zipkin是分布式链路调用监控系统,聚合各业务系统调用延迟数据,达到链路调用监控跟踪。
zipkin
一个独立的分布式追踪系统,客户端存在于应用中(即各服务中),应具备追踪信息生成、采集发送等功能,而服务端应该包含以下基本的三个功能:
- 信息收集:用来收集各服务端采集的信息,并对这些信息进行梳理存储、建立索引。
- 数据存储:存储追踪数据。
- 查询服务:提供查询请求链路信息的接口。
安装使用
下载jar包,直接运行。简单粗暴,但要注意必须jdk1.8及以上。
wget -O zipkin.jar 'https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec'
java -jar zipkin.jar
启动成功后,打开浏览器访问zipkin的webUI,输入http://ip:9411/ ,显示web界面。
架构
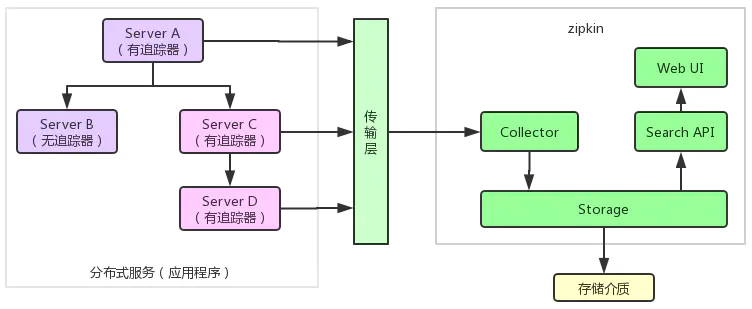
zipkin(服务端)包含四个组件,分别是collector、storage、search、web UI。
- collector 就是信息收集器,作为一个守护进程,它会时刻等待客户端传递过来的追踪数据,对这些数据进行验证、存储以及创建查询需要的索引。
- storage 是存储组件。zipkin 默认直接将数据存在内存中,此外支持使用Cassandra、ElasticSearch 和 Mysql。
- search 是一个查询进程,它提供了简单的JSON API来供外部调用查询。
- web UI 是zipkin的服务端展示平台,主要调用search提供的接口,用图表将链路信息清晰地展示给开发人员。
数据发送
一个 span 表示一次服务调用,那么追踪器必定是被服务调用发起的动作触发,生成基本信息,同时为了追踪服务提供方对其他服务的调用情况,便需要传递本次追踪链路的traceId和本次调用的span-id。服务提供方完成服务将结果响应给调用方时,需要根据调用发起时记录的时间戳与当前时间戳计算本次服务的持续时间进行记录,至此这次调用的追踪span完成,就可以发送给zipkin服务端了。但是需要注意的是,发送span给zipkin collector不得影响此次业务结果,其发送成功与否跟业务无关,因此这里需要采用异步的方式发送,防止追踪系统发送延迟与发送失败导致用户系统的延迟与中断。下图就表示了一次http请求调用的追踪流程(基于zipkin官网提供的流程图):
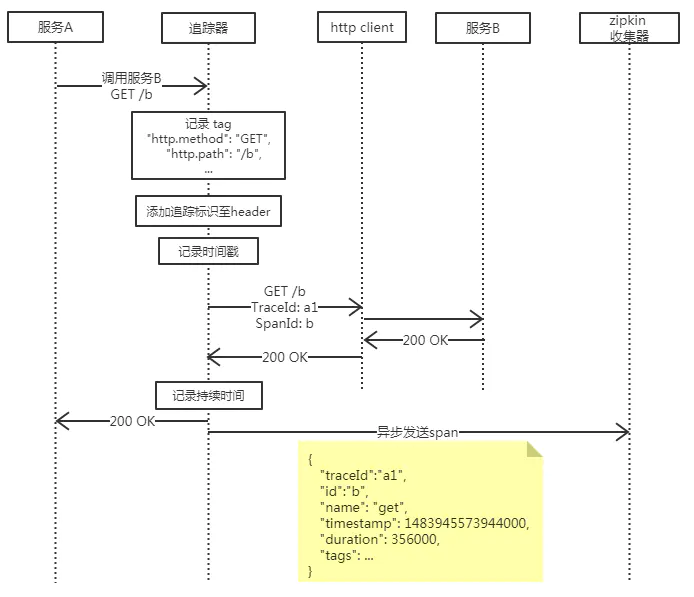
可以看出服务A请求服务B时先被追踪器拦截,记录tag信息、时间戳,同时将追踪标识添加进http header中传递给服务B,在服务B响应后,记录持续时间,最终采取异步的方式发送给zipkin收集器。span从被追踪的服务传送到Zipkin收集器有三种主要的传送方式:http、Kafka以及Scribe(Facebook开源的日志收集系统)。