kube-proxy是Kubernetes的核心组件,部署在每个Node节点上,它是实现Kubernetes Service的通信与负载均衡机制的重要组件; kube-proxy负责为Pod创建代理服务,从apiserver获取所有server信息,并根据server信息创建代理服务,实现server到Pod的请求路由和转发,从而实现K8s层级的虚拟转发网络。
使用
直接使用二进制文件进行启动
/usr/bin/kube-proxy \
--bind-address=10.12.51.171 \
--hostname-override=10.12.51.171 \
--cluster-cidr=10.254.0.0/16 \
--kubeconfig=/etc/kubernetes/kube-proxy.kubeconfig \
--logtostderr=true \
--v=2 \
--ipvs-scheduler=wrr \
--ipvs-min-sync-period=5s \
--ipvs-sync-period=5s \
--proxy-mode=ipvs
我们主要看一下几个核心的启动参数
--alsologtostderr 设置true则日志输出到stderr,也输出到日志文件
--bind-address 0.0.0.0 监听主机IP地址,0.0.0.0监听主机所有主机接口 (default 0.0.0.0)
--cleanup 如果设置为true,则清除iptables和ipvs规则并退出
--cleanup-ipvs 如果设置为true,在运行前kube-proxy将清除ipvs规则(default true)
--cluster-cidr string 集群中 Pod 的CIDR范围。集群外的发送到服务集群IP的流量将被伪装,从pod发送到外部 LoadBalancer IP的流量将被定向到相应的集群IP
--config string 配置文件路径
--config-sync-period duration 从apiserver同步配置的时间间隔(default 15m0s)
--conntrack-max-per-core int32 每个CPU核跟踪的最大NAT连接数(0按原来保留限制并忽略conntrack-min)(default 32768)
--conntrack-min int32 分配的最小conntrack条目,无视conntrack-max-per-core选项(设置conntrack-max-per-core=0保持原始限制)(default 131072)
--conntrack-tcp-timeout-close-wait duration 对于TCP连接处于CLOSE_WAIT阶段的NAT超时时间(default 1h0m0s)
--conntrack-tcp-timeout-established duration TCP连接的空闲超时(default 24h0m0s)
--feature-gates mapStringBool key = value对,用于试验
--healthz-bind-address 0.0.0.0 健康检查服务器提供服务的IP地址及端口(default 0.0.0.0:10256)
--healthz-port int32 配置健康检查服务的端口,0表示禁止 (default 10256)
--hostname-override string 使用该名字作为标识而不是实际的主机名
--iptables-masquerade-bit int32 对于纯iptables代理,则表示fwmark space的位数,用于标记需要SNAT的数据包。[0,31]范围 (default 14)
--iptables-min-sync-period duration 当endpoints和service变化,刷新iptables规则的最小时间间隔
--iptables-sync-period duration iptables刷新的最大时间间隔 (default 30s)
--ipvs-exclude-cidrs strings ipvs proxier清理IPVS规则时不触及的CIDR以逗号分隔的列表
--ipvs-min-sync-period duration 当endpoints和service变化,刷新ipvs规则的最小时间间隔
--ipvs-scheduler string 当proxy模式设置为ipvs,ipvs调度的类型
--ipvs-sync-period duration ipvs刷新的最大时间间隔 (default 30s)
--kube-api-burst int32 发送到kube-apiserver每秒请求量 (default 10)
--kube-api-content-type string 发送到kube-apiserver请求内容类型(default "application/vnd.kubernetes.protobuf")
--kube-api-qps float32 与kube-apiserver通信的qps(default 5)
--kubeconfig string 具有授权信息的kubeconfig文件的路径
--log-backtrace-at traceLocation when logging hits line file:N, emit a stack trace (default :0)
--log-dir string If non-empty, write log files in this directory
--log-flush-frequency duration Maximum number of seconds between log flushes (default 5s)
--logtostderr log to standard error instead of files (default true)
--masquerade-all 纯 iptables 代理,对所有通过集群 service IP发送的流量进行 SNAT(通常不配置)
--master string Kubernetes API server地址,覆盖kubeconfig的配置
--metrics-bind-address 0.0.0.0 对于metrics服务地址和端口 (default 127.0.0.1:10249)
--nodeport-addresses strings A string slice of values which specify the addresses to use for NodePorts. Values may be valid IP blocks (e.g. 1.2.3.0/24, 1.2.3.4/32). The default empty string slice ([]) means to use all local addresses.
--oom-score-adj int32 kube-proxy进程的oom-score-adj值,合法值范围[-1000, 1000] (default -999)
--profiling 设置为true,通过web接口/debug/pprof查看性能分析
--proxy-mode ProxyMode userspace / iptables / ipvs (默认为iptables)
--proxy-port-range port-range Range of host ports (beginPort-endPort, single port or beginPort+offset, inclusive) that may be consumed in order to proxy service traffic. If (unspecified, 0, or 0-0) then ports will be randomly chosen.
--stderrthreshold severity logs at or above this threshold go to stderr (default 2)
--udp-timeout duration ow long an idle UDP connection will be kept open (e.g. '250ms', '2s'). Must be greater than 0. Only applicable for proxy-mode=userspace (default 250ms)
-v, --v Level log level for V logs
--version version[=true] Print version information and quit
--vmodule moduleSpec 逗号分隔的模式=N的列表文件,用以筛选日志记录
--write-config-to string If set, write the default configuration values to this file and exit.
kube-proxy
容器的特点是快速创建、快速销毁,Kubernetes Pod和容器一样只具有临时的生命周期,一个Pod随时有可能被终止或者漂移,随着集群的状态变化而变化,一旦Pod变化,则该Pod提供的服务也就无法访问,如果直接访问Pod则无法实现服务的连续性和高可用性,因此显然不能使用Pod地址作为服务暴露端口。
解决这个问题的办法和传统数据中心解决无状态服务高可用的思路完全一样,通过负载均衡和VIP实现后端真实服务的自动转发、故障转移。
这个负载均衡在Kubernetes中称为Service,VIP即Service ClusterIP,因此可以认为Kubernetes的Service就是一个四层负载均衡,Kubernetes对应的还有七层负载均衡Ingress
services
这个Service就是由kube-proxy实现的,ClusterIP不会因为Pod状态改变而变,需要注意的是VIP即ClusterIP是个假的IP,这个IP在整个集群中根本不存在,这个IP在其他节点以及集群外均无法访问。
所以在你创建service的时候,kube-proxy会为你分配一个clusterIp并且为这个IP实现路由(根据label查询到具体pod,然后根据模式设置路由规则,比如iptables规则),这个路由有很多方式,取决于使用kube-proxy的配置使用方式,具体模式,我们下面详细讲解。关于service资源可以看这里。
ingress
ingress是七层的负载均衡,主要实现给service对外访问的转发机制,具体可以看这里。
模式
kubernetes里kube-proxy支持三种模式,其中userspace mode是v1.0及之前版本的默认模式,从v1.1版本中开始增加了iptables mode,在v1.2版本中正式替代userspace模式成为默认模式,在v1.8之前我们使用的是iptables 以及 userspace两种模式,在kubernetes 1.8之后引入了ipvs模式,并且在v1.11中正式使用,其中iptables和ipvs都是内核态也就是基于netfilter,只有userspace模式是用户态。
userspace
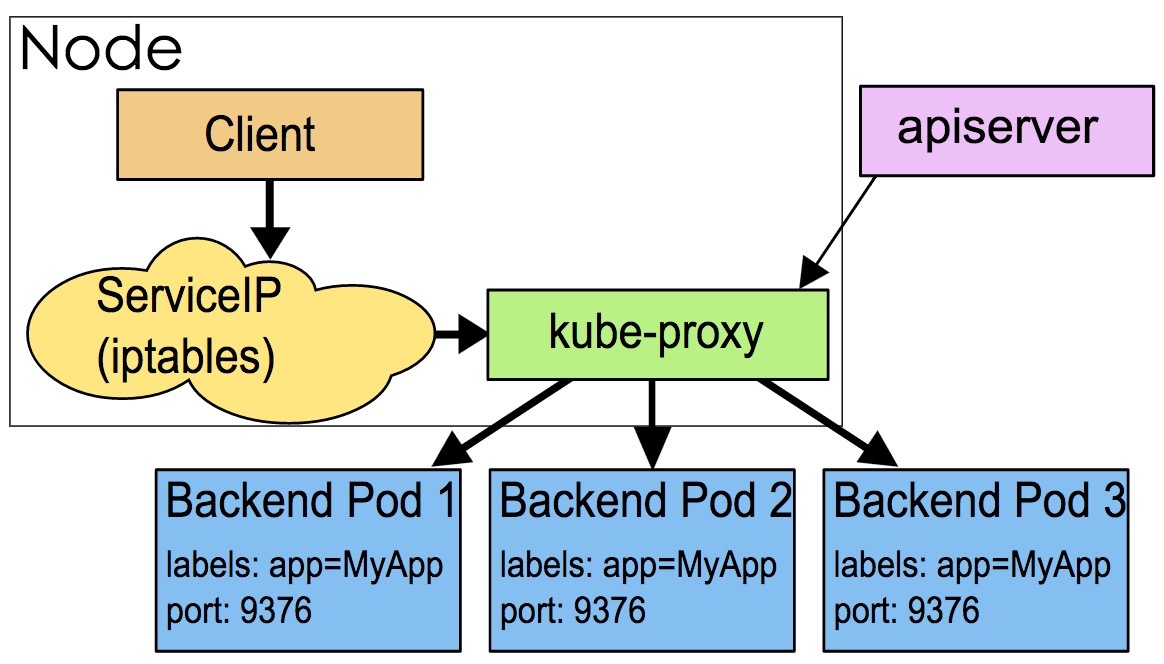
userspace 模式下service的请求会先从用户空间进入内核iptables,然后再回到用户空间,由kube-proxy完成后端Endpoints的选择和代理工作,这样流量从用户空间进出内核带来的性能损耗是不可接受的。这也是k8s v1.0及之前版本中对kube-proxy质疑最大的一点,因此社区就开始研究iptables mode。
iptables
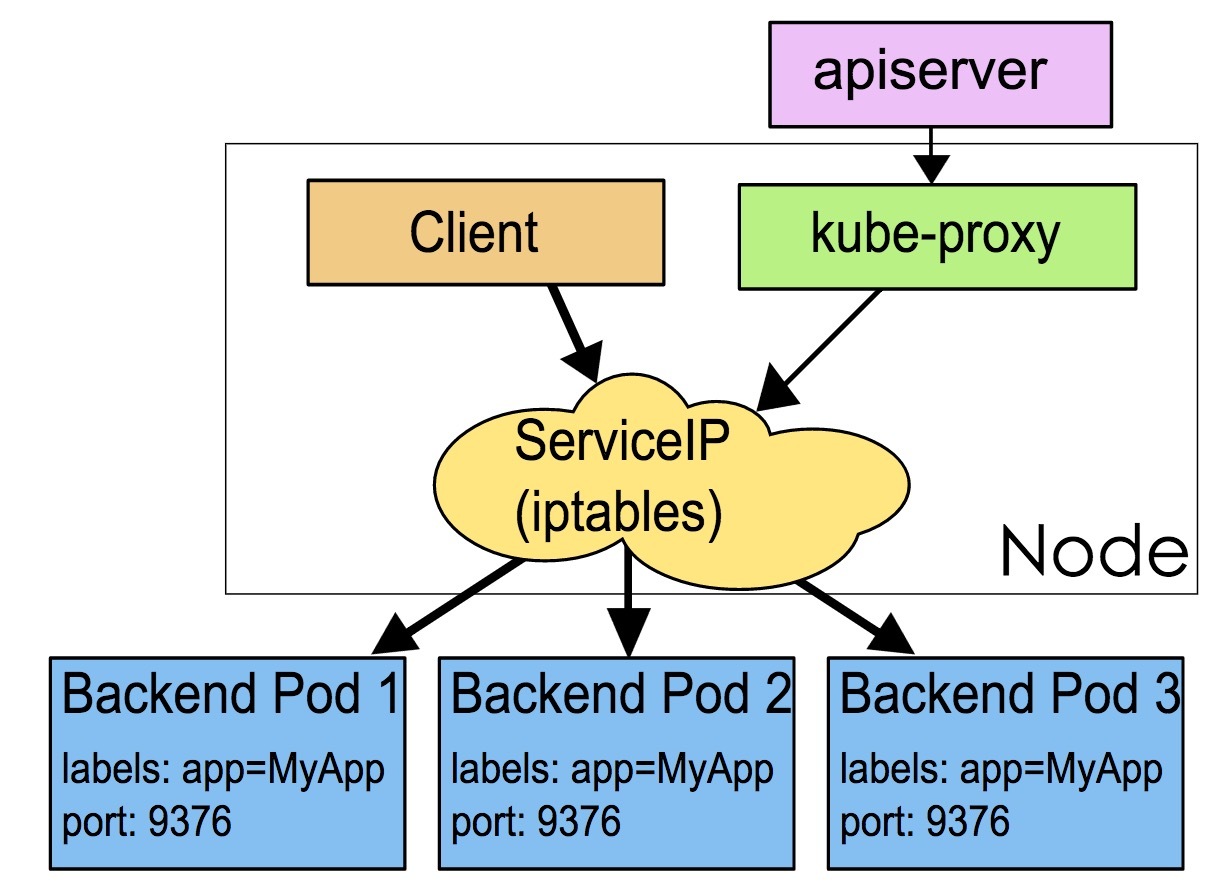
Kube-Proxy 监听 Kubernetes Master 增加和删除 Service 以及 Endpoint 的消息。对于每一个 Service,Kube Proxy 创建相应的 IPtables 规则,并将发送到 Service Cluster IP 的流量转发到 Service 后端提供服务的 Pod 的相应端口上。并且流量的转发都是在内核态进行的,所以性能更高更加可靠。
但是iptables mode因为使用iptable NAT来完成转发,也存在不可忽视的性能损耗。另外,如果集群中存在上万的Service/Endpoint,那么Node上的iptables rules将会非常庞大,性能还会再打折扣。 这也导致,当时大部分企业用k8s上生产时,都不会直接用kube-proxy作为服务代理,而是通过自己开发或者通过Ingress Controller来集成HAProxy, Nginx来代替kube-proxy。
实例
我们来分析下面这个service的iptables规则。
apiVersion: v1
kind: Service
meadata:
labels:
name: tomcat
name: tomcat
space:
ports:
- port: 6080
targetPort: 6080
nodePort: 30005
type: NodePort
selector:
app: tomcat
如上所示,在本例中我们创建了一个NodePort类型名为tomcat的服务。该服务的端口为6080,NodePort为30005,对应后端Pod的端口也为6080。它的Cluster IP为10.254.0.40。tomcat服务有两个后端Pod,IP分别是192.168.20.1和192.168.20.2,这边我们就不展示了。
kube-proxy 为该服务创建的iptables规则如下:
# iptables -S -t nat
-A PREROUTING -m -comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -m -comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A POSTROUTING -m -comment --comment "kubernetes postrouting rules " -j KUBE-POSTROUTING
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
-A KUBE-NODEPORTS -p tcp -m -comment --comment "default/tomcat:"\
-m tcp --dport 30005 -j KUBE-MARK-MASQ
-A KUBE-NODEPORTS -p tcp -m -comment --comment "default/tomcat:"\
-m -tpc --dport 30005 -j KUBE-SVC-67RLXXX
-A KUBE-SEP-ID6YXXX -s 192.168.20.1/32 -m -comment --comment "default/tomcat:"\
-j KUBE-MARK-MASQ
-A KUBE-SEP-ID6YXXX -p tcp -m -comment --comment "default/tomcat:"\
-m tcp -j DANT --to-destination 192.168.20.1:6080
-A KUBE-SEP-IN2YXXX -s 192.168.20.2/32 -m -comment --comment "default/tomcat:"\
-j KUBE-MARK-MASQ
-A KUBE-SEP-IN2YXXX -p tcp -m -comment --comment "default/tomcat:"\
-m tcp -j DANT --to-destination 192.168.20.2:6080
-A KUBE-SERVICES -d 10.254.0.40/32 -p tcp -m -comment --comment \
"default/tomcat: cluster ip" -m tcp --dport 6080 -j KUBE-SVC-67RLXXX
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeport; NOTE: this must be the \
last rule in this chain " -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-SVC-67RLXXX -m comment --comment "default/tomcat:" -m \
statistic --mode random --probability 0.500000000 -j KUBE-SEP-ID6YXXX
-A KUBE-SVC-67RLXXX -m comment --comment "default/tomcat:" -j \
KUBE-SEP-IN2YXXX
...
首先我们先看
-A KUBE-NODEPORTS -p tcp -m -comment --comment "default/tomcat:"\
-m tcp --dport 30005 -j KUBE-MARK-MASQ
-A KUBE-NODEPORTS -p tcp -m -comment --comment "default/tomcat:"\
-m -tpc --dport 30005 -j KUBE-SVC-67RLXXX
通过节点的30005端口访问NodePort,则会进入以下链,kube-proxy针对NodePort流量入口创建了KUBE-NODEPORTS 链。在我们这个例子中,KUBE-NODEPORTS 链进一步跳转到KUBE-SVC-67RLXXX链。
在看
-A KUBE-SVC-67RLXXX -m comment --comment "default/tomcat:" -m \
statistic --mode random --probability 0.500000000 -j KUBE-SEP-ID6YXXX
-A KUBE-SVC-67RLXXX -m comment --comment "default/tomcat:" -j \
KUBE-SEP-IN2YXXX
这里采用了iptables的random模块,使连接有50%的概率进入KUBE-SEP-ID6YXXX链,50%的概率进入KUBE-SEP-IN2YXXX链。因此,kube-proxy的iptables模式采用随机数实现了服务的负载均衡。
在看KUBE-SEP-ID6YXXX 链
-A KUBE-SEP-ID6YXXX -s 192.168.20.1/32 -m -comment --comment "default/tomcat:"\
-j KUBE-MARK-MASQ
-A KUBE-SEP-ID6YXXX -p tcp -m -comment --comment "default/tomcat:"\
-m tcp -j DANT --to-destination 192.168.20.1:6080
KUBE-SEP-ID6YXXX 链的具体作用就是将请求通过DNAT发送到192.168.20.1的6080端口,到这里就完成了基本的转发。
ipvs
当你的宿主机上有大量 Pod 的时候,成百上千条 iptables 规则不断地被刷新,会大量占用该宿主机的 CPU 资源,甚至会让宿主机“卡”在这个过程中。所以说,一直以来,基于 iptables 的 Service 实现,都是制约 Kubernetes 项目承载更多量级的 Pod 的主要障碍。而 IPVS 模式的 Service,就是解决这个问题的一个行之有效的方法。
iptables的数量限制和损耗的缺点,使得ipvs得到了发展。kubernetes从1.8开始增加了IPVS支持,并在Kubernetes 1.12成为kube-proxy的默认代理模式,IPVS相对于iptables来说效率会更加高,使用ipvs模式需要在允许proxy的节点上安装ipvsadm,ipset工具包加载ipvs的内核模块。并且ipvs可以轻松处理每秒 10 万次以上的转发请求。可以说是目前比较流行的使用方式。
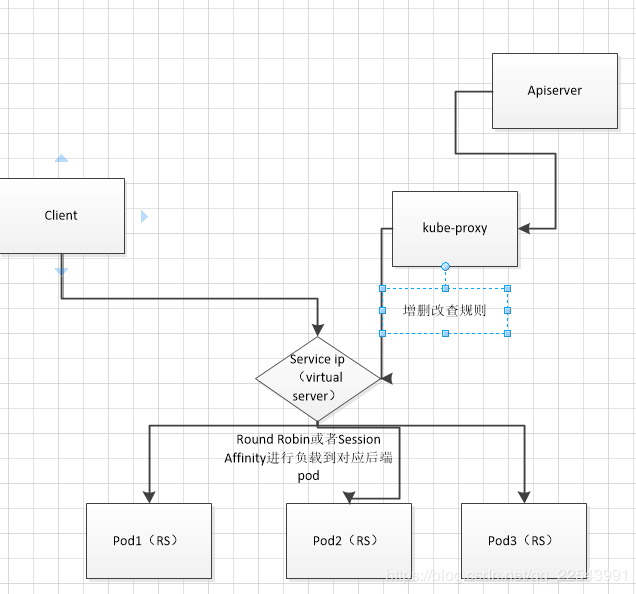
Kube-Proxy 会监视 Kubernetes Service 对象 和 Endpoints,调用 Netlink 接口以相应地创建 IPVS 规则并定期与 Kubernetes Service 对象 和 Endpoints 对象同步 IPVS 规则,以确保 IPVS 状态与期望一致。访问服务时,流量将被重定向到其中一个后端 Pod。
ipvs模式也是基于netfilter,对比iptables模式在大规模Kubernetes集群有更好的扩展性和性能,支持更加复杂的负载均衡算法(如:最小负载、最少连接、加权等),支持Server的健康检查和连接重试等功能。ipvs依赖于iptables,使用iptables进行包过滤、SNAT、masquared。ipvs将使用ipset需要被DROP或MASQUARED的源地址或目标地址,这样就能保证iptables规则数量的固定,我们不需要关心集群中有多少个Service了。
原理
IPVS 模式的工作原理,其实跟 iptables 模式类似。当我们创建了前面的 Service 之后,kube-proxy 首先会在宿主机上创建一个虚拟网卡(叫作:kube-ipvs0),并为它分配 Service VIP 作为 IP 地址,如下所示:
# ip addr
...
73:kube-ipvs0:<BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 1a:ce:f5:5f:c1:4d brd ff:ff:ff:ff:ff:ff
inet 10.0.1.175/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
而接下来,kube-proxy 就会通过 Linux 的 IPVS 模块,为这个 IP 地址设置三个 IPVS 虚拟主机,并设置这三个虚拟主机之间使用轮询模式 (rr) 来作为负载均衡策略。我们可以通过 ipvsadm 查看到这个设置,如下所示:
# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:80 rr
-> 10.244.3.6:9376 Masq 1 0 0
-> 10.244.1.7:9376 Masq 1 0 0
-> 10.244.2.3:9376 Masq 1 0 0
可以看到,这三个 IPVS 虚拟主机的 IP 地址和端口,对应的正是三个被代理的 Pod。这时候,任何发往 10.102.128.4:80 的请求,就都会被 IPVS 模块转发到某一个后端 Pod 上了。
IPVS 并不需要在宿主机上为每个 Pod 设置 iptables 规则,而是把对这些“规则”的处理放到了内核态,从而极大地降低了维护这些规则的代价。这也正印证了我在前面提到过的,“将重要操作放入内核态”是提高性能的重要手段。
而相比于 iptables,IPVS 在内核中的实现其实也是基于 Netfilter 的 NAT 模式,所以在转发这一层上,理论上 IPVS 并没有显著的性能提升。
IPVS 模块只负责上述的负载均衡和代理功能。而一个完整的 Service 流程正常工作所需要的包过滤、SNAT 等操作,还是要靠 iptables 来实现。只不过,这些辅助性的 iptables 规则数量有限,也不会随着 Pod 数量的增加而增加。
参数
在运行基于IPVS的kube-proxy时,需要注意以下参数:
–proxy-mode:除了现有的userspace和iptables模式,IPVS模式通过–proxymode=ipvs进行配置。
–ipvs-scheduler:用来指定ipvs负载均衡算法,如果不配置则默认使用round-robin(rr)算法。
如果不配置则默认使用round-robin(rr)算法。支持配置的负载均衡算法有:
— rr:轮询,这种算法是最简单的,就是按依次循环的方式将请求调度到不同的服务器上,该算法最大的特点就是简单。轮询算法假设所有的服务器处理请求的能力都是一样的,调度器会将所有的请求平均分配给每个真实服务器,不管后端 RS 配置和处理能力,非常均衡地分发下去。
— lc:最小连接,这个算法会根据后端 RS 的连接数来决定把请求分发给谁,比如 RS1 连接数比 RS2 连接数少,那么请求就优先发给 RS1
— dh:目的地址哈希,该算法是根据目标 IP 地址通过散列函数将目标 IP 与服务器建立映射关系,出现服务器不可用或负载过高的情况下,发往该目标 IP 的请求会固定发给该服务器。
— sh:原地址哈希,与目标地址散列调度算法类似,但它是根据源地址散列算法进行静态分配固定的服务器资源。
— sed:最短时延
(未来。kube-proxy可能实现在service的annotations 配置负载均衡策略,这个功能应该只能在IPVS模式下才支持)
–cleanup-ipvs:类似于–cleanup-iptables参数。如果设置为true,则清除在IPVS模式下创建的IPVS规则;
–ipvs-sync-period:表示kube-proxy刷新IPVS规则的最大间隔时间,例如5秒。1分钟等,要求大于0;
–ipvs-min-sync-period:表示kube-proxy刷新IPVS规则最小时间间隔,例如5秒,1分钟等,要求大于0
–ipvs-exclude-cidrs:用于清除IPVS规则时告知kube-proxy不要清理该参数配置的网段的IPVS规则。因为我们无法区别某条IPVS规则到底是kube-proxy创建的,还是其他用户进程的,配置该参数是为了避免删除用户自己的IPVS规则。
从k8s的1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Netfilter,但是ipvs采用的hash表,iptables采用一条条的规则列表。iptables又是为了防火墙设计的,集群数量越多iptables规则就越多,而iptables规则是从上到下匹配,所以效率就越是低下。因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能
ipvs和iptables都是基于netfilter的,两者差别如下:
- ipvs 为大型集群提供了更好的可扩展性和性能
- ipvs 支持比 iptables 更复杂的负载均衡算法(最小负载、最少连接、加权等等)
- ipvs 支持服务器健康检查和连接重试等功能
实践与问题
ingress和service
我们一般使用ingress可以直接使用ingress来监控对应的ep的变化,没必要用svc模式,用svc模式会给加长路径和定位带来很多麻烦,同时service的四层代理是走iptabels的nat转化,性能不行,一般大厂都有自己的接入层,比如开源的a6就性能很强劲,ingress这种一般要求性能很高,所以中间没必要去走一遍svc,而且svc还有一些比较严重的问题:
- 目前svc有个比较严重的问题,如果后端pod反复的重启,当有大量请求的时候,非常容易因为svc问题导致链接耗尽,ingress的性能会直接从几万下降到只有几千