Jaeger 是 Uber 开源的分布式追踪系统,兼容 OpenTracing 标准,于 2017 年 9 月加入 CNCF 基金会。
jaeger
受Dapper和OpenZipkin启发的Jaeger是由Uber Technologies作为开源发布的分布式跟踪系统。它用于监视和诊断基于微服务的分布式系统,包括:
- 分布式上下文传播
- 分布式交易监控
- 根本原因分析
- 服务依赖性分析性能/延迟优化
特性
高扩展性
Jaeger后端的设计没有单点故障,可以根据业务需求进行扩展。例如,Uber上任何给定的Jaeger安装通常每天要处理数十亿个跨度。
原生支持OpenTracing
Jaeger后端,Web UI和工具库已完全设计为支持OpenTracing标准。
- 通过跨度引用将迹线表示为有向无环图(不仅是树)
- 支持强类型的跨度标签和结构化日志通过行李
- 支持通用的分布式上下文传播机制
多存储后端
Jaeger支持两个流行的开源NoSQL数据库作为跟踪存储后端:Cassandra 3.4+和Elasticsearch 5.x / 6.x / 7.x。正在进行使用其他数据库的社区实验,例如ScyllaDB,InfluxDB,Amazon DynamoDB。Jaeger还附带了一个简单的内存存储区,用于测试设置。
现代化的UI
Jaeger Web UI是使用流行的开源框架(如React)以Javascript实现的。v1.0中发布了几项性能改进,以允许UI有效处理大量数据,并显示具有成千上万个跨度的跟踪(例如,我们尝试了具有80,000个跨度的跟踪)。
云原生部署
Jaeger后端作为Docker映像的集合进行分发。这些二进制文件支持各种配置方法,包括命令行选项,环境变量和多种格式(yaml,toml等)的配置文件。Kubernetes模板和Helm图表有助于将其部署到Kubernetes集群。
可观察性
默认情况下,所有Jaeger后端组件都公开Prometheus指标(也支持其他指标后端)。使用结构化日志库zap将日志写到标准输出。
安全
Jaeger的第三方安全审核可在https://github.com/jaegertracing/security-audits 中获得。有关Jaeger中可用安全机制的摘要,请参见问题#1718。
与Zipkin的向后兼容性
尽管我们建议使用OpenTracing API来对应用程序进行检测并绑定到Jaeger客户端库,以从其他地方无法获得的高级功能中受益,但是如果您的组织已经使用Zipkin库对检测进行了投资,则不必重写所有代码。Jaeger通过在HTTP上接受Zipkin格式(Thrift或JSON v1 / v2)的跨度来提供与Zipkin的向后兼容性。从Zipkin后端切换只是将流量从Zipkin库路由到Jaeger后端的问题。
安装部署
开始多合一的最简单方法是使用发布到DockerHub的预构建映像(单个命令行)。
docker run -d --name jaeger \
-e COLLECTOR_ZIPKIN_HTTP_PORT=9411 \
-p 5775:5775/udp \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 14268:14268 \
-p 9411:9411 \
jaegertracing/all-in-one:1.14
Or run the jaeger-all-in-one(.exe) executable from the binary distribution archives:
jaeger-all-in-one --collector.zipkin.http-port=9411
You can then navigate to http://localhost:16686 to access the Jaeger UI.
架构
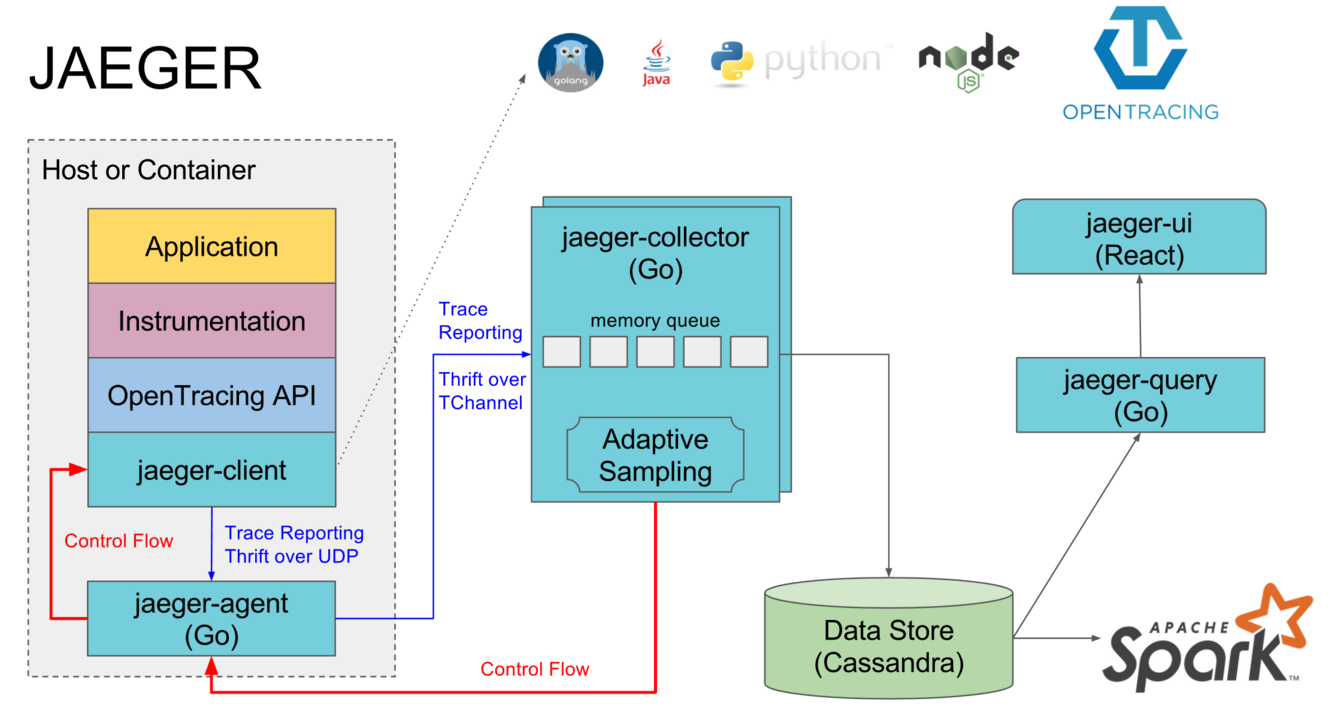
整体可以分为四个部分:
- jaeger-client:Jaeger 的客户端,实现了 OpenTracing 的 API,支持主流编程语言。客户端直接集成在目标 Application 中,其作用是记录和发送 Span 到 Jaeger Agent。在 Application 中调用 Jaeger Client Library 记录 Span 的过程通常被称为埋点。
- jaeger-agent:暂存 Jaeger Client 发来的 Span,并批量向 Jaeger Collector 发送 Span,一般每台机器上都会部署一个 Jaeger Agent。官方的介绍中还强调了 Jaeger Agent 可以将服务发现的功能从 Client 中抽离出来,不过从架构角度讲,如果是部署在 Kubernetes 或者是 Nomad 中,Jaeger Agent 存在的意义并不大。
- jaeger-collector:接受 Jaeger Agent 发来的数据,并将其写入存储后端,目前支持采用 Cassandra 和 Elasticsearch 作为存储后端。个人还是比较推荐用 Elasticsearch,既可以和日志服务共用同一个 ES,又可以使用 Kibana 对 Trace 数据进行额外的分析。架构图中的存储后端是 Cassandra,旁边还有一个 Spark,讲的就是可以用 Spark 等其他工具对存储后端中的 Span 进行直接分析。
- jaeger-query & jaeger-ui:读取存储后端中的数据,以直观的形式呈现。