VictoriaMetrics是一个高性能的,长期存储的prometheus的远程解决方案,实现集群使用的federation的方式,只不过性能很优秀,包括write和query,聚合数据也解决了查询问题。
优势
VictoriaMetrics不仅仅是时序数据库,它的优势主要体现在一下几点:
- 对外支持Prometheus相关的API,所以它可以直接用于Grafana作为Prometheus数据源使用, 同时扩展了PromQL, 详细使用可参考https://github.com/VictoriaMetrics/VictoriaMetrics/wiki/ExtendedPromQL。
- 针对Prometheus的Metrics插入查询具备高性能和良好的扩展性。甚至性能比InfluxDB和TimescaleDB高出20x
- 内存占用方面也做出了优化, 比InfluxDB少10x
- 高性能的数据压缩方式,使存入存储的数据量比TimescaleDB多达70x
- 优化了高延迟IO和低iops的存储
- 操作简单
- 支持从第三方时序数据库获取数据源
- 异常关闭情况下可以保护存储数据损坏
部署
单点
编译
1、二进制
make victoria-metrics
2、docker
make victoria-metrics-prod
启动
直接使用二进制文件进行启动
nohup /opt/victoria-metrics/victoria-metrics-prod -storageDataPath="/data/victoria" -retentionPeriod=2 >>/opt/promes/victoria-metrics/logs/start.log 2>&1 &
- -storageDataPath - path to data directory. VictoriaMetrics stores all the data in this directory.
- -retentionPeriod - retention period in months for the data. Older data is automatically deleted.
- -httpListenAddr - TCP address to listen to for http requests. By default it listens port 8428 on all the network interfaces.
- -graphiteListenAddr - TCP and UDP address to listen to for Graphite data. By default it is disabled.
- -opentsdbListenAddr - TCP and UDP address to listen to for OpenTSDB data. By default it is disabled.
可见他也是一个时序数据库,支持将prometheus,influxdb,graphite,opentsdb的数据的写入,比如使用的是prometheus,只使用了http的端口,在我们对应的prometheus文件中配置远程写入,将数据写入到victoria-metrics中去,配置如下
remote_write:
- url: http://<victoriametrics-addr>:8428/api/v1/write
queue_config:
max_samples_per_send: 10000
数据存储到victoria-metrics,我们还是通过8428端口来读取,我们在grafana中配置datasource:http://victoriametrics-addr-ip:8428
停止
发送SIGINT给进程
高可用
启动多个实例,将prometheus的数据分别写入到这些节点中,加一层负载均衡,就可以实现高可用,解决单点问题,prometheus配置如下
remote_write:
- url: http://<victoriametrics-addr-1>:8428/api/v1/write
queue_config:
max_samples_per_send: 10000
# ...
- url: http://<victoriametrics-addr-N>:8428/api/v1/write
queue_config:
max_samples_per_send: 10000
这边讲一下高可用和水平扩展
高可用是指多活,解决单点故障,正常就是多个相同的服务同时提供服务,来确保一个节点挂了,就能转移到其他的节点上,不影响外部整体的使用,比如redis的主备切换,sentinel机制,还有上面的virtoria-metrics的方式
水平扩展是一种分布式的能力,一个节点不能处理,就多个节点一起处理,这样分担一下,整体的量就上去了,比如redis的cluster集群,理论上只要加节点,就可以存储月来越多的数据,实际集群内部交互还是有瓶颈的
正常的服务,可以说在集群同时解决高可用和水平扩展是很困难的,正常的一个集群的作用
集群内主节点都获取全部数据,然后其他节点都重主节点复制数据,对外一直提供主节点查询,当主节点出现问题的时候,主备切换,这样实现了高可用,但是有单节点数量瓶颈,不能水平扩展。
集群内每个节点获取一部分数据,然后集群内节点相互复制,实现最终一致性,每个节点都保存完整的数据,这个时候一个节点挂了,会出问题,单个节点也会有瓶颈,所以在这个基础上收取前加一层负载均衡,这样当一个节点挂了之后,负载均衡会分配到其他节点上,这样实现了高可用,也实现了水平扩展,但是这个很难实现,而且还是有单节点瓶颈,一般是适用这种数据量很小的需要一致性的服务发现。
集群内每个节点获取一部分数据,并且只存储这一部分数据,然后集群内使用一些数据库或者自身实现关系映射,然后对外查询会路由到对应的节点上去查询数据。这种模式就是支持水平扩展的,但是有一个节点 出问题,查询就会出问题,没有实现高可用,所以在这个基础上实现高可用
- 每个单节点的设置主从复制,相互切换
- 完成集群间的复制
最后可以说是目前比较好的解决方式。
其他操作
- 可以删除数据
- 可以导出数据
- 目前不支持Downsampling,但是victoria-metrics的压缩率和查询效率足以使用
- 单节点不支持水平扩展,但是单节点足以媲美thanos和M3,timescaleDB的性能,如果还是觉得不够用,可以尝试集群版本
- virtoria-metrics的参数基本不用调整,都是优化后的合理设计,自身也支持prometheus监控
测试
启动脚本
[root@test victoria-metrics]# cat start.sh
nohup /opt/victoria-metrics/victoria-metrics-prod -storageDataPath="/data/victoria" -retentionPeriod=2 >>/opt/victoria-metrics/logs/start.log 2>&1 &
-storageDataPath="/data/victoria":数据存储目录
-retentionPeriod=2:数据存储时间,两个月
11天的数据量
[root@test victoria-metrics]# du -sh /data/victoria
20G /data/victoria
cpu和内存消耗
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
21899 root 20 0 42.9g 26g 6280 S 188.5 20.8 13486:10 victoria-metric
4560 root 20 0 159g 26g 365m S 1110.1 20.8 9846:56 prometheus
集群
集群模式是采用的分布式部署,将数据分别存储在不同的节点上,实现了水平扩展,目前还没有relaese版本,需要自己编译,但是解决了数据量的问题,同时在性能方面并没有发生太大的影响。
编译
直接make就会在bin目录下生成可执行文件vmstorage, vmselect and vminsert。
架构原理图
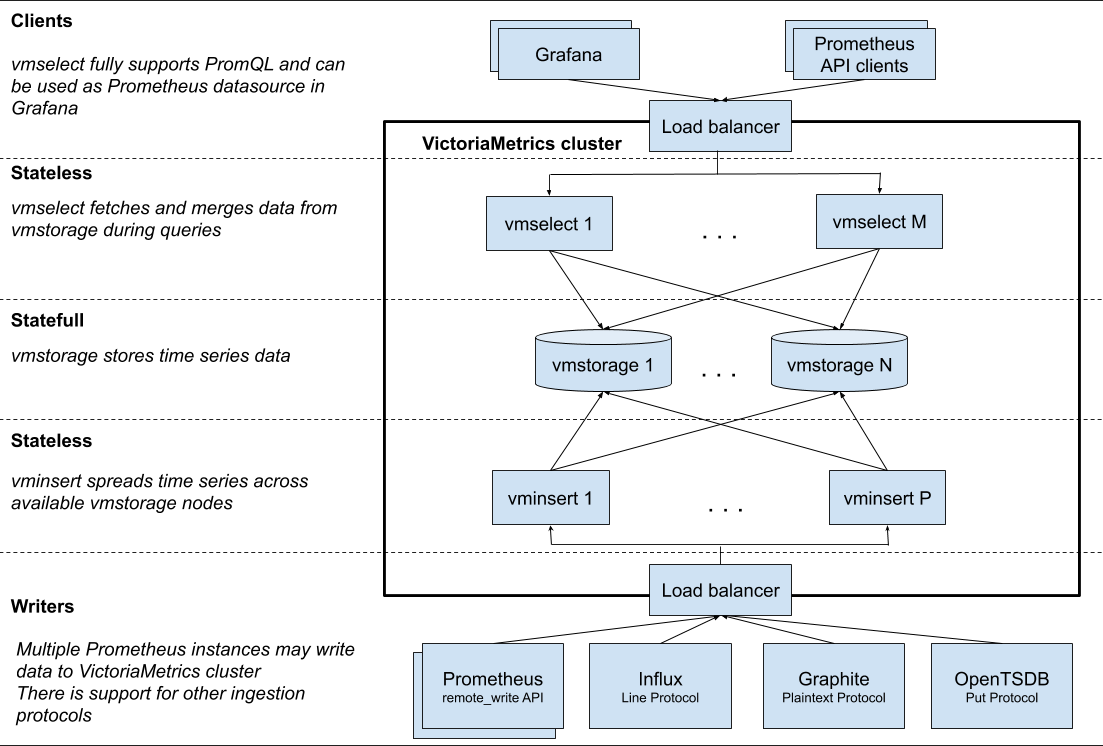
组件
vmstorage - stores the data
vmstore其实就是我们数据存在的地方,需要先启动,否则insert会找不到插入的节点,导致数据丢失。
vminsert - proxies the ingested data to vmstorage shards using consistent hashing
vminsert对采集的提供的代理接口,同时选择将数据插入到我们指定的store节点,可以是单节点,也可以是集群上所有的机器都部署,通过nginx来负载均衡,可以减少节点压力,但是并不能解决单点问题。
vmselect - performs incoming queries using the data from vmstorage
vmselect是给外部进行查询的接口,同时也负责查询数据的聚合功能。负载均衡和vmisert一样,使用nginx。
HTTP api
insert
http://<vminsert-ip>:8480/insert/<accountID>/<suffix>:
<accountID> is an arbitrary number identifying namespace for data ingestion (aka tenant)
<suffix> may have the following values:
1.prometheus - for inserting data with Prometheus remote write API
2.influx/write or influx/api/v2/write - for inserting data with Influx line protocol
querying
http://<vmselect-ip>:8481/select/<accountID>/prometheus/<suffix>:
<accountID> is an arbitrary number identifying data namespace for the query (aka tenant)
<suffix> may have the following values:
1.api/v1/query - performs PromQL instant query
2.api/v1/query_range - performs PromQL range query
3.api/v1/series - performs series query
4.api/v1/labels - returns a list of label names
5.api/v1/label/<label_name>/values - returns values for the given <label_name> according to API
6.federate - returns federated metrics
7.api/v1/export - exports raw data. See this article for details
delete
http://<vmselect-ip>:8481/delete/<accountID>/prometheus/api/v1/admin/tsdb/delete_series?match[]=<timeseries_selector_for_delete>.
vmstorage
vmstore保留了8482端口,提供一下URL:
/snapshot/create - create instant snapshot, which can be used for backups in background. Snapshots are created in <storageDataPath>/snapshots folder, where <storageDataPath> is the corresponding command-line flag value.
/snapshot/list - list available snasphots.
/snapshot/delete?snapshot=<id> - delete the given snapshot.
/snapshot/delete_all - delete all the snapshots.
Snapshots may be created independently on each vmstorage node. There is no need in synchronizing snapshots' creation across vmstorage nodes.
扩展
1、vminsert and vmselect是可扩展的,无状态的,可以随时扩展或者缩容,并不影响,只是需要在负载均衡中将相关节点处理一下
2、vmstore是有状态的,因为是分布式存储数据的,所以新增节点需要如下步骤
- Start new vmstorage node with the same -retentionPeriod as existing nodes in the cluster.
- Gradually restart all the vmselect nodes with new -storageNode arg containing
:8401. - Gradually restart all the vminsert nodes with new -storageNode arg containing
:8400.
备份和恢复
1、主要使用vmstore的url来进行备份
Create an instant snapshot by navigating to /snapshot/create HTTP handler. It will create snapshot and return its name.
Archive the created snapshot from <-storageDataPath>/snapshots/<snapshot_name> folder using any suitable tool that follows symlinks. For instance, cp -L, rsync -L or scp -r. The archival process doesn't interfere with vmstorage work, so it may be performed at any suitable time. Incremental backups are possible with rsync --delete, which should remove extraneous files from backup dir.
Delete unused snapshots via /snapshot/delete?snapshot=<snapshot_name> or /snapshot/delete_all in order to free up occupied storage space.
There is no need in synchronizing backups among all the vmstorage nodes.
2、恢复
- Stop vmstorage node with kill -INT.
- Delete all the contents of the directory pointed by -storageDataPath command-line flag.
- Copy all the contents of the backup directory to -storageDataPath directory.
- Start vmstorage node.
实现原理
vminsert
插入数据就比较简单了,使用了prometheus差不多的数据结构体来存储数据,只要将数据转化为对应的结构体直接存入数据就可以。对于其他的时序数据库比如influxdb都是差不多的数据结构,只要稍微进行转换,就可以将数据存储到存储节点去。
vmstore
存储数据可以比常规的节省10倍的内存
vmselect
查询数据很快
MergeTree
VictoriaMetrics将数据存储在相似于ClickHouse的 MergeTree表 数据结构中。它是用于剖析数据和其余事件流的最快的数据库。在典型的剖析查问上,它的性能要比PostgreSQL和MySQL等传统数据库高10到1000倍。
特性
扩展了promeql
1 、模版
((node_memory_MemTotal_bytes{instance=~"$node:$port", job=~"$job"} - node_memory_MemFree_bytes{instance=~"$node:$port", job=~"$job"}) /
node_memory_MemTotal_bytes{instance=~"$node:$port", job=~"$job"}) * 100
使用模版
WITH (
commonFilters = {instance=~"$node:$port",job=~"$job"}
)
(node_memory_MemTotal_bytes{commonFilters} - node_memory_MemFree_bytes{commonFilters}) /
node_memory_MemTotal_bytes{commonFilters} * 100
发展
vmagent
vmagent是一个很小巧但优秀的代理,它可以帮助您从各种来源收集指标并将其存储到VictoriaMetrics或任何其他支持remote_write协议的与Prometheus兼容的存储系统。
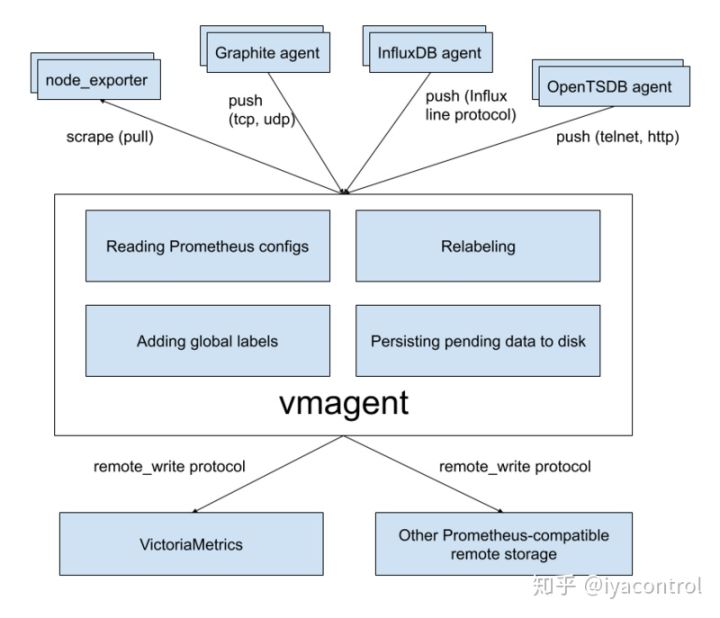
- 可以用作Prometheus的直接替代品,用于抓取目标(例如node_exporter)。
- 可以像Prometheus那样,重新添加,删除和修改标签。可以在将数据发送到远程存储之前对其进行过滤。
- 支持多种VictoriaMetrics支持的数据格式,比如Influx,OpenTSDB,Graphite,Prometheus等。
- 可以将收集的指标同时复制到多个远程存储系统。在与远程存储连接不稳定的环境中工作。如果远程存储不可用,则将收集的指标缓存在-remoteWrite.tmpDataPath中。一旦恢复远程存储的连接,缓冲的metrcis即发送到远程存储。可以通过-remoteWrite.maxDiskUsagePerURL限制缓冲区的最大磁盘使用量。
- 与Prometheus相比,使用较少的RAM,CPU,磁盘IO和网络带宽。
目前来讲,Prometheus依旧不可或缺。vmagent 还处于开发阶段。但是vmagent有取代prometheus的想法是可以看出来的。