Kubernetes 和 Docker 类似,也是通过 Volume 的方式提供对存储的支持。但是Kubernetes对容器存储做了一层自己的抽象,相比docker的存储来讲,K8S的存储抽象更全面,更面向应用,体现在如下几个方面:
- 提供卷生命周期管理
- 提供“声明”式定义,将使用者和提供者分离
- 提供存储类型定义
存储系统架构
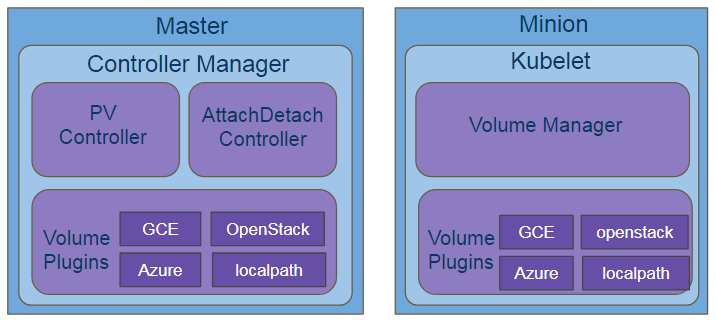
K8S里存储相关的组件,从顶层来讲,主要包含4大组件:
- Volume Plugins — 存储提供的扩展接口, 包含了各类存储提供者的plugin实现。
- Volume Manager — 运行在kubelet 里让存储Ready的部件,负责管理数据卷的 Mount/Umount 操作(也负责数据卷的 Attach/Detach 操作,需配置 kubelet 相关参数开启该特性)、卷设备的格式化等等。
- PV/PVC Controller — 运行在Master上的部件,主要提供卷生命周期管理,负责 PV/PVC 绑定及周期管理,根据需求进行数据卷的 Provision/Delete 操作;所谓将一个 PV 与 PVC 进行“绑定”,其实就是将这个 PV 对象的名字,填在了 PVC 对象的 spec.volumeName 字段上。
- Attach/Detach — 运行在Master上,负责数据卷的 Attach/Detach 操作,将设备挂接到目标节点。
其中Volume Plugins是一个基础部件,后三个是逻辑部件,依赖于Volume Plugins。
上诉其实就是K8S内部的基本逻辑架构,扩展出去再加上外部与这些部件有交互关系的部件(调用者和实现者)和内部可靠性保证的部件,就可以得出K8S的存储的架构全景。
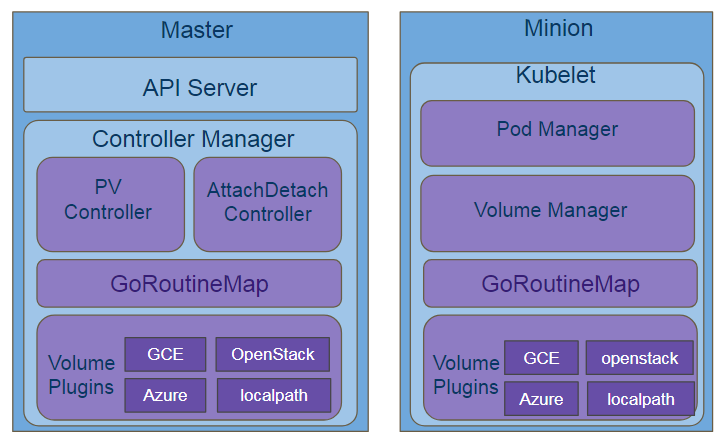
对于调用者,在master上主要是通过监听API Server来获取资源变化,从而触发卷的增删改查,在minion上,因为只有pod调度到这个node上才会有卷的相应操作,所以它的触发端是kubelet(严格讲是kubelet里的pod manager),根据Pod Manager里pod spec里申明的存储来触发卷的挂载操作。
Volume
在上面的架构中,我们可以看出volume是最基础的,先看一下Kubernetes 中 Volume 的 概念与Docker 中的 Volume 类似,但不完全相同。具体区别如下:
- Kubernetes 中的 Volume 与 Pod 的生命周期相同,但与容器的生命周期不相关。当容器终止或重启时,Volume 中的数据也不会丢失。
- 当 Pod 被删除时,Volume 才会被清理。并且数据是否丢失取决于 Volume 的具体类型,比如:emptyDir 类型的 Volume 数据会丢失,而 PV 类型的数据则不会丢失。
Kubernetes 内置的 20 种持久化数据卷实现,基于这些可以实现大部分的存储设置,核心是存储,也有通过volume的特性来进行配置的功能等特性,下面我看看一些常用的原生内置volume的使用。
emptyDir
emptryDir,顾名思义是一个空目录,一个emptyDir 第一次创建是在一个pod被指定到具体node的时候,并且会一直存在在pod的生命周期当中,正如它的名字一样,它初始化是一个空的目录,pod中的容器都可以读写这个目录,这个目录可以被挂在到各个容器相同或者不相同的的路径下。当一个pod因为任何原因被移除的时候,这些数据会被永久删除。
主要用途:
- 临时空间,例如用于某些应用程序运行时所需的临时目录,且无需永久保留
- 长时间任务的中间过程checkpoint的临时保存目录
- 一个容器需要从另一个容器中获取数据库的目录(多容器共享目录)
注意:容器的crashing事件也就是容器崩溃了并不会导致emptyDir中的数据被删除,因为容器的崩溃并不移除pod。
结构
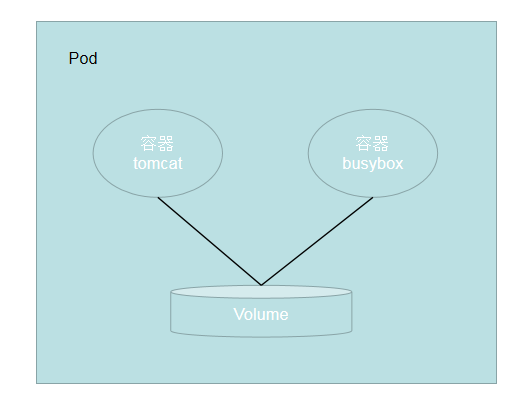
实例
[root@master ~]# cat test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy
spec:
replicas: 1
selector:
matchLabels:
app: mynginx
template:
metadata:
labels:
app: mynginx
spec:
containers:
- name: mynginx
image: nginx:1.15.1
volumeMounts:
- mountPath: /usr/share/nginx/html/
name: share
ports:
- name: nginx
containerPort: 80
- name: busybox
image: busybox
command:
- "/bin/sh"
- "-c"
- "sleep 4444"
volumeMounts:
- mountPath: /data/
name: share
volumes:
- name: share
emptyDir: {}
创建Pod
[root@master ~]# kubectl create -f test.yaml
查看Pod
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
deploy-5cd657dd46-sx287 2/2 Running 0 2m1s
我们进入到busybox容器当中创建一个index.html
[root@master ~]# kubectl exec -it deploy-5cd657dd46-sx287 -c busybox -- /bin/sh
容器内部:
/data # cd /data
/data # echo "fengzi" > index.html
可以到tomcat容器中验证一下共享这个文件。
hostPath
hostPath为在Pod上挂载宿主机上的文件或目录,它通常可以用于以下几方面:
- 容器应用程序生成的日志文件需要永久保存时,可以使用宿主机的告诉文件系统进行存储
- 需要访问宿主机上Docker引擎内部数据结构的容器应用时,可以通过定义hostPath为宿主机/var/lib/docker目录,使容器内部应用可以直接访问Docker的文件系统
在使用这种类型的volume时,需要注意以下几点:
- 在不同的node上具有相同配置的Pod时,可能会因为宿主机上的目录和文件不同而导致对volume上的目录和文件访问结果不一致
- 如果使用了资源配置,则kubernetes无法将hostPath在宿主机上使用的资源纳入管理
结构
实例
[root@master ~]# cat test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mydeploy
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: mynginx
template:
metadata:
name: web
labels:
app: mynginx
spec:
containers:
- name: mycontainer
image: lizhaoqwe/nginx:v1
volumeMounts:
- mountPath: /usr/share/nginx/html
name: persistent-storage
ports:
- containerPort: 80
volumes:
- name: persistent-storage
hostPath:
type: DirectoryOrCreate
path: /mydata
可以看见hostpath有一个type类型字段,它有很多取值有着不同的意义
| 取值 | 行为 |
|---|---|
| 空字符串(默认)用于向后兼容,这意味着在安装 hostPath 卷之前不会执行任何检查。 | |
DirectoryOrCreate |
如果在给定路径上什么都不存在,那么将根据需要创建空目录,权限设置为 0755,具有与 kubelet 相同的组和属主信息。 |
Directory |
在给定路径上必须存在的目录。 |
FileOrCreate |
如果在给定路径上什么都不存在,那么将在那里根据需要创建空文件,权限设置为 0644,具有与 kubelet 相同的组和所有权。 |
File |
在给定路径上必须存在的文件。 |
Socket |
在给定路径上必须存在的 UNIX 套接字。 |
CharDevice |
在给定路径上必须存在的字符设备。 |
BlockDevice |
在给定路径上必须存在的块设备。 |
执行yaml文件
[root@master ~]# kubectl create -f test.yaml
deployment.apps/mydeploy created
在容器和对应的宿主机目录里面的内容是共享的。
projectd
projected 卷类型能将若干现有的卷来源映射到同一目录上,这一类存储的类型的功能和上面说的就不太一样了,其实他的目的不是为了存储数据,而是为了获取数据使用,不太属于存储的范畴,只是借用了存储的功能,这边就简单说一下,这些类型即使不使用projectd也可以通过volume挂载到对应的pod中,可以查看k8s基本原理中对应的基本概念,到目前为止,Kubernetes 支持的 Projected Volume 一共有四种:
- Secret;
- ConfigMap;
- Downward API;
- ServiceAccountToken。
比如,我们下面这个实例就是将 Secret、downwardAPI 和 configMap 的配置通过一个volume映射到一个path上
apiVersion: v1
kind: Pod
metadata:
name: volume-test
spec:
containers:
- name: container-test
image: busybox
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: mysecret
items:
- key: username
path: my-group/my-username
- downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "cpu_limit"
resourceFieldRef:
containerName: container-test
resource: limits.cpu
- configMap:
name: myconfigmap
items:
- key: config
path: my-group/my-config
每个被投射的卷来源都在规约中的 sources 内列出,这里的Secret和ConfigMap我们在基本概念里已经讲的很清楚,我们下面单独讲一下Downward API和ServiceAccountToken。
Downward API
Downward API作用是:让 Pod 里的容器能够直接获取到这个 Pod API 对象本身的信息。
apiVersion: v1
kind: Pod
metadata:
name: test-downwardapi-volume
labels:
zone: us-est-coast
cluster: test-cluster1
rack: rack-22
spec:
containers:
- name: client-container
image: k8s.gcr.io/busybox
command: ["sh", "-c"]
args:
- while true; do
if [[ -e /etc/podinfo/labels ]]; then
echo -en '\n\n'; cat /etc/podinfo/labels; fi;
sleep 5;
done;
volumeMounts:
- name: podinfo
mountPath: /etc/podinfo
readOnly: false
volumes:
- name: podinfo
projected:
sources:
- downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
在这个 Pod 的 YAML 文件中,我定义了一个简单的容器,而这个 Downward API Volume,则声明了要暴露 Pod 的 metadata.labels 信息给容器。通过这样的声明方式,当前 Pod 的 Labels 字段的值,就会被 Kubernetes 自动挂载成为容器里的 /etc/podinfo/labels 文件。而这个容器的启动命令,则是不断打印出 /etc/podinfo/labels 里的内容。所以,当我创建了这个 Pod 之后,就可以通过 kubectl logs 指令,查看到这些 Labels 字段被打印出来,如下所示:
$ kubectl create -f dapi-volume.yaml
$ kubectl logs test-downwardapi-volume
cluster="test-cluster1"
rack="rack-22"
zone="us-est-coast"
目前,Downward API 支持的字段已经非常丰富了,比如:
1. 使用fieldRef可以声明使用:
spec.nodeName - 宿主机名字
status.hostIP - 宿主机IP
metadata.name - Pod的名字
metadata.namespace - Pod的Namespace
status.podIP - Pod的IP
spec.serviceAccountName - Pod的Service Account的名字
metadata.uid - Pod的UID
metadata.labels['<KEY>'] - 指定<KEY>的Label值
metadata.annotations['<KEY>'] - 指定<KEY>的Annotation值
metadata.labels - Pod的所有Label
metadata.annotations - Pod的所有Annotation
2. 使用resourceFieldRef可以声明使用:
容器的CPU limit
容器的CPU request
容器的memory limit
容器的memory request
上面这个列表的内容,随着 Kubernetes 项目的发展肯定还会不断增加。所以这里列出来的信息仅供参考,在使用 Downward API 时,还是要去查阅一下官方文档。
注意:Downward API 能够获取到的信息,一定是 Pod 里的容器进程启动之前就能够确定下来的信息。而如果你想要获取 Pod 容器运行后才会出现的信息,比如,容器进程的 PID,那就肯定不能使用 Downward API 了,而应该考虑在 Pod 里定义一个 sidecar 容器。
ServiceAccountToken
Kubernetes 项目的 Projected Volume 其实只有三种,因为第四种 ServiceAccountToken,只是一种特殊的 Secret 而已。
Service Account 的授权信息和文件,实际上保存在它所绑定的一个特殊的 Secret 对象里的。这个特殊的 Secret 对象,就叫作 ServiceAccountToken。
persistentVolumeClaim
pvc可以说是我们最常用的存储方式,说到pvc,不得不说说 PersistentVolume、PersistentVolumeClaim、StorageClass 三种 API 资源。我们来看一下这几个之间的关系。
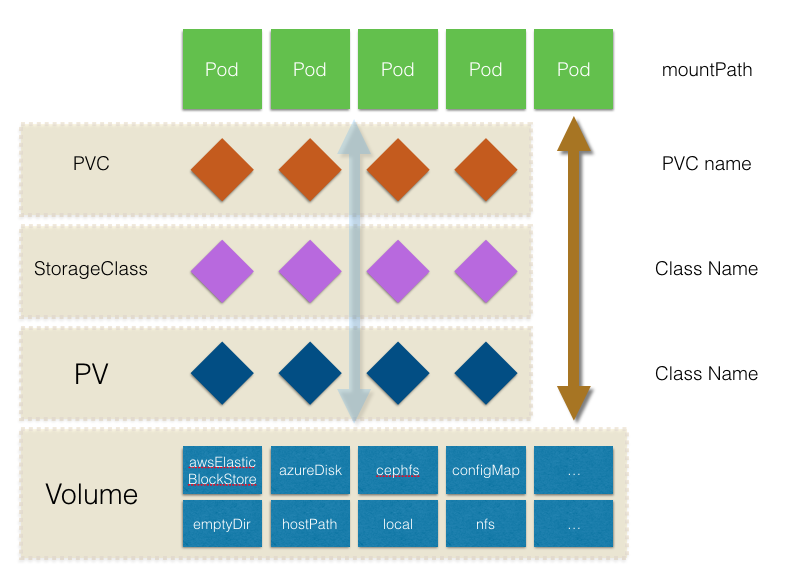
其实PersistentVolume、StorageClass都是pv的抽象,基于vloume基础之上的,只不过是静态和动态的区别,PersistentVolumeClaim是连接前面两个和k8s的桥梁,使得存储和k8s分离,那么为什么还需要pv,我们在之前的基本概念中已经说过,我们详细的看看这三个资源。
pv
PersistentVolume(持久化卷)可以理解成为kubernetes集群中的某个网络存储对应的一块存储,它与Volume类似,定义出来给pvc进行挂载的,只不过非持久化存储的都是不需要资源声明的,pv需要声明来才能被pvc挂载。
pv和正常的挂载有以下区别:
- pv只能是网络存储,不属于任何Node,但可以在每个Node上访问。
- pv并不是被定义在Pod上的,而是独立于Pod之外定义的,也是集群资源的一种。
实例
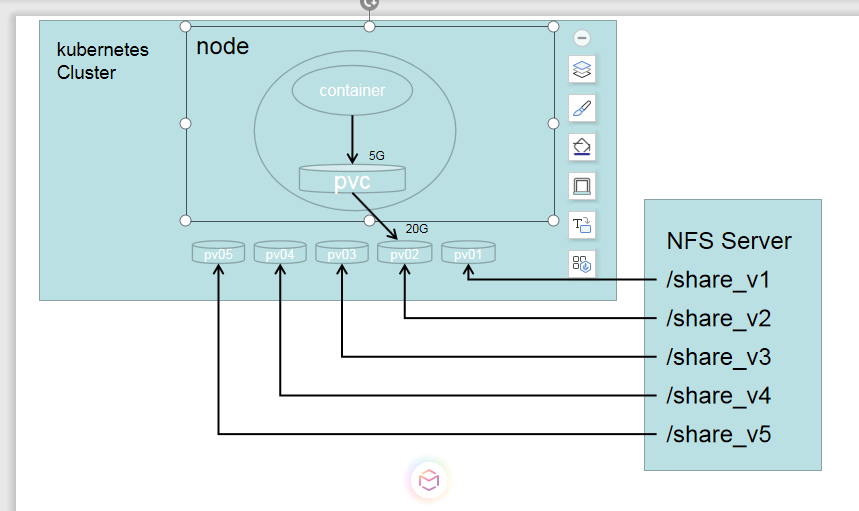
在nfs server服务器上创建nfs卷的映射并重启
[root@localhost ~]# cat /etc/exports
/share_v1 192.168.254.0/24(insecure,rw,no_root_squash)
/share_v2 192.168.254.0/24(insecure,rw,no_root_squash)
[root@localhost ~]# service nfs restart
在nfs server服务器上创建响应目录
[root@localhost /]# mkdir /share_v{1,2}
在kubernetes集群中的master节点上创建pv,我这里创建了5个pv对应nfs server当中映射出来的5个目录
[root@master ~]# cat createpv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv01
spec:
nfs: #存储类型
path: /share_v1 #要挂在的nfs服务器的目录位置
server: 192.168.254.11 #nfs server地址,也可以是域名,前提是能被解析
accessModes: #访问模式:
- ReadWriteMany ReadWriteMany:读写权限,允许多个Node挂载 | ReadWriteOnce:读写权限,只能被单个Node挂在 | ReadOnlyMany:只读权限,允许被多个Node挂载
- ReadWriteOnce
capacity: #存储容量
storage: 10Gi #pv存储卷为10G
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv02
spec:
nfs:
path: /share_v2
server: 192.168.254.11
accessModes:
- ReadWriteMany
capacity:
storage: 20Gi
执行yaml文件
[root@master ~]# kubectl create -f createpv.yaml
persistentvolume/pv01 created
persistentvolume/pv02 created
查看pv
[root@master ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01 10Gi RWO,RWX Retain Available 5m10s
pv02 20Gi RWX Retain Available 5m10s
解析
ACCESS MODES(pv访问模式,其实就是读写权限):
RWO:ReadWriteOnly:是最基本的方式,可读可写,但只支持被单个Pod挂载。
RWX:ReadWriteMany:这种存储可以以读写的方式被多个Pod共享。
ROX:ReadOnlyMany:可以以只读的方式被多个Pod挂载。
| 卷插件 | ReadWriteOnce | ReadOnlyMany | ReadWriteMany |
|---|---|---|---|
| AWSElasticBlockStore | ✓ | - | - |
| AzureFile | ✓ | ✓ | ✓ |
| AzureDisk | ✓ | - | - |
| CephFS | ✓ | ✓ | ✓ |
| Cinder | ✓ | - | - |
| CSI | 取决于驱动 | 取决于驱动 | 取决于驱动 |
| FC | ✓ | ✓ | - |
| FlexVolume | ✓ | ✓ | 取决于驱动 |
| Flocker | ✓ | - | - |
| GCEPersistentDisk | ✓ | ✓ | - |
| Glusterfs | ✓ | ✓ | ✓ |
| HostPath | ✓ | - | - |
| iSCSI | ✓ | ✓ | - |
| Quobyte | ✓ | ✓ | ✓ |
| NFS | ✓ | ✓ | ✓ |
| RBD | ✓ | ✓ | - |
| VsphereVolume | ✓ | - | - (Pod 运行于同一节点上时可行) |
| PortworxVolume | ✓ | - | ✓ |
| ScaleIO | ✓ | ✓ | - |
| StorageOS | ✓ | - | - |
RECLAIM POLICY(重声明策略,其实就是pv使用的策略):
Retain(保留):保护pvc释放的pv及其上的数据,将不会被其他pvc绑定
recycle(回收):保留pv但清空数据
delete(删除):删除pvc释放的pv及后端存储volume
STATUS(阶段状态):
Available:空闲状态
Bound:已经绑定到某个pvc上
Released:对应的pvc已经被删除,但是资源没有被集群回收
Failed:pv自动回收失败
CLAIM:
被绑定到了那个pvc上面格式为:NAMESPACE/PVC_NAME
CAPACITY 存储容量
四个PV选择器
在PVC中绑定一个PV,可以根据下面几种条件组合选择
Access Modes, 按照访问模式选择pv
Resources, 按照资源属性选择, 比如说请求存储大小为8个G的pv
Selector, 按照pv的label选择
Class, 根据StorageClass的class名称选择, 通过annotation指定了Storage Class的名字, 来绑定特定类型的后端存储
目前pv支持的插件类型
awsElasticBlockStore- AWS 弹性块存储(EBS)azureDisk- Azure DiskazureFile- Azure Filecephfs- CephFS volumecinder- Cinder (OpenStack 块存储) (弃用)csi- 容器存储接口 (CSI)fc- Fibre Channel (FC) 存储flexVolume- FlexVolumeflocker- Flocker 存储gcePersistentDisk- GCE 持久化盘glusterfs- Glusterfs 卷hostPath- HostPath 卷 (仅供单节点测试使用;不适用于多节点集群; 请尝试使用local卷作为替代)iscsi- iSCSI (SCSI over IP) 存储local- 节点上挂载的本地存储设备nfs- 网络文件系统 (NFS) 存储photonPersistentDisk- Photon 控制器持久化盘。 (这个卷类型已经因对应的云提供商被移除而被弃用)。portworxVolume- Portworx 卷quobyte- Quobyte 卷rbd- Rados 块设备 (RBD) 卷scaleIO- ScaleIO 卷 (弃用)storageos- StorageOS 卷vsphereVolume- vSphere VMDK 卷
其中最常用的有NFS,ceph rbd,cephFS,hostpath,csi等。后面我们会简单看看这些存储制作pv的使用说明,先看一下常见的pv创建方式。
pv创建方式
我们先了解一下创建 PV 的两种方式
- 一种是集群管理员通过手动方式静态创建应用所需要的 PV,内置的原生的方式。
- 另一种是用户手动创建 PVC 并由 Provisioner 组件动态创建对应的 PV。
静态创建存储卷
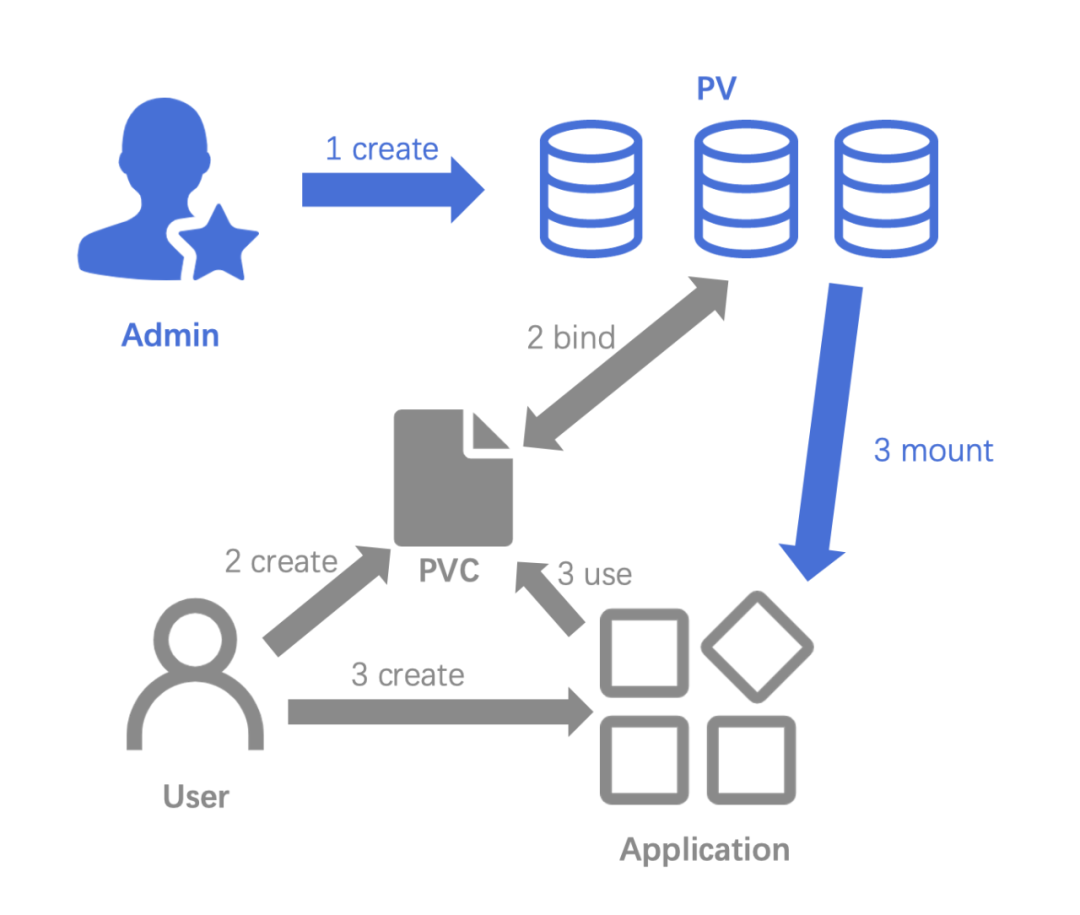
- 集群管理员创建 NFS PV,NFS 属于 K8s 原生支持的 in-tree 存储类型。
- 用户创建 PVC,通过 kubectl get pv 命令可看到 PV 和 PVC 自动绑定
- 用户创建应用,并使用第二步创建的 PVC。
就完成了静态创建存储卷并且使用,也就是我们最初使用的方式。
动态创建存储卷
动态创建存储卷相比静态创建存储卷,少了集群管理员的干预,动态创建存储卷,要求集群中部署有 provisioner 以及对应的 storageclass。
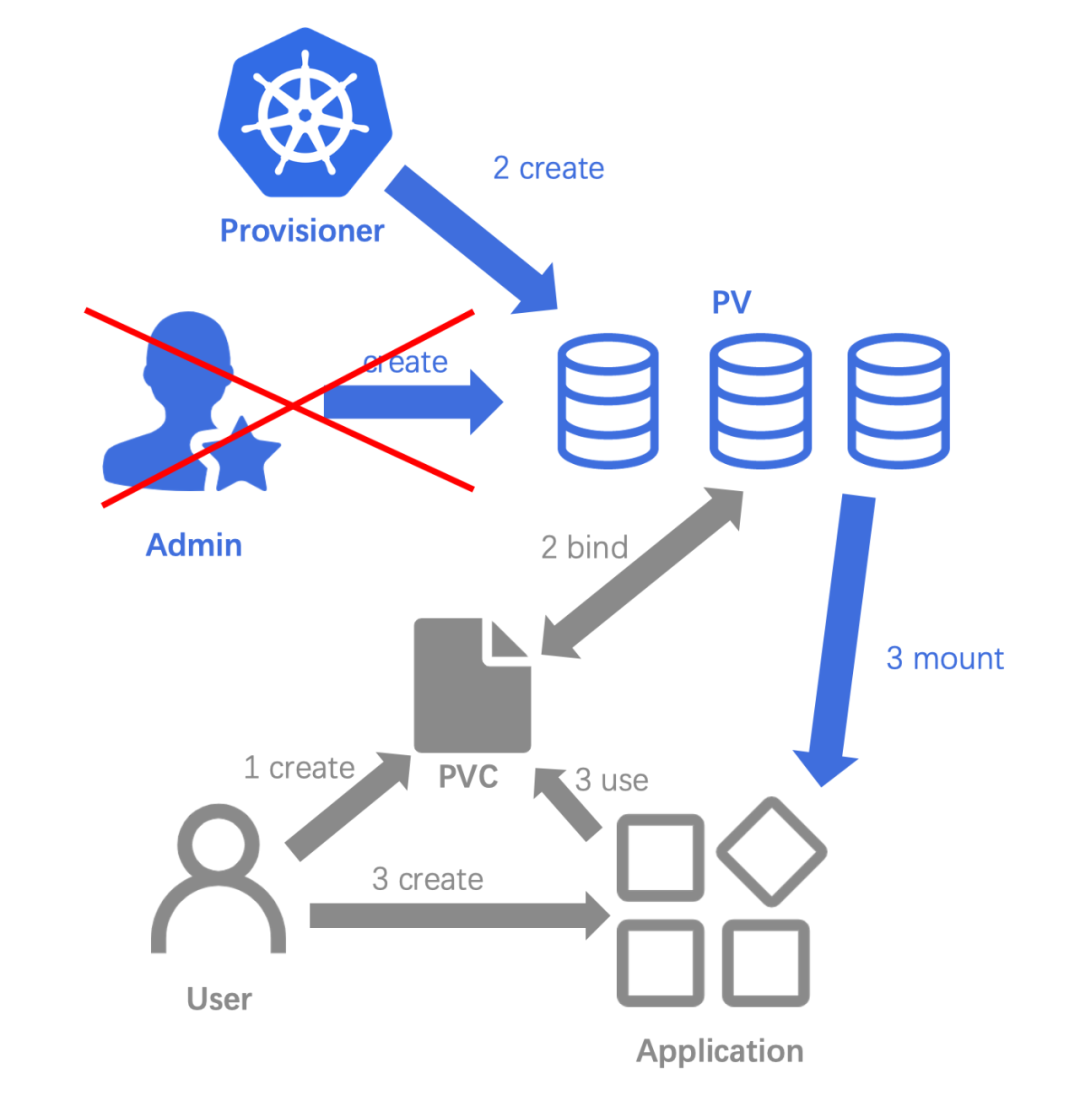
- 集群管理员只需要保证环境中有相关的 storageclass 即可
- 用户创建 PVC,此处 PVC 的 storageClassName 指定为上面的 storageclass 名称,集群中的 provisioner 会动态创建相应 PV。
- 用户创建应用,并使用第二步创建的 PVC,同静态创建存储卷的第三步。
NFS
NFS是Network File System的缩写,就是网络文件系统,这里不详细解说了,可以重这里了解,我们可以通过下图看出使用方式。
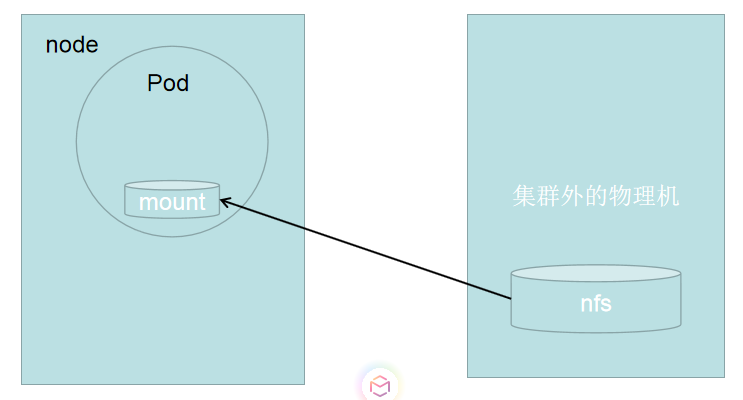
pv我们在上面的实例中已经创建,我们只有创建pvc,然后挂载在pod中就行。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
resources:
requests:
storage: 10Gi
挂载pvc
apiVersion: v1
kind: deployment
metadata:
name: nfs-server
spec:
replicas: 1
selector:
role: nfs-server
template:
metadata:
labels:
role: nfs-server
spec:
containers:
- name: nfs-server
image: k8s.gcr.io/volume-nfs:0.8
ports:
- name: nfs
containerPort: 2049
- name: mountd
containerPort: 20048
- name: rpcbind
containerPort: 111
securityContext:
privileged: true
volumeMounts:
- mountPath: /exports
name: mypvc
volumes:
- name: mypvc
persistentVolumeClaim:
claimName: nfs
glusterfs
GlusterFS (Gluster File System) 是一个开源的分布式文件系统,是 Scale-Out 存储解决方案 Gluster 的核心,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。详细了解可以到这里。
GlusterFS中的volume的模式有很多中,包括以下几种:
1、分布卷(默认模式):即DHT, 也叫 分布卷: 将文件以hash算法随机分布到 一台服务器节点中存储。
2、复制模式:即AFR, 创建volume 时带 replica x 数量: 将文件复制到 replica x 个节点中。
3、条带模式:即Striped, 创建volume 时带 stripe x 数量: 将文件切割成数据块,分别存储到 stripe x 个节点中 ( 类似raid 0 )。
4、分布式条带模式:最少需要4台服务器才能创建。 创建volume 时 stripe 2 server = 4 个节点: 是DHT 与 Striped 的组合型。
5、分布式复制模式:最少需要4台服务器才能创建。 创建volume 时 replica 2 server = 4 个节点:是DHT 与 AFR 的组合型。
6、条带复制卷模式:最少需要4台服务器才能创建。 创建volume 时 stripe 2 replica 2 server = 4 个节点: 是 Striped 与 AFR 的组合型。
7、三种模式混合: 至少需要8台 服务器才能创建。 stripe 2 replica 2 , 每4个节点 组成一个 组。
每一种卷都有不同的使用方式,最后都是以pv和pvc的使用方式。
创建资源pv
$ cat glusterfs-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: gluster-dev-volume
spec:
capacity:
storage: 8Gi
accessModes:
- ReadWriteMany
glusterfs:
endpoints: "glusterfs-cluster"---需要创建endpoints和service来暴露glusterfs
path: "k8s-volume"
readOnly: false
创建资源pvc
$ cat glusterfs-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: glusterfs-nginx
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 8Gi
实例挂载
$ vi nginx-deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-dm
spec:
replicas: 2
template:
metadata:
labels:
name: nginx
spec:
containers:
- name: nginx
image: nginx:alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts:
- name: gluster-dev-volume
mountPath: "/usr/share/nginx/html"
volumes:
- name: gluster-dev-volume
persistentVolumeClaim:
claimName: glusterfs-nginx
然后就可以共享glusterfs的存储了。
ceph
ceph是一个linux PB级分布式文件存储系统,它是一个大容量并且简单扩容,高性能,高可靠等特性,详细了解可以到这里。
fs
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: myservice-pv
labels:
name: myservice-pv
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteMany
cephfs:
monitors:
- node1:6789
- node2:6789
- node3:6789
path: /data/myservice
user: cephfs
secretRef:
name: ceph-secret-client-cephfs(client.cephfs的key)
readOnly: false
persistentVolumeReclaimPolicy: Retain
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myservice-pvc
namespace: dev
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
resources:
requests:
storage: 2Gi
selector:
matchLabels:
name: myservice-pv
---
---
kind: Deployment
apiVersion: apps/v1beta2
metadata:
labels:
app: myservice
name: myservice
namespace: dev
spec:
replicas: 1
selector:
matchLabels:
app: myservice
template:
metadata:
labels:
app: myservice
spec:
containers:
- name: myservice
image: harbor.frognew.com/public/myservice:latest
imagePullPolicy: Always
resources:
requests:
memory: "2Gi"
cpu: "250m"
limits:
memory: "2Gi"
cpu: "500m"
volumeMounts:
- name: data
mountPath: /data
ports:
- containerPort: 8080
protocol: TCP
volumes:
- name: data
persistentVolumeClaim:
claimName: myservice-pvc
rbd
PV的描述文件ceph-pv.yaml如下:
apiVersion: v1
kind: PersistentVolume
metadata:
name: ceph-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
rbd:
monitors:
- 10.47.136.60:6789
pool: rbd
image: ceph-image
user: admin
secretRef:
name: ceph-secret(ceph rbd 的key)
fsType: ext4
readOnly: false
persistentVolumeReclaimPolicy: Recycle
执行创建操作:
# kubectl create -f ceph-pv.yaml
persistentvolume "ceph-pv" created
# kubectl get pv
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM REASON AGE
ceph-pv 1Gi RWO Recycle Available 7s
创建PVC
pvc是Pod对Pv的请求,将请求做成一种资源,便于管理以及pod复用。我们用到的pvc描述文件ceph-pvc.yaml如下:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: ceph-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
执行创建操作:
# kubectl create -f ceph-pvc.yaml
persistentvolumeclaim "ceph-claim" created
# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
ceph-claim Bound ceph-pv 1Gi RWO 12s
创建挂载ceph RBD的pod
pod描述文件ceph-pod1.yaml如下:
apiVersion: v1
kind: Pod
metadata:
name: ceph-pod1
spec:
containers:
- name: ceph-busybox1
image: busybox
command: ["sleep", "600000"]
volumeMounts:
- name: ceph-vol1
mountPath: /usr/share/busybox
readOnly: false
volumes:
- name: ceph-vol1
persistentVolumeClaim:
claimName: ceph-claim
创建pod操作:
# kubectl create -f ceph-pod1.yaml
pod "ceph-pod1" created
# kubectl get pod
NAME READY STATUS RESTARTS AGE
ceph-pod1 0/1 ContainerCreating 0 13s
csi
csi是目前比较主流的方式,可扩展的接口我们后面详细的说明。
local
local也就是我们常说的lpv。
用户希望 Kubernetes 能够直接使用宿主机上的本地磁盘目录,而不依赖于远程存储服务,来提供“持久化”的容器 Volume。这样做的好处很明显,由于这个 Volume 直接使用的是本地磁盘,尤其是 SSD 盘,它的读写性能相比于大多数远程存储来说,要好得多。这个需求对本地物理服务器部署的私有 Kubernetes 集群来说,非常常见。也就是Local Persistent Volume ,lpv但是并不适用于所有应用,它的适用范围非常固定,比如:高优先级的系统应用,需要在多个不同节点上存储数据,并且对 I/O 较为敏感。典型的应用包括:分布式数据存储比如 MongoDB、Cassandra ,prometheus,vm等,分布式文件系统比如 GlusterFS、Ceph 等,以及需要在本地磁盘上进行大量数据缓存的分布式应用。其次,相比于正常的 PV,一旦这些节点宕机且不能恢复时,Local Persistent Volume 的数据就可能丢失。这就要求使用 Local Persistent Volume 的应用必须具备数据备份和恢复的能力,允许你把这些数据定时备份在其他位置。
Local Persistent Volume的实现是pv+NodeAffinity+sc的延时绑定,我们不能局限于path上,仅仅使用hostpath+NodeAffinity来实现,官方也是支持使用hostpath指作为pv,比如,一个 PV 是一个 hostPath 类型的 Volume。如果这个 hostPath 对应的目录,已经在节点 A 上被事先创建好了。那么,我只需要再给这个 Pod 加上一个 nodeAffinity=nodeA,就可以使用这个 Volume 。
但是也说明了仅供单节点测试使用;不适用于多节点集群; 请尝试使用 local 卷作为替代,这又是为什么尼?
其实绝不应该把一个宿主机上的目录当作 PV 使用。这是因为,这种本地目录的存储行为完全不可控,它所在的磁盘随时都可能被应用写满,甚至造成整个宿主机宕机。而且,不同的本地目录之间也缺乏哪怕最基础的 I/O 隔离机制。所以,一个 Local Persistent Volume 对应的存储介质,一定是一块额外挂载在宿主机的磁盘或者块设备(“额外”的意思是,它不应该是宿主机根目录所使用的主硬盘)。这个原则,我们可以称为“一个 PV 一块盘”。所以正常都是使用pv,而不是path。
在这个 PV 的定义里,需要有一个 nodeAffinity 字段指定 node-1 这个节点的名字。这样,调度器在调度 Pod 的时候,就能够知道一个 PV 与节点的对应关系,从而做出正确的选择。这正是 Kubernetes 实现“在调度的时候就考虑 Volume 分布”的主要方法。
实践
先创建pv
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-pv
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /mnt/disks/vol1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node-1
使用 PV 和 PVC 的最佳实践,是你要创建一个 StorageClass 来描述这个 PV,如下所示:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
这个 StorageClass 的名字,叫作 local-storage。有几个注意点
- 它的 provisioner 字段,我们指定的是 no-provisioner。这是因为 Local Persistent Volume 目前尚不支持 Dynamic Provisioning,所以它没办法在用户创建 PVC 的时候,就自动创建出对应的 PV。也就是说,我们前面创建 PV 的操作,是不可以省略的。
- StorageClass 还定义了一个 volumeBindingMode=WaitForFirstConsumer 的属性。它是 Local Persistent Volume 里一个非常重要的特性,即:延迟绑定。
我们知道,当你提交了 PV 和 PVC 的 YAML 文件之后,Kubernetes 就会根据它们俩的属性,以及它们指定的 StorageClass 来进行绑定。只有绑定成功后,Pod 才能通过声明这个 PVC 来使用对应的 PV。可是,如果你使用的是 Local Persistent Volume 的话,就会发现,这个流程根本行不通。比如,现在你有一个 Pod,它声明使用的 PVC 叫作 pvc-1。并且,我们规定,这个 Pod 只能运行在 node-2 上。而在 Kubernetes 集群中,有两个属性(比如:大小、读写权限)相同的 Local 类型的 PV。其中,第一个 PV 的名字叫作 pv-1,它对应的磁盘所在的节点是 node-1。而第二个 PV 的名字叫作 pv-2,它对应的磁盘所在的节点是 node-2。假设现在,Kubernetes 的 Volume 控制循环里,首先检查到了 pvc-1 和 pv-1 的属性是匹配的,于是就将它们俩绑定在一起。然后,你用 kubectl create 创建了这个 Pod。这时候,问题就出现了。调度器看到,这个 Pod 所声明的 pvc-1 已经绑定了 pv-1,而 pv-1 所在的节点是 node-1,根据“调度器必须在调度的时候考虑 Volume 分布”的原则,这个 Pod 自然会被调度到 node-1 上。可是,我们前面已经规定过,这个 Pod 根本不允许运行在 node-1 上。所以。最后的结果就是,这个 Pod 的调度必然会失败。这就是为什么,在使用 Local Persistent Volume 的时候,我们必须想办法推迟这个“绑定”操作。
推迟到调度的时候
所以说,StorageClass 里的 volumeBindingMode=WaitForFirstConsumer 的含义,就是告诉 Kubernetes 里的 Volume 控制循环:虽然你已经发现这个 StorageClass 关联的 PVC 与 PV 可以绑定在一起,但请不要现在就执行绑定操作(即:设置 PVC 的 VolumeName 字段)。而要等到第一个声明使用该 PVC 的 Pod 出现在调度器之后,调度器再综合考虑所有的调度规则,当然也包括每个 PV 所在的节点位置,来统一决定,这个 Pod 声明的 PVC,到底应该跟哪个 PV 进行绑定。这样,在上面的例子里,由于这个 Pod 不允许运行在 pv-1 所在的节点 node-1,所以它的 PVC 最后会跟 pv-2 绑定,并且 Pod 也会被调度到 node-2 上。所以,通过这个延迟绑定机制,原本实时发生的 PVC 和 PV 的绑定过程,就被延迟到了 Pod 第一次调度的时候在调度器中进行,从而保证了这个绑定结果不会影响 Pod 的正常调度。
我们只需要定义一个非常普通的 PVC,就可以让 Pod 使用到上面定义好的 Local Persistent Volume 了,如下所示:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: example-local-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: local-storage
可以看到,这个 PVC 没有任何特别的地方。唯一需要注意的是,它声明的 storageClassName 是 local-storage。所以,将来 Kubernetes 的 Volume Controller 看到这个 PVC 的时候,不会为它进行绑定操作。现在,我们来创建这个 PVC:
$ kubectl create -f local-pvc.yaml
persistentvolumeclaim/example-local-claim created
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
example-local-claim Pending local-storage 7s
可以看到,尽管这个时候,Kubernetes 里已经存在了一个可以与 PVC 匹配的 PV,但这个 PVC 依然处于 Pending 状态,也就是等待绑定的状态。然后,我们编写一个 Pod 来声明使用这个 PVC,如下所示:
kind: Pod
apiVersion: v1
metadata:
name: example-pv-pod
spec:
volumes:
- name: example-pv-storage
persistentVolumeClaim:
claimName: example-local-claim
containers:
- name: example-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: example-pv-storage
这个 Pod 没有任何特别的地方,你只需要注意,它的 volumes 字段声明要使用前面定义的、名叫 example-local-claim 的 PVC 即可。而我们一旦使用 kubectl create 创建这个 Pod,就会发现,我们前面定义的 PVC,会立刻变成 Bound 状态,与前面定义的 PV 绑定在了一起,如下所示:
$ kubectl create -f local-pod.yaml
pod/example-pv-pod created
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
example-local-claim Bound example-pv 5Gi RWO local-storage 6h
也就是说,在我们创建的 Pod 进入调度器之后,“绑定”操作才开始进行。这时候,我们可以尝试在这个 Pod 的 Volume 目录里,创建一个测试文件,比如:
$ kubectl exec -it example-pv-pod -- /bin/sh
# cd /usr/share/nginx/html
# touch test.txt
然后,登录到 node-1 这台机器上,查看一下它的 /mnt/disks/vol1 目录下的内容,你就可以看到刚刚创建的这个文件:
# 在node-1上
$ ls /mnt/disks/vol1
test.txt
而如果你重新创建这个 Pod 的话,就会发现,我们之前创建的测试文件,依然被保存在这个持久化 Volume 当中:
$ kubectl delete -f local-pod.yaml
$ kubectl create -f local-pod.yaml
$ kubectl exec -it example-pv-pod -- /bin/sh
# ls /usr/share/nginx/html
# touch test.txt
这就说明,像 Kubernetes 这样构建出来的、基于本地存储的 Volume,完全可以提供容器持久化存储的功能。所以,像 StatefulSet 这样的有状态编排工具,也完全可以通过声明 Local 类型的 PV 和 PVC,来管理应用的存储状态。需要注意的是,我们上面手动创建 PV 的方式,即 Static 的 PV 管理方式,在删除 PV 时需要按如下流程执行操作:
- 删除使用这个 PV 的 Pod;
- 从宿主机移除本地磁盘(比如,umount 它);
- 删除 PVC;
- 删除 PV。
如果不按照这个流程的话,这个 PV 的删除就会失败。当然,由于上面这些创建 PV 和删除 PV 的操作比较繁琐,Kubernetes 其实提供了一个 Static Provisioner 来帮助你管理这些 PV。比如,我们现在的所有磁盘,都挂载在宿主机的 /mnt/disks 目录下。那么,当 Static Provisioner 启动后,它就会通过 DaemonSet,自动检查每个宿主机的 /mnt/disks 目录。然后,调用 Kubernetes API,为这些目录下面的每一个挂载,创建一个对应的 PV 对象出来。这些自动创建的 PV,如下所示:
$ kubectl get pv
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
local-pv-ce05be60 1024220Ki RWO Delete Available local-storage 26s
$ kubectl describe pv local-pv-ce05be60
Name: local-pv-ce05be60
...
StorageClass: local-storage
Status: Available
Claim:
Reclaim Policy: Delete
Access Modes: RWO
Capacity: 1024220Ki
NodeAffinity:
Required Terms:
Term 0: kubernetes.io/hostname in [node-1]
Message:
Source:
Type: LocalVolume (a persistent volume backed by local storage on a node)
Path: /mnt/disks/vol1
这个 PV 里的各种定义,比如 StorageClass 的名字、本地磁盘挂载点的位置,都可以通过 provisioner 的配置文件指定。当然,provisioner 也会负责前面提到的 PV 的删除工作。
实例
[root@taas-mpi-prd-10-193-28-21.v-bj-4.vivo.lan:/root]
# kubectl get pv -n monitoring | grep vm
vm-storage-0 80000Gi RWO Retain Bound monitoring/data-vmstorage-2 local-storage-vmstorage 14d
vm-storage-1 80000Gi RWO Retain Bound monitoring/data-vmstorage-1 local-storage-vmstorage 14d
vm-storage-2 80000Gi RWO Retain Bound monitoring/data-vmstorage-0 local-storage-vmstorage 14d
[root@taas-mpi-prd-10-193-28-21.v-bj-4.vivo.lan:/root]
# kubectl get pvc -n monitoring | grep vm
data-vmstorage-0 Bound vm-storage-2 80000Gi RWO local-storage-vmstorage 14d
data-vmstorage-1 Bound vm-storage-1 80000Gi RWO local-storage-vmstorage 14d
data-vmstorage-2 Bound vm-storage-0 80000Gi RWO local-storage-vmstorage 14d
[root@taas-mpi-prd-10-193-28-21.v-bj-4.vivo.lan:/root]
# kubectl get sc -n monitoring | grep vm
local-storage-vmstorage kubernetes.io/no-provisioner 14d
[root@taas-mpi-prd-10-193-28-21.v-bj-4.vivo.lan:/root]
# kubectl get pv vm-storage-0 -n monitoring -oyaml
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
meta.helm.sh/release-name: vm
meta.helm.sh/release-namespace: monitoring
pv.kubernetes.io/bound-by-controller: "yes"
creationTimestamp: 2021-06-09T02:54:24Z
finalizers:
- kubernetes.io/pv-protection
labels:
app.kubernetes.io/managed-by: Helm
name: vm-storage-0
resourceVersion: "3703596141"
selfLink: /api/v1/persistentvolumes/vm-storage-0
uid: ff9a0f3a-c8cd-11eb-b835-e4434b707aca
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 80000Gi
claimRef:
apiVersion: v1
kind: PersistentVolumeClaim
name: data-vmstorage-2
namespace: monitoring
resourceVersion: "3703592809"
uid: ff9aaf4d-c8cd-11eb-b835-e4434b707aca
local:
path: /data/vm
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: monitoring.io/node
operator: In
values:
- prometheus
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage-vmstorage
status:
phase: Bound
# kubectl get sc local-storage-vmstorage -n monitoring -oyaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
annotations:
meta.helm.sh/release-name: vm
meta.helm.sh/release-namespace: monitoring
creationTimestamp: 2021-06-09T02:54:24Z
labels:
app.kubernetes.io/managed-by: Helm
name: local-storage-vmstorage
resourceVersion: "3703592791"
selfLink: /apis/storage.k8s.io/v1/storageclasses/local-storage-vmstorage
uid: ff99c127-c8cd-11eb-b835-e4434b707aca
provisioner: kubernetes.io/no-provisioner
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer
# kubectl get pvc data-vmstorage-2 -n monitoring -oyaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
annotations:
meta.helm.sh/release-name: vm
meta.helm.sh/release-namespace: monitoring
pv.kubernetes.io/bind-completed: "yes"
pv.kubernetes.io/bound-by-controller: "yes"
creationTimestamp: 2021-06-09T02:54:24Z
finalizers:
- kubernetes.io/pvc-protection
labels:
app.kubernetes.io/managed-by: Helm
name: data-vmstorage-2
namespace: monitoring
resourceVersion: "3703596144"
selfLink: /api/v1/namespaces/monitoring/persistentvolumeclaims/data-vmstorage-2
uid: ff9aaf4d-c8cd-11eb-b835-e4434b707aca
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 80000Gi
storageClassName: local-storage-vmstorage
volumeName: vm-storage-0
status:
accessModes:
- ReadWriteOnce
capacity:
storage: 80000Gi
phase: Bound
pvc
pvc也是一种集群资源。PVC 描述的,则是 Pod 所希望使用的持久化存储的属性。PVC 其实就是一种特殊的 Volume。可以挂载给volume,
PersistentVolumeClaim(持久化卷声明),PVC 是用户对存储资源的一种请求。可以说是连接k8s和pv的桥梁:
1、职责分离,pvc中只要声明自己需要的大小,访问方式等业务真心关心的存储需求
2、pvc简化来user对存储的要求,pv才是存储的实际信息的承载体,,通过kube-controller-manager中的pv controller将pvc和合适的pv绑定在一起,完成存储。
3、pvc是抽象的接口,pv是接口的实现,其实也就是面向对象的思想,PVC 可以理解为持久化存储的“接口”,它提供了对某种持久化存储的描述,但不提供具体的实现;而这个持久化存储的实现部分则由 PV 负责完成。
接着pv的实例,我们接着pv来继续创建pvc。
[root@master ~]# cat test.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-deploy
namespace: default
spec:
selector:
app: mynginx
type: NodePort
ports:
- name: nginx
port: 80
targetPort: 80
nodePort: 31111
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mydeploy
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: mynginx
template:
metadata:
name: web
labels:
app: mynginx
spec:
containers:
- name: mycontainer
image: nginx
volumeMounts:
- mountPath: /usr/share/nginx/html
name: html
ports:
- containerPort: 80
volumes:
- name: html
persistentVolumeClaim:
claimName: mypvc
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc
namespace: default
spec:
accessMode:
- ReadWriteMany
resources:
requests:
storage: 5Gi
执行yaml文件
[root@master ~]# kubectl create -f test.yaml
service/nginx-deploy created
deployment.apps/mydeploy created
persistentvolumeclaim/mypvc created
再次查看pv,已经显示pvc被绑定到了pv02上
[root@master ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01 10Gi RWO,RWX Retain Available 22m
pv02 20Gi RWX Retain Bound default/mypvc 22m
查看pvc
[root@master ~]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mypvc Bound pv02 20Gi RWX 113s
验证
在nfs server服务器上找到相应的目录执行以下命令
[root@localhost share_v1]# echo 'test pvc' > index.html
然后打开浏览器,OK,没问题。
StorageClass
对于一个大规模的 Kubernetes 集群里很可能有成千上万个 PVC,这就意味着运维人员必须得事先创建出成千上万个 PV。更麻烦的是,随着新的 PVC 不断被提交,运维人员就不得不继续添加新的、能满足条件的 PV,否则新的 Pod 就会因为 PVC 绑定不到 PV 而失败。在实际操作中,这几乎没办法靠人工做到。
为了解决这一问题,Kubernetes 引入了一个新的资源对象:StorageClass,StorageClass 对象的作用,其实就是创建 PV 的模板。
StorageClass 对象会定义如下两个部分内容:
- 第一,PV 的属性。比如,存储类型、Volume 的大小等等。
- 第二,创建这种 PV 需要用到的存储插件。比如,Ceph 等等。
有了这样两个信息之后,当用户通过 PVC 对存储资源进行申请时,StorageClass 会使用 Provisioner(不同 Volume 对应不同的 Provisioner)来自动创建用户所需 PV。这样应用就可以随时申请到合适的存储资源,而不用担心集群管理员没有事先分配好需要的 PV。
自动创建的 PV 以 ${namespace}-${pvcName}-${pvName} 这样的命名格式创建在后端存储服务器上的共享数据目录中。
自动创建的 PV 被回收后会以 archieved-${namespace}-${pvcName}-${pvName} 这样的命名格式存在后端存储服务器上。
其实StorageClass就是动态创建pv,声明一个StorageClass,只要在pvc中annotations中声明对应的标签就可以自动创建pvc中需要的pv,我们来看一一下核心字段provisioner、parameters和reclaimPolicy。
- provisioner 每个 StorageClass 都有一个制备器(Provisioner),用来决定使用哪个卷插件制备 PV。 该字段必须指定。也可以支持可扩展的,比如csi,但是要设置
allowVolumeExpansion字段设置为 true
| 卷插件 | 内置制备器 | 配置例子 | | :——————- | :——–: | :———————————————————-: | | AWSElasticBlockStore | ✓ | AWS EBS | | AzureFile | ✓ | Azure File | | AzureDisk | ✓ | Azure Disk | | CephFS | - | - | | Cinder | ✓ | OpenStack Cinder | | FC | - | - | | FlexVolume | - | - | | Flocker | ✓ | - | | GCEPersistentDisk | ✓ | GCE PD | | Glusterfs | ✓ | Glusterfs | | iSCSI | - | - | | Quobyte | ✓ | Quobyte | | NFS | - | - | | RBD | ✓ | Ceph RBD | | VsphereVolume | ✓ | vSphere | | PortworxVolume | ✓ | Portworx Volume | | ScaleIO | ✓ | ScaleIO | | StorageOS | ✓ | StorageOS | | Local | - | Local |
reclaimPolicy可以是
Delete(默认) 或者Retain。parameters Storage Classes 的参数描述了存储类的卷。取决于制备器,可以接受不同的参数。 例如,参数 type 的值 io1 和参数 iopsPerGB 特定于 EBS PV。 当参数被省略时,会使用默认值。
一个 StorageClass 最多可以定义 512 个参数。这些参数对象的总长度不能 超过 256 KiB, 包括参数的键和值
实例
1、创建 StorageClass 对象
$ vim nfs-client-class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: course-nfs-storage
provisioner: fuseim.pri/ifs # or choose another name, must match deployment's env PROVISIONER_NAME'
2、使用 Kubectl 命令建立这个 StorageClass。
$ kubectl create -f nfs-client-class.yaml
storageclass.storage.k8s.io "course-nfs-storage" created
以上都创建完成后查看下相关资源的状态。
$ kubectl get pods|grep nfs-client
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-9d94b899c-nn4c7 1/1 Running 0 1m
$ kubectl get storageclass
NAME PROVISIONER AGE
course-nfs-storage fuseim.pri/ifs 1m
3、手动创建的一个 PVC 对象
新建一个 PVC 对象,我们在这个 PVC 里添加了一个叫作 storageClassName 的字段,用于指定该 PVC 所要使用的 StorageClass 的名字。比如
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: claim1
spec:
accessModes:
- ReadWriteOnce
storageClassName: course-nfs-storage
resources:
requests:
storage: 30Gi
$ kubectl create -f test-pvc.yaml
persistentvolumeclaim "test-pvc" created
创建完成后,我们来看看对应的资源是否创建成功。
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc1-nfs Bound pv1-nfs 1Gi RWO 4h
test-pvc Bound pvc-3d8d6ecf-9a13-11e8-9a96-001c42c61a79 100Mi RWX course-nfs-storage 41s
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv1-nfs 1Gi RWO Recycle Bound default/pvc1-nfs 5h
pv2-nfs 2Gi RWO Recycle Available 1h
pvc-3d8d6ecf-9a13-11e8-9a96-001c42c61a79 100Mi RWX Delete Bound default/test-pvc course-nfs-storage 2m
从上面的结果我们可以看到一个名为 test-pvc 的 PVC 对象创建成功并且状态已经是 Bound 了。对应也自动创建了一个名为 pvc-3d8d6ecf-9a13-11e8-9a96-001c42c61a79 的 PV 对象,其访问模式是 RWX,回收策略是 Delete。STORAGECLASS 栏中的值也正是我们创建的 StorageClass 对象 course-nfs-storage。
有了 Dynamic Provisioning 机制,运维人员只需要在 Kubernetes 集群里创建出数量有限的 StorageClass 对象就可以了。这就好比,运维人员在 Kubernetes 集群里创建出了各种各样的 PV 模板。这时候,当开发人员提交了包含 StorageClass 字段的 PVC 之后,Kubernetes 就会根据这个 StorageClass 创建出对应的 PV。
上面我们对ceph进行了说明,其实正常情况下都是使用sc来使用的,直接看ceph rbd使用配置,注意:ceph rbd不能多写。
Rbd
1、配置 StorageClass
# 如果使用kubeadm创建的集群 provisioner 使用如下方式
# provisioner: ceph.com/rbd
cat >storageclass-ceph-rdb.yaml<<EOF
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: dynamic-ceph-rdb
provisioner: ceph.com/rbd
# provisioner: kubernetes.io/rbd
parameters:
monitors: 11.11.11.111:6789,11.11.11.112:6789,11.11.11.113:6789
adminId: admin
adminSecretName: ceph-secret
adminSecretNamespace: kube-system
pool: kube
userId: kube
userSecretName: ceph-user-secret
fsType: ext4
imageFormat: "2"
imageFeatures: "layering"
EOF
2、创建pvc
cat >ceph-rdb-pvc-test.yaml<<EOF
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: ceph-rdb-claim
spec:
accessModes:
- ReadWriteOnce
storageClassName: dynamic-ceph-rdb
resources:
requests:
storage: 2Gi
EOF
3、创建 nginx pod 挂载
cat >nginx-pod.yaml<<EOF
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod1
labels:
name: nginx-pod1
spec:
containers:
- name: nginx-pod1
image: nginx:alpine
ports:
- name: web
containerPort: 80
volumeMounts:
- name: ceph-rdb
mountPath: /usr/share/nginx/html
volumes:
- name: ceph-rdb
persistentVolumeClaim:
claimName: ceph-rdb-claim
EOF
fs
1、配置 StorageClass
cat >storageclass-cephfs.yaml<<EOF
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: dynamic-cephfs
provisioner: ceph.com/cephfs
parameters:
monitors: 11.11.11.111:6789,11.11.11.112:6789,11.11.11.113:6789
adminId: admin
adminSecretName: ceph-secret
adminSecretNamespace: "kube-system"
claimRoot: /volumes/kubernetes
EOF
2、创建pvc
cat >cephfs-pvc-test.yaml<<EOF
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: cephfs-claim
spec:
accessModes:
- ReadWriteOnce
storageClassName: dynamic-cephfs
resources:
requests:
storage: 2Gi
EOF
3、创建 nginx pod 挂载
cat >nginx-pod.yaml<<EOF
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod1
labels:
name: nginx-pod1
spec:
containers:
- name: nginx-pod1
image: nginx:alpine
ports:
- name: web
containerPort: 80
volumeMounts:
- name: cephfs
mountPath: /usr/share/nginx/html
volumes:
- name: cephfs
persistentVolumeClaim:
claimName: cephfs-claim
EOF
总结
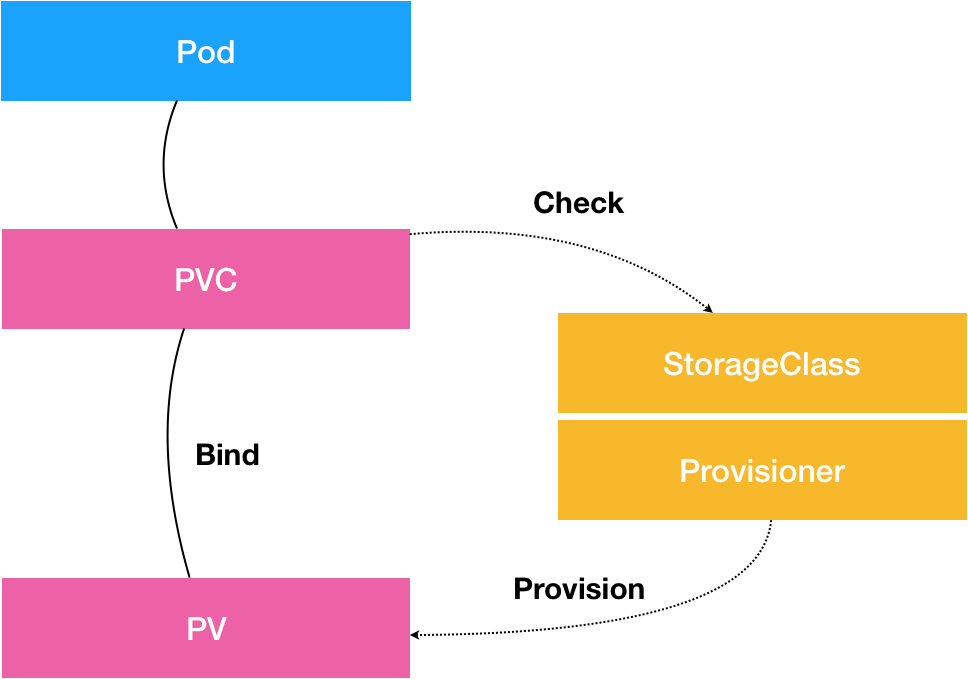
- PVC 描述的,是 Pod 想要使用的持久化存储的属性,比如存储的大小、读写权限等。
- PV 描述的,则是一个具体的 Volume 的属性,比如 Volume 的类型、挂载目录、远程存储服务器地址等。
- 而 StorageClass 的作用,则是充当 PV 的模板。并且,只有同属于一个 StorageClass 的 PV 和 PVC,才可以绑定在一起。
基本原理
核心流程
无论是docker存储也好,K8S存储也好,亦或者是其它类的容器相关的存储抽象,其本质都是一样的——让存储在容器里ready,所谓容器的 Volume,其实就是将一个宿主机上的目录,跟一个容器里的目录绑定挂载在了一起。核心做三件工作:
- Provision/Delete(创建/删除存储卷,处理pv和pvc之间的关系)
- Attach/Detach(挂接和摘除存储卷,处理的是volumes和node上目录之间的关系)
- Mount/Unmount(挂载和摘除目录,处理的是volumes和pod之间的关系)。
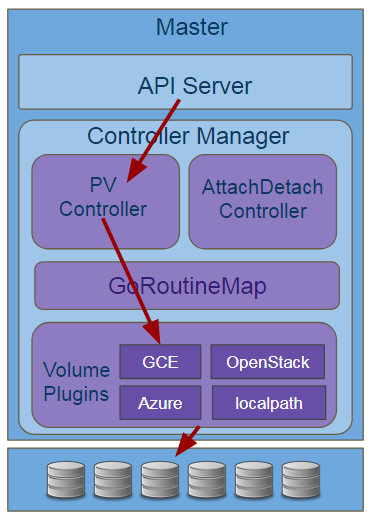
管理
PV Controller和K8S其它组件一样监听API Server中的资源更新,对于卷管理主要是监听PV,PVC, SC三类资源,当监听到这些资源的创建、删除、修改时,PV Controller经过判断是需要做创建、删除、绑定、回收等动作(后续会展开介绍内部逻辑),然后根据需要调用Volume Plugins进行业务处理,大致调用逻辑如下图
挂载
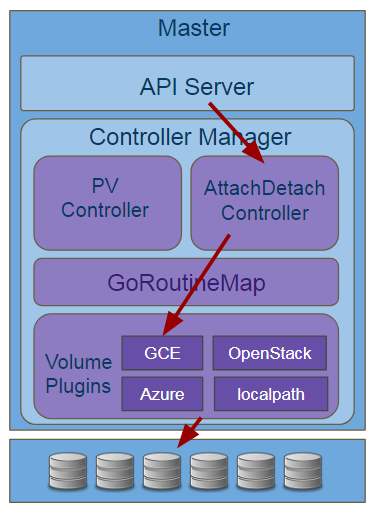
卷的挂载,主要分两个阶段,attach/detach卷和mount/umount 卷,其中卷的attach/detach,有两个组件做这个工作,分别是Master上的AttachDetach Controller 和Minion上的VolumeManager。
先来看看AttachDetach Controller(后简称ADController),ADController的处理流程和上面介绍的PV Controller基本类似,首先监听API Server的资源变化,主要监听的是node和pod资源,通过node和pod变更,触发ADController是否attach/detach操作,然后调用plugin做相应的业务处理,大致流程如下
VolumeManager相比ADController最大的区别是事件触发的来源,VolumeManager不会监听API Server,在Minion端所有的资源监听都是Kubelet完成的,Kubelet会监听到调度到该节点上的pod声明,会把pod缓存到Pod Manager中,VolumeManager通过Pod Manager获取PV/PVC的状态,并进行分析出具体的attach/detach, 操作然后调用plugin进行相应的业务处理,流程如下
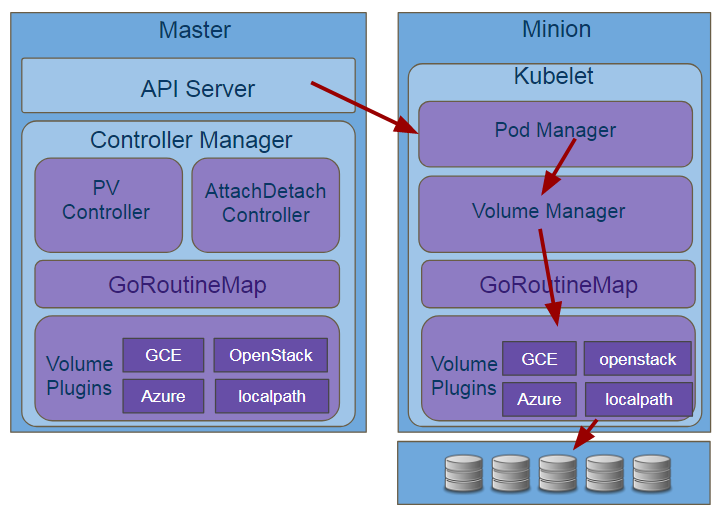
这边只是简单的总结,详细的说明我们会在解析csi的作出对应的解析。
发展
在CSI之前,K8S里提供存储服务都是原生集成在组件中的,提供了内嵌原生 Driver 的方式连接外部的常见存储系统例如 NFS、iSCSI、CephFS、RBD 等来满足不同业务的需求。这种方式需要将存储提供者的代码逻辑放到K8S的代码库中运行(如果要求不高,其实也能运行够用),调用引擎与插件间属于强耦合,这种方式会带来一些问题:
- 存储插件需要一同随K8S发布。
- K8S社区需要对存储插件的测试、维护负责。
- 存储插件的问题有可能会影响K8S部件正常运行。
- 存储插件享有K8S部件同等的特权存在安全隐患。
- 存储插件开发者必须遵循K8S社区的规则开发代码。
所以和其他服务管理系统一样,K8s 逐渐的将存储系统的具体实现从主项目中分离出来,通过定义接口的方式允许第三方厂商自行接入存储服务。在这个道路上也经历了两个阶段:
- Flex Volume, 自 1.2 版本引入。第三方存储服务提供商直接在 K8s Server 上部署符合 Flex Volume 规范的 Driver,利用 K8s 暴露出的 mount/unmount/attach/detach 等关键 API 实现存储系统的接入。
- 这个模式主要的问题是,在这个形态下第三方厂商的 Driver 有权限接入物理节点的根文件系统,这会带来安全上的隐患
- 存储插件在执行mount、attach这类操作时,往往需要到host去安装第三方工具或者加载一些依赖库,这样host的OS版本往往需要定制,不再是一个简单的linux发型版本,这样的情况太多,会使部署变得复杂。
- Container Storage Interface (CSI), 自 1.9 版本引入,目前已经进入 GA 阶段(1.13)。CSI 定义了容器场景所需要的存储控制原语和完整的控制流程,并且在 K8s 的 CSI 实现中,所有的第三方 Driver 和 K8s 的其他服务扩展一样,以服务容器的形态的运行,不会直接影响到 K8s 的核心系统稳定性,是目前主要使用的模式。