以下是Golang GC算法的里程碑:
v1.1 STW(停止所有运行时)
v1.3 Mark(标记) STW(停止所有运行时), Sweep(清除) 并行
v1.5 三色标记法
v1.8 三色标记法 + hybrid write barrier(混合屏障)
经典的GC算法有三种:引用计数(reference counting)、标记-清扫(mark & sweep)、复制收集(Copy and Collection)。 golang时基于标记-清扫(mark & sweep)的基础上进行改进的gc方法。
引用计数法
原理是在每个对象内部维护一个整数值,叫做这个对象的引用计数,当对象被引用时引用计数加一,当对象不被引用时引用计数减一。当引用计数为 0 时,自动销毁对象。
目前引用计数法主要用在 c++ 标准库的 std::shared_ptr 、微软的 COM 、Objective-C 和 PHP 中。
但是引用计数法有个缺陷就是不能解决循环引用的问题。循环引用是指对象 A 和对象 B 互相持有对方的引用。这样两个对象的引用计数都不是 0 ,因此永远不能被收集。
另外的缺陷是,每次对象的赋值都要将引用计数加一,增加了消耗。
标记-清扫(mark & sweep)
此算法主要有两个主要的步骤:
第一步,找出不可达的对象,然后做上标记。
第二步,回收标记好的对象。
操作非常简单,但是有一点需要额外注意: mark and sweep 算法在执行的时候,需要程序暂停即 stop the world 。
也就是说,这段时间程序会阻塞在gc的时候。
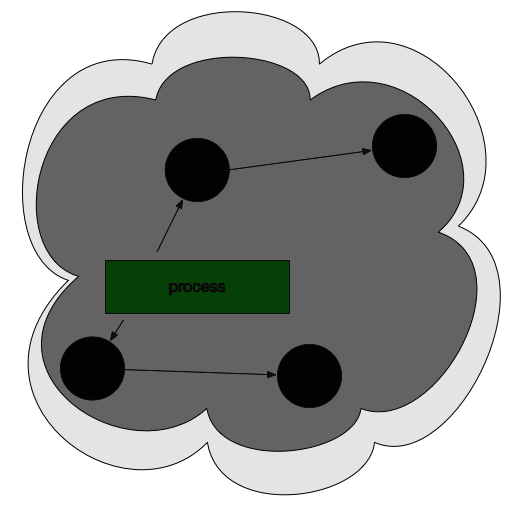
我们来看一下图解:
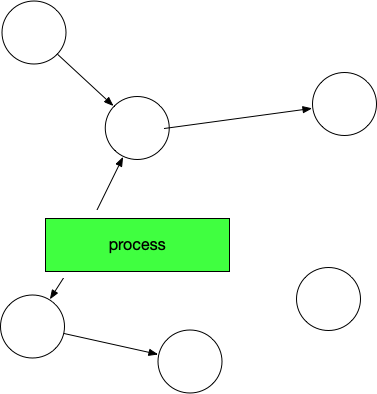
开始标记,程序暂停。程序和对象的此时关系是这样的:
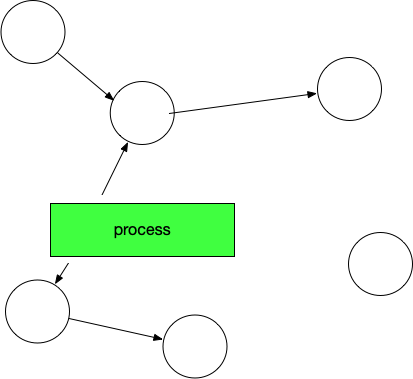
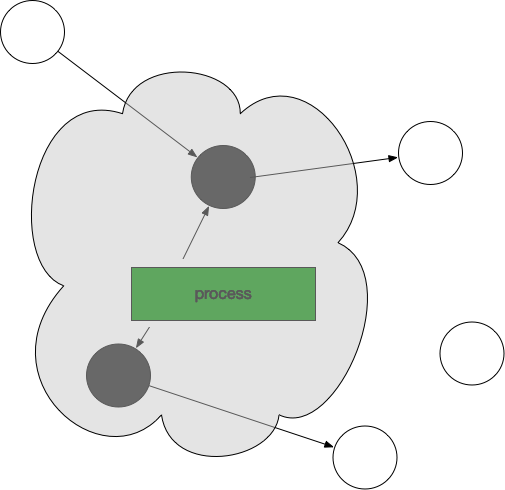
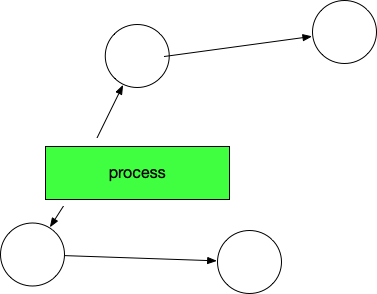
然后开始标记,process找出它所有可达的对象,并做上标记。如下图所示:
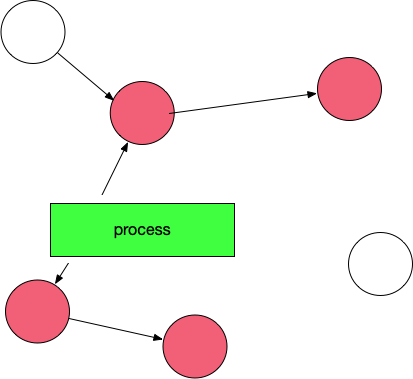
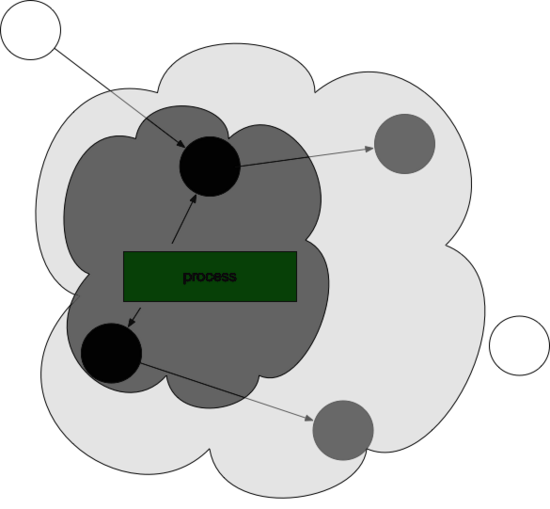
标记完了之后,然后开始清除未标记的对象:
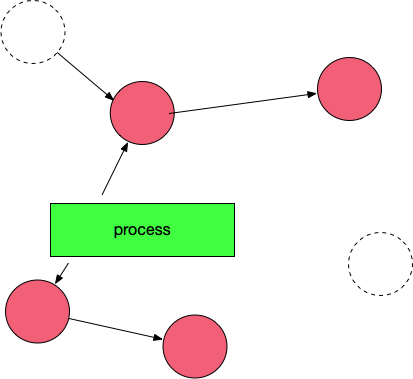
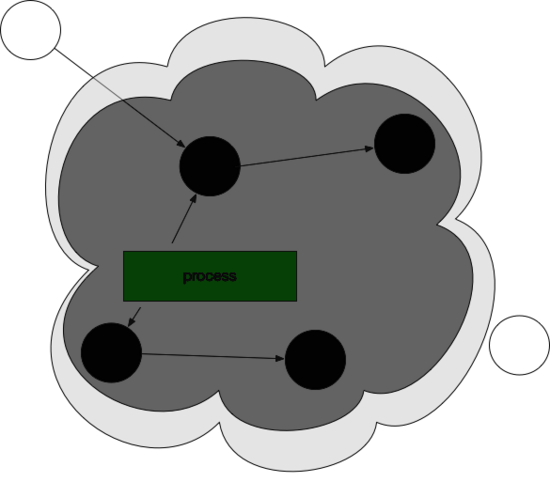
然后 垃圾 清除了,变成了下图这样。
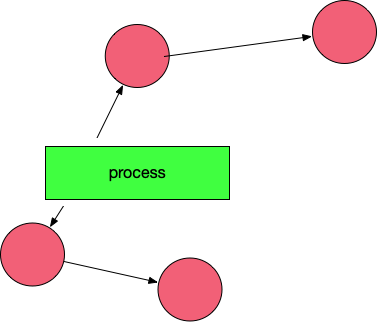
最后,停止暂停,让程序继续跑。然后循环重复这个过程,直到 process 生命周期结束。
标记-清扫(Mark And Sweep)算法存在什么问题?
标记-清扫(Mark And Sweep)算法 这种算法虽然非常的简单,但是还存在一些问题:
- STW,stop the world;让程序暂停,程序出现卡顿。
- 标记需要扫描整个heap
- 清除数据会产生heap碎片
这里面最重要的问题就是:mark-and-sweep 算法会暂停整个整个程序。
Go是如何面对并这个问题的呢?三色并发标记法+混合屏障
三色并发标记法
这个算法可以实现 “on-the-fly”,也就是在程序执行的同时进行收集,并不需要暂停整个程序。
我们先来看看Golang的三色标记法的大体流程。
首先:程序创建的对象都标记为白色。
gc开始:扫描所有可到达的对象,标记为灰色
从灰色对象中找到其引用对象标记为灰色,把灰色对象本身标记为黑色
监视对象中的内存修改,并持续上一步的操作,直到灰色标记的对象不存在
此时,gc回收白色对象。
最后,将所有黑色对象变为白色,并重复以上所有过程。
好了,大体的流程就是这样的。
但是三色标记法是一定要依赖STW的. 因为如果不暂停程序, 程序的逻辑改变对象引用关系, 这种动作如果在标记阶段做了修改,会影响标记结果的正确性。
比如
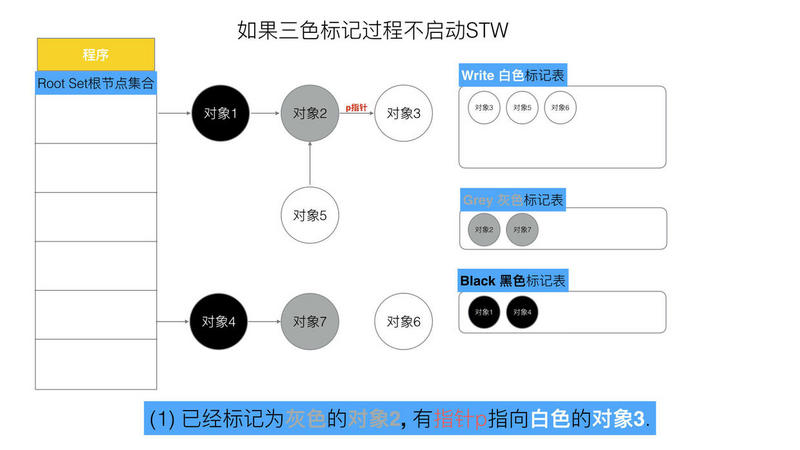
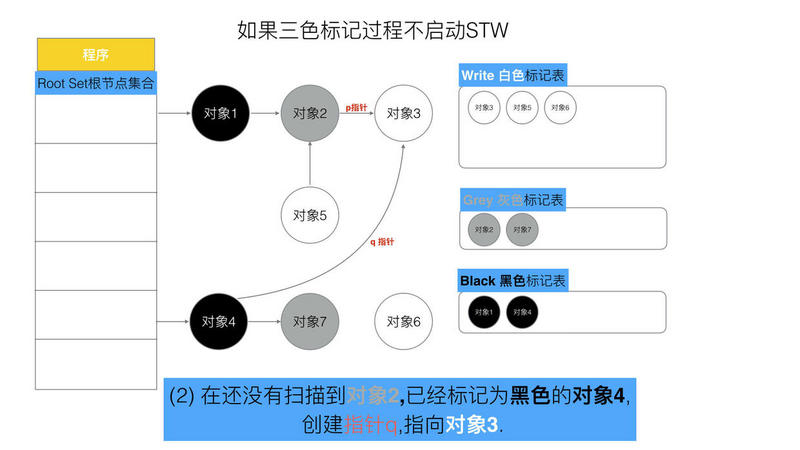
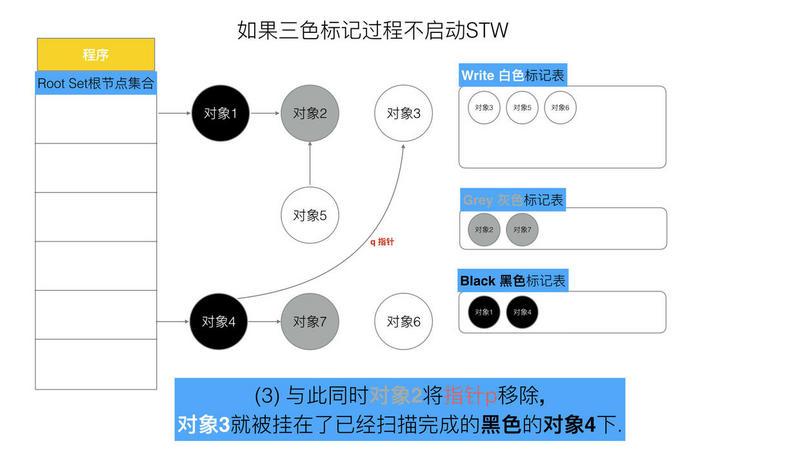
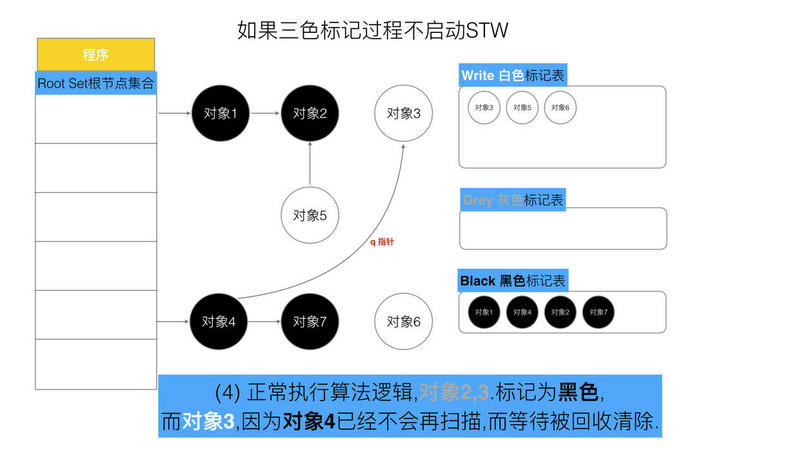
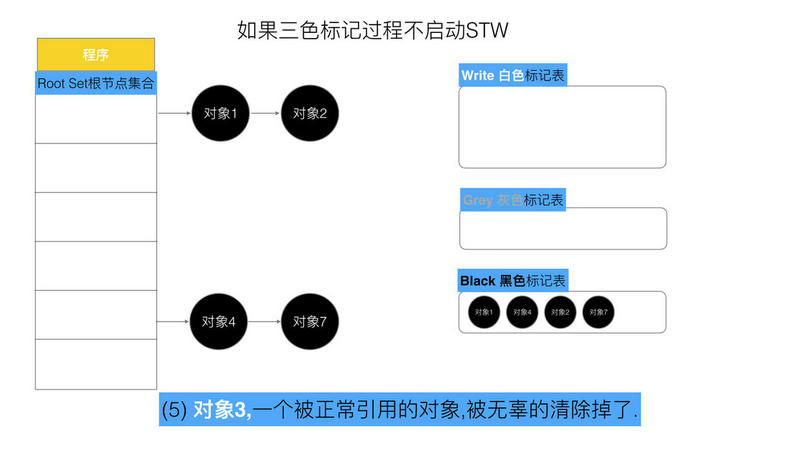
可以看出,有两个问题, 在三色标记法中,是不希望被发生的
条件1: 一个白色对象被黑色对象引用(白色被挂在黑色下)
条件2: 灰色对象与它之间的可达关系的白色对象遭到破坏(灰色同时丢了该白色)
当以上两个条件同时满足时, 就会出现对象丢失现象!
为了防止这种现象的发生,最简单的方式就是STW,直接禁止掉其他用户程序对对象引用关系的干扰,但是STW的过程有明显的资源浪费,对所有的用户程序都有很大影响,如何能在保证对象不丢失的情况下合理的尽可能的提高GC效率,减少STW时间呢?
答案就是, 那么我们只要使用一个机制,来破坏上面的两个条件就可以了.也就是引入来屏障机制
屏障机制
我们让GC回收器,满足下面两种情况之一时,可保对象不丢失. 所以引出两种方式.
“强-弱” 三色不变式
不存在黑色对象引用到白色对象的指针。
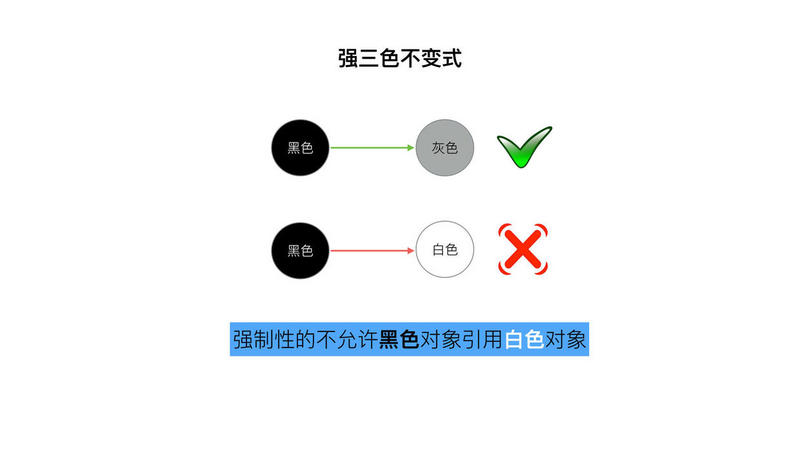
所有被黑色对象引用的白色对象都处于灰色保护状态.
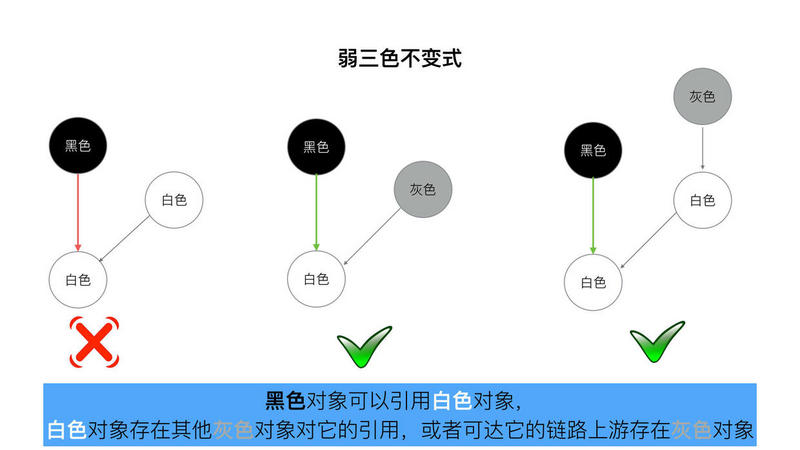
为了遵循上述的两个方式,Golang团队初步得到了如下具体的两种屏障方式“插入屏障”, “删除屏障”.
插入屏障
具体操作: 在A对象引用B对象的时候,B对象被标记为灰色。(将B挂在A下游,B必须被标记为灰色)
满足: 强三色不变式. (不存在黑色对象引用白色对象的情况了, 因为白色会强制变成灰色)
伪码如下:
添加下游对象(当前下游对象slot, 新下游对象ptr) {
//1
标记灰色(新下游对象ptr)
//2
当前下游对象slot = 新下游对象ptr
}
场景:
A.添加下游对象(nil, B) //A 之前没有下游, 新添加一个下游对象B, B被标记为灰色
A.添加下游对象(C, B) //A 将下游对象C 更换为B, B被标记为灰色
这段伪码逻辑就是写屏障,. 我们知道,黑色对象的内存槽有两种位置, 栈和堆. 栈空间的特点是容量小,但是要求相应速度快,因为函数调用弹出频繁使用, 所以“插入屏障”机制,在栈空间的对象操作中不使用. 而仅仅使用在堆空间对象的操作中.
删除屏障
具体操作: 被删除的对象,如果自身为灰色或者白色,那么被标记为灰色。
满足: 弱三色不变式. (保护灰色对象到白色对象的路径不会断)
伪代码:
添加下游对象(当前下游对象slot, 新下游对象ptr) {
//1
if (当前下游对象slot是灰色 || 当前下游对象slot是白色) {
标记灰色(当前下游对象slot) //slot为被删除对象, 标记为灰色
}
//2
当前下游对象slot = 新下游对象ptr
}
场景:
A.添加下游对象(B, nil) //A对象,删除B对象的引用。 B被A删除,被标记为灰(如果B之前为白)
A.添加下游对象(B, C) //A对象,更换下游B变成C。 B被A删除,被标记为灰(如果B之前为白)
让我们回到刚才的问题:Go是如何解决 标记-清除(mark and sweep) 算法中的卡顿(stw,stop the world)问题的呢?就是gc和用户逻辑如何并行操作,减少stw的操作
标记-清除(mark and sweep)算法的STW(stop the world)操作,就是runtime把所有的线程全部冻结掉,所有的线程全部冻结意味着用户逻辑是暂停的。这样所有的对象都不会被修改了,这时候去扫描是绝对安全的。
Go如何减短这个过程呢?标记-清除(mark and sweep)算法包含两部分逻辑:标记和清除。
我们知道Golang三色标记法中最后只剩下的黑白两种对象,黑色对象是程序恢复后接着使用的对象,如果不碰触黑色对象,只清除白色的对象,还有删除保障,肯定不会影响程序逻辑。所以: 清除操作和用户逻辑可以并发。
标记操作和用户逻辑也是并发的,用户逻辑会时常生成对象或者改变对象的引用,就是使用写入保障,标记和用户逻辑就可以并发。
比如
process新生成对象的时候,GC该如何操作呢?不会乱吗?
我们看如下图,在此状态下:process程序又新生成了一个对象,我们设想会变成这样:
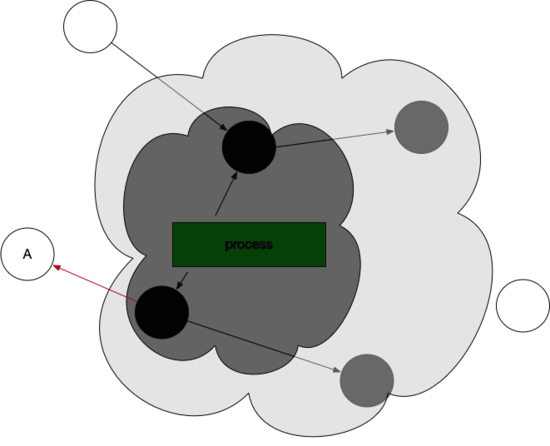
但是这样显然是不对的,因为按照三色标记法的步骤,这样新生成的对象A最后会被清除掉,这样会影响程序逻辑。
Golang为了解决这个问题,引入了 写屏障 这个机制。
写屏障:该屏障之前的写操作和之后的写操作相比,先被系统其它组件感知。
通俗的讲:就是在gc跑的过程中,可以监控对象的内存修改,并对对象进行重新标记。(实际上也是超短暂的stw,然后对对象进行标记)
在上述情况中, 新生成的对象,一律都标位灰色!
即下图:
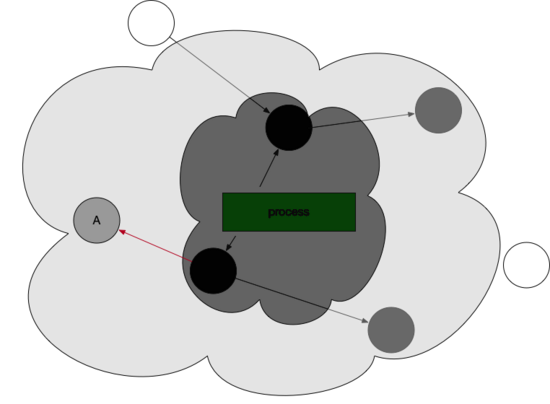
那么,灰色或者黑色对象的引用改为白色对象的时候,Golang是该如何操作的?
看如下图,一个黑色对象引用了曾经标记的白色对象。
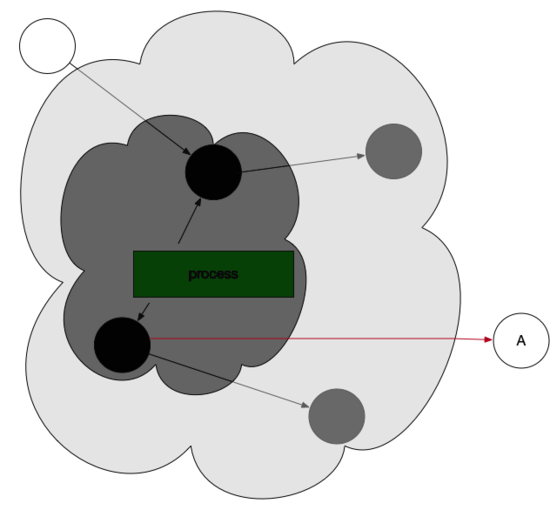
这时候,写屏障机制被触发,向GC发送信号,GC重新扫描对象并标位灰色。
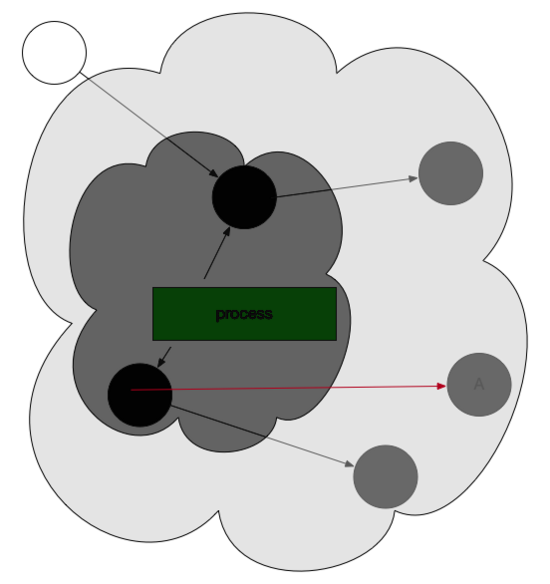
因此,gc一旦开始,无论是创建对象还是对象的引用改变,都会先变为灰色。
触发时机
- gcTriggerAlways: 强制触发GC,没找到什么情况下使用这个
- gcTriggerHeap: 当前分配的内存达到一定值(动态计算)就触发GC
- gcTriggerTime: 当一定时间(2分钟)没有执行过GC就触发GC
- gcTriggerCycle: 要求启动新一轮的GC, 已启动则跳过, 手动触发GC的runtime.GC()会使用这个条件,我们经常在代码中会使用这个来触发强制gc。
调试
GODEBUG=gctrace=1 在运行二进制文件的时候加上这个环境变量可以直接在终端查看相关gc信息。如下
gc 45 @37.801s 11%: 0.19+627+0.29 ms clock, 0.38+424/621/0+0.59 ms cpu, 356->415->225 MB, 453 MB goal, 4 P
- gc 45:表示第45次GC,共有4个P (线程)参与GC。
- @37.801s:表示程序执行的总时间
- 11%: 表示gc 占时间比。
- 0.19+627+0.29 us clock:STW(stop-the-world)0.19ms, 并发标记和扫描的时间627ms, STW标记的时间0.29ms。表示第一次STW + 标记(Marking) + 第二次STW的时钟时间,单位是ms。比如0.006+39+0.004 ms clock,表示第一次STW持续的时间时钟时间是0.006ms,第二次STW持续的时钟时间是0.004ms,标记Marking处理持续的时钟时间是39ms;
- 0.38+424/621/0+0.59 ms cpu, 表示垃圾回收占用cpu时间。表示第一次STW + Mark assist/Mark(Dedicated + Fractional)/Mark(Idle) + 第二次STW的CPU时间。与时钟时间的统计不同,CPU时间会对各个核上对应的处理时间进行累加。比如0.006+36⁄2.2⁄0+0.004 ms cpu,0.006ms表示第一次STW过程中,被STW的多个核的时钟时间之和,其值大于等于对应时钟时间。36ms表示在整个Mark过程中,进行assist Mark的CPU累计时间。2.2ms表示在整个Mark过程中,在gcMarkWorkerDedicatedMode和gcMarkWorkerFractionalMode两种工作模式下进行Mark处理的CPU累计时间之和。0.8ms表示在gcMarkWorkerIdleMode模式下进行Mark处理的CPU累计时间之和。0.004ms表示第二次被STW的多个核的时钟时间之和;
- 356->415->225 MB, 453 MB goal,表示堆的大小,gc后堆的大小,存活堆的大小。表示GC开始前申请的内存大小 -> GC标记(Mark)结束后申请的内存大小 -> 被标记存活的内存大小。比如420->435->210 MB,表示GC开始前一共申请了420MB的内存,GC标记(Mark)处理完后一共申请了435MB的内存,也就说在整个标记阶段,又新申请了15MB的内存,标记阶段一共标记了210MB的内存,就是说有435MB-210MB=225MB的内存可以被回收;
- 453 MB goal 表示整体堆的大小为435M。目标堆大小,也就是下一次GC的大小
- 4 P:占用核个数
根据官方描述,golang1.0 的gc 可以降到100ms 以内,但是这里gc 都超过1s了,这明显是不可以接受的,说明gc 是有很大异常的。
检查思路,首先利用pprof 打出整个调用过程累计的堆分配图,查出到底是哪些模块堆分配异常。通过代码内嵌pprof 暴露端口的方式,终端输出svg。
然后终端输入:
go tool pprof -alloc_space -cum -svg http://127.0.0.1:8080/debug/pprof/heap > heap.svg
就可以找到对应的资源消耗所在了。
Golang 是 runtime 时定期或满足条件时并行执行回收器,也可以在代码中显示调用 runtime.GC(),显示调用会阻塞整个程序直到垃圾回收完成;
gc调优
Go 的 GC 被设计为极致简洁,与较为成熟的 Java GC 的数十个可控参数相比,严格意义上来讲,Go 可供用户调整的参数只有 GOGC 环境变量,所以我们优化的方向只有
- 减少用户代码对 GC 产生的压力,这一方面包含了减少用户代码分配内存的数量(即对程序的代码行为进行调优)
- 最小化 Go 的 GC 对 CPU 的使用率(即调整 GOGC)。
从这两点来看,所谓 GC 调优的核心思想也就是充分的围绕上面的两点来展开:优化内存的申请速度,尽可能的少申请内存,复用已申请的内存。或者简单来说,不外乎这三个关键字:控制、减少、复用。
合理化内存分配、提高CPU 利用率
合理化内存分配的速度
我们来看这样一个例子。在这个例子中,concat 函数负责拼接一些长度不确定的字符串。并且为了快速完成任务,出于某种原因,在两个嵌套的 for 循环中一口气创建了 800 个 goroutine。在 main 函数中,启动了一个 goroutine 并在程序结束前不断的触发 GC,并尝试输出 GC 的平均执行时间:
package main
import (
"fmt"
"os"
"runtime"
"runtime/trace"
"sync/atomic"
"time"
)
var (
stop int32
count int64
sum time.Duration
)
func concat() {
for n := 0; n < 100; n++ {
for i := 0; i < 8; i++ {
go func() {
s := "Go GC"
s += " " + "Hello"
s += " " + "World"
_ = s
}()
}
}
}
func main() {
f, _ := os.Create("trace.out")
defer f.Close()
trace.Start(f)
defer trace.Stop()
go func() {
var t time.Time
for atomic.LoadInt32(&stop) == 0 {
t = time.Now()
runtime.GC()
sum += time.Since(t)
count++
}
fmt.Printf("GC spend avg: %v\n", time.Duration(int64(sum)/count))
}()
concat()
atomic.StoreInt32(&stop, 1)
}
这个程序的执行结果是:
$ go build -o main
$ ./main
GC spend avg: 2.583421ms
GC 平均执行一次需要长达 2ms 的时间,goroutine 的执行时间占其生命周期总时间非常短的一部分,但大部分时间都花费在调度器的等待上了,说明同时创建大量 goroutine 对调度器产生的压力确实不小,我们不妨将这一产生速率减慢,一批一批地创建 goroutine:
func concat() {
wg := sync.WaitGroup{}
for n := 0; n < 100; n++ {
wg.Add(8)
for i := 0; i < 8; i++ {
go func() {
s := "Go GC"
s += " " + "Hello"
s += " " + "World"
_ = s
wg.Done()
}()
}
wg.Wait()
}
}
这时候我们再来看:
$ go build -o main
$ ./main
GC spend avg: 328.54µs
GC 的平均时间就降到 300 微秒了。这时的赋值器 CPU 使用率也提高到了 60%,相对来说就很可观了。
降低并复用已经申请的内存
我们通过一个非常简单的 Web 程序来说明复用内存的重要性。在这个程序中,每当产生一个 /example2的请求时,都会创建一段内存,并用于进行一些后续的工作。
package main
import (
"fmt"
"net/http"
_ "net/http/pprof"
)
func newBuf() []byte {
return make([]byte, 10<<20)
}
func main() {
go func() {
http.ListenAndServe("localhost:6060", nil)
}()
http.HandleFunc("/example2", func(w http.ResponseWriter, r *http.Request) {
b := newBuf()
// 模拟执行一些工作
for idx := range b {
b[idx] = 1
}
fmt.Fprintf(w, "done, %v", r.URL.Path[1:])
})
http.ListenAndServe(":8080", nil)
}
这时候我们使用一个压测工具 ab,来同时产生 500 个请求(-n 一共 500 个请求,-c 一个时刻执行请求的数量,每次 100 个并发请求),GC 反复被触发,一个显而易见的原因就是内存分配过多。我们可以通过 go tool pprof 来查看究竟是谁分配了大量内存(使用 web 指令来使用浏览器打开统计信息的可视化图形),可见 newBuf 产生的申请的内存过多,现在我们使用 sync.Pool 来复用 newBuf 所产生的对象:
package main
import (
"fmt"
"net/http"
_ "net/http/pprof"
"sync"
)
// 使用 sync.Pool 复用需要的 buf
var bufPool = sync.Pool{
New: func() interface{} {
return make([]byte, 10<<20)
},
}
func main() {
go func() {
http.ListenAndServe("localhost:6060", nil)
}()
http.HandleFunc("/example2", func(w http.ResponseWriter, r *http.Request) {
b := bufPool.Get().([]byte)
for idx := range b {
b[idx] = 0
}
fmt.Fprintf(w, "done, %v", r.URL.Path[1:])
bufPool.Put(b)
})
http.ListenAndServe(":8080", nil)
}
但从 Requests per second 每秒请求数来看,从原来的 506.63 变为 1171.32 得到了近乎一倍的提升。从 trace 的结果来看,GC 也没有频繁的被触发从而长期消耗 CPU 使用率。
调整 GOGC
我们已经知道了 GC 的触发原则是由步调算法来控制的,其关键在于估计下一次需要触发 GC 时,堆的大小。可想而知,如果我们在遇到海量请求的时,为了避免 GC 频繁触发,是否可以通过将 GOGC 的值设置得更大,让 GC 触发的时间变得更晚,从而减少其触发频率,进而增加用户代码对机器的使用率。
GOGC代表了占用中的内存增长比率,达到该比率时应当触发1次GC,该参数可以通过环境变量设置。GOGC参数取值为整数,默认值是100,单位是百分比。假如当前heap占用内存为4MB,GOGC = 75,
4 * (1+75%) = 7MB
等heap占用内存大小达到7MB时会触发1轮GC。GOGC还有2个特殊值:
- “off” : 代表关闭GC
- 0 : 代表持续进行垃圾回收,只用于调试
我们可以非常简单粗暴的将 GOGC 调整为 1000,来执行上一个例子中未复用对象之前的程序:
$ GOGC=1000 ./main
当然我们也可以直接设置环境变量为1000,可以测试,压测的结果得到了一定幅度的改善(Requests per second 从原来的 506.63 提高为了 541.61),并且 GC 的执行频率明显降低
在实际实践中可表现为需要紧急处理一些由 GC 带来的瓶颈时,人为将 GOGC 调大,加钱加内存,扛过这一段峰值流量时期。
当然,这种做法其实是治标不治本,并没有从根本上解决内存分配过于频繁的问题,极端情况下,反而会由于 GOGC 太大而导致回收不及时而耗费更多的时间来清理产生的垃圾,这对时间不算敏感的应用还好,但对实时性要求较高的程序来说就是致命的打击了。
如果程序一段时间内驻留内存飙升,并且GC没法立马把这些内存给回收,那么会导致下一次GC的阈值上去,压根没法触发GC,程序肯定会OOM的。这个很显而易见的问题,我都能想到,golang应该不会考虑不到啊,果然在golang 的blog里面https://blog.golang.org/ismmkeynote
目前官方针对这一个问题还没有明确的解决方案,因此这时更妥当的做法仍然是,定位问题的所在,并从代码层面上进行优化。