自从研究了redis的监控工具之后,对于redis的集群实现方案又回头做了一个系统的研究。
首先,先说一下redis,是一个高性能的key-value类型的NoSQL数据库,支持较为丰富的数据类型,单机Redis在普通的服务器上通常ops上限在5w左右,开启pipeline的情况下在20-30w左右。对于大多数中小公司来说,通常单机的Redis已经足够,最多根据不同业务分散到多台Redis。但是随着数据的越来越多,也迫切需求支持分布式集群。
redis集群
目前redis集群已经有了较大的应用,包括官方也推出的redis3.0版本的集群部署方案。
redis集群解决的问题
redis单线程特性,多请求顺序执行,单个耗时的操作会阻塞后续的操作,集群可以并发处理,更高效
单机内存有限
单点问题,缺乏高可用性
不能动态扩容
分区的实现
范围分区:将固定范围的数据key放到对应的实例中。这个方案不是太好,需要维护映射关系。
hash分区(一致性分区):用哈希函数(例如crc32)将key转化为一个数字,然后取模来分配到不同的实例中。
codis分区和redis3.0分区都是分了N个slot,先对key到slot进行hash分区再对slot进行范围分区或者hash分区。
四种部署方案
目前集群主要有四种部署方案
客户端分片
代理分片:twenproxy代理
codis
redis cluster
客户端分片
就是通过客户端来实现分布式分配到不同的主机上的redis实例,也就是客户端分片,来实现分布式集群。
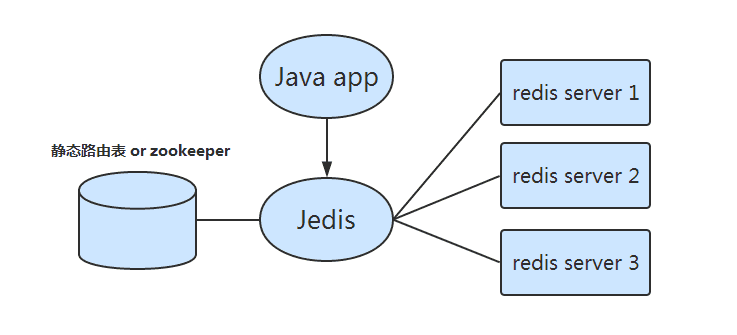
客户端分片是不用经过中间件,但是缺点太多了,所有的逻辑都在客户端,这样就导致了可运维性很差,首先,客户端存在着语言的差异,还有逻辑过分依赖于客户端,升级应用和扩展业务都依赖于客户端的开发,还存在着客户端版本和故障问题难以排查的问题。
代理分片
这边主要介绍的是曾被广泛使用的twenproxy作为中心代理的集群部署方案(twemproxy是twitter开源的一个redis和memcache代理服务器,只用于作为简单的代理中间件,目前twitter内部已经不再使用)。
该集群主要是通过中间件twenproxy来实现,客户端只要通过中间件twenproxy提供的api和端口来进行操作,然后twenproxy提供路由能力(所有的key通过一致性哈希算法分布到集群中所有的redis实例中)到后台redis集群中的不同实例中,实现分布式集群。
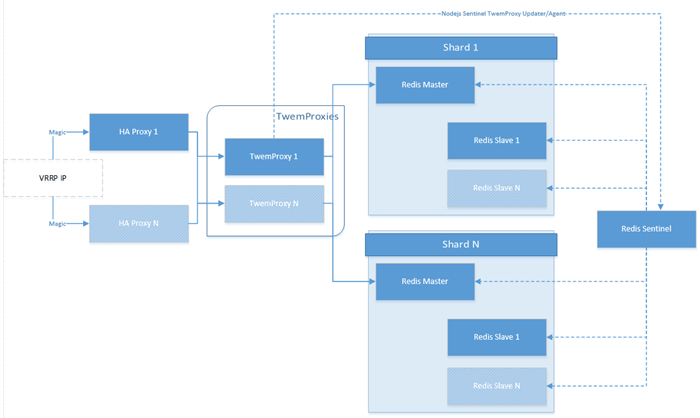
twenproxy还提供了一些其他保障集群稳定的功能
支持无效Redis实例的自动删除
代理与每个redis实例维持长连接,减少客户端和redis实例的连接数
代理是无状态的,可以任意部署多套,避免单点问题
默认启用pipeline,连接复用,提高效率,性能损失在 10% - 20%
这套部署方案,采用组件分离,升级容易,但是这个部署方案有一个很大的缺陷:无法动态扩容,不能平缓的增减redis实例,而且中间件也会消耗性能,在并发上,要求代理数量和实例一致甚至更多才能更好的发挥并发能力。造成运维工作量很大。
codis
codis是豌豆荚开源的一款redis分布式集群的实现方案,它是在redis2.8.21的基础上使用go和c改出来的,其实也是类似于twenproxy的代理模式,但是它可以实现平滑的新增实例,也就是动态扩容。
Codis中采用预分片的形式,启动的时候就创建了1024个slot,1个slot相当于1个箱子,每个箱子有固定的编号,范围是1~1024。slot这个箱子用作存放Key,至于Key存放到哪个箱子,可以通过算法“crc32(key)%1024”获得一个数字,这个数字的范围一定是1~1024之间,Key就放到这个数字对应的slot。例如,如果某个Key通过算法“crc32(key)%1024”得到的数字是5,就放到编码为5的slot(箱子)。1个slot只能放1个Redis Server Group,不能把1个slot放到多个Redis Server Group中。1个Redis Server Group最少可以存放1个slot,最大可以存放1024个slot。因此,Codis中最多可以指定1024个Redis Server Group。
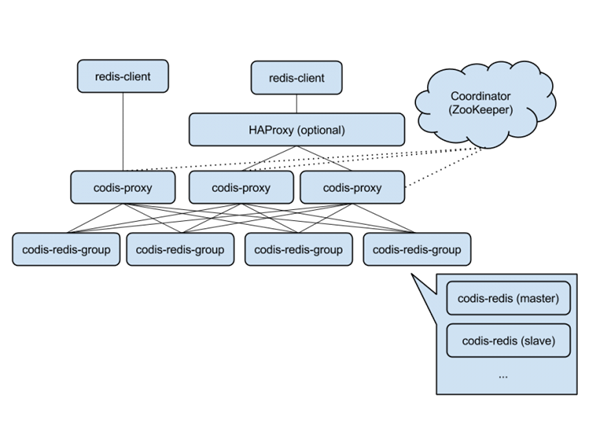
这边对codis四大组成部分
codis-proxy 是客户端连接的 Redis 代理服务, codis-proxy 本身实现了 Redis 协议, 表现得和一个原生的 Redis 没什么区别 (就像 Twemproxy), 对于一个业务来说, 可以用Keepalived等负载均衡软件部署多个 codis-proxy实现高可用, codis-proxy 本身是无状态的。
codis-config 是 Codis 的管理工具, 支持包括, 添加/删除 Redis 节点, 添加/删除 Proxy 节点, 发起数据迁移等操作. codis-config 本身还自带了一个 http server, 会启动一个 dashboard, 用户可以直接在浏览器上观察 Codis 集群的运行状态,可以完善运维。
codis-server 是 Codis 项目维护的一个 Redis 分支, 基于 2.8.21 开发, 加入了 slot 的支持和原子的数据迁移指令. Codis 上层的 codis-proxy 和 codis-config 只能和这个版本的 Redis 交互才能正常运行。
ZooKeeper:Codis依赖于ZooKeeper存储数据路由表的信息和Codis Proxy节点的元信息。另外,Codisconfig发起的命令都会通过ZooKeeper同步到CodisProxy的节点。
依然有中间件的性能消耗问题,但是解决了动态扩容问题。这个思路是目前大多数公司在用的。
redis3.0
1.预分片
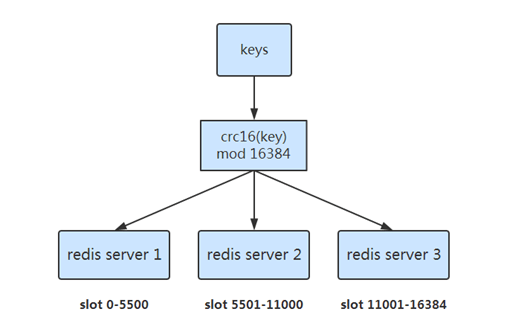
- 预先分配好 16384 个slot
- slot 和 server 的映射关系存储每一个 server 的路由表中
- 根据 CRC16(key) mod 16384 的值,决定将一个key放到哪一个slot中
- 数据迁移时就是调整 slot 的分布
2.设计架构
redis3.0集群部署方案是官方在发布redis3.0版本的时候提供的,它采用了p2p模式,完全去中心化。
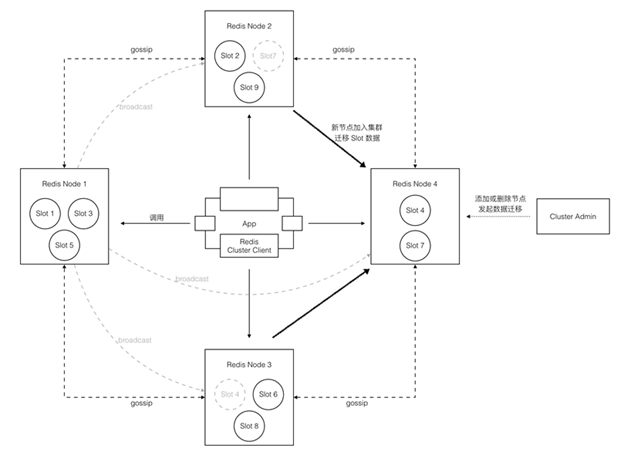
实现
- 无中心化结构,每个节点都保存数据和整个集群的状态。
- 采用 gossip 协议传播信息以及发现新节点,最终实现一致性(最终一致性)。
- 每个节点都和其他所有节点连接,并保持活跃。
- PING/PONG:心跳,附加上自己以及一些其他节点数据,每个节点每秒随机PING几个节点。会选择那些超过cluster-node-timeout一半的时间还未PING过或未收到PONG的节点。
- UPDATE消息:计数戳,如果收到server的计数为3,自己的为4,则发UPDATE更新对方路由表,反之更新自己的路由表,最终集群路由状态会和计数戳最大的实例一样。
- 如果 cluster-node-timeout 设置较小,或者节点较多,数据传输量将比较可观。
- Broadcast:有状态变动时先broadcast,后PING; 发布/订阅。
- Redis node 不作为client请求的代理(不转发请求),client根据node返回的错误信息重定向请求?(需要 smart-client 支持),所以client连接集群中任意一个节点都可以。
高可用
- 每个Redis Node可以有一个或者多个Slave,当Master挂掉时,选举一个Slave形成新的Master。
- Master Slave 之间异步复制(可能会丢数据)。
- 采用 gossip 协议探测其他节点存活状态,超过 cluster-node-timeout,标记为 PFAIL,PING中附加此数据。当 Node A发现半数以上master将失效节点标记为PFAIL,将其标记为FAIL,broadcast FAIL。
- 各 slave 等待一个随机时间后 发起选举,向其他 master broadcast,半数以上同意则赢得选举否则发起下一次选举
- 当 slave 成为 master,先broadcast,后持续PING,最终集群实例都获知此消息
存在的问题
- Gossip协议通信开销
- 严重依赖于smart-client的成熟度
- 如果smart-client支持缓存slot路由,需要额外占用内存空间,为了效率需要建立和所有 redis server 的长连接(每一个使用该库的程序都需要建立这么多连接)。
- 如果不支持缓存路由信息,会先访问任意一台 redis server,之后重定向到新的节点。
- 需要更新当前所有的client。
- 官方只提供了一个ruby程序 redis-trib 完成集群的所有操作,缺乏监控管理工具,很难清楚目前集群的状态
- 数据迁移以Key为单位,速度较慢
- 某些操作不支持,MultiOp和Pipeline都被限定在命令中的所有Key必须都在同一Slot内