CSI是Container Storage Interface的简称,旨在能为容器编排引擎和存储系统间建立一套标准的存储调用接口,实现解耦,通过该接口能为容器编排引擎提供存储服务。
基本使用
以csi-hostpath插件为例,演示部署CSI插件、用户使用CSI插件提供的存储资源。
开启csi
设置Kubernetes服务启动参数,为kube-apiserver、kubecontroller-manager和kubelet服务的启动参数添加。
[root@k8smaster01 ~]# vi /etc/kubernetes/manifests/kube-apiserver.yaml
……
- --allow-privileged=true
- --feature-gates=CSIPersistentVolume=true
- --runtime-config=storage.k8s.io/v1alpha1=true
……
[root@k8smaster01 ~]# vi /etc/kubernetes/manifests/kube-controller-manager.yaml
……
- --feature-gates=CSIPersistentVolume=true
……
[root@k8smaster01 ~]# vi /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
# Note: This dropin only works with kubeadm and kubelet v1.11+
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --feature-gates=CSIPersistentVolume=true"
……
[root@k8smaster01 ~]# systemctl daemon-reload
[root@k8smaster01 ~]# systemctl restart kubelet.service
设计架构
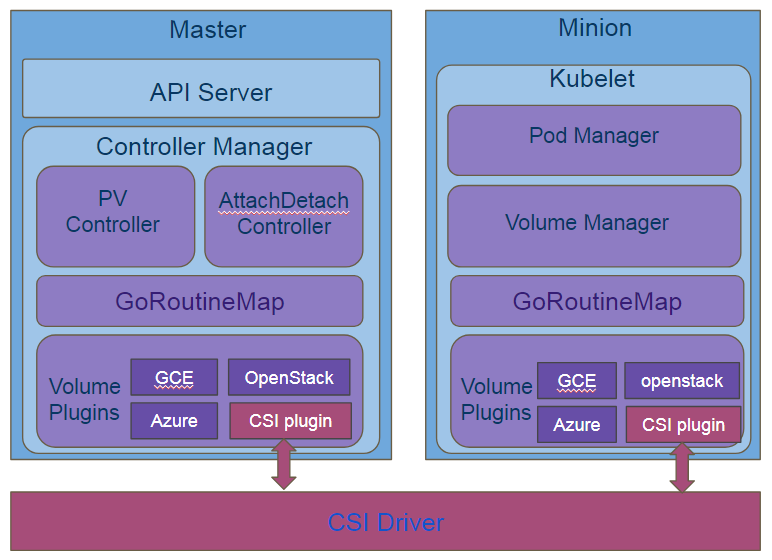
大致看上去,这个和原生存储架构并没有太大的变化,其实不然,原生中Plugin和driver之间的调用使用的是操作系统命令行接口,而CSI采用的是grpc调用,grpc调用的一个优势就是可以将grpc服务运行在socket上,这样服务端就可以运行在socket端点的任何地方,换句话说就是可以被隔离单独运行,这样就可以实现扩展,然后通过标准rpc接口,完成本地原生模式的控制。扩展机制有很多,目前比较常用的就是官方抽象出来的统一接口csi。
csi提供了一套标准的接口集成在k8s的源码(kube-controller-manager,kubelet)中,然后第三方的存储插件只要实现这些接口并注册就可以调用对应的函数进行pv和pvc的自动创建,提供了可扩展的机会。
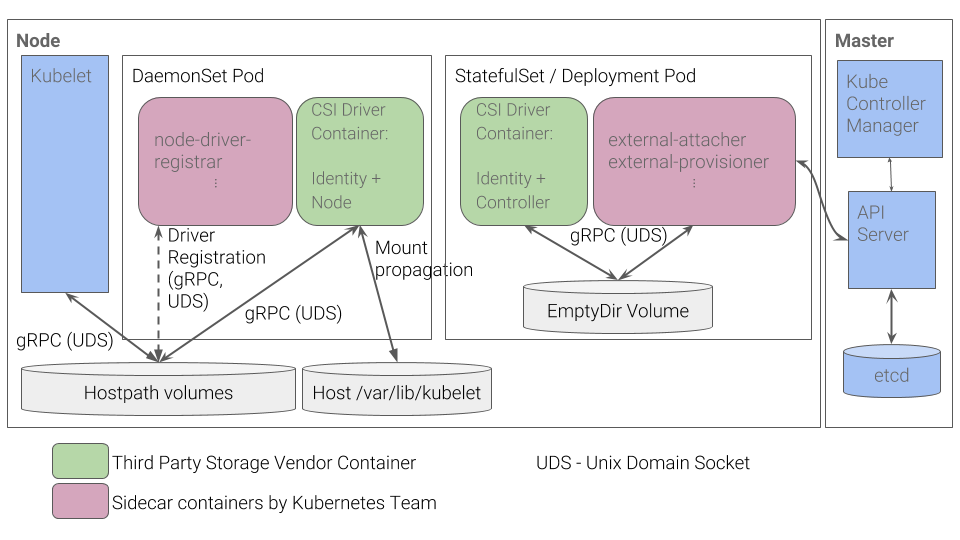
根据官方提供的部署架构如下
- 右边一个StatefulSet或Deployment的pod,可以说是csi controller,提供存储服务视角对存储资源和存储卷进行管理和操作。在Kubernetes中建议将其部署为单实例Pod,可以使用StatefulSet或Deployment控制器进行部署,设置副本数量为1,保证为一种存储插件只运行一个控制器实例。
- 用户实现的 CSI 插件,也就是CSI Driver存储驱动容器(正常和下面的CSI 插件是同一个程序,也可以分开做一个控制插件,一个操作插件)
- 与Master(kube-controller-manager)通信的辅助sidecar容器。
- External Attacher:Kubernetes 提供的 sidecar 容器,它监听 VolumeAttachment 和 PersistentVolume 对象的变化情况,并调用 CSI 插件的 ControllerPublishVolume 和 ControllerUnpublishVolume 等 API 将 Volume 挂载或卸载到指定的 Node 上,也就是对应的 Attach/Detach 操作,因为 K8s 的 PV 控制器无法直接调用 Volume Plugins 的相关函数,故由 External Attacher 通过 gRPC 来调用。(官网提供)
- External Provisioner:Kubernetes 提供的 sidecar 容器,它监听 PersistentVolumeClaim 对象的变化情况,并调用 CSI 插件的 ControllerPublish 和 ControllerUnpublish 等 API 管理 Volume,也就是Provision/Delete 操作,因为 K8s 的 PV 控制器无法直接调用 Volume Plugins 的相关函数,故由 External Provioner 通过 gRPC 来调用。(官网提供)
- 这两个容器通过本地Socket(Unix DomainSocket,UDS),并使用gPRC协议进行通信。
- sidecar容器通过Socket调用CSI Driver容器的CSI接口,CSI Driver容器负责具体的存储卷操作。
- 左边一个Daemonset的pod:对主机(Node)上的Volume进行管理和操作。在Kubernetes中建议将其部署为DaemonSet,在每个Node上都运行一个Pod,以便 Kubelet 可以调用,它包含 2 个容器:
- 用户实现的 CSI 插件,也就是CSI Driver存储驱动容器,主要功能是接收kubelet的调用,需要实现一系列与Node相关的CSI接口,例如NodePublishVolume接口(用于将Volume挂载到容器内的目标路径)、NodeUnpublishVolume接口(用于从容器中卸载Volume),等等。
- Driver Registrar:注册 CSI 插件到 kubelet 中,并初始化 NodeId(即给 Node 对象增加一个 Annotation csi.volume.kubernetes.io/nodeid)(官网提供)
- node-driver-registrar容器与kubelet通过Node主机的一个hostPath目录下的unixsocket进行通信。CSI Driver容器与kubelet通过Node主机的另一个hostPath目录下的unixsocket进行通信,同时需要将kubelet的工作目录(默认为/var/lib/kubelet)挂载给CSIDriver容器,用于为Pod进行Volume的管理操作(包括mount、umount等)。
所以重点就是用户自己实现的插件逻辑,官方已经支持实现了很多的插件,我们在开发的时候可以参考。
上面简单的说了组件,以及相关的部署,下面我们通过一个交互图来了解如何实现out-of-tree的csi volume的。

右边的就是插件程序,由csi定义的三个部分组成,中间就是扩展的控制器,用于注册插件程序,联通集群和插件程序的交互的桥梁,左边就是我们的集群需要使用的组件,我们详细看一下。
- Driver Registrar 组件,负责将插件注册到 kubelet 里面(这可以类比为,将可执行文件放在插件目录下)。而在具体实现上,Driver Registrar 需要请求 CSI 插件的 Identity 服务来获取插件信息。
- External Provisioner 组件,负责的正是 Provision 阶段。在具体实现上,External Provisioner 监听(Watch)了 APIServer 里的 PVC 对象。当一个 PVC 被创建时,它就会调用 CSI Controller 的 CreateVolume 方法,为你创建对应 PV。
- External Attacher 组件,负责的正是“Attach 阶段”。在具体实现上,它监听了 APIServer 里 VolumeAttachment 对象的变化。VolumeAttachment 对象是 Kubernetes 确认一个 Volume 可以进入“Attach 阶段”的重要标志。一旦出现了 VolumeAttachment 对象,External Attacher 就会调用 CSI Controller 服务的 ControllerPublish 方法,完成它所对应的 Volume 的 Attach 阶段。
- Volume 的“Mount 阶段”,并不属于 External Components 的职责。当 kubelet 的 VolumeManagerReconciler 控制循环检查到它需要执行 Mount 操作的时候,会通过 pkg/volume/csi 包,直接调用 CSI Node 服务完成 Volume 的“Mount 阶段”。
到这里我们就可以清晰的看到组件的作用,并且部署使用deployment和daemonset的含义,我们还可以通过网上的一个时序图来看看创建一个pod,各个组件之间的交互,更加详细的讲解了apiserver中的控制器是如何进行逻辑控制的。
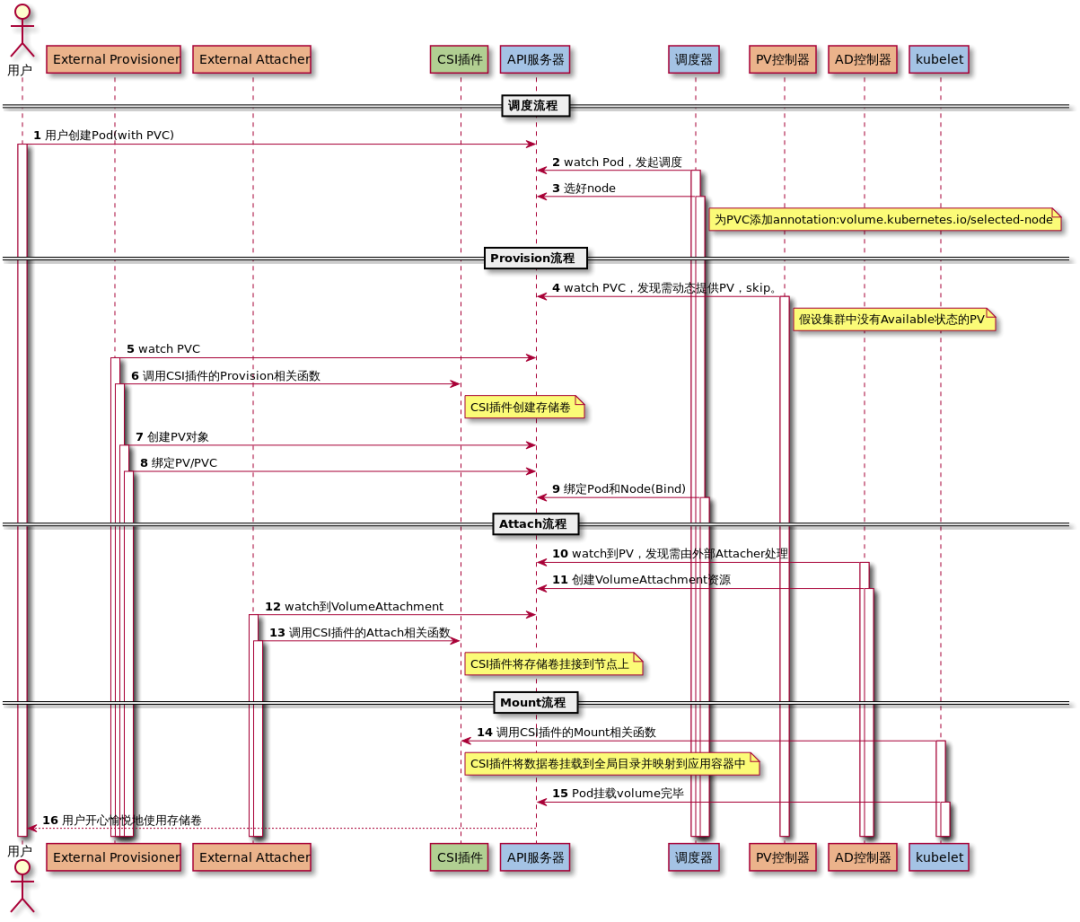
调度流程
- 创建pod,使用pvc,然后就是正常的调度,选择好node后,对应的pvc添加annotation:volume.kubernetes.io/selected-node
provision流程
- 其实就是创建volume的流程,首先pv控制器watch 到该 Pod 使用的 PVC 处于 Pending 状态,查找集群中没有可以绑定的pv,动态创建。
- 动态创建使用的out-of-tree的模式,使用的csi场景下,这个时候通过external provisioner 来调用csi plugin ,使用调用csi对应的函数去创建pv对象,其实就是调用了Controller Plugin的CreateVolume函数。
- pv创建好后,就绑定pvc。
- 然后调度器将pod和node绑定。
attach流程
- 其实就是将pv挂载到node上,通过AD控制器watch pv,通过external attacher和csi plugin进行交互,调用Controller Plugin的ControllerPublishVolume函数完成attach操作。
mount流程
- 最后就是将pv挂载到pod中,kubelet中的volume manager调用csi plugin的NodeStageVolume、NodePublishVolume完成对应的mount操作,kubelet不需要使用grpc交互,直接调用本地二进制文件就可以。
说到这里,有必要说一下一个典型的 CSI Volume 生命周期如下图(来自 CSI SPEC)所示
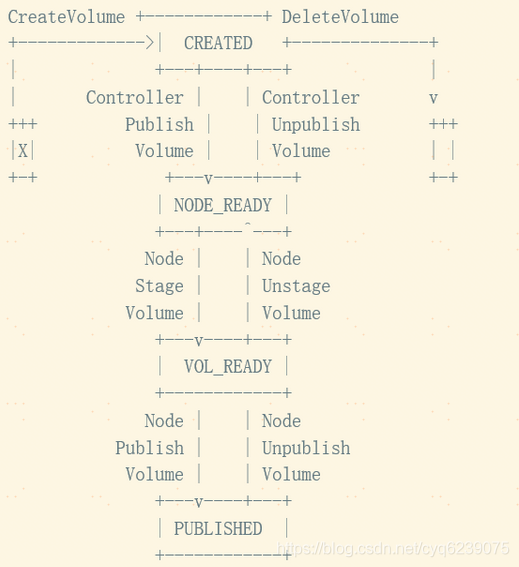
- Volume 被创建后进入 CREATED 状态,此时 Volume 仅在存储系统中存在,对于所有的 Node 或者 Container 都是不可感知的;
- 对 CREATED 状态的 Volume 进行 Controlller Publish 动作后在指定的 Node 上进入 NODE_READY 的状态,此时 Node 可以感知到 Volume,但是 Container 依然不可见;
- 在 Node 对 Volume 进行 Stage 操作,进入 VOL_READY 的状态,此时 Node 已经与 Volume 建立连接。Volume 在 Node 上以某种形式存在;
- 在 Node 上对 Volume 进行 Publish 操作,此时 Volume 将转化为 Node 上 Container 可见的形态被 Container 利用,进入正式服务的状态;
- 当 Container 的生命周期结束或其他不再需要 Volume 情况发生时,Node 执行 Unpublish Volume 动作,将 Volume 与 Container 之间的连接关系解除,回退至 VOL_READY 状态;
- Node Unstage 操作将会把 Volume 与 Node 的连接断开,回退至 NODE_READY 状态;
- Controller Unpublish 操作则会取消 Node 对 Volume 的访问权限;
- Delete 则从存储系统中销毁 Volume。
从这个图我们可以看出一个存储卷的供应分别调用了Controller Plugin的CreateVolume、ControllerPublishVolume及Node Plugin的NodeStageVolume、NodePublishVolume这4个gRPC接口,存储卷的销毁分别调用了Node Plugin的NodeUnpublishVolume、NodeUnstageVolume及Controller的ControllerUnpublishVolume、DeleteVolume这4个gRPC接口。
到此,csi的设计架构流程英国是很清晰的了,下面我们详细的看看其原理。
基本原理
我们还是通过一个pod的创建过程中存储的相关操作来知悉如何实现存储,也是对上面核心流程的展开。
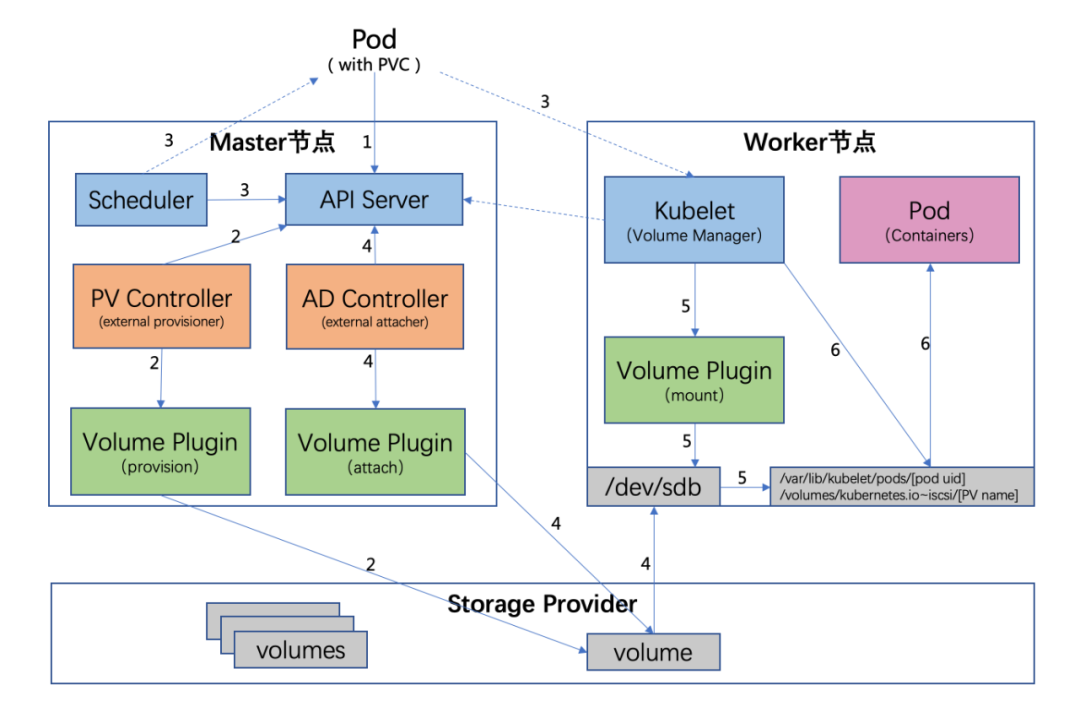
pod创建过程中调用存储的相关流程
- 用户创建了一个包含 PVC 的 Pod,该 PVC 要求使用动态存储卷;
- PV 控制器 watch 到该 Pod 使用的 PVC 处于 Pending 状态,于是调用 Volume Plugin(in-tree使用原生的Provisioner ,如果out-of-tree 由 External Provisioner 来处理)创建存储卷,并创建 PV 对象;
- Scheduler 根据 Pod 配置、节点状态、PV 配置等信息,把 Pod 调度到一个合适的 Worker 节点上;
- AD 控制器发现 Pod 和 PVC 处于待挂接状态,于是调用 Volume Plugin 挂接存储设备到目标 Worker 节点上
- 在 Worker 节点上,Kubelet 中的 Volume Manager 等待存储设备挂接完成,并通过 Volume Plugin 将设备挂载到全局目录:/var/lib/kubelet/pods/[pod uid]/volumes/kubernetes.io~iscsi/[PV name](以 iscsi 为例);
- Kubelet 通过 Docker 启动 Pod 的 Containers,用 bind mount 方式将已挂载到本地全局目录的卷映射到容器中。
provisioning volumes
先了解一些pv控制器的基本概念
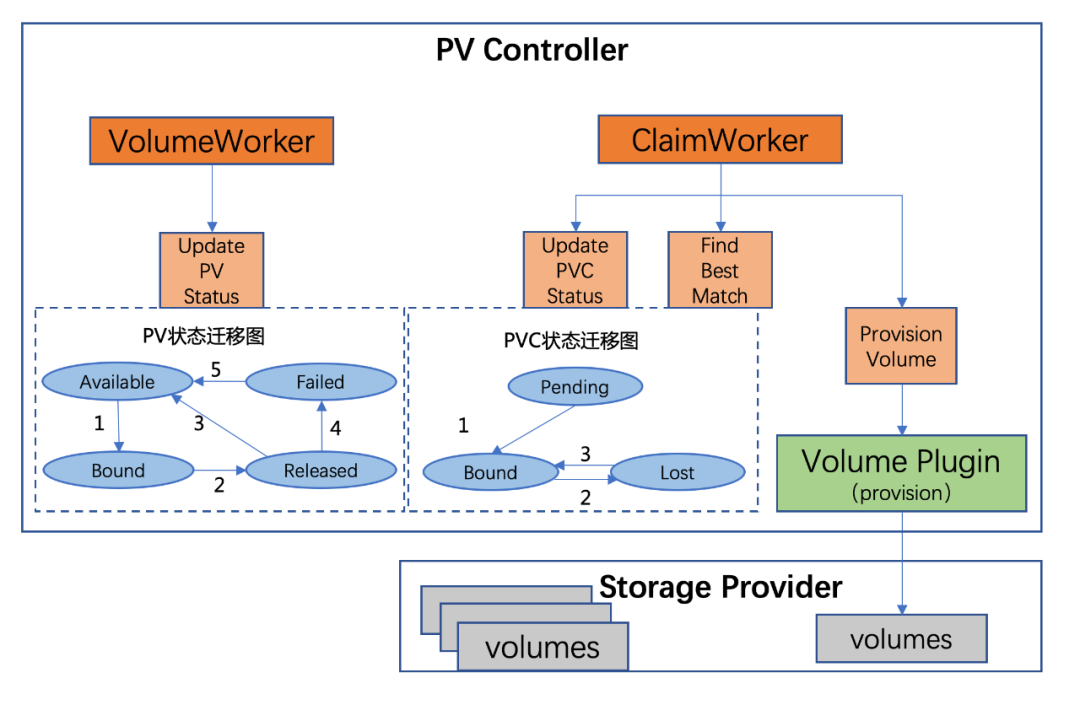
重图上可见pv控制器中主要有两个worker
- ClaimWorker:处理 PVC 的 add / update / delete 相关事件以及 PVC 的状态迁移;
- VolumeWorker:负责 PV 的状态迁移。
PV 状态迁移(UpdatePVStatus)
- PV 初始状态为 Available,当 PV 与 PVC 绑定后,状态变为 Bound;
- 与 PV 绑定的 PVC 删除后,状态变为 Released;
- 当 PV 回收策略为 Recycled 或手动删除 PV 的 .Spec.ClaimRef 后,PV 状态变为 Available;
- 当 PV 回收策略未知或 Recycle 失败或存储卷删除失败,PV 状态变为 Failed;
- 手动删除 PV 的 .Spec.ClaimRef,PV 状态变为 Available。
PVC 状态迁移(UpdatePVCStatus)
- 当集群中不存在满足 PVC 条件的 PV 时,PVC 状态为 Pending。在 PV 与 PVC 绑定后,PVC 状态由 Pending 变为 Bound;
- 与 PVC 绑定的 PV 在环境中被删除,PVC 状态变为 Lost;
- 再次与一个同名 PV 绑定后,PVC 状态变为 Bound。
再来看Provisioning 流程就十分清晰简单了
先寻找静态存储卷(FindBestMatch)
PV 控制器首先在环境中筛选一个状态为 Available 的 PV 与新 PVC 匹配。
- DelayBinding:PV 控制器判断该 PVC 是否需要延迟绑定:
- 查看 PVC 的 annotation 中是否包含 volume.kubernetes.io/selected-node,若存在则表示该 PVC 已经被调度器指定好了节点(属于 ProvisionVolume),故不需要延迟绑定;
- 若 PVC 的 annotation 中不存在 volume.kubernetes.io/selected-node,同时没有 StorageClass,默认表示不需要延迟绑定;若有 StorageClass,查看其 VolumeBindingMode 字段,若为 WaitForFirstConsumer 则需要延迟绑定,若为 Immediate 则不需要延迟绑定;
- FindBestMatchPVForClaim:PV 控制器尝试找一个满足 PVC 要求的环境中现有的 PV。PV 控制器会将所有的 PV 进行一次筛选,并会从满足条件的 PV 中选择一个最佳匹配的 PV。筛选规则:
- VolumeMode 是否匹配;
- PV 是否已绑定到 PVC 上;
- PV 的 .Status.Phase 是否为 Available;
- LabelSelector 检查,PV 与 PVC 的 label 要保持一致;
- PV 与 PVC 的 StorageClass 是否一致;
- 每次迭代更新最小满足 PVC requested size 的 PV,并作为最终结果返回;
- Bind:PV 控制器对选中的 PV、PVC 进行绑定:
- 更新 PV 的 .Spec.ClaimRef 信息为当前 PVC;
- 更新 PV 的 .Status.Phase 为 Bound;
- 新增 PV 的 annotation :pv.kubernetes.io/bound-by-controller: “yes”;
- 更新 PVC 的 .Spec.VolumeName 为 PV 名称;
- 更新 PVC 的 .Status.Phase 为 Bound;
- 新增 PVC 的 annotation:pv.kubernetes.io/bound-by-controller: “yes” 和 pv.kubernetes.io/bind-completed: “yes”;
再动态创建存储卷(ProvisionVolume)
若环境中没有合适的 PV,则进入动态 Provisioning 场景:
- Before Provisioning:
- PV 控制器首先判断 PVC 使用的 StorageClass 是 in-tree 还是 out-of-tree:通过查看 StorageClass 的 Provisioner 字段是否包含 “kubernetes.io/” 前缀来判断;
- PV 控制器更新 PVC 的 annotation:
claim.Annotations[“volume.beta.kubernetes.io/storage-provisioner”] = storageClass.Provisioner;
- in-tree Provisioning(internal provisioning):
- in-tree 的 Provioner 会实现 ProvisionableVolumePlugin 接口的 NewProvisioner 方法,用来返回一个新的 Provisioner;
- PV 控制器调用 Provisioner 的 Provision 函数,该函数会返回一个 PV 对象;
- PV 控制器创建上一步返回的 PV 对象,将其与 PVC 绑定,Spec.ClaimRef 设置为 PVC,.Status.Phase 设置为 Bound,.Spec.StorageClassName 设置为与 PVC 相同的 StorageClassName;同时新增 annotation:“pv.kubernetes.io/bound-by-controller”=“yes” 和 “pv.kubernetes.io/provisioned-by”=plugin.GetPluginName();
- out-of-tree Provisioning(external provisioning):
- External Provisioner 检查 PVC 中的 claim.Spec.VolumeName 是否为空,不为空则直接跳过该 PVC;
- External Provisioner 检查 PVC 中的
claim.Annotations[“volume.beta.kubernetes.io/storage-provisioner”]是否等于自己的 Provisioner Name(External Provisioner 在启动时会传入 –provisioner 参数来确定自己的 Provisioner Name); - 若 PVC 的 VolumeMode=Block,检查 External Provisioner 是否支持块设备;
- External Provisioner 调用 Provision 函数:通过 gRPC 调用 CSI 存储插件的 CreateVolume 接口;
- External Provisioner 创建一个 PV 来代表该 volume,同时将该 PV 与之前的 PVC 做绑定。
deleting volumes
用户删除 PVC,PV 控制器改变 PV.Status.Phase 为 Released。
当 PV.Status.Phase == Released 时,PV 控制器首先检查 Spec.PersistentVolumeReclaimPolicy 的值,为 Retain 时直接跳过,为 Delete 时:
- in-tree Deleting:
- in-tree 的 Provioner 会实现 DeletableVolumePlugin 接口的 NewDeleter 方法,用来返回一个新的 Deleter;
- 控制器调用 Deleter 的 Delete 函数,删除对应 volume;
- 在 volume 删除后,PV 控制器会删除 PV 对象;
- out-of-tree Deleting:
- External Provisioner 调用 Delete 函数,通过 gRPC 调用 CSI 插件的 DeleteVolume 接口;
- 在 volume 删除后,External Provisioner 会删除 PV 对象
Attaching Volumes
Kubelet 组件和 AD 控制器都可以做 attach/detach 操作,若 Kubelet 的启动参数中指定了 –enable-controller-attach-detach,则由 Kubelet 来做;否则默认由 AD 控制起来做。
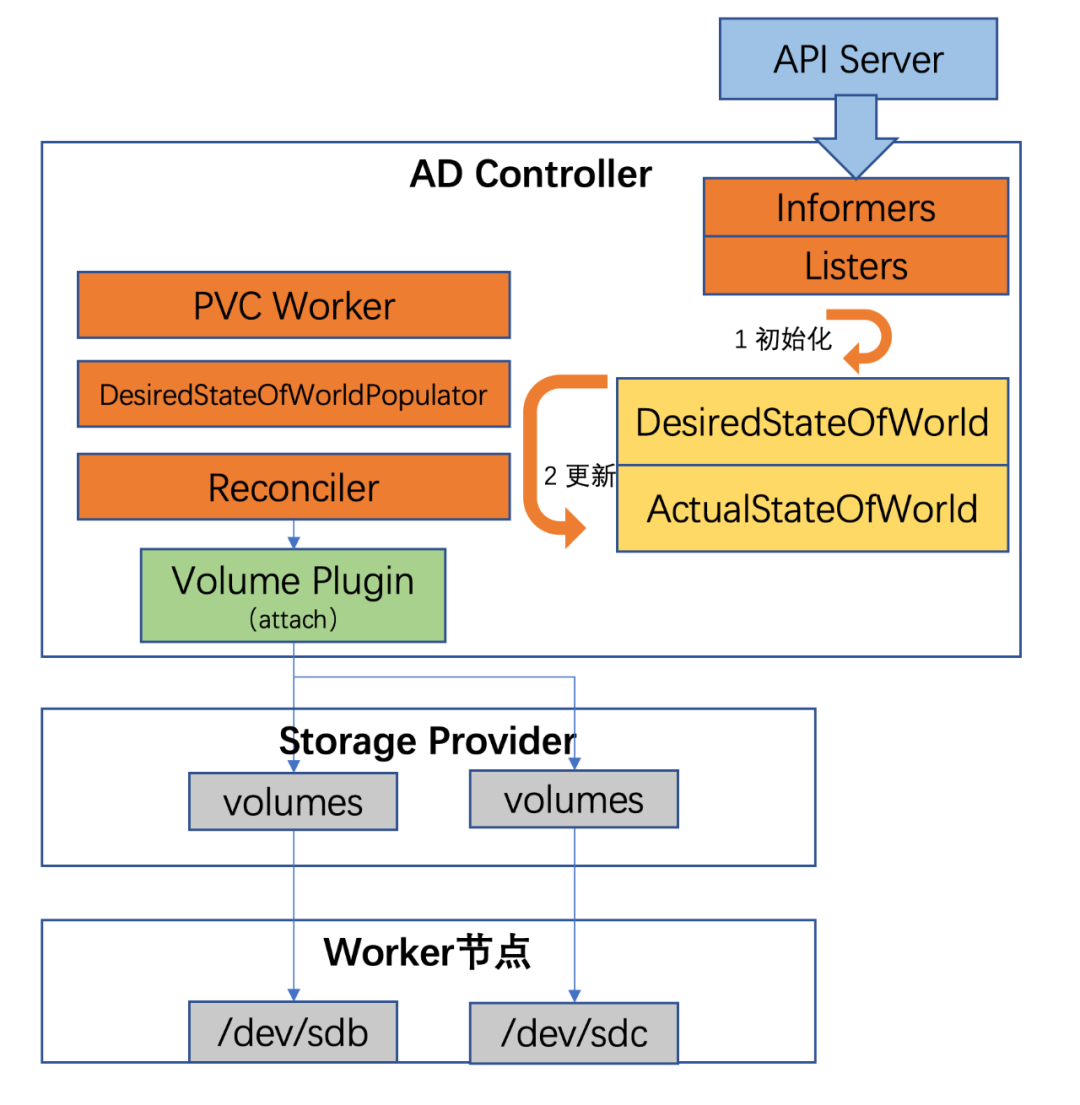
AD 控制器中有两个核心变量:
- DesiredStateOfWorld(DSW):集群中预期的数据卷挂接状态,包含了 nodes->volumes->pods 的信息;
- ActualStateOfWorld(ASW):集群中实际的数据卷挂接状态,包含了 volumes->nodes 的信息。
Attaching 流程如下:
- AD 控制器根据集群中的资源信息,初始化 DSW 和 ASW。
- AD 控制器内部有三个组件周期性更新 DSW 和 ASW:
- Reconciler。通过一个 GoRoutine 周期性运行,确保 volume 挂接 / 摘除完毕。此期间不断更新 ASW:
- in-tree attaching:
- in-tree 的 Attacher 会实现 AttachableVolumePlugin 接口的 NewAttacher 方法,用来返回一个新的 Attacher;
- AD 控制器调用 Attacher 的 Attach 函数进行设备挂接;
- 更新 ASW。
- out-of-tree attaching:
- 调用 in-tree 的 CSIAttacher 创建一个 VolumeAttachement(VA)对象,该对象包含了 Attacher 信息、节点名称、待挂接 PV 信息;
- External Attacher 会 watch 集群中的 VolumeAttachement 资源,发现有需要挂接的数据卷时,调用 Attach 函数,通过 gRPC 调用 CSI 插件的 ControllerPublishVolume 接口。
- DesiredStateOfWorldPopulator。通过一个 GoRoutine 周期性运行,主要功能是更新 DSW:
- findAndRemoveDeletedPods - 遍历所有 DSW 中的 Pods,若其已从集群中删除则从 DSW 中移除;
- findAndAddActivePods - 遍历所有 PodLister 中的 Pods,若 DSW 中不存在该 Pod 则添加至 DSW。
- PVC Worker。watch PVC 的 add/update 事件,处理 PVC 相关的 Pod,并实时更新 DSW。
Detaching Volumes
Detaching 流程如下:
- 当 Pod 被删除,AD 控制器会 watch 到该事件。首先 AD 控制器检查 Pod 所在的 Node 资源是否包含”volumes.kubernetes.io/keep-terminated-pod-volumes”标签,若包含则不做操作;不包含则从 DSW 中去掉该 volume;
- AD 控制器通过 Reconciler 使 ActualStateOfWorld 状态向 DesiredStateOfWorld 状态靠近,当发现 ASW 中有 DSW 中不存在的 volume 时,会做 Detach 操作:
- in-tree detaching:
- AD 控制器会实现 AttachableVolumePlugin 接口的 NewDetacher 方法,用来返回一个新的 Detacher;
- 控制器调用 Detacher 的 Detach 函数,detach 对应 volume;
- AD 控制器更新 ASW。
- out-of-tree detaching:
- AD 控制器调用 in-tree 的 CSIAttacher 删除相关 VolumeAttachement 对象;
- External Attacher 会 watch 集群中的 VolumeAttachement(VA)资源,发现有需要摘除的数据卷时,调用 Detach 函数,通过 gRPC 调用 CSI 插件的 ControllerUnpublishVolume 接口;
- AD 控制器更新 ASW。
Mounting/Unmounting Volumes
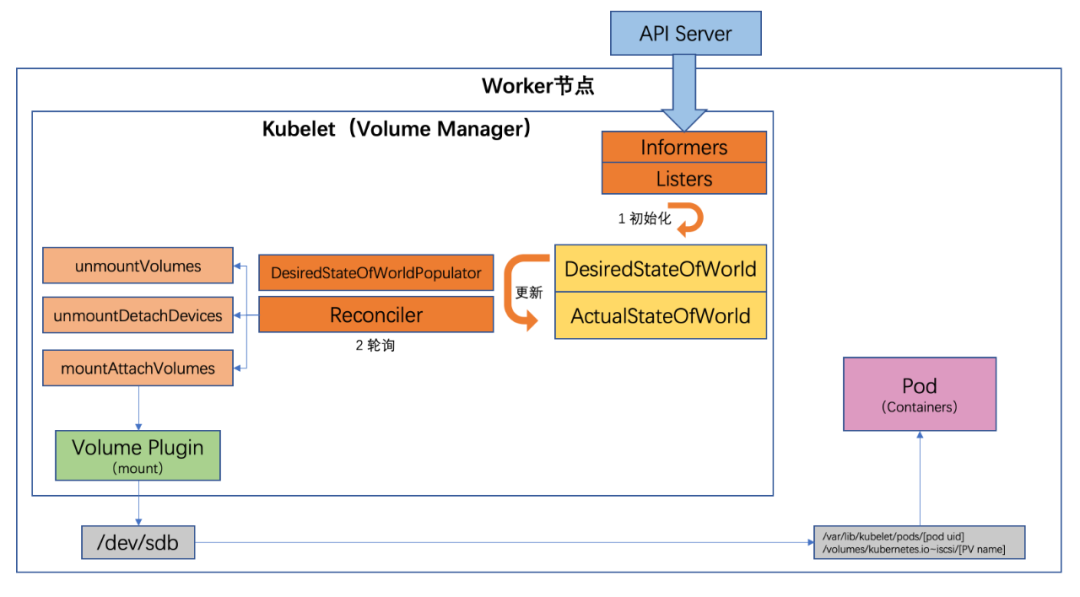
Volume Manager 中同样也有两个核心变量:
- DesiredStateOfWorld(DSW):集群中预期的数据卷挂载状态,包含了 volumes->pods 的信息;
- ActualStateOfWorld(ASW):集群中实际的数据卷挂载状态,包含了 volumes->pods 的信息。
全局目录(global mount path)存在的目的:块设备在 Linux 上只能挂载一次,而在 K8s 场景中,一个 PV 可能被挂载到同一个 Node 上的多个 Pod 实例中。若块设备格式化后先挂载至 Node 上的一个临时全局目录,然后再使用 Linux 中的 bind mount 技术把这个全局目录挂载进 Pod 中对应的目录上,就可以满足要求。上述流程图中,全局目录即 /var/lib/kubelet/pods/[pod uid]/volumes/kubernetes.io~iscsi/[PV name]
Mounting/UnMounting 流程如下:
- VolumeManager 根据集群中的资源信息,初始化 DSW 和 ASW。
- VolumeManager 内部有两个组件周期性更新 DSW 和 ASW:
- DesiredStateOfWorldPopulator:通过一个 GoRoutine 周期性运行,主要功能是更新 DSW;
- Reconciler:通过一个 GoRoutine 周期性运行,确保 volume 挂载 / 卸载完毕。此期间不断更新 ASW:
- unmountVolumes:确保 Pod 删除后 volumes 被 unmount。遍历一遍所有 ASW 中的 Pod,若其不在 DSW 中(表示 Pod 被删除),此处以 VolumeMode=FileSystem 举例,则执行如下操作:
- Remove all bind-mounts:调用 Unmounter 的 TearDown 接口(若为 out-of-tree 则调用 CSI 插件的 NodeUnpublishVolume 接口);
- Unmount volume:调用 DeviceUnmounter 的 UnmountDevice 函数(若为 out-of-tree 则调用 CSI 插件的 NodeUnstageVolume 接口);
- 更新 ASW。
- mountAttachVolumes:确保 Pod 要使用的 volumes 挂载成功。遍历一遍所有 DSW 中的 Pod,若其不在 ASW 中(表示目录待挂载映射到 Pod 上),此处以 VolumeMode=FileSystem 举例,执行如下操作:
- 等待 volume 挂接到节点上(由 External Attacher or Kubelet 本身挂接);
- 挂载 volume 到全局目录:调用 DeviceMounter 的 MountDevice 函数(若为 out-of-tree 则调用 CSI 插件的 NodeStageVolume 接口);
- 更新 ASW:该 volume 已挂载到全局目录;
- bind-mount volume 到 Pod 上:调用 Mounter 的 SetUp 接口(若为 out-of-tree 则调用 CSI 插件的 NodePublishVolume 接口);
- 更新 ASW。
- unmountDetachDevices:确保需要 unmount 的 volumes 被 unmount。遍历一遍所有 ASW 中的 UnmountedVolumes,若其不在 DSW 中(表示 volume 已无需使用),执行如下操作:
- Unmount volume:调用 DeviceUnmounter 的 UnmountDevice 函数(若为 out-of-tree 则调用 CSI 插件的 NodeUnstageVolume 接口);
- 更新 ASW。
源码解析
pv controller
根据存储流程,首先调度后,pv控制器来处理pv和pvc的关系,pv控制器在组件kube-controller-manager中,我们先来看看pv控制器,首先看到pv控制器在kube-controller-manager的注册。
controllers["persistentvolume-binder"] = startPersistentVolumeBinderController
controllers["persistentvolume-expander"] = startVolumeExpandController
分别支持原生的存储和扩展的存储,我们来看对待的初始化函数。
func startPersistentVolumeBinderController(ctx ControllerContext) (http.Handler, bool, error) {
plugins, err := ProbeControllerVolumePlugins(ctx.Cloud, ctx.ComponentConfig.PersistentVolumeBinderController.VolumeConfiguration)
if err != nil {
return nil, true, fmt.Errorf("failed to probe volume plugins when starting persistentvolume controller: %v", err)
}
filteredDialOptions, err := options.ParseVolumeHostFilters(
ctx.ComponentConfig.PersistentVolumeBinderController.VolumeHostCIDRDenylist,
ctx.ComponentConfig.PersistentVolumeBinderController.VolumeHostAllowLocalLoopback)
if err != nil {
return nil, true, err
}
params := persistentvolumecontroller.ControllerParameters{
KubeClient: ctx.ClientBuilder.ClientOrDie("persistent-volume-binder"),
SyncPeriod: ctx.ComponentConfig.PersistentVolumeBinderController.PVClaimBinderSyncPeriod.Duration,
VolumePlugins: plugins,
Cloud: ctx.Cloud,
ClusterName: ctx.ComponentConfig.KubeCloudShared.ClusterName,
VolumeInformer: ctx.InformerFactory.Core().V1().PersistentVolumes(),
ClaimInformer: ctx.InformerFactory.Core().V1().PersistentVolumeClaims(),
ClassInformer: ctx.InformerFactory.Storage().V1().StorageClasses(),
PodInformer: ctx.InformerFactory.Core().V1().Pods(),
NodeInformer: ctx.InformerFactory.Core().V1().Nodes(),
EnableDynamicProvisioning: ctx.ComponentConfig.PersistentVolumeBinderController.VolumeConfiguration.EnableDynamicProvisioning,
FilteredDialOptions: filteredDialOptions,
}
volumeController, volumeControllerErr := persistentvolumecontroller.NewController(params)
if volumeControllerErr != nil {
return nil, true, fmt.Errorf("failed to construct persistentvolume controller: %v", volumeControllerErr)
}
go volumeController.Run(ctx.Stop)
return nil, true, nil
}
创建各种params最后创建结构体PersistentVolumeController
// NewController creates a new PersistentVolume controller
func NewController(p ControllerParameters) (*PersistentVolumeController, error) {
eventRecorder := p.EventRecorder
if eventRecorder == nil {
broadcaster := record.NewBroadcaster()
broadcaster.StartStructuredLogging(0)
broadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: p.KubeClient.CoreV1().Events("")})
eventRecorder = broadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: "persistentvolume-controller"})
}
controller := &PersistentVolumeController{
volumes: newPersistentVolumeOrderedIndex(),
claims: cache.NewStore(cache.DeletionHandlingMetaNamespaceKeyFunc),
kubeClient: p.KubeClient,
eventRecorder: eventRecorder,
runningOperations: goroutinemap.NewGoRoutineMap(true /* exponentialBackOffOnError */),
cloud: p.Cloud,
enableDynamicProvisioning: p.EnableDynamicProvisioning,
clusterName: p.ClusterName,
createProvisionedPVRetryCount: createProvisionedPVRetryCount,
createProvisionedPVInterval: createProvisionedPVInterval,
claimQueue: workqueue.NewNamed("claims"),
volumeQueue: workqueue.NewNamed("volumes"),
resyncPeriod: p.SyncPeriod,
operationTimestamps: metrics.NewOperationStartTimeCache(),
}
...
}
然后初始化volumes的插件,包括hostpath nfs csi等等
// Prober is nil because PV is not aware of Flexvolume.
if err := controller.volumePluginMgr.InitPlugins(p.VolumePlugins, nil /* prober */, controller); err != nil {
return nil, fmt.Errorf("Could not initialize volume plugins for PersistentVolume Controller: %v", err)
}
然后添加volume informer机制
p.VolumeInformer.Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) { controller.enqueueWork(controller.volumeQueue, obj) },
UpdateFunc: func(oldObj, newObj interface{}) { controller.enqueueWork(controller.volumeQueue, newObj) },
DeleteFunc: func(obj interface{}) { controller.enqueueWork(controller.volumeQueue, obj) },
},
)
controller.volumeLister = p.VolumeInformer.Lister()
controller.volumeListerSynced = p.VolumeInformer.Informer().HasSynced
然后添加claim informer机制
p.ClaimInformer.Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) { controller.enqueueWork(controller.claimQueue, obj) },
UpdateFunc: func(oldObj, newObj interface{}) { controller.enqueueWork(controller.claimQueue, newObj) },
DeleteFunc: func(obj interface{}) { controller.enqueueWork(controller.claimQueue, obj) },
},
)
controller.claimLister = p.ClaimInformer.Lister()
controller.claimListerSynced = p.ClaimInformer.Informer().HasSynced
最后添加 storageclas pod node资源 informer机制
controller.classLister = p.ClassInformer.Lister()
controller.classListerSynced = p.ClassInformer.Informer().HasSynced
controller.podLister = p.PodInformer.Lister()
controller.podIndexer = p.PodInformer.Informer().GetIndexer()
controller.podListerSynced = p.PodInformer.Informer().HasSynced
controller.NodeLister = p.NodeInformer.Lister()
controller.NodeListerSynced = p.NodeInformer.Informer().HasSynced
到此NewController调用就结束了,下面调用这个PersistentVolumeController的run函数运行
// Run starts all of this controller's control loops
func (ctrl *PersistentVolumeController) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer ctrl.claimQueue.ShutDown()
defer ctrl.volumeQueue.ShutDown()
klog.Infof("Starting persistent volume controller")
defer klog.Infof("Shutting down persistent volume controller")
if !cache.WaitForNamedCacheSync("persistent volume", stopCh, ctrl.volumeListerSynced, ctrl.claimListerSynced, ctrl.classListerSynced, ctrl.podListerSynced, ctrl.NodeListerSynced) {
return
}
ctrl.initializeCaches(ctrl.volumeLister, ctrl.claimLister)
go wait.Until(ctrl.resync, ctrl.resyncPeriod, stopCh)
go wait.Until(ctrl.volumeWorker, time.Second, stopCh)
go wait.Until(ctrl.claimWorker, time.Second, stopCh)
metrics.Register(ctrl.volumes.store, ctrl.claims, &ctrl.volumePluginMgr)
<-stopCh
}
开启了三个goroutine来定期执行对应的函数
- resysc 定期list pv pvc并加入到队列
- volumeManager 这个我们在之前说过,主要是管理pv的状态迁移
- claimWorker 这个我们在之前说过,主要处理 PVC 的 add / update / delete 相关事件以及 PVC 的状态迁移
我们来看看对应的函数,先看resysc
// resync supplements short resync period of shared informers - we don't want
// all consumers of PV/PVC shared informer to have a short resync period,
// therefore we do our own.
func (ctrl *PersistentVolumeController) resync() {
klog.V(4).Infof("resyncing PV controller")
pvcs, err := ctrl.claimLister.List(labels.NewSelector())
if err != nil {
klog.Warningf("cannot list claims: %s", err)
return
}
for _, pvc := range pvcs {
ctrl.enqueueWork(ctrl.claimQueue, pvc)
}
pvs, err := ctrl.volumeLister.List(labels.NewSelector())
if err != nil {
klog.Warningf("cannot list persistent volumes: %s", err)
return
}
for _, pv := range pvs {
ctrl.enqueueWork(ctrl.volumeQueue, pv)
}
}
可见就是获取pvcs,pvs,最后放到对应的队列中处理。我们再来看看volumeManager
// volumeWorker processes items from volumeQueue. It must run only once,
// syncVolume is not assured to be reentrant.
func (ctrl *PersistentVolumeController) volumeWorker() {
workFunc := func() bool {
keyObj, quit := ctrl.volumeQueue.Get()
if quit {
return true
}
defer ctrl.volumeQueue.Done(keyObj)
key := keyObj.(string)
klog.V(5).Infof("volumeWorker[%s]", key)
_, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
klog.V(4).Infof("error getting name of volume %q to get volume from informer: %v", key, err)
return false
}
volume, err := ctrl.volumeLister.Get(name)
if err == nil {
// The volume still exists in informer cache, the event must have
// been add/update/sync
ctrl.updateVolume(volume)
return false
}
if !errors.IsNotFound(err) {
klog.V(2).Infof("error getting volume %q from informer: %v", key, err)
return false
}
// The volume is not in informer cache, the event must have been
// "delete"
volumeObj, found, err := ctrl.volumes.store.GetByKey(key)
if err != nil {
klog.V(2).Infof("error getting volume %q from cache: %v", key, err)
return false
}
if !found {
// The controller has already processed the delete event and
// deleted the volume from its cache
klog.V(2).Infof("deletion of volume %q was already processed", key)
return false
}
volume, ok := volumeObj.(*v1.PersistentVolume)
if !ok {
klog.Errorf("expected volume, got %+v", volumeObj)
return false
}
ctrl.deleteVolume(volume)
return false
}
for {
if quit := workFunc(); quit {
klog.Infof("volume worker queue shutting down")
return
}
}
}
从队列取进行处理,未有就退出等待下一个周期在处理,如果有则 updateVolume 更新操作,可能包括 add update sync 等操作,处理并删除队列,具体处理的逻辑在上面已经说过,我们简单看一下
extrenal provisioner[todo]
csi插件[todo]
AD controller
AD Controller中核心部件包括两个缓存,一个populator,一个reconciler,一个status updater。
两个缓存分别是desired status和actual status,分别代表跟attach/detach相关对象模型的期望状态和实际状态。 reconciler通过定期比较期望状态和实际状态来决定是执行attach,还是detach,还是什么都不做。 populator负责定期从API Server同步相关模型值到期望状态缓存中。 status updater负责node的状态刷新,这里主要是当有卷做完attach/detach操作后,从记录实际状态缓存中获取每个node已经attach的卷信息,向API Server同步node.Status.VolumesAttached,通过这个状态Kubelet才知道AD Controller是否已经完成attach操作。详细代码查看这里,结构见下图:
核心的逻辑部件有一定了解之后,再梳理下它的逻辑。对于AD Controller来讲,它的核心职责就是当API Server中,有卷声明的pod与node间的关系发生变化时,需要决定是通过调用存储插件将这个pod关联的卷attach到对应node的主机(或者虚拟机)上,还是将卷从node上detach掉,这里的关系变化可能是pod调度某个node上,也可能是某个pod在node上终止掉了,所以它需要做这几件事情:
监控API Server 中的pod和node。 监控当前各个node上卷的实际attach状态。 通过对比API Server中pod和node的状态变化以及node上的实际attach状态来决定做attach、detach操作。 调用相应的卷插件执行attach,detach操作。 操作完成后,通知其它关联组件(这里主要是kubelet)做相应的业务操作。
external-attacher[todo]
kubelet[todo]
开发csi插件
基本概念
csi插件的实现,官方已经封装好的lib,我们只要实现对应的接口就可以了,目前我们可以实现的插件有两种类型,如下:
- Controller Plugin,负责存储对象(Volume)的生命周期管理,在集群中仅需要有一个即可;
- Node Plugin,在必要时与使用 Volume 的容器所在的节点交互,提供诸如节点上的 Volume 挂载/卸载等动作支持,如有需要则在每个服务节点上均部署。
官方提供了rpc接口实现上面两个插件,如下:
- 身份服务:Node Plugin和Controller Plugin都必须实现这些RPC集。
- GetPluginInfo, 获取 Plugin 基本信息
- GetPluginCapabilities,获取 Plugin 支持的能力
- Probe,探测 Plugin 的健康状态
- 控制器服务:Controller Plugin必须实现这些RPC集。CSI Controller 服务里定义的这些操作有个共同特点,那就是它们都无需在宿主机上进行,而是属于 Kubernetes 里 Volume Controller 的逻辑,也就是属于 Master 节点的一部分。需要注意的是,正如我在前面提到的那样,CSI Controller 服务的实际调用者,并不是 Kubernetes(即:通过 pkg/volume/csi 发起 CSI 请求),而是 External Provisioner 和 External Attacher。这两个 External Components,分别通过监听 PVC 和 VolumeAttachement 对象,来跟 Kubernetes 进行协作。
- Volume CRUD,包括了扩容和容量探测等 Volume 状态检查与操作接口
- Controller Publish/Unpublish Volume ,也就是对 CSI Volume 进行 Attach/Dettach,还包括Node 对 Volume 的访问权限管理
- Snapshot CRD,快照的创建和删除操作,目前 CSI 定义的 Snapshot 仅用于创建 Volume,未提供回滚的语义
- 节点服务:Node Plugin必须实现这些RPC集。CSI Volume 需要在宿主机上执行的操作,都定义在了 CSI Node 服务里面
- Node Stage/Unstage/Publish/Unpublish/GetStats Volume,节点上 Volume 的连接状态管理,也就是mount是由 NodeStageVolume 和 NodePublishVolume 两个接口共同实现的。
- Node Expand Volume, 节点上的 Volume 扩容操作,在 volume 逻辑大小扩容之后,可能还需要同步的扩容 Volume 之上的文件系统并让使用 Volume 的 Container 感知到,所以在 Node Plugin 上需要有对应的接口
- Node Get Capabilities/Info, Plugin 的基础属性与 Node 的属性查询
CSI 插件的三部分 CSI Identity , CSI Controller , CSI Node 可放在同一个二进制程序中实现。就是我们常见的插件,当然针对不同的存储,可以只实现一种类型就可以。
对应的rpc定义可以看源码,简单的看一下对应的定义
service Identity {
rpc GetPluginInfo(GetPluginInfoRequest)
returns (GetPluginInfoResponse) {}
rpc GetPluginCapabilities(GetPluginCapabilitiesRequest)
returns (GetPluginCapabilitiesResponse) {}
rpc Probe (ProbeRequest)
returns (ProbeResponse) {}
}
service Controller {
rpc CreateVolume (CreateVolumeRequest)
returns (CreateVolumeResponse) {}
rpc DeleteVolume (DeleteVolumeRequest)
returns (DeleteVolumeResponse) {}
rpc ControllerPublishVolume (ControllerPublishVolumeRequest)
returns (ControllerPublishVolumeResponse) {}
rpc ControllerUnpublishVolume (ControllerUnpublishVolumeRequest)
returns (ControllerUnpublishVolumeResponse) {}
rpc ValidateVolumeCapabilities (ValidateVolumeCapabilitiesRequest)
returns (ValidateVolumeCapabilitiesResponse) {}
rpc ListVolumes (ListVolumesRequest)
returns (ListVolumesResponse) {}
rpc GetCapacity (GetCapacityRequest)
returns (GetCapacityResponse) {}
rpc ControllerGetCapabilities (ControllerGetCapabilitiesRequest)
returns (ControllerGetCapabilitiesResponse) {}
rpc CreateSnapshot (CreateSnapshotRequest)
returns (CreateSnapshotResponse) {}
rpc DeleteSnapshot (DeleteSnapshotRequest)
returns (DeleteSnapshotResponse) {}
rpc ListSnapshots (ListSnapshotsRequest)
returns (ListSnapshotsResponse) {}
rpc ControllerExpandVolume (ControllerExpandVolumeRequest)
returns (ControllerExpandVolumeResponse) {}
rpc ControllerGetVolume (ControllerGetVolumeRequest)
returns (ControllerGetVolumeResponse) {
option (alpha_method) = true;
}
}
service Node {
rpc NodeStageVolume (NodeStageVolumeRequest)
returns (NodeStageVolumeResponse) {}
rpc NodeUnstageVolume (NodeUnstageVolumeRequest)
returns (NodeUnstageVolumeResponse) {}
rpc NodePublishVolume (NodePublishVolumeRequest)
returns (NodePublishVolumeResponse) {}
rpc NodeUnpublishVolume (NodeUnpublishVolumeRequest)
returns (NodeUnpublishVolumeResponse) {}
rpc NodeGetVolumeStats (NodeGetVolumeStatsRequest)
returns (NodeGetVolumeStatsResponse) {}
rpc NodeExpandVolume(NodeExpandVolumeRequest)
returns (NodeExpandVolumeResponse) {}
rpc NodeGetCapabilities (NodeGetCapabilitiesRequest)
returns (NodeGetCapabilitiesResponse) {}
rpc NodeGetInfo (NodeGetInfoRequest)
returns (NodeGetInfoResponse) {}
}
这些接口都定义在csi的spec的lib中,所以我们开发的时候会引用这个库,我们只要实现这些接口就可以实现csi的基本插件功能。
我们在来看一下我们说的组件和这个rpc是怎么个关系
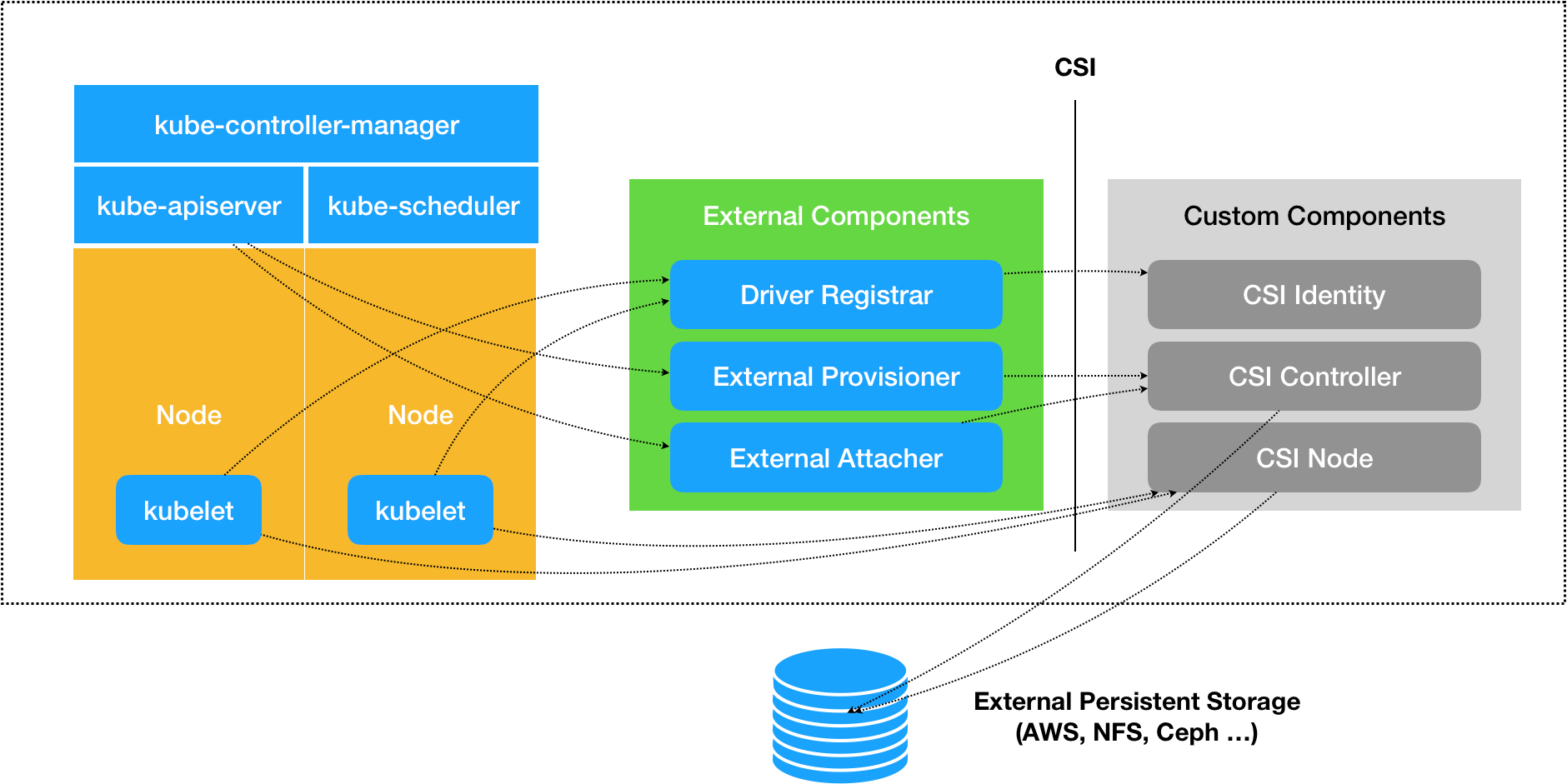
- Driver Registrar 组件,负责将插件注册到 kubelet 里面(这可以类比为,将可执行文件放在插件目录下)。而在具体实现上,Driver Registrar 需要请求 CSI 插件的 Identity 服务来获取插件信息。
- External Provisioner 组件,负责的正是 Provision 阶段。在具体实现上,External Provisioner 监听(Watch)了 APIServer 里的 PVC 对象。当一个 PVC 被创建时,它就会调用 CSI Controller 的 CreateVolume 方法,为你创建对应 PV。
- External Attacher 组件,负责的正是“Attach 阶段”。在具体实现上,它监听了 APIServer 里 VolumeAttachment 对象的变化。VolumeAttachment 对象是 Kubernetes 确认一个 Volume 可以进入“Attach 阶段”的重要标志。一旦出现了 VolumeAttachment 对象,External Attacher 就会调用 CSI Controller 服务的 ControllerPublish 方法,完成它所对应的 Volume 的 Attach 阶段。
- Volume 的“Mount 阶段”,并不属于 External Components 的职责。当 kubelet 的 VolumeManagerReconciler 控制循环检查到它需要执行 Mount 操作的时候,会通过 pkg/volume/csi 包,直接调用 CSI Node 服务完成 Volume 的“Mount 阶段”。
实例
csi-driver-host-path 是社区实现的一个 CSI 插件的示例,它以 hostpath 为后端存储,kubernetes 通过这个 CSI 插件 driver 来对接 hostpath ,管理本地 Node 节点上的存储卷。我们以这个为例子,来看看如何编写一个csi插件。
目录结构
├── hostpath
│ ├── controllerserver.go
│ ├── nodeserver.go
│ ├── nodeserver_test.go
│ ├── hostpath.go
│ └── utils.go
│ └── identityserver.go
- controllerserver.go主要是实现controller的rpc接口
- nodeserver.go主要是实现node的rpc接口
- utils.go基本公用函数
- hostpath.go入口,启动rpc服务,只要把编写好的 gRPC Server 注册给 CSI,它就可以响应来自 External Components 的 CSI 请求了。
- identityserver.go身份验证的rpc接口
启动rpc服务
首先肯定是定一个结构体包含plugin启动的所需信息
type hostPath struct {
driver *csicommon.CSIDriver
ids *identityServer
ns *nodeServer
cs *controllerServer
cap []*csi.VolumeCapability_AccessMode
cscap []*csi.ControllerServiceCapability
}
简单的介绍一下这个结构体
- csicommon.CSIDriver:k8s自定义代表插件的结构体, 初始化的时候需要指定插件的RPC功能和支持的读写模式
- endpoint:插件的监听地址,一般的,我们测试的时候可以用tcp方式进行,比如
tcp://127.0.0.1:10000,最后在k8s中部署的时候一般使用unix方式:/csi/csi.sock - csicommon.DefaultIdentityServer: 认证服务一般不需要特别实现,使用k8s公共部分的即可
- controllerServer: 实现CSI中的controller服务的RPC功能,继承后可以选择性覆盖部分方法
- nodeServer: 实现CSI中的node服务的RPC功能,继承后可以选择性覆盖部分方法
然后就是调用这个结构体的run方法,该方法中调用csicommon的公共方法启动socket监听
func (hp *hostPath) Run(driverName, nodeID, endpoint string) {
glog.Infof("Driver: %v ", driverName)
glog.Infof("Version: %s", vendorVersion)
// Initialize default library driver
hp.driver = csicommon.NewCSIDriver(driverName, vendorVersion, nodeID)
if hp.driver == nil {
glog.Fatalln("Failed to initialize CSI Driver.")
}
hp.driver.AddControllerServiceCapabilities(
[]csi.ControllerServiceCapability_RPC_Type{
csi.ControllerServiceCapability_RPC_CREATE_DELETE_VOLUME,
csi.ControllerServiceCapability_RPC_CREATE_DELETE_SNAPSHOT,
csi.ControllerServiceCapability_RPC_LIST_SNAPSHOTS,
})
hp.driver.AddVolumeCapabilityAccessModes([]csi.VolumeCapability_AccessMode_Mode{csi.VolumeCapability_AccessMode_SINGLE_NODE_WRITER})
// Create GRPC servers
hp.ids = NewIdentityServer(hp.driver)
hp.ns = NewNodeServer(hp.driver)
hp.cs = NewControllerServer(hp.driver)
s := csicommon.NewNonBlockingGRPCServer()
s.Start(endpoint, hp.ids, hp.cs, hp.ns)
s.Wait()
}
start来启动grpc服务来给对应的客户端进行调用
func (s *nonBlockingGRPCServer) serve(endpoint string, ids csi.IdentityServer, cs csi.ControllerServer, ns csi.NodeServer) {
proto, addr, err := parseEndpoint(endpoint)
if err != nil {
glog.Fatal(err.Error())
}
if proto == "unix" {
addr = "/" + addr
if err := os.Remove(addr); err != nil && !os.IsNotExist(err) { //nolint: vetshadow
glog.Fatalf("Failed to remove %s, error: %s", addr, err.Error())
}
}
listener, err := net.Listen(proto, addr)
if err != nil {
glog.Fatalf("Failed to listen: %v", err)
}
opts := []grpc.ServerOption{
grpc.UnaryInterceptor(logGRPC),
}
server := grpc.NewServer(opts...)
s.server = server
if ids != nil {
csi.RegisterIdentityServer(server, ids)
}
if cs != nil {
csi.RegisterControllerServer(server, cs)
}
if ns != nil {
csi.RegisterNodeServer(server, ns)
}
glog.Infof("Listening for connections on address: %#v", listener.Addr())
server.Serve(listener)
}
实现CSI Identity
然后就是对应接口的实现,先看CSI Identity 用于认证driver的身份信息,上面提到的 kubernetes 外部组件调用,返回 CSI driver 的身份信息和健康状态。
func NewIdentityServer(name, version string) *identityServer {
return &identityServer{
name: name,
version: version,
}
}
func (ids *identityServer) GetPluginInfo(ctx context.Context, req *csi.GetPluginInfoRequest) (*csi.GetPluginInfoResponse, error) {
glog.V(5).Infof("Using default GetPluginInfo")
if ids.name == "" {
return nil, status.Error(codes.Unavailable, "Driver name not configured")
}
if ids.version == "" {
return nil, status.Error(codes.Unavailable, "Driver is missing version")
}
return &csi.GetPluginInfoResponse{
Name: ids.name,
VendorVersion: ids.version,
}, nil
}
func (ids *identityServer) Probe(ctx context.Context, req *csi.ProbeRequest) (*csi.ProbeResponse, error) {
return &csi.ProbeResponse{}, nil
}
func (ids *identityServer) GetPluginCapabilities(ctx context.Context, req *csi.GetPluginCapabilitiesRequest) (*csi.GetPluginCapabilitiesResponse, error) {
glog.V(5).Infof("Using default capabilities")
return &csi.GetPluginCapabilitiesResponse{
Capabilities: []*csi.PluginCapability{
{
Type: &csi.PluginCapability_Service_{
Service: &csi.PluginCapability_Service{
Type: csi.PluginCapability_Service_CONTROLLER_SERVICE,
},
},
},
},
}, nil
}
其中name就是我们每次在sc中声明的csi插件的值,Kubernetes 正是通过 GetPluginInfo 的返回值,来找到你在 StorageClass 里声明要使用的 CSI 插件的。
另外一个 GetPluginCapabilities 接口也很重要。这个接口返回的是这个 CSI 插件的“能力”。比如,当你编写的 CSI 插件不准备实现“Provision 阶段”和“Attach 阶段”(比如,一个最简单的 NFS 存储插件就不需要这两个阶段)时,你就可以通过这个接口返回:本插件不提供 CSI Controller 服务,即:没有 csi.PluginCapability_Service_CONTROLLER_SERVICE 这个“能力”。这样,Kubernetes 就知道这个信息了。
最后,CSI Identity 服务还提供了一个 Probe 接口。Kubernetes 会调用它来检查这个 CSI 插件是否正常工作。一般情况下,我建议你在编写插件时给它设置一个 Ready 标志,当插件的 gRPC Server 停止的时候,把这个 Ready 标志设置为 false。或者,你可以在这里访问一下插件的端口,类似于健康检查的做法。
实现CSI Controller
再来看看CSI Controller 主要实现 Volume 管理流程当中的 “Provision” 和 “Attach” 阶段。”Provision” 阶段是指创建和删除 Volume 的流程,而 “Attach” 阶段是指把存储卷附着在某个 Node 或脱离某个 Node 的流程。只有块存储类型的 CSI 插件才需要 “Attach” 功能。
func NewControllerServer(ephemeral bool) *controllerServer {
if ephemeral {
return &controllerServer{caps: getControllerServiceCapabilities(nil)}
}
return &controllerServer{
caps: getControllerServiceCapabilities(
[]csi.ControllerServiceCapability_RPC_Type{
csi.ControllerServiceCapability_RPC_CREATE_DELETE_VOLUME,
csi.ControllerServiceCapability_RPC_CREATE_DELETE_SNAPSHOT,
csi.ControllerServiceCapability_RPC_LIST_SNAPSHOTS,
}),
}
}
func (cs *controllerServer) CreateVolume(ctx context.Context, req *csi.CreateVolumeRequest) (*csi.CreateVolumeResponse, error) {
if err := cs.validateControllerServiceRequest(csi.ControllerServiceCapability_RPC_CREATE_DELETE_VOLUME); err != nil {
glog.V(3).Infof("invalid create volume req: %v", req)
return nil, err
}
// Check arguments
if len(req.GetName()) == 0 {
return nil, status.Error(codes.InvalidArgument, "Name missing in request")
}
caps := req.GetVolumeCapabilities()
if caps == nil {
return nil, status.Error(codes.InvalidArgument, "Volume Capabilities missing in request")
}
// Keep a record of the requested access types.
var accessTypeMount, accessTypeBlock bool
for _, cap := range caps {
if cap.GetBlock() != nil {
accessTypeBlock = true
}
if cap.GetMount() != nil {
accessTypeMount = true
}
}
// A real driver would also need to check that the other
// fields in VolumeCapabilities are sane. The check above is
// just enough to pass the "[Testpattern: Dynamic PV (block
// volmode)] volumeMode should fail in binding dynamic
// provisioned PV to PVC" storage E2E test.
if accessTypeBlock && accessTypeMount {
return nil, status.Error(codes.InvalidArgument, "cannot have both block and mount access type")
}
var requestedAccessType accessType
if accessTypeBlock {
requestedAccessType = blockAccess
} else {
// Default to mount.
requestedAccessType = mountAccess
}
// Check for maximum available capacity
capacity := int64(req.GetCapacityRange().GetRequiredBytes())
if capacity >= maxStorageCapacity {
return nil, status.Errorf(codes.OutOfRange, "Requested capacity %d exceeds maximum allowed %d", capacity, maxStorageCapacity)
}
// Need to check for already existing volume name, and if found
// check for the requested capacity and already allocated capacity
if exVol, err := getVolumeByName(req.GetName()); err == nil {
// Since err is nil, it means the volume with the same name already exists
// need to check if the size of exisiting volume is the same as in new
// request
if exVol.VolSize >= int64(req.GetCapacityRange().GetRequiredBytes()) {
// exisiting volume is compatible with new request and should be reused.
// TODO (sbezverk) Do I need to make sure that RBD volume still exists?
return &csi.CreateVolumeResponse{
Volume: &csi.Volume{
VolumeId: exVol.VolID,
CapacityBytes: int64(exVol.VolSize),
VolumeContext: req.GetParameters(),
},
}, nil
}
return nil, status.Error(codes.AlreadyExists, fmt.Sprintf("Volume with the same name: %s but with different size already exist", req.GetName()))
}
volumeID := uuid.NewUUID().String()
path := getVolumePath(volumeID)
if requestedAccessType == blockAccess {
executor := utilexec.New()
size := fmt.Sprintf("%dM", capacity/mib)
// Create a block file.
out, err := executor.Command("fallocate", "-l", size, path).CombinedOutput()
if err != nil {
glog.V(3).Infof("failed to create block device: %v", string(out))
return nil, err
}
// Associate block file with the loop device.
volPathHandler := volumepathhandler.VolumePathHandler{}
_, err = volPathHandler.AttachFileDevice(path)
if err != nil {
glog.Errorf("failed to attach device: %v", err)
// Remove the block file because it'll no longer be used again.
if err2 := os.Remove(path); err != nil {
glog.Errorf("failed to cleanup block file %s: %v", path, err2)
}
return nil, status.Error(codes.Internal, fmt.Sprintf("failed to attach device: %v", err))
}
}
vol, err := createHostpathVolume(volumeID, req.GetName(), capacity, requestedAccessType)
if err != nil {
return nil, status.Error(codes.Internal, fmt.Sprintf("failed to create volume: %s", err))
}
glog.V(4).Infof("created volume %s at path %s", vol.VolID, vol.VolPath)
if req.GetVolumeContentSource() != nil {
contentSource := req.GetVolumeContentSource()
if contentSource.GetSnapshot() != nil {
snapshotId := contentSource.GetSnapshot().GetSnapshotId()
snapshot, ok := hostPathVolumeSnapshots[snapshotId]
if !ok {
return nil, status.Errorf(codes.NotFound, "cannot find snapshot %v", snapshotId)
}
if snapshot.ReadyToUse != true {
return nil, status.Errorf(codes.Internal, "Snapshot %v is not yet ready to use.", snapshotId)
}
snapshotPath := snapshot.Path
args := []string{"zxvf", snapshotPath, "-C", path}
executor := utilexec.New()
out, err := executor.Command("tar", args...).CombinedOutput()
if err != nil {
return nil, status.Error(codes.Internal, fmt.Sprintf("failed pre-populate data for volume: %v: %s", err, out))
}
}
}
return &csi.CreateVolumeResponse{
Volume: &csi.Volume{
VolumeId: volumeID,
CapacityBytes: req.GetCapacityRange().GetRequiredBytes(),
VolumeContext: req.GetParameters(),
},
}, nil
}
func (cs *controllerServer) DeleteVolume(ctx context.Context, req *csi.DeleteVolumeRequest) (*csi.DeleteVolumeResponse, error) {
// Check arguments
if len(req.GetVolumeId()) == 0 {
return nil, status.Error(codes.InvalidArgument, "Volume ID missing in request")
}
if err := cs.validateControllerServiceRequest(csi.ControllerServiceCapability_RPC_CREATE_DELETE_VOLUME); err != nil {
glog.V(3).Infof("invalid delete volume req: %v", req)
return nil, err
}
vol, err := getVolumeByID(req.GetVolumeId())
if err != nil {
// Return OK if the volume is not found.
return &csi.DeleteVolumeResponse{}, nil
}
glog.V(4).Infof("deleting volume %s", vol.VolID)
if vol.VolAccessType == blockAccess {
volPathHandler := volumepathhandler.VolumePathHandler{}
// Get the associated loop device.
device, err := volPathHandler.GetLoopDevice(getVolumePath(vol.VolID))
if err != nil {
return nil, status.Error(codes.Internal, fmt.Sprintf("failed to get the loop device: %v", err))
}
if device != "" {
// Remove any associated loop device.
glog.V(4).Infof("deleting loop device %s", device)
if err := volPathHandler.RemoveLoopDevice(device); err != nil {
return nil, status.Error(codes.Internal, fmt.Sprintf("failed to remove loop device: %v", err))
}
}
}
if err := deleteHostpathVolume(vol.VolID); err != nil && !os.IsNotExist(err) {
return nil, status.Error(codes.Internal, fmt.Sprintf("failed to delete volume: %s", err))
}
glog.V(4).Infof("volume deleted ok: %s", vol.VolID)
return &csi.DeleteVolumeResponse{}, nil
}
其中,CreateVolume 和 DeleteVolume 是实现 “Provision” 阶段需要实现的接口,External provisioner 组件会 CSI 插件的这个接口以创建或者删除存储卷。
CreateVolume其实就是调用对应存储的api来创建一个存储卷,如果你使用的是其他类型的块存储(比如 Cinder、Ceph RBD 等),对应的操作也是类似地调用创建存储卷的 API。
ControllerPublishVolume 和 ControllerUnpublishVolume 是实现 “Attach” 阶段需要实现的接口,External attach 组件会调用 CSI 插件实现的这个接口以把某个块存储卷附着或脱离某个 Node 。
ControllerPublishVolume其实就是调用对应的存储的api将某个块存储卷附着某个 Node。
如果想扩展 CSI 的功能,可以实现更多功能的接口,如快照功能的接口 CreateSnapshot 和 DeleteSnapshot。
实现CSI Node
最后再来看看CSI Node 部分主要负责 Volume 管理流程当中的 “Mount” 阶段,即把 Volume 挂载至 Pod 容器,或者从 Pod 中卸载 Volume 。在宿主机 Node 上需要执行的操作都包含在这个部分。
func NewNodeServer(nodeId string, ephemeral bool) *nodeServer {
return &nodeServer{
nodeID: nodeId,
ephemeral: ephemeral,
}
}
func (ns *nodeServer) NodePublishVolume(ctx context.Context, req *csi.NodePublishVolumeRequest) (*csi.NodePublishVolumeResponse, error) {
// Check arguments
if req.GetVolumeCapability() == nil {
return nil, status.Error(codes.InvalidArgument, "Volume capability missing in request")
}
if len(req.GetVolumeId()) == 0 {
return nil, status.Error(codes.InvalidArgument, "Volume ID missing in request")
}
if len(req.GetTargetPath()) == 0 {
return nil, status.Error(codes.InvalidArgument, "Target path missing in request")
}
targetPath := req.GetTargetPath()
if req.GetVolumeCapability().GetBlock() != nil &&
req.GetVolumeCapability().GetMount() != nil {
return nil, status.Error(codes.InvalidArgument, "cannot have both block and mount access type")
}
// if ephemeral is specified, create volume here to avoid errors
if ns.ephemeral {
volID := req.GetVolumeId()
volName := fmt.Sprintf("ephemeral-%s", volID)
vol, err := createHostpathVolume(req.GetVolumeId(), volName, maxStorageCapacity, mountAccess)
if err != nil && !os.IsExist(err) {
glog.Error("ephemeral mode failed to create volume: ", err)
return nil, status.Error(codes.Internal, err.Error())
}
glog.V(4).Infof("ephemeral mode: created volume: %s", vol.VolPath)
}
vol, err := getVolumeByID(req.GetVolumeId())
if err != nil {
return nil, status.Error(codes.NotFound, err.Error())
}
if req.GetVolumeCapability().GetBlock() != nil {
if vol.VolAccessType != blockAccess {
return nil, status.Error(codes.InvalidArgument, "cannot publish a non-block volume as block volume")
}
volPathHandler := volumepathhandler.VolumePathHandler{}
// Get loop device from the volume path.
loopDevice, err := volPathHandler.GetLoopDevice(vol.VolPath)
if err != nil {
return nil, status.Error(codes.Internal, fmt.Sprintf("failed to get the loop device: %v", err))
}
mounter := mount.New("")
// Check if the target path exists. Create if not present.
_, err = os.Lstat(targetPath)
if os.IsNotExist(err) {
if err = mounter.MakeFile(targetPath); err != nil {
return nil, status.Error(codes.Internal, fmt.Sprintf("failed to create target path: %s: %v", targetPath, err))
}
}
if err != nil {
return nil, status.Errorf(codes.Internal, "failed to check if the target block file exists: %v", err)
}
// Check if the target path is already mounted. Prevent remounting.
notMount, err := mounter.IsNotMountPoint(targetPath)
if err != nil {
if !os.IsNotExist(err) {
return nil, status.Errorf(codes.Internal, "error checking path %s for mount: %s", targetPath, err)
}
notMount = true
}
if !notMount {
// It's already mounted.
glog.V(5).Infof("Skipping bind-mounting subpath %s: already mounted", targetPath)
return &csi.NodePublishVolumeResponse{}, nil
}
options := []string{"bind"}
if err := mount.New("").Mount(loopDevice, targetPath, "", options); err != nil {
return nil, status.Error(codes.Internal, fmt.Sprintf("failed to mount block device: %s at %s: %v", loopDevice, targetPath, err))
}
} else if req.GetVolumeCapability().GetMount() != nil {
if vol.VolAccessType != mountAccess {
return nil, status.Error(codes.InvalidArgument, "cannot publish a non-mount volume as mount volume")
}
notMnt, err := mount.New("").IsLikelyNotMountPoint(targetPath)
if err != nil {
if os.IsNotExist(err) {
if err = os.MkdirAll(targetPath, 0750); err != nil {
return nil, status.Error(codes.Internal, err.Error())
}
notMnt = true
} else {
return nil, status.Error(codes.Internal, err.Error())
}
}
if !notMnt {
return &csi.NodePublishVolumeResponse{}, nil
}
fsType := req.GetVolumeCapability().GetMount().GetFsType()
deviceId := ""
if req.GetPublishContext() != nil {
deviceId = req.GetPublishContext()[deviceID]
}
readOnly := req.GetReadonly()
volumeId := req.GetVolumeId()
attrib := req.GetVolumeContext()
mountFlags := req.GetVolumeCapability().GetMount().GetMountFlags()
glog.V(4).Infof("target %v\nfstype %v\ndevice %v\nreadonly %v\nvolumeId %v\nattributes %v\nmountflags %v\n",
targetPath, fsType, deviceId, readOnly, volumeId, attrib, mountFlags)
options := []string{"bind"}
if readOnly {
options = append(options, "ro")
}
mounter := mount.New("")
path := getVolumePath(volumeId)
if err := mounter.Mount(path, targetPath, "", options); err != nil {
var errList strings.Builder
errList.WriteString(err.Error())
if ns.ephemeral {
if rmErr := os.RemoveAll(path); rmErr != nil && !os.IsNotExist(rmErr) {
errList.WriteString(fmt.Sprintf(" :%s", rmErr.Error()))
}
}
}
}
return &csi.NodePublishVolumeResponse{}, nil
}
func (ns *nodeServer) NodeUnpublishVolume(ctx context.Context, req *csi.NodeUnpublishVolumeRequest) (*csi.NodeUnpublishVolumeResponse, error) {
// Check arguments
if len(req.GetVolumeId()) == 0 {
return nil, status.Error(codes.InvalidArgument, "Volume ID missing in request")
}
if len(req.GetTargetPath()) == 0 {
return nil, status.Error(codes.InvalidArgument, "Target path missing in request")
}
targetPath := req.GetTargetPath()
volumeID := req.GetVolumeId()
vol, err := getVolumeByID(volumeID)
if err != nil {
return nil, status.Error(codes.NotFound, err.Error())
}
switch vol.VolAccessType {
case blockAccess:
// Unmount and delete the block file.
err = mount.New("").Unmount(targetPath)
if err != nil {
return nil, status.Error(codes.Internal, err.Error())
}
if err = os.RemoveAll(targetPath); err != nil {
return nil, status.Error(codes.Internal, err.Error())
}
glog.V(4).Infof("hostpath: volume %s has been unpublished.", targetPath)
case mountAccess:
// Unmounting the image
err = mount.New("").Unmount(req.GetTargetPath())
if err != nil {
return nil, status.Error(codes.Internal, err.Error())
}
glog.V(4).Infof("hostpath: volume %s/%s has been unmounted.", targetPath, volumeID)
}
if ns.ephemeral {
glog.V(4).Infof("deleting volume %s", volumeID)
if err := deleteHostpathVolume(volumeID); err != nil && !os.IsNotExist(err) {
return nil, status.Error(codes.Internal, fmt.Sprintf("failed to delete volume: %s", err))
}
}
return &csi.NodeUnpublishVolumeResponse{}, nil
}
func (ns *nodeServer) NodeStageVolume(ctx context.Context, req *csi.NodeStageVolumeRequest) (*csi.NodeStageVolumeResponse, error) {
// Check arguments
if len(req.GetVolumeId()) == 0 {
return nil, status.Error(codes.InvalidArgument, "Volume ID missing in request")
}
if len(req.GetStagingTargetPath()) == 0 {
return nil, status.Error(codes.InvalidArgument, "Target path missing in request")
}
if req.GetVolumeCapability() == nil {
return nil, status.Error(codes.InvalidArgument, "Volume Capability missing in request")
}
return &csi.NodeStageVolumeResponse{}, nil
}
func (ns *nodeServer) NodeUnstageVolume(ctx context.Context, req *csi.NodeUnstageVolumeRequest) (*csi.NodeUnstageVolumeResponse, error) {
// Check arguments
if len(req.GetVolumeId()) == 0 {
return nil, status.Error(codes.InvalidArgument, "Volume ID missing in request")
}
if len(req.GetStagingTargetPath()) == 0 {
return nil, status.Error(codes.InvalidArgument, "Target path missing in request")
}
return &csi.NodeUnstageVolumeResponse{}, nil
}
kubelet 会调用 CSI 插件实现的接口,以实现 volume 的挂载和卸载。
其中 Volume 的挂载被分成了 NodeStageVolume 和 NodePublishVolume 两个阶段。NodeStageVolume 接口主要是针对块存储类型的 CSI 插件而提供的。 块设备在 “Attach” 阶段被附着在 Node 上后,需要挂载至 Pod 对应目录上,但因为块设备在 linux 上只能 mount 一次,而在 kubernetes volume 的使用场景中,一个 volume 可能被挂载进同一个 Node 上的多个 Pod 实例中,所以这里提供了 NodeStageVolume 这个接口,使用这个接口把块设备格式化后先挂载至 Node 上的一个临时全局目录,然后再调用 NodePublishVolume 使用 linux 中的 bind mount 技术把这个全局目录挂载进 Pod 中对应的目录上。
其实就是我们首先需要格式化这个设备,然后才能把它挂载到 Volume 对应的宿主机目录上,所以需要NodeStageVolume。
NodeUnstageVolume 和 NodeUnpublishVolume 正是 volume 卸载阶段所分别对应的上述两个流程。从上述代码中可以看到,因为 hostpath 非块存储类型的第三方存储,所以没有实现 NodeStageVolume 和 NodeUnstageVolume 这两个接口。
当然,如果是非块存储类型的 CSI 插件,也就不必实现 NodeStageVolume 和 NodeUnstageVolume 这两个接口了。
到这里一个完整的csi插件就开发完成,大体都是这些流程,只要实现对应的rpc接口逻辑就好。