本篇文章主要是对prometheus的一些原理进行解析。
启动流程解析
Prometheus 启动过程中,主要包含服务组件初始化,服务组件配置应用及启动各个服务组件三个部分,下面基于版本 v2.7.1,详细分析这三部分内容。
服务组件初始化
Storage组件初始化
Prometheus的Storage组件是时序数据库,包含两个:localStorage和remoteStorage。localStorage当前版本指TSDB,用于对metrics的本地存储存储,remoteStorage用于metrics的远程存储,其中fanoutStorage作为localStorage和remoteStorage的读写代理服务器。
初始化流程如下,代码文件prometheus/cmd/prometheus/main.go
localStorage = &tsdb.ReadyStorage{} //本地存储
remoteStorage = remote.NewStorage(log.With(logger, "component", "remote"), //远端存储 localStorage.StartTime, time.Duration(cfg.RemoteFlushDeadline))
fanoutStorage = storage.NewFanout(logger, localStorage, remoteStorage) //读写代理服务器
notifier 组件初始化
notifier组件用于发送告警信息给AlertManager,通过方法notifier.NewManager完成初始化
代码文件prometheus/cmd/prometheus/main.go
notifierManager = notifier.NewManager(&cfg.notifier, log.With(logger, "component", "notifier"))
discoveryManagerScrape组件初始化
discoveryManagerScrape组件用于服务发现,当前版本支持多种服务发现系统,比如kuberneters等,通过方法discovery.NewManager完成初始化。
代码文件prometheus/cmd/prometheus/main.go
discoveryManagerScrape = discovery.NewManager(ctxScrape, log.With(logger, "component", "discovery manager scrape"), discovery.Name("scrape"))
discoveryManagerNotify组件初始化
discoveryManagerNotify组件用于告警通知服务发现,比如AlertManager服务.也是通过方法discovery.NewManager完成初始化,不同的是,discoveryManagerNotify服务于notify,而discoveryManagerScrape服务于scrape。
代码文件prometheus/cmd/prometheus/main.go
discoveryManagerNotify = discovery.NewManager(ctxNotify, log.With(logger, "component", "discovery manager notify"), discovery.Name("notify")
scrapeManager组件初始化
scrapeManager组件利用discoveryManagerScrape组件发现的targets,抓取对应targets的所有metrics,并将抓取的metrics存储到fanoutStorage中,通过方法scrape.NewManager完成初始化。
代码文件prometheus/cmd/prometheus/main.go
scrapeManager = scrape.NewManager(log.With(logger, "component", "scrape manager"), fanoutStorage)
queryEngine组件
queryEngine组件用于rules查询和计算,通过方法promql.NewEngine完成初始化。
代码文件prometheus/cmd/prometheus/main.go
opts = promql.EngineOpts{
Logger: log.With(logger, "component", "query engine"),
Reg: prometheus.DefaultRegisterer,
MaxConcurrent: cfg.queryConcurrency, //最大并发查询个数
MaxSamples: cfg.queryMaxSamples,
Timeout: time.Duration(cfg.queryTimeout), //查询超时时间
}
queryEngine = promql.NewEngine(opts)
ruleManager组件初始化
ruleManager组件通过方法rules.NewManager完成初始化.其中rules.NewManager的参数涉及多个组件:存储,queryEngine和notifier,整个流程包含rule计算和发送告警。
代码文件prometheus/cmd/prometheus/main.go
ruleManager = rules.NewManager(&rules.ManagerOptions{
Appendable: fanoutStorage, //存储器
TSDB: localStorage, //本地时序数据库TSDB
QueryFunc: rules.EngineQueryFunc(queryEngine, fanoutStorage), //rules计算
NotifyFunc: sendAlerts(notifierManager, cfg.web.ExternalURL.String()), //告警通知
Context: ctxRule, //用于控制ruleManager组件的协程
ExternalURL: cfg.web.ExternalURL, //通过Web对外开放的URL
Registerer: prometheus.DefaultRegisterer,
Logger: log.With(logger, "component", "rule manager"),
OutageTolerance: time.Duration(cfg.outageTolerance), //当prometheus重启时,保持alert状态(https://ganeshvernekar.com/gsoc-2018/persist-for-state/)
ForGracePeriod: time.Duration(cfg.forGracePeriod),
ResendDelay: time.Duration(cfg.resendDelay),
}
Web组件初始化
Web组件用于为Storage组件,queryEngine组件,scrapeManager组件, ruleManager组件和notifier 组件提供外部HTTP访问方式,也就是我们经常访问的prometheus的界面。
初始化代码如下,代码文件prometheus/cmd/prometheus/main.go
cfg.web.Context = ctxWeb
cfg.web.TSDB = localStorage.Get
cfg.web.Storage = fanoutStorage
cfg.web.QueryEngine = queryEngine
cfg.web.ScrapeManager = scrapeManager
cfg.web.RuleManager = ruleManager
cfg.web.Notifier = notifierManager
cfg.web.Version = &web.PrometheusVersion{
Version: version.Version,
Revision: version.Revision,
Branch: version.Branch,
BuildUser: version.BuildUser,
BuildDate: version.BuildDate,
GoVersion: version.GoVersion,
}
cfg.web.Flags = map[string]string{}
// Depends on cfg.web.ScrapeManager so needs to be after cfg.web.ScrapeManager = scrapeManager
webHandler := web.New(log.With(logger, "component", "web"), &cfg.web)
服务组件配置应用
除了服务组件ruleManager用的方法是Update,其他服务组件的在匿名函数中通过各自的ApplyConfig方法,实现配置的管理。
代码文件prometheus/cmd/prometheus/main.go
reloaders := []func(cfg *config.Config) error{
remoteStorage.ApplyConfig, //存储配置
webHandler.ApplyConfig, //web配置
notifierManager.ApplyConfig, //notifier配置
scrapeManager.ApplyConfig, //scrapeManger配置
//从配置文件中提取Section:scrape_configs
func(cfg *config.Config) error {
c := make(map[string]sd_config.ServiceDiscoveryConfig)
for _, v := range cfg.ScrapeConfigs {
c[v.JobName] = v.ServiceDiscoveryConfig
}
return discoveryManagerScrape.ApplyConfig(c)
},
//从配置文件中提取Section:alerting
func(cfg *config.Config) error {
c := make(map[string]sd_config.ServiceDiscoveryConfig)
for _, v := range cfg.AlertingConfig.AlertmanagerConfigs {
// AlertmanagerConfigs doesn't hold an unique identifier so we use the config hash as the identifier.
b, err := json.Marshal(v)
if err != nil {
return err
}
c[fmt.Sprintf("%x", md5.Sum(b))] = v.ServiceDiscoveryConfig
}
return discoveryManagerNotify.ApplyConfig(c)
},
//从配置文件中提取Section:rule_files
func(cfg *config.Config) error {
// Get all rule files matching the configuration paths.
var files []string
for _, pat := range cfg.RuleFiles {
fs, err := filepath.Glob(pat)
if err != nil {
// The only error can be a bad pattern.
return fmt.Errorf("error retrieving rule files for %s: %s", pat, err)
}
files = append(files, fs...)
}
return ruleManager.Update(time.Duration(cfg.GlobalConfig.EvaluationInterval), files)
},
}
服务组件remoteStorage,webHandler,notifierManager和ScrapeManager的ApplyConfig方法,参数cfg *config.Config中传递的配置文件,是整个文件prometheus.yml
代码文件prometheus/scrape/manager.go
func (m *Manager) ApplyConfig(cfg *config.Config) error {
.......
}
服务组件discoveryManagerScrape和discoveryManagerNotify的ApplyConfig方法,参数中传递的配置文件,是文件中的一个Section
代码文件prometheus/discovery/manager.go
func (m *Manager) ApplyConfig(cfg map[string]sd_config.ServiceDiscoveryConfig) error {
......
}
所以,需要利用匿名函数提前处理下,取出对应的Section。
代码文件prometheus/cmd/prometheus/main.go
//从配置文件中提取Section:scrape_configs
func(cfg *config.Config) error {
c := make(map[string]sd_config.ServiceDiscoveryConfig)
for _, v := range cfg.ScrapeConfigs {
c[v.JobName] = v.ServiceDiscoveryConfig
}
return discoveryManagerScrape.ApplyConfig(c)
},
//从配置文件中提取Section:alerting
func(cfg *config.Config) error {
c := make(map[string]sd_config.ServiceDiscoveryConfig)
for _, v := range cfg.AlertingConfig.AlertmanagerConfigs {
// AlertmanagerConfigs doesn't hold an unique identifier so we use the config hash as the identifier.
b, err := json.Marshal(v)
if err != nil {
return err
}
c[fmt.Sprintf("%x", md5.Sum(b))] = v.ServiceDiscoveryConfig
}
return discoveryManagerNotify.ApplyConfig(c)
}
服务组件ruleManager,在匿名函数中提取出Section:rule_files
代码文件prometheus/cmd/prometheus/main.go
//从配置文件中提取Section:rule_files
func(cfg *config.Config) error {
// Get all rule files matching the configuration paths.
var files []string
for _, pat := range cfg.RuleFiles {
fs, err := filepath.Glob(pat)
if err != nil {
// The only error can be a bad pattern.
return fmt.Errorf("error retrieving rule files for %s: %s", pat, err)
}
files = append(files, fs...)
}
return ruleManager.Update(time.Duration(cfg.GlobalConfig.EvaluationInterval), files)
},
利用该组件内置的Update方法完成配置管理。
代码文件prometheus/rules/manager.go
func (m *Manager) Update(interval time.Duration, files []string) error {
.......
}
最后,通过reloadConfig方法,加载各个服务组件的配置项
代码文件prometheus/cmd/prometheus/main.go
func reloadConfig(filename string, logger log.Logger, rls ...func(*config.Config) error) (err error) {
level.Info(logger).Log("msg", "Loading configuration file", "filename", filename)
defer func() {
if err == nil {
configSuccess.Set(1)
configSuccessTime.SetToCurrentTime()
} else {
configSuccess.Set(0)
}
}()
conf, err := config.LoadFile(filename)
if err != nil {
return fmt.Errorf("couldn't load configuration (--config.file=%q): %v", filename, err)
}
failed := false
//通过一个for循环,加载各个服务组件的配置项
for _, rl := range rls {
if err := rl(conf); err != nil {
level.Error(logger).Log("msg", "Failed to apply configuration", "err", err)
failed = true
}
}
if failed {
return fmt.Errorf("one or more errors occurred while applying the new configuration (--config.file=%q)", filename)
}
promql.SetDefaultEvaluationInterval(time.Duration(conf.GlobalConfig.EvaluationInterval))
level.Info(logger).Log("msg", "Completed loading of configuration file", "filename", filename)
return nil
}
服务组件启动
实例化
这里引用了github.com/oklog/oklog/pkg/group包,实例化一个对象g
代码文件prometheus/cmd/prometheus/main.go
// "github.com/oklog/oklog/pkg/group"
var g group.Group
{
......
}
对象g中包含各个服务组件的入口,通过调用Add方法把把这些入口添加到对象g中,以组件scrapeManager为例。
代码文件prometheus/cmd/prometheus/main.go
{
// Scrape manager.
//通过方法Add,把ScrapeManager组件添加到g中
g.Add(
func() error {
// When the scrape manager receives a new targets list
// it needs to read a valid config for each job.
// It depends on the config being in sync with the discovery manager so
// we wait until the config is fully loaded.
<-reloadReady.C
//ScrapeManager组件的启动函数
err := scrapeManager.Run(discoveryManagerScrape.SyncCh())
level.Info(logger).Log("msg", "Scrape manager stopped")
return err
},
func(err error) {
// Scrape manager needs to be stopped before closing the local TSDB
// so that it doesn't try to write samples to a closed storage.
level.Info(logger).Log("msg", "Stopping scrape manager...")
scrapeManager.Stop()
},
)
}
run
通过对象g,调用方法run,启动所有服务组件
代码文件prometheus/cmd/prometheus/main.go
if err := g.Run(); err != nil {
level.Error(logger).Log("err", err)
os.Exit(1)
}
level.Info(logger).Log("msg", "See you next time!")
至此,Prometheus的启动过程分析完成。
内部结构
Prometheus的内部主要分为三大块,Retrieval是负责定时去暴露的目标页面上去抓取采样指标数据,Storage是负责将采样数据写磁盘,PromQL是Prometheus提供的查询语言模块。当然还有其他的一些组件,可以参考上面组件的初始化,比如一些web,notify等。
Retrieval
采集实现
Prometheus采集数据使用pull模式,通过HTTP协议去采集指标,只要应用系统能够提供HTTP接口就可以接入监控系统。
拉取目标称之为scrape,一个scrape一般对应一个进程,如下为scrape相关的配置。
配置文件
scrape_interval: 15s
scrape_configs:
- job_name: 'test_server_name'
static_configs:
- targets: ['localhost:8886']
labels:
project: 'test_server'
environment: 'test'
该配置描述:每15秒去拉取一次上报数据,拉取目标为localhost:8886。
读取配置
ScrapeConfig的结构如下:
type ScrapeConfig struct {
// 作业名称
JobName string `yaml:"job_name"`
// 同名lable,是否覆盖处理
HonorLabels bool `yaml:"honor_labels,omitempty"`
HonorTimestamps bool `yaml:"honor_timestamps"`
// 采集目标url参数
Params url.Values `yaml:"params,omitempty"`
// 采集周期
ScrapeInterval model.Duration `yaml:"scrape_interval,omitempty"`
// 采集超时时间
ScrapeTimeout model.Duration `yaml:"scrape_timeout,omitempty"`
// 目标 URl path
MetricsPath string `yaml:"metrics_path,omitempty"`
Scheme string `yaml:"scheme,omitempty"`
SampleLimit uint `yaml:"sample_limit,omitempty"`
// 服务发现配置
ServiceDiscoveryConfig sd_config.ServiceDiscoveryConfig `yaml:",inline"`
// 客户端http client 配置
HTTPClientConfig config_util.HTTPClientConfig `yaml:",inline"`
// 目标重置规则
RelabelConfigs []*relabel.Config `yaml:"relabel_configs,omitempty"`
// 指标重置规则
MetricRelabelConfigs []*relabel.Config `yaml:"metric_relabel_configs,omitempty"`
}
读取配置:
func (m *Manager) ApplyConfig(cfg *config.Config) error {
m.mtxScrape.Lock()
defer m.mtxScrape.Unlock()
// 初始化map结构,用于保存配置
c := make(map[string]*config.ScrapeConfig)
for _, scfg := range cfg.ScrapeConfigs {
// 配置读取维度
c[scfg.JobName] = scfg
}
m.scrapeConfigs = c
// 设置 所有时间序列和警告与外部通信时用的外部标签 external_labels
if err := m.setJitterSeed(cfg.GlobalConfig.ExternalLabels); err != nil {
return err
}
// 如果配置已经更改,清理历史配置,重新加载到池子中
var failed bool
for name, sp := range m.scrapePools {
// 如果当前job不存在,则删除
if cfg, ok := m.scrapeConfigs[name]; !ok {
sp.stop()
delete(m.scrapePools, name)
} else if !reflect.DeepEqual(sp.config, cfg) {
// 如果配置变更,重新启动reload,进行加载
err := sp.reload(cfg)
if err != nil {
level.Error(m.logger).Log("msg", "error reloading scrape pool", "err", err, "scrape_pool", name)
failed = true
}
}
}
// 失败 return
if failed {
return errors.New("failed to apply the new configuration")
}
return nil
}
Prometheus 中,将任意一个独立的数据源(target)称之为实例(instance)。包含相同类型的实例的集合称之为作业(job),从读取配置中,我们也能看到,以job为key。所以注意job在业务侧的使用。
Scrape Manager
添加Scrape Manager 到 run.Group启动。reloadReady.C的作用是当Manager接收到一组数据采集目标(target)的时候,他需要为每个job读取有效的配置。因此这里等待所有配置加载完成,进行下一步。
g.Add(
func() error {
// 当所有配置都准备好
<-reloadReady.C
// 启动scrapeManager
err := scrapeManager.Run(discoveryManagerScrape.SyncCh())
level.Info(logger).Log("msg", "Scrape manager stopped")
return err
},
func(err error) {
// 失败处理
level.Info(logger).Log("msg", "Stopping scrape manager...")
scrapeManager.Stop()
},
)
加载Targets
加载targets,如果targets更新,会触发重新加载,reloader的加载发生在后台,所以并不会影响target的更新,(配置文件中配置的target是依赖discoveryManagerScrape.ApplyConfig©进行加载的,后面分析target服务发现的时候详细分析)。
func (m *Manager) Run(tsets <-chan map[string][]*targetgroup.Group) error {
go m.reloader()
for {
select {
// 触发重新加载目标。添加新增
case ts := <-tsets:
m.updateTsets(ts)
select {
// 关闭 Scrape Manager 处理信号
case m.triggerReload <- struct{}{}:
default:
}
case <-m.graceShut:
return nil
}
}
}
scrape pool
顺着Run继续阅读,reload为每一组tatget生成一个对应的scrape pool管理targets集合,scrapePool结构如下:
type scrapePool struct {
appendable Appendable
logger log.Logger
// 读写锁
mtx sync.RWMutex
// Scrape 配置
config *config.ScrapeConfig
// http client
client *http.Client
// 正在运行的target
activeTargets map[uint64]*Target
// 无效的target
droppedTargets []*Target
// 所有运行的loop
loops map[uint64]loop
// 取消
cancel context.CancelFunc
// 创建loop
newLoop func(scrapeLoopOptions) loop
}
执行reload
m.reloade的流程也很简单,setName指我们配置中的job,如果scrapePools不存在该job,则添加,添加前也是先校验该job的配置是否存在,不存在则报错,创建scrape pool。总结看就是为每个job创建与之对应的scrape pool
func (m *Manager) reload() {
//加锁
m.mtxScrape.Lock()
var wg sync.WaitGroup
for setName, groups := range m.targetSets {
//检查该scrape是否存在scrapePools,不存在则创建
if _, ok := m.scrapePools[setName]; !ok {
//读取该scrape的配置
scrapeConfig, ok := m.scrapeConfigs[setName]
if !ok {
// 未读取到该scrape的配置打印错误
level.Error(m.logger).Log("msg", "error reloading target set", "err", "invalid config id:"+setName)
// 跳出
continue
}
// 创建该scrape的scrape pool
sp, err := newScrapePool(scrapeConfig, m.append, m.jitterSeed, log.With(m.logger, "scrape_pool", setName))
if err != nil {
level.Error(m.logger).Log("msg", "error creating new scrape pool", "err", err, "scrape_pool", setName)
continue
}
// 保存
m.scrapePools[setName] = sp
}
wg.Add(1)
// 并行运行,提升性能。
go func(sp *scrapePool, groups []*targetgroup.Group) {
sp.Sync(groups)
wg.Done()
}(m.scrapePools[setName], groups)
}
// 释放锁
m.mtxScrape.Unlock()
// 阻塞,等待所有pool运行完毕
wg.Wait()
}
创建scrape pool
scrape pool利用newLoop去为该job下的所有target生成对应的loop:
func newScrapePool(cfg *config.ScrapeConfig, app Appendable, jitterSeed uint64, logger log.Logger) (*scrapePool, error) {
targetScrapePools.Inc()
if logger == nil {
logger = log.NewNopLogger()
}
// 创建http client,用于执行数据抓取
client, err := config_util.NewClientFromConfig(cfg.HTTPClientConfig, cfg.JobName)
if err != nil {
targetScrapePoolsFailed.Inc()
return nil, errors.Wrap(err, "error creating HTTP client")
}
// 设置buffers
buffers := pool.New(1e3, 100e6, 3, func(sz int) interface{} { return make([]byte, 0, sz) })
// 设置scrapePool的一些基础属性
ctx, cancel := context.WithCancel(context.Background())
sp := &scrapePool{
cancel: cancel,
appendable: app,
config: cfg,
client: client,
activeTargets: map[uint64]*Target{},
loops: map[uint64]loop{},
logger: logger,
}
// newLoop用于生层loop,主要处理对应的target,可以理解为,每个target对应一个loop。
sp.newLoop = func(opts scrapeLoopOptions) loop {
// Update the targets retrieval function for metadata to a new scrape cache.
cache := newScrapeCache()
opts.target.setMetadataStore(cache)
return newScrapeLoop(
ctx,
opts.scraper,
log.With(logger, "target", opts.target),
buffers,
func(l labels.Labels) labels.Labels {
return mutateSampleLabels(l, opts.target, opts.honorLabels, opts.mrc)
},
func(l labels.Labels) labels.Labels { return mutateReportSampleLabels(l, opts.target) },
func() storage.Appender {
app, err := app.Appender()
if err != nil {
panic(err)
}
return appender(app, opts.limit)
},
cache,
jitterSeed,
opts.honorTimestamps,
)
}
return sp, nil
}
group转化为target
scrape pool创建完成后,则通过sp.Sync执行,使用该job对应的pool遍历Group,使其转换为target
go func(sp *scrapePool, groups []*targetgroup.Group) {
sp.Sync(groups)
wg.Done()
}(m.scrapePools[setName], groups)
Sync函数解读如下:
func (sp *scrapePool) Sync(tgs []*targetgroup.Group) {
start := time.Now()
var all []*Target
// 加锁
sp.mtx.Lock()
sp.droppedTargets = []*Target{}
// 遍历所有Group
for _, tg := range tgs {
// 转化对应 targets
targets, err := targetsFromGroup(tg, sp.config)
if err != nil {
level.Error(sp.logger).Log("msg", "creating targets failed", "err", err)
continue
}
// 将所有有效targets添加到all,等待处理
for _, t := range targets {
// 检查该target的lable是否有效
if t.Labels().Len() > 0 {
// 添加到all队列中
all = append(all, t)
} else if t.DiscoveredLabels().Len() > 0 {
// 记录无效target
sp.droppedTargets = append(sp.droppedTargets, t)
}
}
}
// 解锁
sp.mtx.Unlock()
// 处理all队列,执行scarape同步操作
sp.sync(all)
targetSyncIntervalLength.WithLabelValues(sp.config.JobName).Observe(
time.Since(start).Seconds(),
)
targetScrapePoolSyncsCounter.WithLabelValues(sp.config.JobName).Inc()
}
生成loop
在sync最后,调用了当前scrape pool的sync去处理all队列中的target,添加新的target,删除失效的target。实现如下:
func (sp *scrapePool) sync(targets []*Target) {
// 加锁
sp.mtx.Lock()
defer sp.mtx.Unlock()
var (
// target 标记
uniqueTargets = map[uint64]struct{}{}
// 采集周期
interval = time.Duration(sp.config.ScrapeInterval)
// 采集超时时间
timeout = time.Duration(sp.config.ScrapeTimeout)
limit = int(sp.config.SampleLimit)
// 重复lable是否覆盖
honorLabels = sp.config.HonorLabels
honorTimestamps = sp.config.HonorTimestamps
mrc = sp.config.MetricRelabelConfigs
)
// 遍历all队列中的所有target
for _, t := range targets {
// 赋值,避免range的坑
t := t
// 生成对应的hash(对该hash算法感兴趣可以看下这里的源码)
hash := t.hash()
// 标记
uniqueTargets[hash] = struct{}{}
// 判断该taget是否已经在运行了。如果没有则运行该target对应的loop,将该loop加入activeTargets中
if _, ok := sp.activeTargets[hash]; !ok {
s := &targetScraper{Target: t, client: sp.client, timeout: timeout}
l := sp.newLoop(scrapeLoopOptions{
target: t,
scraper: s,
limit: limit,
honorLabels: honorLabels,
honorTimestamps: honorTimestamps,
mrc: mrc,
})
sp.activeTargets[hash] = t
sp.loops[hash] = l
// 启动该loop
go l.run(interval, timeout, nil)
} else {
// 该target对应的loop已经运行,设置最新的标签信息
sp.activeTargets[hash].SetDiscoveredLabels(t.DiscoveredLabels())
}
}
var wg sync.WaitGroup
// 停止并且移除无效的targets与对应的loops
// 遍历activeTargets正在执行的Target
for hash := range sp.activeTargets {
// 检查该hash对应的标记是否存在,放过不存在执行清除逻辑
if _, ok := uniqueTargets[hash]; !ok {
wg.Add(1)
// 异步清除
go func(l loop) {
// 停止该loop
l.stop()
// 执行完成
wg.Done()
}(sp.loops[hash])
// 从loops中删除该hash对应的loop
delete(sp.loops, hash)
// 从activeTargets中删除该hash对应的target
delete(sp.activeTargets, hash)
}
}
// 等待所有执行完成
wg.Wait()
}
运行loop
scrape pool对应的sync的实现中可以看到,如果该target没有运行,则启动该target对应的loop,执行l.run,通过一个goroutine来执行
func (sl *scrapeLoop) run(interval, timeout time.Duration, errc chan<- error) {
// 偏移量相关设置
select {
case <-time.After(sl.scraper.offset(interval, sl.jitterSeed)):
// Continue after a scraping offset.
case <-sl.scrapeCtx.Done():
close(sl.stopped)
return
}
var last time.Time
// 根据interval设置定时器
ticker := time.NewTicker(interval)
defer ticker.Stop()
mainLoop:
for {
select {
case <-sl.ctx.Done():
close(sl.stopped)
return
case <-sl.scrapeCtx.Done():
break mainLoop
default:
}
var (
start = time.Now()
scrapeCtx, cancel = context.WithTimeout(sl.ctx, timeout)
)
// 记录第一次
if !last.IsZero() {
targetIntervalLength.WithLabelValues(interval.String()).Observe(
time.Since(last).Seconds(),
)
}
// 根据上次拉取数据的大小,设置buffer空间
b := sl.buffers.Get(sl.lastScrapeSize).([]byte)
buf := bytes.NewBuffer(b)
// 读取数据,设置到buffer中
contentType, scrapeErr := sl.scraper.scrape(scrapeCtx, buf)
// 取消,结束scrape
cancel()
if scrapeErr == nil {
b = buf.Bytes()
if len(b) > 0 {
// 记录本次Scrape大小
sl.lastScrapeSize = len(b)
}
} else {
// 错误处理
level.Debug(sl.l).Log("msg", "Scrape failed", "err", scrapeErr.Error())
if errc != nil {
errc <- scrapeErr
}
}
// 生成数据,存储指标
total, added, seriesAdded, appErr := sl.append(b, contentType, start)
if appErr != nil {
level.Warn(sl.l).Log("msg", "append failed", "err", appErr)
if _, _, _, err := sl.append([]byte{}, "", start); err != nil {
level.Warn(sl.l).Log("msg", "append failed", "err", err)
}
}
// 对象复用
sl.buffers.Put(b)
if scrapeErr == nil {
scrapeErr = appErr
}
// 上报指标,进行统计
if err := sl.report(start, time.Since(start), total, added, seriesAdded, scrapeErr); err != nil {
level.Warn(sl.l).Log("msg", "appending scrape report failed", "err", err)
}
// 重置时间位置
last = start
select {
case <-sl.ctx.Done():
close(sl.stopped)
return
case <-sl.scrapeCtx.Done():
break mainLoop
case <-ticker.C:
}
}
close(sl.stopped)
sl.endOfRunStaleness(last, ticker, interval)
}
拉取数据
依赖scrape实现数据的抓取,使用GET方法。
func (s *targetScraper) scrape(ctx context.Context, w io.Writer) (string, error) {
if s.req == nil {
// 新建Http Request
req, err := http.NewRequest("GET", s.URL().String(), nil)
if err != nil {
return "", err
}
// 设置请求头
req.Header.Add("Accept", acceptHeader)
req.Header.Add("Accept-Encoding", "gzip")
req.Header.Set("User-Agent", userAgentHeader)
req.Header.Set("X-Prometheus-Scrape-Timeout-Seconds", fmt.Sprintf("%f", s.timeout.Seconds()))
s.req = req
}
// 发起请求
resp, err := s.client.Do(s.req.WithContext(ctx))
if err != nil {
return "", err
}
defer func() {
io.Copy(ioutil.Discard, resp.Body)
resp.Body.Close()
}()
// 错误处理
if resp.StatusCode != http.StatusOK {
return "", errors.Errorf("server returned HTTP status %s", resp.Status)
}
// 检查Content-Encoding
if resp.Header.Get("Content-Encoding") != "gzip" {
// copy buffer到w
_, err = io.Copy(w, resp.Body)
if err != nil {
return "", err
}
return resp.Header.Get("Content-Type"), nil
}
if s.gzipr == nil {
s.buf = bufio.NewReader(resp.Body)
s.gzipr, err = gzip.NewReader(s.buf)
if err != nil {
return "", err
}
} else {
s.buf.Reset(resp.Body)
if err = s.gzipr.Reset(s.buf); err != nil {
return "", err
}
}
_, err = io.Copy(w, s.gzipr)
s.gzipr.Close()
if err != nil {
return "", err
}
return resp.Header.Get("Content-Type"), nil
}
总结
每一个job有一个与之对应的scrape pool,每一个target有一个与之对应的loop,每个loop内部执 Http Get请求拉取数据。通过一些控制参数,控制采集周期以及结束等逻辑。
数据规范
数据模型
Prometheus与其他主流时序数据库一样,在数据模型定义上,也会包含metric name、一个或多个labels(同tags)以及metric value
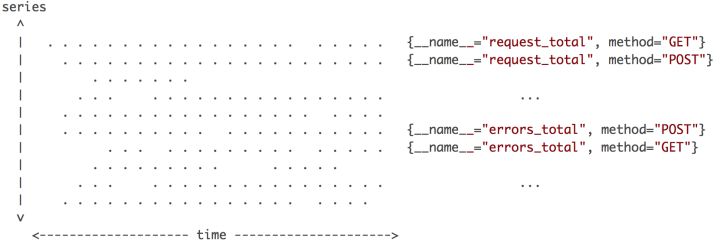
上图是所有数据点分布的一个简单视图,横轴是时间,纵轴是时间线,区域内每个点就是数据点。Prometheus每次接收数据,收到的是图中区域内纵向的一条线。这个表述很形象,在同一时刻,每条时间线只会产生一个数据点,但同时会有多条时间线产生数据,把这些数据点连在一起,就是一条竖线。这个特征很重要,影响数据写入和压缩的优化策略。
探针数据
都体现在client_golang的库中,直接去client_golang文章中参考。
PromQL
PromQL 是 Prom 中的查询语言,提供了简洁的、贴近自然语言的语法实现时序数据的分析计算。
原理
PromQL 表达式输入是一段文本,Prom 会解析这段文本,将它转化为一个结构化的语法树对象,进而实现相应的数据计算逻辑。
sum(avg_over_time(go_goroutines{job="prometheus"}[5m])) by (instance)
上述表达式可以从外往内分解为三层:
sum(…) by (instance):序列纵向分组合并序列(包含相同的 instance 会分配到一组)
avg_over_time(…)
go_goroutines{job="prometheus"}[5m]
- 时间点对象MatrixSelector 对象,是获取时序数据的基础结构
- 获取时间段里面的数据,通过iterator 是序列筛选结果的顺序访问接口,获取某个时间点往前的一段历史数据,这是一个二维矩阵 (matrix),进而由外层函数将这段历史数据汇总成一个 vector
- 实现对一段数据的汇总,然后求平均值
- 最后来看关键字(keyword)sum 的实现,这里注意 sum 不是函数(Function)而是关键字。
sum(avg_over_time(go_goroutines{job=“prometheus”}[5m])) by (instance) 计算过程
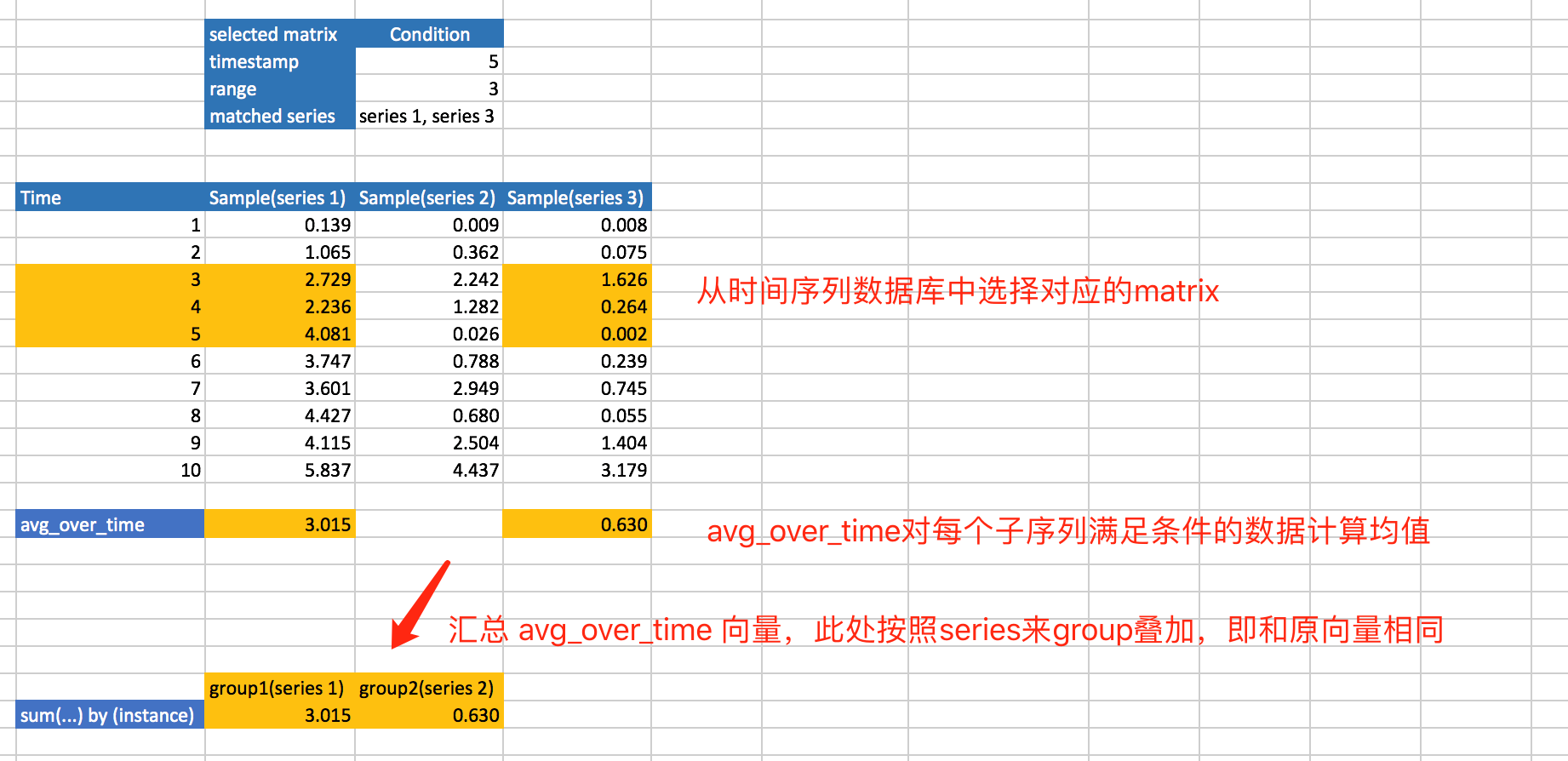
PromQL 有三个很简单的原则:
- 任意 PromQL 返回的结果都不是原始数据,即使查询一个具体的 Metric(如 go_goroutines),结果也不是原始数据
- 任意 Metrics 经过 Function 计算后会丢失
__name__Label - 子序列间具备完全相同的 Label/Value 键值对(可以有不同的
__name__)才能进行代数运算
storage
源码解读
真正存储指标的是storage.Appender,在scrape与storage之间有一层缓存。缓存主要的作用是过滤错误的指标。
type scrapeCache struct {
iter uint64 // scrape批次
successfulCount int // 成功保存的元数据数
series map[string]*cacheEntry // 缓存解析的相关数据
droppedSeries map[string]*uint64 // 缓存无效指标
seriesCur map[uint64]labels.Labels // 本次采集指标
seriesPrev map[uint64]labels.Labels // 上次采集指标
metaMtx sync.Mutex
metadata map[string]*metaEntry
}
创建scrapeCache,调用newScrapeLoop,初始化scrapeLoop,会判断scrapeCache是否为空,如果为nil,调用newScrapeCache对cache进行初始化。
if cache == nil {
cache = newScrapeCache()
}
newScrapeCache()如下:
func newScrapeCache() *scrapeCache {
return &scrapeCache{
series: map[string]*cacheEntry{},
droppedSeries: map[string]*uint64{},
seriesCur: map[uint64]labels.Labels{},
seriesPrev: map[uint64]labels.Labels{},
metadata: map[string]*metaEntry{},
}
}
scrapeCache 方法介绍,这里简介各个fun的作用,详细代码不做注解。
// 根据met信息,获取对应的cacheEntry
func (c *scrapeCache) get(met string) (*cacheEntry, bool)
// 根据met创建cacheEntry节点
func (c *scrapeCache) addRef(met string, ref uint64, lset labels.Labels, hash uint64)
// 添加无效指标,met作为key
func (c *scrapeCache) addDropped(met string)
// 根据met,检查该指标是否有效
func (c *scrapeCache) getDropped(met string) bool
// 添加当前采集指标
func (c *scrapeCache) trackStaleness(hash uint64, lset labels.Labels)
// 检查指标状态
func (c *scrapeCache) forEachStale(f func(labels.Labels) bool)
// 缓存清理
func (c *scrapeCache) iterDone(flushCache bool)
存储过程
分析scrapeLoop.append是如何实现存储数据的。
func (sl *scrapeLoop) append(b []byte, contentType string, ts time.Time) (total, added, seriesAdded int, err error) {
var (
// 获取指标存储组件
app = sl.appender()
// 获取解析组件
p = textparse.New(b, contentType)
defTime = timestamp.FromTime(ts)
numOutOfOrder = 0
numDuplicates = 0
numOutOfBounds = 0
)
var sampleLimitErr error
loop:
for {
var et textparse.Entry
// 开始遍历,遍历到EOF(字节流尾部),终止遍历
if et, err = p.Next(); err != nil {
if err == io.EOF {
err = nil
}
break
}
// 以下Entry类型跳过
switch et {
case textparse.EntryType:
sl.cache.setType(p.Type())
continue
case textparse.EntryHelp:
sl.cache.setHelp(p.Help())
continue
case textparse.EntryUnit:
sl.cache.setUnit(p.Unit())
continue
case textparse.EntryComment:
continue
default:
}
total++
t := defTime
// 获取指标label,时间戳(如果设置了),当前样本值
met, tp, v := p.Series()
// 如果设置了honorTimestamps,时间戳设置为nil
if !sl.honorTimestamps {
tp = nil
}
// 如果时间戳不为空,更新当前t
if tp != nil {
t = *tp
}
// 检查该指标值是否有效,无效则直接跳过当前处理
if sl.cache.getDropped(yoloString(met)) {
continue
}
// 根据当前met获取对应的cacheEntry结构
ce, ok := sl.cache.get(yoloString(met))
// 如果从缓存中获取,则执行指标的存储操作
if ok {
// 指标存储
switch err = app.AddFast(ce.lset, ce.ref, t, v); err {
case nil:
// 如果不带时间戳
if tp == nil {
// 存储该不带时间戳的指标到seriesCur中。
sl.cache.trackStaleness(ce.hash, ce.lset)
}
// 未找到错误,重置ok为false,执行!ok逻辑
case storage.ErrNotFound:
ok = false
// 乱序样本
case storage.ErrOutOfOrderSample:
// 乱序样本错误记录,并上报
numOutOfOrder++
level.Debug(sl.l).Log("msg", "Out of order sample", "series", string(met))
targetScrapeSampleOutOfOrder.Inc()
continue
// 重复样本
case storage.ErrDuplicateSampleForTimestamp:
// 重复样本错误记录,并上报
numDuplicates++
level.Debug(sl.l).Log("msg", "Duplicate sample for timestamp", "series", string(met))
targetScrapeSampleDuplicate.Inc()
continue
// 存储越界
case storage.ErrOutOfBounds:
// 存储越界错误记录,并上报
numOutOfBounds++
level.Debug(sl.l).Log("msg", "Out of bounds metric", "series", string(met))
targetScrapeSampleOutOfBounds.Inc()
continue
// 超出样本限制错误
case errSampleLimit:
// 如果我们达到上限也要继续解析输出,所以我们要上报正确的样本总量
sampleLimitErr = err
added++
continue
// 未知情况,终止loop
default:
break loop
}
}
// 在缓存中未查找到,
if !ok {
var lset labels.Labels
// 生成mets
mets := p.Metric(&lset)
// 生成hash值
hash := lset.Hash()
// 根据配置重置label set
lset = sl.sampleMutator(lset)
// 如果label set为空,则表明该mets为非法指标
if lset == nil {
// 添加mets到无效指标字典中
sl.cache.addDropped(mets)
continue
}
var ref uint64
// 存储指标
ref, err = app.Add(lset, t, v)
// 错误处理同上,不重复描述
switch err {
case nil:
// 乱序样本
case storage.ErrOutOfOrderSample:
err = nil
numOutOfOrder++
level.Debug(sl.l).Log("msg", "Out of order sample", "series", string(met))
targetScrapeSampleOutOfOrder.Inc()
continue
// 重复样本
case storage.ErrDuplicateSampleForTimestamp:
err = nil
numDuplicates++
level.Debug(sl.l).Log("msg", "Duplicate sample for timestamp", "series", string(met))
targetScrapeSampleDuplicate.Inc()
continue
// 存储越界
case storage.ErrOutOfBounds:
err = nil
numOutOfBounds++
level.Debug(sl.l).Log("msg", "Out of bounds metric", "series", string(met))
targetScrapeSampleOutOfBounds.Inc()
continue
// 样本限制
case errSampleLimit:
sampleLimitErr = err
added++
continue
default:
level.Debug(sl.l).Log("msg", "unexpected error", "series", string(met), "err", err)
break loop
}
if tp == nil {
// 存储该不带时间戳的指标到seriesCur中。
sl.cache.trackStaleness(hash, lset)
}
// 缓存该指标到series中
sl.cache.addRef(mets, ref, lset, hash)
seriesAdded++
}
added++
}
// 错误相关处理,不做分析。
if sampleLimitErr != nil {
if err == nil {
err = sampleLimitErr
}
targetScrapeSampleLimit.Inc()
}
if numOutOfOrder > 0 {
level.Warn(sl.l).Log("msg", "Error on ingesting out-of-order samples", "num_dropped", numOutOfOrder)
}
if numDuplicates > 0 {
level.Warn(sl.l).Log("msg", "Error on ingesting samples with different value but same timestamp", "num_dropped", numDuplicates)
}
if numOutOfBounds > 0 {
level.Warn(sl.l).Log("msg", "Error on ingesting samples that are too old or are too far into the future", "num_dropped", numOutOfBounds)
}
if err == nil {
// 指标状态检查。
sl.cache.forEachStale(func(lset labels.Labels) bool {
// 标记存储中的过期指标
_, err = app.Add(lset, defTime, math.Float64frombits(value.StaleNaN))
switch err {
// 以下错误不做处理
case storage.ErrOutOfOrderSample, storage.ErrDuplicateSampleForTimestamp:
err = nil
}
return err == nil
})
}
if err != nil {
// 出现错误,存储组件进行回滚
app.Rollback()
return total, added, seriesAdded, err
}
// 存储提交
if err := app.Commit(); err != nil {
return total, added, seriesAdded, err
}
// 执行缓存清理相关工作
sl.cache.iterDone(len(b) > 0)
return total, added, seriesAdded, nil
}
总结
整个存储逻辑都围绕着过滤无效指标进行。特殊点在于存储的时候指标分为有时间戳与无时间戳两种情况。
1、有时间戳
- 解析指标数据通过Series()
- 利用getDropped判断指标是否有效,无效则跳出处理
- 通过get查找对应cacheEntry,如果找到利用app.AddFast直接存储样本值。如果未找到,使用sampleMutator进行解析重置,判断lset是否为空,为空则使用addDropped添加到无效字典中,跳出当前处理,如果有效则使用app.Add存储指标。(可以看到,通过get找到使用AddFast存储,未找到使用Add存储,感兴趣可以看下两个fun实现的区别)
- 通过forEachStale检查指标是否过期。
- app.Add标记过期指标
- 调用iterDone进行相关缓存清理。
2、无时间戳
每次存储后,如果不带时间戳都会调用trackStaleness,存储指标到seriesCur中
这里seriesCur与seriesPrev的作用就是处理指标label是否过期的。forEachStale实现如下:
func (c *scrapeCache) forEachStale(f func(labels.Labels) bool) {
for h, lset := range c.seriesPrev {
if _, ok := c.seriesCur[h]; !ok {
if !f(lset) {
break
}
}
}
}
如果seriesPrev中的指标(label)存在于seriesPrev,则不处理,如果不存在,则说明过期。其中在iterDone中。
// 交换seriesPrev与seriesCur
c.seriesPrev, c.seriesCur = c.seriesCur, c.seriesPrev
// 清空当前指标缓存列表
for k := range c.seriesCur {
delete(c.seriesCur, k)
}
所以,每次存储处理后,都会交换seriesPrev与seriesCur,然后清空seriesCur。下次存储在做比较。如果命中过期规则,则标记该样本值为StaleNaN。
local storage
v2
Prometheus 1.0版本的TSDB(V2存储引擎)使用了G家的LevelDB来做索引(PromSQL重度依赖LevelDB),并且使用了和Facebook Gorilla一样的压缩算法,能够将16个字节的数据点压缩到平均1.37个字节。
V2存储引擎对于大量的采样数据有自己的存储层,Prometheus为每个时序数据创建一个本地文件,以1024byte大小的chunk来组织。写到head chunk,写满1KB,就再生成新的块,完成的块,是不可再变更的 , 根据配置文件的设置,有一部份chunk会被保留在内存里,按照LRU算法,定期将块写进磁盘文件内。
缺陷
- 文件数会随着时间线的数量同比增长,慢慢会耗尽inode。
- 即便使用了Chunk写优化,若一次写入涉及的时间线过多,IOPS要求还是会很高。
- 每个文件不可能会时刻保持open状态,一次查询可能需要重新打开大量文件,增大查询延迟。
- 数据回收需要从大量文件扫描和重写数据,耗时较长。
- 数据需要在内存中积累一定时间以Chunk写,V2会采用定时写Checkpoint的机制来尽量保证内存中数据不丢失。但通常记录Checkpoint的时间大于能承受的数据丢失的时间窗口,并且在节点恢复时从checkpoint restore数据的时间也会很长。
优化策略
Chunk写,热数据内存缓存
Prometheus一次性接收到的数据是一条竖线,包含很多的数据点,但是这些数据点属于不同的时间线。而当前的设计是一条时间线对应一个独立的文件,所以每次写入都会需要向很多不同的文件写入极少量的数据。针对这个问题,V2存储引擎的优化策略是Chunk写,针对单个时间线的写入必须是批量写,那就需要数据在时间线维度累积一定时间后才能凑到一定量的数据点。Chunk写策略带来的好处除了批量写外,还能优化热数据查询效率以及数据压缩率。V2存储引擎使用了和Facebook Gorilla一样的压缩算法,能够将16个字节的数据点压缩到平均1.37个字节,节省12倍内存和空间。Chunk写就要求数据一定要在服务器内存里积累一定的时间,即热数据基本都在内存中,查询效率很高。
v3
Prometheus 2.0版本引入了全新的V3存储引擎,提供了更高的写入和查询性能。
V3引擎完全重新设计,但是也延续了v2的一些优化策略,也来解决V2引擎中存在的这些问题。V3引擎可以看做是一个简单版、针对时序数据场景优化过后的LSM,可以带着LSM的设计思想来理解,先看一下V3引擎中数据的文件目录结构。

data目录下存放所有的数据,data目录的下一级目录是以’b-‘为前缀,顺序自增的ID为后缀的目录,代表Block。每个Block下有chunks、index和meta.json,chunks目录下存放chunk的数据。这个chunk和V2的chunk是一个概念,唯一的不同是一个chunk内会包含很多的时间线,而不再只是一条。index是这个block下对chunk的索引,可以支持根据某个label快速定位到时间线以及数据所在的chunk。meta.json是一个简单的关于block数据和状态的一个描述文件。要理解V3引擎的设计思想,只需要搞明白几个问题:
- chunk文件的存储格式?
- index的存储格式,如何实现快速查找?
- 为何最后一个block没有chunk目录但有一个wal目录?
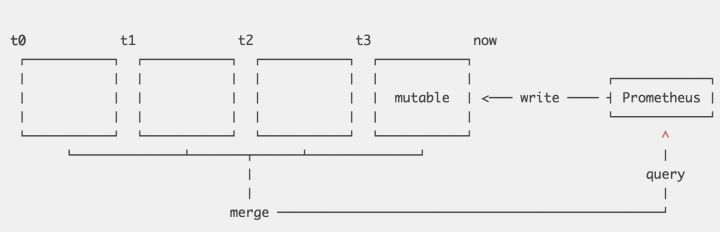
Prometheus将数据按时间维度切分为多个block,每个block被认为是独立的一个数据库,覆盖不同的时间范围的数据,完全没有交叉。每个Block下chunk内的数据dump到文件后即不可再修改,只有最近的一个block允许接收新数据。最新的block内数据写入会先写到一个内存的结构,为了保证数据不丢失,会先写一份WAL(write ahead log)。
V3完全借鉴了LSM的设计思想,针对时序数据特征做了一些优化,带来很多好处:
- 当查询一个时间范围的数据时,可快速排除无关的block。每个block有独立的index,能够有效解决V2内遇到的『无效时间线 Series Churn』的问题。
- 内存数据dump到chunk file,可高效采用大块数据顺序写,对SSD和HDD都很友好。
- 和V2一样,最近的数据在内存内,最近的数据也是最热的数据,在内存可支持最高效的查询。
- 老数据的回收变得非常简单和高效,只需要删除少量目录。
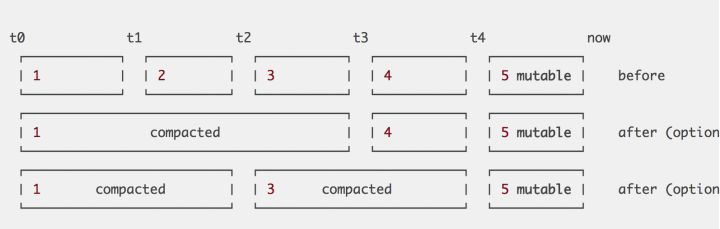
V3内block以两个小时的跨度来切割,这个时间跨度不能太大,也不能太小。太大的话若内存中要保留两个小时数据,则内存占用会比较大。太小的话会导致太多的block,查询时需要对更多的文件做查询。所以两个小时是一个综合考虑后决定的值,但是当查询大跨度时间范围时,仍不可避免需要跨多个文件,例如查询一周时间跨度需要84个文件。V3也是采用了LSM一样的compaction策略来做查询优化,把小的block合并为大的block,compaction期间也可做其他一些事,例如删除过期数据或重构chunk数据以支持更高效的查询。InfluxDB也有多种不同的compaction策略,在不同的时刻使用。
prometheus重2.0版本开始使用了V3引擎,V3没有和V2一样采用LevelDB,在已经持久化的Block,Index已经固定下来,不可修改。而对于最新的还在写数据的block,V3则会把所有的索引全部hold在内存,维护一个内存结构,等到这个block被关闭,再持久化到文件。这样做会比较简单一点,内存里维护时间线到ID的映射以及label到ID列表的映射,查询效率会很高。而且Prometheus对Label的基数会有一个假设:『a real-world dataset of ~4.4 million series with about 12 labels each has less than 5,000 unique labels』,这个全部保存在内存也是一个很小的量级,完全没有问题。InfluxDB采用的是类似的策略,而其他一些TSDB则直接使用ElasticSearch作为索引引擎。
针对时序数据这种写多读少的场景,类LSM的存储引擎还是有不少优势的。有些TSDB直接基于开源的LSM引擎分布式数据库例如Hbase或Cassandra,也有自己基于LevelDB/RocksDB研发,或者再像InfluxDB和Prometheus一样纯自研,因为时序数据这一特定场景还是可以做更多的优化,例如索引、compaction策略等。Prometheus V3引擎的设计思想和InfluxDB真的很像,优化思路高度一致,后续在有新的需求的出现后,会有更多变化。
总结
Prometheus将Timeseries数据按2小时一个block进行存储。每个block由一个目录组成,该目录里包含:一个或者多个chunk文件(保存timeseries数据)、一个metadata文件、一个index文件(通过metric name和labels查找timeseries数据在chunk文件的位置)。最新写入的数据保存在内存block中,达到2小时后写入磁盘。为了防止程序崩溃导致数据丢失,实现了WAL(write-ahead-log)机制,将timeseries原始数据追加写入log中进行持久化。删除timeseries时,删除条目会记录在独立的tombstone文件中,而不是立即从chunk文件删除。启动时会以写入日志(WAL)的方式来实现重播,从而恢复数据。
这些2小时的block会在后台压缩成更大的block,数据压缩合并成更高level的block文件后删除低level的block文件。这个和leveldb、rocksdb等LSM树的思路一致。
这些设计和Gorilla的设计高度相似,所以Prometheus几乎就是等于一个缓存TSDB。它本地存储的特点决定了它不能用于long-term数据存储,只能用于短期窗口的timeseries数据保存和查询,并且不具有高可用性(宕机会导致历史数据无法读取)。
具体形式
1、磁盘文件结构
内存中的block
内存中的block数据未刷盘时,block目录下面主要保存wal文件。
./data/01BKGV7JBM69T2G1BGBGM6KB12
./data/01BKGV7JBM69T2G1BGBGM6KB12/meta.json
./data/01BKGV7JBM69T2G1BGBGM6KB12/wal/000002
./data/01BKGV7JBM69T2G1BGBGM6KB12/wal/000001
持久化的block
持久化的block目录下wal文件被删除,timeseries数据保存在chunk文件里。index用于索引timeseries在wal文件里的位置。
./data/01BKGV7JC0RY8A6MACW02A2PJD
./data/01BKGV7JC0RY8A6MACW02A2PJD/meta.json
./data/01BKGV7JC0RY8A6MACW02A2PJD/index
./data/01BKGV7JC0RY8A6MACW02A2PJD/chunks
./data/01BKGV7JC0RY8A6MACW02A2PJD/chunks/000001
./data/01BKGV7JC0RY8A6MACW02A2PJD/tombstones
2、mmap
使用mmap读取压缩合并后的大文件(不占用太多句柄),建立进程虚拟地址和文件偏移的映射关系,只有在查询读取对应的位置时才将数据真正读到物理内存。绕过文件系统page cache,减少了一次数据拷贝。查询结束后,对应内存由Linux系统根据内存压力情况自动进行回收,在回收之前可用于下一次查询命中。因此使用mmap自动管理查询所需的的内存缓存,具有管理简单,处理高效的优势。 从这里也可以看出,它并不是完全基于内存的TSDB,和Gorilla的区别在于查询历史数据需要读取磁盘文件。
3、Compaction
Compaction主要操作包括合并block、删除过期数据、重构chunk数据。其中合并多个block成为更大的block,可以有效减少block个数,当查询覆盖的时间范围较长时,避免需要合并很多block的查询结果。 为提高删除效率,删除时序数据时,会记录删除的位置,只有block所有数据都需要删除时,才将block整个目录删除。因此block合并的大小也需要进行限制,避免保留了过多已删除空间(额外的空间占用)。比较好的方法是根据数据保留时长,按百分比(如10%)计算block的最大时长。
4、Inverted Index
Inverted Index(倒排索引)基于其内容的子集提供数据项的快速查找。简而言之,我可以查看所有标签为app=“nginx”的数据,而不必遍历每一个timeseries,并检查是否包含该标签。 为此,每个时间序列key被分配一个唯一的ID,通过它可以在恒定的时间内检索,在这种情况下,ID就是正向索引。 举个栗子:如ID为9,10,29的series包含label app=“nginx”,则lable “nginx”的倒排索引为[9,10,29]用于快速查询包含该label的series。
5、存储配置
对于本地存储,prometheus提供了一些配置项,主要包括:
--storage.tsdb.path: 存储数据的目录,默认为data/,如果要挂外部存储,可以指定该目录
--storage.tsdb.retention.time: 数据过期清理时间,默认保存15天
--storage.tsdb.retention.size: 实验性质,声明数据块的最大值,不包括wal文件,如512MB
--storage.tsdb.retention: 已被废弃,改为使用storage.tsdb.retention.time
Prometheus将所有当前使用的块保留在内存中。此外,它将最新使用的块保留在内存中,最大内存可以通过storage.local.memory-chunks标志配置。
监测当前使用的内存量:
prometheus_local_storage_memory_chunks
process_resident_memory_bytes
监测当前使用的存储指标:
prometheus_local_storage_memory_series: 时间序列持有的内存当前块数量
prometheus_local_storage_memory_chunks: 在内存中持久块的当前数量
prometheus_local_storage_chunks_to_persist: 当前仍然需要持久化到磁盘的的内存块数量
prometheus_local_storage_persistence_urgency_score: 紧急程度分数
6、性能
在文章Writing a Time Series Database from Scratch里,作者给出了benchmark测试结果为Macbook Pro上写入达到2000万每秒。这个数据比Gorilla论文中的目标7亿次写入每分钟(1000千多万每秒)提供了更高的单机性能。
remote storage
Prometheus 的设计者非常看重监控系统自身的稳定性,所以 Prometheus 仅仅依赖了本地文件系统,而这就决定了 Prometheus 自身并不适合存储长期数据。本地存储的优势就是运维简单,缺点就是无法海量的metrics持久化和数据存在丢失的风险,我们在实际使用过程中,出现过几次wal文件损坏,无法再写入的问题。
所以 Prometheus 提供了 remote read 和 remote write 的接口,让用户自己去实现对接,prometheus以两种方式与远程存储系统集成:
- Prometheus可以以标准格式将其提取的样本写入远程URL。
- Prometheus可以以标准格式从远程URL读取(返回)样本数据。

Adapter 是一个中间组件,Prometheus 与 Adapter 之间通过由 Prometheus 定义的标准格式发送和接收数据,Adapter 与外部存储系统之间的通信可以自定义,目前 Prometheus 和 Adapter 之间通过 grpc 通信。Prometheus 将 samples 发送到 Adapter。为了提高效率,samples 会在队列中先缓存,再打包发送给 Adapter,所以一个读请求中包含了 start_timestamp,end_timestamp 和 label_matchers,response 则包含所有 match 到的 time series,也就是说,Prometheus 仅通过 Adapter 来获取时间序列,进一步的处理都在 Prometheus 中完成。
remote read 和 remote write 的配置还没有稳定,我们从代码中来一探究竟,HTTPClientConfig 可以用来配置 HTTP 相关的 auth 信息,proxy 方式,以及 tls。WriteRelabelConfigs 用在发送过程中对 timeseries 进行 relabel。QueueConfig 定义了发送队列的 batch size,queue 数量,发送失败时的重试次数与等待时间等参数。
write
Prometheus 默认定义了 1000 个 queue,batch size 为 100,预期可以达到 1M samples/s 的发送速率。Prometheus 输出了一些 queue 相关的指标,例如 failed_samples_total, dropped_samples_total,如果这两个指标的 rate 大于 0,就需要说明 Remote Storage 出现了问题导致发送失败,或者队列满了导致 samples 被丢弃掉。
read
ReadRecent 如果为 false,Prometheus 会在处理查询时比较本地存储中最早的数据的 timestamp 与 query 的 start timestamp,如果发现需要的数据都在本地存储中,则会跳过对 Remote Storage 的查询。
社区中支持prometheus远程读写的方案
AppOptics: write
Chronix: write
Cortex: read and write
CrateDB: read and write
Elasticsearch: write
Gnocchi: write
Graphite: write
InfluxDB: read and write
OpenTSDB: write
PostgreSQL/TimescaleDB: read and write
SignalFx: write
clickhouse: read and write
目前远程存储使用最多的是influxdb(收费),opentsdb(依赖hbase),m3db(不稳定),VM(很优秀的存储查询性能)。
服务发现
Prometheus目前支持以下平台的动态发现能力:
- 容器编排系统:kubernetes
- 云平台:EC2、Azure、OpenStack
- 服务发现:DNS、Zookeeper、Consul 等。
加载配置 ServiceDiscoveryConfig配置结构如下:
type ServiceDiscoveryConfig struct {
// 静态服务发现配置
StaticConfigs []*targetgroup.Group `yaml:"static_configs,omitempty"`
// DNS服务发现配置
DNSSDConfigs []*dns.SDConfig `yaml:"dns_sd_configs,omitempty"`
// 配置文件服务发现配置
FileSDConfigs []*file.SDConfig `yaml:"file_sd_configs,omitempty"`
// Consul服务发现配置
ConsulSDConfigs []*consul.SDConfig `yaml:"consul_sd_configs,omitempty"`
// zookeeper Serverset 服务发现配置
ServersetSDConfigs []*zookeeper.ServersetSDConfig `yaml:"serverset_sd_configs,omitempty"`
// zookeeper Nerve 服务发现配置
NerveSDConfigs []*zookeeper.NerveSDConfig `yaml:"nerve_sd_configs,omitempty"`
// 根据Marathon API 服务发现配置
MarathonSDConfigs []*marathon.SDConfig `yaml:"marathon_sd_configs,omitempty"`
// 根据Kubernetes API 服务发现配置
KubernetesSDConfigs []*kubernetes.SDConfig `yaml:"kubernetes_sd_configs,omitempty"`
// GCE 服务发现配置
GCESDConfigs []*gce.SDConfig `yaml:"gce_sd_configs,omitempty"`
// EC2服务发现配置
EC2SDConfigs []*ec2.SDConfig `yaml:"ec2_sd_configs,omitempty"`
// Openstack 服务发现配置
OpenstackSDConfigs []*openstack.SDConfig `yaml:"openstack_sd_configs,omitempty"`
// Azure 服务发现配置
AzureSDConfigs []*azure.SDConfig `yaml:"azure_sd_configs,omitempty"`
// Triton 服务发现配置
TritonSDConfigs []*triton.SDConfig `yaml:"triton_sd_configs,omitempty"`
}
在Prometheus初始化过程中,通过执行discoveryManagerScrape.ApplyConfig进行服务发现相关配置的加载。
移除目前正在运行的providers,根据新的provided 配置,启动新的providers。。
func (m *Manager) ApplyConfig(cfg map[string]sd_config.ServiceDiscoveryConfig) error {
// 加锁
m.mtx.Lock()
// 函数结束后 解锁
defer m.mtx.Unlock()
// 遍历已存在target
for pk := range m.targets {
if _, ok := cfg[pk.setName]; !ok {
// 删除标签
discoveredTargets.DeleteLabelValues(m.name, pk.setName)
}
}
// 取消所有Discoverer
m.cancelDiscoverers()
for name, scfg := range cfg {
// 根据scfg,注册服务发现实例
m.registerProviders(scfg, name)
// 设置标签
discoveredTargets.WithLabelValues(m.name, name).Set(0)
}
for _, prov := range m.providers {
// 启动服务发现实例
m.startProvider(m.ctx, prov)
}
return nil
}
注册Providers
其中m.registerProviders的主要作用就是根据cfg(配置)注册所有provider实例,保存在m.providers
func (m *Manager) registerProviders(cfg sd_config.ServiceDiscoveryConfig, setName string) {
// 标签
var added bool
// 加载Providers的add方法
add := func(cfg interface{}, newDiscoverer func() (Discoverer, error)) {
// 读取cfg类型
t := reflect.TypeOf(cfg).String()
for _, p := range m.providers {
// 检查该cfg是否加载过
if reflect.DeepEqual(cfg, p.config) {
// 如果加载过,记录该job
p.subs = append(p.subs, setName)
// 变更标签状态
added = true
// 跳出
return
}
}
// 创建一个Discoverer实例
d, err := newDiscoverer()
if err != nil {
level.Error(m.logger).Log("msg", "Cannot create service discovery", "err", err, "type", t)
failedConfigs.WithLabelValues(m.name).Inc()
return
}
// 创建一个provider
provider := provider{
// 生成provider名称
name: fmt.Sprintf("%s/%d", t, len(m.providers)),
// 关联对应的Discoverer实例(比如DNS、zk等)
d: d,
// 关联配置
config: cfg,
// 关联job
subs: []string{setName},
}
// 添加该provider到m.providers队列中
m.providers = append(m.providers, &provider)
// 更新标签
added = true
}
// 遍历DNS配置,生成该Discoverer
for _, c := range cfg.DNSSDConfigs {
add(c, func() (Discoverer, error) {
return dns.NewDiscovery(*c, log.With(m.logger, "discovery", "dns")), nil
})
}
.
.
.
.
.
.
// 类似配置遍历省略,感兴趣可以阅读源码查看
}
启动Provider
在ApplyConfig,执行m.startProvider(m.ctx, prov)启动provider。
func (m *Manager) startProvider(ctx context.Context, p *provider) {
level.Info(m.logger).Log("msg", "Starting provider", "provider", p.name, "subs", fmt.Sprintf("%v", p.subs))
ctx, cancel := context.WithCancel(ctx)
// 记录发现的服务
updates := make(chan []*targetgroup.Group)
// 添加取消方法
m.discoverCancel = append(m.discoverCancel, cancel)
// 执行run 每个服务发现都有自己的run方法。
go p.d.Run(ctx, updates)
// 更新发现的服务
go m.updater(ctx, p, updates)
}
这里分析DNS 服务发现对应的Run方法。需要标注下,DNS对应的Discovery其实是refresh中的Discovery的Run实现。
d.Discovery = refresh.NewDiscovery(
logger,
"dns",
time.Duration(conf.RefreshInterval),
d.refresh,
)
Run实现如下:
func (d *Discovery) Run(ctx context.Context, ch chan<- []*targetgroup.Group) {
// 首次进入,执行更新
tgs, err := d.refresh(ctx)
if err != nil {
level.Error(d.logger).Log("msg", "Unable to refresh target groups", "err", err.Error())
} else {
select {
case ch <- tgs:
case <-ctx.Done():
return
}
}
// 创建定时器
ticker := time.NewTicker(d.interval)
defer ticker.Stop()
for {
select {
case <-ticker.C:
// 定时执行更新,如果发现变化,通过ch发出更新信息
tgs, err := d.refresh(ctx)
if err != nil {
level.Error(d.logger).Log("msg", "Unable to refresh target groups", "err", err.Error())
continue
}
select {
// 发送 变化的targets
case ch <- tgs:
case <-ctx.Done():
return
}
case <-ctx.Done():
return
}
}
}
更新服务
当服务发现变化的targets时,通过updates chan进行更新。最终更新Discovery Manager的targets。
func (m *Manager) updater(ctx context.Context, p *provider, updates chan []*targetgroup.Group) {
for {
select {
case <-ctx.Done():
return
// 接收updates数据
case tgs, ok := <-updates:
receivedUpdates.WithLabelValues(m.name).Inc()
if !ok {
level.Debug(m.logger).Log("msg", "discoverer channel closed", "provider", p.name)
return
}
// 更新targets
for _, s := range p.subs {
m.updateGroup(poolKey{setName: s, provider: p.name}, tgs)
}
select {
// 发送更新通知
case m.triggerSend <- struct{}{}:
default:
}
}
}
}
启动discovery manager
加载完配置,并且完成注册、启动、更新操作后,开始执行discoveryManagerScrape.Run方法。
func (m *Manager) Run() error {
// 后台处理
go m.sender()
for range m.ctx.Done() {
m.cancelDiscoverers()
return m.ctx.Err()
}
return nil
}
定时执行,当接收到服务发现的更新通知,通过m.allGroups()同步服务快照信息到scrapeManager
func (m *Manager) sender() {
// 创建定时器
ticker := time.NewTicker(m.updatert)
defer ticker.Stop()
for {
select {
case <-m.ctx.Done():
return
case <-ticker.C:
select {
// 检测到更新
case <-m.triggerSend:
sentUpdates.WithLabelValues(m.name).Inc()
select {
// 通过allGroups同步服务快照信息到scrapeManager
case m.syncCh <- m.allGroups():
default:
delayedUpdates.WithLabelValues(m.name).Inc()
level.Debug(m.logger).Log("msg", "discovery receiver's channel was full so will retry the next cycle")
select {
case m.triggerSend <- struct{}{}:
default:
}
}
default:
}
}
}
}
关联ScrapeManager
关联
在ScrapeManager在启动的时候会关联discoveryManagerScrape.SyncCh()。
func() error {
<-reloadReady.C
// 关联 discoveryManagerScrape 的 syncCh
err := scrapeManager.Run(discoveryManagerScrape.SyncCh())
level.Info(logger).Log("msg", "Scrape manager stopped")
return err
},
更新
更新ScrapeManager的targets
func (m *Manager) Run(tsets <-chan map[string][]*targetgroup.Group) error {
go m.reloader()
for {
select {
// 收到更新targets
case ts := <-tsets:
m.updateTsets(ts)
select {
case m.triggerReload <- struct{}{}:
default:
}
case <-m.graceShut:
return nil
}
}
}
执行更新
func (m *Manager) updateTsets(tsets map[string][]*targetgroup.Group) {
m.mtxScrape.Lock()
// 替换新的 tagets
m.targetSets = tsets
m.mtxScrape.Unlock()
}
总结
discoveryManager在加载配置的时候,顺便完成provider的注册、启动、以及discovery的自更新通知操作。discoveryManager与ScrapeManager通过discoveryManager的syncCh通道来关联同步。
整个服务发现的流程很值得学习,尤其是discoveryManager支持多种服务发现的扩展配置的相关设设计很值得学习。
扩展
集群
Prometheus有两个比较著名的扩展版一个是cortex,另一个是thanos。
thanos在github的简介是『Highly available Prometheus setup with long term storage capabilities』,它基于Prometheus的最大改进是底层存储可扩展支持对象存储,例如AWS的S3,使得单机容量可扩展。这个得益于Prometheus 2.0中V3引擎的特性,持久化的Chunk文件是immutable的,所以能够很容易迁移到对象存储上。从它的设计文档里可以看出,它引入了一个Sidecar节点,与Prometheus server结对部署,主要作用将本地数据backup到远端的对象存储。当然数据被切割到本地和对象存储内后,为了支持统一的查询接口,又引入了Store层。Store层支持标准查询接口,屏蔽了底层是对象存储的细节,同时做了一些查询优化例如对Index的缓存。thanos中包含多个类型的节点,包括Prometheus Server、Sidecar、Store node、Rule node、compactor和query layer,其中只有query layer能水平扩展,因为其是无状态的。也就是说,单个实例的Prometheus其写入能力还是会有瓶颈,cotex相比它则在scalability上改进了更多。
cortex在github的简介是『A multitenant, horizontally scalable Prometheus as a Service』,几个关键词:多租户、水平扩展及服务化。
现在还可以使用远程存储聚合的方式来实现集群,比如做的比较好的VM。