kubelet用于处理master节点下发到本节点的任务,管理Pod以及Pod中的容器。每个kubelet进程会在API Server上注册节点信息,定期向master节点汇报节点资源的使用情况,并通过cAdvisor监控容器和节点的资源。
kubelet
kubelet 这个组件本身,也是 Kubernetes 里面第二个不可被替代的组件(第一个不可被替代的组件当然是 kube-apiserver)。也就是说,无论如何,我都不太建议你对 kubelet 的代码进行大量的改动。保持 kubelet 跟上游基本一致的重要性,就跟保持 kube-apiserver 跟上游一致是一个道理。
kubelet 本身,也是按照“控制器”模式来工作的。
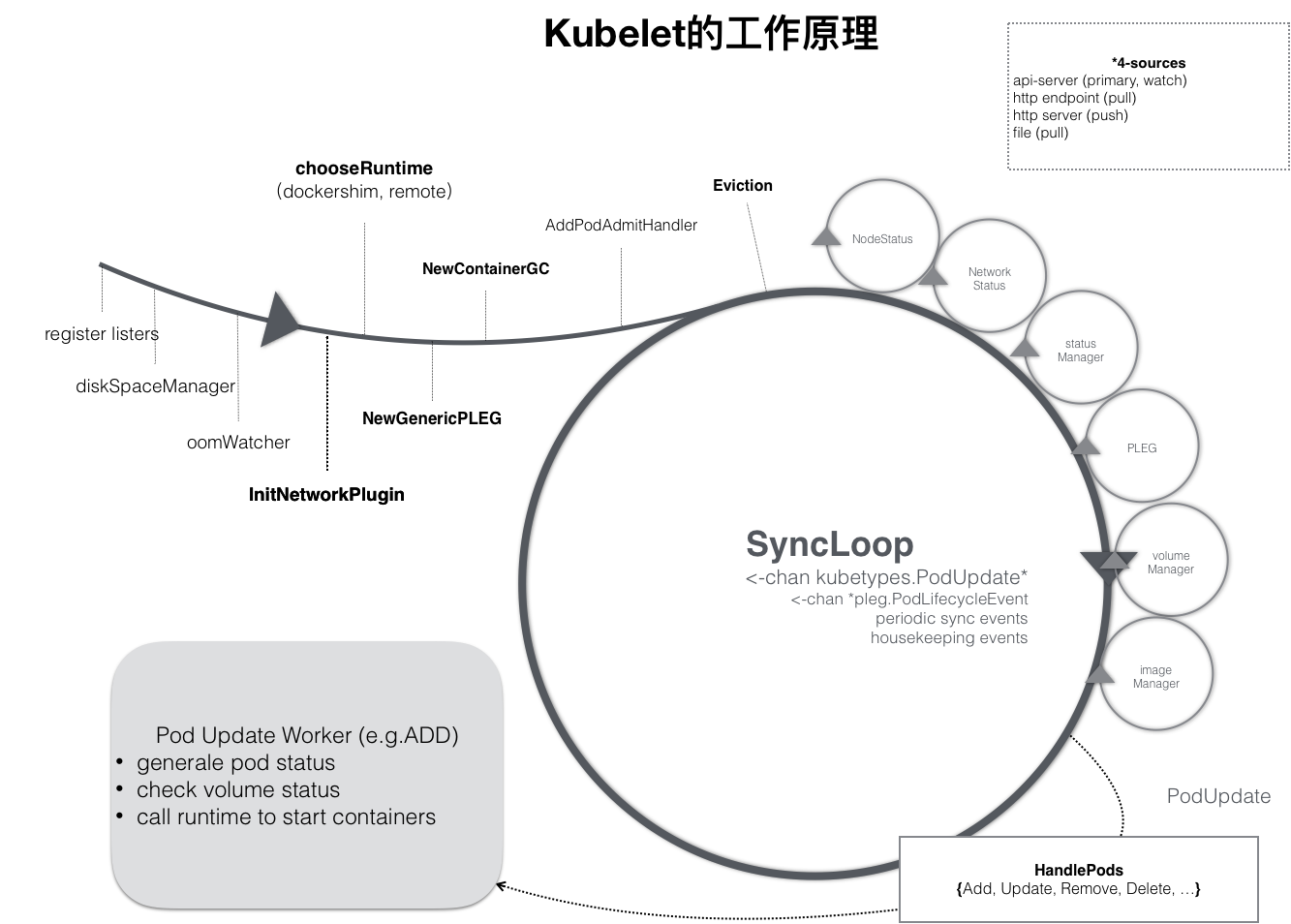
kubelet 的工作核心,就是一个控制循环,即:SyncLoop(图中的大圆圈)。而驱动这个控制循环运行的事件,包括四种:
- Pod 更新事件;
- Pod 生命周期变化;
- kubelet 本身设置的执行周期;
- 定时的清理事件。
跟其他控制器类似,kubelet 启动的时候,要做的第一件事情,就是设置 Listers,也就是注册它所关心的各种事件的 Informer。这些 Informer,就是 SyncLoop 需要处理的数据的来源。此外,kubelet 还负责维护着很多很多其他的子控制循环(也就是图中的小圆圈)。这些控制循环的名字,一般被称作某某 Manager,比如 Volume Manager、Image Manager、Node Status Manager 等等。不难想到,这些控制循环的责任,就是通过控制器模式,完成 kubelet 的某项具体职责。比如 Node Status Manager,就负责响应 Node 的状态变化,然后将 Node 的状态收集起来,并通过 Heartbeat 的方式上报给 APIServer。再比如 CPU Manager,就负责维护该 Node 的 CPU 核的信息,以便在 Pod 通过 cpuset 的方式请求 CPU 核的时候,能够正确地管理 CPU 核的使用量和可用量。
SyncLoop,又是如何根据 Pod 对象的变化,来进行容器操作的呢?
kubelet 也是通过 Watch 机制,监听了与自己相关的 Pod 对象的变化。当然,这个 Watch 的过滤条件是该 Pod 的 nodeName 字段与自己相同。kubelet 会把这些 Pod 的信息缓存在自己的内存里。而当一个 Pod 完成调度、与一个 Node 绑定起来之后, 这个 Pod 的变化就会触发 kubelet 在控制循环里注册的 Handler,也就是上图中的 HandlePods 部分。此时,通过检查该 Pod 在 kubelet 内存里的状态,kubelet 就能够判断出这是一个新调度过来的 Pod,从而触发 Handler 里 ADD 事件对应的处理逻辑。在具体的处理过程当中,kubelet 会启动一个名叫 Pod Update Worker 的、单独的 Goroutine 来完成对 Pod 的处理工作。
比如,如果是 ADD 事件的话,kubelet 就会为这个新的 Pod 生成对应的 Pod Status,检查 Pod 所声明使用的 Volume 是不是已经准备好。然后,调用下层的容器运行时(比如 Docker),开始创建这个 Pod 所定义的容器。而如果是 UPDATE 事件的话,kubelet 就会根据 Pod 对象具体的变更情况,调用下层容器运行时进行容器的重建工作。
kubelet 调用下层容器运行时的执行过程,并不会直接调用 Docker 的 API,而是通过一组叫作 CRI(Container Runtime Interface,容器运行时接口)的 gRPC 接口来间接执行的。Kubernetes 项目之所以要在 kubelet 中引入这样一层单独的抽象,当然是为了对 Kubernetes 屏蔽下层容器运行时的差异。实际上,对于 1.6 版本之前的 Kubernetes 来说,它就是直接调用 Docker 的 API 来创建和管理容器的。
把 kubelet 对容器的操作,统一地抽象成一个接口CRI。这样,kubelet 就只需要跟这个接口打交道了。而作为具体的容器项目,比如 Docker、 rkt、runV,它们就只需要自己提供一个该接口的实现,然后对 kubelet 暴露出 gRPC 服务即可。
目前kubelet还集成这docker的负责响应的组件dockershim,而其他容器化CRI shim就需要自己实现部署了,所以可见dockershim被移除是必然的趋势,k8s只会提供一套统一的接口cri。
节点管理
节点通过设置kubelet的启动参数“–register-node”来决定是否向API Server注册自己。如果该参数为true,那么kubelet将试着通过API Server注册自己。在自注册时,kubelet启动时还包括以下参数:
--api-servers:API Server的位置
--kubeconfing:kubeconfig文件,用于访问API Server的安全配置文件
--cloud-provider:云服务商地址,仅用于共有云环境
如果没有选择自注册模式,用户需要手动去配置node的资源信息,同时告知ndoe上的kubelet API Server的位置。Kubelet在启动时通过API Server注册节点信息,并定时向API Server发送节点新消息,API Server在接受到这些消息之后,将这些信息写入etcd中。通过kubelet的启动参数“–node-status-update-frequency”设置kubelet每个多长时间向API Server报告节点状态,默认为10s
pod管理
资源获取
kubelet通过以下几种方式获取自身node上所要运行的pod清单:
- 文件:kubelet启动参数“–config”指定的配置文件目录下的文件(默认为“/etc/Kubernetes/manifests”)通过–file-check-frequency设置检查该文件的时间间隔,默认为20s
- HTTP端点:通过“–manifest-url”参数设置。通过“–http-check-frequency”设置检查该HTTP端点数据的时间间隔,默认为20s。
- API Server:kubelet通过API server监听etcd目录,同步pod列表
注意:这里static pod,不是被API Server创建的,而是被kubelet创建,之前文章中提到了静态的pod是在kubelet的配置文件中编写,并且总在kubelet所在node上运行。
创建流程
Kubelet监听etcd,所有针对pod的操作将会被kubelet监听到。如果是新的绑定到本节点的pod,则按照pod清单的要求创建pod,如果是删除pod,则kubelet通过docker client去删除pod中的容器,并删除该pod。
具体的针对创建和修改pod任务,流程为:
- 为该pod创建一个目录
- 从API Server读取该pod清单
- 为该pod挂载外部volume
- 下载pod用到的secret
- 检查已经运行在节点中的pod,如果该pod没有容器或者Pause容器没有启动,则先停止pod里的所有容器的进程。如果pod中有需要删除的容器,则删除这些容器
- 为pod中的每个容器做如下操作
- 为容器计算一个hash值,然后用容器的名字去查询docker容器的hash值。若查找到容器,且两者得到hash不同,则停止docker中的容器的进程,并且停止与之关联pause容器的进程;若两个相同,则不做任何处理
- 如果容器被停止了,且容器没有指定restartPolicy(重启策略),则不做任何处理
- 调用docker client 下载容器镜像,调用docker client 运行容器
容器的健康检查
Pod通过两类探针来检查容器的健康状态。一个是livenessProbe探针,用于判断容器是否健康,告诉kubelet一个容器什么时候处于不健康状态,如果livenessProbe探针探测到容器不健康,则kubelet将删除该容器,并根据容器的重启策略做相应的处理;如果一个容器不包含livenessProbe探针,那么kubelet认为livenessProbe探针的返回值永远为“success”。
另一个探针为ReadinessProbe,用于判断容器是否启动完成,且准备接受请求。如果ReadinessProbe探针检测到失败,则pod的状态将被修改,endpoint controller将从service的endpoints中删除包含该容器所在pod的IP地址的endpoint条目。
cadvisor资源监控
cadcisor是为容器监控而生的监控工具,目前集成在kubelet中,以4194端口进行暴露。
源码解析
目前是基于master来进行源码处理,目前release版本是1.20,最常用的是1.18
启动分析
kubelet使用的是cobra第三方包来做启动包,同时做了命令行参数的处理,首先是NewKubeletCommand
// NewKubeletCommand creates a *cobra.Command object with default parameters
func NewKubeletCommand() *cobra.Command {
cleanFlagSet := pflag.NewFlagSet(componentKubelet, pflag.ContinueOnError)
cleanFlagSet.SetNormalizeFunc(cliflag.WordSepNormalizeFunc)
kubeletFlags := options.NewKubeletFlags()
kubeletConfig, err := options.NewKubeletConfiguration()
// programmer error
if err != nil {
klog.Fatal(err)
}
...
}
可见kubelet的启动参数可以是命令行参数kubeletFlags,也可以是配置文件kubeletConfig,启动就是使用的cobra中的run方法
Run: func(cmd *cobra.Command, args []string) {
// initial flag parse, since we disable cobra's flag parsing
if err := cleanFlagSet.Parse(args); err != nil {
cmd.Usage()
klog.Fatal(err)
}
// check if there are non-flag arguments in the command line
cmds := cleanFlagSet.Args()
if len(cmds) > 0 {
cmd.Usage()
klog.Fatalf("unknown command: %s", cmds[0])
}
// short-circuit on help
help, err := cleanFlagSet.GetBool("help")
if err != nil {
klog.Fatal(`"help" flag is non-bool, programmer error, please correct`)
}
if help {
cmd.Help()
return
}
// short-circuit on verflag
verflag.PrintAndExitIfRequested()
cliflag.PrintFlags(cleanFlagSet)
// set feature gates from initial flags-based config
if err := utilfeature.DefaultMutableFeatureGate.SetFromMap(kubeletConfig.FeatureGates); err != nil {
klog.Fatal(err)
}
// validate the initial KubeletFlags
if err := options.ValidateKubeletFlags(kubeletFlags); err != nil {
klog.Fatal(err)
}
if kubeletFlags.ContainerRuntime == "remote" && cleanFlagSet.Changed("pod-infra-container-image") {
klog.Warning("Warning: For remote container runtime, --pod-infra-container-image is ignored in kubelet, which should be set in that remote runtime instead")
}
// load kubelet config file, if provided
if configFile := kubeletFlags.KubeletConfigFile; len(configFile) > 0 {
kubeletConfig, err = loadConfigFile(configFile)
if err != nil {
klog.Fatal(err)
}
// We must enforce flag precedence by re-parsing the command line into the new object.
// This is necessary to preserve backwards-compatibility across binary upgrades.
// See issue #56171 for more details.
if err := kubeletConfigFlagPrecedence(kubeletConfig, args); err != nil {
klog.Fatal(err)
}
// update feature gates based on new config
if err := utilfeature.DefaultMutableFeatureGate.SetFromMap(kubeletConfig.FeatureGates); err != nil {
klog.Fatal(err)
}
}
// We always validate the local configuration (command line + config file).
// This is the default "last-known-good" config for dynamic config, and must always remain valid.
if err := kubeletconfigvalidation.ValidateKubeletConfiguration(kubeletConfig); err != nil {
klog.Fatal(err)
}
if (kubeletConfig.KubeletCgroups != "" && kubeletConfig.KubeReservedCgroup != "") && (0 != strings.Index(kubeletConfig.KubeletCgroups, kubeletConfig.KubeReservedCgroup)) {
klog.Warning("unsupported configuration:KubeletCgroups is not within KubeReservedCgroup")
}
// use dynamic kubelet config, if enabled
var kubeletConfigController *dynamickubeletconfig.Controller
if dynamicConfigDir := kubeletFlags.DynamicConfigDir.Value(); len(dynamicConfigDir) > 0 {
var dynamicKubeletConfig *kubeletconfiginternal.KubeletConfiguration
dynamicKubeletConfig, kubeletConfigController, err = BootstrapKubeletConfigController(dynamicConfigDir,
func(kc *kubeletconfiginternal.KubeletConfiguration) error {
// Here, we enforce flag precedence inside the controller, prior to the controller's validation sequence,
// so that we get a complete validation at the same point where we can decide to reject dynamic config.
// This fixes the flag-precedence component of issue #63305.
// See issue #56171 for general details on flag precedence.
return kubeletConfigFlagPrecedence(kc, args)
})
if err != nil {
klog.Fatal(err)
}
// If we should just use our existing, local config, the controller will return a nil config
if dynamicKubeletConfig != nil {
kubeletConfig = dynamicKubeletConfig
// Note: flag precedence was already enforced in the controller, prior to validation,
// by our above transform function. Now we simply update feature gates from the new config.
if err := utilfeature.DefaultMutableFeatureGate.SetFromMap(kubeletConfig.FeatureGates); err != nil {
klog.Fatal(err)
}
}
}
// construct a KubeletServer from kubeletFlags and kubeletConfig
kubeletServer := &options.KubeletServer{
KubeletFlags: *kubeletFlags,
KubeletConfiguration: *kubeletConfig,
}
// use kubeletServer to construct the default KubeletDeps
kubeletDeps, err := UnsecuredDependencies(kubeletServer, utilfeature.DefaultFeatureGate)
if err != nil {
klog.Fatal(err)
}
// add the kubelet config controller to kubeletDeps
kubeletDeps.KubeletConfigController = kubeletConfigController
// set up signal context here in order to be reused by kubelet and docker shim
ctx := genericapiserver.SetupSignalContext()
// run the kubelet
klog.V(5).Infof("KubeletConfiguration: %#v", kubeletServer.KubeletConfiguration)
if err := Run(ctx, kubeletServer, kubeletDeps, utilfeature.DefaultFeatureGate); err != nil {
klog.Fatal(err)
}
}
这个方法虽然比较长,但是除了最终的Run方法,其余的步骤还是为kubelet的启动构建初始化的参数,无非就是换一个名称,换一个不同的结构体,并配置相依赖的参数,主要包括以下步骤: - 解析参数,对参数的合法性进行判断; - 根据kubeletConfig解析一些特殊的特性所需要配置的参数; - 配置kubeletServer,包括KubeletFlags和KubeletConfiguration两个参数; - 构造kubeletDeps结构体; - 启动最终的Run方法。
继续调用run方法
func Run(ctx context.Context, s *options.KubeletServer, kubeDeps *kubelet.Dependencies, featureGate featuregate.FeatureGate) error {
logOption := logs.NewOptions()
logOption.LogFormat = s.Logging.Format
logOption.LogSanitization = s.Logging.Sanitization
logOption.Apply()
// To help debugging, immediately log version
klog.Infof("Version: %+v", version.Get())
if err := initForOS(s.KubeletFlags.WindowsService, s.KubeletFlags.WindowsPriorityClass); err != nil {
return fmt.Errorf("failed OS init: %v", err)
}
if err := run(ctx, s, kubeDeps, featureGate); err != nil {
return fmt.Errorf("failed to run Kubelet: %v", err)
}
return nil
}
initForOS通过对操作系统的判断,如果是windows系统需要做一些预先的特殊处理;然后继续执行run方法
func run(ctx context.Context, s *options.KubeletServer, kubeDeps *kubelet.Dependencies, featureGate featuregate.FeatureGate) (err error) {
// Set global feature gates based on the value on the initial KubeletServer
err = utilfeature.DefaultMutableFeatureGate.SetFromMap(s.KubeletConfiguration.FeatureGates)
if err != nil {
return err
}
// validate the initial KubeletServer (we set feature gates first, because this validation depends on feature gates)
if err := options.ValidateKubeletServer(s); err != nil {
return err
}
// Obtain Kubelet Lock File
if s.ExitOnLockContention && s.LockFilePath == "" {
return errors.New("cannot exit on lock file contention: no lock file specified")
}
done := make(chan struct{})
if s.LockFilePath != "" {
klog.Infof("acquiring file lock on %q", s.LockFilePath)
if err := flock.Acquire(s.LockFilePath); err != nil {
return fmt.Errorf("unable to acquire file lock on %q: %v", s.LockFilePath, err)
}
if s.ExitOnLockContention {
klog.Infof("watching for inotify events for: %v", s.LockFilePath)
if err := watchForLockfileContention(s.LockFilePath, done); err != nil {
return err
}
}
}
// Register current configuration with /configz endpoint
err = initConfigz(&s.KubeletConfiguration)
if err != nil {
klog.Errorf("unable to register KubeletConfiguration with configz, error: %v", err)
}
if len(s.ShowHiddenMetricsForVersion) > 0 {
metrics.SetShowHidden()
}
// About to get clients and such, detect standaloneMode
standaloneMode := true
if len(s.KubeConfig) > 0 {
standaloneMode = false
}
if kubeDeps == nil {
kubeDeps, err = UnsecuredDependencies(s, featureGate)
if err != nil {
return err
}
}
if kubeDeps.Cloud == nil {
if !cloudprovider.IsExternal(s.CloudProvider) {
cloudprovider.DeprecationWarningForProvider(s.CloudProvider)
cloud, err := cloudprovider.InitCloudProvider(s.CloudProvider, s.CloudConfigFile)
if err != nil {
return err
}
if cloud != nil {
klog.V(2).Infof("Successfully initialized cloud provider: %q from the config file: %q\n", s.CloudProvider, s.CloudConfigFile)
}
kubeDeps.Cloud = cloud
}
}
hostName, err := nodeutil.GetHostname(s.HostnameOverride)
if err != nil {
return err
}
nodeName, err := getNodeName(kubeDeps.Cloud, hostName)
if err != nil {
return err
}
// if in standalone mode, indicate as much by setting all clients to nil
switch {
case standaloneMode:
kubeDeps.KubeClient = nil
kubeDeps.EventClient = nil
kubeDeps.HeartbeatClient = nil
klog.Warningf("standalone mode, no API client")
case kubeDeps.KubeClient == nil, kubeDeps.EventClient == nil, kubeDeps.HeartbeatClient == nil:
clientConfig, closeAllConns, err := buildKubeletClientConfig(ctx, s, nodeName)
if err != nil {
return err
}
if closeAllConns == nil {
return errors.New("closeAllConns must be a valid function other than nil")
}
kubeDeps.OnHeartbeatFailure = closeAllConns
kubeDeps.KubeClient, err = clientset.NewForConfig(clientConfig)
if err != nil {
return fmt.Errorf("failed to initialize kubelet client: %v", err)
}
// make a separate client for events
eventClientConfig := *clientConfig
eventClientConfig.QPS = float32(s.EventRecordQPS)
eventClientConfig.Burst = int(s.EventBurst)
kubeDeps.EventClient, err = v1core.NewForConfig(&eventClientConfig)
if err != nil {
return fmt.Errorf("failed to initialize kubelet event client: %v", err)
}
// make a separate client for heartbeat with throttling disabled and a timeout attached
heartbeatClientConfig := *clientConfig
heartbeatClientConfig.Timeout = s.KubeletConfiguration.NodeStatusUpdateFrequency.Duration
// The timeout is the minimum of the lease duration and status update frequency
leaseTimeout := time.Duration(s.KubeletConfiguration.NodeLeaseDurationSeconds) * time.Second
if heartbeatClientConfig.Timeout > leaseTimeout {
heartbeatClientConfig.Timeout = leaseTimeout
}
heartbeatClientConfig.QPS = float32(-1)
kubeDeps.HeartbeatClient, err = clientset.NewForConfig(&heartbeatClientConfig)
if err != nil {
return fmt.Errorf("failed to initialize kubelet heartbeat client: %v", err)
}
}
if kubeDeps.Auth == nil {
auth, runAuthenticatorCAReload, err := BuildAuth(nodeName, kubeDeps.KubeClient, s.KubeletConfiguration)
if err != nil {
return err
}
kubeDeps.Auth = auth
runAuthenticatorCAReload(ctx.Done())
}
var cgroupRoots []string
nodeAllocatableRoot := cm.NodeAllocatableRoot(s.CgroupRoot, s.CgroupsPerQOS, s.CgroupDriver)
cgroupRoots = append(cgroupRoots, nodeAllocatableRoot)
kubeletCgroup, err := cm.GetKubeletContainer(s.KubeletCgroups)
if err != nil {
klog.Warningf("failed to get the kubelet's cgroup: %v. Kubelet system container metrics may be missing.", err)
} else if kubeletCgroup != "" {
cgroupRoots = append(cgroupRoots, kubeletCgroup)
}
runtimeCgroup, err := cm.GetRuntimeContainer(s.ContainerRuntime, s.RuntimeCgroups)
if err != nil {
klog.Warningf("failed to get the container runtime's cgroup: %v. Runtime system container metrics may be missing.", err)
} else if runtimeCgroup != "" {
// RuntimeCgroups is optional, so ignore if it isn't specified
cgroupRoots = append(cgroupRoots, runtimeCgroup)
}
if s.SystemCgroups != "" {
// SystemCgroups is optional, so ignore if it isn't specified
cgroupRoots = append(cgroupRoots, s.SystemCgroups)
}
if kubeDeps.CAdvisorInterface == nil {
imageFsInfoProvider := cadvisor.NewImageFsInfoProvider(s.ContainerRuntime, s.RemoteRuntimeEndpoint)
kubeDeps.CAdvisorInterface, err = cadvisor.New(imageFsInfoProvider, s.RootDirectory, cgroupRoots, cadvisor.UsingLegacyCadvisorStats(s.ContainerRuntime, s.RemoteRuntimeEndpoint))
if err != nil {
return err
}
}
// Setup event recorder if required.
makeEventRecorder(kubeDeps, nodeName)
if kubeDeps.ContainerManager == nil {
if s.CgroupsPerQOS && s.CgroupRoot == "" {
klog.Info("--cgroups-per-qos enabled, but --cgroup-root was not specified. defaulting to /")
s.CgroupRoot = "/"
}
var reservedSystemCPUs cpuset.CPUSet
if s.ReservedSystemCPUs != "" {
// is it safe do use CAdvisor here ??
machineInfo, err := kubeDeps.CAdvisorInterface.MachineInfo()
if err != nil {
// if can't use CAdvisor here, fall back to non-explicit cpu list behavor
klog.Warning("Failed to get MachineInfo, set reservedSystemCPUs to empty")
reservedSystemCPUs = cpuset.NewCPUSet()
} else {
var errParse error
reservedSystemCPUs, errParse = cpuset.Parse(s.ReservedSystemCPUs)
if errParse != nil {
// invalid cpu list is provided, set reservedSystemCPUs to empty, so it won't overwrite kubeReserved/systemReserved
klog.Infof("Invalid ReservedSystemCPUs \"%s\"", s.ReservedSystemCPUs)
return errParse
}
reservedList := reservedSystemCPUs.ToSlice()
first := reservedList[0]
last := reservedList[len(reservedList)-1]
if first < 0 || last >= machineInfo.NumCores {
// the specified cpuset is outside of the range of what the machine has
klog.Infof("Invalid cpuset specified by --reserved-cpus")
return fmt.Errorf("Invalid cpuset %q specified by --reserved-cpus", s.ReservedSystemCPUs)
}
}
} else {
reservedSystemCPUs = cpuset.NewCPUSet()
}
if reservedSystemCPUs.Size() > 0 {
// at cmd option valication phase it is tested either --system-reserved-cgroup or --kube-reserved-cgroup is specified, so overwrite should be ok
klog.Infof("Option --reserved-cpus is specified, it will overwrite the cpu setting in KubeReserved=\"%v\", SystemReserved=\"%v\".", s.KubeReserved, s.SystemReserved)
if s.KubeReserved != nil {
delete(s.KubeReserved, "cpu")
}
if s.SystemReserved == nil {
s.SystemReserved = make(map[string]string)
}
s.SystemReserved["cpu"] = strconv.Itoa(reservedSystemCPUs.Size())
klog.Infof("After cpu setting is overwritten, KubeReserved=\"%v\", SystemReserved=\"%v\"", s.KubeReserved, s.SystemReserved)
}
kubeReserved, err := parseResourceList(s.KubeReserved)
if err != nil {
return err
}
systemReserved, err := parseResourceList(s.SystemReserved)
if err != nil {
return err
}
var hardEvictionThresholds []evictionapi.Threshold
// If the user requested to ignore eviction thresholds, then do not set valid values for hardEvictionThresholds here.
if !s.ExperimentalNodeAllocatableIgnoreEvictionThreshold {
hardEvictionThresholds, err = eviction.ParseThresholdConfig([]string{}, s.EvictionHard, nil, nil, nil)
if err != nil {
return err
}
}
experimentalQOSReserved, err := cm.ParseQOSReserved(s.QOSReserved)
if err != nil {
return err
}
devicePluginEnabled := utilfeature.DefaultFeatureGate.Enabled(features.DevicePlugins)
kubeDeps.ContainerManager, err = cm.NewContainerManager(
kubeDeps.Mounter,
kubeDeps.CAdvisorInterface,
cm.NodeConfig{
RuntimeCgroupsName: s.RuntimeCgroups,
SystemCgroupsName: s.SystemCgroups,
KubeletCgroupsName: s.KubeletCgroups,
ContainerRuntime: s.ContainerRuntime,
CgroupsPerQOS: s.CgroupsPerQOS,
CgroupRoot: s.CgroupRoot,
CgroupDriver: s.CgroupDriver,
KubeletRootDir: s.RootDirectory,
ProtectKernelDefaults: s.ProtectKernelDefaults,
NodeAllocatableConfig: cm.NodeAllocatableConfig{
KubeReservedCgroupName: s.KubeReservedCgroup,
SystemReservedCgroupName: s.SystemReservedCgroup,
EnforceNodeAllocatable: sets.NewString(s.EnforceNodeAllocatable...),
KubeReserved: kubeReserved,
SystemReserved: systemReserved,
ReservedSystemCPUs: reservedSystemCPUs,
HardEvictionThresholds: hardEvictionThresholds,
},
QOSReserved: *experimentalQOSReserved,
ExperimentalCPUManagerPolicy: s.CPUManagerPolicy,
ExperimentalCPUManagerReconcilePeriod: s.CPUManagerReconcilePeriod.Duration,
ExperimentalPodPidsLimit: s.PodPidsLimit,
EnforceCPULimits: s.CPUCFSQuota,
CPUCFSQuotaPeriod: s.CPUCFSQuotaPeriod.Duration,
ExperimentalTopologyManagerPolicy: s.TopologyManagerPolicy,
ExperimentalTopologyManagerScope: s.TopologyManagerScope,
},
s.FailSwapOn,
devicePluginEnabled,
kubeDeps.Recorder)
if err != nil {
return err
}
}
if err := checkPermissions(); err != nil {
klog.Error(err)
}
utilruntime.ReallyCrash = s.ReallyCrashForTesting
// TODO(vmarmol): Do this through container config.
oomAdjuster := kubeDeps.OOMAdjuster
if err := oomAdjuster.ApplyOOMScoreAdj(0, int(s.OOMScoreAdj)); err != nil {
klog.Warning(err)
}
err = kubelet.PreInitRuntimeService(&s.KubeletConfiguration,
kubeDeps, &s.ContainerRuntimeOptions,
s.ContainerRuntime,
s.RuntimeCgroups,
s.RemoteRuntimeEndpoint,
s.RemoteImageEndpoint,
s.NonMasqueradeCIDR)
if err != nil {
return err
}
if err := RunKubelet(s, kubeDeps, s.RunOnce); err != nil {
return err
}
// If the kubelet config controller is available, and dynamic config is enabled, start the config and status sync loops
if utilfeature.DefaultFeatureGate.Enabled(features.DynamicKubeletConfig) && len(s.DynamicConfigDir.Value()) > 0 &&
kubeDeps.KubeletConfigController != nil && !standaloneMode && !s.RunOnce {
if err := kubeDeps.KubeletConfigController.StartSync(kubeDeps.KubeClient, kubeDeps.EventClient, string(nodeName)); err != nil {
return err
}
}
if s.HealthzPort > 0 {
mux := http.NewServeMux()
healthz.InstallHandler(mux)
go wait.Until(func() {
err := http.ListenAndServe(net.JoinHostPort(s.HealthzBindAddress, strconv.Itoa(int(s.HealthzPort))), mux)
if err != nil {
klog.Errorf("Starting healthz server failed: %v", err)
}
}, 5*time.Second, wait.NeverStop)
}
if s.RunOnce {
return nil
}
// If systemd is used, notify it that we have started
go daemon.SdNotify(false, "READY=1")
select {
case <-done:
break
case <-ctx.Done():
break
}
return nil
}
主要执行对参数的再一次验证,以及新的结构体的初始化。后续开始构建一些重要的客户端,包括eventClient主要处理事件的上报,与apiserver打交道;heartbeatClient主要处理心跳操作,与之后的PLEG相关;csiClient主要与CSI接口相关。配置完成之后,最终进入RunKubelet方法。
// RunKubelet is responsible for setting up and running a kubelet. It is used in three different applications:
// 1 Integration tests
// 2 Kubelet binary
// 3 Standalone 'kubernetes' binary
// Eventually, #2 will be replaced with instances of #3
func RunKubelet(kubeServer *options.KubeletServer, kubeDeps *kubelet.Dependencies, runOnce bool) error {
hostname, err := nodeutil.GetHostname(kubeServer.HostnameOverride)
if err != nil {
return err
}
// Query the cloud provider for our node name, default to hostname if kubeDeps.Cloud == nil
nodeName, err := getNodeName(kubeDeps.Cloud, hostname)
if err != nil {
return err
}
hostnameOverridden := len(kubeServer.HostnameOverride) > 0
// Setup event recorder if required.
makeEventRecorder(kubeDeps, nodeName)
var nodeIPs []net.IP
if kubeServer.NodeIP != "" {
for _, ip := range strings.Split(kubeServer.NodeIP, ",") {
parsedNodeIP := net.ParseIP(strings.TrimSpace(ip))
if parsedNodeIP == nil {
klog.Warningf("Could not parse --node-ip value %q; ignoring", ip)
} else {
nodeIPs = append(nodeIPs, parsedNodeIP)
}
}
}
if !utilfeature.DefaultFeatureGate.Enabled(features.IPv6DualStack) && len(nodeIPs) > 1 {
return fmt.Errorf("dual-stack --node-ip %q not supported in a single-stack cluster", kubeServer.NodeIP)
} else if len(nodeIPs) > 2 || (len(nodeIPs) == 2 && utilnet.IsIPv6(nodeIPs[0]) == utilnet.IsIPv6(nodeIPs[1])) {
return fmt.Errorf("bad --node-ip %q; must contain either a single IP or a dual-stack pair of IPs", kubeServer.NodeIP)
} else if len(nodeIPs) == 2 && kubeServer.CloudProvider != "" {
return fmt.Errorf("dual-stack --node-ip %q not supported when using a cloud provider", kubeServer.NodeIP)
} else if len(nodeIPs) == 2 && (nodeIPs[0].IsUnspecified() || nodeIPs[1].IsUnspecified()) {
return fmt.Errorf("dual-stack --node-ip %q cannot include '0.0.0.0' or '::'", kubeServer.NodeIP)
}
capabilities.Initialize(capabilities.Capabilities{
AllowPrivileged: true,
})
credentialprovider.SetPreferredDockercfgPath(kubeServer.RootDirectory)
klog.V(2).Infof("Using root directory: %v", kubeServer.RootDirectory)
if kubeDeps.OSInterface == nil {
kubeDeps.OSInterface = kubecontainer.RealOS{}
}
k, err := createAndInitKubelet(&kubeServer.KubeletConfiguration,
kubeDeps,
&kubeServer.ContainerRuntimeOptions,
kubeServer.ContainerRuntime,
hostname,
hostnameOverridden,
nodeName,
nodeIPs,
kubeServer.ProviderID,
kubeServer.CloudProvider,
kubeServer.CertDirectory,
kubeServer.RootDirectory,
kubeServer.ImageCredentialProviderConfigFile,
kubeServer.ImageCredentialProviderBinDir,
kubeServer.RegisterNode,
kubeServer.RegisterWithTaints,
kubeServer.AllowedUnsafeSysctls,
kubeServer.ExperimentalMounterPath,
kubeServer.KernelMemcgNotification,
kubeServer.ExperimentalCheckNodeCapabilitiesBeforeMount,
kubeServer.ExperimentalNodeAllocatableIgnoreEvictionThreshold,
kubeServer.MinimumGCAge,
kubeServer.MaxPerPodContainerCount,
kubeServer.MaxContainerCount,
kubeServer.MasterServiceNamespace,
kubeServer.RegisterSchedulable,
kubeServer.KeepTerminatedPodVolumes,
kubeServer.NodeLabels,
kubeServer.SeccompProfileRoot,
kubeServer.NodeStatusMaxImages)
if err != nil {
return fmt.Errorf("failed to create kubelet: %v", err)
}
// NewMainKubelet should have set up a pod source config if one didn't exist
// when the builder was run. This is just a precaution.
if kubeDeps.PodConfig == nil {
return fmt.Errorf("failed to create kubelet, pod source config was nil")
}
podCfg := kubeDeps.PodConfig
if err := rlimit.SetNumFiles(uint64(kubeServer.MaxOpenFiles)); err != nil {
klog.Errorf("Failed to set rlimit on max file handles: %v", err)
}
// process pods and exit.
if runOnce {
if _, err := k.RunOnce(podCfg.Updates()); err != nil {
return fmt.Errorf("runonce failed: %v", err)
}
klog.Info("Started kubelet as runonce")
} else {
startKubelet(k, podCfg, &kubeServer.KubeletConfiguration, kubeDeps, kubeServer.EnableCAdvisorJSONEndpoints, kubeServer.EnableServer)
klog.Info("Started kubelet")
}
return nil
}
RunKubelet方法最重要的方法有两个:CreateAndInitKubelet和startKubelet,可以理解为CreateAndInitKubelet为参数的配置,startKubelet为最终的启动,其实最后说来说去还是把参数封装一遍,重新构造新的结构体来运行。
CreateAndInitKubelet方法通过调用NewMainKubelet返回Kubelet结构体。在NewMainKubelet中,主要的配置有:
- PodConfig。通过makePodSourceConfig可以发现kubelet获取Pod的来源有以下途径:静态Pod、静态Pod的URL地址以及kube-apiserver;
- 容器与镜像的GC参数。
- 驱逐Pod策略。
最终通过参数填充Kubelet结构体,完成kubelet结构体参数的最终配置。
然后就是启动startKubelet,在启动之前,判断是以后台daemon进程一直运行还是只启动一次,即runOnce,基本上都是以后台daemon启动的方式,所以大部分调用的是startKubelet方法。
func startKubelet(k kubelet.Bootstrap, podCfg *config.PodConfig, kubeCfg *kubeletconfiginternal.KubeletConfiguration, kubeDeps *kubelet.Dependencies, enableCAdvisorJSONEndpoints, enableServer bool) {
// start the kubelet
go k.Run(podCfg.Updates())
// start the kubelet server
if enableServer {
go k.ListenAndServe(net.ParseIP(kubeCfg.Address), uint(kubeCfg.Port), kubeDeps.TLSOptions, kubeDeps.Auth,
enableCAdvisorJSONEndpoints, kubeCfg.EnableDebuggingHandlers, kubeCfg.EnableContentionProfiling, kubeCfg.EnableSystemLogHandler)
}
if kubeCfg.ReadOnlyPort > 0 {
go k.ListenAndServeReadOnly(net.ParseIP(kubeCfg.Address), uint(kubeCfg.ReadOnlyPort), enableCAdvisorJSONEndpoints)
}
if utilfeature.DefaultFeatureGate.Enabled(features.KubeletPodResources) {
go k.ListenAndServePodResources()
}
}
可见开来goroutine,调用run方法,上面构建的是kubelet结构体,所以这边调用的也是kubelet的run方法。
// Run starts the kubelet reacting to config updates
func (kl *Kubelet) Run(updates <-chan kubetypes.PodUpdate) {
if kl.logServer == nil {
kl.logServer = http.StripPrefix("/logs/", http.FileServer(http.Dir("/var/log/")))
}
if kl.kubeClient == nil {
klog.Warning("No api server defined - no node status update will be sent.")
}
// Start the cloud provider sync manager
if kl.cloudResourceSyncManager != nil {
go kl.cloudResourceSyncManager.Run(wait.NeverStop)
}
if err := kl.initializeModules(); err != nil {
kl.recorder.Eventf(kl.nodeRef, v1.EventTypeWarning, events.KubeletSetupFailed, err.Error())
klog.Fatal(err)
}
// Start volume manager
go kl.volumeManager.Run(kl.sourcesReady, wait.NeverStop)
if kl.kubeClient != nil {
// Start syncing node status immediately, this may set up things the runtime needs to run.
go wait.Until(kl.syncNodeStatus, kl.nodeStatusUpdateFrequency, wait.NeverStop)
go kl.fastStatusUpdateOnce()
// start syncing lease
go kl.nodeLeaseController.Run(wait.NeverStop)
}
go wait.Until(kl.updateRuntimeUp, 5*time.Second, wait.NeverStop)
// Set up iptables util rules
if kl.makeIPTablesUtilChains {
kl.initNetworkUtil()
}
// Start a goroutine responsible for killing pods (that are not properly
// handled by pod workers).
go wait.Until(kl.podKiller.PerformPodKillingWork, 1*time.Second, wait.NeverStop)
// Start component sync loops.
kl.statusManager.Start()
kl.probeManager.Start()
// Start syncing RuntimeClasses if enabled.
if kl.runtimeClassManager != nil {
kl.runtimeClassManager.Start(wait.NeverStop)
}
// Start the pod lifecycle event generator.
kl.pleg.Start()
kl.syncLoop(updates, kl)
}
可以看到这边是kubelet的调度核心,在该方法内,通过多个goroutine完成最终的kubelet的任务:
- volumeManager,volume相关管理;
- syncNodeStatus,定时同步Node状态;
- updateRuntimeUp,定时更新Runtime状态;
- syncNetworkUtil,定时同步网络状态;
- podKiller,定时清理死亡的pod;
- statusManager,pod状态管理;
- probeManager,pod探针管理;
- 启动PLEG;
- syncLoop,最重要的主进程,不停监听外部数据的变化执行pod的相应操作。
至此,kubelet启动过程完成。启动主要完成的任务就是参数的配置和多个任务的启动,通过构造一个循环进程不停监听外部事件的变化,执行对应的pod处理工作,这也就是kubelet所需要负责的任务。
Pod启动流程
在上面主进程syncLoop中,不停监听外部数据的变化执行pod的相应操作,那么如何启动pod的,我们来看一下
func (kl *Kubelet) syncLoop(updates <-chan kubetypes.PodUpdate, handler SyncHandler) {
klog.Info("Starting kubelet main sync loop.")
// The syncTicker wakes up kubelet to checks if there are any pod workers
// that need to be sync'd. A one-second period is sufficient because the
// sync interval is defaulted to 10s.
syncTicker := time.NewTicker(time.Second)
defer syncTicker.Stop()
housekeepingTicker := time.NewTicker(housekeepingPeriod)
defer housekeepingTicker.Stop()
plegCh := kl.pleg.Watch()
const (
base = 100 * time.Millisecond
max = 5 * time.Second
factor = 2
)
duration := base
// Responsible for checking limits in resolv.conf
// The limits do not have anything to do with individual pods
// Since this is called in syncLoop, we don't need to call it anywhere else
if kl.dnsConfigurer != nil && kl.dnsConfigurer.ResolverConfig != "" {
kl.dnsConfigurer.CheckLimitsForResolvConf()
}
for {
if err := kl.runtimeState.runtimeErrors(); err != nil {
klog.Errorf("skipping pod synchronization - %v", err)
// exponential backoff
time.Sleep(duration)
duration = time.Duration(math.Min(float64(max), factor*float64(duration)))
continue
}
// reset backoff if we have a success
duration = base
kl.syncLoopMonitor.Store(kl.clock.Now())
if !kl.syncLoopIteration(updates, handler, syncTicker.C, housekeepingTicker.C, plegCh) {
break
}
kl.syncLoopMonitor.Store(kl.clock.Now())
}
}
核心处理函数syncLoopIteration,它有五个参数
- configCh:获取Pod信息的channel,关于Pod相关的事件都从该channel获取;
- handler:处理Pod的handler;
- syncCh:同步所有等待同步的Pod;
- houseKeepingCh:清理Pod的channel;
- plegCh:获取PLEG信息,同步Pod。
通过select判断某个channel获取到信息,处理相应的操作。Pod的启动显然与configCh相关。
func (kl *Kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
// Update from a config source; dispatch it to the right handler
// callback.
if !open {
klog.Errorf("Update channel is closed. Exiting the sync loop.")
return false
}
switch u.Op {
case kubetypes.ADD:
klog.V(2).Infof("SyncLoop (ADD, %q): %q", u.Source, format.Pods(u.Pods))
// After restarting, kubelet will get all existing pods through
// ADD as if they are new pods. These pods will then go through the
// admission process and *may* be rejected. This can be resolved
// once we have checkpointing.
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
klog.V(2).Infof("SyncLoop (UPDATE, %q): %q", u.Source, format.PodsWithDeletionTimestamps(u.Pods))
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
klog.V(2).Infof("SyncLoop (REMOVE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
klog.V(4).Infof("SyncLoop (RECONCILE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
klog.V(2).Infof("SyncLoop (DELETE, %q): %q", u.Source, format.Pods(u.Pods))
// DELETE is treated as a UPDATE because of graceful deletion.
handler.HandlePodUpdates(u.Pods)
case kubetypes.SET:
// TODO: Do we want to support this?
klog.Errorf("Kubelet does not support snapshot update")
default:
klog.Errorf("Invalid event type received: %d.", u.Op)
}
kl.sourcesReady.AddSource(u.Source)
case e := <-plegCh:
if e.Type == pleg.ContainerStarted {
// record the most recent time we observed a container start for this pod.
// this lets us selectively invalidate the runtimeCache when processing a delete for this pod
// to make sure we don't miss handling graceful termination for containers we reported as having started.
kl.lastContainerStartedTime.Add(e.ID, time.Now())
}
if isSyncPodWorthy(e) {
// PLEG event for a pod; sync it.
if pod, ok := kl.podManager.GetPodByUID(e.ID); ok {
klog.V(2).Infof("SyncLoop (PLEG): %q, event: %#v", format.Pod(pod), e)
handler.HandlePodSyncs([]*v1.Pod{pod})
} else {
// If the pod no longer exists, ignore the event.
klog.V(4).Infof("SyncLoop (PLEG): ignore irrelevant event: %#v", e)
}
}
if e.Type == pleg.ContainerDied {
if containerID, ok := e.Data.(string); ok {
kl.cleanUpContainersInPod(e.ID, containerID)
}
}
case <-syncCh:
// Sync pods waiting for sync
podsToSync := kl.getPodsToSync()
if len(podsToSync) == 0 {
break
}
klog.V(4).Infof("SyncLoop (SYNC): %d pods; %s", len(podsToSync), format.Pods(podsToSync))
handler.HandlePodSyncs(podsToSync)
case update := <-kl.livenessManager.Updates():
if update.Result == proberesults.Failure {
// The liveness manager detected a failure; sync the pod.
// We should not use the pod from livenessManager, because it is never updated after
// initialization.
pod, ok := kl.podManager.GetPodByUID(update.PodUID)
if !ok {
// If the pod no longer exists, ignore the update.
klog.V(4).Infof("SyncLoop (container unhealthy): ignore irrelevant update: %#v", update)
break
}
klog.V(1).Infof("SyncLoop (container unhealthy): %q", format.Pod(pod))
handler.HandlePodSyncs([]*v1.Pod{pod})
}
case <-housekeepingCh:
if !kl.sourcesReady.AllReady() {
// If the sources aren't ready or volume manager has not yet synced the states,
// skip housekeeping, as we may accidentally delete pods from unready sources.
klog.V(4).Infof("SyncLoop (housekeeping, skipped): sources aren't ready yet.")
} else {
klog.V(4).Infof("SyncLoop (housekeeping)")
if err := handler.HandlePodCleanups(); err != nil {
klog.Errorf("Failed cleaning pods: %v", err)
}
}
}
return true
}
可以看出重configCh获取的pod的信息包含操作,不同的操作有这边不同的处理函数,关于操作和函数的定义如下
const (
// SET is the current pod configuration.
SET PodOperation = iota
// ADD signifies pods that are new to this source.
ADD
// DELETE signifies pods that are gracefully deleted from this source.
DELETE
// REMOVE signifies pods that have been removed from this source.
REMOVE
// UPDATE signifies pods have been updated in this source.
UPDATE
// RECONCILE signifies pods that have unexpected status in this source,
// kubelet should reconcile status with this source.
RECONCILE
)
// SyncHandler is an interface implemented by Kubelet, for testability
type SyncHandler interface {
HandlePodAdditions(pods []*v1.Pod)
HandlePodUpdates(pods []*v1.Pod)
HandlePodRemoves(pods []*v1.Pod)
HandlePodReconcile(pods []*v1.Pod)
HandlePodSyncs(pods []*v1.Pod)
HandlePodCleanups() error
}
创建pod就应该是ADD操作,其对应的处理方法为HandlePodAdditions,我们handler其实传递的就是kubelet的结构体,所以其实就是kubelet的HandlePodAdditions函数
func (kl *Kubelet) HandlePodAdditions(pods []*v1.Pod) {
start := kl.clock.Now()
sort.Sort(sliceutils.PodsByCreationTime(pods))
for _, pod := range pods {
existingPods := kl.podManager.GetPods()
// Always add the pod to the pod manager. Kubelet relies on the pod
// manager as the source of truth for the desired state. If a pod does
// not exist in the pod manager, it means that it has been deleted in
// the apiserver and no action (other than cleanup) is required.
kl.podManager.AddPod(pod)
if kubetypes.IsMirrorPod(pod) {
kl.handleMirrorPod(pod, start)
continue
}
if !kl.podIsTerminated(pod) {
// Only go through the admission process if the pod is not
// terminated.
// We failed pods that we rejected, so activePods include all admitted
// pods that are alive.
activePods := kl.filterOutTerminatedPods(existingPods)
// Check if we can admit the pod; if not, reject it.
if ok, reason, message := kl.canAdmitPod(activePods, pod); !ok {
kl.rejectPod(pod, reason, message)
continue
}
}
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodCreate, mirrorPod, start)
kl.probeManager.AddPod(pod)
}
}
主要以下几个步骤:
- 根据Pod的创建时间对Pod进行排序;
- podManager添加Pod;(对Pod的管理依赖于podManager)
- 处理mirrorPod,即静态Pod的处理;
- 通过dispatchWork方法分发任务,处理Pod的创建;
- probeManager添加Pod。(readiness和liveness探针)
核心就是dispatchWork做的,它调用了kl.podWorkers.UpdatePod方法对Pod进行创建。
func (kl *Kubelet) dispatchWork(pod *v1.Pod, syncType kubetypes.SyncPodType, mirrorPod *v1.Pod, start time.Time) {
// check whether we are ready to delete the pod from the API server (all status up to date)
containersTerminal, podWorkerTerminal := kl.podAndContainersAreTerminal(pod)
if pod.DeletionTimestamp != nil && containersTerminal {
klog.V(4).Infof("Pod %q has completed execution and should be deleted from the API server: %s", format.Pod(pod), syncType)
kl.statusManager.TerminatePod(pod)
return
}
// optimization: avoid invoking the pod worker if no further changes are possible to the pod definition
if podWorkerTerminal {
klog.V(4).Infof("Pod %q has completed, ignoring remaining sync work: %s", format.Pod(pod), syncType)
return
}
// Run the sync in an async worker.
kl.podWorkers.UpdatePod(&UpdatePodOptions{
Pod: pod,
MirrorPod: mirrorPod,
UpdateType: syncType,
OnCompleteFunc: func(err error) {
if err != nil {
metrics.PodWorkerDuration.WithLabelValues(syncType.String()).Observe(metrics.SinceInSeconds(start))
}
},
})
// Note the number of containers for new pods.
if syncType == kubetypes.SyncPodCreate {
metrics.ContainersPerPodCount.Observe(float64(len(pod.Spec.Containers)))
}
}
func (p *podWorkers) UpdatePod(options *UpdatePodOptions) {
pod := options.Pod
uid := pod.UID
var podUpdates chan UpdatePodOptions
var exists bool
p.podLock.Lock()
defer p.podLock.Unlock()
if podUpdates, exists = p.podUpdates[uid]; !exists {
// We need to have a buffer here, because checkForUpdates() method that
// puts an update into channel is called from the same goroutine where
// the channel is consumed. However, it is guaranteed that in such case
// the channel is empty, so buffer of size 1 is enough.
podUpdates = make(chan UpdatePodOptions, 1)
p.podUpdates[uid] = podUpdates
// Creating a new pod worker either means this is a new pod, or that the
// kubelet just restarted. In either case the kubelet is willing to believe
// the status of the pod for the first pod worker sync. See corresponding
// comment in syncPod.
go func() {
defer runtime.HandleCrash()
p.managePodLoop(podUpdates)
}()
}
if !p.isWorking[pod.UID] {
p.isWorking[pod.UID] = true
podUpdates <- *options
} else {
// if a request to kill a pod is pending, we do not let anything overwrite that request.
update, found := p.lastUndeliveredWorkUpdate[pod.UID]
if !found || update.UpdateType != kubetypes.SyncPodKill {
p.lastUndeliveredWorkUpdate[pod.UID] = *options
}
}
}
UpdatePod方法通过podUpdates的map类型获取相对应的Pod,map的key为Pod的UID,value为UpdatePodOptions的结构体channel。通过获取到需要创建的Pod之后,单独起一个goroutine调用managePodLoop方法完成Pod的创建,managePodLoop方法最终调用syncPodFn完成Pod的创建,syncPodFn对应的就是Kubelet的syncPod方法,位于kubernetes/pkg/kubelet/kubelet.go下。经过层层环绕,syncPod就是最终处理Pod创建的方法。
func (p *podWorkers) managePodLoop(podUpdates <-chan UpdatePodOptions) {
var lastSyncTime time.Time
for update := range podUpdates {
err := func() error {
podUID := update.Pod.UID
// This is a blocking call that would return only if the cache
// has an entry for the pod that is newer than minRuntimeCache
// Time. This ensures the worker doesn't start syncing until
// after the cache is at least newer than the finished time of
// the previous sync.
status, err := p.podCache.GetNewerThan(podUID, lastSyncTime)
if err != nil {
// This is the legacy event thrown by manage pod loop
// all other events are now dispatched from syncPodFn
p.recorder.Eventf(update.Pod, v1.EventTypeWarning, events.FailedSync, "error determining status: %v", err)
return err
}
err = p.syncPodFn(syncPodOptions{
mirrorPod: update.MirrorPod,
pod: update.Pod,
podStatus: status,
killPodOptions: update.KillPodOptions,
updateType: update.UpdateType,
})
lastSyncTime = time.Now()
return err
}()
// notify the call-back function if the operation succeeded or not
if update.OnCompleteFunc != nil {
update.OnCompleteFunc(err)
}
if err != nil {
// IMPORTANT: we do not log errors here, the syncPodFn is responsible for logging errors
klog.Errorf("Error syncing pod %s (%q), skipping: %v", update.Pod.UID, format.Pod(update.Pod), err)
}
p.wrapUp(update.Pod.UID, err)
}
}
syncPod主要的工作
func (kl *Kubelet) syncPod(o syncPodOptions) error {
// pull out the required options
pod := o.pod
mirrorPod := o.mirrorPod
podStatus := o.podStatus
updateType := o.updateType
// if we want to kill a pod, do it now!
if updateType == kubetypes.SyncPodKill {
killPodOptions := o.killPodOptions
if killPodOptions == nil || killPodOptions.PodStatusFunc == nil {
return fmt.Errorf("kill pod options are required if update type is kill")
}
apiPodStatus := killPodOptions.PodStatusFunc(pod, podStatus)
kl.statusManager.SetPodStatus(pod, apiPodStatus)
// we kill the pod with the specified grace period since this is a termination
if err := kl.killPod(pod, nil, podStatus, killPodOptions.PodTerminationGracePeriodSecondsOverride); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToKillPod, "error killing pod: %v", err)
// there was an error killing the pod, so we return that error directly
utilruntime.HandleError(err)
return err
}
return nil
}
// If the pod is a static pod and its mirror pod is still gracefully terminating,
// we do not want to start the new static pod until the old static pod is gracefully terminated.
podFullName := kubecontainer.GetPodFullName(pod)
if kl.podKiller.IsMirrorPodPendingTerminationByPodName(podFullName) {
return fmt.Errorf("pod %q is pending termination", podFullName)
}
// Latency measurements for the main workflow are relative to the
// first time the pod was seen by the API server.
var firstSeenTime time.Time
if firstSeenTimeStr, ok := pod.Annotations[kubetypes.ConfigFirstSeenAnnotationKey]; ok {
firstSeenTime = kubetypes.ConvertToTimestamp(firstSeenTimeStr).Get()
}
// Record pod worker start latency if being created
// TODO: make pod workers record their own latencies
if updateType == kubetypes.SyncPodCreate {
if !firstSeenTime.IsZero() {
// This is the first time we are syncing the pod. Record the latency
// since kubelet first saw the pod if firstSeenTime is set.
metrics.PodWorkerStartDuration.Observe(metrics.SinceInSeconds(firstSeenTime))
} else {
klog.V(3).Infof("First seen time not recorded for pod %q", pod.UID)
}
}
// Generate final API pod status with pod and status manager status
apiPodStatus := kl.generateAPIPodStatus(pod, podStatus)
// The pod IP may be changed in generateAPIPodStatus if the pod is using host network. (See #24576)
// TODO(random-liu): After writing pod spec into container labels, check whether pod is using host network, and
// set pod IP to hostIP directly in runtime.GetPodStatus
podStatus.IPs = make([]string, 0, len(apiPodStatus.PodIPs))
for _, ipInfo := range apiPodStatus.PodIPs {
podStatus.IPs = append(podStatus.IPs, ipInfo.IP)
}
if len(podStatus.IPs) == 0 && len(apiPodStatus.PodIP) > 0 {
podStatus.IPs = []string{apiPodStatus.PodIP}
}
// Record the time it takes for the pod to become running.
existingStatus, ok := kl.statusManager.GetPodStatus(pod.UID)
if !ok || existingStatus.Phase == v1.PodPending && apiPodStatus.Phase == v1.PodRunning &&
!firstSeenTime.IsZero() {
metrics.PodStartDuration.Observe(metrics.SinceInSeconds(firstSeenTime))
}
runnable := kl.canRunPod(pod)
if !runnable.Admit {
// Pod is not runnable; update the Pod and Container statuses to why.
apiPodStatus.Reason = runnable.Reason
apiPodStatus.Message = runnable.Message
// Waiting containers are not creating.
const waitingReason = "Blocked"
for _, cs := range apiPodStatus.InitContainerStatuses {
if cs.State.Waiting != nil {
cs.State.Waiting.Reason = waitingReason
}
}
for _, cs := range apiPodStatus.ContainerStatuses {
if cs.State.Waiting != nil {
cs.State.Waiting.Reason = waitingReason
}
}
}
// Update status in the status manager
kl.statusManager.SetPodStatus(pod, apiPodStatus)
// Kill pod if it should not be running
if !runnable.Admit || pod.DeletionTimestamp != nil || apiPodStatus.Phase == v1.PodFailed {
var syncErr error
if err := kl.killPod(pod, nil, podStatus, nil); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToKillPod, "error killing pod: %v", err)
syncErr = fmt.Errorf("error killing pod: %v", err)
utilruntime.HandleError(syncErr)
} else {
if !runnable.Admit {
// There was no error killing the pod, but the pod cannot be run.
// Return an error to signal that the sync loop should back off.
syncErr = fmt.Errorf("pod cannot be run: %s", runnable.Message)
}
}
return syncErr
}
// If the network plugin is not ready, only start the pod if it uses the host network
if err := kl.runtimeState.networkErrors(); err != nil && !kubecontainer.IsHostNetworkPod(pod) {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.NetworkNotReady, "%s: %v", NetworkNotReadyErrorMsg, err)
return fmt.Errorf("%s: %v", NetworkNotReadyErrorMsg, err)
}
// Create Cgroups for the pod and apply resource parameters
// to them if cgroups-per-qos flag is enabled.
pcm := kl.containerManager.NewPodContainerManager()
// If pod has already been terminated then we need not create
// or update the pod's cgroup
if !kl.podIsTerminated(pod) {
// When the kubelet is restarted with the cgroups-per-qos
// flag enabled, all the pod's running containers
// should be killed intermittently and brought back up
// under the qos cgroup hierarchy.
// Check if this is the pod's first sync
firstSync := true
for _, containerStatus := range apiPodStatus.ContainerStatuses {
if containerStatus.State.Running != nil {
firstSync = false
break
}
}
// Don't kill containers in pod if pod's cgroups already
// exists or the pod is running for the first time
podKilled := false
if !pcm.Exists(pod) && !firstSync {
if err := kl.killPod(pod, nil, podStatus, nil); err == nil {
podKilled = true
} else {
klog.Errorf("killPod for pod %q (podStatus=%v) failed: %v", format.Pod(pod), podStatus, err)
}
}
// Create and Update pod's Cgroups
// Don't create cgroups for run once pod if it was killed above
// The current policy is not to restart the run once pods when
// the kubelet is restarted with the new flag as run once pods are
// expected to run only once and if the kubelet is restarted then
// they are not expected to run again.
// We don't create and apply updates to cgroup if its a run once pod and was killed above
if !(podKilled && pod.Spec.RestartPolicy == v1.RestartPolicyNever) {
if !pcm.Exists(pod) {
if err := kl.containerManager.UpdateQOSCgroups(); err != nil {
klog.V(2).Infof("Failed to update QoS cgroups while syncing pod: %v", err)
}
if err := pcm.EnsureExists(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToCreatePodContainer, "unable to ensure pod container exists: %v", err)
return fmt.Errorf("failed to ensure that the pod: %v cgroups exist and are correctly applied: %v", pod.UID, err)
}
}
}
}
// Create Mirror Pod for Static Pod if it doesn't already exist
if kubetypes.IsStaticPod(pod) {
deleted := false
if mirrorPod != nil {
if mirrorPod.DeletionTimestamp != nil || !kl.podManager.IsMirrorPodOf(mirrorPod, pod) {
// The mirror pod is semantically different from the static pod. Remove
// it. The mirror pod will get recreated later.
klog.Infof("Trying to delete pod %s %v", podFullName, mirrorPod.ObjectMeta.UID)
var err error
deleted, err = kl.podManager.DeleteMirrorPod(podFullName, &mirrorPod.ObjectMeta.UID)
if deleted {
klog.Warningf("Deleted mirror pod %q because it is outdated", format.Pod(mirrorPod))
} else if err != nil {
klog.Errorf("Failed deleting mirror pod %q: %v", format.Pod(mirrorPod), err)
}
}
}
if mirrorPod == nil || deleted {
node, err := kl.GetNode()
if err != nil || node.DeletionTimestamp != nil {
klog.V(4).Infof("No need to create a mirror pod, since node %q has been removed from the cluster", kl.nodeName)
} else {
klog.V(4).Infof("Creating a mirror pod for static pod %q", format.Pod(pod))
if err := kl.podManager.CreateMirrorPod(pod); err != nil {
klog.Errorf("Failed creating a mirror pod for %q: %v", format.Pod(pod), err)
}
}
}
}
// Make data directories for the pod
if err := kl.makePodDataDirs(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToMakePodDataDirectories, "error making pod data directories: %v", err)
klog.Errorf("Unable to make pod data directories for pod %q: %v", format.Pod(pod), err)
return err
}
// Volume manager will not mount volumes for terminated pods
if !kl.podIsTerminated(pod) {
// Wait for volumes to attach/mount
if err := kl.volumeManager.WaitForAttachAndMount(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedMountVolume, "Unable to attach or mount volumes: %v", err)
klog.Errorf("Unable to attach or mount volumes for pod %q: %v; skipping pod", format.Pod(pod), err)
return err
}
}
// Fetch the pull secrets for the pod
pullSecrets := kl.getPullSecretsForPod(pod)
// Call the container runtime's SyncPod callback
result := kl.containerRuntime.SyncPod(pod, podStatus, pullSecrets, kl.backOff)
kl.reasonCache.Update(pod.UID, result)
if err := result.Error(); err != nil {
// Do not return error if the only failures were pods in backoff
for _, r := range result.SyncResults {
if r.Error != kubecontainer.ErrCrashLoopBackOff && r.Error != images.ErrImagePullBackOff {
// Do not record an event here, as we keep all event logging for sync pod failures
// local to container runtime so we get better errors
return err
}
}
return nil
}
return nil
}
上面代码主要做了如下事情
- 更新Pod的状态,对应generateAPIPodStatus和statusManager.SetPodStatus方法;
- 创建Pod存储的目录,对应makePodDataDirs方法;
- 挂载对应的volume,对应volumeManager.WaitForAttachAndMount方法;
- 获取ImagePullSecrets,对应getPullSecretsForPod方法;
- 创建容器,对应containerRuntime.SyncPod方法
创建容器containerRuntime.SyncPod方法
func (m *kubeGenericRuntimeManager) SyncPod(pod *v1.Pod, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) (result kubecontainer.PodSyncResult) {
// Step 1: Compute sandbox and container changes.
podContainerChanges := m.computePodActions(pod, podStatus)
klog.V(3).Infof("computePodActions got %+v for pod %q", podContainerChanges, format.Pod(pod))
if podContainerChanges.CreateSandbox {
ref, err := ref.GetReference(legacyscheme.Scheme, pod)
if err != nil {
klog.Errorf("Couldn't make a ref to pod %q: '%v'", format.Pod(pod), err)
}
if podContainerChanges.SandboxID != "" {
m.recorder.Eventf(ref, v1.EventTypeNormal, events.SandboxChanged, "Pod sandbox changed, it will be killed and re-created.")
} else {
klog.V(4).Infof("SyncPod received new pod %q, will create a sandbox for it", format.Pod(pod))
}
}
// Step 2: Kill the pod if the sandbox has changed.
if podContainerChanges.KillPod {
if podContainerChanges.CreateSandbox {
klog.V(4).Infof("Stopping PodSandbox for %q, will start new one", format.Pod(pod))
} else {
klog.V(4).Infof("Stopping PodSandbox for %q because all other containers are dead.", format.Pod(pod))
}
killResult := m.killPodWithSyncResult(pod, kubecontainer.ConvertPodStatusToRunningPod(m.runtimeName, podStatus), nil)
result.AddPodSyncResult(killResult)
if killResult.Error() != nil {
klog.Errorf("killPodWithSyncResult failed: %v", killResult.Error())
return
}
if podContainerChanges.CreateSandbox {
m.purgeInitContainers(pod, podStatus)
}
} else {
// Step 3: kill any running containers in this pod which are not to keep.
for containerID, containerInfo := range podContainerChanges.ContainersToKill {
klog.V(3).Infof("Killing unwanted container %q(id=%q) for pod %q", containerInfo.name, containerID, format.Pod(pod))
killContainerResult := kubecontainer.NewSyncResult(kubecontainer.KillContainer, containerInfo.name)
result.AddSyncResult(killContainerResult)
if err := m.killContainer(pod, containerID, containerInfo.name, containerInfo.message, nil); err != nil {
killContainerResult.Fail(kubecontainer.ErrKillContainer, err.Error())
klog.Errorf("killContainer %q(id=%q) for pod %q failed: %v", containerInfo.name, containerID, format.Pod(pod), err)
return
}
}
}
// Keep terminated init containers fairly aggressively controlled
// This is an optimization because container removals are typically handled
// by container garbage collector.
m.pruneInitContainersBeforeStart(pod, podStatus)
// We pass the value of the PRIMARY podIP and list of podIPs down to
// generatePodSandboxConfig and generateContainerConfig, which in turn
// passes it to various other functions, in order to facilitate functionality
// that requires this value (hosts file and downward API) and avoid races determining
// the pod IP in cases where a container requires restart but the
// podIP isn't in the status manager yet. The list of podIPs is used to
// generate the hosts file.
//
// We default to the IPs in the passed-in pod status, and overwrite them if the
// sandbox needs to be (re)started.
var podIPs []string
if podStatus != nil {
podIPs = podStatus.IPs
}
// Step 4: Create a sandbox for the pod if necessary.
// 创建使用 pause 镜像创建的 sandbox
podSandboxID := podContainerChanges.SandboxID
if podContainerChanges.CreateSandbox {
var msg string
var err error
klog.V(4).Infof("Creating PodSandbox for pod %q", format.Pod(pod))
createSandboxResult := kubecontainer.NewSyncResult(kubecontainer.CreatePodSandbox, format.Pod(pod))
result.AddSyncResult(createSandboxResult)
podSandboxID, msg, err = m.createPodSandbox(pod, podContainerChanges.Attempt)
if err != nil {
createSandboxResult.Fail(kubecontainer.ErrCreatePodSandbox, msg)
klog.Errorf("createPodSandbox for pod %q failed: %v", format.Pod(pod), err)
ref, referr := ref.GetReference(legacyscheme.Scheme, pod)
if referr != nil {
klog.Errorf("Couldn't make a ref to pod %q: '%v'", format.Pod(pod), referr)
}
m.recorder.Eventf(ref, v1.EventTypeWarning, events.FailedCreatePodSandBox, "Failed to create pod sandbox: %v", err)
return
}
klog.V(4).Infof("Created PodSandbox %q for pod %q", podSandboxID, format.Pod(pod))
podSandboxStatus, err := m.runtimeService.PodSandboxStatus(podSandboxID)
if err != nil {
ref, referr := ref.GetReference(legacyscheme.Scheme, pod)
if referr != nil {
klog.Errorf("Couldn't make a ref to pod %q: '%v'", format.Pod(pod), referr)
}
m.recorder.Eventf(ref, v1.EventTypeWarning, events.FailedStatusPodSandBox, "Unable to get pod sandbox status: %v", err)
klog.Errorf("Failed to get pod sandbox status: %v; Skipping pod %q", err, format.Pod(pod))
result.Fail(err)
return
}
// If we ever allow updating a pod from non-host-network to
// host-network, we may use a stale IP.
if !kubecontainer.IsHostNetworkPod(pod) {
// Overwrite the podIPs passed in the pod status, since we just started the pod sandbox.
podIPs = m.determinePodSandboxIPs(pod.Namespace, pod.Name, podSandboxStatus)
klog.V(4).Infof("Determined the ip %v for pod %q after sandbox changed", podIPs, format.Pod(pod))
}
}
// the start containers routines depend on pod ip(as in primary pod ip)
// instead of trying to figure out if we have 0 < len(podIPs)
// everytime, we short circuit it here
podIP := ""
if len(podIPs) != 0 {
podIP = podIPs[0]
}
// Get podSandboxConfig for containers to start.
configPodSandboxResult := kubecontainer.NewSyncResult(kubecontainer.ConfigPodSandbox, podSandboxID)
result.AddSyncResult(configPodSandboxResult)
podSandboxConfig, err := m.generatePodSandboxConfig(pod, podContainerChanges.Attempt)
if err != nil {
message := fmt.Sprintf("GeneratePodSandboxConfig for pod %q failed: %v", format.Pod(pod), err)
klog.Error(message)
configPodSandboxResult.Fail(kubecontainer.ErrConfigPodSandbox, message)
return
}
// Helper containing boilerplate common to starting all types of containers.
// typeName is a label used to describe this type of container in log messages,
// currently: "container", "init container" or "ephemeral container"
start := func(typeName string, spec *startSpec) error {
startContainerResult := kubecontainer.NewSyncResult(kubecontainer.StartContainer, spec.container.Name)
result.AddSyncResult(startContainerResult)
isInBackOff, msg, err := m.doBackOff(pod, spec.container, podStatus, backOff)
if isInBackOff {
startContainerResult.Fail(err, msg)
klog.V(4).Infof("Backing Off restarting %v %+v in pod %v", typeName, spec.container, format.Pod(pod))
return err
}
klog.V(4).Infof("Creating %v %+v in pod %v", typeName, spec.container, format.Pod(pod))
// NOTE (aramase) podIPs are populated for single stack and dual stack clusters. Send only podIPs.
if msg, err := m.startContainer(podSandboxID, podSandboxConfig, spec, pod, podStatus, pullSecrets, podIP, podIPs); err != nil {
startContainerResult.Fail(err, msg)
// known errors that are logged in other places are logged at higher levels here to avoid
// repetitive log spam
switch {
case err == images.ErrImagePullBackOff:
klog.V(3).Infof("%v %+v start failed in pod %v: %v: %s", typeName, spec.container, format.Pod(pod), err, msg)
default:
utilruntime.HandleError(fmt.Errorf("%v %+v start failed in pod %v: %v: %s", typeName, spec.container, format.Pod(pod), err, msg))
}
return err
}
return nil
}
// Step 5: start ephemeral containers
// These are started "prior" to init containers to allow running ephemeral containers even when there
// are errors starting an init container. In practice init containers will start first since ephemeral
// containers cannot be specified on pod creation.
if utilfeature.DefaultFeatureGate.Enabled(features.EphemeralContainers) {
for _, idx := range podContainerChanges.EphemeralContainersToStart {
start("ephemeral container", ephemeralContainerStartSpec(&pod.Spec.EphemeralContainers[idx]))
}
}
// Step 6: start the init container.
if container := podContainerChanges.NextInitContainerToStart; container != nil {
// Start the next init container.
if err := start("init container", containerStartSpec(container)); err != nil {
return
}
// Successfully started the container; clear the entry in the failure
klog.V(4).Infof("Completed init container %q for pod %q", container.Name, format.Pod(pod))
}
// Step 7: start containers in podContainerChanges.ContainersToStart.
for _, idx := range podContainerChanges.ContainersToStart {
start("container", containerStartSpec(&pod.Spec.Containers[idx]))
}
return
}
主要做了以下的事情
- Compute sandbox and container changes.
- Kill pod sandbox if necessary.
- Kill any containers that should not be running.
- Create sandbox if necessary.
- Create ephemeral containers.
- Create init containers.
- Create normal containers.
至此,Pod的启动到创建过程完成。
pod创建中的CNI网络插件
在上面的Create sandbox调用createPodSandbox来创建 pause 镜像创建的 sandbox过程中会调用CRI相关接口来实现容器的运行,其中就包括了网络的设置。
// createPodSandbox creates a pod sandbox and returns (podSandBoxID, message, error).
func (m *kubeGenericRuntimeManager) createPodSandbox(pod *v1.Pod, attempt uint32) (string, string, error) {
podSandboxConfig, err := m.generatePodSandboxConfig(pod, attempt)
if err != nil {
message := fmt.Sprintf("GeneratePodSandboxConfig for pod %q failed: %v", format.Pod(pod), err)
klog.Error(message)
return "", message, err
}
// Create pod logs directory
err = m.osInterface.MkdirAll(podSandboxConfig.LogDirectory, 0755)
if err != nil {
message := fmt.Sprintf("Create pod log directory for pod %q failed: %v", format.Pod(pod), err)
klog.Errorf(message)
return "", message, err
}
runtimeHandler := ""
if m.runtimeClassManager != nil {
runtimeHandler, err = m.runtimeClassManager.LookupRuntimeHandler(pod.Spec.RuntimeClassName)
if err != nil {
message := fmt.Sprintf("CreatePodSandbox for pod %q failed: %v", format.Pod(pod), err)
return "", message, err
}
if runtimeHandler != "" {
klog.V(2).Infof("Running pod %s with RuntimeHandler %q", format.Pod(pod), runtimeHandler)
}
}
podSandBoxID, err := m.runtimeService.RunPodSandbox(podSandboxConfig, runtimeHandler)
if err != nil {
message := fmt.Sprintf("CreatePodSandbox for pod %q failed: %v", format.Pod(pod), err)
klog.Error(message)
return "", message, err
}
return podSandBoxID, "", nil
}
可见调用来m.runtimeService.RunPodSandbox来创建容器,PodSandboxManager就是基本容器的操作
type PodSandboxManager interface {
// RunPodSandbox creates and starts a pod-level sandbox. Runtimes should ensure
// the sandbox is in ready state.
RunPodSandbox(config *runtimeapi.PodSandboxConfig, runtimeHandler string) (string, error)
// StopPodSandbox stops the sandbox. If there are any running containers in the
// sandbox, they should be force terminated.
StopPodSandbox(podSandboxID string) error
// RemovePodSandbox removes the sandbox. If there are running containers in the
// sandbox, they should be forcibly removed.
RemovePodSandbox(podSandboxID string) error
// PodSandboxStatus returns the Status of the PodSandbox.
PodSandboxStatus(podSandboxID string) (*runtimeapi.PodSandboxStatus, error)
// ListPodSandbox returns a list of Sandbox.
ListPodSandbox(filter *runtimeapi.PodSandboxFilter) ([]*runtimeapi.PodSandbox, error)
// PortForward prepares a streaming endpoint to forward ports from a PodSandbox, and returns the address.
PortForward(*runtimeapi.PortForwardRequest) (*runtimeapi.PortForwardResponse, error)
}
type RuntimeService interface {
RuntimeVersioner
ContainerManager
PodSandboxManager
ContainerStatsManager
// UpdateRuntimeConfig updates runtime configuration if specified
UpdateRuntimeConfig(runtimeConfig *runtimeapi.RuntimeConfig) error
// Status returns the status of the runtime.
Status() (*runtimeapi.RuntimeStatus, error)
}
dockerService 类实现了上面 CRI 接口,dockerService创建的时候传入的 cni 配置目录和bin目录,初始化插件,并供后续选择,所以我们直接看dockerService的RunPodSandbox函数
func (ds *dockerService) RunPodSandbox(ctx context.Context, r *runtimeapi.RunPodSandboxRequest) (*runtimeapi.RunPodSandboxResponse, error) {
config := r.GetConfig()
// Step 1: Pull the image for the sandbox.
image := defaultSandboxImage
podSandboxImage := ds.podSandboxImage
if len(podSandboxImage) != 0 {
image = podSandboxImage
}
// NOTE: To use a custom sandbox image in a private repository, users need to configure the nodes with credentials properly.
// see: http://kubernetes.io/docs/user-guide/images/#configuring-nodes-to-authenticate-to-a-private-repository
// Only pull sandbox image when it's not present - v1.PullIfNotPresent.
if err := ensureSandboxImageExists(ds.client, image); err != nil {
return nil, err
}
// Step 2: Create the sandbox container.
if r.GetRuntimeHandler() != "" && r.GetRuntimeHandler() != runtimeName {
return nil, fmt.Errorf("RuntimeHandler %q not supported", r.GetRuntimeHandler())
}
createConfig, err := ds.makeSandboxDockerConfig(config, image)
if err != nil {
return nil, fmt.Errorf("failed to make sandbox docker config for pod %q: %v", config.Metadata.Name, err)
}
createResp, err := ds.client.CreateContainer(*createConfig)
if err != nil {
createResp, err = recoverFromCreationConflictIfNeeded(ds.client, *createConfig, err)
}
if err != nil || createResp == nil {
return nil, fmt.Errorf("failed to create a sandbox for pod %q: %v", config.Metadata.Name, err)
}
resp := &runtimeapi.RunPodSandboxResponse{PodSandboxId: createResp.ID}
ds.setNetworkReady(createResp.ID, false)
defer func(e *error) {
// Set networking ready depending on the error return of
// the parent function
if *e == nil {
ds.setNetworkReady(createResp.ID, true)
}
}(&err)
// Step 3: Create Sandbox Checkpoint.
if err = ds.checkpointManager.CreateCheckpoint(createResp.ID, constructPodSandboxCheckpoint(config)); err != nil {
return nil, err
}
// Step 4: Start the sandbox container.
// Assume kubelet's garbage collector would remove the sandbox later, if
// startContainer failed.
err = ds.client.StartContainer(createResp.ID)
if err != nil {
return nil, fmt.Errorf("failed to start sandbox container for pod %q: %v", config.Metadata.Name, err)
}
// Rewrite resolv.conf file generated by docker.
// NOTE: cluster dns settings aren't passed anymore to docker api in all cases,
// not only for pods with host network: the resolver conf will be overwritten
// after sandbox creation to override docker's behaviour. This resolv.conf
// file is shared by all containers of the same pod, and needs to be modified
// only once per pod.
if dnsConfig := config.GetDnsConfig(); dnsConfig != nil {
containerInfo, err := ds.client.InspectContainer(createResp.ID)
if err != nil {
return nil, fmt.Errorf("failed to inspect sandbox container for pod %q: %v", config.Metadata.Name, err)
}
if err := rewriteResolvFile(containerInfo.ResolvConfPath, dnsConfig.Servers, dnsConfig.Searches, dnsConfig.Options); err != nil {
return nil, fmt.Errorf("rewrite resolv.conf failed for pod %q: %v", config.Metadata.Name, err)
}
}
// Do not invoke network plugins if in hostNetwork mode.
if config.GetLinux().GetSecurityContext().GetNamespaceOptions().GetNetwork() == runtimeapi.NamespaceMode_NODE {
return resp, nil
}
// Step 5: Setup networking for the sandbox.
// All pod networking is setup by a CNI plugin discovered at startup time.
// This plugin assigns the pod ip, sets up routes inside the sandbox,
// creates interfaces etc. In theory, its jurisdiction ends with pod
// sandbox networking, but it might insert iptables rules or open ports
// on the host as well, to satisfy parts of the pod spec that aren't
// recognized by the CNI standard yet.
cID := kubecontainer.BuildContainerID(runtimeName, createResp.ID)
networkOptions := make(map[string]string)
if dnsConfig := config.GetDnsConfig(); dnsConfig != nil {
// Build DNS options.
dnsOption, err := json.Marshal(dnsConfig)
if err != nil {
return nil, fmt.Errorf("failed to marshal dns config for pod %q: %v", config.Metadata.Name, err)
}
networkOptions["dns"] = string(dnsOption)
}
err = ds.network.SetUpPod(config.GetMetadata().Namespace, config.GetMetadata().Name, cID, config.Annotations, networkOptions)
if err != nil {
errList := []error{fmt.Errorf("failed to set up sandbox container %q network for pod %q: %v", createResp.ID, config.Metadata.Name, err)}
// Ensure network resources are cleaned up even if the plugin
// succeeded but an error happened between that success and here.
err = ds.network.TearDownPod(config.GetMetadata().Namespace, config.GetMetadata().Name, cID)
if err != nil {
errList = append(errList, fmt.Errorf("failed to clean up sandbox container %q network for pod %q: %v", createResp.ID, config.Metadata.Name, err))
}
err = ds.client.StopContainer(createResp.ID, defaultSandboxGracePeriod)
if err != nil {
errList = append(errList, fmt.Errorf("failed to stop sandbox container %q for pod %q: %v", createResp.ID, config.Metadata.Name, err))
}
return resp, utilerrors.NewAggregate(errList)
}
return resp, nil
}
调用ds.network.SetUpPod来对容器的网络进行设置
func (pm *PluginManager) SetUpPod(podNamespace, podName string, id kubecontainer.ContainerID, annotations, options map[string]string) error {
const operation = "set_up_pod"
defer recordOperation(operation, time.Now())
fullPodName := kubecontainer.BuildPodFullName(podName, podNamespace)
pm.podLock(fullPodName).Lock()
defer pm.podUnlock(fullPodName)
klog.V(3).Infof("Calling network plugin %s to set up pod %q", pm.plugin.Name(), fullPodName)
if err := pm.plugin.SetUpPod(podNamespace, podName, id, annotations, options); err != nil {
recordError(operation)
return fmt.Errorf("networkPlugin %s failed to set up pod %q network: %v", pm.plugin.Name(), fullPodName, err)
}
return nil
}
这边就调用的插件管理模式的SetUpPod函数。我们配置的时候是cni模式,是有这边就是调用cniNetworkPlugin的SetUpPod函数
func (plugin *cniNetworkPlugin) SetUpPod(namespace string, name string, id kubecontainer.ContainerID, annotations, options map[string]string) error {
if err := plugin.checkInitialized(); err != nil {
return err
}
netnsPath, err := plugin.host.GetNetNS(id.ID)
if err != nil {
return fmt.Errorf("CNI failed to retrieve network namespace path: %v", err)
}
// Todo get the timeout from parent ctx
cniTimeoutCtx, cancelFunc := context.WithTimeout(context.Background(), network.CNITimeoutSec*time.Second)
defer cancelFunc()
// Windows doesn't have loNetwork. It comes only with Linux
if plugin.loNetwork != nil {
if _, err = plugin.addToNetwork(cniTimeoutCtx, plugin.loNetwork, name, namespace, id, netnsPath, annotations, options); err != nil {
return err
}
}
_, err = plugin.addToNetwork(cniTimeoutCtx, plugin.getDefaultNetwork(), name, namespace, id, netnsPath, annotations, options)
return err
}
然后就调用插件实现的接口来实现网络。pod创建的时候就是调用的AddNetworkList接口,也就是CNI包中的CNIConfig实现的AddNetworkList接口
func (plugin *cniNetworkPlugin) addToNetwork(ctx context.Context, network *cniNetwork, podName string, podNamespace string, podSandboxID kubecontainer.ContainerID, podNetnsPath string, annotations, options map[string]string) (cnitypes.Result, error) {
rt, err := plugin.buildCNIRuntimeConf(podName, podNamespace, podSandboxID, podNetnsPath, annotations, options)
if err != nil {
klog.Errorf("Error adding network when building cni runtime conf: %v", err)
return nil, err
}
pdesc := podDesc(podNamespace, podName, podSandboxID)
netConf, cniNet := network.NetworkConfig, network.CNIConfig
klog.V(4).Infof("Adding %s to network %s/%s netns %q", pdesc, netConf.Plugins[0].Network.Type, netConf.Name, podNetnsPath)
res, err := cniNet.AddNetworkList(ctx, netConf, rt)
if err != nil {
klog.Errorf("Error adding %s to network %s/%s: %v", pdesc, netConf.Plugins[0].Network.Type, netConf.Name, err)
return nil, err
}
klog.V(4).Infof("Added %s to network %s: %v", pdesc, netConf.Name, res)
return res, nil
}
CNIConfig实现的AddNetworkList接口会将对应的配置和参数,转化为环境变量执行CNI插件的二进制文件,完成对容器的网络配置,下面的步骤也就是CNI的实现。