为给定的用户命令选择尽可能长的插件名称。
# for a given kubectl command, the plugin with the longest possible filename will always be preferred
kubectl foo bar baz
Plugin kubectl-foo-bar-baz is executed
kubectl foo bar
Plugin kubectl-foo-bar is executed
kubectl foo bar baz buz
Plugin kubectl-foo-bar-baz is executed, with "buz" as its first argument
kubectl foo bar buz
Plugin kubectl-foo-bar is executed, with "buz" as its first argument
custom resource(自定义资源)
自定义资源是k8s api的扩展。
资源就是api对象的一种,比如pod就是一种资源,自定义就是自己定义一种这样的在原生集群中没有的类型。
自定义资源只是一种数据结构对象,只有结合控制器才能提供真正的声明式api。一个声明式API 允许你声明或指定的资源的理想状态,控制器将结构化数据同步到为用户所需状态的记录,并持续保持该状态。
声明式api和命令式api
- Declarative(声明式设计)指的是这么一种软件设计理念和做法:我们向一个工具描述我们想要让一个事物达到的目标状态,由这个工具自己内部去figure out如何令这个事物达到目标状态。
- Imperative(命令式设计)模式中,我们描述的是一系列的动作。这一系列的动作如果被正确的顺利执行,最终结果是这个事物达到了我们期望的目标状态的。
Kubernetes提供了两种向集群添加自定义资源的方法
- CRD很简单,无需任何编程即可通过CustomResourceDefinition API资源类型进行创建。
- API聚合需要编程,但可以更好地控制API行为,例如如何存储数据以及在API版本之间进行转换。
CRD更易于使用,聚合的API更灵活。
我们在来聊聊api group 和 api version
$ kubectl api-versions
admissionregistration.k8s.io/v1
admissionregistration.k8s.io/v1beta1
apiextensions.k8s.io/v1
apiextensions.k8s.io/v1beta1
apiregistration.k8s.io/v1
apiregistration.k8s.io/v1beta1
apps.kruise.io/v1alpha1
apps/v1
authentication.k8s.io/v1
authentication.k8s.io/v1beta1
authorization.k8s.io/v1
authorization.k8s.io/v1beta1
autoscaling/v1
autoscaling/v2beta1
autoscaling/v2beta2
batch/v1
batch/v1beta1
certificates.k8s.io/v1beta1
coordination.k8s.io/v1
coordination.k8s.io/v1beta1
custom.metrics.k8s.io/v1beta1
discovery.k8s.io/v1beta1
events.k8s.io/v1beta1
extensions/v1beta1
metrics.k8s.io/v1beta1
monitoring.coreos.com/v1
networking.k8s.io/v1
networking.k8s.io/v1beta1
node.k8s.io/v1beta1
policy/v1beta1
rbac.authorization.k8s.io/v1
rbac.authorization.k8s.io/v1beta1
scheduling.k8s.io/v1
scheduling.k8s.io/v1beta1
storage.k8s.io/v1
storage.k8s.io/v1beta1
v1
第一个 admissionregistration.k8s.io/v1beta1 中,admissionregistration.k8s.io 是 api group,v1beta1 表示它的版本。所以api都是有APIgroup/apiversion组成的,如果 api group 为空表示核心 api。
每个api其实都是通过apiservice这种类型进行注册的
$ kubectl get apiservice
NAME SERVICE AVAILABLE AGE
v1. Local True 20d
v1.admissionregistration.k8s.io Local True 20d
v1.apiextensions.k8s.io Local True 20d
v1.apps Local True 20d
v1.authentication.k8s.io Local True 20d
v1.authorization.k8s.io Local True 20d
v1.autoscaling Local True 20d
v1.batch Local True 20d
v1.coordination.k8s.io Local True 20d
v1.monitoring.coreos.com Local True 2d20h
v1.networking.k8s.io Local True 20d
v1.rbac.authorization.k8s.io Local True 20d
v1.scheduling.k8s.io Local True 20d
v1.storage.k8s.io Local True 20d
v1alpha1.apps.kruise.io Local True 2d20h
v1beta1.admissionregistration.k8s.io Local True 20d
v1beta1.apiextensions.k8s.io Local True 20d
v1beta1.authentication.k8s.io Local True 20d
v1beta1.authorization.k8s.io Local True 20d
v1beta1.batch Local True 20d
v1beta1.certificates.k8s.io Local True 20d
v1beta1.coordination.k8s.io Local True 20d
v1beta1.custom.metrics.k8s.io custom-metrics/custom-metrics-apiserver False (MissingEndpoints) 3h18m
v1beta1.discovery.k8s.io Local True 20d
v1beta1.events.k8s.io Local True 20d
v1beta1.extensions Local True 20d
v1beta1.metrics.k8s.io monitoring/prometheus-adapter True 18h
v1beta1.networking.k8s.io Local True 20d
v1beta1.node.k8s.io Local True 20d
v1beta1.policy Local True 20d
v1beta1.rbac.authorization.k8s.io Local True 20d
v1beta1.scheduling.k8s.io Local True 20d
v1beta1.storage.k8s.io Local True 20d
v2beta1.autoscaling Local True 20d
v2beta2.autoscaling Local True 20d
kubernetes 的资源都是由 api group 提供的。那么如何知道哪些资源是由哪些 api group 提供的呢?
$ kubectl api-resources
NAME SHORTNAMES APIGROUP NAMESPACED KIND
bindings true Binding
componentstatuses cs false ComponentStatus
configmaps cm true ConfigMap
endpoints ep true Endpoints
events ev true Event
limitranges limits true LimitRange
namespaces ns false Namespace
nodes no false Node
persistentvolumeclaims pvc true PersistentVolumeClaim
persistentvolumes pv false PersistentVolume
pods po true Pod
podtemplates true PodTemplate
replicationcontrollers rc true ReplicationController
resourcequotas quota true ResourceQuota
secrets true Secret
serviceaccounts sa true ServiceAccount
services svc true Service
mutatingwebhookconfigurations admissionregistration.k8s.io false MutatingWebhookConfiguration
validatingwebhookconfigurations admissionregistration.k8s.io false ValidatingWebhookConfiguration
customresourcedefinitions crd,crds apiextensions.k8s.io false CustomResourceDefinition
apiservices apiregistration.k8s.io false APIService
controllerrevisions apps true ControllerRevision
daemonsets ds apps true DaemonSet
deployments deploy apps true Deployment
replicasets rs apps true ReplicaSet
statefulsets sts apps true StatefulSet
broadcastjobs bj apps.kruise.io true BroadcastJob
clonesets clone apps.kruise.io true CloneSet
sidecarsets apps.kruise.io false SidecarSet
statefulsets sts apps.kruise.io true StatefulSet
uniteddeployments ud apps.kruise.io true UnitedDeployment
tokenreviews authentication.k8s.io false TokenReview
localsubjectaccessreviews authorization.k8s.io true LocalSubjectAccessReview
selfsubjectaccessreviews authorization.k8s.io false SelfSubjectAccessReview
selfsubjectrulesreviews authorization.k8s.io false SelfSubjectRulesReview
subjectaccessreviews authorization.k8s.io false SubjectAccessReview
horizontalpodautoscalers hpa autoscaling true HorizontalPodAutoscaler
cronjobs cj batch true CronJob
jobs batch true Job
certificatesigningrequests csr certificates.k8s.io false CertificateSigningRequest
leases coordination.k8s.io true Lease
endpointslices discovery.k8s.io true EndpointSlice
events ev events.k8s.io true Event
ingresses ing extensions true Ingress
nodes metrics.k8s.io false NodeMetrics
pods metrics.k8s.io true PodMetrics
alertmanagers monitoring.coreos.com true Alertmanager
podmonitors monitoring.coreos.com true PodMonitor
prometheuses monitoring.coreos.com true Prometheus
prometheusrules monitoring.coreos.com true PrometheusRule
servicemonitors monitoring.coreos.com true ServiceMonitor
thanosrulers monitoring.coreos.com true ThanosRuler
ingressclasses networking.k8s.io false IngressClass
ingresses ing networking.k8s.io true Ingress
networkpolicies netpol networking.k8s.io true NetworkPolicy
runtimeclasses node.k8s.io false RuntimeClass
poddisruptionbudgets pdb policy true PodDisruptionBudget
podsecuritypolicies psp policy false PodSecurityPolicy
clusterrolebindings rbac.authorization.k8s.io false ClusterRoleBinding
clusterroles rbac.authorization.k8s.io false ClusterRole
rolebindings rbac.authorization.k8s.io true RoleBinding
roles rbac.authorization.k8s.io true Role
priorityclasses pc scheduling.k8s.io false PriorityClass
csidrivers storage.k8s.io false CSIDriver
csinodes storage.k8s.io false CSINode
storageclasses sc storage.k8s.io false StorageClass
volumeattachments storage.k8s.io false VolumeAttachment
NAME 列就是资源名,它的功能由 APIGROUP 列的 api group 提供。SHORTNAMES 列就是这些资源的缩写了,缩写在使用 kubectl 时非常好用。同样APIGROUP 都为空,表示这些资源都是核心 api 提供的。
所以对于自定义api,我们就需要用到他们的 api group 和 api version 进行注册,就可以同样的作用了。
这边只是资源定义,实现还是要依赖于controller。
Schedulers
调度扩展主要是通过调度框架来实现。
网络插件
网络扩展主要通过CNI接口来实现。
存储插件
存储扩展主要通过CSI接口来实现。
硬件扩展
2016 年,随着 AlphaGo 的走红和 TensorFlow 项目的异军突起,一场名为 AI 的技术革命迅速从学术界蔓延到了工业界,所谓的 AI 元年,就此拉开帷幕。当然,机器学习或者说人工智能,并不是什么新鲜的概念。而这次热潮的背后,云计算服务的普及与成熟,以及算力的巨大提升,其实正是将人工智能从象牙塔带到工业界的一个重要推手。而与之相对应的,从 2016 年开始,Kubernetes 社区就不断收到来自不同渠道的大量诉求,希望能够在 Kubernetes 集群上运行 TensorFlow 等机器学习框架所创建的训练(Training)和服务(Serving)任务。而这些诉求中,除了前面我为你讲解过的 Job、Operator 等离线作业管理需要用到的编排概念之外,还有一个亟待实现的功能,就是对 GPU 等硬件加速设备管理的支持。
在 Kubernetes 中,对所有硬件加速设备进行管理的功能,都是由一种叫作 Device Plugin 的插件来负责的。这其中,当然也就包括了对该硬件的 Extended Resource 进行汇报的逻辑。
实例
以 NVIDIA 的 GPU 设备为例,Kubernetes 在 Pod 的 API 对象里,并没有为 GPU 专门设置一个资源类型字段,而是使用了一种叫作 Extended Resource(ER)的特殊字段来负责传递 GPU 的信息。比如下面这个例子:
apiVersion: v1
kind: Pod
metadata:
name: cuda-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
可以看到,在上述 Pod 的 limits 字段里,这个资源的名称是nvidia.com/gpu,它的值是 1。也就是说,这个 Pod 声明了自己要使用一个 NVIDIA 类型的 GPU。而在 kube-scheduler 里面,它其实并不关心这个字段的具体含义,只会在计算的时候,一律将调度器里保存的该类型资源的可用量,直接减去 Pod 声明的数值即可。所以说,Extended Resource,其实是 Kubernetes 为用户设置的一种对自定义资源的支持。当然,为了能够让调度器知道这个自定义类型的资源在每台宿主机上的可用量,宿主机节点本身,就必须能够向 API Server 汇报该类型资源的可用数量。在 Kubernetes 里,各种类型的资源可用量,其实是 Node 对象 Status 字段的内容,比如下面这个例子:
apiVersion: v1
kind: Node
metadata:
name: node-1
...
Status:
Capacity:
cpu: 2
memory: 2049008Ki
而为了能够在上述 Status 字段里添加自定义资源的数据,你就必须使用 PATCH API 来对该 Node 对象进行更新,加上你的自定义资源的数量。这个 PATCH 操作,可以简单地使用 curl 命令来发起,如下所示:
# 启动 Kubernetes 的客户端 proxy,这样你就可以直接使用 curl 来跟 Kubernetes 的API Server 进行交互了
$ kubectl proxy
# 执行 PACTH 操作
$ curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/nvidia.com/gpu", "value": "1"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
PATCH 操作完成后,你就可以看到 Node 的 Status 变成了如下所示的内容:
apiVersion: v1
kind: Node
...
Status:
Capacity:
cpu: 2
memory: 2049008Ki
nvidia.com/gpu: 1
这样在调度器里,它就能够在缓存里记录下 node-1 上的nvidia.com/gpu类型的资源的数量是 1。当然,在 Kubernetes 的 GPU 支持方案里,你并不需要真正去做上述关于 Extended Resource 的这些操作。都是上面说的对所有硬件加速设备进行管理的功能,都是由一种叫作 Device Plugin 的插件来负责的。
原理
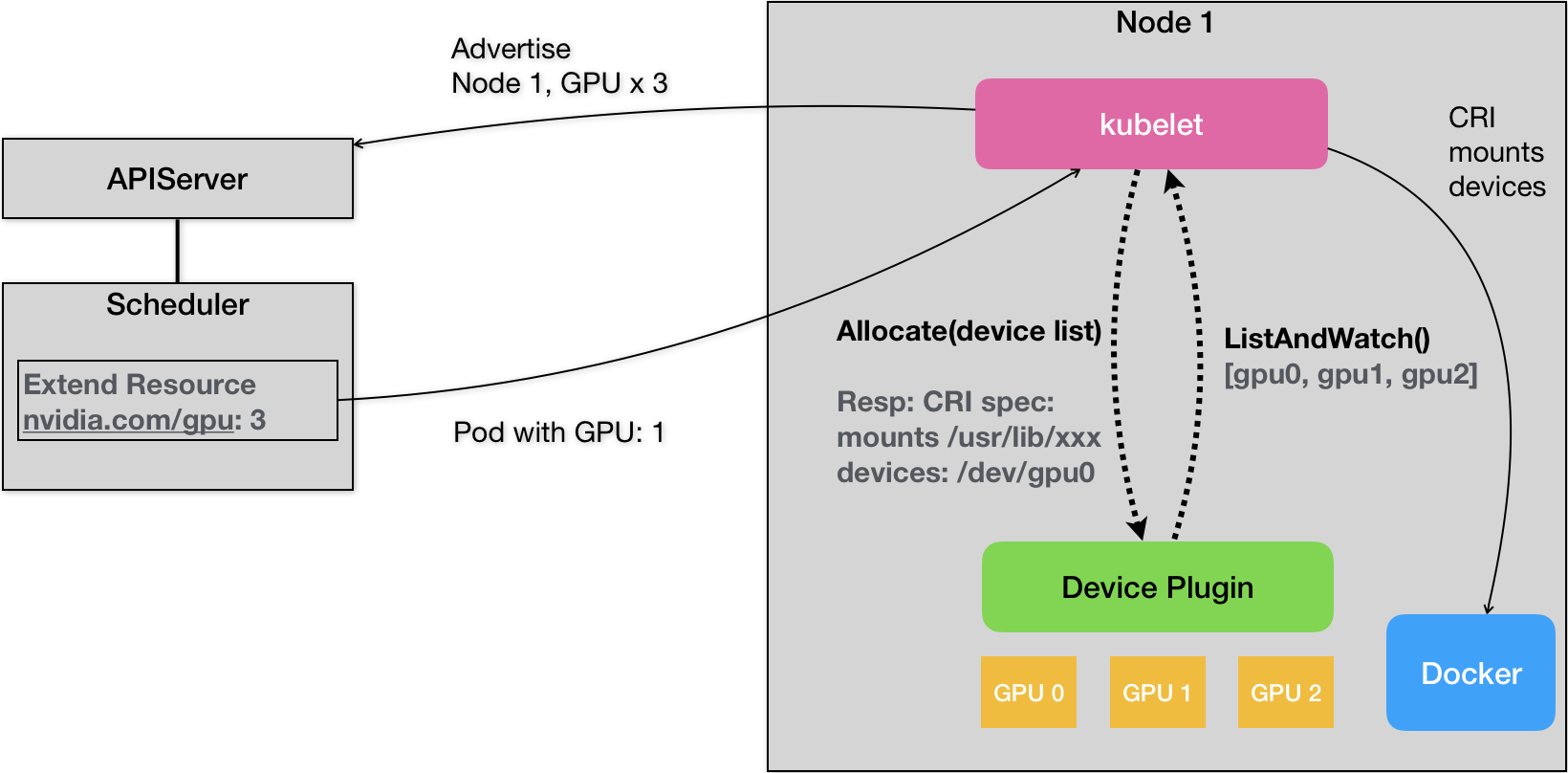
首先,对于每一种硬件设备,都需要有它所对应的 Device Plugin 进行管理,这些 Device Plugin,都通过 gRPC 的方式,同 kubelet 连接起来。以 NVIDIA GPU 为例,它对应的插件叫作NVIDIA GPU device plugin。
这个 Device Plugin 会通过一个叫作 ListAndWatch 的 API,定期向 kubelet 汇报该 Node 上 GPU 的列表。比如,在我们的例子里,一共有三个 GPU(GPU0、GPU1 和 GPU2)。这样,kubelet 在拿到这个列表之后,就可以直接在它向 APIServer 发送的心跳里,以 Extended Resource 的方式,加上这些 GPU 的数量,比如nvidia.com/gpu=3。所以说,用户在这里是不需要关心 GPU 信息向上的汇报流程的。
ListAndWatch 向上汇报的信息,只有本机上 GPU 的 ID 列表,而不会有任何关于 GPU 设备本身的信息。而且 kubelet 在向 API Server 汇报的时候,只会汇报该 GPU 对应的 Extended Resource 的数量。当然,kubelet 本身,会将这个 GPU 的 ID 列表保存在自己的内存里,并通过 ListAndWatch API 定时更新。
而当一个 Pod 想要使用一个 GPU 的时候,它只需要像我在本文一开始给出的例子一样,在 Pod 的 limits 字段声明nvidia.com/gpu: 1。那么接下来,Kubernetes 的调度器就会从它的缓存里,寻找 GPU 数量满足条件的 Node,然后将缓存里的 GPU 数量减 1,完成 Pod 与 Node 的绑定。
这个调度成功后的 Pod 信息,自然就会被对应的 kubelet 拿来进行容器操作。而当 kubelet 发现这个 Pod 的容器请求一个 GPU 的时候,kubelet 就会从自己持有的 GPU 列表里,为这个容器分配一个 GPU。此时,kubelet 就会向本机的 Device Plugin 发起一个 Allocate() 请求。这个请求携带的参数,正是即将分配给该容器的设备 ID 列表。当 Device Plugin 收到 Allocate 请求之后,它就会根据 kubelet 传递过来的设备 ID,从 Device Plugin 里找到这些设备对应的设备路径和驱动目录。当然,这些信息,正是 Device Plugin 周期性的从本机查询到的。比如,在 NVIDIA Device Plugin 的实现里,它会定期访问 nvidia-docker 插件,从而获取到本机的 GPU 信息。而被分配 GPU 对应的设备路径和驱动目录信息被返回给 kubelet 之后,kubelet 就完成了为一个容器分配 GPU 的操作。接下来,kubelet 会把这些信息追加在创建该容器所对应的 CRI 请求当中。这样,当这个 CRI 请求发给 Docker 之后,Docker 为你创建出来的容器里,就会出现这个 GPU 设备,并把它所需要的驱动目录挂载进去。
总结
目前,Kubernetes 社区里已经实现了很多硬件插件,比如FPGA、SRIOV、RDMA等等。
GPU 等硬件设备的调度工作,实际上是由 kubelet 完成的。即,kubelet 会负责从它所持有的硬件设备列表中,为容器挑选一个硬件设备,然后调用 Device Plugin 的 Allocate API 来完成这个分配操作。可以看到,在整条链路中,调度器扮演的角色,仅仅是为 Pod 寻找到可用的、支持这种硬件设备的节点而已。这就使得,Kubernetes 里对硬件设备的管理,只能处理“设备个数”这唯一一种情况。一旦你的设备是异构的、不能简单地用“数目”去描述具体使用需求的时候,比如,“我的 Pod 想要运行在计算能力最强的那个 GPU 上”,Device Plugin 就完全不能处理了。更不用说,在很多场景下,我们其实希望在调度器进行调度的时候,就可以根据整个集群里的某种硬件设备的全局分布,做出一个最佳的调度选择。
Device Plugin 的设计,也使得 Kubernetes 里,缺乏一种能够对 Device 进行描述的 API 对象。这就使得如果你的硬件设备本身的属性比较复杂,并且 Pod 也关心这些硬件的属性的话,那么 Device Plugin 也是完全没有办法支持的。更为棘手的是,在 Device Plugin 的设计和实现中,Google 的工程师们一直不太愿意为 Allocate 和 ListAndWatch API 添加可扩展性的参数。这就使得,当你确实需要处理一些比较复杂的硬件设备使用需求时,是没有办法通过扩展 Device Plugin 的 API 来实现的。
针对这些问题,RedHat 在社区里曾经大力推进过 ResourceClass的设计,试图将硬件设备的管理功能上浮到 API 层和调度层。但是,由于各方势力的反对,这个提议最后不了了之了。所以说,目前 Kubernetes 本身的 Device Plugin 的设计,实际上能覆盖的场景是非常单一的,属于“可用”但是“不好用”的状态。并且, Device Plugin 的 API 本身的可扩展性也不是很好。这也就解释了为什么像 NVIDIA 这样的硬件厂商,实际上并没有完全基于上游的 Kubernetes 代码来实现自己的 GPU 解决方案,而是做了一定的改动,也就是 fork。这,实属不得已而为之。
实战问题
- 暂停容器,来查看相关问题是容器启动错误比较常用的方法,比如先不启动程序,先执行sleep。