一个完整的监控体系包括:采集数据、分析存储数据、展示数据、告警以及自动化处理、监控工具自身的安全机制,我们来看看如何使用prometheus进行基础设施监控架构。
架构
首先可以看一下官方给出的架构方案
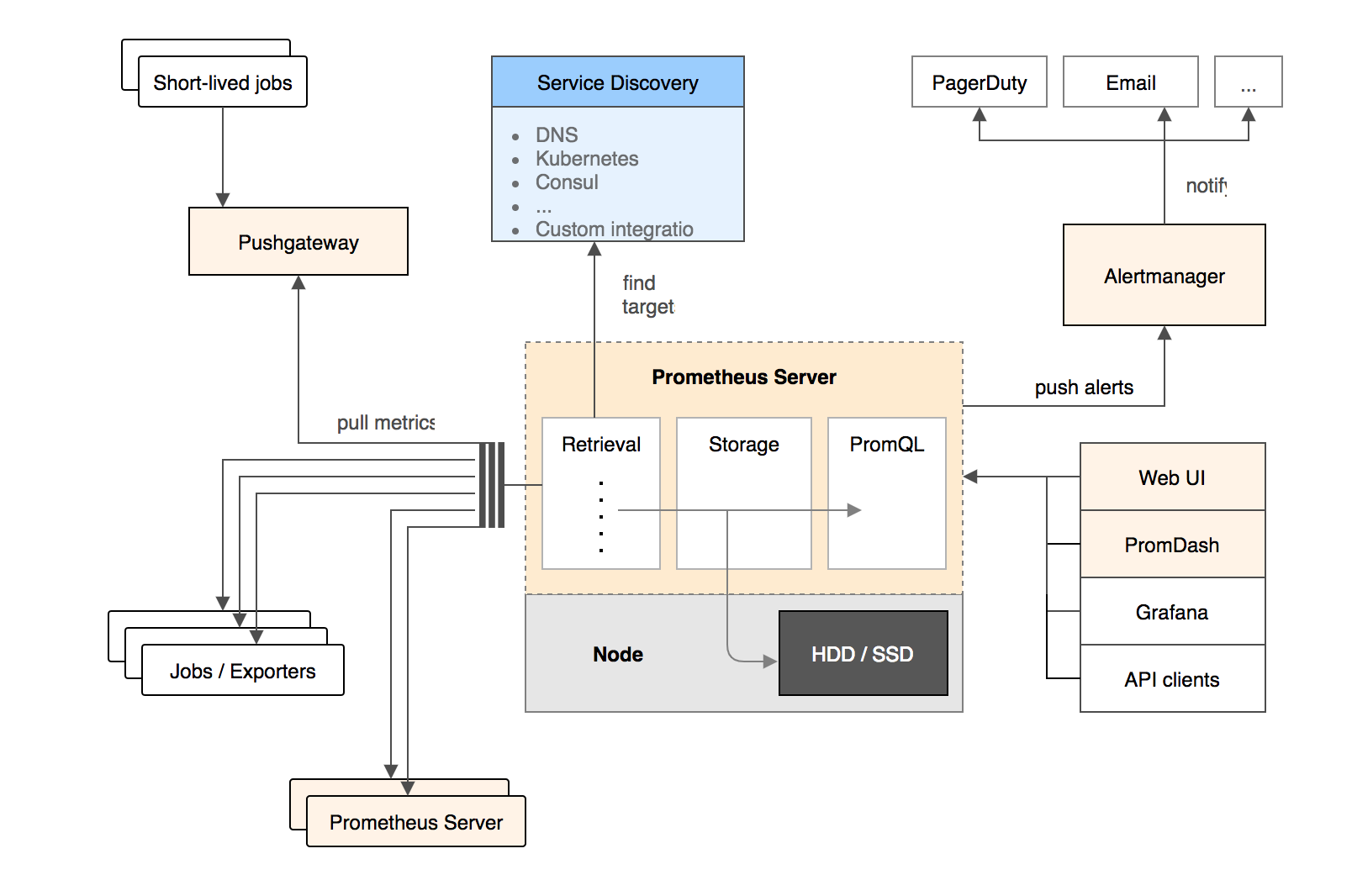
这边对架构正常使用做一个补充说明:
- grafana是无状态的,可以多部署几个通过nginx来负载均衡,通过不同的端口去访问不同的thanos-query。
- thanos-query查询对应的prometheus集群,获取数据。这边使用thanos来完成了prometheus集群功能,具体看thanos的实现。
- prometheus使用hashmod来实现对数据采集的分片,把数据放到不同的prometheus的节点上,实现集群,这个没有使用federation,因为联合在大规模的情况下,瓶颈比较严重,还有目前只是单采集模式,可以设置双采,使用vip+keepalive来实现主备切换。
- prometheus去采集数据并不是直接使用target连接,使用nginx进行了转发采集,使用prometheus的relabel来设置address,使得所有采集都连接nginx,然后使用target作为参数,最终访问target地址,获取数据,这样可以将nginx的网络打通,就能实现跨机房跨区域采集了,后面有网络问题也是处理nginx所在的机器就好。这两步具体可以查看prometheus的实现。
- 具体的采集监控内容可以通过探针的部署使用来区分。
- prometheus的数据可以提供给第三方使用,可以直接将数据通过adapter推送的kafka,给其他使用方消费
- 远程存储这一块,直接使用了remote read/write,当原生数据库不支持的时候,需要使用adapter进行转化发送。其实大部分我们使用的prometheus的扩展来做存储查询。
- 告警直接根据rule文件推送的alartmanager,这个alartmanager是一个分布式的,在prometheus的yaml文件中都要配置上,alartmanager也可以将数据推送给mq(需要改造),正常可以使用kafka,给一些告警平台进行消费使用。rule文件直接使用consul的注册信息生成,注册信息是后台管理的。
- 动态注册,服务发现这一块,可以看见,使用的是consul+consul-template,使用consul注册,并且保存注册信息,这边使用了consul的k/v模式(为什么使用这个下面有说明),然后使用consul-template这个工具将注册的信息生成json文件给prometheus的file_sd_condig使用。使用crontab 来定时更新文件,实现配置文件的自动加载。
大体架构如此,就可以实现一套物理环境的基础设施监控。
2020.08.08
NOTE:基于thanos查询慢,VM优秀的写入和查询性能,已经使用远程存储将数据都存储到VM进行查询,所以prometheus将数据都写到VM,VM具体查看VM的实现。
设计原则
- 监控的是基础设施,目的是为了解决问题,没有必要朝着大而全的方向去做,对于没有必要采集的指标,不浪费资源。
- 需要处理的告警才发出来,发出来的是必须要处理的告警
- 业务系统和监控分离,哪怕业务系统挂了,监控也不能挂,监控挂了,不影响业务系统的运行。
监控内容
具体见监控内容可以查看每个探针,我们来看一下prometheus的exporter。
采集组件
prometheus的exporter都是独立的,简单几个使用还是不错,解耦还开箱即用,但是数量多了,运维的压力变大了,例如探针管理升级,运行情况的检查等,有几种方案解决
- 做一个管理平台,类似于我们的后台系统,专门对exporter进行管理
- 用一个主进程整合几个探针,每个探针依旧是原来的版本
- 用telegraf来支持各种类型的input,all in one
prometheus使用总结
consul的service的瓶颈问题
之前使用consul的services注册job的服务信息,然后使用consul-template动态生成prometheus的配置文件。然后prometheus通过查询consul中注册的信息正则匹配来完成prometheus的采集操作 但是这样当job量很大的时候,比如有20组job,一组job130的target的的时候,就会出现consul请求api瓶颈
现在使用consul的k/v格式进行注册,直接通过IP:port作为key,对应的label作为vaule,然后使用consul-template动态生成discovery的json文件,然后prometheus使用file sd来发现这个json文件,相当于将对应的json的内容写到了prometheus的配置文件中去,这个时候五分钟consul-template动态生成一次,不会每次都去请求,这样consul的压力就几乎没有了,经过测试可以达到5000个target,prometheus的shard极限,对consul依旧没有什么压力,现在主要瓶颈在于json文件大小,filesd的压力,可以继续优化成多个文件。
自动刷新配置文件
由于Prometheus是“拉”的方式主动监测,所以需要在server端指定被监控节点的列表。当被监控的节点增多之后,每次增加节点都需要更改配置文件,非常麻烦,我这里用consul-template+consul动态生成配置文件,这种方式同样适用于其他需要频繁更改配置文件的服务。另外一种解决方案是etcd+confd,基本现在主流的动态配置系统分这两大阵营。consul-template的定位和confd差不多,不过它是consul自家推出的模板系统。