学习使用go语言已经有一段时间了,积累了很多的经验,这边进行不断接触的知识点进行零散的整理并持续积累,也便于后期的备忘。
为什么使用go?
1、相对于c/c++开发来说,go的封装和丰富的标准库,极大的提高了开发的效率。基本的服务端开发都可以使用golang来开发。
2、go的编译和执行效率相对来说很快,部署也很简单
3、go原生支持高并发这块也是很优秀的。
主要使用领域:微服务解决方案(istio),云平台(k8s),web服务(各种web框架,http原生支持并发)—服务端(高并发),区块链,分布式(存储,推送系统)
Go语言的三位最初的缔造者 — Rob Pike、Robert Griesemer 和 Ken Thompson 中,Robert Griesemer 参与设计了Java的HotSpot虚拟机和Chrome浏览器的JavaScript V8引擎,Rob Pike 在大名鼎鼎的bell lab侵淫多年,参与了Plan9操作系统、C编译器以及多种语言编译器的设计和实现,Ken Thompson 更是图灵奖得主、Unix之父、C语言之父。这三人在计算机史上可是元老级别的人物,特别是 Ken Thompson ,是一手缔造了Unix和C语言计算机领域的上古大神,所以Go语言的设计哲学有着深深的Unix烙印:简单、模块化、正交、组合、pipe、功能短小且聚焦等;而令许多开发者青睐于Go的简洁、高效编程模式的原因,也正在于此。
语言设计
传统的面向过程的语言开发,编译器其中最最基础和原始的目标之一就是把一份代码里的函数名称,转化成一个相对内存地址,把调用这个函数的语句转换成一个jmp跳转指令。在程序开始运行时候,调用语句可以正确跳转到对应的函数地址。直白,但是。。。太死板了
我们希望灵活,于是需要开发面向对象的语言,c++在c的基础上增加了类的部分,就是让编译器多绕个弯,在严格的c编译器上增加一层类处理的机制,把一个函数限制在它处在的class环境里,每次请求一个函数调用,先找到它的对象, 其类型,返回值,参数等等,确定了这些后再jmp跳转到需要的函数。这样很多程序增加了灵活性同样一个函数调用会根据请求参数和类的环境返回完全不同的结果。增加类机制后,就模拟了现实世界的抽象模式,不同的对象有不同的属性和方法。同样的方法,不同的类有不同的行为,还是死板, 我们仍然叫c++是static language。
runtime环境注册所有全局的类,函数,变量等等信息等等,我们可以无限的为这个层增加必要的功能。调用函数时候,会先从这个运行时环境里检测所以可能的参数再做jmp跳转,这就是runtime。编译器开发起来比上面更加弯弯绕。但是这个层极大增加了程序的灵活性。
尽管 Go 编译器产生的是本地可执行代码,这些代码仍旧运行在 Go 的 runtime(这部分的代码可以在 runtime 包中找到)当中。这个 runtime 类似 Java 和 .NET 语言所用到的虚拟机,它负责管理包括内存分配、垃圾回收、栈处理、goroutine、channel、切片(slice)、map 和反射(reflection)等等。
runtime 主要由 C 语言编写(Go 1.5 开始自举),并且是每个 Go 包的最顶级包。你可以在目录 $GOROOT/src/runtime 中找到相关内容。
基础语法
go语言的所有源代码都必须由unicode编码规范的UTF-8编码格式进行编码。下面是基础语法。
变量
1.用关键字var来声明
2.可以类型判断
var i = 10支持多返回值,改进了c中笨拙的语言风格
3.支持多重赋值
var width, height int = 100, 50 // 声明多个变量
i,j = j,i这样就完成了交换。
4.可以直接用:=这个服务声明初始化,但必须不是声明过的。
a := 10类似于
var i int
i = 10;
5.:= 符号不能使用在函数外,在函数外必须要var进行声明。
6.像err这种可以重复使用:=来定义,即使被声明过,但是要满足以下条件:
- 该变量在一个作用域内
- 初始化中相应的值是可以赋给这个变量的
- 声明中至少有一个其他的变量是被声明的新的变量
7.支持匿名变量
func getname()(firstname,lastname,nickname){
}
调用可以用_来表达我们不想要的变量--->_,_,nickname := getname();
常量
1.iota 一个特殊的常量,出现一次自动加一,当出现const的时候会自动置零
const (
A = iota //0
B //1
C = "a" //a
D //a
E = iota //4
F //5
)
2.常量不能使用 := 语法定义
3.枚举类型不需要enum
正常定义
const(
Sunday = iota
monday
)
其中的大写字母开头的在包外可用,小写字母开头的包内私有
我们可以使用下划线跳过不想要的值。
type AudioOutput int
const (
OutMute AudioOutput = iota // 0
OutMono // 1
OutStereo // 2
_
_
OutSurround // 5
)
4.常量的定义格式:
const identifier [type] = value
[type]类型可以省略,编译器可以根据变量的值来推断其类型.
显示类型 const b string = "abc"
隐式类型 const b = "abc"
运算符
Go 编程语言支持以下按位运算符:
& bitwise AND
| bitwise OR
^ bitwise XOR
&^ AND NOT
<< left shift
>> right shift
& 运算符
在 Go 中, & 运算符在两个整型操作数中执行按位 AND 操作。AND 操作具有以下属性,只要有一个失败就是false:
func main() {
var x uint8 = 0xAC // x = 10101100
x = x & 0xF0 // x = 10100000
}
所有的位运算都支持简写的赋值形式。 例如,前面的例子可以重写为如下。
func main() {
var x uint8 = 0xAC // x = 10101100
x &= 0xF0 // x = 10100000
}
另外一个巧妙的技巧是:你可以用 & 操作去测试一个数字是奇数还是偶数。原因是当一个数字的二进制的最低位是 1 的时候,那他就是奇数。我们可以用一个数字和 1 进行 & 操作,如果的到的结果是 1 ,那么这个原始的数字就是奇数
import (
"fmt"
"math/rand"
)
func main() {
for x := 0; x < 100; x+>{
num := rand.Int()
if num&1 == 1 {
fmt.Printf("%d is odd\n", num)
} else {
fmt.Printf("%d is even\n", num)
}
}
}
| 操作符
| 对其整型操作数执行按位或操作。回想一下或(OR)操作符具备以下性质,只有有一个成立就是true:
func main() {
var a uint8 = 0
a |= 196
fmt.Printf("%b", a)
}
// 打印结果 11000100
在使用位掩码技术为给定的整型数字设置任意位时,或运算非常有用。
位运算的配置用法
我们可以结合使用 OR 和 AND 运算的方式来分别设置和读取某位的配置值。接下来的源码片段演示了这个操作。函数 procstr 会转换字符串的内容。它需要两个参数:第一个, str,是将要被转换的字符串,第二个, conf,是一个使用位掩码的方式指定多重转换配置的整数。
const (
UPPER = 1 // 大写字符串
LOWER = 2 // 小写字符串
CAP = 4 // 字符串单词首字母大写
REV = 8 // 反转字符串
)
func main() {
fmt.Println(procstr("HELLO PEOPLE!", LOWER|REV|CAP))
}
func procstr(str string, conf byte) string {
// 反转字符串
rev := func(s string) string {
runes := []rune(s)
n := len(runes)
for i := 0; i < n/2; i+>{
runes[i], runes[n-1-i] = runes[n-1-i], runes[i]
}
return string(runes)
}
// 查询配置中的位操作
if (conf & UPPER) != 0 {
str = strings.ToUpper(str)
}
if (conf & LOWER) != 0 {
str = strings.ToLower(str)
}
if (conf & CAP) != 0 {
str = strings.Title(str)
}
if (conf & REV) != 0 {
str = rev(str)
}
return str
}
上面的 procstr(“HELLO PEOPLE!”, LOWER|REV|CAP) 方法会把字符串变成小写,然后反转字符串,最后把字符串里面的单词首字母变成大写。这个功能是通过设置 conf 里的第二,三,四位的值为 14 来完成的。然后代码使用连续的 if 语句块来获取这些位操作进行对应的字符串转换。
^ 操作符
在 Go 中 按位 异或 操作是用 ^ 来表示的。 异或运算符有如下的特点,相同为false,相异为true,也叫不进位加法:
func main() {
var a uint16 = 0xCEFF
a ^= 0xFF00 // same a = a ^ 0xFF00
}
// a = 0xCEFF (11001110 11111111)
// a ^=0xFF00 (11001110 11111111 + 1111111100000000 = 00110001 11111111)
在前面的代码片段中,与 1 进行异或的位被翻转(从 0 到 1 或从 1 到 0)。
异或 运算的一个实际用途,例如,可以利用 异或运算去比较两个数字的符号是否一样。当 (a ^ b) ≥ 0 (或相反符号的 (a ^ b) < 0 )为 true 的时候,两个整数 a,b 具有相同的符号,如下面的程序所示:
func main() {
a, b := -12, 25
fmt.Println("a and b have same sign?", (a ^ b) >= 0)
}
当执行上面这个程序的时候,将会打印出:a and b have same sign? false。
^ 作为取反位运算符 (非)
不像其他语言 (c/c++,Java,Python,Javascript等可能使用~取反), Go 没有专门的一元取反位运算符。取而代之的是,XOR 运算符 ^,也可作为一元取反运算符作用于一个数字。对于给定位 x,在 Go 中 x = 1 ^ x 可以翻转该位。在以下的代码段中我们可以看到使用 ^a 获取变量 a 的取反值的操作。
func main() {
var a byte = 0x0F
fmt.Printf("%08b\n", a)
fmt.Printf("%08b\n", ^a)
}
// 打印结果
00001111 // var a
11110000 // ^a
&^ 操作符
&^ 操作符意为 与非,是 与 和 非 操作符的简写形式,也就是先与操作再非操作。
接下来的代码片段使用 AND NOT 操作符,将变量值 1010 1011 变为 1010 0000,清除了操作数上的低四位。
func main() {
var a byte = 0xAB
fmt.Printf("%08b\n", a)
a &^= 0x0F
fmt.Printf("%08b\n", a)
}
// 打印:
10101011
10100000
<<和>> 操作符
与其他 C 的衍生语言类似, Go 使用 << 和 >> 来表示左移运算符和右移运算符,如下所示:
Given integer operands a and n,
a << n; shifts all bits in a to the left n times
a >> n; shifts all bits in a to the right n times
例如,在下面的代码片段中变量 a (00000011)的值将会左移位运算符分别移动三次。每次输出结果都是为了说明左移的目的。
func main() {
var a int8 = 3
fmt.Printf("%08b\n", a)
fmt.Printf("%08b\n", a<<1)
fmt.Printf("%08b\n", a<<2)
fmt.Printf("%08b\n", a<<3)
}
// 输出的结果:
00000011
00000110
00001100
00011000
注意每次移动都会将低位右侧补零。相对应,使用右移位操作符进行运算时,每个位均向右方移动,空出的高位补零,如下示例 (有符号数除外,参考下面的算术移位注释)。
func main() {
var a uint8 = 120
fmt.Printf("%08b\n", a)
fmt.Printf("%08b\n", a>>1)
fmt.Printf("%08b\n", a>>2)
}
// 打印:
01111000
00111100
00011110
可以利用左移和右移运算中,每次移动都表示一个数的 2 次幂这个特性,来作为某些乘法和除法运算的小技巧。例如,如下代码中,我们可以使用右移运算将 200(存储在变量 a 中)除以 2 。
func main() {
a := 200
fmt.Printf("%d\n", a>>1)
}
// 打印:
100
或是通过左移 2 位,将一个数乘以 4:
func main() {
a := 12
fmt.Printf("%d\n", a<<2)
}
// 打印:
48
位移运算符提供了有趣的方式处理二进制值中特定位置的值。例如,下列的代码中,| 和 << 用于设置变量 a 的第三个 bit 位。
func main() {
var a int8 = 8
fmt.Printf("%08b\n", a)
a = a | (1<<2)
fmt.Printf("%08b\n", a)
}
// prints:
00001000
00001100
或者,您可以组合位移运算符和 & 测试是否设置了第 n 位,如下面示例所示:
func main() {
var a int8 = 12
if a&(1<<2) != 0 {
fmt.Println("take action")
}
}
// 打印:
take action
使用 &^ 和位移运算符,我们可以取消设置一个值的某个位。例如,下面的示例将变量 a 的第三位置为 0 :
func main() {
var a int8 = 13
fmt.Printf("%04b\n", a)
a = a &^ (1 << 2)
fmt.Printf("%04b\n", a)
}
// 打印:
1101
1001
当要位移的值(左操作数)是有符号值时,Go 自动应用算术位移。在右移操作期间,复制(或扩展)二进制补码符号位以填充位移的空隙。
总结
与其它现代运算符一样,Go 支持所有二进制位操作运算符。这篇文章仅仅提供了可以用这些操作符完成的各种黑科技示例。你可以在网络上找到很多文章,特别是 Sean Eron Anderson写的 Bit Twiddling Hacks。
数组
数组其实是一段连续的内存,通过唯一索引下标(由于地址也是连续的,所以下标根据地址循序来就行,不需要存)来获取对应内存的值。
1、Go语言的数组不同于C语言或者其他语言的数组,C语言的数组变量是指向数组第一个元素的指针;而Go语言的数组是一个值,Go语言中的数组是值类型,一个数组变量就表示着整个数组,意味着Go语言的数组在传递的时候,传递的是原数组的拷贝。 重点是值类型,每次传参都是一个副本,要传址,需要用数组切片
2、遍历数组元素,除了用下标,也可以用关键字range,有两个返回值,一个是下标,一个是value,在对strings进行遍历的时候一个是下标,一个是ACSII
var a [10]int
var a = [10]int{0,1,2,3,4,5,6,7,8,9}
var a = [...]int{0,1,2,3,4,5,6,7,8,9}
var a = [2][2]int{[2]int{1,1}, [2]int{2,2}}
var a = [2][2]int{{1,1}, {2,2}}
3、Golang动态数组
数组申明
var dynaArr []string
动态添加成员
dynaArr = append(dynaArr, "one")
这边讲解一下append
就是将后面一个值拷贝一份到前面,如果是值就拷贝值,如果是地址就拷贝地址,所以当是地址的时候,源数据发现变化,append后的数据也会发生变化,变成重复的,所以传地址最好每次重新定义一个实例,或者就不要传输地址,定义一个实例就好。
实例
package main
import (
"fmt"
)
func main() {
var dynaArr []string
dynaArr = append(dynaArr, "one")
dynaArr = append(dynaArr, "two")
dynaArr = append(dynaArr, "three")
fmt.Println(dynaArr)
}
下面这个输出是0,0,0,0,0,1,2,3,可见初始化的也是占空间的,所以赋值需要make
func main() {
s := make([]int, 5)
s = append(s, 1, 2, 3)
fmt.Println(s)
}
4、结构体数组
package main
import (
"fmt"
)
type A struct{
Path string
Length int
}
func main() {
var dynaArr []A
t := A{"/tmp", 1023}
dynaArr = append(dynaArr, t)
dynaArr = append(dynaArr, A{"~", 2048})
t.Path, t.Length = "/", 4096
dynaArr = append(dynaArr, t)
fmt.Println(dynaArr)
}
注意大小写,大写为公有,小写为私有
5、数组切片
切片是一个很小的对象,是对数组进行了抽象,并提供相关的操作方法。切片有三个属性字段:长度、容量和指向数组的指针。
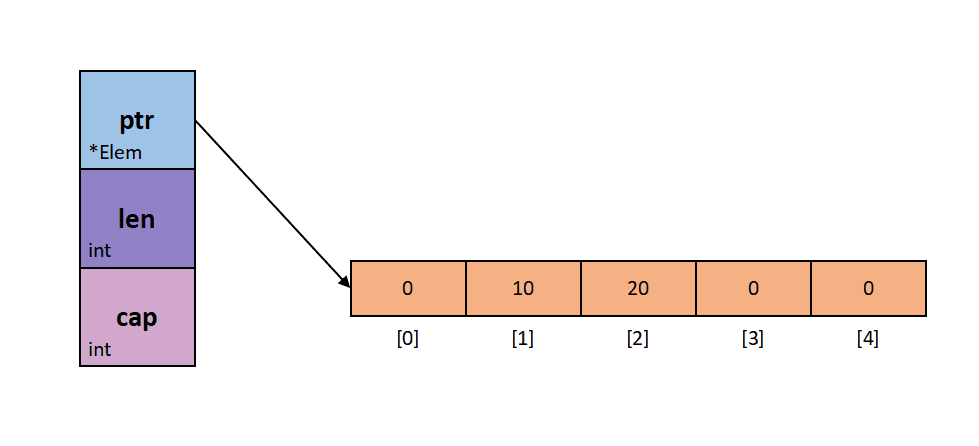
上图中,ptr指的是指向array的pointer,len是指切片的长度, cap指的是切片的容量。现在,我想你对数组和切片有了一个本质的认识。
切片是数组的指针管理,数组就是存储数据的
items := make([]interface{}, 0, len(proxyInfos))
items只是一个指针,当给他一个新地址的时候,就会指向新的空间,原来的对象在函数执行完以后,GC 就可以工作,把对象释放掉,但是如果像slice删除这种操作
return append(slice[:i], slice[i+1:]...)
还是指向原来的数组的地址,就可以读取到这个地址下分配的所有空间,就会出现数据多余的情况,所以只要把slice当成指针就很好理解了。
切记:slice是一个指针
创建
1、在一个数组的基础上用[:]来创建--golang slice对数组是址引用,同用一个地址空间,slice变化时,原数组是发生变化的。slice基于数组建立的也是一种引用,当slice改变的时候,原来的数组也会变化,但是当slice空间翻倍了,就会重新开辟一片空间,就不会互相影响变化了
2、直接用make函数创建
创建一个初始元素个数为5的数组切片,元素初始值为0:
mySlice1 := make([] int, 5)
创建一个初始元素个数为5的数组切片,元素初始值为0,并预留10个元素的存储空间:
mySlice2 := make([] int, 5, 10)
直接创建并初始化包含5个元素的数组切片:
mySlice3 := [] int{1, 2, 3, 4, 5}
求数组长度的函数区别
cap():分配的空间
len():所占的元素,实际数据的长度
copy():复制,以小的为准
切片优点
可以动态增减元素,原始数组增减数据是要重新分配内存,然后将数据搬过去,这样比较消耗性能,但是数据切片则可以用cap()知道分配的空间,然后充分利用,而后在内存不够会自动扩大内存。
package main
import "fmt"
func main() {
a := make([]byte,2)
b := make([]byte,4)
c := []byte{1,2,3,4}
b = c
a = c
fmt.Println(a,b,len(a),len(b),cap(a),cap(b))
}
$ go run slicedistribution.go
[1 2 3 4] [1 2 3 4] 4 4 4 4
通常我们我们还使用append,不用make来指定内存大小,直接在使用的时候就可以自动分配。
切片扩容请记住以下两条规则:
如果切片的容量小于1024个元素,那么扩容的时候slice的cap就翻番,乘以2;一旦元素个数超过1024个元素,增长因子就变成1.25,即每次增加原来容量的四分之一。
如果扩容之后,还没有触及原数组的容量,那么,切片中的指针指向的位置,就还是原数组,如果扩容之后,超过了原数组的容量,那么,Go就会开辟一块新的内存,把原来的值拷贝过来,这种情况丝毫不会影响到原数组。
实际上还有更加复杂的其他规则
append单个元素,或者append少量的多个元素,这里的少量指double之后的容量能容纳,这样就会走以下扩容流程,不足1024,双倍扩容,超过1024的,1.25倍扩容。
若是append多个元素,且double后的容量不能容纳,直接使用预估的容量。
敲重点!!!!此外,以上两个分支得到新容量后,均需要根据slice的类型size,算出新的容量所需的内存情况capmem,然后再进行capmem向上取整,得到新的所需内存,除上类型size,得到真正的最终容量,作为新的slice的容量。
最大值
slice的最大空间也是有限制的:The elements can be addressed by integer indices 0 through len(s)-1。这意味着 slice 的最大容量是目标版本上默认整数的大小。
关于切片的比较
切片之间不允许比较。切片只能与nil值比较。
map之间不允许比较。map只能与nil值比较。
那怎么比较切片
reflect比较的方法
func StringSliceReflectEqual(a, b []string) bool {
return reflect.DeepEqual(a, b)
}
循环遍历比较的方法
func StringSliceEqual(a, b []string) bool {
if len(a) != len(b) {
return false
}
if (a == nil) != (b == nil) {
return false
}
for i, v := range a {
if v != b[i] {
return false
}
}
return true
}
6、slice基本操作增删改查:
删除
func remove(slice []interface{}, i int) []interface{} {
// copy(slice[i:], slice[i+1:])
// return slice[:len(slice)-1]
return append(slice[:i], slice[i+1:]...)
}
获取新值的时候,必须使用append后的值来赋值,虽然slice是引用,原来的值删除是使用append,最后一个值还是存在的,这样就会出现最后的值一直重复,大小不变。
循环删除
由于每次删除后对应的数组是变化的,并不是保持原来的遍历,所以最好不要使用range,使用i来控制,如下
chars := []string{"a", "a", "b"}
for i := 0; i < len(chars); i+>{
if chars[i] == "a" {
chars = append(chars[:i], chars[i+1:]...)
i-- // form the remove item index to start iterate next item
}
}
fmt.Printf("%+v", chars)
一个关于下标的问题
当数据循环到最后一个数据的时候会不会out of range--不会
func main() {
var a = [10]int{0,1,2,3,4,5,6,7,8,9}
b := a[1:5]
b[1] = 10
fmt.Println(a)
fmt.Println(b)
c := append(a[:9],a[10:]...)
fmt.Println(c)
fmt.Println(a[10:])
}
chunyindeMacBook-Pro:test chunyinjiang$ go run array.go
[0 1 10 3 4 5 6 7 8 9]
[1 10 3 4]
[0 1 10 3 4 5 6 7 8]
[]
slice切片包含前面的下标不包含后面的指标,最大下标可以是数组的数量,也就是比下标大一,所以上面的a[10:]不会出错,但是a[10]是不对的,a[11:]也是不对的
新增
func add(slice []interface{}, value interface{}) []interface{} {
return append(slice, value)
}
插入
func insert(slice *[]interface{}, index int, value interface{}) {
rear := append([]interface{}{}, (*slice)[index:]...)
*slice = append(append((*slice)[:index], value), rear...)
}
修改
func update(slice []interface{}, index int, value interface{}) {
slice[index] = value
}
查找
func find(slice []interface{}, index int) interface{} {
return slice[index]
}
清空slice
func empty(slice *[]interface{}) {
// *slice = nil
*slice = append([]interface{}{})
}
遍历
func list(slice []interface{}) {
for _, v := range slice {
fmt.Printf("%d ", v)
}
}
range slice是会获取到cap slice的所有的值,所以在遍历删除slice中的元素的时候,不要使用range,使用for正常的循环
7、注意点
b[1:4]就生成了一个新切片,切片元素范围为1,2,3,不包括4.
切片并不是值拷贝,而是引用拷贝。对切片的操作就会影响到原始数组中的值
切片和数组的下标都是重0开始的。
cannot use []int literal (type []int) as type int in append
他会告诉你 正常的使用应该是int 类型而不是[]int 类型
test = append(test, []int{5, 6, 7}) //正确的玩法 切记记得加 3个点 test = append(test, []int{5, 6, 7}...)slice的引用
slice是引用类型,在内存中并没有属于自己的内存空间,而是通过指针指向进行切片的队列。由于队列分配的内存空间是连续的,所以如果slice的最后一个元素不是list的最后一个元素,那么在append的时候,新追加的元素就会覆盖掉原数组的元素。而由于slice是指针组织的,所以这个list的所有slice都会被影响。如果切片末尾元素就是队列的末尾元素,返回的 slice 数组指针将指向这个空间,而原数组的内容将保持不变,其它引用此数组的 slice 则不受影响。
Slice是引用类型,指向的都是内存中的同一块内存,不过在实际应用中,有的时候却会发生“意外”,这种情况只有在像切片append元素的时候出现,Slice的处理机制是这样的,当Slice的容量还有空闲的时候,append进来的元素会直接使用空闲的容量空间,但是一旦append进来的元素个数超过了原来指定容量值的时候,内存管理器就是重新开辟一个更大的内存空间,用于存储多出来的元素,并且会将原来的元素复制一份,放到这块新开辟的内存空间。可以看到执行了append操作如果扩容后,内存地址发生了变化,说明已经不是引用传递。
这边对引用类型做一个总结,golang中有哪些是引用类型
切片(slice)
字典(map)
通道(channel)
接口(interface)
8、数组和切片的对比
数组
在Go中,
数组是值。将一个数组赋值给另一个,会拷贝所有的元素。
特别是,如果你给函数传递一个数组,其将收到一个数组的拷贝,而不是它的指针。
数组的大小是其类型的一部分。类型 [10]int 和 [20]int 是不同的。
切片
切片持有对底层数组的引用,如果你将一个切片赋值给另一个,二者都将引用同一个数组。如果函数接受 一个切片参数,那么其对切片的元素所做的改动,对于调用者是可见的,好比是传递了一个底层数组的指 针。
关于接收者对指针和值 的规则是这样的,值方法可以在指针和值上进行调用,而指针方法只能在指针上调用。这是因为指针方法 可以修改接收者;使用拷贝的值来调用它们,将会导致那些修改会被丢弃。
9、数组传递地址的方法(二维数组也是一样)
If you’re reading this post you’re probably searching on Google how to solve this problem: you’re passing a pointer to a slice or map in a function, and when referencing an item with *variable[0], you get that error.
How do I solve it?
The solution is simple: instead of using
*variable[0]
use
(*variable)[0]
Why am I getting this weird error?
*variable[0] is interpreted by the Go compiler as *(variable[0]). So what you’re telling the compiler to do is, get the first element in the slice, or the map item with key 0, and dereference that pointer.
This explains the error: variable in that context is a pointer, not a value, so you cannot get the [0] item of a pointer to an address, you need to dereference it first to get the value, which is what I think you are trying to do in the first place.
10、真实空间
我们可以直接通过这个实例来看切片在数组上的建立和append的区别
package main
import (
"fmt"
)
func main() {
str1 := []string{"a", "b", "c"}
str2 := str1[1:]
str2[1] = "new"
fmt.Println(str1)
str2 = append(str2, "z", "x", "y")
fmt.Println(str1)
}
结果
[a b new]
[a b new]
可见,golang 中的切片底层其实使用的是数组。当使用str1[1:] 使,str2 和 str1 底层共享一个数组,这回导致 str2[1] = “new” 语句影响 str1。而 append 会导致底层数组扩容,生成新的数组,因此追加数据后的 str2 不会影响 str1。
11、数组只能与相同纬度长度以及类型的其他数组比较,切片之间不能直接比较。。
map
map就是k/v的映射,map持有对底层数据结构的引用。如果将map传递给函数,其对map的内容做了改 变,则这 些改变对于调用者是可见的。
定义申明
map[key] = value
定义 var a map[string]value
比如
// 先声明map
var m1 map[string]string
// 再使用make函数创建一个非nil的map,nil map不能赋值
m1 = make(map[string]string)
// 最后给已声明的map赋值
m1["a"] = "aa"
m1["b"] = "bb"
map元素查找
在Go语言中,map的查找功能设计得比较精巧。判断是否成功找到特定的键,不需要检查取到的值是否为nil,只需查看第二个返回值。要从map中查找一个特定的键,可以通过下面的代码来实现:
value, ok := myMap["1234"]
if ok{
//处理找到的value
}
map不像array和基础类型在你定义就会给你初始化一个默认值,所以在使用map进行赋值的时候,必须先对map进行初始化:
conf.Scripts = make(map[string]*Script)
tmpScript.Cmd = value.(string)
conf.Scripts[metric] = &tmpScript
未初始化会报错
assignment to entry in nil map
要删除一个map项,使用 delete 内建函数,其参数为map和要删除的key。即使key已经不在map中, 这样做也是安全的。
delete(timeZone, "PDT") // Now on Standard Time
实现map的有序输出
就是人为的对key进行排序,然后遍历key,或者先遍历再排序。
package main
import (
"fmt"
"sort"
)
func main() {
/* 声明一个字符串切片,存储map的key值 */
var Name []string
Name = append(Name, "Bob", "Andy", "Clark", "David", "Ella")
/* 声明索引类型为字符串的map */
var Person = make(map[string]string)
Person["Bob"] = "B"
Person["Andy"] = "A"
Person["Clark"] = "C"
Person["David"] = "D"
Person["Ella"] = "E"
fmt.Println("未排序输出:")
for key, value := range Person {
fmt.Println(key, ":", value)
}
/* 对slice数组进行排序,然后就可以根据key值顺序读取map */
sort.Strings(Name)
fmt.Println("排序输出:")
for _, Key := range Name {
/* 按顺序从MAP中取值输出 */
if Value, ok := Person[Key]; ok {
fmt.Println(Key, ":", Value)
}
}
}
Go 原生的 map 数据类型是非并发安全的,在go1.9开始发布了sync.map是线程安全的。
sync.map
在golang1.9以前,我们都是使用sync.RWMutex枷锁来实现线程安全
实例
package beego
import (
"sync"
)
type BeeMap struct {
lock *sync.RWMutex
bm map[interface{}]interface{}
}
func NewBeeMap() *BeeMap {
return &BeeMap{
lock: new(sync.RWMutex),
bm: make(map[interface{}]interface{}),
}
}
//Get from maps return the k's value
func (m *BeeMap) Get(k interface{}) interface{} {
m.lock.RLock()
defer m.lock.RUnlock()
if val, ok := m.bm[k]; ok {
return val
}
return nil
}
// Maps the given key and value. Returns false
// if the key is already in the map and changes nothing.
func (m *BeeMap) Set(k interface{}, v interface{}) bool {
m.lock.Lock()
defer m.lock.Unlock()
if val, ok := m.bm[k]; !ok {
m.bm[k] = v
} else if val != v {
m.bm[k] = v
} else {
return false
}
return true
}
// Returns true if k is exist in the map.
func (m *BeeMap) Check(k interface{}) bool {
m.lock.RLock()
defer m.lock.RUnlock()
if _, ok := m.bm[k]; !ok {
return false
}
return true
}
func (m *BeeMap) Delete(k interface{}) {
m.lock.Lock()
defer m.lock.Unlock()
delete(m.bm, k)
}
我们在项目中还可以通过数组、map、sync.RWMutex来实现普通map的并发读写,采用map数组,把key hash到相应的map,每个map单独加锁以降低锁的粒度
那么golang sync.map是如何实现线程安全的呢?
简单总结就是使用了互斥量和原子操作,用空间换时间。使用无锁读和读写分离的方式,详细了解可以看这里。
数据类型
下面是 Go 支持的基本类型:
bool
数字类型
数字类型有很多
int8, int16, int32, int64, int--有符号 int:根据不同的底层平台(Underlying Platform),表示 32 或 64 位整型。除非对整型的大小有特定的需求,否则你通常应该使用 int 表示整型。 uint8, uint16, uint32, uint64, uint--无符号 float32, float64 complex64, complex128 complex64:实部和虚部都是 float32 类型的的复数。 complex128:实部和虚部都是 float64 类型的的复数。 内建函数 complex 用于创建一个包含实部和虚部的复数。complex 函数的定义如下: func complex(r, i FloatType) ComplexTypebyte
byte 是 uint8 的别名。
rune
rune 是 int32 的别名。
string
Go 有着非常严格的强类型特征。Go 没有自动类型提升或类型转换
比如在 C 语言中是完全合法的,然而在 Go 中,却是行不通的。i 的类型是 int ,而 j 的类型是 float64 ,我们正试图把两个不同类型的数相加,Go 不允许这样的操作。
数据类型转化
func main() { var e interface{} e = 10 switch v := e.(type) { case int: fmt.Println("整型", v) var s int s = v fmt.Println(s) case string: fmt.Println("字符串", v) } }这边有一个重点,”type”只能用与interface,下面这个就是错误的
func main() { i := GetValue() switch i.(type) { case int: println("int") case string: println("string") case interface{}: println("interface") default: println("unknown") } } func GetValue() int { return 1 }golang 中字符串是不能赋值 nil 的,也不能跟 nil 比较。
字符串转成切片,会产生拷贝。严格来说,只要是发生类型强转都会发生内存拷贝。可以通过使用unsafe标准库来实现不拷贝来提高性能。
字符类型
在Go语言中支持两个字符类型,一个是 byte (实际上是 uint8 的别名),代表UTF-8字符串的单个字节的值; 另一个是 rune ,代表单个Unicode字符。出于简化语言的考虑,Go语言的多数API都假设字符串为UTF-8编码。 尽管Unicode字符在标准库中有支持,但实际上较少使用。
语句
控制语句
顺序
选择
if条件中初始化的变量可以在else中使用 switch可以获取接口变量的动态类型循环
支持for,不支持while和do_while goto语句--->跳到标志位函数
1.关键字func、函数名、参数列表、返回值、函数体和返回语句。
func Add(a int, b int) (ret int, err error) { }2.函数调用
需要先牢记这样的规则:小写字母开头的函数只在本包内可见,大写字母开头的函数才能被其他包使用。调用模式如下:
n, err := Foo(0) if err != nil { // 错误处理 } else { // 使用返回值n }3.不定参数
传入参数的数量不定
语法糖:…type
func myfunc(args ... int) { } 如果是不同的类型则用interface{} func myfunc(args ... interface{}) { }如果你的 slice 已经有了多个值,想把它们作为变参使用,你要这样调用 func(slice…)。
nums := []int{1, 2, 3, 4} myfunc(noms…)什么是可变参数函数? 可变参数函数即其参数数量是可变的 —— 0 个或多个。声明可变参数函数的方式是在其参数类型前带上省略符(三个点)前缀。也就是不定参数
原理: 可变参数函数会在其内部创建一个”新的切片”。事实上,可变参数是一个简化了切片类型参数传入的语法糖。
names ...string----->names := []string{}可变参数的使用场景
避免创建仅作传入参数用的临时切片 当参数数量未知 传达你希望增加可读性的意图使用
1.传入已有的切片
你可以通过向一个已有的切片添加可变参数运算符 ”…“ 后缀的方式将其传入可变参数函数。函数会在内部直接使用这个传入的切片,并不会创建一个的新的。
2.一些切片传入后的特异表现
传入的切片是会被改变的,源切片也同时被改变
这是因为,传入的切片和函数内部使用的切片共享同一个底层数组,因此在函数内部改变这个数组的值同样会影响到传入的切片:
3.返回传入的切片
返回值的类型不可以是可变参数的形式,但你可以将它作为一个切片返回:
你也可以像下面这样将数组转化成切片后传入可变参数函数:
names := [2]string{"carl", "sagan"} toFullname(names[:]...)[]string 和 …string 是不可互相替代的
可以通过将非可变参数置于可变参数前面的方式来混合使用它们,不能在可变参数之后再声明参数
4.支持多返回值,改进了c中笨拙的语言风格
Go 语言的函数支持多返回值有很多的作用,其中我们很常用的可以在返回接口把业务语义(业务返回值)和控制语义(出错返回值)区分开。Go 语言的很多函数都会返回 result、err 两个值,于是就有这样几点:
- 参数上基本上就是入参,而返回接口把结果和错误分离,这样使得函数的接口语义清晰。
- Go 语言中的错误参数如果要忽略,需要显式地忽略,用 _ 这样的变量来忽略。
- 如果返回的 error 是个接口(其中只有一个方法 Error(),返回一个 string ),所以你可以扩展自定义的错误处理。
如果一个函数返回了多个不同类型的 error,你也可以使用下面这样的方式,我们可以看到,Go 语言的错误处理的方式,本质上是返回值检查,但是它也兼顾了异常的一些好处——对错误的扩展。
if err != nil { switch err.(type) { case *json.SyntaxError: ... case *ZeroDivisionError: ... case *NullPointerError: ... default: ... } }
5.支持在函数参数中给返回值命名
6.支持匿名函数
7.参数类型
Go语言的函数调用参数全部是传值的, 包括 slice/map/chan 在内所有类型, 没有传引用的说法.但是slice/map/chan是引用类型,因为在make的时候返回的就是指针,所以是变成了地址引用
8.传值和传指针–和c++一样
当我们传一个参数值到被调用函数里面时,实际上是传了这个值的一份copy,当在被调用函数中修改参数值的时候, 调用函数中相应实参不会发生任何变化,因为数值变化只作用在copy上。 为了验证我们上面的说法,我们来看一个例子
package main import "fmt" //简单的一个函数,实现了参数+1的操作 func add1(a int) int { a = a+1 // 我们改变了a的值 return a //返回一个新值 } func main() { x := 3 fmt.Println("x = ", x) // 应该输出 "x = 3" x1 := add1(x) //调用add1(x) fmt.Println("x+1 = ", x1) // 应该输出"x+1 = 4" fmt.Println("x = ", x) // 应该输出"x = 3" }看到了吗?虽然我们调用了add1函数,并且在add1中执行a = a+1操作,但是上面例子中x变量的值没有发生变化 理由很简单:因为当我们调用add1的时候,add1接收的参数其实是x的copy,而不是x本身。 那你也许会问了,如果真的需要传这个x本身,该怎么办呢? 这就牵扯到了所谓的指针。我们知道,变量在内存中是存放于一定地址上的,修改变量实际是修改变量地址处的内 存。只有add1函数知道x变量所在的地址,才能修改x变量的值。所以我们需要将x所在地址&x传入函数,并将函数 的参数的类型由int改为*int,即改为指针类型,才能在函数中修改x变量的值。此时参数仍然是按copy传递的,只 是copy的是一个指针。请看下面的例子
package main import "fmt" //简单的一个函数,实现了参数+1的操作 func add1(a *int) int { // 请注意, *a = *a+1 // 修改了a的值 return *a // 返回新值 } func main() { x := 3 fmt.Println("x = ", x) // 应该输出 "x = 3" x1 := add1(&x) // 调用 add1(&x) 传x的地址 fmt.Println("x+1 = ", x1) // 应该输出 "x+1 = 4" fmt.Println("x = ", x) // 应该输出 "x = 4" }这样,我们就达到了修改x的目的。那么到底传指针有什么好处呢?
传指针使得多个函数能操作同一个对象。 传指针比较轻量级 (8bytes),只是传内存地址,我们可以用指针传递体积大的结构体。如果用参数值传递的 话, 在每次copy上面就会花费相对较多的系统开销(内存和时间)。所以当你要传递大的结构体的时候,用 指针是一个明智的选择。 Go语言中string,slice,map这三种类型的实现机制类似指针,所以可以直接传递,而不用取地址后传递 指针。(注:若函数需改变slice的长度,则仍需要取地址传递指针)错误处理
error接口
两个函数panic,recover–这是一个强大的工具,应该减少使用
关键字defer,panic,recover
1.defer 语句会延迟函数的执行直到上层函数返回。
2.defer要求获得一个函数的实例,return只需要类型定义。
3.defer 是后进先出。也就是最后的语句最先执行。
4.panic 需要等defer 结束后才会向上传递。 出现panic恐慌时候,会先按照defer的后入先出的顺序执行,最后才会执行panic。
5.Defer调用的函数可以在返回语句执行后读取或修改命名的返回值.
6.defer语句用于延迟一个函数或者方法(或者当前所创建的匿名函数)的执行,它会在外围函数或者方法返回之前但是其返回值(如果有的话)计算之后执行。这样就有可能在一个被延迟执行的函数内部修改外围函数的命名返回值
7.recover方法只可以在defer方法中调用,这是因为panic链的方法中只有defer方法可以被执行。
8.如果recover方法被调用,但是没有任何的panic发生,recover方法只会返回nil。如果有panic发生,那么panic就停止并且给panic的赋值会被返回。
一个真实的panic 和 recover配合使用的用例可以参考标准库: json package. 它提供JSON格式的解码, 当 遇到非法格式的输入时会抛出panic异常, 然后panicking扩散到上一级调用者堆栈, 由上一级调用者通过recover捕获panic和错误信息(参考 decode.go 中的 ‘error’ 和 ‘unmarshal’).
Go库的实现习惯: 即使在pkg内部使用了panic, 但是在导出API时会被转化为明确的错误值.
下面这个函数检查作为其参数的函数在执行时是否会产生panic:
func throwsPanic(f func()) (b bool) { defer func() { if x := recover(); x != nil { b = true } }() f() //执行函数f,如果f中出现了panic,那么就可以恢复回来 return }面向对象
很直接,没有隐藏this指针
func (a Integer) Less(b Integer) bool { // 面向对象 return a < b } func Integer_Less(a Integer, b Integer) bool { // 面向过程 return a < b } a.Less(2) // 面向对象的用法 Integer_Less(a, 2) // 面向过程的用法struct
结构体与数组一样,是复合类型,无论是作为实参传递给函数时,还是赋值给其他变量,都是值传递,即复一个副本。
一个结构体,并没有包含自身,比如Member中的字段不能是Member类型,但却可能是*Member。
一个命名为S的结构体类型将不能再包含S类型的成员:因为一个聚合的值不能包含它自身。(该限制同样适应于数组。)但是S类型的结构体可以包含*S指针类型的成员,这可以让我们创建递归的数据结构,比如链表和树结构等
type tree struct { value int left, right *tree } // Sort sorts values in place. func Sort(values []int) { var root *tree for _, v := range values { root = add(root, v) } appendValues(values[:0], root) } // appendValues appends the elements of t to values in order // and returns the resulting slice. func appendValues(values []int, t *tree) []int { if t != nil { values = appendValues(values, t.left) values = append(values, t.value) values = appendValues(values, t.right) } return values } func add(t *tree, value int) *tree { if t == nil { // Equivalent to return &tree{value: value}. t = new(tree) t.value = value return t } if value < t.value { t.left = add(t.left, value) } else { t.right = add(t.right, value) } return t }STRUCT基本和c差不多,也有继承采取了组合的文法–通过结构体继承,没有private,public关键字来保护,而是通过字母大小写来处理
初始化常用方法:
rect1 := new(Rect) rect2 := &Rect{} rect3 := &Rect{0, 0, 100, 200} rect4 := &Rect{width: 100, height: 200}注意这几个变量全部为指向Rect结构的指针(指针变量),因为使用了new()函数和&操作符.而如果使用方法
a := Rect{}则表示这个是一个Rect{}类型.两者是不一样的.
未显式初始化的都是对应的零值
构造函数用一个全局函数NEWXXXX来表示
func NewRect(x, y, width, height float64) *Rect { return &Rect{x, y, width, height} }struct可以实现golang的面向对象编程,每个struct的对应的实现函数 ,就是相当于这个struct的成员函数,就像访问自己的成员一样。
继承也是使用struct的组合实现的
实例
type Animal struct { Name string //名称 Color string //颜色 Height float32 //身高 Weight float32 //体重 Age int //年龄 } //奔跑 func (a Animal)Run() { fmt.Println(a.Name >"is running") } //吃东西 func (a Animal)Eat() { fmt.Println(a.Name >"is eating") } type Cat struct { a Animal } func main() { var c = Cat{ a: Animal{ Name: "猫猫", Color: "橙色", Weight: 10, Height: 30, Age: 5, }, } fmt.Println(c.a.Name) c.a.Run() }匿名组合,就是不使用变量名,Go语言支持直接将类型作为结构体的字段,而不需要取变量名,这种字段叫匿名字段
type Lion struct { Animal //匿名字段 } func main(){ var lion = Lion{ Animal{ Name: "小狮子", Color: "灰色", }, } lion.Run() fmt.Println(lion.Name) }
go的内嵌和组合实现了go的继承和派生的作用。
关键字
golang中关键字
break case chan const continue default func defer go else goto fallthrough if for import interface map package range return select struct switch type var具体作用
var和const Go语言基础里面的变量和常量申明 package和import 已经有过短暂的接触,就是包 func 用于定义函数和方法 return 用于从函数返回 defer 用于类似析构函数 go 用于并行 select 用于选择不同类型的通讯,监听 interface 用于定义接口 struct 用于定义抽象数据类型, break、case、continue、for、fallthrough、else、if、switch、goto、default 这流程介绍里面 chan 用于channel通讯 type 用于声明自定义类型 map 用于声明map类型数据 range 用于读取slice、map、channel数据
go语言的三大核心
goroutine和channel是Go并发的两大基石,那么接口是Go语言编程中数据类型的关键。
Golang使用Groutine和channels实现了CSP(Communicating Sequential Processes)模型,即通信顺序进程模型。Goroutine 和 Channel 分别对应 CSP 中的实体和传递信息的媒介,Go 语言中的 Goroutine 会通过 Channel 传递数据。
在Go语言的实际编程中,几乎所有的数据结构都围绕接口展开,接口是Go语言中所有数据结构的核心。
这三个可以说是go语言的核心所在,goroutine和channel和interface都单独成篇。
零碎基础知识
golang是一门静态类型开发语言
每个 Go 程序都是由包组成的,程序运行的入口是包
main。go自己的设计哲学:
1、不得包含源代码文件中没有用到的包
2、函数的左括号{位置
3、函数名大小写规则
4、不一定要用分号结束语句
5、package的名称必须和目录名保持一致
Go语言的工作空间结构:
Go语言的工作空间其实就是一个文件目录,目录中必须包含src、pkg、bin三个目录。
其中src目录用于存放Go源代码,pkg目录用于package对象,bin目录用于存放可执行对象
环境变量
go命名行用到了GOPATH环境变量,在这个目录下收索
export GOPATH=你的工作空间路径 export PATH=$PATH:$GOPATH/bin----安装用这个路劲go的初始化函数init是在main函数的之前执行的
Go里面有两个保留的函数:init函数(能够应用于所有的package)和main函数(只能应用于package main)。 这两个函数在定义时不能有任何的参数和返回值。虽然一个package里面可以写任意多个init函数,但这无论是对 于可读性还是以后的可维护性来说,我们都强烈建议用户在一个package中每个文件只写一个init函数。
全局唯一性操作
var once sync.Once
go环境变量:
GOROOT :go的安装目录
GOPATH :你自己开发go语言代码的目录,目录结构为bin,pkg,src,如果你有多个目录,那么使用分号分隔。
命名函数
我们给 fmt.Println 一个短名字的别名
var p = fmt.Println命令行参数
os.Args 提供原始命令行参数访问功能。注意,切片中的第一个参数是该程序的路径,并且 os.Args[1:]保存所有程序的的参数。
go提供了安装包,直接下载解压设置/etc/profile环境变量就可以使用go了,简单便捷
export GOROOT=/home/test/Go/go—-源码安装路径 export PATH=$GOROOT/bin:$PATH——声明应用 export GOPATH=/home/test/Go/go-project—你的项目路劲import
import “fmt”最常用的一种形式
import “./test”导入同一目录下test包中的内容
import f “fmt”导入fmt,并给他启别名f
import . “fmt”,将fmt启用别名”.“,这样就可以直接使用其内容,而不用再添加fmt,如fmt.Println可以直接写成Println
import _ “fmt” 表示不使用该包,而是只是使用该包的init函数,并不显示的使用该包的其他内容。注意:这种形式的import,当import时就执行了fmt包中的init函数,而不能够使用该包的其他函数。
struct
定义:
type person struct { name string age int }初始化:
直接初始化
var P person // P现在就是person类型的变量了 P.name = "Astaxie" // 赋值"Astaxie"给P的name属性. P.age = 25 // 赋值"25"给变量P的age属性按照顺序提供初始化值
P := person{"Tom", 25}通过field:value的方式初始化,这样可以任意顺序
P := person{age:24, name:"Tom"}
进行结构体比较时候,只有相同类型的结构体才可以比较,结构体是否相同不但与属性类型个数有关,还与属性顺序相关。结构体是相同的,但是结构体属性中有不可以比较的类型,如map,slice,还是不可比较的。
如果该结构属性都是可以比较的,那么就可以使用“==”进行比较操作。可以使用reflect.DeepEqual进行比较
struct内部的的成员一般需要给外部使用,不管是同一个文件还是几个文件,所以都是需要大写开头
错误
Handler crashed with error runtime error: invalid memory address or nil pointer dereference一般报这个错误原因
值为nil解决方法
找到这个位置,值为nil 判断一下再输出或者赋值nil 可以用作 interface、function、pointer、map、slice 和 channel 的“空值”。但是如果不特别指定的话,Go 语言不能识别类型,所以会报错。
goto
goto不能跳转到其他函数或者内层代码
在golang中同属于流程控制,和判断,循环一样。
Go 1.9 新特性
Alias and defintion
基于一个类型创建一个新类型,称之为defintion; 基于一个类型创建一个别名,称之为alias。 defintion,虽然底层类型为int类型,但是不能直接赋值,需要强转; alias,可以直接赋值。命名
go提倡命名不使用下划线
if后不提倡使用括号
提出命名不带数据类型,不够简洁,而且现在ide功能也是很全面清晰
隐藏
for k:= range labels { labelNames = append(labelNames, k) }这边这个v不需要使用_就可以不写。
_代表空白标志符
range分配的变量
range对应的变量的地址是不变的,地址的上的数据是变化的,比如
type student struct { Name string Age int } func pase_student() { m := make(map[string]*student) stus := []student{ {Name: "zhou", Age: 24}, {Name: "li", Age: 23}, {Name: "wang", Age: 22}, } for _, stu := range stus { m[stu.Name] = &stu } }最后获取的m中value值是一样的,都是stu的地址,stu不会随着range重新分配变量,一直都是一个,所以内部的赋值一直都是stu的同一个地址,正常的写法是定义的时候不用地址
type student struct { Name string Age int } func pase_student() { m := make(map[string]student) stus := []student{ {Name: "zhou", Age: 24}, {Name: "li", Age: 23}, {Name: "wang", Age: 22}, } for _, stu := range stus { m[stu.Name] = stu } }换一个角度,rang遍历数组,切片,map时,都是值拷贝,在循环中更改值不会影响原来的
变量声明
“:=”只能在声明“局部变量”的时候使用,而“var”没有这个限制。
运算符
在Go中 “++” 和 “- -” 只能作为语句而非表达式 示例代码:
a := 1 a ++ // 注意:不能写成 ++a 或 -- a 必须放在右边使用 // b := a++// 此处为错误的用法,不能写在一行,要单独作为语句使用 fmt.Println(a) // 2封装实例(deafulat)
go标准库中,经常这么做
定义了一个类型,提供了很多方法;为了方便使用,会实例化一个该类型的实例(通用),这样便可以直接使用该实例调用方法。比如:
encoding/base64 中提供了 StdEncoding 和 URLEncoding 实例,使用时:base64.StdEncoding.Encode()
在 flag 包使用了有类似的方法,比如 CommandLine 实例,只不过 flag 进行了进一步封装:将 FlagSet 的方法都重新定义了一遍,也就是提供了一序列函数,而函数中只是简单的调用已经实例化好了的 FlagSet 实例:CommandLine 的方法。这样,使用者是这么调用:flag.Parse() 而不是 flag. CommandLine.Parse()。(Go 1.2 起,将 CommandLine 导出,之前是非导出的)
map和slice遍历顺序问题
我理解为在range时为引用类型(slice,map,channel)创建索引,而map的索引是未被指定的,所以无序。
因此如果需要保证顺序输出,我是使用了slice。当然range 数组是有序的输出。
调用
当package无法调用对应的方法时,第一个看是否是大写,小写对外不公开,第二个看是否包名和变量名重复
无法修改map中的成员变量
在开始代码设计的时候想要将原struct中的成员变量进行修改或者替换。
x = y 这种赋值的方式,你必须知道 x的地址,然后才能把值 y 赋给 x。 但 go 中的 map 的 value 本身是不可寻址的,因为 map 的扩容的时候,可能要做 key/val pair迁移 value 本身地址是会改变的 不支持寻址的话又怎么能赋值呢代码示例如下
package main import "fmt" var m = map[string]struct{ x, y int } { "foo": {2, 3} } func main() { m["foo"].x = 4 fmt.Printf("result is : %+v", m) }本以为这个会将 m[“foo”] 中的 x 替换成 4, 从而打印出来的效果是
result is : map[foo:{x:4 y:3}]然而,并不是的,这段代码在保存后编译时提示
cannot assign to struct field m["foo"].x in map这就尴尬了,无法在已经存在的key的节点中修改值,这是为什么?
m中已经存在”foo”这个节点了啊,
简单来说就是map不是一个并发安全的结构,所以,并不能修改他在结构体中的值。
这如果目前的形式不能修改的话,就面临两种选择,
1.修改原来的设计;
2.想办法让map中的成员变量可以修改,—-使用指针
因为懒得该这个结构体,就选择了方法2,
但是不支持这种方式传递值,应该如何进行修改现在已经存在在struct中的map的成员变量呢?
热心的网友们倒是提供了一种方式,示例如下:
package main import "fmt" var m = map[string]struct{ x, y int } { "foo": {2, 3} } func main() { tmp := m["foo"] tmp.x = 4 m["foo"] = tmp fmt.Printf("result is : %+v", m) }果然和预期结果一致,不过,总是觉得有点怪怪的,
既然是使用了类似临时空间的方式,那我们用地址引用传值不也是一样的么…
于是,我们就使用了另外一种方式来处理这个东西,
示例如下:
package main import "fmt" var m = map[string]*struct{ x, y int } { "foo": &{2, 3} } func main() { m["foo"].x = 4 fmt.Println("result is : %+v \n", m) fmt.Println("m's node is : %+v \n", *m["foo"]) }最后的展示结果为:
result is : map[foo:0xc42000cff0] m's node is : {4, 3}代理
以前我一直以为只需要给git加代理就可以了,其实go命令本身就有proxy的。比如http_proxy=socks5://127.0.0.1:1080 go get -u -v github.com/gin-gonic/gin
执行原理
Go 的可执行文件都比相对应的源代码文件要大很多,这恰恰说明了 Go 的 runtime 嵌入到了每一个可执行文件当中。当然,在部署到数量巨大的集群时,较大的文件体积也是比较头疼的问题。但总得来说,Go 的部署工作还是要比 Java 和 Python 轻松得多。因为 Go 不需要依赖任何其它文件,它只需要一个单独的静态文件,这样你也不会像使用其它语言一样在各种不同版本的依赖文件之间混淆。
参数interface
接口interface作为返回参数,只要是实现了这个接口内的所有的方法的struct,都可以返回给这个参数
例如filebeat中filebeat的new函数的返回,就是把fileabeat的结构体返回给了beat.Beater接口interface
另外一方面也可以解释 var a beat.Beater = &Filebeat{}
可以把一个结构体赋值给一个接口
调用子进程
编程中遇到使用相对路径再配置文件中,调用process b的可以先获取当前进程运行的绝对路径,正常大部分都是使用绝对路径。
google开源的包
为什么gRPC-go在github的地址是”https://github.com/grpc/grpc-go" , 但是为什么要用“google.golang.org/grpc”进行安装呢?应该grpc原本是google内部的项目,归属golang,就放在了google.golang.org下面了,后来对外开放,又将其迁移到github上面了,又因为golang比较坑爹的import路径规则,所以就都没有改路径名了。
但是这样就有个问题了。要如何去管理版本呢?这个目前我还没有什么比较好的方法,希望知道的朋友一起分享下。目前想到一个方法是手动下载某个版本,然后写个脚本统一修改代码中的import里面的路径.
google在github上也有一个账号https://github.com/google/,对应的google开源的项目在这个下面,由于google去get 包不太友好,可以来这边来下载。
也有去一下专门下载包的第三方网站去下载,比如https://gopm.io/
每一个可独立运行的Go程序,必定包含一个package main,在这个main包中必定包含一个入口函数main,而这 个函数既没有参数,也没有返回值。
求余
求余, B % A
hashcode
package main import ( "fmt" "hash/crc32" ) // String hashes a string to a unique hashcode. // // crc32 returns a uint32, but for our use we need // and non negative integer. Here we cast to an integer // and invert it if the result is negative. func String(s string) int { v := int(crc32.ChecksumIEEE([]byte(s))) if v >= 0 { return v } if -v >= 0 { return -v } // v == MinInt return 0 } func main(){ str := "123456abcd" for i:=0; i<3;i+>{ hc := String(str) fmt.Println("hashcode:", hc) } }gouroutine执行失败需要退出整个进程,可以使用panic
golang字符串去除空格和换行符
package main import ( "fmt" "strings" ) func main() { str := "welcome to bai\ndu\n.com" // 去除空格 str = strings.Replace(str, " ", "", -1) // 去除换行符 str = strings.Replace(str, "\n", "", -1) fmt.Println(str) }range空的内容的时候
package main import ( "fmt" ) func main() { var res = []string {""} var flag = true for _, value := range res { fmt.Println("have value:",value) flag = false } for i:=0;i<len(res);i++{ fmt.Println("have value:",res[i]) } if !flag { fmt.Println("response array the number of row UnMatch") } }输出
chunyindeMacBook-Pro:test chunyinjiang$ go run range.go have value: have value: response array the number of row UnMatch[]byte to string
package main import ( "fmt" ) func main() { data := [4]byte{0x31, 0x32, 0x33, 0x34} str := string(data[:]) fmt.Println(str) }read内容的问题
buf := make([]byte, 512) _, err := conn.Read(buf) input := string(buf)如果接收的数据不够512bytes怎么办?会变成buf末尾跟了很多个0(make([]byte, 512)会把全部都初始化为0),虽然0在c里面代表字符串的结尾,但是go可不是哦。
所以,正确的代码应该是这样
buf := make([]byte, 512) for { n, err := conn.Read(buf) // n代表读取的数量。 if err != nil { break } input := string(buf[:n]) }获取字符的数值
int('9' - '0')//9,所以这个用于获取正常的数值的方式 int('9')//49--ACSIIfmt打印结构体内容
fmt包内置的方法,本来就可以展示类似Json的形式,没必要自己瞎搞。把上面的输出代码改了:
fmt.Printf("%+v\n", a)实例
package main import ( "fmt" ) type Power struct{ age int high int name string } func main() { var i Power = Power{age: 10, high: 178, name: "NewMan"} fmt.Printf("type:%T\n", i) fmt.Printf("value:%v\n", i) fmt.Printf("value+:%+v\n", i) fmt.Printf("value#:%#v\n", i) fmt.Println("========interface========") var interf interface{} = i fmt.Printf("%v\n", interf) fmt.Println(interf) }output:
type:main.Power value:{10 178 NewMan} value+:{age:10 high:178 name:NewMan} value#:main.Power{age:10, high:178, name:”NewMan”} ========interface======== {10 178 NewMan} {10 178 NewMan}还有
fmt.Printf("metrics name buf : %s\n",ic.MetricNameBuf )等价于
fmt.Println("metrics name buf :",string(ic.MetricNameBuf) )go可以通过gdb来调试
编译Go程序的时候需要注意以下几点
1. 传递参数-ldflags "-s",忽略debug的打印信息 2. 传递-gcflags "-N -l" 参数,这样可以忽略Go内部做的一些优化,聚合变量和函数等优化,这样对于GDB调 试来说非常困难,所以在编译的时候加入这两个参数避免这些优化。常用命令
GDB的一些常用命令如下所示
list 简写命令l,用来显示源代码,默认显示十行代码,后面可以带上参数显示的具体行,例如:list 15,显示 十行代码,其中第15行在显示的十行里面的中间,如下所示。 10 time.Sleep(2 * time.Second) 11 c <- i 12 } 13 close(c) 14 } 15 16 func main() { 17 18 19 break msg := "Starting main" fmt.Println(msg) bus := make(chan int) 简写命令 b,用来设置断点,后面跟上参数设置断点的行数,例如b 10在第十行设置断点。 delete 简写命令 d,用来删除断点,后面跟上断点设置的序号,这个序号可以通过info breakpoints获取 相应的设置的断点序号,如下是显示的设置断点序号。 Num Type Disp Enb Address What 2 breakpoint keep y 0x0000000000400dc3 in main.main at /home/xiemengjun/gdb.go:2 breakpoint already hit 1 time backtrace 简写命令 bt,用来打印执行的代码过程,如下所示: #0 main.main () at /home/xiemengjun/gdb.go:23 #1 0x000000000040d61e in runtime.main () at /home/xiemengjun/go/src/pkg/runtime/proc.c:244 #2 0x000000000040d6c1 in schedunlock () at /home/xiemengjun/go/src/pkg/runtime/proc.c:267 #3 0x0000000000000000 in ?? () 231 3 info info命令用来显示信息,后面有几种参数,我们常用的有如下几种: print info locals 显示当前执行的程序中的变量值 info breakpoints 显示当前设置的断点列表 info goroutines 显示当前执行的goroutine列表,如下代码所示,带*的表示当前执行的 * 1 running runtime.gosched * 2 syscall runtime.entersyscall 3 waiting runtime.gosched 4 runnable runtime.gosched 简写命令p,用来打印变量或者其他信息,后面跟上需要打印的变量名,当然还有一些很有用的函数$len()和 $cap(),用来返回当前string、slices或者maps的长度和容量。 whatis 用来显示当前变量的类型,后面跟上变量名,例如whatis msg,显示如下: type = struct string next 简写命令 n,用来单步调试,跳到下一步,当有断点之后,可以输入n跳转到下一步继续执行 coutinue 简称命令 c,用来跳出当前断点处,后面可以跟参数N,跳过多少次断点 set variable 该命令用来改变运行过程中的变量值,格式如:set variable <var>=<value>调试过程
我们通过下面这个代码来演示如何通过GDB来调试Go程序,下面是将要演示的代码:
package main import ( "fmt" "time" ) func counting(c chan<- int) { for i := 0; i < 10; i+>{ time.Sleep(2 c <- i } close(c) } func main() { msg := "Starting fmt.Println(msg) bus := make(chan msg = "starting a gofunc" go counting(bus) for count := range bus { * time.Second) main" int) 232 fmt.Println("count:", count) } }编译文件,生成可执行文件gdbfile:
go build -gcflags "-N -l" -ldflags "-s" gdbfile.go通过gdb命令启动调试:
gdb gdbfile 启动之后首先看看这个程序是不是可以运行起来,只要输入run命令回车后程序就开始运行,程序正常的话可以看到程序输出如下,和我们在命令行直接执行程序输出是一样的:
(gdb) run Starting Starting count: 0 count: 1 count: 2 count: 3 count: 4 count: 5 count: 6 count: 7 count: 8 count: 9 [LWP 2771 exited] [Inferior 1 (process 2771) exited normally]好了,现在我们已经知道怎么让程序跑起来了,接下来开始给代码设置断点:
(gdb) b 23 Breakpoint 1 at 0x400d8d: file /home/xiemengjun/gdbfile.go, line 23. (gdb) run Starting program: /home/xiemengjun/gdbfile Starting main [New LWP 3284] [Switching to LWP 3284] Breakpoint 1, main.main () at /home/xiemengjun/gdbfile.go:23 23 fmt.Println("count:", count)上面例子b 23表示在第23行设置了断点,之后输入run开始运行程序。现在程序在前面设置断点的地方停住了,我们 需要查看断点相应上下文的源码,输入list就可以看到源码显示从当前停止行的前五行开始:
(gdb) list 18 fmt.Println(msg) 19 bus := make(chan int) 20 msg = "starting a gofunc" 21 go counting(bus) 22 for count := range bus { 23 fmt.Println("count:", count) 24 } 25 }现在GDB在运行当前的程序的环境中已经保留了一些有用的调试信息,我们只需打印出相应的变量,查看相应变量的类型及值:
(gdb) info locals count = 0 bus = 0xf840001a50 (gdb) p count $1 = 0 (gdb) p bus $2 = (chan int) 0xf840001a50 (gdb) whatis bus type = chan int program: /home/xiemengjun/gdbfile main接下来该让程序继续往下执行,请继续看下面的命令
(gdb) c Continuing. count: 0 [New LWP 3303] [Switching to LWP 3303] Breakpoint 1, main.main () at /home/xiemengjun/gdbfile.go:23 23 fmt.Println("count:", count) (gdb) c Continuing. count: 1 [Switching to LWP 3302] Breakpoint 1, main.main () at /home/xiemengjun/gdbfile.go:23 23 fmt.Println("count:", count)每次输入c之后都会执行一次代码,又跳到下一次for循环,继续打印出来相应的信息。 设想目前需要改变上下文相关变量的信息,跳过一些过程,并继续执行下一步,得出修改后想要的结果:
(gdb) info locals count = 2 bus = 0xf840001a50 (gdb) set variable count=9 (gdb) info locals count = 9 bus = 0xf840001a50 (gdb) c Continuing. count: 9 [Switching to LWP 3302] Breakpoint 1, main.main () at /home/xiemengjun/gdbfile.go:23 23 fmt.Println("count:", count)最后稍微思考一下,前面整个程序运行的过程中到底创建了多少个goroutine,每个goroutine都在做什么:
(gdb) info goroutines * 1 running runtime.gosched * 2 syscall runtime.entersyscall 3 waiting runtime.gosched 4 runnable runtime.gosched (gdb) goroutine 1 bt #0 0x000000000040e33b in runtime.gosched () at /home/xiemengjun/go/src/pkg/runtime/proc.c:927 #1 0x0000000000403091 in runtime.chanrecv (c=void, ep=void, selected=void, received=void) at /home/xiemengjun/go/src/pkg/runtime/chan.c:327 #2 0x000000000040316f in runtime.chanrecv2 (t=void, c=void) at /home/xiemengjun/go/src/pkg/runtime/chan.c:420 #3 0x0000000000400d6f in main.main () at /home/xiemengjun/gdbfile.go:22 #4 0x000000000040d0c7 in runtime.main () at /home/xiemengjun/go/src/pkg/runtime/proc.c:244 #5 0x000000000040d16a in schedunlock () at /home/xiemengjun/go/src/pkg/runtime/proc.c:267 #6 0x0000000000000000 in ?? ()通过查看goroutines的命令我们可以清楚地了解goruntine内部是怎么执行的,每个函数的调用顺序已经明明白白地显示出来了。
利用cpu多核来处理http请求,下面这个没有用go默认就是单核处理http的.
runtime.GOMAXPROCS(runtime.NumCPU());interface转化string
var x interface{} = "abc" str := fmt.Sprintf("%v", x)golang中json中出现list该怎么定义
使用map进行struct定义
{"plugin_params": map<string>string,}return
退出执行,不指定返回值
通常有两种情况不需要指定返回值退出函数执行过程。第一是:函数没有返回值;第二是:函数返回值有变量名,不需要显示的指定返回值。
Connection reset by peer
1.如果一端的Socket被关闭(或主动关闭,或因为异常退出而 引起的关闭),另一端仍发送数据,发送的第一个数据包引发该异常(Connect reset by peer)。
Socket默认连接60秒,60秒之内没有进行心跳交互,即读写数据,就会自动关闭连接。
2.一端退出,但退出时并未关闭该连接,另一端如果在从连接中读数据则抛出该异常(Connection reset)。
时间比较
time1 := "2015-03-20 08:50:29" time2 := "2015-03-21 09:04:25" //先把时间字符串格式化成相同的时间类型 t1, err := time.Parse("2006-01-02 15:04:05", time1) t2, err := time.Parse("2006-01-02 15:04:05", time2) if err == nil && t1.Before(t2) { //处理逻辑 fmt.Println("true") }定时12点
func startTimer(f func()) { go func() { for { f() now := time.Now() // 计算下一个零点 next := now.Add(time.Hour * 24) next = time.Date(next.Year(), next.Month(), next.Day(), 0, 0, 0, 0, next.Location()) t := time.NewTimer(next.Sub(now)) <-t.C } }() }golang中交换字符串中的字符,需要先转化为[]byte来转化
func smallestStringWithSwaps(s string, pairs [][]int) string { n := len(s) res := make([]byte,n) for k,v := range s{ res[k] = byte(v) } for _,v := range pairs{ left := v[0] right := v[1] if left < right { if res[left] > res[right]{ res[left],res[right] = res[right],res[left] } } } return string(res) }
常规使用
go 内存和指针
Go语言中的指针和C语言中在使用上几乎没有什么差别。
make和new
Go语言中有两个分配内存的机制,分别是内建的函数new和make。但是new和make并不能等同,他们所做的事情其实并不同,所应用到的类型也不相同。
1、 new(T)函数是一个分配内存的内建函数,但是不同于其他语言中内建new函数所做的工作,在Go语言中,new只是将内存清零,并没有初始化内存。所以在Go语言中,new(T)所做的工作是为T类型分配了值为零的内存空间并返回其地址,即返回*T。也就是说,new(T)返回一个指向新分配的类型T的零值指针
内置函数 new 分配空间。传递给new 函数的是一个类型,不是一个值。返回值是 指向这个新分配的零值的指针。
即:var pInt *int = new(int) //*pInt = nil
2、 make(T, args)函数与new(T)函数的目的不同。make(T, args)仅用于创建切片、map和channel(消息管道),make(T, args)返回类型T的一个被初始化了的实例。而new(T)返回指向类型T的零值指针。也就是说new函数返回的是*T的未初始化零值指针,而make函数返回的是T的初始化了的实例
内建函数 make 分配并且初始化 一个 slice, 或者 map 或者 chan 对象。 并且只能是这三种对象。 和 new 一样,第一个参数是 类型,不是一个值。 但是make 的返回值就是这个类型(即使一个引用类型),而不是指针。 具体的返回值,依赖具体传入的类型。
//创建一个初始元素个数为5的数组切片,元素初始值为0
a := make([]int, 5) // len(a)=5
Go语言中出现new和make两个分配内存的函数,并且使用起来还有差异,主要原因是切片、map、channel这三种类型在使用前必须初始化相关的数据结构。例如,切片是一个有三项内容的数据类型,包括指向数据的指针(在一个数组内部进行切片)、长度和容量,在这三项内容被初始化之前,切片值为nil。换句话说:对于切片、map、channel,make(T, args)初始化了其内部的数据结构并为他们准备了将要使用的值
例如:make([]int, 10, 100); //分配一个整形数组,长度为10,容量为100,并返回其前10个数组的切片
所以,在为切片、map、channel这三种类型分配内存时,为了不必要的使问题复杂化,应该使用Go的内建make函数
记住 make 只用于map,slice和channel,并且不返回指针。要获得一个显式的指针,使用 new 进行分配,或者显式地使用一个变量的地址。
这些例子阐释了 new 和 make 之间的差别。
var p *[]int = new([]int) // allocates slice structure; *p == nil; rarely useful
var v []int = make([]int, 100) // the slice v now refers to a new array of 100 ints
// Unnecessarily complex:
var p *[]int = new([]int)
*p = make([]int, 100, 100)
// Idiomatic:
v := make([]int, 100)
问题
1.panic: runtime error: invalid memory address or nil pointer dereference
正常都是内存没有分配
2.routers/routers.go:14:61: cannot call pointer method on controllers.UserController literal
原因: 指针不能作为接收者, 需要需要定义指针变量来接送地址
实例
type myTreeNode struct{
node *tree.TreeNode
}
func (mynode *myTreeNode) postOrader(){
if mynode==nil || mynode.node==nil{
return
}
//错误的写法
myTreeNode{mynode.node.Left}.postOrader()
right := myTreeNode{mynode.node.Right}.postOrader()
mynode.node.Print()
//正确的写法
left := myTreeNode{mynode.node.Left}
left.postOrader()
right := myTreeNode{mynode.node.Right}
right.postOrader()
mynode.node.Print()
}
GoLang中 json、map、struct 之间的相互转化
golang 中 json 转 struct
使用 json.Unmarshal 时,结构体的每一项必须是导出项(import field)。也就是说结构体的 key 对应的首字母必须为大写。
请看下面的例子:
import (
"testing"
"encoding/json"
)
type Person struct {
name string
age int
}
func TestStruct2Json(t *testing.T) {
jsonStr := `
{
"name":"liangyongxing",
"age":12
}
`
var person Person
json.Unmarshal([]byte(jsonStr), &person)
t.Log(person)
}
输出的结果如下:
1
{ 0}
从结果可以看出,json 数据并没有写入 Person 结构体中。结构体 key 首字母大写的话就可以,修改后:
import (
"testing"
"encoding/json"
)
type Person struct {
Name string
Age int
}
func TestStruct2Json(t *testing.T) {
jsonStr := `
{
"name":"liangyongxing",
"age":12
}
`
var person Person
json.Unmarshal([]byte(jsonStr), &person)
t.Log(person)
}
打印结果如下:
1
{liangyongxing 12}
从以上结果我们可以发现一个很重要的信息,json 里面的 key 和 struct 里面的 key一个是小写一个是大写,即两者大小写并没有对上。从这里我们就可以得出一个结论,要想能够附上值需要结构体中的变量名首字母大写,而在转换的 json 串中大小写都可以,即在 json 传中字段名称大小写不敏感。那么经过验证发现,在 json 中如果写成如下方式:
jsonStr :=
{
"NaMe":"liangyongxing",
"agE":12
}
最终结果仍然是有值的,那么就验证了我们上面的结论,json 串中对字段名大小写不敏感(不一定是首字母,这点需要注意)
在结构体中是可以引入 tag 标签的,这样在匹配的时候 json 串对应的字段名需要与 tag 标签中定义的字段名匹配,当然在 tag 中定义的名称就不需要首字母大写了,且对应的 json 串中字段名称仍然大小写不敏感,和上面的结论一致。(注意:此时结构体中对应的字段名可以不用和匹配的一致,但是也必须首字母大写,只有大写的才是可对外提供访问的)
import (
"testing"
"encoding/json"
)
//这里对应的 N 和 A 不能为小写,首字母必须为大写,这样才可对外提供访问,具体 json 匹配是通过后面的 tag 标签进行匹配的,与 N 和 A 没有关系
//tag 标签中 json 后面跟着的是字段名称,都是字符串类型,要求必须加上双引号,否则 golang 是无法识别它的类型
type Person struct {
N string `json:"name"`
A int `json:"age"`
}
func TestStruct2Json(t *testing.T) {
jsonStr := `
{
"name":"liangyongxing",
"age":12
}
`
var person Person
json.Unmarshal([]byte(jsonStr), &person)
t.Log(person)
}
复制代码
这样输出的结果如下:
1
{liangyongxing 12}
当然,你也可以再做一个实验,验证 tag 标签中对应的字段名称大小写不敏感,这里就不做冗余介绍了。
golang 中 struct 转 json 串
直接使用Marshal
package commontest
import (
"testing"
"encoding/json"
)
func TestStruct2Json(t *testing.T) {
p := Person{
Name: "liangyongxing",
Age: 29,
}
t.Logf("Person 结构体打印结果:%v", p)
//Person 结构体转换为对应的 Json
jsonBytes, err := json.Marshal(p)
if err != nil {
t.Fatal(err)
}
t.Logf("转换为 json 串打印结果:%s", string(jsonBytes))
}
打印结果如下所示:
/usr/local/go/bin/go test -v commontest -run ^TestStruct2Json$
struct2json_test.go:14: Person 结构体打印结果:{liangyongxing 29}
struct2json_test.go:21: 转换为 json 串打印结果:{"name":"liangyongxing","age":29}
ok commontest 0.006s
golang 中 json 转 map
也是使用Unmarshal
package commontest
import (
"testing"
"encoding/json"
)
func TestJson2Map(t *testing.T) {
jsonStr := `
{
"name":"liangyongxing",
"age":12
}
`
var mapResult map[string]interface{}
//使用 json.Unmarshal(data []byte, v interface{})进行转换,返回 error 信息
if err := json.Unmarshal([]byte(jsonStr), &mapResult); err != nil {
t.Fatal(err)
}
t.Log(mapResult)
}
打印结果信息如下:
/usr/local/go/bin/go test -v commontest -run ^TestJson2Map$
json2map_test.go:19: map[name:liangyongxing age:12]
ok commontest 0.007s
golang 中 map 转 json 串
也是使用Marshal
import (
"testing"
"encoding/json"
)
func TestMap2Json(t *testing.T) {
mapInstance := make(map[string]interface{})
mapInstance["Name"] = "liang637210"
mapInstance["Age"] = 28
mapInstance["Address"] = "北京昌平区"
jsonStr, err := json.Marshal(mapInstance)
if err != nil {
t.Fatal(err)
}
t.Logf("Map2Json 得到 json 字符串内容:%s", jsonStr)
}
/usr/local/go/bin/go test -v commontest -run ^TestMap2Json$
map2json_test.go:20: Map2Json 得到 json 字符串内容:{"Address":"北京昌平区","Age":28,"Name":"liang637210"}
ok commontest 0.008s
golang中map转 struct
其实在map和struct之间的转化完全可以通过上面的两次转换来完成,就是比较消耗资源,可以通过下列方法一次完成相互转换。
这个转换网上有比较完整的项目,已经上传到对应的 github 上了,需要下载之后使用:
$ go get github.com/goinggo/mapstructure
之后我们就可以直接使用它提供的方法将 map 转换为 struct,让我们直接上代码吧
import (
"testing"
"github.com/goinggo/mapstructure"
)
func TestMap2Struct(t *testing.T) {
mapInstance := make(map[string]interface{})
mapInstance["Name"] = "liang637210"
mapInstance["Age"] = 28
var person Person
//将 map 转换为指定的结构体
if err := mapstructure.Decode(mapInstance, &person); err != nil {
t.Fatal(err)
}
t.Logf("map2struct后得到的 struct 内容为:%v", person)
}
/usr/local/go/bin/go test -v commontest -run ^TestMap2Struct$
map2struct_test.go:18: map2struct后得到的 struct 内容为:{liang637210 28}
ok commontest 0.009s
golang 中 struct 转 map
使用reflect
package commontest
import (
"testing"
"reflect"
)
type User struct {
Id int `json:"id"`
Username string `json:"username"`
Password string `json:"password"`
}
func Struct2Map(obj interface{}) map[string]interface{} {
t := reflect.TypeOf(obj)
v := reflect.ValueOf(obj)
var data = make(map[string]interface{})
for i := 0; i < t.NumField(); i+>{
data[t.Field(i).Name] = v.Field(i).Interface()
}
return data
}
func TestStruct2Map(t *testing.T) {
user := User{5, "zhangsan", "password"}
data := Struct2Map(user)
t.Logf("struct2map得到的map内容为:%v", data)
}
打印结果如下:
/usr/local/go/bin/go test -v commontest -run ^TestStruct2Map$
struct2map_test.go:28: struct2map得到的map内容为:map[Id:5 Username:zhangsan Password:password]
ok commontest 0.007s
关于relflect的使用可以参考标准库。
优雅重启升级
使用 Go 语言实现优雅的服务器重启
1、不关闭现有连接:例如我们不希望关掉已部署的运行中的程序。但又想不受限制地随时升级服务。
2、socket连接要随时响应用户请求:任何时刻socket的关闭可能使用户返回'连接被拒绝'的消息,而这是不可取的。
3、新的进程要能够启动并替换掉旧的。
实现
在基于Unix的操作系统中,signal(信号)是与长时间运行的进程交互的常用方法.
SIGTERM: 优雅地停止进程
SIGHUP: 重启/重新加载进程 (例如: nginx, sshd, apache)
如果收到SIGHUP信号,优雅地重启进程需要以下几个步骤:
1、服务器要拒绝新的连接请求,但要保持已有的连接。
2、启用新版本的进程
3、将socket“交给”新进程,新进程开始接受新连接请求
4、旧进程处理完毕后立即停止。
错误处理(函数式编程)
if err !=nil 的代码在golang编码过程中经常会大量出现,我们可以通过函数式编程解决一部分问题,如下
func parse(r io.Reader) (*Point, error) {
var p Point
if err := binary.Read(r, binary.BigEndian, &p.Longitude); err != nil {
return nil, err
}
if err := binary.Read(r, binary.BigEndian, &p.Latitude); err != nil {
return nil, err
}
if err := binary.Read(r, binary.BigEndian, &p.Distance); err != nil {
return nil, err
}
if err := binary.Read(r, binary.BigEndian, &p.ElevationGain); err != nil {
return nil, err
}
if err := binary.Read(r, binary.BigEndian, &p.ElevationLoss); err != nil {
return nil, err
}
}
可见上面出现了大量的if err !=nil 的代码,我们可以优化成下面的代码
func parse(r io.Reader) (*Point, error) {
var p Point
var err error
read := func(data interface{}) {
if err != nil {
return
}
err = binary.Read(r, binary.BigEndian, data)
}
read(&p.Longitude)
read(&p.Latitude)
read(&p.Distance)
read(&p.ElevationGain)
read(&p.ElevationLoss)
if err != nil {
return &p, err
}
return &p, nil
}
可见将if err != nil的代码函数化,可以大量的错误处理代码,这是处理错误代码的一种方式,但是也是有针对性。
标准库(常用)
标准库:https://books.studygolang.com/The-Golang-Standard-Library-by-Example/
直接去网页版查询,经常使用,方可记住,没事也可以看看,可以根据实例巩固,golang的标准库是相当的丰富,足够我们实现很多功能。
reflect
relflect就是动态运行时的状态,对自己行为的描述(self-representation)和监测(examination)。
io
io是所有需要交互的输入输出模式的基础。
ioutil
ioutil主要是提供了一些常用、方便的IO操作函数。
fmt
fmt是实现了格式化的I/O函数,这点类似C语言中的printf和scanf,但是更加简单。
strconv
strconv包实现了基本数据类型和其字符串表示的相互转换。
time
time包中包括两类时间:时间点(某一时刻)和时长(某一段时间)的基本操作。
sync
sync包提供了基本的同步基元,包括底层的原子级内存操作。
runtime包
runtime包提供和go运行时环境的互操作,如控制go协程的函数。
math/rand
math包实现的就是数学函数计算。
strings
strings包实现的就是字符串的操作。
flag
flag包实现的就是命令行参数设置解析,一般我们会选择一个我们会针对不同的功能需求选用不同的命令行解析包。
sort
sort包实现的就是排序算法。
archive
archive就是使用tar和zip两种方式对文档进行归档。
builtin
builtin包是go的预声明定义,包括go语言中常用的各种类型和方法声明,包括变量和常量两部分。
compress
compress一般用于压缩。
bytes
bytes该包定义了一些操作 byte slice 的便利操作。
context
context控制并发。
http
http实现基本http请求。
pprof
pprof性能调优的工具。
interface
interface实现接口。
技术栈
技术栈就是我们开发中经常使用的框架,golang标准库非常丰富,一般我们开发直接可以使用标准库就可以,但是也有一些比较好的技术栈可以直接使用开发,减少重复找轮子的代价,golang开发主要在两个方面:服务器和云计算
服务器
后端服务我们主要使用的是golang的高并发能力和简单的开发框架。
云计算
云计算目前主要即使k8s以及其生态建设。
开发工具
sublime text
尝试了liteide和sublime text,感觉还是sublime text比较好,它支持源码的查看的跳转,编译执行,而liteide在跳转上有点问题,不能跳转到自定义的函数,不知道是不是我配置的问题(基本上就是在查看选项设定了go环境变量),所以自己开发的时候决定用sublime
sublime text go环境搭建
在mac上安装go并设置好环境变量
安装一个Package Control,这个应该是一个插件管理工具,用于安装很多其他插件的,只要用ctrl>` 打开命令行输入执行命令
import urllib.request,os,hashlib; h = '7183a2d3e96f11eeadd761d777e62404' >'e330c659d4bb41d3bdf022e94cab3cd0'; pf = 'Package Control.sublime-package'; ipp = sublime.installed_packages_path(); urllib.request.install_opener( urllib.request.build_opener( urllib.request.ProxyHandler()) ); by = urllib.request.urlopen( 'http://sublime.wbond.Net/' >pf.replace(' ', '%20')).read(); dh = hashlib.sha256(by).hexdigest(); print('Error validating download (got %s instead of %s), please try manual install' % (dh, h)) if dh != h else open(os.path.join( ipp, pf), 'wb' ).write(by)安装好后可以在preferences中找到这个插件。
安装go插件gosublime
我们点击Package Control插件或者用shift+ctrl+p来打开,输入pcip(Package Control:Install Package的缩写)也就是安装插件的意思。然后输入gosublime就会自动安装了,安装好了依旧可以在preferences下找到这个gosublime插件。
然后就可以在gopath下建src,src下建对应的项目,使用sublime进行编码,查看,按command+b进入到shell模式进行编译执行。
sublime text只能做一个简单的文本编辑器,不算一个完整的IDE,放弃用于golang编程,用于简单的文本编辑器,使用goland编码。
goland
一款类似于idea的IDE,同一个公司出品,目前正在使用,比较好用,目前主打开发工具。
vscode
使用的人也是比较多的,功能强大,主要是占用内存很小只有几十M,相比于goland的几个G来说,好很多
Go 谚语
本文译自go-proverbs, 脱胎于 Rob Pike 振奋人心的演讲视频 talk at Gopherfest SV 2015 (bilibili).
不要通过共享内存进行通信, 通过通信共享内存 (Don’t communicate by sharing memory, share memory by communicating),
传统的线程模型(通常在编写 Java, C++和 Python 程序时使用)要求程序员使用共享内存在线程之间进行通信. 通常, 共享数据结构受锁保护, 线程将争夺这些锁访问数据, 在某些情况下, 通过使用 Python 的 Queue 等线程安全的数据结构可以使这变得更容易.
Go 的并发原语 (goroutines 和 channels) 为构造并发软件提供了一种优雅而独特的手段. (这些概念有一个有趣的历史, 要从 C.A.R.Hoare 的通信顺序进程说起.) Go 鼓励使用 channels 在 goroutines 之间传递对数据的引用, 而不是显式地使用锁来调解对共享数据的访问. 这种方法确保只有一个 goroutine 可以在给定的时间访问数据. 这个概念总结在 Effective Go 文档中 (任何 Go 程序员都必须阅读).
Go 官方博客中有一篇文章对该谚语解读, 可以参见原文.
并发不是并行 (Concurrency is not parallelism)
当人们听到 并发 这个词的时候, 他们经常会想到并行, 这是一个相关的, 但非常独特的概念. 在编程中, 并发是独立执行的进程的组成, 而并行则是 (可能相关的) 计算的同时执行. 并发是一次处理很多事情. 并行是一次做很多事情.
Channels 重排序; 互斥量串行化 (Channels orchestrate; mutexes serialize)
这个看中文(翻译待商榷)是不是一脸懵 (虽然英文也看不懂) ? 其实分号前后说的是一个意思, 该谚语按我的个人理解可以用 go 程序 (来自 go tour) 解释成如下:
package main import "fmt" func sum(s []int, c chan int) { sum := 0 for _, v := range s { sum += v } c <- sum // 此处如果改成互斥量一样可以做到 } func main() { s := []int{7, 2, 8, -9, 4, 0} c := make(chan int) go sum(s[:len(s)/2], c) go sum(s[len(s)/2:], c) x, y := <-c, <-c fmt.Println(x, y, x+y) }接口越大, 抽象越弱 (The bigger the interface, the weaker the abstraction)
接口背后的概念是通过将对象的行为抽象为简单的契约来允许重用性. 虽然接口不是 Go 专有的, 但由于 Go 接口通常趋向于小型化, Go 程序员才广泛使用它们. 通常情况下, 一个接口只限于一到两个方法.
Go io 包接口就是典型的例子.
充分利用零值 (Make the zero value useful)
零值的典型例子如 bytes.Buffer 和 sync.Mutex:
var buf bytes.Buffer buf.Write([]byte("hello")) fmt.Println(buf.String()) var mu sync.Mutex mu.Lock() mu.Unlock()这样看起来是不是感觉一点用没有 ? 如果这样呢 ?
type Map struct { mu sync.RWMutex // ... } func (m *Map) Set(k, v interface{}) { m.mu.Lock() defer m.mu.Unlock() if m.m == nil { m.m = make(map[interface{}]interface{}) } m.m[k] = v }interface{} 言之无物 (interface{} says nothing)
该谚语不是说 interface {} 不代表任何东西, 而是说该类型无静态检查以及调用时保证, 比如你的 func 接收一个 interface{} 类型, 你写的时候是可用的, 但是某个时间你进行了代码重构可能坏掉了.
Gofmt 的风格没有人喜欢, 但是 gofmt 是每个人的最爱 (Gofmt’s style is no one’s favorite, yet gofmt is everyone’s favorite)
该谚语告诉我们少些风格之争, 用这些时间多写代码.
小复制好过小依赖 (A little copying is better than a little dependency)
简单说就是如果你可以手动撸小快代码就不要导入一个库去做, 比如 UUID:
// see: https://groups.google.com/d/msg/golang-nuts/d0nF_k4dSx4/rPGgfXv6QCoJ package main import ( "fmt" "os" ) func main() { f, _ := os.Open("/dev/urandom") // 演示用忽略 errcheck b := make([]byte, 16) f.Read(b) f.Close() uuid := fmt.Sprintf("%x-%x-%x-%x-%x", b[0:4], b[4:6], b[6:8], b[8:10], b[10:]) fmt.Println(uuid) }虽然有一堆写好的 UUID 库, 当你仅仅需要一个 UUID v4 实现.
系统调用必须始终使用构建标签保证 (Syscall must always be guarded with build tags)
不同的系统 (*NIX, Windows) 调用导致你同一个 func (实现并不一样) 可能需要在不同的系统上构建才能得到你想要的结果. 简单说就是系统调用不可移植才这么干. 示例可参见 Go 标准库 syscall.
Cgo 必须始终使用构建标签保证 (Cgo must always be guarded with build tags)
基本上原因同上一条.
Cgo 不是 Go (Cgo is not Go)
如果可能不要用 Cgo.
unsafe 包无保证 (With the unsafe package there are no guarantees)
包如其名, 不安全. 你可以使用 unsafe 包如果你准备好了有一天它会坏掉.
清晰好过聪明 (Clear is better than clever)
Rob Pike 在他与别人合著的 <程序设计实践> 中写到: “写清晰的代码, 不要写聪明的代码”.
反射永远不是清晰的 (Reflection is never clear)
很多人在 Stackoverflow 上抱怨 Go 的反射不工作, 因为那不是为你准备的! 只有很少很少的人应该用反射这个非常强大而又非常难的特性. 新手应该远离反射和 interface{}.
错误也是一种值 (Errors are values)
值可以被编程, 并且由于错误是值, 所以错误可以被编程. Go 官方博客有对此的解读.
不要止步于检查错误而要优雅的处理 (Don’t just check errors, handle them gracefully)
Dave Cheney 有篇博客详细解读了该谚语.
设计架构, 命名组件, 记录细节 (Design the architecture, name the components, document the details)
当你写一个大型系统的时候, 你把它设计成一种结构化的东西. 想象组件的每一个部分并行工作, 为不同的组件起好的名字, 因为这些名字会出现在稿纸上.
拿 Go 程序来说, 如果名字不错, 组件就好理解, 那么程序的结构设计就会清晰, 程序会感觉很自然.
但是还有很多东西你需要解释, 所以这些是你需要解释的细节. 但是命名会帮助你解释很大一部分设计. 细节只是填补材料的缺口可能用来为用户打印工程图解文档.
文档是针对用户的 (Documentation is for users)
很多人写文档表明某个 func 是做什么的, 但是他们不想想这个 func 是为谁而写. 这有很大的不同. 你知道这个 func 返回什么是对的, 但是它为什么返回了你使用的时候不一样的结果?
把自己当成使用者而不是写它的人, 那么 godoc 上的文档就是对用户有用的. 这对于其他语言一样适用.
不要慌 (Don’t panic)
不要使用 panic 进行正常的错误处理. 使用错误 (error) 和多个返回值.
协程调度是很轻的操作,这当然没错。但他们都没有告诉你更重要的一点:协程调度反复高频出现没有goroutine可供调度的代价在Go的当前实现里是显著的。
好的习惯是,稍大的类型存到map都存储指针而不是值。
定义数据结构的时候,减少后面使用的转换
defer是性能杀手,我的原则是能不用尽量避开。
能不在循环内部做的,就不要在循环内存处理
减少内存的频繁分配,减少使用全局锁的可能