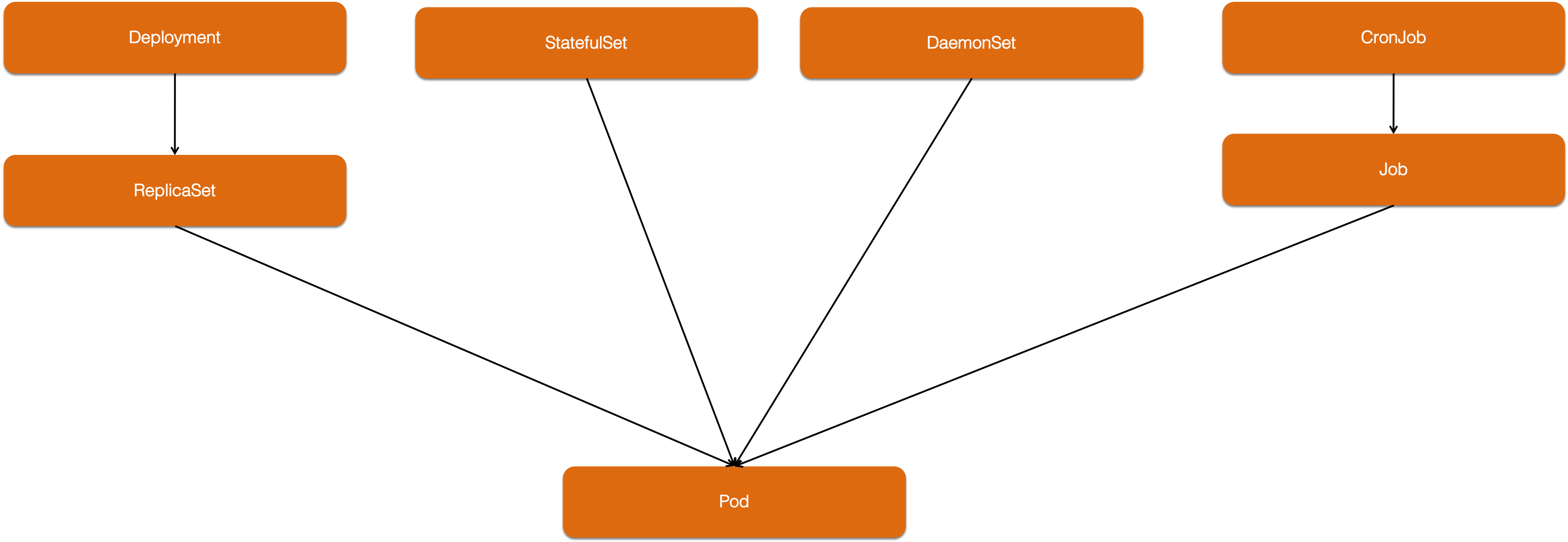
pod只是运行的最小单元,我们一般不会直接使用pod。大部分情况下我们都是使用deployment(RS),deamonset,statefulset,job等控制器来完成部署调度使用。
控制器原理
编写自定义控制器代码的过程包括:编写 main 函数、编写自定义控制器的定义,以及编写控制器里的业务逻辑三个部分。
举个例子,我现在要为 k8s 添加一个名叫 Network 的 API 资源类型。它的作用是,一旦用户创建一个 Network 对象,那么 Kubernetes 就应该使用这个对象定义的网络参数,调用真实的网络插件,创建一个真正的“网络”。
main
main 函数的主要工作就是,定义并初始化一个自定义控制器(Custom Controller),然后启动它。这部分代码的主要内容如下所示:
func main() {
...
cfg, err := clientcmd.BuildConfigFromFlags(masterURL, kubeconfig)
...
kubeClient, err := kubernetes.NewForConfig(cfg)
...
networkClient, err := clientset.NewForConfig(cfg)
...
networkInformerFactory := informers.NewSharedInformerFactory(networkClient, ...)
controller := NewController(kubeClient, networkClient,
networkInformerFactory.Samplecrd().V1().Networks())
go networkInformerFactory.Start(stopCh)
if err = controller.Run(2, stopCh); err != nil {
glog.Fatalf("Error running controller: %s", err.Error())
}
}
- 第一步:main 函数根据我提供的 Master 配置(APIServer 的地址端口和 kubeconfig 的路径),创建一个 Kubernetes 的 client(kubeClient)和 Network 对象的 client(networkClient)。没有提供 Master 配置,main 函数会直接使用一种名叫 InClusterConfig 的方式来创建这个 client。这个方式,会假设你的自定义控制器是以 Pod 的方式运行在 Kubernetes 集群里的。
- 第二步:main 函数为 Network 对象创建一个叫作 InformerFactory(即:networkInformerFactory)的工厂,并使用它生成一个 Network 对象的 Informer,传递给控制器。
- 第三步:main 函数启动上述的 Informer,然后执行 controller.Run,启动自定义控制器。
这边是network的控制器,如果是其他类似的资源控制器,就会创建对应的资源client和informer。
补充
这个是在老版本的crd开发中的一个main情况,在最新的kuberbuilder构建的crd中,有所不同,下面kubebuilder有详细说明,但是整体的原理还是不变的。
编写自定义控制器的定义
我们先了解一下整个架构,我们用一幅流程图来表示
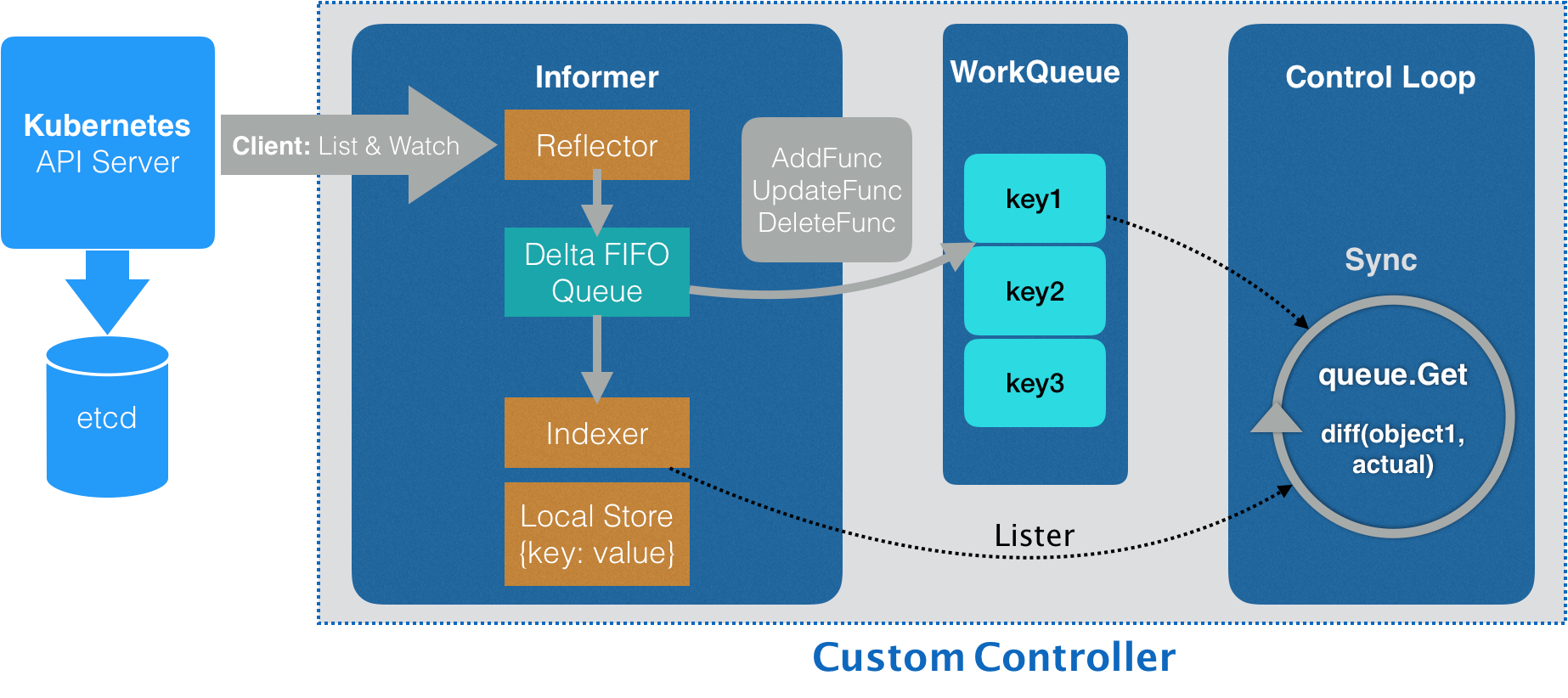
控制器首先通过Informer从 Kubernetes 的 APIServer 里获取它所关心的对象,这里就是定义的 Network 对象。Informer 与 API 对象是一一对应的,在创建这个 Informer 工厂的时候,需要给它传递一个client结构体 networkClient,然后 Network Informer 正是使用这个 networkClient跟 APIServer 建立了连接。然后 Informer 中的 Reflector 包负责维护这个连接的,Reflector 使用了ListAndWatch 的方法,来“获取”并“监听”这些 Network 对象实例的变化。
APIServer 端有新的 Network 实例被创建、删除或者更新等变化,Reflector通过ListAndWatch接口 都会收到“事件通知”,然后将该事件及它对应的 API 对象这个组合(称为增量(Delta))放进一个 Delta FIFO Queue(即:增量先进先出队列)中。
Informer 会不断地从这个 Delta FIFO Queue 里读取(Pop)增量。Informer 就会判断当前获取的这个增量里的事件类型,然后创建或者更新本地对象的缓存(在 Kubernetes 里一般被叫作 Store)。Informer 最重要的职责就是同步本地缓存的工作。
- 如果事件类型是 Added(添加对象),那么 Informer 会通过Indexer 的库把这个增量里的 API 对象保存在本地缓存中,并为它创建索引。
- 如果增量的事件类型是 Deleted(删除对象),那么 Informer 就会从本地缓存中删除这个对象。
Informer 的第二个职责也就是下面的流程,根据这些事件的类型,触发事先注册好的 ResourceEventHandler。这些 Handler,需要在创建控制器的时候注册给它对应的 Informer。
接下来,我们就来编写这个控制器的定义,它的主要内容如下所示:
func NewController(
kubeclientset kubernetes.Interface,
networkclientset clientset.Interface,
networkInformer informers.NetworkInformer) *Controller {
...
controller := &Controller{
kubeclientset: kubeclientset,
networkclientset: networkclientset,
networksLister: networkInformer.Lister(),
networksSynced: networkInformer.Informer().HasSynced,
workqueue: workqueue.NewNamedRateLimitingQueue(..., "Networks"),
...
}
networkInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.enqueueNetwork,
UpdateFunc: func(old, new interface{}) {
oldNetwork := old.(*samplecrdv1.Network)
newNetwork := new.(*samplecrdv1.Network)
if oldNetwork.ResourceVersion == newNetwork.ResourceVersion {
return
}
controller.enqueueNetwork(new)
},
DeleteFunc: controller.enqueueNetworkForDelete,
return controller
}
控制器结构体说明
- 前面在 main 函数里创建了两个 client(kubeclientset 和 networkclientset),然后在这段代码里,使用这两个 client 和前面创建的 Informer,初始化了自定义控制器。
- 在这个自定义控制器里,还设置了一个工作队列(work queue),它正是处于示意图中间位置的 WorkQueue。这个工作队列的作用是,负责同步 Informer 和控制循环之间的数据。
- 然后,networkInformer 注册了三个 Handler(AddFunc、UpdateFunc 和 DeleteFunc),分别对应 API 对象的“添加”“更新”和“删除”事件。而具体的处理操作,都是将该事件对应的 API 对象加入到工作队列中。实际入队的并不是 API 对象本身,而是它们的 Key( API 对象的namespace/name),也是下面我们控制循环获取的值。
到这里整个Informer流程其实已经结束了,可见informer就是一个带有本地缓存和索引机制的、可以注册 EventHandler 的 client。
它是自定义控制器跟 APIServer 进行数据同步的重要组件,通过一种叫作 ListAndWatch 的方法,把 APIServer 中的 API 对象缓存在了本地,并负责更新和维护这个缓存。在informer中定义了 resyncPeriod,这是一个定时更新的时间,达到这个时间Informer 维护的本地缓存都会使用最近一次 LIST 返回的结果强制更新一次,从而保证缓存的有效性(这个缓存强制更新的操作就叫作:resync)。这个定时 resync 操作,也会触发 Informer 注册的“更新”事件。实际上Network 对象实际上并没有发生变化,新、旧两个 Network 对象的 ResourceVersion 是一样的。这时,Informer 就不需要对这个更新事件做进一步的处理了。其实这种先判断了一下新、旧两个 Network 对象的版本(ResourceVersion)是否发生了变化,然后才开始进行的入队操作,是listandwatch机制保证顺序性的功能。
ListAndWatch 其实我们在apiserver中有过详细的讲解,就是通过 APIServer 的 LIST API“获取”所有最新版本的 API 对象;然后,再通过 WATCH API 来“监听”所有这些 API 对象的变化。然后Informer 就可以通过上面讲解的流程实时地更新本地缓存,并且调用这些事件对应的 EventHandler 了。
其实这一块基本上都可以使用工具生成了,我们只要知道informer的原理。
我们大多数需要编写的是这个crd的结构体字段,我们来看一下Kubebuilder 已经帮你创建和默认的结构,大体如下:
// Jcy is the Schema for the Jcy API
// +k8s:openapi-gen=true
type XXX struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec XXXSpec `json:"spec,omitempty"` 期待的状态
Status XXXStatus `json:"status,omitempty"` 实际的状态
}
我们需要做的就是扩展XXXSpec和XXXStatus来定义我们需要使用的字段。
控制器里的业务逻辑:控制循环
接下来,我们就来到了示意图中最后面的控制循环(Control Loop)部分,也正是我在 main 函数最后调用 controller.Run() 启动的“控制循环”。它的主要内容如下所示:
func (c *Controller) Run(threadiness int, stopCh <-chan struct{}) error {
...
if ok := cache.WaitForCacheSync(stopCh, c.networksSynced); !ok {
return fmt.Errorf("failed to wait for caches to sync")
}
...
for i := 0; i < threadiness; i++ {
go wait.Until(c.runWorker, time.Second, stopCh)
}
...
return nil
}
可以看到,启动控制循环的逻辑非常简单:
- 首先,等待 Informer 完成一次本地缓存的数据同步操作;
- 然后,直接通过 goroutine 启动一个(或者并发启动多个)“无限循环”的任务。这边是一个队列+工作池的模式,池的大小可以在控制器的结构体中配置。
而这个“无限循环”任务的每一个循环周期,执行的正是我们真正关心的业务逻辑。
补充
最新使用kubebuilder构建的控制器的启动有所不同,但是功能差不多
// Start implements controller.Controller
func (c *Controller) Start(stop <-chan struct{}) error {
c.mu.Lock()
// TODO(pwittrock): Reconsider HandleCrash
defer utilruntime.HandleCrash()
defer c.Queue.ShutDown()
// Start the SharedIndexInformer factories to begin populating the SharedIndexInformer caches
log.Info("Starting Controller", "controller", c.Name)
// Wait for the caches to be synced before starting workers
if c.WaitForCacheSync == nil {
c.WaitForCacheSync = c.Cache.WaitForCacheSync
}
if ok := c.WaitForCacheSync(stop); !ok {
// This code is unreachable right now since WaitForCacheSync will never return an error
// Leaving it here because that could happen in the future
err := fmt.Errorf("failed to wait for %s caches to sync", c.Name)
log.Error(err, "Could not wait for Cache to sync", "controller", c.Name)
c.mu.Unlock()
return err
}
if c.JitterPeriod == 0 {
c.JitterPeriod = 1 * time.Second
}
// Launch workers to process resources
log.Info("Starting workers", "controller", c.Name, "worker count", c.MaxConcurrentReconciles)
for i := 0; i < c.MaxConcurrentReconciles; i++ {
// Process work items
go wait.Until(c.worker, c.JitterPeriod, stop)
}
c.Started = true
c.mu.Unlock()
<-stop
log.Info("Stopping workers", "controller", c.Name)
return nil
}
所以接下来,我们就来编写这个自定义控制器的业务逻辑,它的主要内容如下所示:
func (c *Controller) runWorker() {
for c.processNextWorkItem() {
}
}
func (c *Controller) processNextWorkItem() bool {
obj, shutdown := c.workqueue.Get()
...
err := func(obj interface{}) error {
...
if err := c.syncHandler(key); err != nil {
return fmt.Errorf("error syncing '%s': %s", key, err.Error())
}
c.workqueue.Forget(obj)
...
return nil
}(obj)
...
return true
}
func (c *Controller) syncHandler(key string) error {
namespace, name, err := cache.SplitMetaNamespaceKey(key)
...
network, err := c.networksLister.Networks(namespace).Get(name)
if err != nil {
if errors.IsNotFound(err) {
glog.Warningf("Network does not exist in local cache: %s/%s, will delete it from Neutron ...",
namespace, name)
glog.Warningf("Network: %s/%s does not exist in local cache, will delete it from Neutron ...",
namespace, name)
// FIX ME: call Neutron API to delete this network by name.
//
// neutron.Delete(namespace, name)
return nil
}
...
return err
}
glog.Infof("[Neutron] Try to process network: %#v ...", network)
// FIX ME: Do diff().
//
// actualNetwork, exists := neutron.Get(namespace, name)
//
// if !exists {
// neutron.Create(namespace, name)
// } else if !reflect.DeepEqual(actualNetwork, network) {
// neutron.Update(namespace, name)
// }
return nil
}
可以看到,在这个执行周期里(processNextWorkItem),我们首先从工作队列里出队(workqueue.Get)了一个成员,也就是一个 Key(Network 对象的:namespace/name)。然后,在 syncHandler 方法中,我使用这个 Key,尝试从 Informer 维护的缓存中拿到了它所对应的 Network 对象。可以看到,在这里,我使用了 networksLister 来尝试获取这个 Key 对应的 Network 对象。这个操作,其实就是在访问本地缓存的索引。实际上,在 Kubernetes 的源码中,你会经常看到控制器从各种 Lister 里获取对象,比如:podLister、nodeLister 等等,它们使用的都是 Informer 和缓存机制。
- 如果控制循环从缓存中拿不到这个对象(即:networkLister 返回了 IsNotFound 错误),那就意味着这个 Network 对象的 Key 是通过前面的“删除”事件添加进工作队列的。所以,尽管队列里有这个 Key,但是对应的 Network 对象已经被删除了。这时候,我就需要调用网络插件的API,把这个 Key 对应的网络从真实的集群里删除掉。
- 如果能够获取到对应的 Network 对象,我就可以执行控制器模式里的对比“期望状态”和“实际状态”的逻辑了,也是我们主要开发的reconcile的逻辑。
其中,自定义控制器“千辛万苦”拿到的这个 Network 对象,正是 APIServer 里保存的“期望状态”,即:用户通过 YAML 文件提交到 APIServer 里的信息。“实际状态”来自于实际的集群中kubelet的上报了。
- 如果实际不存在,这就是一个典型的“期望状态”与“实际状态”不一致的情形。这时,我就需要使用这个 Network 对象里的信息(比如:CIDR 和 Gateway),调用网络插件的API 来创建真实的网络。
- 如果存在,那么,我就要读取这个真实网络的信息,判断它是否跟 Network 对象里的信息一致,从而决定我是否更新这个已经存在的真实网络。
总结
控制型模式最核心的就是控制循环的概念。
我们可以用一段 Go 语言风格的伪代码,为你描述这个控制循环:
for {
实际状态 := 获取集群中对象X的实际状态(Actual State)
期望状态 := 获取集群中对象X的期望状态(Desired State)
if 实际状态 == 期望状态{
什么都不做
} else {
执行编排动作,将实际状态调整为期望状态
}
}
- 实际状态status往往来自于 Kubernetes 集群本身。比如,kubelet 通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,或者控制器主动收集的它自己感兴趣的信息,这些都是常见的实际状态的来源。
- 期望状态spec,一般来自于用户提交的 YAML 文件。比如,Deployment 对象中 Replicas 字段的值。很明显,这些信息往往都保存在 Etcd 中。
外界通过修改资源 spec 来控制资源,控制器比较资源 spec 和 status,从而计算一个 diff,diff 最后会用来决定执行对系统进行什么样的控制操作。
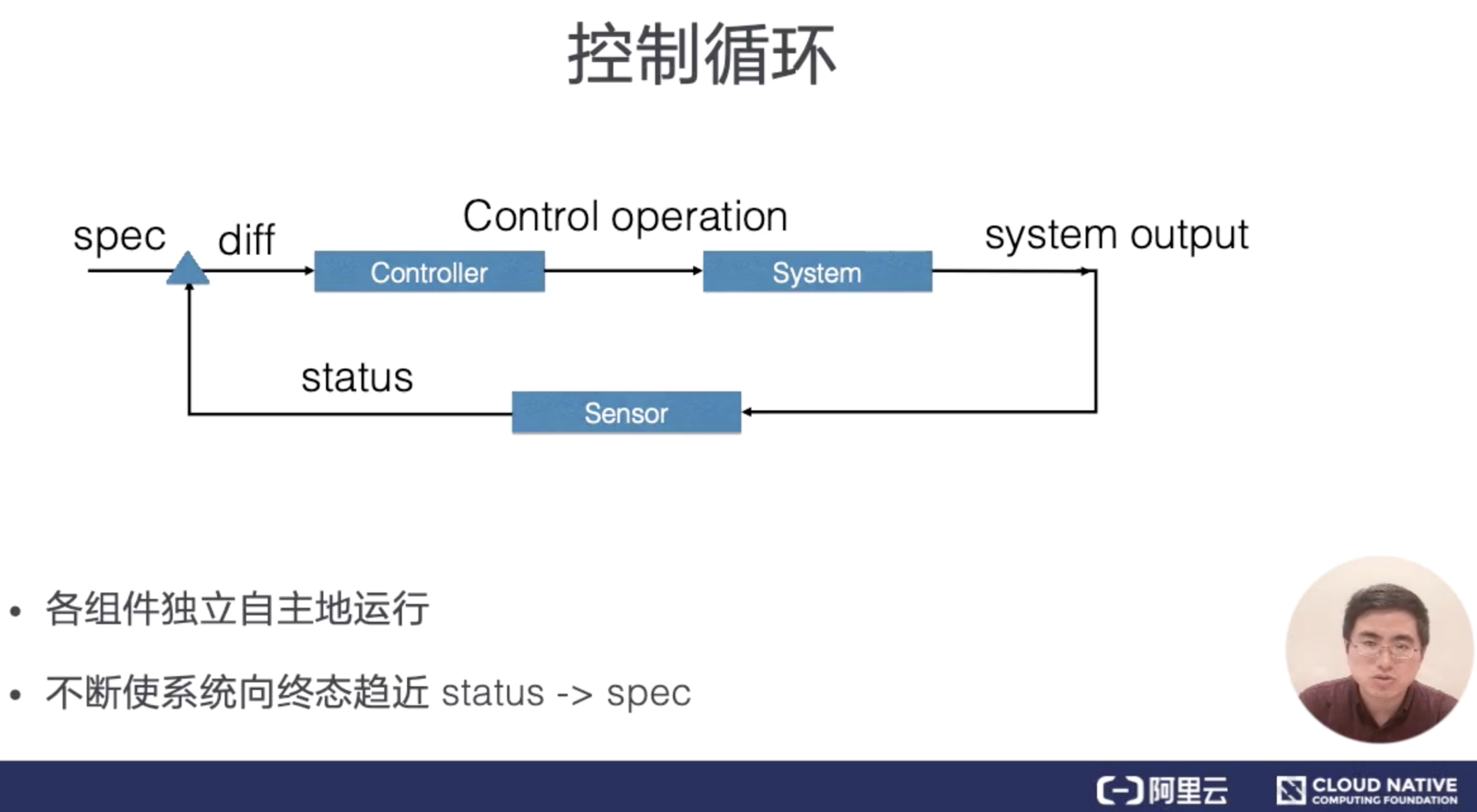
其实我们核心的开发就是控制循环的逻辑,负责获取事件(给定的 Kubernetes 服务器只会保留一定的时间内发生的历史变更列表。 使用 etcd3 的集群默认保存过去 5 分钟内发生的变更。),并且对事件进行对比,然后做创建删除的操作,其他的组件官方提供的工具都能自动生成,即:pkg/client/{informers, listers, clientset}里的内容。。
reconcile的逻辑我们也可以使用一段伪代码来表示,其实和上面的核心控制循环路基差不多,也是我们正常开发的流程,当然在真正的开发中要比这个复杂的多。
event := 获取事件(namespace/name)
期望状态 := 获取对应api对象在缓存中的状态,也就是期望的状态
实际状态 := 获取对应api对象的实际状态,也就是status的状态
if 期望状态 == 实际状态 {
不在做进一步的处理
}else{
调用client-go的库来修改对应的api在etcd中存储的资源
}
实例
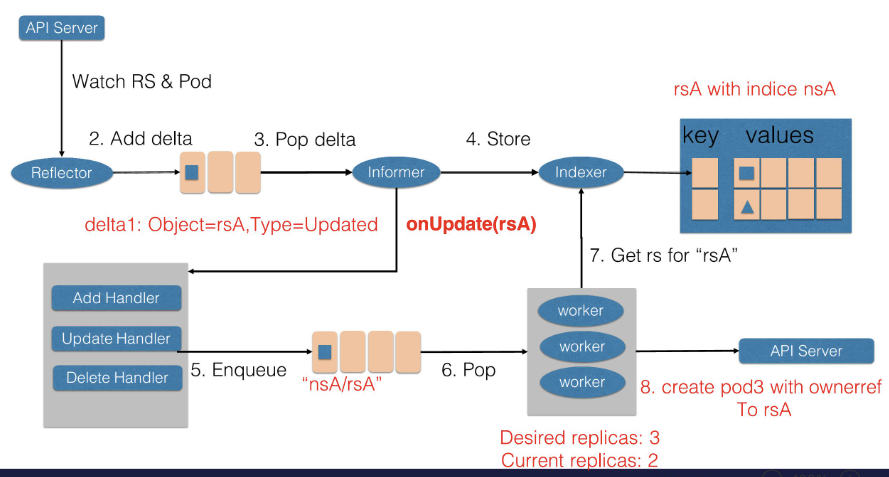
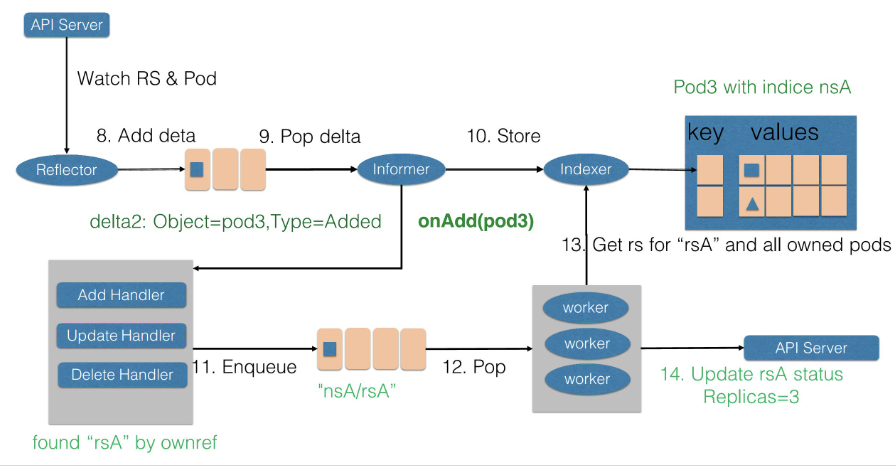
- 首先,Reflector 会 watch 到 ReplicaSet 和 Pod 两种资源的变化。发现 ReplicaSet 发生变化后,在 delta 队列中塞入了对象是 rsA,而且类型是更新的记录。
- Informer 一方面把新的 ReplicaSet 更新到缓存中,并与 Namespace nsA 作为索引。另外一方面,调用 Update 的回调函数,ReplicaSet 控制器发现 ReplicaSet 发生变化后会把字符串的 nsA/rsA 字符串塞入到工作队列中,工作队列后的一个 Worker 从工作队列中取到了 nsA/rsA 这个字符串的 key,并且从缓存中取到了最新的 ReplicaSet 数据。
- Worker 通过比较 ReplicaSet 中 spec 和 status 里的数值,发现需要对这个 ReplicaSet 进行扩容,因此 ReplicaSet 的 Worker 创建了一个 Pod,这个 pod 中的 Ownereference 取向了 ReplicaSet rsA。
- 然后 Reflector Watch 到的 Pod 新增事件,在 delta 队列中额外加入了 Add 类型的 deta 记录,一方面把新的 Pod 记录通过 Indexer 存储到了缓存中,另一方面调用了 ReplicaSet 控制器的 Add 回调函数,Add 回调函数通过检查 pod ownerReferences 找到了对应的 ReplicaSet,并把包括 ReplicaSet 命名空间和字符串塞入到了工作队列中。
- ReplicaSet 的 Woker 在得到新的工作项之后,从缓存中取到了新的 ReplicaSet 记录,并得到了其所有创建的 Pod,因为 ReplicaSet 的状态不是最新的,也就是所有创建 Pod 的数量不是最新的。因此在此时 ReplicaSet 更新 status 使得 spec 和 status 达成一致。
k8s原生控制器
RC
Replication Controller 保证了在所有时间内,都有特定数量的Pod副本正在运行,如果太多了,Replication Controller就杀死几个,如果太少了,Replication Controller会新建几个。
后来这种资源控制器和kube-controller-manager的模块同名,所以修改为ReplicaSet,一样的功能。
depolymemt
Deployment为Pod和ReplicaSet提供了一个声明式定义(declarative)方法,主要是在RS的基础上实现以下的功能:
- 定义Deployment来创建Pod和ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
定义
Deployment 这种控制器的设计原理,就是用一种对象管理另一种对象的“艺术”,在k8s中很常见但是很好的设计思想,在这里就是指deployment控制RS,两个在k8s中都是API对象。
- 这个控制器对象本身,负责定义被管理对象的期望状态。比如,Deployment 里的 replicas=2 这个字段。
- 被控制对象的定义,则是一个“模板”。Deployment 这个 template 字段里的内容,跟一个标准的 Pod 对象的 API 定义,丝毫不差。而所有被这个 Deployment 管理的 Pod 实例,其实都是根据这个 template 字段的内容创建出来的。像 Deployment 定义的 template 字段,在 Kubernetes 项目中有一个专有的名字,叫作 PodTemplate(Pod 模板)。这个概念非常重要,大多数控制器都会使用 PodTemplate 来统一定义它所要管理的 Pod。我们还会看到其他类型的对象模板,比如 Volume 的模板。
所以Deployment 这个控制器的yaml文件,实际上都是由上半部分的控制器自身的定义(包括期望状态),加上下半部分的被控制对象的模板组成的。

我们简单的看一下deployment控制器的必须的字段有
- apiVersion 版本
- kind 类型
- metadata 元数据,API 对象的 Metadata 里,都有一个字段叫作 ownerReference,用于保存当前这个 API 对象的拥有者(Owner)的信息。对于一个 Deployment 所管理的 Pod,它的 ownerReference 是谁?所以,这个问题的答案就是:ReplicaSet。
- spec 详细信息,在spec中必须有的两个字段是.spec.template
和.spec.selector,还包含一些其他定义的字段如下,查看官方文档。
deploymemt就是使用ReplicaSet来实现的,现在基本都是使用这个来进行无状态的应用部署。
实例:一个简单的nginx应用
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
扩容
可是为什么需要deployment?rs不就能实现副本的控制了吗?其实Deployment 同样通过“控制器模式”,来操作 ReplicaSet 的个数和属性,进而实现“水平扩展 / 收缩”和“滚动更新”这两个编排动作。ReplicaSet 并不直接支持滚动更新,这才是重点,我们一一详解。
kubectl scale deployment nginx-deployment --replicas 10
通过scale直接扩展副本的个数,如果集群支持 horizontal pod autoscaling 的话,还可以为Deployment设置自动扩展:
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80
可见,“水平扩展 / 收缩”非常容易实现,Deployment Controller 只需要修改它所控制的 ReplicaSet 的 Pod 副本个数就可以了。
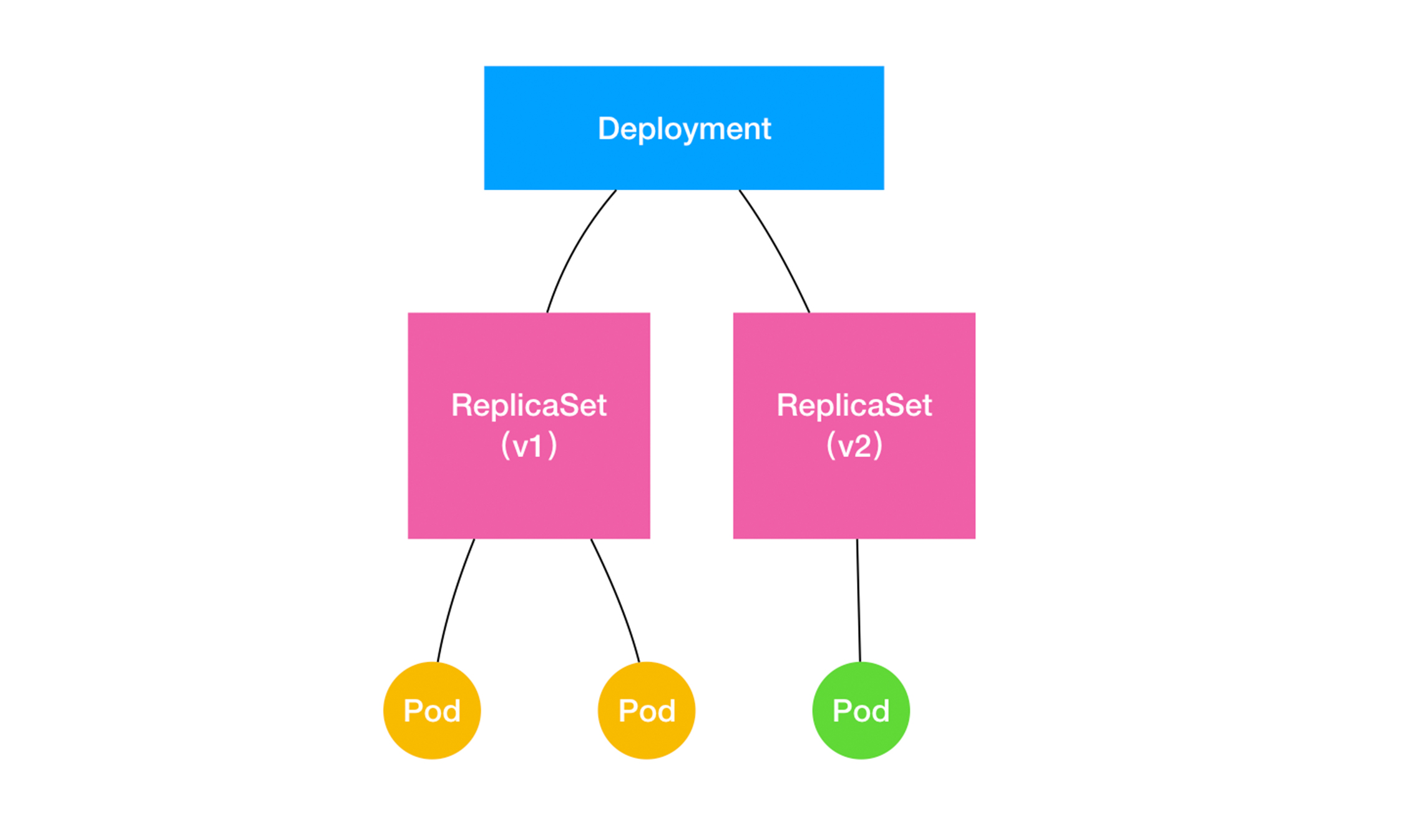
滚动更新
只要修改镜像版本就可以自动触发滚动更新,更新过程可以用一个简单的图来表示,从图可见,replicaset其实就是对应了我们的版本控制的功能。
$ kubectl create -f docs/user-guide/nginx-deployment.yaml --record
deployment "nginx-deployment" created
将kubectl的 —record 的flag设置为 true可以在annotation中记录当前命令创建或者升级了该资源。获取信息
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 18s
- DESIRED:用户期望的 Pod 副本个数(spec.replicas 的值);
- CURRENT:当前处于 Running 状态的 Pod 的个数;
- UP-TO-DATE:当前处于最新版本的 Pod 的个数,所谓最新版本指的是 Pod 的 Spec 部分与 Deployment 里 Pod 模板里定义的完全一致;
- AVAILABLE:当前已经可用的 Pod 的个数,即:既是 Running 状态,又是最新版本,并且已经处于 Ready(健康检查正确)状态的 Pod 的个数。
Kubernetes 项目还为我们提供了一条指令,让我们可以实时查看 Deployment 对象的状态变化。这个指令就是 kubectl rollout status:
$ kubectl rollout status deployment/nginx-deployment
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
deployment.apps/nginx-deployment successfully rolled out
在这个返回结果中,“2 out of 3 new replicas have been updated”意味着已经有 2 个 Pod 进入了 UP-TO-DATE 状态。继续等待一会儿,我们就能看到这个 Deployment 的 3 个 Pod,就进入到了 AVAILABLE 状态,也就是上面的状态。
再来看rs和pod
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-2035384211 3 3 0 18s
$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-2035384211-7ci7o 1/1 Running 0 18s app=nginx,pod-template-hash=2035384211
nginx-deployment-2035384211-kzszj 1/1 Running 0 18s app=nginx,pod-template-hash=2035384211
nginx-deployment-2035384211-qqcnn 1/1 Running 0 18s app=nginx,pod-template-hash=2035384211
在用户提交了一个 Deployment 对象后,Deployment Controller 就会立即创建一个 Pod 副本个数为 3 的 ReplicaSet。这个 ReplicaSet 的名字,则是由 Deployment 的名字和一个随机字符串共同组成。这个随机字符串叫作 pod-template-hash,也就是上面的2035384211。ReplicaSet 会把这个随机字符串加在它所控制的所有 Pod 的标签里,从而保证这些 Pod 不会与集群里的其他 Pod 混淆。而 ReplicaSet 的 DESIRED、CURRENT 和 READY 字段的含义,和 Deployment 中是一致的。所以,相比之下,Deployment 只是在 ReplicaSet 的基础上,添加了 UP-TO-DATE 这个跟版本有关的状态字段。这个时候,如果我们修改了 Deployment 的 Pod 模板,“滚动更新”就会被自动触发。
更新镜像也比较简单:
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
我们可以使用edit命令来编辑Deployment,修改 .spec.template.spec.containers[0].image ,将nginx:1.7.9 改写成nginx:1.9.1。
$ kubectl edit deployment/nginx-deployment
deployment "nginx-deployment" edited
查看rollout的状态,只要执行:
$ kubectl rollout status deployment/nginx-deployment
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
deployment "nginx-deployment" successfully rolled out
这时,你可以通过查看 Deployment 的 Events,看到这个“滚动更新”的流程:
$ kubectl describe deployment nginx-deployment
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
...
Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 1
Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 2
Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 2
Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 1
Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 3
Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 0
Deployment Controller 会使用这个修改后的 Pod 模板,创建一个新的 ReplicaSet(hash=1764197365),这个新的 ReplicaSet 的初始 Pod 副本数是:0。然后,在 Age=24 s 的位置,Deployment Controller 开始将这个新的 ReplicaSet 所控制的 Pod 副本数从 0 个变成 1 个。紧接着,在 Age=22 s 的位置,Deployment Controller 又将旧的 ReplicaSet(hash=3167673210)所控制的旧 Pod 副本数减少一个。如此交替进行,新 ReplicaSet 管理的 Pod 副本数,从 0 个变成 1 个,再变成 2 个,最后变成 3 个。而旧的 ReplicaSet 管理的 Pod 副本数则从 3 个变成 2 个,再变成 1 个,最后变成 0 个。这样,就完成了这一组 Pod 的版本升级过程。
像这样,将一个集群中正在运行的多个 Pod 版本,交替地逐一升级的过程,就是“滚动更新”。在这个“滚动更新”过程完成之后,你可以查看一下新、旧两个 ReplicaSet 的最终状态:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-1764197365 3 3 3 6s
nginx-deployment-3167673210 0 0 0 30s
这种“滚动更新”的好处是显而易见的,就是及时停止,不影响服务能力。比如,在升级刚开始的时候,集群里只有 1 个新版本的 Pod。如果这时,新版本 Pod 有问题启动不起来,那么“滚动更新”就会停止,从而允许开发和运维人员介入。而在这个过程中,由于应用本身还有两个旧版本的 Pod 在线,所以服务并不会受到太大的影响。在这个升级过程中一定要使用 Pod 的 Health Check 机制检查应用的运行状态,而不是简单地依赖于容器的 Running 状态。要不然的话,虽然容器已经变成 Running 了,但服务很有可能尚未启动,“滚动更新”的效果也就达不到了。
而为了进一步保证服务的连续性,Deployment Controller 还会确保,在任何时间窗口内,只有指定比例的 Pod 处于离线状态。同时,它也会确保,在任何时间窗口内,只有指定比例的新 Pod 被创建出来。这两个比例的值都是可以配置的,默认都是 DESIRED 值的 25%。
在上面这个 Deployment 的例子中,它有 3 个 Pod 副本,那么控制器在“滚动更新”的过程中永远都会确保至少有 2 个 Pod 处于可用状态,至多只有 4 个 Pod 同时存在于集群中。这个策略,是 Deployment 对象的一个字段,名叫 RollingUpdateStrategy,如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
...
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
在上面这个 RollingUpdateStrategy 的配置中,maxSurge 指定的是除了 DESIRED 数量之外,在一次“滚动”中,Deployment 控制器还可以创建多少个新 Pod;而 maxUnavailable 指的是,在一次“滚动”中,Deployment 控制器可以删除多少个旧 Pod。同时,这两个配置还可以用前面我们介绍的百分比形式来表示,比如:maxUnavailable=50%,指的是我们最多可以一次删除“50%*DESIRED 数量”个 Pod。
我们对 Deployment 进行的每一次更新操作,都会生成一个新的 ReplicaSet 对象,用于回滚,但是这样浪费资源,所以,Kubernetes 项目还提供了一个指令,使得我们对 Deployment 的多次更新操作,最后 只生成一个 ReplicaSet。具体的做法是,在更新 Deployment 前,你要先执行一条 kubectl rollout pause 指令。它的用法如下所示:
$ kubectl rollout pause deployment/nginx-deployment
deployment.extensions/nginx-deployment paused
这个 kubectl rollout pause 的作用,是让这个 Deployment 进入了一个“暂停”状态。所以接下来,你就可以随意使用 kubectl edit 或者 kubectl set image 指令,修改这个 Deployment 的内容了。由于此时 Deployment 正处于“暂停”状态,所以我们对 Deployment 的所有修改,都不会触发新的“滚动更新”,也不会创建新的 ReplicaSet。而等到我们对 Deployment 修改操作都完成之后,只需要再执行一条 kubectl rollout resume 指令,就可以把这个 Deployment“恢复”回来,如下所示:
$ kubectl rollout resume deployment/nginx-deployment
deployment.extensions/nginx-deployment resumed
回滚
我们只需要执行一条 kubectl rollout undo 命令,就能把整个 Deployment 回滚到上一个版本
$ kubectl rollout undo deployment/nginx-deployment
deployment.extensions/nginx-deployment
很容易想到,在具体操作上,Deployment 的控制器,其实就是让这个旧 ReplicaSet(hash=1764197365)再次“扩展”成 3 个 Pod,而让新的 ReplicaSet(hash=2156724341)重新“收缩”到 0 个 Pod。
检查Deployment升级的历史记录可以回滚到更早的版本,首先,检查下Deployment的revision:
$ kubectl rollout history deployment/nginx-deployment
deployments "nginx-deployment":
REVISION CHANGE-CAUSE
1 kubectl create -f docs/user-guide/nginx-deployment.yaml --record
2 kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
3 kubectl set image deployment/nginx-deployment nginx=nginx:1.91
可以看到,我们前面执行的创建和更新操作,分别对应了版本 1 和版本 2,而那次失败的更新操作,则对应的是版本 3。当然,你还可以通过这个 kubectl rollout history 指令,看到每个版本对应的 Deployment 的 API 对象的细节,具体命令如下所示:
$ kubectl rollout history deployment/nginx-deployment --revision=2
然后,我们就可以在 kubectl rollout undo 命令行最后,加上要回滚到的指定版本的版本号,就可以回滚到指定版本了。这个指令的用法如下:
$ kubectl rollout undo deployment/nginx-deployment --to-revision=2
deployment.extensions/nginx-deployment
即使你像上面这样小心翼翼地控制了 ReplicaSet 的生成数量,随着应用版本的不断增加,Kubernetes 中还是会为同一个 Deployment 保存很多很多不同的 ReplicaSet。Deployment 对象有一个字段,叫作 spec.revisionHistoryLimit,就是 Kubernetes 为 Deployment 保留的“历史版本”个数。所以,如果把它设置为 0,你就再也不能做回滚操作了。
StatefulSet
statefulset其实就是就是一种特殊的deployment,他对pod进行了从0开始递增的编号,对应的体现在pod的名字和hostname上,有了这个编号,不但可以控制它的启动顺序,代表它的网络标识,还可以结合k8s的两个功能headless service(编号的pod的name和hostname不会变,对应的service也是直接可以解析到对应的hostname或者name,这样访问就不会变,这边headless service直接解析到对应的编号的pod的hostname的功能)和 pv/pvc(pvc的name不会变,对应的存储也不会变,重建可以直接使用)的实现了拓扑状态和存储状态的维护,从而实现了有状态应用。
StatefulSet 的设计其实非常容易理解。它把真实世界里的应用状态,抽象为了两种情况:
- 拓扑状态。这种情况意味着,应用的多个实例之间不是完全对等的关系。这些应用实例,必须按照某些顺序启动,比如应用的主节点 A 要先于从节点 B 启动。而如果你把 A 和 B 两个 Pod 删除掉,它们再次被创建出来时也必须严格按照这个顺序才行。并且,新创建出来的 Pod,必须和原来 Pod 的网络标识一样,这样原先的访问者才能使用同样的方法,访问到这个新 Pod。
- 存储状态。这种情况意味着,应用的多个实例分别绑定了不同的存储数据。对于这些应用实例来说,Pod A 第一次读取到的数据,和隔了十分钟之后再次读取到的数据,应该是同一份,哪怕在此期间 Pod A 被重新创建过。这种情况最典型的例子,就是一个数据库应用的多个存储实例。
所以,StatefulSet 的核心功能,就是通过某种方式记录这些状态,然后在 Pod 被重新创建时,能够为新 Pod 恢复这些状态。
statefulset升级是重最高编号开始的。
拓扑状态
现在我们就来编写一个 StatefulSet 的 YAML 文件,如下所示:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.9.1
ports:
- containerPort: 80
name: web
这个 YAML 文件,和我们在前面文章中用到的 nginx-deployment 的唯一区别,就是多了一个 serviceName=nginx 字段。这个字段的作用,就是告诉 StatefulSet 控制器,在执行控制循环(Control Loop)的时候,请使用 nginx 这个 Headless Service 来保证 Pod 的“可解析身份”。所以,当你通过 kubectl create 创建了上面这个 Service 和 StatefulSet 之后,就会看到如下两个对象:
$ kubectl create -f svc.yaml
$ kubectl get service nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP None <none> 80/TCP 10s
$ kubectl create -f statefulset.yaml
$ kubectl get statefulset web
NAME DESIRED CURRENT AGE
web 2 1 19s
这时候,如果你手比较快的话,还可以通过 kubectl 的 -w 参数,即:Watch 功能,实时查看 StatefulSet 创建两个有状态实例的过程:如果手不够快的话,Pod 很快就创建完了。不过,你依然可以通过这个 StatefulSet 的 Events 看到这些信息。
$ kubectl get pods -w -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 19s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 20s
通过上面这个 Pod 的创建过程,我们不难看到,StatefulSet 给它所管理的所有 Pod 的名字,进行了编号,编号规则是:-。而且这些编号都是从 0 开始累加,与 StatefulSet 的每个 Pod 实例一一对应,绝不重复。更重要的是,这些 Pod 的创建,也是严格按照编号顺序进行的。比如,在 web-0 进入到 Running 状态、并且细分状态(Conditions)成为 Ready 之前,web-1 会一直处于 Pending 状态。
当这两个 Pod 都进入了 Running 状态之后,你就可以查看到它们各自唯一的“网络身份”了。我们使用 kubectl exec 命令进入到容器中查看它们的 hostname:
$ kubectl exec web-0 -- sh -c 'hostname'
web-0
$ kubectl exec web-1 -- sh -c 'hostname'
web-1
可以看到,这两个 Pod 的 hostname 与 Pod 名字是一致的,都被分配了对应的编号。接下来,我们再试着以 DNS 的方式,访问一下这个 Headless Service,然后,通过新建一个简单一次性pod来看,在这个 Pod 的容器里面,我们尝试用 nslookup 命令,解析一下 Pod 对应的 Headless Service:
$ kubectl run -i --tty --image busybox:1.28.4 dns-test --restart=Never --rm /bin/sh
$ nslookup web-0.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-0.nginx
Address 1: 10.244.1.7
$ nslookup web-1.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-1.nginx
Address 1: 10.244.2.7
从 nslookup 命令的输出结果中,我们可以看到,在访问 web-0.nginx 的时候,最后解析到的,正是 web-0 这个 Pod 的 IP 地址;而当访问 web-1.nginx 的时候,解析到的则是 web-1 的 IP 地址。这时候,如果你在另外一个 Terminal 里把这两个“有状态应用”的 Pod 删掉:
$ kubectl delete pod -l app=nginx
pod "web-0" deleted
pod "web-1" deleted
再在当前 Terminal 里 Watch 一下这两个 Pod 的状态变化,就会发现一个有趣的现象:
$ kubectl get pod -w -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 0/1 ContainerCreating 0 0s
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 2s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 32s
可以看到,当我们把这两个 Pod 删除之后,Kubernetes 会按照原先编号的顺序,创建出了两个新的 Pod。并且,Kubernetes 依然为它们分配了与原来相同的“网络身份”:web-0.nginx 和 web-1.nginx。通过这种严格的对应规则,StatefulSet 就保证了 Pod 网络标识的稳定性。
如果 web-0 是一个需要先启动的主节点,web-1 是一个后启动的从节点,那么只要这个 StatefulSet 不被删除,你访问 web-0.nginx 时始终都会落在主节点上,访问 web-1.nginx 时,则始终都会落在从节点上,这个关系绝对不会发生任何变化。所以,如果我们再用 nslookup 命令,查看一下这个新 Pod 对应的 Headless Service 的话:
$ kubectl run -i --tty --image busybox dns-test --restart=Never --rm /bin/sh
$ nslookup web-0.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-0.nginx
Address 1: 10.244.1.8
$ nslookup web-1.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-1.nginx
Address 1: 10.244.2.8
我们可以看到,在这个 StatefulSet 中,这两个新 Pod 的“网络标识”(比如:web-0.nginx 和 web-1.nginx),再次解析到了正确的 IP 地址(比如:web-0 Pod 的 IP 地址 10.244.1.8)。通过这种方法,Kubernetes 就成功地将 Pod 的拓扑状态(比如:哪个节点先启动,哪个节点后启动),按照 Pod 的“名字 + 编号”的方式固定了下来。此外,Kubernetes 还为每一个 Pod 提供了一个固定并且唯一的访问入口,即:这个 Pod 对应的 DNS 记录。这些状态,在 StatefulSet 的整个生命周期里都会保持不变,绝不会因为对应 Pod 的删除或者重新创建而失效。不过,相信你也已经注意到了,尽管 web-0.nginx 这条记录本身不会变,但它解析到的 Pod 的 IP 地址,并不是固定的。这就意味着,对于“有状态应用”实例的访问,你必须使用 DNS 记录或者 hostname 的方式,而绝不应该直接访问这些 Pod 的 IP 地址。
StatefulSet 这个控制器的主要作用之一,就是使用 Pod 模板创建 Pod 的时候,对它们进行编号,并且按照编号顺序逐一完成创建工作。而当 StatefulSet 的“控制循环”发现 Pod 的“实际状态”与“期望状态”不一致,需要新建或者删除 Pod 进行“调谐”的时候,它会严格按照这些 Pod 编号的顺序,逐一完成这些操作。
所以,StatefulSet 其实可以认为是对 Deployment 的改良。与此同时,通过 Headless Service 的方式,StatefulSet 为每个 Pod 创建了一个固定并且稳定的 DNS 记录,来作为它的访问入口。实际上,在部署“有状态应用”的时候,应用的每个实例拥有唯一并且稳定的“网络标识”,是一个非常重要的假设。
存储状态
PVC、PV 的设计,也使得 StatefulSet 对存储状态的管理成为了可能。
我们还是以上一篇文章中用到的 StatefulSet 为例
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.9.1
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
这次,我们为这个 StatefulSet 额外添加了一个 volumeClaimTemplates 字段。从名字就可以看出来,它跟 Deployment 里 Pod 模板(PodTemplate)的作用类似。也就是说,凡是被这个 StatefulSet 管理的 Pod,都会声明一个对应的 PVC;而这个 PVC 的定义,就来自于 volumeClaimTemplates 这个模板字段。更重要的是,这个 PVC 的名字,会被分配一个与这个 Pod 完全一致的编号。
这个自动创建的 PVC,与 PV 绑定成功后,就会进入 Bound 状态,这就意味着这个 Pod 可以挂载并使用这个 PV 了。当然,PVC 与 PV 的绑定得以实现的前提是,运维人员已经在系统里创建好了符合条件的 PV(比如,我们在前面用到的 pv-volume);或者,你的 Kubernetes 集群运行在公有云上,这样 Kubernetes 就会通过 Dynamic Provisioning 的方式,自动为你创建与 PVC 匹配的 PV。
我们在使用 kubectl create 创建了 StatefulSet 之后,就会看到 Kubernetes 集群里出现了两个 PVC:
$ kubectl create -f statefulset.yaml
$ kubectl get pvc -l app=nginx
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
www-web-0 Bound pvc-15c268c7-b507-11e6-932f-42010a800002 1Gi RWO 48s
www-web-1 Bound pvc-15c79307-b507-11e6-932f-42010a800002 1Gi RWO 48s
可以看到,这些 PVC,都以“
我们就可以使用如下所示的指令,在 Pod 的 Volume 目录里写入一个文件,来验证一下上述 Volume 的分配情况:
$ for i in 0 1; do kubectl exec web-$i -- sh -c 'echo hello $(hostname) > /usr/share/nginx/html/index.html'; done
如上所示,通过 kubectl exec 指令,我们在每个 Pod 的 Volume 目录里,写入了一个 index.html 文件。这个文件的内容,正是 Pod 的 hostname。比如,我们在 web-0 的 index.html 里写入的内容就是”hello web-0”。此时,如果你在这个 Pod 容器里访问“http://localhost”,你实际访问到的就是 Pod 里 Nginx 服务器进程,而它会为你返回 /usr/share/nginx/html/index.html 里的内容。这个操作的执行方法如下所示:
$ for i in 0 1; do kubectl exec -it web-$i -- curl localhost; done
hello web-0
hello web-1
如果你使用 kubectl delete 命令删除这两个 Pod,这些 Volume 里的文件会不会丢失呢?
$ kubectl delete pod -l app=nginx
pod "web-0" deleted
pod "web-1" deleted
可以看到,正如我们前面介绍过的,在被删除之后,这两个 Pod 会被按照编号的顺序被重新创建出来。而这时候,如果你在新创建的容器里通过访问“http://localhost”的方式去访问 web-0 里的 Nginx 服务:
# 在被重新创建出来的Pod容器里访问http://localhost
$ kubectl exec -it web-0 -- curl localhost
hello web-0
就会发现,这个请求依然会返回:hello web-0。也就是说,原先与名叫 web-0 的 Pod 绑定的 PV,在这个 Pod 被重新创建之后,依然同新的名叫 web-0 的 Pod 绑定在了一起。对于 Pod web-1 来说,也是完全一样的情况。这是怎么做到的呢?
首先,当你把一个 Pod,比如 web-0,删除之后,这个 Pod 对应的 PVC 和 PV,并不会被删除,而这个 Volume 里已经写入的数据,也依然会保存在远程存储服务里(比如,我们在这个例子里用到的 Ceph 服务器)。此时,StatefulSet 控制器发现,一个名叫 web-0 的 Pod 消失了。所以,控制器就会重新创建一个新的、名字还是叫作 web-0 的 Pod 来,“纠正”这个不一致的情况。需要注意的是,在这个新的 Pod 对象的定义里,它声明使用的 PVC 的名字,还是叫作:www-web-0。这个 PVC 的定义,还是来自于 PVC 模板(volumeClaimTemplates),这是 StatefulSet 创建 Pod 的标准流程。所以,在这个新的 web-0 Pod 被创建出来之后,Kubernetes 为它查找名叫 www-web-0 的 PVC 时,就会直接找到旧 Pod 遗留下来的同名的 PVC,进而找到跟这个 PVC 绑定在一起的 PV。这样,新的 Pod 就可以挂载到旧 Pod 对应的那个 Volume,并且获取到保存在 Volume 里的数据。通过这种方式,Kubernetes 的 StatefulSet 就实现了对应用存储状态的管理。
总结
- 首先,StatefulSet 的控制器直接管理的是 Pod。这是因为,StatefulSet 里的不同 Pod 实例,不再像 ReplicaSet 中那样都是完全一样的,而是有了细微区别的。比如,每个 Pod 的 hostname、名字等都是不同的、携带了编号的。而 StatefulSet 区分这些实例的方式,就是通过在 Pod 的名字里加上事先约定好的编号。
- 其次,Kubernetes 通过 Headless Service,为这些有编号的 Pod,在 DNS 服务器中生成带有同样编号的 DNS 记录。只要 StatefulSet 能够保证这些 Pod 名字里的编号不变,那么 Service 里类似于 web-0.nginx.default.svc.cluster.local 这样的 DNS 记录也就不会变,而这条记录解析出来的 Pod 的 IP 地址,则会随着后端 Pod 的删除和再创建而自动更新。这当然是 Service 机制本身的能力,不需要 StatefulSet 操心。
- 最后,StatefulSet 还为每一个 Pod 分配并创建一个同样编号的 PVC。这样,Kubernetes 就可以通过 Persistent Volume 机制为这个 PVC 绑定上对应的 PV,从而保证了每一个 Pod 都拥有一个独立的 Volume。在这种情况下,即使 Pod 被删除,它所对应的 PVC 和 PV 依然会保留下来。所以当这个 Pod 被重新创建出来之后,Kubernetes 会为它找到同样编号的 PVC,挂载这个 PVC 对应的 Volume,从而获取到以前保存在 Volume 里的数据。
StatefulSet 其实就是一种特殊的 Deployment,而其独特之处在于,它的每个 Pod 都被编号了。而且,这个编号会体现在 Pod 的名字和 hostname 等标识信息上,这不仅代表了 Pod 的创建顺序,也是 Pod 的重要网络标识(即:在整个集群里唯一的、可被访问的身份)。有了这个编号后,StatefulSet 就使用 Kubernetes 里的两个标准功能:Headless Service 和 PV/PVC,实现了对 Pod 的拓扑状态和存储状态的维护。实际上,在下一篇文章的“有状态应用”实践环节,以及后续的讲解中,你就会逐渐意识到,StatefulSet 可以说是 Kubernetes 中作业编排的“集大成者”。因为,几乎每一种 Kubernetes 的编排功能,都可以在编写 StatefulSet 的 YAML 文件时被用到。
应用
StatefulSet是为了解决有状态服务的问题(对应Deployments和ReplicaSets是为无状态服务而设计),其应用场景包括
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现
- 有序收缩,有序删除(即从N-1到0)
从上面的应用场景可以发现,StatefulSet由以下几个部分组成:
- 用于定义网络标志(DNS domain)的Headless Service
- 用于创建PersistentVolumes的volumeClaimTemplates
- 定义具体应用的StatefulSet
StatefulSet中每个Pod的DNS格式为statefulSetName-{0..N-1}.serviceName.namespace.svc.cluster.local,其中
- serviceName为Headless Service的名字
- 0..N-1为Pod所在的序号,从0开始到N-1
- statefulSetName为StatefulSet的名字
- namespace为服务所在的namespace,Headless Servic和StatefulSet必须在相同的namespace
- .cluster.local为Cluster Domain,
其实,StatefulSet 其实就是对现有典型运维业务的容器化抽象。也就是说,你一定有方法在不使用 Kubernetes、甚至不使用容器的情况下,自己 DIY 一个类似的方案出来。但是,一旦涉及到升级、版本管理等更工程化的能力,Kubernetes 的好处,才会更加凸现。比如,如何对 StatefulSet 进行“滚动更新”(rolling update)?很简单。你只要修改 StatefulSet 的 Pod 模板,就会自动触发“滚动更新”:
$ kubectl patch statefulset mysql --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"mysql:5.7.23"}]'
statefulset.apps/mysql patched
在这里,我使用了 kubectl patch 命令。它的意思是,以“补丁”的方式(JSON 格式的)修改一个 API 对象的指定字段,也就是我在后面指定的“spec/template/spec/containers/0/image”。这样,StatefulSet Controller 就会按照与 Pod 编号相反的顺序,从最后一个 Pod 开始,逐一更新这个 StatefulSet 管理的每个 Pod。而如果更新发生了错误,这次“滚动更新”就会停止。
此外,StatefulSet 的“滚动更新”还允许我们进行更精细的控制,比如金丝雀发布(Canary Deploy)或者灰度发布,这意味着应用的多个实例中被指定的一部分不会被更新到最新的版本。这个字段,正是 StatefulSet 的 spec.updateStrategy.rollingUpdate 的 partition 字段。比如,现在我将前面这个 StatefulSet 的 partition 字段设置为 2:
$ kubectl patch statefulset mysql -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":2}}}}'
statefulset.apps/mysql patched
其中,kubectl patch 命令后面的参数(JSON 格式的),就是 partition 字段在 API 对象里的路径。所以,上述操作等同于直接使用 kubectl edit 命令,打开这个对象,把 partition 字段修改为 2。这样,我就指定了当 Pod 模板发生变化的时候,比如 MySQL 镜像更新到 5.7.23,那么只有序号大于或者等于 2 的 Pod 会被更新到这个版本。并且,如果你删除或者重启了序号小于 2 的 Pod,等它再次启动后,也会保持原先的 5.7.2 版本,绝不会被升级到 5.7.23 版本。
简单示例
以一个简单的nginx服务web.yaml为例,也是对上面实例的扩展:
---
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: gcr.io/google_containers/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
annotations:
volume.alpha.kubernetes.io/storage-class: anything
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
创建
$ kubectl create -f web.yaml
service "nginx" created
statefulset "web" created
查看创建的headless service和statefulset
$ kubectl get service nginx
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx None <none> 80/TCP 1m
$ kubectl get statefulset web
NAME DESIRED CURRENT AGE
web 2 2 2m
根据volumeClaimTemplates自动创建PVC(在GCE中会自动创建kubernetes.io/gce-pd类型的volume)
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
www-web-0 Bound pvc-d064a004-d8d4-11e6-b521-42010a800002 1Gi RWO 16s
www-web-1 Bound pvc-d06a3946-d8d4-11e6-b521-42010a800002 1Gi RWO 16s
查看创建的Pod,他们都是有序的
$ kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 5m
web-1 1/1 Running 0 4m
使用nslookup查看这些Pod的DNS
$ kubectl run -i --tty --image busybox dns-test --restart=Never --rm /bin/sh
/ # nslookup web-0.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-0.nginx
Address 1: 10.244.2.10
/ # nslookup web-1.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-1.nginx
Address 1: 10.244.3.12
/ # nslookup web-0.nginx.default.svc.cluster.local
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-0.nginx.default.svc.cluster.local
Address 1: 10.244.2.10
还可以进行其他的操作
扩容
$ kubectl scale statefulset web --replicas=5
缩容
$ kubectl patch statefulset web -p '{"spec":{"replicas":3}}'
镜像更新
$ kubectl patch statefulset web --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"gcr.io/google_containers/nginx-slim:0.7"}]'
删除StatefulSet和Headless Service
$ kubectl delete statefulset web
$ kubectl delete service nginx
StatefulSet删除后PVC还会保留着,数据不再使用的话也需要删除
$ kubectl delete pvc www-web-0 www-web-1
zookeeper
另外一个更能说明StatefulSet强大功能的示例为zookeeper.yaml。
---
apiVersion: v1
kind: Service
metadata:
name: zk-headless
labels:
app: zk-headless
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
clusterIP: None
selector:
app: zk
---
apiVersion: v1
kind: ConfigMap
metadata:
name: zk-config
data:
ensemble: "zk-0;zk-1;zk-2"
jvm.heap: "2G"
tick: "2000"
init: "10"
sync: "5"
client.cnxns: "60"
snap.retain: "3"
purge.interval: "1"
---
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-budget
spec:
selector:
matchLabels:
app: zk
minAvailable: 2
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: zk
spec:
serviceName: zk-headless
replicas: 3
template:
metadata:
labels:
app: zk
annotations:
pod.alpha.kubernetes.io/initialized: "true"
scheduler.alpha.kubernetes.io/affinity: >
{
"podAntiAffinity": {
"requiredDuringSchedulingRequiredDuringExecution": [{
"labelSelector": {
"matchExpressions": [{
"key": "app",
"operator": "In",
"values": ["zk-headless"]
}]
},
"topologyKey": "kubernetes.io/hostname"
}]
}
}
spec:
containers:
- name: k8szk
imagePullPolicy: Always
image: gcr.io/google_samples/k8szk:v1
resources:
requests:
memory: "4Gi"
cpu: "1"
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
env:
- name : ZK_ENSEMBLE
valueFrom:
configMapKeyRef:
name: zk-config
key: ensemble
- name : ZK_HEAP_SIZE
valueFrom:
configMapKeyRef:
name: zk-config
key: jvm.heap
- name : ZK_TICK_TIME
valueFrom:
configMapKeyRef:
name: zk-config
key: tick
- name : ZK_INIT_LIMIT
valueFrom:
configMapKeyRef:
name: zk-config
key: init
- name : ZK_SYNC_LIMIT
valueFrom:
configMapKeyRef:
name: zk-config
key: tick
- name : ZK_MAX_CLIENT_CNXNS
valueFrom:
configMapKeyRef:
name: zk-config
key: client.cnxns
- name: ZK_SNAP_RETAIN_COUNT
valueFrom:
configMapKeyRef:
name: zk-config
key: snap.retain
- name: ZK_PURGE_INTERVAL
valueFrom:
configMapKeyRef:
name: zk-config
key: purge.interval
- name: ZK_CLIENT_PORT
value: "2181"
- name: ZK_SERVER_PORT
value: "2888"
- name: ZK_ELECTION_PORT
value: "3888"
command:
- sh
- -c
- zkGenConfig.sh && zkServer.sh start-foreground
readinessProbe:
exec:
command:
- "zkOk.sh"
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
exec:
command:
- "zkOk.sh"
initialDelaySeconds: 15
timeoutSeconds: 5
volumeMounts:
- name: datadir
mountPath: /var/lib/zookeeper
securityContext:
runAsUser: 1000
fsGroup: 1000
volumeClaimTemplates:
- metadata:
name: datadir
annotations:
volume.alpha.kubernetes.io/storage-class: anything
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 20Gi
创建
kubectl create -f zookeeper.yaml
mysql集群部署
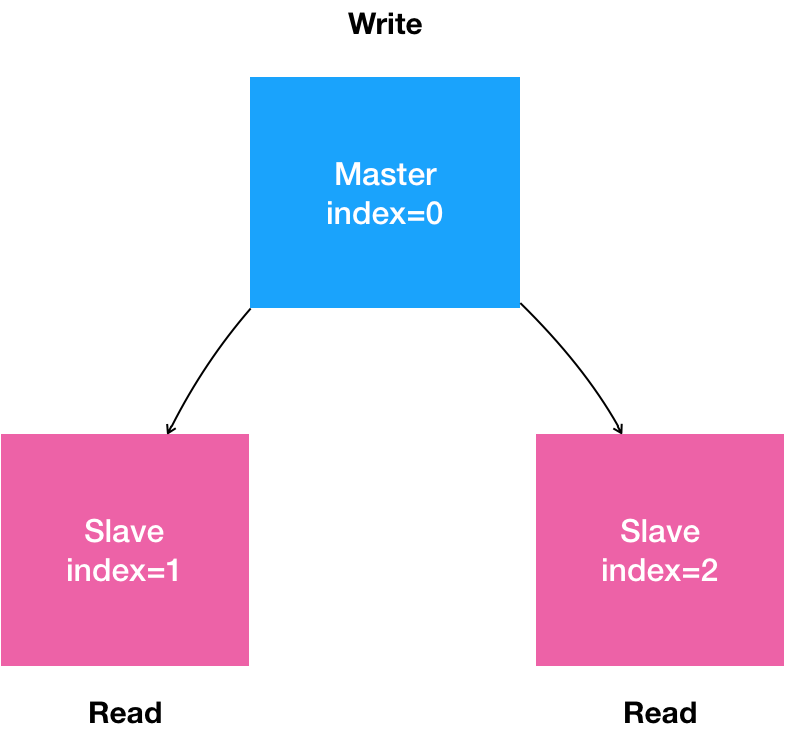
首先,用自然语言来描述一下我们想要部署的“有状态应用”。
- 是一个“主从复制”(Maser-Slave Replication)的 MySQL 集群;
- 有 1 个主节点(Master);
- 有多个从节点(Slave)
- 从节点需要能水平扩展;
- 所有的写操作,只能在主节点上执行;
- 读操作可以在所有节点上执行。
这就是一个非常典型的主从模式的 MySQL 集群了。
DaemonSet
daemonset主要依靠调度的tolerations功能和node affinity功能实现了每个节点上一个实例的控制。
DaemonSet保证在每个Node上都运行一个容器副本,常用来部署一些集群的日志、监控或者其他系统管理应用。典型的应用包括:
- 各种网络插件的 Agent 组件,都必须运行在每一个节点上,用来处理这个节点上的容器网络;
- 各种存储插件的 Agent 组件,也必须运行在每一个节点上,用来在这个节点上挂载远程存储目录,操作容器的 Volume 目录;
- 日志收集,比如fluentd,logstash等
- 系统监控,比如Prometheus Node Exporter,collectd,New Relic agent,Ganglia gmond等
- 系统程序,比如kube-proxy, kube-dns, glusterd, ceph等
使用Fluentd收集日志的例子:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: k8s.gcr.io/fluentd-elasticsearch:1.20
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
这个 DaemonSet,管理的是一个 fluentd-elasticsearch 镜像的 Pod。这个镜像的功能非常实用:通过 fluentd 将 Docker 容器里的日志转发到 ElasticSearch 中。可以看到,DaemonSet 跟 Deployment 其实非常相似,只不过是没有 replicas 字段;它也使用 selector 选择管理所有携带了 name=fluentd-elasticsearch 标签的 Pod。而这些 Pod 的模板,也是用 template 字段定义的。在这个字段中,我们定义了一个使用 fluentd-elasticsearch:1.20 镜像的容器,而且这个容器挂载了两个 hostPath 类型的 Volume,分别对应宿主机的 /var/log 目录和 /var/lib/docker/containers 目录。显然,fluentd 启动之后,它会从这两个目录里搜集日志信息,并转发给 ElasticSearch 保存。这样,我们通过 ElasticSearch 就可以很方便地检索这些日志了。需要注意的是,Docker 容器里应用的日志,默认会保存在宿主机的 /var/lib/docker/containers/{{. 容器 ID}}/{{. 容器 ID}}-json.log 文件里,所以这个目录正是 fluentd 的搜集目标。
DaemonSet 又是如何保证每个 Node 上有且只有一个被管理的 Pod 呢?这是一个典型的“控制器模型”能够处理的问题。
实现原理
1、选择node
DaemonSet Controller,首先从 Etcd 里获取所有的 Node 列表,然后遍历所有的 Node。这时,它就可以很容易地去检查,当前这个 Node 上是不是有一个携带了 name=fluentd-elasticsearch 标签的 Pod 在运行。而检查的结果,可能有这么三种情况:
- 没有这种 Pod,那么就意味着要在这个 Node 上创建这样一个 Pod;
- 有这种 Pod,但是数量大于 1,那就说明要把多余的 Pod 从这个 Node 上删除掉;
- 正好只有一个这种 Pod,那说明这个节点是正常的。
其中,删除节点(Node)上多余的 Pod 非常简单,直接调用 Kubernetes API 就可以了。但是,如何在指定的 Node 上创建新 Pod 呢?如果你已经熟悉了 Pod API 对象的话,那一定可以立刻说出答案:用 nodeSelector,选择 Node 的名字即可。不过,在 Kubernetes 项目里,nodeSelector 其实已经是一个将要被废弃的字段了。因为,现在有了一个新的、功能更完善的字段可以代替它,即:nodeAffinity。我们先来看看
指定Node节点
DaemonSet会忽略Node的unschedulable状态,有两种方式来指定Pod只运行在指定的Node节点上,上面说了现在基本使用:nodeAffinity:功能更丰富的Node选择器,比如支持集合操作
nodeAffinity示例
nodeAffinity目前支持两种:requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution,分别代表必须满足条件和优选条件。比如下面的例子代表调度到包含标签kubernetes.io/e2e-az-name并且值为e2e-az1或e2e-az2的Node上,并且优选还带有标签another-node-label-key=another-node-label-value的Node。
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: gcr.io/google_containers/pause:2.0
我们的 DaemonSet Controller 会在创建 Pod 的时候,自动在这个 Pod 的 API 对象里,加上这样一个 nodeAffinity 定义。其中,需要绑定的节点名字,正是当前正在遍历的这个 Node。当然,DaemonSet 并不需要修改用户提交的 YAML 文件里的 Pod 模板,而是在向 Kubernetes 发起请求之前,直接修改根据模板生成的 Pod 对象。
2、忽略不能调度的规则
此外,DaemonSet 还会给这个 Pod 自动加上另外一个与调度相关的字段,叫作 tolerations。这个字段意味着这个 Pod,会“容忍”(Toleration)某些 Node 的“污点”(Taint)。而 DaemonSet 自动加上的 tolerations 字段,格式如下所示
apiVersion: v1
kind: Pod
metadata:
name: with-toleration
spec:
tolerations:
- key: node.kubernetes.io/unschedulable
operator: Exists
effect: NoSchedule
这个 Toleration 的含义是:“容忍”所有被标记为 unschedulable“污点”的 Node;“容忍”的效果是允许调度。
而在正常情况下,被标记了 unschedulable“污点”的 Node,是不会有任何 Pod 被调度上去的(effect: NoSchedule)。可是,DaemonSet 自动地给被管理的 Pod 加上了这个特殊的 Toleration,就使得这些 Pod 可以忽略这个限制,继而保证每个节点上都会被调度一个 Pod。当然,如果这个节点有故障的话,这个 Pod 可能会启动失败,而 DaemonSet 则会始终尝试下去,直到 Pod 启动成功。
假如当前 DaemonSet 管理的,是一个网络插件的 Agent Pod,那么你就必须在这个 DaemonSet 的 YAML 文件里,给它的 Pod 模板加上一个能够“容忍”node.kubernetes.io/network-unavailable“污点”的 Toleration。正如下面这个例子所示:
...
template:
metadata:
labels:
name: network-plugin-agent
spec:
tolerations:
- key: node.kubernetes.io/network-unavailable
operator: Exists
effect: NoSchedule
在 Kubernetes 项目中,当一个节点的网络插件尚未安装时,这个节点就会被自动加上名为node.kubernetes.io/network-unavailable的“污点”。而通过这样一个 Toleration,调度器在调度这个 Pod 的时候,就会忽略当前节点上的“污点”,从而成功地将网络插件的 Agent 组件调度到这台机器上启动起来。这种机制,正是我们在部署 Kubernetes 集群的时候,能够先部署 Kubernetes 本身、再部署网络插件的根本原因。
你也可以在 Pod 模板里加上更多种类的 Toleration,从而利用 DaemonSet 达到自己的目的。比如,在这个 fluentd-elasticsearch DaemonSet 里,我就给它加上了这样的 Toleration:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
这是因为在默认情况下,Kubernetes 集群不允许用户在 Master 节点部署 Pod。因为,Master 节点默认携带了一个叫作node-role.kubernetes.io/master的“污点”。所以,为了能在 Master 节点上部署 DaemonSet 的 Pod,我就必须让这个 Pod“容忍”这个“污点”。
滚动升级
deamonset一样修改镜像就支持滚动升级的,和deployment一样。但是它的版本维护就有点不一样了。
在k8s中,所谓,一切皆对象!
在 Kubernetes 项目中,任何你觉得需要记录下来的状态,都可以被用 API 对象的方式实现。当然,“版本”也不例外。Kubernetes v1.7 之后添加了一个 API 对象,名叫 ControllerRevision,专门用来记录某种 Controller 对象的版本。比如,你可以通过如下命令查看 fluentd-elasticsearch 对应的 ControllerRevision:
$ kubectl get controllerrevision -n kube-system -l name=fluentd-elasticsearch
NAME CONTROLLER REVISION AGE
fluentd-elasticsearch-64dc6799c9 daemonset.apps/fluentd-elasticsearch 2 1h
而如果你使用 kubectl describe 查看这个 ControllerRevision 对象:
$ kubectl describe controllerrevision fluentd-elasticsearch-64dc6799c9 -n kube-system
Name: fluentd-elasticsearch-64dc6799c9
Namespace: kube-system
Labels: controller-revision-hash=2087235575
name=fluentd-elasticsearch
Annotations: deprecated.daemonset.template.generation=2
kubernetes.io/change-cause=kubectl set image ds/fluentd-elasticsearch fluentd-elasticsearch=k8s.gcr.io/fluentd-elasticsearch:v2.2.0 --record=true --namespace=kube-system
API Version: apps/v1
Data:
Spec:
Template:
$ Patch: replace
Metadata:
Creation Timestamp: <nil>
Labels:
Name: fluentd-elasticsearch
Spec:
Containers:
Image: k8s.gcr.io/fluentd-elasticsearch:v2.2.0
Image Pull Policy: IfNotPresent
Name: fluentd-elasticsearch
...
Revision: 2
Events: <none>
就会看到,这个 ControllerRevision 对象,实际上是在 Data 字段保存了该版本对应的完整的 DaemonSet 的 API 对象。并且,在 Annotation 字段保存了创建这个对象所使用的 kubectl 命令。接下来,我们可以尝试将这个 DaemonSet 回滚到 Revision=1 时的状态:
$ kubectl rollout undo daemonset fluentd-elasticsearch --to-revision=1 -n kube-system
daemonset.extensions/fluentd-elasticsearch rolled back
这个 kubectl rollout undo 操作,实际上相当于读取到了 Revision=1 的 ControllerRevision 对象保存的 Data 字段。而这个 Data 字段里保存的信息,就是 Revision=1 时这个 DaemonSet 的完整 API 对象。所以,现在 DaemonSet Controller 就可以使用这个历史 API 对象,对现有的 DaemonSet 做一次 PATCH 操作(等价于执行一次 kubectl apply -f “旧的 DaemonSet 对象”),从而把这个 DaemonSet“更新”到一个旧版本。这也是为什么,在执行完这次回滚完成后,你会发现,DaemonSet 的 Revision 并不会从 Revision=2 退回到 1,而是会增加成 Revision=3。这是因为,一个新的 ControllerRevision 被创建了出来。
StatefulSet 也是直接控制 Pod 对象的,所以也是使用 ControllerRevision 进行版本管理。在 Kubernetes 项目里,ControllerRevision 其实是一个通用的版本管理对象。这样,Kubernetes 项目就巧妙地避免了每种控制器都要维护一套冗余的代码和逻辑的问题。
job
depolyment,statefulset,deamonset主要编排的对象,都是“在线业务”,即:Long Running Task(长作业)。有一类作业显然不满足这样的条件,这就是“离线业务”,或者叫作 Batch Job(计算业务)。这种业务在计算完成后就直接退出了,而此时如果依然用 Deployment 来管理这种业务的话,就会发现 Pod 会在计算结束后退出,然后被 Deployment Controller 不断地重启,这就有问题了,更加不需要“滚动更新”这样的编排功能。
Job负责批量处理短暂的一次性任务 (short lived one-off tasks),即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
Kubernetes支持以下几种Job:
- 非并行Job:通常创建一个Pod直至其成功结束
- 固定结束次数的Job:设置.spec.completions,创建多个Pod,直到.spec.completions个Pod成功结束
- 带有工作队列的并行Job:设置.spec.Parallelism但不设置.spec.completions,当所有Pod结束并且至少一个成功时,Job就认为是成功
根据.spec.completions和.spec.Parallelism的设置,可以将Job划分为以下几种pattern:
- Job类型 使用示例 行为 completions Parallelism
- 一次性Job 数据库迁移 创建一个Pod直至其成功结束 1 1
- 固定结束次数的Job 处理工作队列的Pod 依次创建一个Pod运行直至completions个成功结束 2+ 1
- 固定结束次数的并行Job 多个Pod同时处理工作队列 依次创建多个Pod运行直至completions个成功结束 2+ 2+
- 并行Job 多个Pod同时处理工作队列 创建一个或多个Pod直至有一个成功结束 1 2+
Job Spec格式
spec.template格式同Pod
RestartPolicy仅支持Never或OnFailure
单个Pod时,默认Pod成功运行后Job即结束
.spec.completions标志Job结束需要成功运行的Pod个数,默认为1
.spec.parallelism标志并行运行的Pod的个数,默认为1
spec.activeDeadlineSeconds标志失败Pod的重试最大时间,超过这个时间不会继续重试
一个简单的例子:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
$ kubectl create -f ./job.yaml
job "pi" created
$ pods=$(kubectl get pods --selector=job-name=pi --output=jsonpath={.items..metadata.name})
$ kubectl logs $pods
3.141592653589793238462643383279502...
固定结束次数的Job示例
apiVersion: batch/v1
kind: Job
metadata:
name: busybox
spec:
completions: 3
template:
metadata:
name: busybox
spec:
containers:
- name: busybox
image: busybox
command: ["echo", "hello"]
restartPolicy: Never
CronJob
CronJob即定时任务,就类似于Linux系统的crontab,在指定的时间周期运行指定的任务。在Kubernetes 1.5,使用CronJob需要开启batch/v2alpha1 API,即–runtime-config=batch/v2alpha1。
CronJob Spec
.spec.schedule指定任务运行周期,格式同Cron
.spec.jobTemplate指定需要运行的任务,格式同Job
.spec.startingDeadlineSeconds指定任务开始的截止期限
.spec.concurrencyPolicy指定任务的并发策略,支持Allow、Forbid和Replace三个选项
实例
apiVersion: batch/v2alpha1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
创建
$ kubectl create -f cronjob.yaml
cronjob "hello" created
当然,也可以用kubectl run来创建一个CronJob:
kubectl run hello --schedule="*/1 * * * *" --restart=OnFailure --image=busybox -- /bin/sh -c "date; echo Hello from the Kubernetes cluster"
$ kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST-SCHEDULE
hello */1 * * * * False 0 <none>
$ kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
hello-1202039034 1 1 49s
$ pods=$(kubectl get pods --selector=job-name=hello-1202039034 --output=jsonpath={.items..metadata.name} -a)
$ kubectl logs $pods
Mon Aug 29 21:34:09 UTC 2016
Hello from the Kubernetes cluster
注意,删除cronjob的时候不会自动删除job,这些job可以用kubectl delete job来删除
$ kubectl delete cronjob hello
cronjob "hello" deleted
总结
这边讲解的就是原生的资源定义和使用,其实都是通过控制器来完成基本的控制的,控制器的源码在kube-controller-manager中。
k8s自定义控制器
日常业务开发过程中,虽然常规的资源基本满足需求,但是这些常规的资源大多仅仅是代表相对底层、通用的概念的对象, 某些情况下我们总是想根据业务定制我们的资源类型,并且利用kubernetes的声明式API,对资源的增删改查进行监听并作出具体的业务功能。随着Kubernetes生态系统的持续发展,越来越多高层次的对象将会不断涌现,比起目前使用的对象,新对象将更加专业化。
在这一块,目前业界比较多使用自定义的就是阿里云,其开源的项目kruise包含来很多的使用场景。具体可以看我的关于kruise的文章。
最初开发流程
作为一个k8s研发,会写控制器是一项最基本的工作,我们最初是参考官方提供的sample-controller来完成控制器开发的,k8s自定义controller开发的整个过程:
- 创建自定义API对象CRD(Custom Resource Definition),令k8s明白我们自定义的API对象;
- 编写代码,将CRD的情况写入对应的代码中,然后通过自动代码生成工具,将controller之外的informer,client等内容较为固定的代码通过工具生成;
- 编写controller,在里面判断实际情况是否达到了API对象的声明情况,如果未达到,就要进行实际业务处理,而这也是controller的通用做法;
实际编码过程并不复杂,动手编写的文件如下:
├── controller.go
├── main.go
└── pkg
├── apis
│ └── test
│ ├── register.go
│ └── v1
│ ├── doc.go
│ ├── register.go
│ └── types.go
└── signals
├── signal.go
├── signal_posix.go
└── signal_windows.go
下面我们以实例来看看具体的开发。
定义CRD
创建jcy.yaml文件
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
# metadata.name的内容是由"复数名.分组名"构成,如下,jcys是复数名,test.k8s.io是分组名
name: jcy.test.k8s.io
spec:
# 分组名,在REST API中也会用到的,格式是: /apis/分组名/CRD版本
group: test.k8s.io
# list of versions supported by this CustomResourceDefinition
versions:
- name: v1
# 是否有效的开关.
served: true
# 只有一个版本能被标注为storage
storage: true
# 范围是属于namespace的
scope: Namespaced
names:
# 复数名
plural: jcys
# 单数名
singular: jcy
# 类型名
kind: Jcy
# 简称,就像service的简称是svc
shortNames:
- j
yaml中的关键字段
- group:设置API所属的组,将其映射为API URL中的 “/apis/” 下一级目录。它是逻辑上相关的Kinds集合,自定义的
- scope:该API的生效范围,可选项为Namespaced和Cluster。
- version:每个 Group 可以存在多个版本。例如,v1alpha1,然后升为 v1beta1,最后稳定为 v1 版本。
- ames:CRD的名称,包括单数、复数、kind、所属组等名称定义
在jcy.yaml所在目录执行命令kubectl apply -f jcy.yaml,即可在k8s环境创建Jcy的定义,今后如果发起对类型为Jcy的对象的处理,k8s的api server就能识别到该对象类型了,如下所示,可以用kubectl get crd和kubectl describe crd stu命令查看更多细节,stu是在jcy.yaml中定义的简称
[root@master custom_controller]# kubectl apply -f jcy.yaml
customresourcedefinition.apiextensions.k8s.io/jcy.test.k8s.io created
[root@master custom_controller]# kubectl get crd
NAME CREATED AT
jcy.test.k8s.io 2019-03-30T13:33:13Z
[root@master custom_controller]# kubectl describe crd stu
Name: jcys.test.k8s.io
Namespace:
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"apiextensions.k8s.io/v1beta1","kind":"CustomResourceDefinition","metadata":{"annotations":{},"name":"jcys.test...
API Version: apiextensions.k8s.io/v1beta1
Kind: CustomResourceDefinition
Metadata:
Creation Timestamp: 2019-03-30T13:33:13Z
Generation: 1
Resource Version: 292010
Self Link: /apis/apiextensions.k8s.io/v1beta1/customresourcedefinitions/jcys.test.k8s.io
UID: 5e4ceb6e-52f0-11e9-96e1-000c29f1f9c9
如果您已配置好etcdctl,可以访问k8s的etcd上存储的数据,那么执行以下命令,就可以看到新的CRD已经保存在etcd中了
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt --key=/etc/kubernetes/pki/etcd/healthcheck-client.key get /registry/apiextensions.k8s.io/customresourcedefinitions/ --prefix
/registry/apiextensions.k8s.io/customresourcedefinitions/jcys.test.k8s.io{
"kind": "CustomResourceDefinition",
"apiVersion": "apiextensions.k8s.io/v1beta1",
"metadata": {
"name": "jcys.test.k8s.io",
"uid": "5e4ceb6e-52f0-11e9-96e1-000c29f1f9c9",
"generation": 1,
"creationTimestamp": "2019-03-30T13:33:13Z",
"annotations": {
"kubectl.kubernetes.io/last-applied-configuration": "{\"apiVersion\":\"apiextensions.k8s.io/v1beta1\",\"kind\":\"CustomResourceDefinition\",\"metadata\":{\"annotations\":{},\"name\":\"jcys.test.k8s.io\"},\"spec\":{\"group\":\"test.k8s.io\",\"names\":{\"kind\":\"Jcy\",\"plural\":\"jcys\",\"shortNames\":[\"stu\"],\"singular\":\"jcy\"},\"scope\":\"Namespaced\",\"versions\":[{\"name\":\"v1\",\"served\":true,\"storage\":true}]}}\n"
}
},
"spec": {
"group": "test.k8s.io",
"version": "v1",
"names": {
"plural": "jcys",
"singular": "jcy",
"shortNames": [
"stu"
],
"kind": "Jcy",
"listKind": "JcyList"
},
"scope": "Namespaced",
"versions": [
{
"name": "v1",
"served": true,
"storage": true
}
],
"conversion": {
"strategy": "None"
}
},
"status": {
"conditions": [
{
"type": "NamesAccepted",
"status": "True",
"lastTransitionTime": "2019-03-30T13:33:13Z",
"reason": "NoConflicts",
"message": "no conflicts found"
},
{
"type": "Established",
"status": "True",
"lastTransitionTime": null,
"reason": "InitialNamesAccepted",
"message": "the initial names have been accepted"
}
],
"acceptedNames": {
"plural": "jcys",
"singular": "jcy",
"shortNames": [
"stu"
],
"kind": "Jcy",
"listKind": "JcyList"
},
"storedVersions": [
"v1"
]
}
}
下面就可以创建stu类型的对象了,比如我们创建object-jcy.yaml
apiVersion: test.k8s.io/v1
kind: Jcy
metadata:
name: object-jcy
spec:
name: "张三"
school: "深圳中学"
这个资源对象跟定义pod差不多,它的主要信息都是来源上面的定义,Kind是Jcy,apiVersion就是group/version,除了这些设置,还需要在spec端设置相应的参数,一般是开发者自定义定制的。
在object-jcy.yaml文件所在目录执行命令kubectl apply -f object-jcy.yaml,会看到提示创建成功
[root@master custom_controller]# kubectl apply -f object-jcy.yaml
jcy.test.k8s.io/object-jcy created
行命令kubectl get stu可见已创建成功的Jcy对象
[root@master custom_controller]# kubectl get jcy
NAME AGE
object-jcy 15s
控制台输出的就是该Jcy对象存储在etcd中的内容
{
"apiVersion": "test.k8s.io/v1",
"kind": "Jcy",
"metadata": {
"annotations": {
"kubectl.kubernetes.io/last-applied-configuration": "{\"apiVersion\":\"test.k8s.io/v1\",\"kind\":\"Jcy\",\"metadata\":{\"annotations\":{},\"name\":\"object-jcy\",\"namespace\":\"default\"},\"spec\":{\"name\":\"张三\",\"school\":\"深圳中学\"}}\n"
},
"creationTimestamp": "2019-03-31T02:56:25Z",
"generation": 1,
"name": "object-jcy",
"namespace": "default",
"uid": "92927d0d-5360-11e9-9d2a-000c29f1f9c9"
},
"spec": {
"name": "张三",
"school": "深圳中学"
}
}
至此,自定义API对象(也就是CRD)就创建成功了。
CRD控制器的原理
自定义控制器的工作原理,我们在上面已经详细说明了,很多东西直接是用工具生成的。
如果仅仅是在etcd保存Jcy对象是没有什么意义的,试想通过deployment创建pod时,如果只在etcd创建pod对象,而不去node节点创建容器,那这个pod对象只是一条数据而已,没有什么实质性作用,其他对象如service、pv也是如此。
代码实际上可以通过code-generator官方提供的工具生成的。
将controller之外的informer,client等内容较为固定的代码通过工具生成
从上图可以发现整个逻辑还是比较复杂的,为了简化我们的自定义controller开发,k8s的大师们利用自动代码生成工具将controller之外的事情都做好了,我们只要专注于controller的开发就好。
1、$GOPATH/src/目录下创建一个文件夹k8s_customize_controller:
2、进入文件夹k8s_customize_controller,执行如下命令创建三层目录:
mkdir -p pkg/apis/jcy
3、在新建的jcy目录下创建文件register.go,内容如下:
package jcy
const (
GroupName = "test.k8s.io"
Version = "v1"
)
4、在新建的jcy目录下创建名为v1的文件夹;
5、在新建的v1文件夹下创建文件doc.go,内容如下:
// +k8s:deepcopy-gen=package
// +groupName=test.k8s.io
package v1
上述代码中的两行注释,都是代码生成工具会用到的,一个是声明为整个v1包下的类型定义生成DeepCopy方法,另一个声明了这个包对应的API的组名,和CRD中的组名一致;
6、在v1文件夹下创建文件types.go,里面定义了Jcy对象的具体内容:
package v1
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
// +genclient
// +genclient:noStatus
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
type Jcy struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec JcySpec `json:"spec"`
}
type JcySpec struct {
name string `json:"name"`
school string `json:"school"`
}
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// JcytList is a list of Jcy resources
type JcytList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata"`
Items []Jcy `json:"items"`
}
从上述源码可见,Jcy对象的内容已经被设定好,主要有name和school这两个字段,表示学生的名字和所在学校,因此创建Jcy对象的时候内容就要和这里匹配了;
在这个文件中也有几个k8s的Annotation 风格的注释
+genclient 这段注解的意思是:请为下面资源类型生成对应的 Client 代码。
- +genclient 这段注解的意思是:请为下面资源类型生成对应的 Client 代码。
- +genclient:noStatus 的意思是:这个 API 资源类型定义里,没有 Status 字段,因为Mydemo才是主类型,所以 +genclient 要写在Mydemo之上,不用写在MydemoList之上,这时要细心注意的。
- +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object 的意思是,请在生成 DeepCopy 的时候,实现 Kubernetes 提供的 runtime.Object 接口。否则,在某些版本的 Kubernetes 里,你的这个类型定义会出现编译错误。
7、在v1目录下创建register.go文件,此文件的作用是通过addKnownTypes方法使得client可以知道Jcy类型的API对象:
package v1
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/apimachinery/pkg/runtime/schema"
"k8s_customize_controller/pkg/apis/test"
)
var SchemeGroupVersion = schema.GroupVersion{
Group: Jcy.GroupName,
Version: Jcy.Version,
}
var (
SchemeBuilder = runtime.NewSchemeBuilder(addKnownTypes)
AddToScheme = SchemeBuilder.AddToScheme
)
func Resource(resource string) schema.GroupResource {
return SchemeGroupVersion.WithResource(resource).GroupResource()
}
func Kind(kind string) schema.GroupKind {
return SchemeGroupVersion.WithKind(kind).GroupKind()
}
func addKnownTypes(scheme *runtime.Scheme) error {
scheme.AddKnownTypes(
SchemeGroupVersion,
&Jcy{},
&JcyList{},
)
// register the type in the scheme
metav1.AddToGroupVersion(scheme, SchemeGroupVersion)
return nil
}
至此,为自动生成代码做的准备工作已经完成了,目前为止,$GOPATH/src目录下的文件和目录结构是这样的:
[root@golang src]# tree
.
└── k8s_customize_controller
└── pkg
└── apis
└── jcy
├── register.go
└── v1
├── doc.go
├── register.go
└── types.go
5 directories, 4 files
8、执行以下命令,会先下载依赖包,再下载代码生成工具code-generator,再执行代码生成脚本generate-groups.sh:
cd $GOPATH/src \
&& go get -u k8s.io/apimachinery/pkg/apis/meta/v1 \
&& go get -u k8s.io/code-generator/... \
&& cd $GOPATH/src/k8s.io/code-generator \
&& ./generate-groups.sh all \
k8s_customize_controller/pkg/client \
k8s_customize_controller/pkg/apis \
test:v1
如果代码写得没有问题,会看到以下输出:
Generating deepcopy funcs
Generating clientset for test:v1 at k8s_customize_controller/pkg/client/clientset
Generating listers for test:v1 at k8s_customize_controller/pkg/client/listers
Generating informers for test:v1 at k8s_customize_controller/pkg/client/informers
此时再去$GOPATH/src/k8s_customize_controller目录下执行tree命令,可见已生成了很多内容:
[root@master k8s_customize_controller]# tree
.
└── pkg
├── apis
│ └── jcy
│ ├── register.go
│ └── v1
│ ├── doc.go
│ ├── register.go
│ ├── types.go
│ └── zz_generated.deepcopy.go
└── client
├── clientset
│ └── versioned
│ ├── clientset.go
│ ├── doc.go
│ ├── fake
│ │ ├── clientset_generated.go
│ │ ├── doc.go
│ │ └── register.go
│ ├── scheme
│ │ ├── doc.go
│ │ └── register.go
│ └── typed
│ └── test
│ └── v1
│ ├── test_client.go
│ ├── doc.go
│ ├── fake
│ │ ├── doc.go
│ │ ├── fake_test_client.go
│ │ └── fake_jcy.go
│ ├── generated_expansion.go
│ └── jcy.go
├── informers
│ └── externalversions
│ ├── test
│ │ ├── interface.go
│ │ └── v1
│ │ ├── interface.go
│ │ └── jcy.go
│ ├── factory.go
│ ├── generic.go
│ └── internalinterfaces
│ └── factory_interfaces.go
└── listers
└── test
└── v1
├── expansion_generated.go
└── jcy.go
21 directories, 27 files
如上所示,zz_generated.deepcopy.go就是DeepCopy代码文件,client目录下的内容都是客户端相关代码,在开发controller时会用到;
client目录下的clientset、informers、listers的身份和作用可以和前面的原理图中的不同模块结合来理解;
至此,自动生成代码的步骤已经完成。下面就是写我们的controller的逻辑了
编写controller代码
在k8s_customize_controller目录下创建controller.go
package main
import (
"fmt"
"time"
"github.com/golang/glog"
corev1 "k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/api/errors"
"k8s.io/apimachinery/pkg/util/runtime"
utilruntime "k8s.io/apimachinery/pkg/util/runtime"
"k8s.io/apimachinery/pkg/util/wait"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/kubernetes/scheme"
typedcorev1 "k8s.io/client-go/kubernetes/typed/core/v1"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/tools/record"
"k8s.io/client-go/util/workqueue"
jcy "github.com/kingjcy/k8s-controller-custom-resource/pkg/apis/jcy/v1"
clientset "github.com/kingjcy/k8s-controller-custom-resource/pkg/client/clientset/versioned"
jcyscheme "github.com/kingjcy/k8s-controller-custom-resource/pkg/client/clientset/versioned/scheme"
informers "github.com/kingjcy/k8s-controller-custom-resource/pkg/client/informers/externalversions/jcy/v1"
listers "github.com/kingjcy/k8s-controller-custom-resource/pkg/client/listers/jcy/v1"
)
const controllerAgentName = "jcy-controller"
const (
SuccessSynced = "Synced"
MessageResourceSynced = "Jcy synced successfully"
)
// Controller is the controller implementation for Jcy resources
type Controller struct {
// kubeclientset is a standard kubernetes clientset
kubeclientset kubernetes.Interface
// jcyclientset is a clientset for our own API group
jcyclientset clientset.Interface
jcysLister listers.JcyLister
jcysSynced cache.InformerSynced
workqueue workqueue.RateLimitingInterface
recorder record.EventRecorder
}
// NewController returns a new jcy controller
func NewController(
kubeclientset kubernetes.Interface,
jcyclientset clientset.Interface,
jcyInformer informers.jcyInformer) *Controller {
utilruntime.Must(jcyscheme.AddToScheme(scheme.Scheme))
glog.V(4).Info("Creating event broadcaster")
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartLogging(glog.Infof)
eventBroadcaster.StartRecordingToSink(&typedcorev1.EventSinkImpl{Interface: kubeclientset.CoreV1().Events("")})
recorder := eventBroadcaster.NewRecorder(scheme.Scheme, corev1.EventSource{Component: controllerAgentName})
//使用client 和前面创建的 Informer,初始化了自定义控制器结构体
controller := &Controller{
kubeclientset: kubeclientset,
jcyclientset: jcyclientset,
jcysLister: jcyInformer.Lister(),
jcysSynced: jcyInformer.Informer().HasSynced,
workqueue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "Jcys"),
recorder: recorder,
}
//jcyInformer注册了三个 Handler(AddFunc、UpdateFunc 和 DeleteFunc),分别对应 API 对象的“添加”“更新”和“删除”事件。而具体的处理操作,都是将该事件对应的 API 对象加入到工作队列中
glog.Info("Setting up event handlers")
// Set up an event handler for when Jcy resources change
jcyInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.enqueueJcy,
UpdateFunc: func(old, new interface{}) {
oldJcy := old.(*test.Jcy)
newJcy := new.(*test.Jcy)
if oldJcy.ResourceVersion == newJcy.ResourceVersion {
//版本一致,就表示没有实际更新的操作,立即返回
return
}
controller.enqueueJcy(new)
},
DeleteFunc: controller.enqueueJcyForDelete,
})
return controller
}
//在此处开始controller的业务,也就是原理图中的Control Loop的部分,启动控制循环的逻辑非常简单,就是同步+循环监听任务。而这个循环监听任务就是我们真正的业务实现部分了
func (c *Controller) Run(threadiness int, stopCh <-chan struct{}) error {
defer runtime.HandleCrash()
defer c.workqueue.ShutDown()
glog.Info("开始controller业务,开始一次缓存数据同步")
if ok := cache.WaitForCacheSync(stopCh, c.jcysSynced); !ok {
return fmt.Errorf("failed to wait for caches to sync")
}
glog.Info("worker启动")
for i := 0; i < threadiness; i++ {
go wait.Until(c.runWorker, time.Second, stopCh)
}
glog.Info("worker已经启动")
<-stopCh
glog.Info("worker已经结束")
return nil
}
//runWorker是一个不断运行的方法,并且一直会调用 c.processNextWorkItem 从workqueue读取和读取消息
func (c *Controller) runWorker() {
for c.processNextWorkItem() {
}
}
// 从workqueue取数据处理
func (c *Controller) processNextWorkItem() bool {
obj, shutdown := c.workqueue.Get()
if shutdown {
return false
}
// We wrap this block in a func so we can defer c.workqueue.Done.
err := func(obj interface{}) error {
defer c.workqueue.Done(obj)
var key string
var ok bool
if key, ok = obj.(string); !ok {
c.workqueue.Forget(obj)
runtime.HandleError(fmt.Errorf("expected string in workqueue but got %#v", obj))
return nil
}
// 在syncHandler中处理业务
if err := c.syncHandler(key); err != nil {
return fmt.Errorf("error syncing '%s': %s", key, err.Error())
}
c.workqueue.Forget(obj)
glog.Infof("Successfully synced '%s'", key)
return nil
}(obj)
if err != nil {
runtime.HandleError(err)
return true
}
return true
}
// 处理,尝试从 Informer 维护的缓存中拿到了它所对应的对象
func (c *Controller) syncHandler(key string) error {
// Convert the namespace/name string into a distinct namespace and name
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
runtime.HandleError(fmt.Errorf("invalid resource key: %s", key))
return nil
}
// 从缓存中取对象
jcy, err := c.jcysLister.jcys(namespace).Get(name)
if err != nil {
// 如果Jcy对象被删除了,就会走到这里,所以应该在这里加入执行
if errors.IsNotFound(err) {
glog.Infof("Jcy对象被删除,请在这里执行实际的删除业务: %s/%s ...", namespace, name)
return nil
}
runtime.HandleError(fmt.Errorf("failed to list jcy by: %s/%s", namespace, name))
return err
}
glog.Infof("这里是jcy对象的期望状态: %#v ...", jcy)
glog.Infof("实际状态是从业务层面得到的,此处应该去的实际状态,与期望状态做对比,并根据差异做出响应(新增或者删除)")
c.recorder.Event(jcy, corev1.EventTypeNormal, SuccessSynced, MessageResourceSynced)
return nil
}
// 数据先放入缓存,再入队列
func (c *Controller) enqueueJcy(obj interface{}) {
var key string
var err error
// 将对象放入缓存
if key, err = cache.MetaNamespaceKeyFunc(obj); err != nil {
runtime.HandleError(err)
return
}
// 将key放入队列
c.workqueue.AddRateLimited(key)
}
// 删除操作
func (c *Controller) enqueueJcyForDelete(obj interface{}) {
var key string
var err error
// 从缓存中删除指定对象
key, err = cache.DeletionHandlingMetaNamespaceKeyFunc(obj)
if err != nil {
runtime.HandleError(err)
return
}
//再将key放入队列
c.workqueue.AddRateLimited(key)
}
上述代码有以下几处关键点:
- 创建controller的NewController方法中,定义了收到Jcy对象的增删改消息时的具体处理逻辑,除了同步本地缓存,就是将该对象的key放入消息中;
- 实际处理消息的方法是syncHandler,这里面可以添加实际的业务代码,来响应Jcy对象的增删改情况,达到业务目的;
2、在$GOPATH/src/k8s_customize_controller/pkg目录下新建目录signals,在signals目录下新建文件signal_posix.go
// +build !windows
package signals
import (
"os"
"syscall"
)
var shutdownSignals = []os.Signal{os.Interrupt, syscall.SIGTERM}
在signals目录下新建文件signal.go
package signals
import (
"os"
"os/signal"
)
var onlyOneSignalHandler = make(chan struct{})
func SetupSignalHandler() (stopCh <-chan struct{}) {
close(onlyOneSignalHandler) // panics when called twice
stop := make(chan struct{})
c := make(chan os.Signal, 2)
signal.Notify(c, shutdownSignals...)
go func() {
<-c
close(stop)
<-c
os.Exit(1) // second signal. Exit directly.
}()
return stop
}
3、接下来可以编写main.go了,在k8s_customize_controller目录下创建main.go文件
package main
import (
"flag"
"time"
"github.com/golang/glog"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/clientcmd"
// Uncomment the following line to load the gcp plugin (only required to authenticate against GKE clusters).
// _ "k8s.io/client-go/plugin/pkg/client/auth/gcp"
clientset "k8s_customize_controller/pkg/client/clientset/versioned"
informers "k8s_customize_controller/pkg/client/informers/externalversions"
"k8s_customize_controller/pkg/signals"
)
var (
masterURL string
kubeconfig string
)
func main() {
flag.Parse()
// 处理信号量
stopCh := signals.SetupSignalHandler()
// 处理入参
cfg, err := clientcmd.BuildConfigFromFlags(masterURL, kubeconfig)
if err != nil {
glog.Fatalf("Error building kubeconfig: %s", err.Error())
}
kubeClient, err := kubernetes.NewForConfig(cfg)
if err != nil {
glog.Fatalf("Error building kubernetes clientset: %s", err.Error())
}
jcyClient, err := clientset.NewForConfig(cfg)
if err != nil {
glog.Fatalf("Error building example clientset: %s", err.Error())
}
jcyInformerFactory := informers.NewSharedInformerFactory(jcyClient, time.Second*30)
//得到controller
controller := NewController(kubeClient, jcyClient,
jcyInformerFactory.Bolingcavalry().V1().Jcys())
//启动informer
go jcyInformerFactory.Start(stopCh)
//controller开始处理消息
if err = controller.Run(2, stopCh); err != nil {
glog.Fatalf("Error running controller: %s", err.Error())
}
}
func init() {
flag.StringVar(&kubeconfig, "kubeconfig", "", "Path to a kubeconfig. Only required if out-of-cluster.")
flag.StringVar(&masterURL, "master", "", "The address of the Kubernetes API server. Overrides any value in kubeconfig. Only required if out-of-cluster.")
}
部署验证
编译和启动
在$GOPATH/src/k8s_customize_controller目录下,执行以下命令
go get k8s.io/client-go/kubernetes/scheme \
&& go get github.com/golang/glog \
&& go get k8s.io/kube-openapi/pkg/util/proto \
&& go get k8s.io/utils/buffer \
&& go get k8s.io/utils/integer \
&& go get k8s.io/utils/trace
- 上述脚本将编译过程中依赖的库通过go get方式进行获取,属于笨办法,更好的方法是选用一种包依赖工具,具体的可以参照k8s的官方demo,这个代码中同时提供了godep和vendor两种方式来处理上面的包依赖问题,地址是:https://github.com/kubernetes/sample-controller
- 解决了包依赖问题后,在$GOPATH/src/k8s_customize_controller目录下执行命令go build,即可在当前目录生成k8s_customize_controller文件;
- 将文件k8s_customize_controller复制到k8s环境中,记得通过chmod a+x命令给其可执行权限;
- 执行命令./k8s_customize_controller -kubeconfig=$HOME/.kube/config -alsologtostderr=true,会立即启动controller,看到控制台输出如下
启动
[root@master 31]# ./k8s_customize_controller -kubeconfig=$HOME/.kube/config -alsologtostderr=true
I0331 23:27:17.909265 21540 controller.go:72] Setting up event handlers
I0331 23:27:17.909450 21540 controller.go:96] 开始controller业务,开始一次缓存数据同步
I0331 23:27:18.110448 21540 controller.go:101] worker启动
I0331 23:27:18.110516 21540 controller.go:106] worker已经启动
I0331 23:27:18.110653 21540 controller.go:181] 这里是jcy对象的期望状态: &v1.Jcy{TypeMeta:v1.TypeMeta{Kind:"Jcy", APIVersion:"test.k8s.io/v1"}, ObjectMeta:v1.ObjectMeta{Name:"object-jcy", GenerateName:"", Namespace:"default", SelfLink:"/apis/test.k8s.io/v1/namespaces/default/jcys/object-jcy", UID:"92927d0d-5360-11e9-9d2a-000c29f1f9c9", ResourceVersion:"310395", Generation:1, CreationTimestamp:v1.Time{Time:time.Time{wall:0x0, ext:63689597785, loc:(*time.Location)(0x1f9c200)}}, DeletionTimestamp:(*v1.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string{"kubectl.kubernetes.io/last-applied-configuration":"{\"apiVersion\":\"test.k8s.io/v1\",\"kind\":\"Jcy\",\"metadata\":{\"annotations\":{},\"name\":\"object-jcy\",\"namespace\":\"default\"},\"spec\":{\"name\":\"张三\",\"school\":\"深圳中学\"}}\n"}, OwnerReferences:[]v1.OwnerReference(nil), Initializers:(*v1.Initializers)(nil), Finalizers:[]string(nil), ClusterName:"", ManagedFields:[]v1.ManagedFieldsEntry(nil)}, Spec:v1.JcySpec{name:"", school:""}} ...
至此,自定义controller已经启动成功了,并且从缓存中获取到了上一章中创建的对象的信息,接下来我们在k8s环境对Jcy对象做增删改,看看controller是否能做出响应;
验证controller
新开一个窗口连接到k8s环境,新建一个名为new-jcy.yaml的文件,内容如下:
apiVersion: test.k8s.io/v1
kind: Jcy
metadata:
name: new-jcy
spec:
name: "李四"
school: "深圳小学"
在new-jcy.yaml所在目录执行命令kubectl apply -f new-jcy.yaml;
返回controller所在的控制台窗口,发现新输出了如下内容,可见新增jcy对象的事件已经被controller监听并处理:
I0331 23:43:03.789894 21540 controller.go:181] 这里是jcy对象的期望状态: &v1.Jcy{TypeMeta:v1.TypeMeta{Kind:"", APIVersion:""}, ObjectMeta:v1.ObjectMeta{Name:"new-jcy", GenerateName:"", Namespace:"default", SelfLink:"/apis/test.k8s.io/v1/namespaces/default/jcys/new-jcy", UID:"abcd77d6-53cb-11e9-9d2a-000c29f1f9c9", ResourceVersion:"370653", Generation:1, CreationTimestamp:v1.Time{Time:time.Time{wall:0x0, ext:63689643783, loc:(*time.Location)(0x1f9c200)}}, DeletionTimestamp:(*v1.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string{"kubectl.kubernetes.io/last-applied-configuration":"{\"apiVersion\":\"test.k8s.io/v1\",\"kind\":\"Jcy\",\"metadata\":{\"annotations\":{},\"name\":\"new-jcy\",\"namespace\":\"default\"},\"spec\":{\"name\":\"李四\",\"school\":\"深圳小学\"}}\n"}, OwnerReferences:[]v1.OwnerReference(nil), Initializers:(*v1.Initializers)(nil), Finalizers:[]string(nil), ClusterName:"", ManagedFields:[]v1.ManagedFieldsEntry(nil)}, Spec:v1.JcySpec{name:"", school:""}} ...
I0331 23:43:03.790076 21540 controller.go:182] 实际状态是从业务层面得到的,此处应该去的实际状态,与期望状态做对比,并根据差异做出响应(新增或者删除)
I0331 23:43:03.790120 21540 controller.go:145] Successfully synced 'default/new-jcy'
I0331 23:43:03.790141 21540 event.go:209] Event(v1.ObjectReference{Kind:"Jcy", Namespace:"default", Name:"new-jcy", UID:"abcd77d6-53cb-11e9-9d2a-000c29f1f9c9", APIVersion:"test.k8s.io/v1", ResourceVersion:"370653", FieldPath:""}): type: 'Normal' reason: 'Synced' Jcy synced successfully
接下来您也可以尝试修改和删除已有的Jcy对象,观察controller控制台的输出,确定是否已经监听到所有jcy变化的事件,例如删除的事件日志如下:
I0331 23:44:37.236090 21540 controller.go:171] Jcy对象被删除,请在这里执行实际的删除业务: default/new-jcy ...
I0331 23:44:37.236118 21540 controller.go:145] Successfully synced 'default/new-jcy'
kubebuilder
Kubebuilder 的工作流程如下:
- 创建一个新的工程目录
- 创建一个或多个资源 API CRD 然后将字段添加到资源
- 在控制器中实现协调循环(reconcile loop),watch 额外的资源
- 在集群中运行测试(自动安装 CRD 并自动启动控制器)
- 更新引导集成测试测试新字段和业务逻辑
- 使用用户提供的 Dockerfile 构建和发布容器
依赖
- go version v1.15+.
- docker version 17.03+.
- kubectl version v1.11.3+.
- kustomize v3.1.0+
- 能够访问 Kubernetes v1.11.3+ 集群
- 版本:2.3.1
还有一些kubebuilder依赖的重要库
安装
直接去github项目上下载release对应的系统文件,或者使用命令下载
os=$(go env GOOS)
arch=$(go env GOARCH)
# 下载 kubebuilder 并解压到 tmp 目录中
curl -L https://go.kubebuilder.io/dl/2.3.1/${os}/${arch} | tar -xz -C /tmp/
然后将其放到可执行的路径下,比如
sudo mv /tmp/kubebuilder_2.3.1_${os}_${arch} /usr/local/kubebuilder
export PATH=$PATH:/usr/local/kubebuilder/bin
使用
创建一个项目
创建一个目录,然后在里面运行 kubebuilder init 命令,初始化一个新项目,–domain flag arg 来指定 api group。示例如下。
mkdir $GOPATH/src/example
cd $GOPATH/src/example
kubebuilder init --domain test
当项目创建好之后,会提醒你是否下载依赖,然后你会发现大半个 Kubernetes 的代码已经在你 GOPATH 里了,这是的目录如下
├── Dockerfile 制作镜像的dockerfile
├── Makefile
├── PROJECT
├── bin
│ └── manager
├── config
│ ├── certmanager
│ │ ├── certificate.yaml
│ │ ├── kustomization.yaml
│ │ └── kustomizeconfig.yaml
│ ├── default
│ │ ├── kustomization.yaml
│ │ ├── manager_auth_proxy_patch.yaml
│ │ ├── manager_webhook_patch.yaml
│ │ └── webhookcainjection_patch.yaml
│ ├── manager
│ │ ├── kustomization.yaml
│ │ └── manager.yaml
│ ├── prometheus
│ │ ├── kustomization.yaml
│ │ └── monitor.yaml
│ ├── rbac
│ │ ├── auth_proxy_client_clusterrole.yaml
│ │ ├── auth_proxy_role.yaml
│ │ ├── auth_proxy_role_binding.yaml
│ │ ├── auth_proxy_service.yaml
│ │ ├── kustomization.yaml
│ │ ├── leader_election_role.yaml
│ │ ├── leader_election_role_binding.yaml
│ │ └── role_binding.yaml
│ └── webhook
│ ├── kustomization.yaml
│ ├── kustomizeconfig.yaml
│ └── service.yaml
├── go.mod
├── go.sum
├── hack
│ └── boilerplate.go.txt
└── main.go
可见是一堆yaml文件。
创建API
运行下面的命令,创建一个新的 API(组/版本)为 “webapp.test(这个test就是前面init的domain)/v1”,并在上面创建新的 Kind(CRD) “Jcy”。
kubebuilder create api --group webapp --version v1 --kind Jcy
我们来看看对应的生成的目录结构
├── Dockerfile
├── Makefile
├── PROJECT
├── api
│ └── v1
│ ├── groupversion_info.go 包含了关于 group-version 的一些元数据
│ ├── jcy_types.go 数据结构
│ └── zz_generated.deepcopy.go 包含了前述 runtime.Object 接口的自动实现,这些实现标记了代表 Kinds 的所有根类型。
├── bin
│ └── manager
├── config
│ ├── certmanager
│ │ ├── certificate.yaml
│ │ ├── kustomization.yaml
│ │ └── kustomizeconfig.yaml
│ ├── crd 部署crd的yaml
│ │ ├── kustomization.yaml
│ │ ├── kustomizeconfig.yaml
│ │ └── patches
│ │ ├── cainjection_in_jcies.yaml
│ │ └── webhook_in_jcies.yaml
│ ├── default
│ │ ├── kustomization.yaml
│ │ ├── manager_auth_proxy_patch.yaml
│ │ ├── manager_webhook_patch.yaml
│ │ └── webhookcainjection_patch.yaml
│ ├── manager 部署controller的yaml,以pod形式启动
│ │ ├── kustomization.yaml
│ │ └── manager.yaml
│ ├── prometheus
│ │ ├── kustomization.yaml
│ │ └── monitor.yaml
│ ├── rbac rbac权限运行的时候也是要用的
│ │ ├── auth_proxy_client_clusterrole.yaml
│ │ ├── auth_proxy_role.yaml
│ │ ├── auth_proxy_role_binding.yaml
│ │ ├── auth_proxy_service.yaml
│ │ ├── jcy_editor_role.yaml
│ │ ├── jcy_viewer_role.yaml
│ │ ├── kustomization.yaml
│ │ ├── leader_election_role.yaml
│ │ ├── leader_election_role_binding.yaml
│ │ └── role_binding.yaml
│ ├── samples cd的简单实例
│ │ └── webapp_v1_jcy.yaml
│ └── webhook
│ ├── kustomization.yaml
│ ├── kustomizeconfig.yaml
│ └── service.yaml
├── controllers controller的逻辑
│ ├── jcy_controller.go
│ └── suite_test.go
├── go.mod
├── go.sum
├── hack
│ └── boilerplate.go.txt
└── main.go 入口函数
创建 api 你会发现 Kubebuilder 会帮你创建一些目录和源代码文件:
- 在 api 里面包含了资源 Jcy 的默认数据结构
- 在 controllers 里面 Jcy 的默认 Controller
main入口
我们的 main 文件最开始是 import 一些基本库,尤其是:
- 核心的 控制器运行时 库,也就是controller-runtime
- 默认的控制器运行时日志库– Zap
如下所示
package main
import (
"flag"
"fmt"
"os"
"k8s.io/apimachinery/pkg/runtime"
_ "k8s.io/client-go/plugin/pkg/client/auth/gcp"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/cache"
"sigs.k8s.io/controller-runtime/pkg/log/zap"
// +kubebuilder:scaffold:imports
)
每一组控制器都需要一个 Scheme(一种追踪 Go Type 的方法,它对应于给定的 GVK),它提供了 Kinds 和相应的 Go 类型之间的映射。如下所示
var (
scheme = runtime.NewScheme()
setupLog = ctrl.Log.WithName("setup")
)
func init() {
// +kubebuilder:scaffold:scheme
}
然后看main
func main() {
var metricsAddr string
flag.StringVar(&metricsAddr, "metrics-addr", ":8080", "The address the metric endpoint binds to.")
flag.Parse()
ctrl.SetLogger(zap.New(zap.UseDevMode(true)))
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{Scheme: scheme, MetricsBindAddress: metricsAddr})
if err != nil {
setupLog.Error(err, "unable to start manager")
os.Exit(1)
}
这段代码的核心逻辑比较简单:
- 我们通过 flag 库解析入参
- 我们实例化了一个manager,它记录着我们所有控制器的运行情况,以及设置共享缓存和API服务器的客户端(注意,我们把我们的 Scheme 的信息告诉了 manager)。
- 运行 manager,它反过来运行我们所有的控制器和 webhooks。manager 状态被设置为 Running,直到它收到一个优雅停机 (graceful shutdown) 信号。这样一来,当我们在 Kubernetes 上运行时,我们就可以优雅地停止 pod。
这边封装的比较好了,manager启动其实做了很多的事情,我们在下面的源码详解中说明。
开发结构体
一个api对象的命名是GVK(Group Version Kind),每个api对象都有着一样的初始化结构体,就在对应的type.go文件里面。
我们来看看这个结构体文件,首先导入meta/v1 API 组,通常本身并不会暴露该组,而是包含所有 Kubernetes 种类共有的元数据。
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
我们来看一下Kubebuilder 已经帮你创建和默认的结构:
// Jcy is the Schema for the Jcy API
// +k8s:openapi-gen=true
type Jcy struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec JcySpec `json:"spec,omitempty"` 期待的状态
Status JcyStatus `json:"status,omitempty"` 实际的状态
}
我们需要做的就是扩展JcySpec和JcyStatus来定义我们需要使用的字段。其实就是我们在yaml文件中使用的一下配置。
还提供了批量操作LIST
// JcyList contains a list of Jcy
type JcyList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []Jcy `json:"items"`
}
最后,我们将这个 Go 类型添加到 API 组中。这允许我们将这个 API 组中的类型可以添加到任何Scheme。
func init() {
SchemeBuilder.Register(&Jcy{}, &JcyList{})
}
设计一个api
其实就是如何设计spec中的数据,这个是有一定的规范的
- 所有序列化的字段必须是 驼峰式
- 使用omitempty 标签来标记一个字段在空的时候应该在序列化的时候省略。
- 字段可以使用大多数的基本类型。数字是个例外:出于 API 兼容性的目的,我们只允许三种数字类型。对于整数,需要使用 int32 和 int64 类型;对于小数,使用 resource.Quantity 类型。
- 还有一个我们使用的特殊类型:metav1.Time。 它有一个稳定的、可移植的序列化格式的功能,其他与 time.Time 相同。
开发控制器
在来看看Controller默认 Jcy Controller 名为 ReconcileJcy,这个就是我们控制器的reconciler 结构体,都是kubebuilder默认创建的,其只有一个主要方法就是:
func (r *ReconcileJcy) Reconcile(request reconcile.Request) (reconcile.Result, error)
在使这个 Controller Work 之前,需要 pkg.controller.app.app_controller.go 中的 add 方法中注册要关注的事件,当任何感兴趣的事件发生时,Reconcile 便会被调用,这个函数的职责,就像 Deployment Controller 的 syncHandler 一样,当有事件发生时,去比对当前资源的状态和预期的状态是否一致,如果不一致,就去矫正。
我们来看看这个控制器文件,首先是import包
package controllers
import (
"context"
"github.com/go-logr/logr"
"k8s.io/apimachinery/pkg/runtime"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
batchv1 "tutorial.kubebuilder.io/project/api/v1"
)
可见核心的就是 controller-runtime 运行库,以及 client 包和我们的 API 类型包。
接下来,kubebuilder 为我们搭建了一个基本的 reconciler 结构。
// JcyReconciler reconciles a Jcy object
type JcyReconciler struct {
client.Client
Log logr.Logger
Scheme *runtime.Scheme
}
大多数控制器需要一个日志句柄和一个上下文,所以我们在 Reconcile 中将他们初始化。上下文是用来允许取消请求的,也或者是实现 tracing 等功能。它是所有 client 方法的第一个参数。Background 上下文只是一个基本的上下文,没有任何额外的数据或超时时间限制。日志当然就是打印日志的。
func (r *JcyReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
_ = context.Background()
_ = r.Log.WithValues("jcy", req.NamespacedName)
// your logic here
return ctrl.Result{}, nil
}
最后,我们将 Reconcile 添加到 manager 中,这样当 manager 启动时它就会被启动。
func (r *JcyReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&webappv1.Jcy{}).
Complete(r)
}
下面就是我们来实现基本逻辑了。
总结
其实我们开发控制器,现在只要做三部分相关的开发
- 编写 main 函数,下面介绍
- 编写自定义控制器的定义,
- 编写控制器里的业务逻辑。
其实就是我在一开始说的根据原理基本开发的内容。
测试
当 CR 的结构已经确定和 Controller 代码完成之后,便可以尝试试运行一下。Kubebuilder 可以通过本地 kubeconfig 配置的集群试运行(对于快速创建一个开发集群推荐 minikube)。
首先记得在 main.go 中的 init 方法中添加 schema,确定监控的资源,可以根据需要来新增:
func init() {
_ = corev1.AddToScheme(scheme)
_ = appsv1.AddToScheme(scheme)
_ = extensionsv1beta1.AddToScheme(scheme)
_ = apis.AddToScheme(scheme)
// +kubebuilder:scaffold:scheme
}
然后使 Kubebuilder 重新生成代码:
make
然后将 config/crd 下的 CRD yaml 应用到当前集群:
make install
在本地运行 CRD Controller(直接执行 main 函数也可以):
make run
专业名称
- groups(组)就是相关功能的集合,就是自定义的一个名
- versions(版本)就是版本,一个组可以有多个版本,一般版本都是重v1alpha1,然后升为 v1beta1,最后稳定为 v1 版本。
- Kinds(类型)就是API类型,就是我们定义的类型
- resources(资源)就是 API 中的一个 Kind 的使用方式,就是Kind 的对象标识。通常情况下,Kind 和 resources 之间有一个一对一的映射。 例如,pods 资源对应于 Pod 种类。
- GVK(Group Version Kind)就是当我们在一个特定的群组版本 (Group-Version) 中提到一个 Kind,每个 GVK 对应 Golang 代码中的到对应生成代码中的 Go type。
- GVR(Group Version Resources)就是就是当我们在一个特定的群组版本 (Group-Version) 中提到一个 resources
- Scheme是一种追踪 Go Type 的方法,它对应于给定的 GVK。提供了 Kinds 与对应 Go types 的映射,也就是说给定 Go type 就知道他的 GVK,给定 GVK 就知道他的 Go type。
源码解析
刚开始使用 Kubebuilder 的时候,因为封装程度很高,很多事情都是懵逼状态,剖析完之后很多问题就很明白了。
main
从 main.go 开始。Kubebuilder 创建的 main.go 是整个项目的入口,逻辑十分简单:
var (
scheme = runtime.NewScheme()
setupLog = ctrl.Log.WithName("setup")
)
func init() {
appsv1alpha1.AddToScheme(scheme)
// +kubebuilder:scaffold:scheme
}
func main() {
...
// 1、init Manager
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{Scheme: scheme, MetricsBindAddress: metricsAddr})
if err != nil {
setupLog.Error(err, "unable to start manager")
os.Exit(1)
}
// 2、init Reconciler(Controller)
err = (&controllers.ApplicationReconciler{
Client: mgr.GetClient(),
Log: ctrl.Log.WithName("controllers").WithName("Application"),
Scheme: mgr.GetScheme(),
}).SetupWithManager(mgr)
if err != nil {
setupLog.Error(err, "unable to create controller", "controller", "EDASApplication")
os.Exit(1)
}
// +kubebuilder:scaffold:builder
setupLog.Info("starting manager")
// 3、start Manager
if err := mgr.Start(ctrl.SetupSignalHandler()); err != nil {
setupLog.Error(err, "problem running manager")
os.Exit(1)
}
可以看到在 init 方法里面我们将 appsv1alpha1 注册到 Scheme 里面去了,这样一来 Cache 就知道 watch 谁了,main 方法里面的逻辑基本都是 Manager 的:
- 初始化了一个 Manager;
- 将 Manager 的 Client 传给 Controller,并且调用 SetupWithManager 方法传入 Manager 进行 Controller 的初始化;
- 启动 Manager。
我们的核心就是看这 3 个流程。
Manager 初始化
Manager 初始化代码如下:
// New returns a new Manager for creating Controllers.
func New(config *rest.Config, options Options) (Manager, error) {
...
// Create the cache for the cached read client and registering informers
cache, err := options.NewCache(config, cache.Options{Scheme: options.Scheme, Mapper: mapper, Resync: options.SyncPeriod, Namespace: options.Namespace})
if err != nil {
return nil, err
}
apiReader, err := client.New(config, client.Options{Scheme: options.Scheme, Mapper: mapper})
if err != nil {
return nil, err
}
writeObj, err := options.NewClient(cache, config, client.Options{Scheme: options.Scheme, Mapper: mapper})
if err != nil {
return nil, err
}
...
return &controllerManager{
config: config,
scheme: options.Scheme,
errChan: make(chan error),
cache: cache,
fieldIndexes: cache,
client: writeObj,
apiReader: apiReader,
recorderProvider: recorderProvider,
resourceLock: resourceLock,
mapper: mapper,
metricsListener: metricsListener,
internalStop: stop,
internalStopper: stop,
port: options.Port,
host: options.Host,
leaseDuration: *options.LeaseDuration,
renewDeadline: *options.RenewDeadline,
retryPeriod: *options.RetryPeriod,
}, nil
}
可以看到主要是创建 Cache 与 Clients:
创建 Cache
Cache 初始化代码如下:
// New initializes and returns a new Cache.
func New(config *rest.Config, opts Options) (Cache, error) {
opts, err := defaultOpts(config, opts)
if err != nil {
return nil, err
}
im := internal.NewInformersMap(config, opts.Scheme, opts.Mapper, *opts.Resync, opts.Namespace)
return &informerCache{InformersMap: im}, nil
}
// newSpecificInformersMap returns a new specificInformersMap (like
// the generical InformersMap, except that it doesn't implement WaitForCacheSync).
func newSpecificInformersMap(...) *specificInformersMap {
ip := &specificInformersMap{
Scheme: scheme,
mapper: mapper,
informersByGVK: make(map[schema.GroupVersionKind]*MapEntry),
codecs: serializer.NewCodecFactory(scheme),
resync: resync,
createListWatcher: createListWatcher,
namespace: namespace,
}
return ip
}
// MapEntry contains the cached data for an Informer
type MapEntry struct {
// Informer is the cached informer
Informer cache.SharedIndexInformer
// CacheReader wraps Informer and implements the CacheReader interface for a single type
Reader CacheReader
}
func createUnstructuredListWatch(gvk schema.GroupVersionKind, ip *specificInformersMap) (*cache.ListWatch, error) {
...
// Create a new ListWatch for the obj
return &cache.ListWatch{
ListFunc: func(opts metav1.ListOptions) (runtime.Object, error) {
if ip.namespace != "" && mapping.Scope.Name() != meta.RESTScopeNameRoot {
return dynamicClient.Resource(mapping.Resource).Namespace(ip.namespace).List(opts)
}
return dynamicClient.Resource(mapping.Resource).List(opts)
},
// Setup the watch function
WatchFunc: func(opts metav1.ListOptions) (watch.Interface, error) {
// Watch needs to be set to true separately
opts.Watch = true
if ip.namespace != "" && mapping.Scope.Name() != meta.RESTScopeNameRoot {
return dynamicClient.Resource(mapping.Resource).Namespace(ip.namespace).Watch(opts)
}
return dynamicClient.Resource(mapping.Resource).Watch(opts)
},
}, nil
}
可以看到 Cache 主要就是创建了 InformersMap,Scheme 里面的每个 GVK 都创建了对应的 Informer,通过 informersByGVK 这个 map 做 GVK 到 Informer 的映射,每个 Informer 会根据 ListWatch 函数对对应的 GVK 进行 List 和 Watch。
创建 Clients
创建 Clients 很简单:
// defaultNewClient creates the default caching client
func defaultNewClient(cache cache.Cache, config *rest.Config, options client.Options) (client.Client, error) {
// Create the Client for Write operations.
c, err := client.New(config, options)
if err != nil {
return nil, err
}
return &client.DelegatingClient{
Reader: &client.DelegatingReader{
CacheReader: cache,
ClientReader: c,
},
Writer: c,
StatusClient: c,
}, nil
}
读操作使用上面创建的 Cache,写操作使用 K8s go-client 直连。
Controller 初始化
下面看看 Controller 的启动:
func (r *EDASApplicationReconciler) SetupWithManager(mgr ctrl.Manager) error {
err := ctrl.NewControllerManagedBy(mgr).
For(&appsv1alpha1.EDASApplication{}).
Complete(r)
return err
}
使用的是 Builder 模式,NewControllerManagerBy 和 For 方法都是给 Builder 传参,最重要的是最后一个方法 Complete,其逻辑是:
func (blder *Builder) Build(r reconcile.Reconciler) (manager.Manager, error) {
...
// Set the Manager
if err := blder.doManager(); err != nil {
return nil, err
}
// Set the ControllerManagedBy
if err := blder.doController(r); err != nil {
return nil, err
}
// Set the Watch
if err := blder.doWatch(); err != nil {
return nil, err
}
...
return blder.mgr, nil
}
主要是看看 doController 和 doWatch 方法:
doController 方法
func New(name string, mgr manager.Manager, options Options) (Controller, error) {
if options.Reconciler == nil {
return nil, fmt.Errorf("must specify Reconciler")
}
if len(name) == 0 {
return nil, fmt.Errorf("must specify Name for Controller")
}
if options.MaxConcurrentReconciles <= 0 {
options.MaxConcurrentReconciles = 1
}
// Inject dependencies into Reconciler
if err := mgr.SetFields(options.Reconciler); err != nil {
return nil, err
}
// Create controller with dependencies set
c := &controller.Controller{
Do: options.Reconciler,
Cache: mgr.GetCache(),
Config: mgr.GetConfig(),
Scheme: mgr.GetScheme(),
Client: mgr.GetClient(),
Recorder: mgr.GetEventRecorderFor(name),
Queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), name),
MaxConcurrentReconciles: options.MaxConcurrentReconciles,
Name: name,
}
// Add the controller as a Manager components
return c, mgr.Add(c)
}
该方法初始化了一个 Controller,传入了一些很重要的参数:
- Do:Reconcile 逻辑;
- Cache:找 Informer 注册 Watch;
- Client:对 K8s 资源进行 CRUD;
- Queue:Watch 资源的 CUD 事件缓存;
- Recorder:事件收集。
doWatch 方法
func (blder *Builder) doWatch() error {
// Reconcile type
src := &source.Kind{Type: blder.apiType}
hdler := &handler.EnqueueRequestForObject{}
err := blder.ctrl.Watch(src, hdler, blder.predicates...)
if err != nil {
return err
}
// Watches the managed types
for _, obj := range blder.managedObjects {
src := &source.Kind{Type: obj}
hdler := &handler.EnqueueRequestForOwner{
OwnerType: blder.apiType,
IsController: true,
}
if err := blder.ctrl.Watch(src, hdler, blder.predicates...); err != nil {
return err
}
}
// Do the watch requests
for _, w := range blder.watchRequest {
if err := blder.ctrl.Watch(w.src, w.eventhandler, blder.predicates...); err != nil {
return err
}
}
return nil
}
可以看到该方法对本 Controller 负责的 CRD 进行了 watch,同时底下还会 watch 本 CRD 管理的其他资源,这个 managedObjects 可以通过 Controller 初始化 Buidler 的 Owns 方法传入,说到 Watch 我们关心两个逻辑:
注册的 handler
type EnqueueRequestForObject struct{}
// Create implements EventHandler
func (e *EnqueueRequestForObject) Create(evt event.CreateEvent, q workqueue.RateLimitingInterface) {
...
q.Add(reconcile.Request{NamespacedName: types.NamespacedName{
Name: evt.Meta.GetName(),
Namespace: evt.Meta.GetNamespace(),
}})
}
// Update implements EventHandler
func (e *EnqueueRequestForObject) Update(evt event.UpdateEvent, q workqueue.RateLimitingInterface) {
if evt.MetaOld != nil {
q.Add(reconcile.Request{NamespacedName: types.NamespacedName{
Name: evt.MetaOld.GetName(),
Namespace: evt.MetaOld.GetNamespace(),
}})
} else {
enqueueLog.Error(nil, "UpdateEvent received with no old metadata", "event", evt)
}
if evt.MetaNew != nil {
q.Add(reconcile.Request{NamespacedName: types.NamespacedName{
Name: evt.MetaNew.GetName(),
Namespace: evt.MetaNew.GetNamespace(),
}})
} else {
enqueueLog.Error(nil, "UpdateEvent received with no new metadata", "event", evt)
}
}
// Delete implements EventHandler
func (e *EnqueueRequestForObject) Delete(evt event.DeleteEvent, q workqueue.RateLimitingInterface) {
...
q.Add(reconcile.Request{NamespacedName: types.NamespacedName{
Name: evt.Meta.GetName(),
Namespace: evt.Meta.GetNamespace(),
}})
}
可以看到 Kubebuidler 为我们注册的 Handler 就是将发生变更的对象的 NamespacedName 入队列,如果在 Reconcile 逻辑中需要判断创建/更新/删除,需要有自己的判断逻辑。
注册的流程
// Watch implements controller.Controller
func (c *Controller) Watch(src source.Source, evthdler handler.EventHandler, prct ...predicate.Predicate) error {
...
log.Info("Starting EventSource", "controller", c.Name, "source", src)
return src.Start(evthdler, c.Queue, prct...)
}
// Start is internal and should be called only by the Controller to register an EventHandler with the Informer
// to enqueue reconcile.Requests.
func (is *Informer) Start(handler handler.EventHandler, queue workqueue.RateLimitingInterface,
...
is.Informer.AddEventHandler(internal.EventHandler{Queue: queue, EventHandler: handler, Predicates: prct})
return nil
}
我们的 Handler 实际注册到 Informer 上面,这样整个逻辑就串起来了,通过 Cache 我们创建了所有 Scheme 里面 GVKs 的 Informers,然后对应 GVK 的 Controller 注册了 Watch Handler 到对应的 Informer,这样一来对应的 GVK 里面的资源有变更都会触发 Handler,将变更事件写到 Controller 的事件队列中,之后触发我们的 Reconcile 方法。
Manager 启动
func (cm *controllerManager) Start(stop <-chan struct{}) error {
...
go cm.startNonLeaderElectionRunnables()
...
}
func (cm *controllerManager) startNonLeaderElectionRunnables() {
...
// Start the Cache. Allow the function to start the cache to be mocked out for testing
if cm.startCache == nil {
cm.startCache = cm.cache.Start
}
go func() {
if err := cm.startCache(cm.internalStop); err != nil {
cm.errChan <- err
}
}()
...
// Start Controllers
for _, c := range cm.nonLeaderElectionRunnables {
ctrl := c
go func() {
cm.errChan <- ctrl.Start(cm.internalStop)
}()
}
cm.started = true
}
主要就是启动 Cache,Controller,将整个事件流运转起来,我们下面来看看启动逻辑。
Cache 启动
func (ip *specificInformersMap) Start(stop <-chan struct{}) {
func() {
...
// Start each informer
for _, informer := range ip.informersByGVK {
go informer.Informer.Run(stop)
}
}()
}
func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) {
...
// informer push resource obj CUD delta to this fifo queue
fifo := NewDeltaFIFO(MetaNamespaceKeyFunc, s.indexer)
cfg := &Config{
Queue: fifo,
ListerWatcher: s.listerWatcher,
ObjectType: s.objectType,
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
// handler to process delta
Process: s.HandleDeltas,
}
func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
// this is internal controller process delta generate by reflector
s.controller = New(cfg)
s.controller.(*controller).clock = s.clock
s.started = true
}()
...
wg.StartWithChannel(processorStopCh, s.processor.run)
s.controller.Run(stopCh)
}
func (c *controller) Run(stopCh <-chan struct{}) {
...
r := NewReflector(
c.config.ListerWatcher,
c.config.ObjectType,
c.config.Queue,
c.config.FullResyncPeriod,
)
...
// reflector is delta producer
wg.StartWithChannel(stopCh, r.Run)
// internal controller's processLoop is comsume logic
wait.Until(c.processLoop, time.Second, stopCh)
}
Cache 的初始化核心是初始化所有的 Informer,Informer 的初始化核心是创建了 reflector 和内部 controller,reflector 负责监听 Api Server 上指定的 GVK,将变更写入 delta 队列中,可以理解为变更事件的生产者,内部 controller 是变更事件的消费者,他会负责更新本地 indexer,以及计算出 CUD 事件推给我们之前注册的 Watch Handler。
Controller 启动
// Start implements controller.Controller
func (c *Controller) Start(stop <-chan struct{}) error {
...
for i := 0; i < c.MaxConcurrentReconciles; i++ {
// Process work items
go wait.Until(func() {
for c.processNextWorkItem() {
}
}, c.JitterPeriod, stop)
}
...
}
func (c *Controller) processNextWorkItem() bool {
...
obj, shutdown := c.Queue.Get()
...
var req reconcile.Request
var ok bool
if req, ok = obj.(reconcile.Request);
...
// RunInformersAndControllers the syncHandler, passing it the namespace/Name string of the
// resource to be synced.
if result, err := c.Do.Reconcile(req); err != nil {
c.Queue.AddRateLimited(req)
...
}
...
}
Controller 的初始化是启动 goroutine 不断地查询队列,如果有变更消息则触发到我们自定义的 Reconcile 逻辑。
Kubebuilder 作为工具已经为我们做了很多,到最后我们只需要实现 Reconcile 方法即可,相比一开始更加的自动化,其实operator也是一种特殊模式的控制器,也可以使用kubebuilder来开发。