Kubernetes 项目的核心原理,就是“控制器模式”。
kube-controller-manager
controller-manager是管理器的控制者,使用是集群管理控制中心,内部对应控制器如下
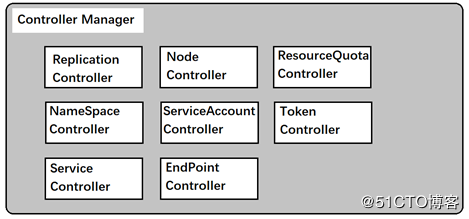
他们通过API Server提供的接口实时监控整个集群里的每一个资源对象的当前状态,当发生各种故障导致系统状态发生变化,这些controller会尝试将系统从“现有装态”修正到“期望状态”。
在controller manager启动的时候会遍历所有的controller,执行初始化函数,那么一共支持多少controller?我们可以重代码注册中看到,代码位置:cmd/kube-controller-manager/app/coontrollermanager.go:387
func NewControllerInitializers(loopMode ControllerLoopMode) map[string]InitFunc {
controllers := map[string]InitFunc{}
controllers["endpoint"] = startEndpointController
controllers["endpointslice"] = startEndpointSliceController
controllers["endpointslicemirroring"] = startEndpointSliceMirroringController
controllers["replicationcontroller"] = startReplicationController
controllers["podgc"] = startPodGCController
controllers["resourcequota"] = startResourceQuotaController
controllers["namespace"] = startNamespaceController
controllers["serviceaccount"] = startServiceAccountController
controllers["garbagecollector"] = startGarbageCollectorController
controllers["daemonset"] = startDaemonSetController
controllers["job"] = startJobController
controllers["deployment"] = startDeploymentController
controllers["replicaset"] = startReplicaSetController
controllers["horizontalpodautoscaling"] = startHPAController
controllers["disruption"] = startDisruptionController
controllers["statefulset"] = startStatefulSetController
controllers["cronjob"] = startCronJobController
controllers["csrsigning"] = startCSRSigningController
controllers["csrapproving"] = startCSRApprovingController
controllers["csrcleaner"] = startCSRCleanerController
controllers["ttl"] = startTTLController
controllers["bootstrapsigner"] = startBootstrapSignerController
controllers["tokencleaner"] = startTokenCleanerController
controllers["nodeipam"] = startNodeIpamController
controllers["nodelifecycle"] = startNodeLifecycleController
if loopMode == IncludeCloudLoops {
controllers["service"] = startServiceController
controllers["route"] = startRouteController
controllers["cloud-node-lifecycle"] = startCloudNodeLifecycleController
// TODO: volume controller into the IncludeCloudLoops only set.
}
controllers["persistentvolume-binder"] = startPersistentVolumeBinderController
controllers["attachdetach"] = startAttachDetachController
controllers["persistentvolume-expander"] = startVolumeExpandController
controllers["clusterrole-aggregation"] = startClusterRoleAggregrationController
controllers["pvc-protection"] = startPVCProtectionController
controllers["pv-protection"] = startPVProtectionController
controllers["ttl-after-finished"] = startTTLAfterFinishedController
controllers["root-ca-cert-publisher"] = startRootCACertPublisher
controllers["ephemeral-volume"] = startEphemeralVolumeController
if utilfeature.DefaultFeatureGate.Enabled(genericfeatures.APIServerIdentity) &&
utilfeature.DefaultFeatureGate.Enabled(genericfeatures.StorageVersionAPI) {
controllers["storage-version-gc"] = startStorageVersionGCController
}
return controllers
}
可见支持很多的controller,我们来看看我们常见的控制器。
replication controller
replication controller副本控制 ,副本控制器的核心作用是确保任何使用集群中的一个RC所关联的Pod副本数量保持预设的值。
node controller节点管理。
首先我们需要了解kubelet通过apiserver向etcd中存储的节点信息:有节点健康状况,节点资源,节点名称地址,操作系统版本,docker版本,kubelet版本等等,其中一个节点健康状况分为三种True,false,unknown三种状态,也是最直接的节点状态
然后这个控制器就会重etcd中逐个节点读取这些状态,将来自kubelet状态来改变node controller中nodestatusmap中状态,对于状态不对的node节点加入一个队列,等待确认node是否有问题,有问题就进行信息同步,并且删除节点。
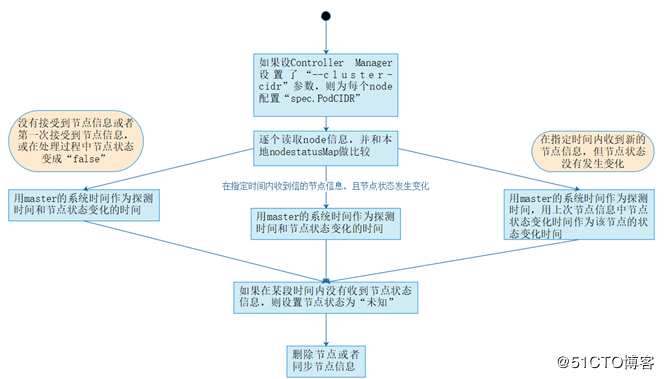
具体步骤
- 如果controller manager在启动时设置了–cluster-cidr,那么为每一个没有设置spec.PodCIDR的节点生成一个CIDR地址,并用该地址设置节点的spec.PodCIDR属性。
- 逐个读取节点信息,此时node controller中有一个nodestatusMap,里面存储了信息,与新发送过来的节点信息做比较,并更新nodestatusMap中的节点信息。Kubelet发送过来的节点信息,有三种情况:未发送、发送但节点信息未变化、发送并且节点信息变化。此时node controller根据发送的节点信息,更新nodestatusMap,如果判断出在某段时间内没有接受到某个节点的信息,则设置节点状态为“未知”。
- 最后,将未就绪状态的节点加入到待删除队列中,待删除后,通过API Server将etcd中该节点的信息删除。如果节点为就绪状态,那么就向etcd中同步该节点信息。
resourcequota controller资源配额
这一个功能十分必要,它确保任何对象任何时候都不会超量占用资源,确保来系统的稳定性。目前k8s支持三个层次的资源配额
- 容器级别 可以限制cpu和memory
- pod级别 对pod内所有容器的可用资源进行限制
- namespace级别 pod数量,rc数量 service数量,rq数量,secret数量,persistent volume数量
实现机制:准入机制(admission caotrol),admission control当前提供了两种方式的配额约束,分别是limitRanger和resourceQuota。其中limitRanger作用于pod和容器上。ResourceQuota作用于namespace上,用于限定一个namespace里的各类资源的使用总额。
在etcd中会维护一个资源配额记录,每次用户通过apiserver进行请求时,这个控制器会先进行计算,如果资源不过就会拒绝请求。
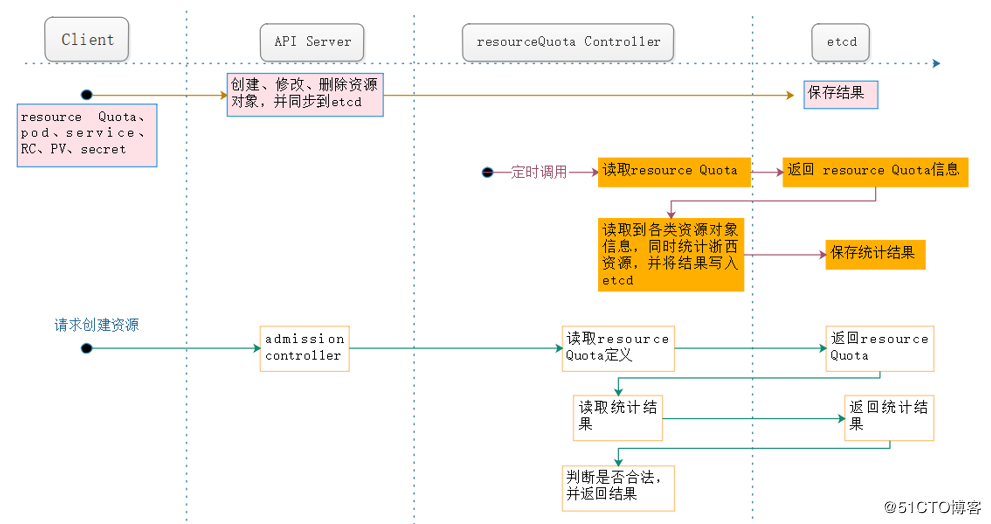
从上图中,我们可以看出,大概有三条路线,resourceQuota controller在这三条路线中都起着重要的作用:
- 如果用户在定义pod时同时声明了limitranger,则用户通过API Server请求创建或者修改资源对象,这是admission control会计算当前配额的使用情况,不符合约束的则创建失败。
- 对于定义了resource Quota的namespace,resourceQuota controller会定期统计和生成该namespace下的各类对象资源使用总量,统计结果包括:pod、service、RC、secret和PV等对象的实例个数,以及该namespace下所有的container实例所使用的资源量(CPU,memory),然后会将这些结果写入到etcd中,写入的内容为资源对象名称、配额制、使用值,然后admission control会根据统计结果判断是否超额,以确保相关namespace下的资源配置总量不会超过resource Quota的限定值。
namespace controller
namespace controller主要是监控namespace的状态,在其失效的情况下,对其进行处理。
用户通过API Server可以创建新的namespace并保存在etcd中,namespace controller定时通过API Server读取这些namespace信息。如果namespace被API标记为优雅删除(通过设置删除周期),则将该namespace的状态设置为“terminating”并保存到etcd中。同时namespace controller删除该namespace下的serviceAccount,RC,pod,secret,PV,listRange,resourceQuota和event等资源对象。
当namespace的状态为“terminating”后,由admission controller的namespaceLifecycle插件来阻止为该namespace创建新的资源。同时在namespace controller删除完该namespace中的所有资源对象后,namespace controller对该namespace 执行finalize操作,删除namespace的spec.finallizers域中的信息。
当然这里有一种特殊情况,当个namespace controller发现namespace设置了删除周期,并且该namespace 的spec.finalizers域值为空,那么namespace controller将通过API Server删除该namespace 的资源。
serviceAccount controller和token controller
TODO
service controller和endpoint controller
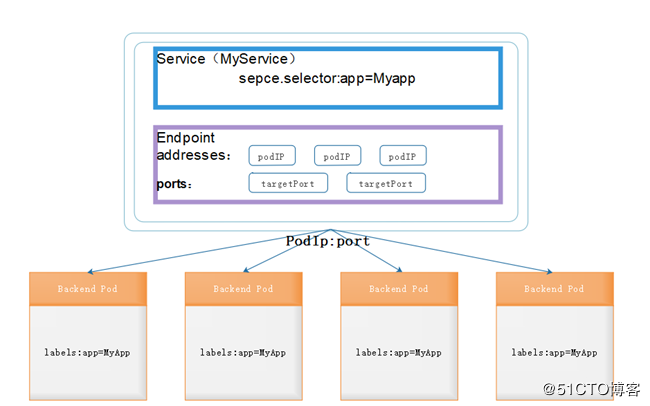
上图所示了service和endpoint与pod的关系,endpoints表示一个service对应的所有的pod副本的访问地址,而endpoints controller就是负责生成和维护所有endpoints对象的控制器。
它负责监听service和对应的pod副本的变化,如果检测到service被删除,则删除和该service同名的endpoints对象。如果检测到新的service被创建或者修改,则根据该service的信息获取到相关的pod列表,然后创建或者更新service对应的endpoints对象。如果检测到pod的事件,则更新它对应service的endpoints对象(增加或者删除或者修改对应的endpoint条目)。
我们都知道将service和pod通过label关联之后,我们访问service的clusterIP对应的服务,就能通过kube-proxy将路由转发到对应的后端的endpoint(pod IP +port)上,最终访问到容器中的服务,实现了service的负载均衡功能。
service controller的作用,它其实是属于kubernetes与外部的云平台之间的一个接口控制器。Service controller监听service的变化,如果是一个loadBalancer类型的service,则service controller确保外部的云平台上该service对应的loadbalance实例被相应的创建、删除以及更新路由转发表(根据endpoint的条目)。
pv controller
其实就是我们注册函数中的controllers["persistentvolume-binder"] = startPersistentVolumeBinderController
PV 控制器 watch 到该 Pod 使用的 PVC 处于 Pending 状态,于是调用 Volume Plugin(in-tree)创建存储卷,并创建 PV 对象(out-of-tree 由 External Provisioner 来处理)。
TODO
源码解析
TODO