一个完整的监控体系包括:采集数据、分析存储数据、展示数据、告警以及自动化处理、监控工具自身的安全机制。我们来看看使用prometheus进行kubernetes的容器监控。
物理部署promehteus监控K8s
集群监控
k8s的集群的监控主要分为以下三个方面,当然还有一些k8s扩展使用的组件都是由对应的监控的。
k8s的物理机监控
架构图
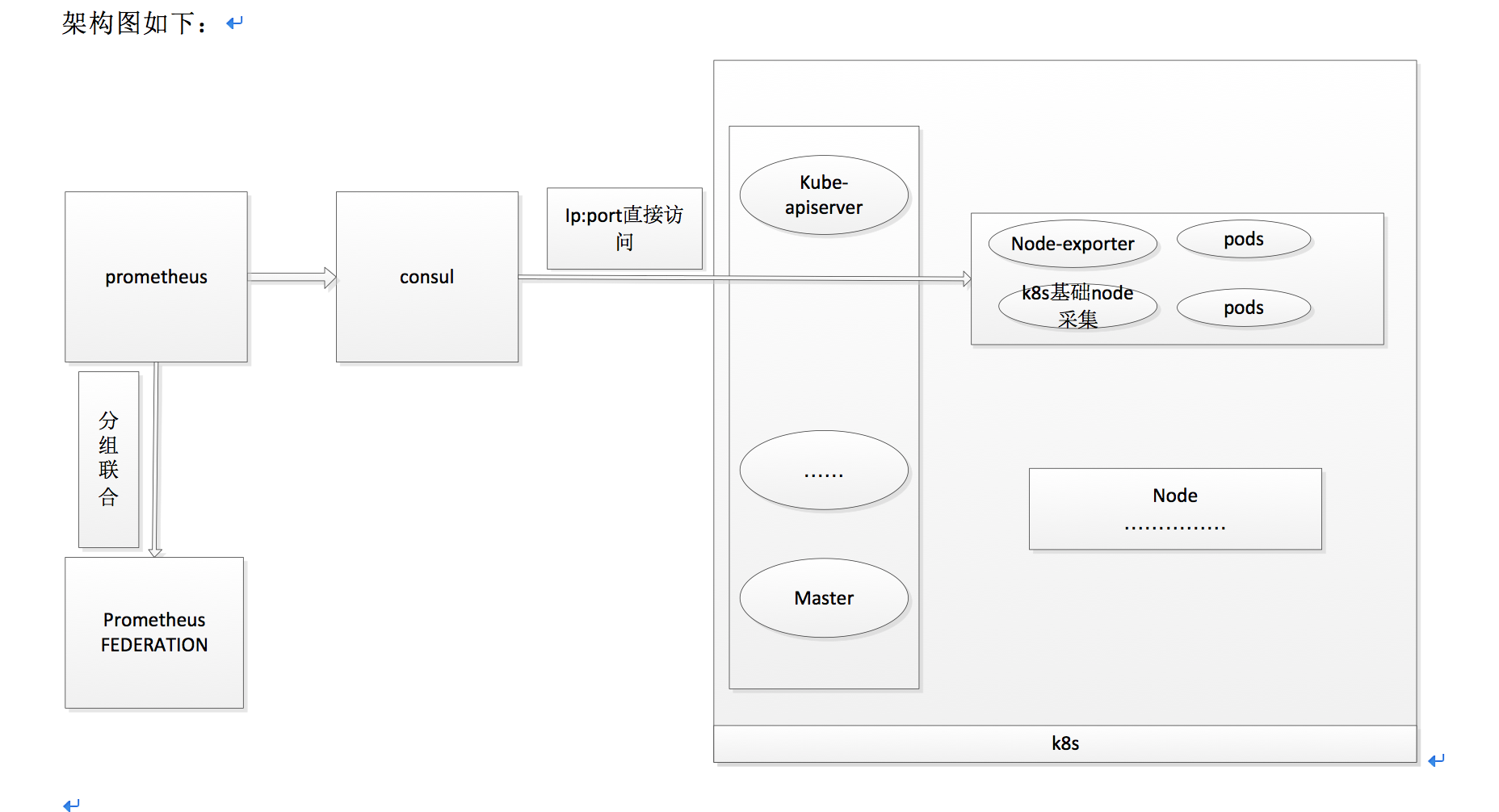
直接使用prometheus的node-exporter就可以来获取数据的。Node-exporter会部署在每一个节点上,获取当前物理机的指标,当k8s的node节点数多的时候需要分组进行采集,并且k8s使用的网络支持固定ip,所以直接采用将ip:port注册到consul中,然后prometheus获取注册信息直接采集数据,物理机监控主要是使用node_exporter探针来获取物理机的cpu,内存,磁盘空间和i/o等指标。
node_exporter可以直接采用的是k8s的daemonset部署的方式,先将node-exporter打成镜像,部署在k8s pod上
物理监控我们必须要关心一下我们常用的指标
物理机层面
cpu的使用率/已经使用/总量/request
- 使用率:1- avg(irate(node_cpu_seconds_total{mode=“idle”,ip=~“$node”,cluster_name=~“$cluster”}[2m]))
- 已经使用:(count(node_cpu_seconds_total{mode=“system”,ip=~“$node”,cluster_name=~“$cluster”})-sum(irate(node_cpu_seconds_total{mode=“idle”,ip=~“$node”,cluster_name=~“$cluster”}[5m])))
- 总量:count(node_cpu_seconds_total{mode=“system”,ip=~“$node”,cluster_name=~“$cluster”})
memory的使用率/已经使用/总量/request
- 使用率:((sum(node_memory_MemTotal_bytes{ip=~“$node”,cluster_name=~“$cluster”}) - sum(node_memory_MemFree_bytes{ip=~“$node”,cluster_name=~“$cluster”}) - sum(node_memory_Cached_bytes{ip=~“$node”,cluster_name=~“$cluster”})) / sum(node_memory_MemTotal_bytes{ip=~“$node”,cluster_name=~“$cluster”})) * 100
- 已经使用:sum(node_memory_MemTotal_bytes{ip=~“$node”,cluster_name=~“$cluster”}) - sum(node_memory_MemFree_bytes{ip=~“$node”,cluster_name=~“$cluster”}) - sum(node_memory_Cached_bytes{ip=~“$node”,cluster_name=~“$cluster”})
- 总量:sum(node_memory_MemTotal_bytes{ip=~“$node”,cluster_name=~“$cluster”})
- request:sum(kube_pod_container_resource_requests_memory_bytes{cluster_name=~“$cluster”,node=~“$node_name”,instance=“$instance”})
disk和disk io
- 使用率:(sum(node_filesystem_size_bytes{device!=“rootfs”,ip=~“$node”,cluster_name=~“$cluster”,fstype !=“fuse.ossfs.ossInode”}) - sum(node_filesystem_free_bytes{device!=“rootfs”,ip=~“$node”,cluster_name=~“$cluster”,fstype !=“fuse.ossfs.ossInode”})) / sum(node_filesystem_size_bytes{device!=“rootfs”,ip=~“$node”,cluster_name=~“$cluster”,fstype !=“fuse.ossfs.ossInode”}) * 100
- io-read:sum(rate(node_disk_read_bytes_total{ip=~“$node”,cluster_name=~“$cluster”,device=“sdb”}[5m]))
- io-write:sum(rate(node_disk_written_bytes_total{ip=~“$node”,cluster_name=~“$cluster”,device=“sdb”}[5m]))
- io-time:sum(rate(node_disk_io_time_seconds_total{ip=~“$node”,cluster_name=~“$cluster”,device=“sdb”}[5m]))
指标可以直接查看对应的grafana的json文件,这边就不一一列举了
k8s本身指标的监控
主要是k8s自身使用的组件的指标监控
架构图
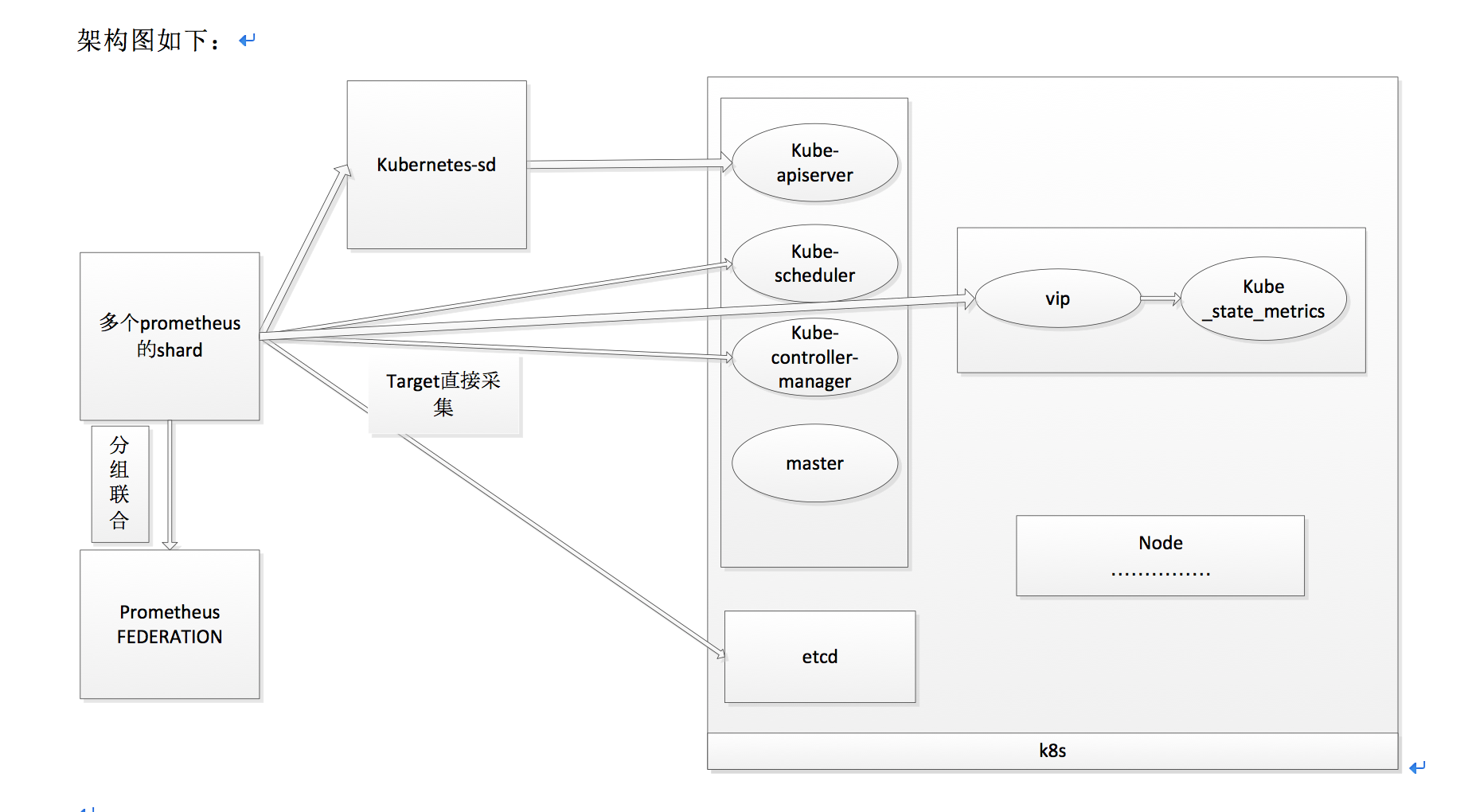
可见都是通过k8s自身组件来暴露指标给prometheus进行采集的。直接将集群的机器的IP:port注册到consul中去给prometheus拉去探测。
这边有一个不同的地方,就是每个pod的性能情况都是通过cadvisor统一获取,不需要对每一个pod进行按着探针来监控,pod的注册也是为了业务监控的需要,和自身的监控指标并木有关系。
在k8s中安装kube-state-metrics组件用来采集kubernetes的各种组件状态信息。
Kubernetes集群上Pod, DaemonSet, Deployment, Job, CronJob等各种资源对象的状态需要监控数据可以被cadvisor采集。cadvisor集成在kubelet中,不需要单独部署。
下面是一些监控的组件的端口
Node需要注册target,包括kubelet, cadvisor集成在kubelet中和kubelet同时暴露出来,但是使用不同的url, node-exporter, (node_list包含master节点和node节点)
For node in node_list
http://node_ip:9100/metrics
kube-scheduler监控
For node in masters
http://node_ip:10251/metrics
kube-controller-manager监控
For node in masters
http://node_ip:10252/metrics
kube-apiserver监控:需要权限的prometheus带着证书去访问
https://vip:6443/metrics
kube-state-metrics监控
https://vip:10241/metrics
这个vip会把请求转成master上的apiserver或者kube-state-metrics
etcd:需要权限的prometheus带着证书去访问
https://etcd-ip:2379/metrics
https://etcd-event-ip:2382/metrics
指标都是重上面的组件中要么采集,要么暴露出来的,主要监控项(表达式可以去json文件中去看)
pod和container的cpu,memory
pod的数量和状态
pod的disk
etcd等各个组件的状态
应用的监控
主要是对一些中间件的监控,架构设计如下
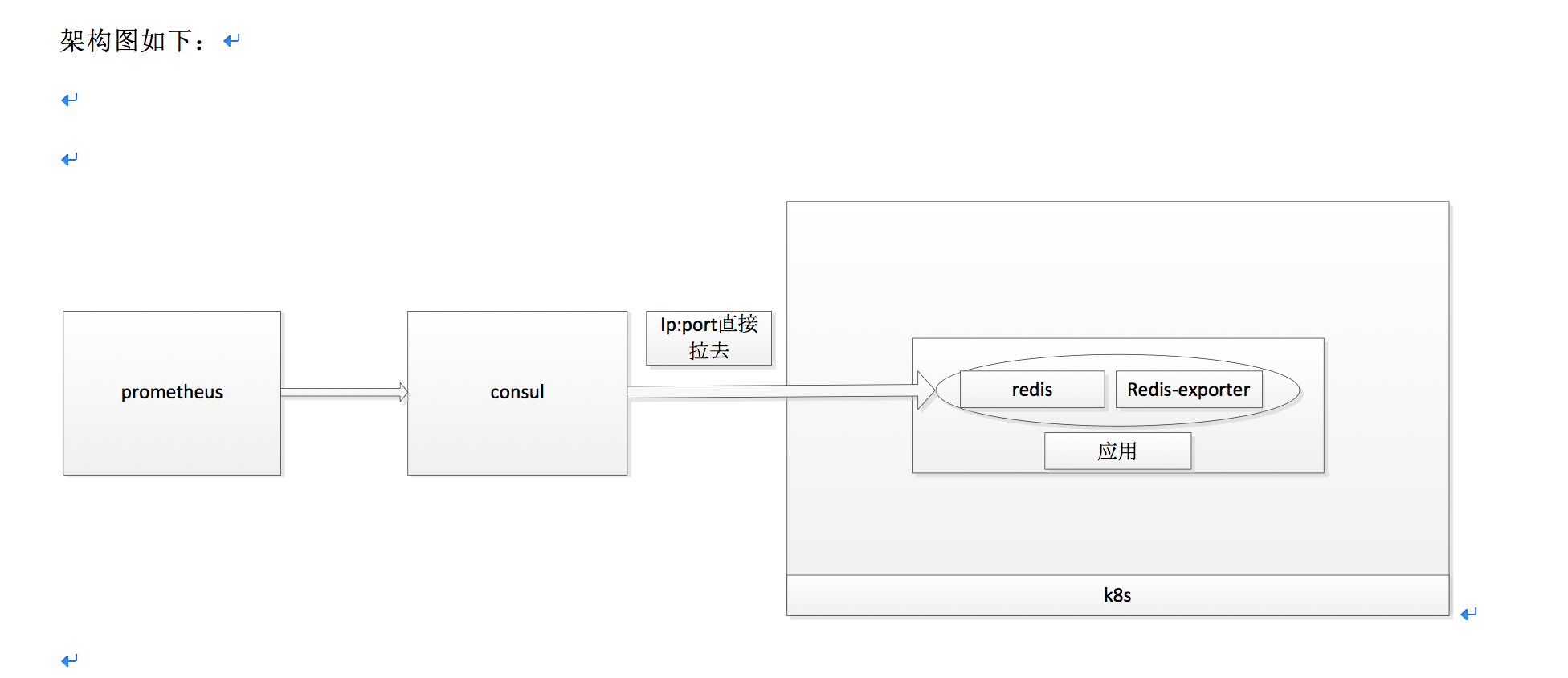
K8s内部部署采用单pod单容器多进程的模式,先把镜像打好,然后在启动应用的时候把探针放进去一起启动。
直接通过ip:port来访问探针指标,使用外部的prometheus来采集探针提供的指标,最后在grafana上进行展示。
这边注明一下使用单容器多进程的方式。
2020.09.09
上面的方式会互相影响,所以使用sidecar的控制器,可以自动启停增加删除容器,所以最好使用sidecar的模式进行监控。
sidecar的模式,单pod双容器
这种模式,探针和应用分离开来,互不影响,便于更新,还在同一个pod下,可以共享网络 但是这种模式,单独启动了一个容器占用了一部分资源,两个镜像比较麻烦,需要管理。
个人比较推荐sidecar模式。
单pod单容器多进程模式
这种模式,不能实现解耦,一个应用挂了,监控也跟着挂了, 但是不占用资源,不用管理。
多pod单容器模式
这种模式,网络需要打通,还是新建pod浪费资源,目前48C256G的机器没个节点上最多要求不能超过一百个pod。
容器的设计模式
这边讲解一些容器的设计模式:
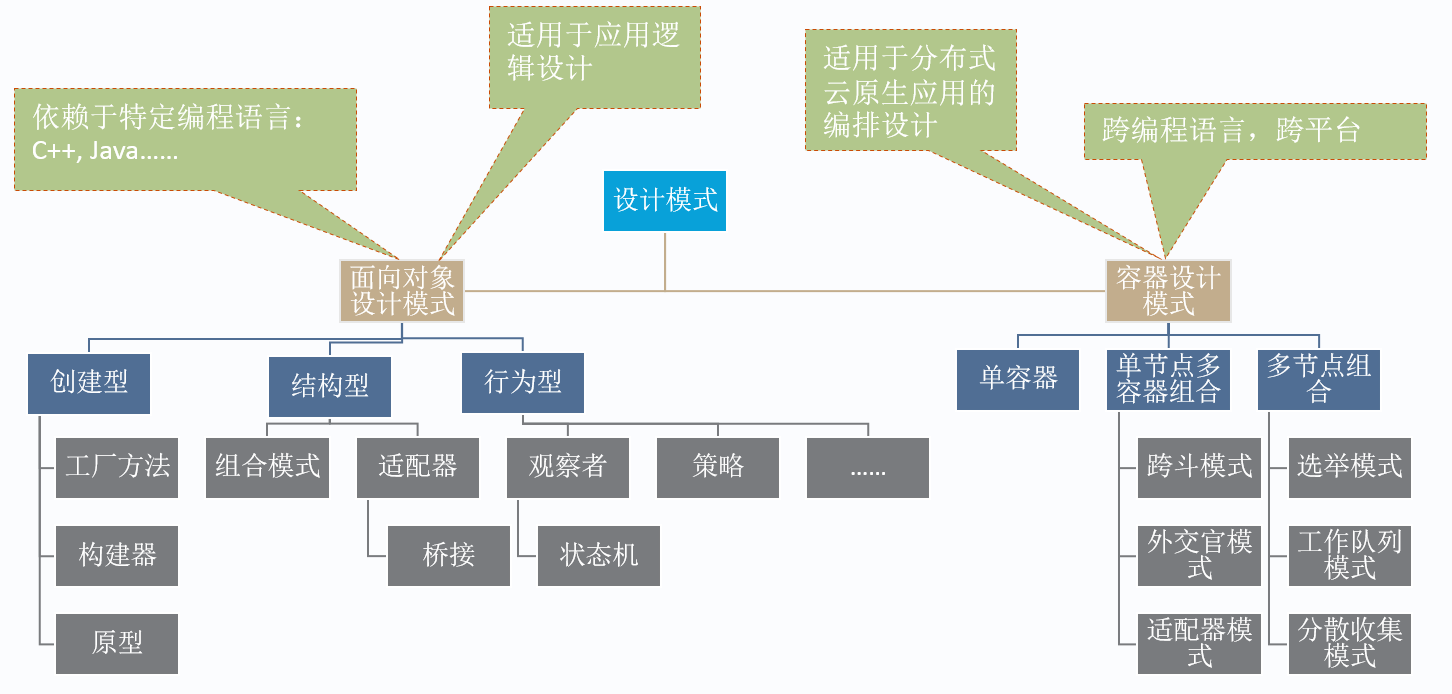
重这个对比图中可以看出
1)单容器管理模式;
一个pod一个容器的模式,管理简单清晰。直接使用基本命令就可以运行,当然在一个容器中可以运行多个进程,互相协作。
2)单节点多容器模式;
多容器才可以体现k8s的强大,Pod是一个轻量级的节点,同一个Pod中的容器可以共享同一块存储空间和同一个网络地址空间,这使得我们可以实现一些组合多个容器在同一节点工作的模式。
挎斗模式(Sidecar pattern)
这种模式主要是利用在同一Pod中的容器可以共享存储空间的能力。比如一个往文件系统中写文件,一个容器重文件系统中读取文件。
外交官模式(Ambassador pattern)
这种模式主要利用同一Pod中的容器可以共享网络地址空间的特性。比如一个容器开启一个proxy,给外部访问,类似于网关(外交官),然后这个容器来对转发请求到内部其他容器中处理,然后proxy容器和内部其他容器共享内部网络,直接使用localhost访问就好了。
适配器模式(Adapter pattern)
分布地执行和存储,统一的监控和管理。比如业务逻辑容器的pod中运行一个exporter容器,对外统一暴露指标,适配prometheus。
其实这三种只是根据使用不同特性区分了而已,其实就是pod内部共享。
3)多节点多容器模式;
多节点选举模式
多节点选举在分布式系统中是一种重要的模式,特别是对有状态服务来说。在分布式系统中,一般来说,无状态服务,可以随意的水平伸缩,只要把运行业务逻辑的实例复制出去运行就可以,这也就是K8s里ReplicationController和ReplicaSet所做的事情。
对于有状态服务,人们也希望能够水平的扩展,但因为每个实例有自己的持久化状态,而这个持久化状态必须要延续它的生命,因此,有状态服务的水平伸缩模式就是状态的分片,其中机制跟数据库的分片是一致的。那么对于一个原生为分布式系统设计的有状态服务,每个实例与分片数据的对应关系,就成为这个有状态服务的全局信息。对于任何服务,多个实例的全局信息都需要一个保存的地方。
一个简单的办法是保存在外部的一个代理服务器上,这也就是MariaDB的Galera解决方案的做法,也是所以代理服务器为后端服务器所做的事情。但这种方式的问题在于,系统要依赖外部代理服务器,而代理服务器本身的高可用和水平伸缩还是没有解决的问题。
所以对于要原生自己解决高可用和水平伸缩问题的系统,例如Etcd和ElasticSearch,一定要有原生的主控节点选举机制。这样这个分布式系统就不需要依赖外部的系统来维护自己的状态了。对于一个分布式系统,最主要的系统全局信息,就是集群中有哪些节点,Master节点是哪个,每个节点对应哪个分片。主控节点的任务,就是保存和分发这些信息。
在K8s集群中,一个微服务实例Pod可以有多个容器。这一特性很好地提高了多节点选举机制的可重用性。它使得我们可以专门开发一个用于选举的容器镜像,在实际部署中,将选举容器和普通应用容器组合起来,应用容器只需要从本地的选举容器读取状态,就可以得到选举结果。这样,使得应用容器可以只关注自身业务逻辑相关的代码。
这就是多节点多容器的选举模式,是一种使用方式。
工作队列模式
分布式系统的一个重要作用是能够充分利用多个物理计算资源的能力,特别是在动态按需调动计算资源完成计算任务。设想如果有大量的需要处理的任务随机的到来,对计算资源需要的容量是不确定地;显然,按照最大可能计算量和最小可能计算量设置计算节点都是不合理的。所以可以启动多个节点多个容器来处理队列中的任务,也是一种使用方式。
分散收集模式
根节点接受到来自客户端的服务请求,将服务请求分配给不同的业务模块分散处理,处理结果收集到根节点,经过一定的汇聚合并运算,产生一个合并的结果交付给客户端。也就是启动多个节点多个容器来协调处理,再通过代理合并返回,也是一种使用方式。
其实可以看见,容器的模式都是来源于物理的使用方式,也是一些常用的架构,只不过环境换成了容器,有了对应的制约和方便管理。
探针组件
Kube-state-metrics
将Kube-state-metrics使用镜像在k8s中运行,运行在master节点上,可以获取到kube相关的所有指标,也就是具体的各种资源对象的状态指标。
对应的ymal文件
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources:
- configmaps
- secrets
- nodes
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources:
- daemonsets
- deployments
- replicasets
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources:
- statefulsets
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources:
- cronjobs
- jobs
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources:
- horizontalpodautoscalers
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: kube-system
name: kube-state-metrics-resizer
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get"]
- apiGroups: ["extensions"]
resources:
- deployments
resourceNames: ["kube-state-metrics"]
verbs: ["get", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: kube-state-metrics
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kube-state-metrics-resizer
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: kube-system
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: kube-state-metrics
namespace: kube-system
spec:
template:
metadata:
labels:
k8s-app: kube-state-metrics
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
serviceAccountName: kube-state-metrics
hostNetwork: true
nodeSelector:
node-role.kubernetes.io/master.node: ""
containers:
- name: kube-state-metrics
image: xgharborsit01.sncloud.com/sncloud/kube-state-metrics:1.4.0
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 200m
memory: 128Mi
env:
- name: KUBERNETES_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: KUBERNETES_SERVICE_HOST
value: 10.243.129.252
- name: KUBERNETES_SERVICE_PORT
value: "6443"
volumeMounts:
- mountPath: /opt/kube-state-metrics/logs
subPath: kube-state-metrics
name: k8slog
ports:
- name: http-metrics
containerPort: 10241
- name: telemetry
containerPort: 10242
readinessProbe:
httpGet:
path: /healthz
port: 10241
initialDelaySeconds: 5
timeoutSeconds: 5
volumes:
- hostPath:
path: /var/run/docker.sock
name: docker-sock
- hostPath:
path: /k8s_log
name: k8slog
Node-exporter
Node-exporter也是使用镜像运行在k8s的每个节点上,用于获取k8s部署节点的物理机器资源信息,并不能获取对应的k8s集群的信息。
对应的yaml文件
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: node-exporter
namespace: kube-system
spec:
template:
metadata:
labels:
app: node-exporter
name: node-exporter
namespace: kube-system
spec:
containers:
- image: xgharborsit01.sncloud.com:443/sncloud/node_exporter:0.16.0
imagePullPolicy: IfNotPresent
name: node-exporter
resources:
limits:
memory: 256Mi
cpu: 200m
requests:
memory: 128Mi
cpu: 100m
env:
- name: KUBERNETES_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
ports:
- containerPort: 9100
hostPort: 9100
name: scrape
volumeMounts:
- name: proc
mountPath: /host/proc
readOnly: true
- name: sys
mountPath: /host/sys
readOnly: true
- mountPath: /opt/node-exporter/logs
subPath: node-exporter
name: k8slog
volumes:
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
- hostPath:
path: /k8s_log
type: ""
name: k8slog
hostNetwork: true
hostPID: true
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
cadvisor-proxy
cadvisor-proxy对cadvisor的指标进行过滤处理。这个组件也是部署在k8s上运行。
对应的ymal部署文件
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: cadvisor-proxy
namespace: kube-system
spec:
template:
metadata:
labels:
app: cadvisor-proxy
spec:
hostNetwork: true
containers:
- name: proxy
image: xgharborsit01.sncloud.com:443/sncloud/cadvisor-proxy:1.0.0
imagePullPolicy: Always
args:
- --log.path=/opt/cadvisor-proxy/logs
resources:
limits:
memory: 100Mi
cpu: 500m
requests:
memory: 100Mi
cpu: 100m
volumeMounts:
- mountPath: /var/run/docker.sock
name: docker-sock
readOnly: true
- mountPath: /opt/cadvisor-proxy/logs
subPath: cadvisor-proxy
name: k8slog
env:
- name: HOST_IP
valueFrom:
fieldRef:
fieldPath: status.hostIP
volumes:
- hostPath:
path: /var/run/docker.sock
name: docker-sock
- hostPath:
path: /k8s_log
name: k8slog
各种应用的exporter
这边监控应用都是将对应的探针和对应的应用一起打在一个镜像里,也就是一个容器运行了两个程序,直接获取对应的指标。也有使用sidecar的模式在一个pod中运行两个容器,获取指标。下面会具体说明sidecar和这种模式的相关差异使用
组件的区别
cAdvisor
cAdvisor是Google开源的容器资源监控和性能分析工具,它是专门为容器而生,本身也支持 Docker 容器。
Cadvisor可以直接部署运行在vm或者docker上,监控当前环境下docker运行的容器的资源情况。
在 Kubernetes 中,我们不需要单独去安装,cAdvisor 已经集成在kubelet中,自己暴露指标,作为 kubelet 内置的一部分程序可以直接使用。
cAdvisor主要监控数据是容器的资源性能数据,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况。
Kube-state-metrics
kube-state-metrics通过监听 API Server 生成有关资源对象的状态指标,比如 Deployment、Node、Pod,需要注意的是 kube-state-metrics 只是简单提供一个 metrics 数据,并不会存储这些指标数据,所以我们可以使用 Prometheus 来抓取这些数据然后存储。
kube-state-metrics主要监控数据主要是k8s集群有关资源的状态。比如pod的状态,副本数,重启次数等资源状态进行监控。
metrics-server
metrics-server 也是一个集群范围内的资源数据聚合工具,是 Heapster 的替代品,Heapster现在已经停止维护和使用,同样的,metrics-server 也只是显示数据,并不提供数据存储服务。
metrics-server定时从Kubelet的Summary API(类似/ap1/v1/nodes/nodename/stats/summary)采集指标信息。
metrics-server主要监控数据主要是kubelet和集成的cadvisor中暴露的容器和集群节点的资源情况,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况,以及kubelet对于同期的维护情况。
kube-state-metrics 和metrics-server和prometheus
1.kube-state-metrics中监控的数据,metrics-server包括其他组件都无法提供。比如
- 我调度了多少个replicas?现在可用的有几个?
- 多少个Pod是running/stopped/terminated状态?
- Pod重启了多少次?
- 我有多少job在运行中
等这一系列资源状态的数据。
2.两者其实没有太大的可比性,本质不一样。
- Metrics-server是官方废弃heapster项目,新开的一个项目,就是为了将核心资源监控作为一等公民对待,即像pod、service那样直接通过api-server或者client直接访问,不再是安装一个hepater来汇聚且由heapster单独管理。从 Kubernetes1.8 开始,Metrics-server就作为一个 Deployment对象默认部署在由kube-up.sh脚本创建的集群中,这样就可以直接暴露相关聚合的数据。如果形象的说的话,Metrics-server实质上是一个监控系统。
- kube-state-metrics关注于获取k8s各种资源的最新状态,类似于监控系统中的一个探针。
可见两种着力点的方向不一样。
3.Prometheus和Metrics-server
- Prometheus监控系统不用Metrics-server
- Prometheus监控系统一般不用Metrics-server,因为他们都是自己做指标收集、集成的。可以说Prometheus包含了metric-server的能力,且prometheus更加强大,比如Prometheus可以监控metric-server本身组件的监控状态并适时报警,这里的监控就可以通过kube-state-metrics来实现,如metric-server的pod的运行状态。
- 当然也可以使用Metrics-server,Metrics-server从 Kubelet、cAdvisor 等获取核心数据,再由prometheus从 metrics-server 获取核心度量,从其他数据源(如 Node Exporter 等)获取非核心度量,再基于它们构建监控告警系统。但是这边新增了一层,在原来的不新增的情况下也是能实现的。所以正常prometheus不使用Metrics-server。
问题处理
监控支持多k8s集群场景
在prometheus采集的时候对集群打标签,一个集群统一一个标签
应用关联k8s
应用监控时,我们需要知道当前应用是跑在哪个pod上的,这样就需要唯一标志,因为我可以有pod_IP并且在pod创建后podip就固定了,所以可以根据pod ip到cavisor中获取对应的pod name,然后根据pod name来获取对应pod的指标,包括到kube-state-metrics匹配对应的状态指标。
这样就可以实现,用户到应用,应用对应的在哪个pod,pod在哪个node,以及pod的相关信息,这种一层层的监控结构。
后面对探针进行改造,对于每一个暴露出来的指标,加上pod ip和pod name的label,然后以这两个纬度进行监控。
k8s部署promehteus监控K8s
探针这一块后端部署都是上面的物理部署一样的,包括cadvisor-proxy,node-exporter,kube-state-metrics等,因为这些本来就是部署在k8s上面的,使用的也是一样的,这这边要解决的就是上面部署在物理机上的组件,包含prometheus,thanos,grafana,alertmanager等还有服务发现的方式。
metrics
我们就可以按照 Metrics 数据的来源,来对 Kubernetes 的监控体系做一个汇总了。
- 第一种 Metrics,是宿主机的监控数据。这部分数据的提供,需要借助一个由 Prometheus 维护的Node Exporter 工具。一般来说,Node Exporter 会以 DaemonSet 的方式运行在宿主机上。其实,所谓的 Exporter,就是代替被监控对象来对 Prometheus 暴露出可以被“抓取”的 Metrics 信息的一个辅助进程。而 Node Exporter 可以暴露给 Prometheus 采集的 Metrics 数据, 也不单单是节点的负载(Load)、CPU 、内存、磁盘以及网络这样的常规信息,它的 Metrics 指标可以说是“包罗万象”。
- 第二种 Metrics,是来自于 Kubernetes 的 API Server、kubelet 等组件的 /metrics API。除了常规的 CPU、内存的信息外,这部分信息还主要包括了各个组件的核心监控指标。比如,对于 API Server 来说,它就会在 /metrics API 里,暴露出各个 Controller 的工作队列(Work Queue)的长度、请求的 QPS 和延迟数据等等。这些信息,是检查 Kubernetes 本身工作情况的主要依据。
- 第三种 Metrics,是 Kubernetes 相关的监控数据。这部分数据,一般叫作 Kubernetes 核心监控数据(core metrics)。这其中包括了 Pod、Node、容器、Service 等主要 Kubernetes 核心概念的 Metrics。其中,容器相关的 Metrics 主要来自于 kubelet 内置的 cAdvisor 服务。在 kubelet 启动后,cAdvisor 服务也随之启动,而它能够提供的信息,可以细化到每一个容器的 CPU 、文件系统、内存、网络等资源的使用情况。
这里提到的 Kubernetes 核心监控数据,其实使用的是 Kubernetes 的一个非常重要的扩展能力,叫作 Metrics Server。它主要就是采集core metrics,提供mertrics.k8s.io来查询
提到core metrics,就要提Custom Metrics,自定义监控指标,这个也是通过Aggregator APIServer扩展实现的,Custom Metrics APIServer 的实现,其实就是一个 Prometheus 项目的 Adaptor。当你把 Custom Metrics APIServer 启动之后,Kubernetes 里就会出现一个叫作custom.metrics.k8s.io的 API。而当你访问这个 URL 时,Aggregator 就会把你的请求转发给 Custom Metrics APIServer 。
这两种api的提供,都是基于k8s强大的 API 扩展机制Aggregator APIServer,我们在k8s API的扩展中有讲到过,当 Kubernetes 的 API Server 开启了 Aggregator 模式之后,你再访问 apis/metrics.k8s.io/v1beta1 的时候,实际上访问到的是一个叫作 kube-aggregator 的代理。而 kube-apiserver,正是这个代理的一个后端;而 Metrics Server,则是另一个后端。而且,在这个机制下,你还可以添加更多的后端给这个 kube-aggregator。所以 kube-aggregator 其实就是一个根据 URL 选择具体的 API 后端的代理服务器。通过这种方式,我们就可以很方便地扩展 Kubernetes 的 API 了。

手动部署
部署prometheus
在k8s上部署Prometheus十分简单,只需要下面4个文件:prometheus.rbac.yml, prometheus.config.yml, prometheus.deploy.yml, prometheus.svc.yml。
下面给的例子中将Prometheus部署到kube-system命名空间。
prometheus.rbac.yml定义了Prometheus容器访问k8s apiserver所需的ServiceAccount和ClusterRole及ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: kube-system
prometheus.config.yml configmap中的prometheus的配置文件
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-system
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: 'kubernetes-services'
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module: [http_2xx]
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.example.com:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name
- job_name: 'kubernetes-ingresses'
kubernetes_sd_configs:
- role: ingress
relabel_configs:
- source_labels: [__meta_kubernetes_ingress_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__meta_kubernetes_ingress_scheme,__address__,__meta_kubernetes_ingress_path]
regex: (.+);(.+);(.+)
replacement: ${1}://${2}${3}
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.example.com:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_ingress_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_ingress_name]
target_label: kubernetes_name
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
prometheus.deploy.yml定义Prometheus的部署:
---
apiVersion: apps/v1beta2
kind: Deployment
metadata:
labels:
name: prometheus-deployment
name: prometheus
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
containers:
- image: harbor.frognew.com/prom/prometheus:2.0.0
name: prometheus
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention=24h"
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: "/prometheus"
name: data
- mountPath: "/etc/prometheus"
name: config-volume
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 2500Mi
serviceAccountName: prometheus
imagePullSecrets:
- name: regsecret
volumes:
- name: data
emptyDir: {}
- name: config-volume
configMap:
name: prometheus-config
prometheus.svc.yml定义Prometheus的Servic,需要将Prometheus以NodePort, LoadBalancer或使用Ingress暴露到集群外部,这样外部的Prometheus才能访问它:
---
kind: Service
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus
namespace: kube-system
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
nodePort: 30003
selector:
app: prometheus
上面就完成了prometheus在k8s的集群中部署,当然只是部署了prometheus,整体的架构还是可以参考物理架构部署
部署kube-state-metrics
kube-state-metrics已经给出了在Kubernetes部署的manifest定义文件,直接部署,上面物理部署的时候也已经说明了部署详情。
将kube-state-metrics部署到Kubernetes上之后,就会发现Kubernetes集群中的Prometheus会在kubernetes-service-endpoints这个job下自动服务发现kube-state-metrics,并开始拉取metrics,当然集群外部的Prometheus也能从集群中的Prometheus拉取到这些数据了。这是因为上2.2中prometheus.config.yml中Prometheus的配置文件job kubernetes-service-endpoints的配置。而部署kube-state-metrics的manifest定义文件kube-state-metrics-service.yaml对kube-state-metricsService的定义包含annotation prometheus.io/scrape: ‘true’,因此kube-state-metrics的endpoint可以被Prometheus自动服务发现。
peometheus-operator
还有很多组件需要k8s部署,但是现在已经不需要这样一个个去手动写yaml文件部署,k8s推出了operator的模式进行promehteus的部署,可以快速的部署使用。
使用k8s的服务发现
具体情况在prometheus的k8s服务发现模式已经详解过。
总结
配置项总结
- kubernetes-service-endpoints和kubernetes-pods采集应用中metrics,当然并不是所有的都提供了metrics接口。
- kubernetes-ingresses 和kubernetes-services 健康监测服务和ingress健康的状态
- kubernetes-cadvisor 和 kubernetes-nodes,通过发现node,监控node 和容器的cpu等指标
- 自动发现源码,可以参考client-go和prometheus自动发现k8s,这种监听k8s集群中资源的变化,使用informer实现,不要轮询kube-apiserver接口。
物理部署和k8s的区别和结合
物理部署下的consul走的文件服务发现和k8s的服务发现完全是两种方式,在小规模的情况下使用k8s确实方便,但是在规模较大的情况,就需要分片,目前thanos也是支持k8s,所以应该也是可以分片的,也可以将数据聚合到vm中去。