并发编程是我们计算机技术中最常用的一种编程技术,是一种基于多元程序的一种应用。
并发演进
- 多进程——-开销太大,都是基于内核的调用
- 多线程——-相对开销小,但是远远达不到需求,最多并发1万这样
- 基于回调的非阻塞/异步io—-共享内存式的同步异步,导致编程相当复杂
- 协程—-轻量级线程,轻松达到100w的并发,使用成本低、消耗资源低、能效高
C10K问题
为什么需要不断的并发演进,支撑这么高并发的请求呢?我们先从C10K问题说起:2001年左右的时候,有一个叫Dan Kegel的人在网上提出:现在的硬件应该能够让一台机器支持10000个并发的client。然后他讨论了用不同的方式实现大规模并发服务的技术。
当然, 现在C10K 已经不是问题了, 任何一个普通的程序员, 都能利用手边的语言和库, 轻松地写出 C10K 的服务器. 这既得益于软件的进步, 也得益于硬件性能的提高,现在应该扩展讨论的是应该是C10M问题了。
目前使用的最多的就是Coroutine模型 和 非阻塞/异步IO(callback)
不论线程还是进程,都不可能一个连接创建一个,相应的成本太大,多进程和多线程都有资源耗费比较大的问题,所以在高并发量的服务器端使用并不多。解决方案是一个线程或者进程处理多个连接,更具体的现在比较主流的是:Coroutine模型 和 非阻塞/异步IO(callback),在分析这两个之前,我们先看看多进程和多线程的情况。
1、多进程
这种模型在linux下面的服务程序广泛采用,比如大名鼎鼎的apache,主进程负责监听和管理连接,而具体的业务处理都会交给子进程来处理。
这种架构的最大的好处是隔离性,子进程万一crash并不会影响到父进程。缺点就是对系统的负担过重,想像一下如果有上万的连接,会需要多少进程来处理。所以这种模型比较合适那种不需要太多并发量的服务器程序。另外,进程间的通讯效率也是一个瓶颈之一,大部分会采用share memory等技术来减低通讯开销。
这种模型的问题在于服务器的性能会随着连接数的增多而变差,关键性能和可扩展性并不是一回事,并不是扩展和性能是成比例上升。比如:
持续几秒的短期连接,比如快速事务,如果每秒处理1000个事务,只有约1000个并发连接到服务器。事务延长到10秒,要维持每秒1000个事务,必须打开1万个并发连接。这种情况下:尽管你不顾DoS攻击,Apache也会性能陡降;同时大量的下载操作也会使Apache崩溃。如果每秒处理的连接从5千增加到1万,你会怎么做?比方说,你升级硬件并且提高处理器速度到原来的2倍。发生了什么?你得到两倍的性能,但你没有得到两倍的处理规模。每秒处理的连接可能只达到了6000。你继续提高速度,情况也没有改善。甚至16倍的性能时,仍然不能处理1万个并发连接。所以说性能和可扩展性是不一样的。
其实这也是apache的核心问题,Apache会创建一个CGI进程,然后关闭,这个步骤并没有扩展。为什么呢?内核使用的O(N^2)算法使服务器无法处理1万个并发连接。
内核算法中的两个基本问题:
- 连接数=线程数/进程数。当一个数据包进来,内核会遍历其所有进程以决定由哪个进程来处理这个数据包。
- 连接数=选择数/轮询次数(单线程)。同样的可扩展性问题,每个包都要走一遭列表上所有的socket。
解决方法:
- 改进内核使其在常数时间内查找。
- 使线程切换时间与线程数量无关。
- 使用一个新的可扩展epoll()/IOCompletionPort常数时间去做socket查询。
2、多线程
这种模型在windows下面比较常见。它使用一个线程来处理一个client。他的好处是编程简单,最重要的是你会有一个清晰连续顺序的work flow。简单意味着不容易出错,但是这种模型的问题就是太多的线程会减低软件的运行效率,当然比进程节省资源。
我们知道,操作系统的最小调度单元是“线程”,要执行任何一段代码,都必须落实到“线程”上。可惜线程太重,资源占用太高,频繁创建销毁会带来比较严重的性能问题,于是又诞生出线程池之类的常见使用模式。也是类似的原因,“阻塞”一个线程往往不是一个好主意,因为线程虽然暂停了,但是它所占用的资源还在。线程的暂停和继续对于调度器都会带来压力,而且线程越多,调度时的开销便越大,这其中的平衡很难把握。
针对这个问题,有两类架构解决它:基于callback和coroutine的架构。
3、Callback- 非阻塞/异步IO
这种架构的特点是使用非阻塞的IO,这样服务器就可以持续运转,而不需要等待,可以使用很少的线程,即使只有一个也可以。需要定期的任务可以采取定时器来触发。把这种架构发挥到极致的就是node.js,一个用javascript来写服务器端程序的框架。在node.js中,所有的io都是non-block的,可以设置回调。
举个例子来说明一下。 传统的写法:
var file = open(‘my.txt’);
var data = file.read(); //block
sleep(1);
print(data); //block
node.js的写法:
fs.open(‘my.txt’,function(err,data){
setTimeout(1000,function(){
console.log(data);
}
}); //non-block
这种架构的好处是performance会比较好,缺点是编程复杂,把以前连续的流程切成了很多片段。另外也不能充分发挥多核的能力。
4、Coroutine-协程
Coroutine是一种概念,很多语言都是支持启动coroutine,包括java,做的最好的就是goroutine。
coroutine本质上是一种轻量级的thread,它的开销会比使用thread少很多。多个coroutine可以按照次序在一个thread里面执行,一个coroutine如果处于block状态,可以交出执行权,让其他的coroutine继续执行。
非阻塞I/O模型协程(Coroutines)使得开发者可以采用阻塞式的开发风格,却能够实现非阻塞I/O的效果隐式事件调度,
简单来说:协程十分轻量,可以在一个进程中执行有数以十万计的协程,依旧保持高性能。
协程和线程的区别是:协程避免了无意义的调度,由此可以提高性能,但也因此,程序员必须自己承担调度的责任。
执行协程只需要极少的栈内存(大概是4~5KB),默认情况下,线程栈的大小为1MB。
goroutine就是一段代码,一个函数入口,以及在堆上为其分配的一个堆栈。所以它非常廉价,我们可以很轻松的创建上万个goroutine,但它们并不是被操作系统所调度执行。
Google go语言对coroutine使用了语言级别的支持,使用关键字go来启动一个coroutine(从这个关键字可以看出Go语言对coroutine的重视),结合chan(类似于message queue的概念)来实现coroutine的通讯,实现了Go的理念 ”Do not communicate by sharing memory; instead, share memory by communicating.”。
goroutine 的一个主要特性就是它们的消耗;创建它们的初始内存成本很低廉(与需要 1 至 8MB 内存的传统 POSIX 线程形成鲜明对比)以及根据需要动态增长和缩减占用的资源。这使得 goroutine 会从 4096 字节的初始栈内存占用开始按需增长或缩减内存占用,而无需担心资源的耗尽。
为了实现这个目标,链接器(5l、6l 和 8l)会在每个函数前插入一个序文,这个序文会在函数被调用之前检查判断当前的资源是否满足调用该函数的需求(备注 1)。如果不满足,则调用 runtime.morestack 来分配新的栈页面(备注 2),从函数的调用者那里拷贝函数的参数,然后将控制权返回给调用者。此时,已经可以安全地调用该函数了。当函数执行完毕,事情并没有就此结束,函数的返回参数又被拷贝至调用者的栈结构中,然后释放无用的栈空间。
通过这个过程,有效地实现了栈内存的无限使用。假设你并不是不断地在两个栈之间往返,通俗地讲叫栈分割,则代价是十分低廉的。
简单来说:Go语言通过系统的线程来多路派遣这些函数的执行,使得每个用go关键字执行的函数可以运行成为一个单位协程。当一个协程阻塞的时候,调度器就会自动把其他协程安排到另外的线程中去执行,从而实现了程序无等待并行化运行。而且调度的开销非常小,一颗CPU调度的规模不下于每秒百万次,这使得我们能够创建大量的goroutine,从而可以很轻松地编写高并发程序,达到我们想要的目的。
Coroutine模型 和 非阻塞/异步IO(callback)性能对比
- 从性能角度来说,callback的典型node.js和golang的性能测试结果,两者差不多。
- 不过从代码可读性角度来说,callback确实有点不太好。
进程、线程、协程的关系和区别:
- 进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度。
- 线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度(标准线程是的)。
- 协程和线程一样共享堆,不共享栈,协程由程序员在协程的代码里显示调度。
多进程并发
进程
我们把一个运行的程序就叫做进程,可以说是操作系统运行和资源分配的一个基本单位。在进程中有进程id作为唯一标识,来对进程进行操作。进程进一步衍生出子进程的概念。对应的也有子父进程的关系。
简单说一下go中获取进程id和对应的父进程id
pid := os.Getpid()
ppid := os.Getppid()
正常大部分的父进程都是1,也就是内核启动进程。
进程状态
1、R (TASK_RUNNING),可执行状态。
只有在该状态的进程才可能在CPU上运行。而同一时刻可能有多个进程处于可执行状态,这些进程的task_struct结构(进程控制块)被放入对应CPU的可执行队列中(一个进程最多只能出现在一个CPU的可执行队列中)。进程调度器的任务就是从各个CPU的可执行队列中分别选择一个进程在该CPU上运行。
很多操作系统教科书将正在CPU上执行的进程定义为RUNNING状态、而将可执行但是尚未被调度执行的进程定义为READY状态,这两种状态在linux下统一为 TASK_RUNNING状态。
2、S (TASK_INTERRUPTIBLE),可中断的睡眠状态。
处于这个状态的进程因为等待某某事件的发生(比如等待socket连接、等待信号量),而被挂起。这些进程的task_struct结构被放入对应事件的等待队列中。当这些事件发生时(由外部中断触发、或由其他进程触发),对应的等待队列中的一个或多个进程将被唤醒。
通过ps命令我们会看到,一般情况下,进程列表中的绝大多数进程都处于TASK_INTERRUPTIBLE状态(除非机器的负载很高)。毕竟CPU就这么一两个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。
3、D (TASK_UNINTERRUPTIBLE),不可中断的睡眠状态。
与TASK_INTERRUPTIBLE状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的并不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。 绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。否则你将惊奇的发现,kill -9竟然杀不死一个正在睡眠的进程了!于是我们也很好理解,为什么ps命令看到的进程几乎不会出现TASK_UNINTERRUPTIBLE状态,而总是TASK_INTERRUPTIBLE状态。
而TASK_UNINTERRUPTIBLE状态存在的意义就在于,内核的某些处理流程是不能被打断的。如果响应异步信号,程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了。(参见《linux内核异步中断浅析》) 在进程对某些硬件进行操作时(比如进程调用read系统调用对某个设备文件进行读操作,而read系统调用最终执行到对应设备驱动的代码,并与对应的物理设备进行交互),可能需要使用TASK_UNINTERRUPTIBLE状态对进程进行保护,以避免进程与设备交互的过程被打断,造成设备陷入不可控的状态。这种情况下的TASK_UNINTERRUPTIBLE状态总是非常短暂的,通过ps命令基本上不可能捕捉到。
linux系统中也存在容易捕捉的TASK_UNINTERRUPTIBLE状态。执行vfork系统调用后,父进程将进入TASK_UNINTERRUPTIBLE状态,直到子进程调用exit或exec(参见《神奇的vfork》)。 通过下面的代码就能得到处于TASK_UNINTERRUPTIBLE状态的进程:
#include
void main()
{
if (!vfork())
sleep(100);
}
编译运行,然后ps一下:
kouu@kouu-one:~/test$ ps -ax | grep a\.out
4371 pts/0 D+ 0:00 ./a.out
4372 pts/0 S+ 0:00 ./a.out
4374 pts/1 S+ 0:00 grep a.out
然后我们可以试验一下TASK_UNINTERRUPTIBLE状态的威力。不管kill还是kill -9,这个TASK_UNINTERRUPTIBLE状态的父进程依然屹立不倒。我们介绍了Linux进程的R、S、D三种状态,这里接着上面的文章介绍另外三个状态。
4、T (TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态。
向进程发送一个SIGSTOP信号,它就会因响应该信号而进入TASK_STOPPED状态(除非该进程本身处于TASK_UNINTERRUPTIBLE状态而不响应信号)。(SIGSTOP与SIGKILL信号一样,是非常强制的。不允许用户进程通过signal系列的系统调用重新设置对应的信号处理函数。) 向进程发送一个SIGCONT信号,可以让其从TASK_STOPPED状态恢复到TASK_RUNNING状态。
当进程正在被跟踪时,它处于TASK_TRACED这个特殊的状态。“正在被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。比如在gdb中对被跟踪的进程下一个断点,进程在断点处停下来的时候就处于TASK_TRACED状态。而在其他时候,被跟踪的进程还是处于前面提到的那些状态。
对于进程本身来说,TASK_STOPPED和TASK_TRACED状态很类似,都是表示进程暂停下来。 而TASK_TRACED状态相当于在TASK_STOPPED之上多了一层保护,处于TASK_TRACED状态的进程不能响应SIGCONT信号而被唤醒。只能等到调试进程通过ptrace系统调用执行PTRACE_CONT、PTRACE_DETACH等操作(通过ptrace系统调用的参数指定操作),或调试进程退出,被调试的进程才能恢复TASK_RUNNING状态。
5、Z (TASK_DEAD - EXIT_ZOMBIE),退出状态,进程成为僵尸进程。
进程在退出的过程中,处于TASK_DEAD状态。
在这个退出过程中,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。于是进程就只剩下task_struct这么个空壳,故称为僵尸。 之所以保留task_struct,是因为task_struct里面保存了进程的退出码、以及一些统计信息。而其父进程很可能会关心这些信息。比如在shell中,$?变量就保存了最后一个退出的前台进程的退出码,而这个退出码往往被作为if语句的判断条件。 当然,内核也可以将这些信息保存在别的地方,而将task_struct结构释放掉,以节省一些空间。但是使用task_struct结构更为方便,因为在内核中已经建立了从pid到task_struct查找关系,还有进程间的父子关系。释放掉task_struct,则需要建立一些新的数据结构,以便让父进程找到它的子进程的退出信息。
父进程可以通过wait系列的系统调用(如wait4、waitid)来等待某个或某些子进程的退出,并获取它的退出信息。然后wait系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉。 子进程在退出的过程中,内核会给其父进程发送一个信号,通知父进程来“收尸”。这个信号默认是SIGCHLD,但是在通过clone系统调用创建子进程时,可以设置这个信号。
通过下面的代码能够制造一个EXIT_ZOMBIE状态的进程:
#include
void main()
{
if (fork())
while(1)
sleep(100);
}
编译运行,然后ps一下:
kouu@kouu-one:~/test$ ps -ax | grep a\.out
10410 pts/0 S+ 0:00 ./a.out
10411 pts/0 Z+ 0:00 [a.out]
10413 pts/1 S+ 0:00 grep a.out
只要父进程不退出,这个僵尸状态的子进程就一直存在。那么如果父进程退出了呢,谁又来给子进程“收尸”? 当进程退出的时候,会将它的所有子进程都托管给别的进程(使之成为别的进程的子进程)。托管给谁呢?可能是退出进程所在进程组的下一个进程(如果存在的话),或者是1号进程。所以每个进程、每时每刻都有父进程存在。除非它是1号进程。
1号进程,pid为1的进程,又称init进程。 linux系统启动后,第一个被创建的用户态进程就是init进程。它有两项使命: 1、执行系统初始化脚本,创建一系列的进程(它们都是init进程的子孙); 2、在一个死循环中等待其子进程的退出事件,并调用waitid系统调用来完成“收尸”工作; init进程不会被暂停、也不会被杀死(这是由内核来保证的)。它在等待子进程退出的过程中处于TASK_INTERRUPTIBLE状态,“收尸”过程中则处于TASK_RUNNING状态。
6、X (TASK_DEAD - EXIT_DEAD),退出状态,进程即将被销毁。
而进程在退出过程中也可能不会保留它的task_struct。比如这个进程是多线程程序中被detach过的进程(进程?线程?参见《linux线程浅析》)。或者父进程通过设置SIGCHLD信号的handler为SIG_IGN,显式的忽略了SIGCHLD信号。(这是posix的规定,尽管子进程的退出信号可以被设置为SIGCHLD以外的其他信号。) 此时,进程将被置于EXIT_DEAD退出状态,这意味着接下来的代码立即就会将该进程彻底释放。所以EXIT_DEAD状态是非常短暂的,几乎不可能通过ps命令捕捉到。
进程的初始状态
进程是通过fork系列的系统调用(fork、clone、vfork)来创建的,内核(或内核模块)也可以通过kernel_thread函数创建内核进程。这些创建子进程的函数本质上都完成了相同的功能——将调用进程复制一份,得到子进程。(可以通过选项参数来决定各种资源是共享、还是私有。) 那么既然调用进程处于TASK_RUNNING状态(否则,它若不是正在运行,又怎么进行调用?),则子进程默认也处于TASK_RUNNING状态。 另外,在系统调用调用clone和内核函数kernel_thread也接受CLONE_STOPPED选项,从而将子进程的初始状态置为 TASK_STOPPED。
进程状态变迁
进程自创建以后,状态可能发生一系列的变化,直到进程退出。而尽管进程状态有好几种,但是进程状态的变迁却只有两个方向——从TASK_RUNNING状态变为非TASK_RUNNING状态、或者从非TASK_RUNNING状态变为TASK_RUNNING状态。 也就是说,如果给一个TASK_INTERRUPTIBLE状态的进程发送SIGKILL信号,这个进程将先被唤醒(进入TASK_RUNNING状态),然后再响应SIGKILL信号而退出(变为TASK_DEAD状态)。并不会从TASK_INTERRUPTIBLE状态直接退出。
进程从非TASK_RUNNING状态变为TASK_RUNNING状态,是由别的进程(也可能是中断处理程序)执行唤醒操作来实现的。执行唤醒的进程设置被唤醒进程的状态为TASK_RUNNING,然后将其task_struct结构加入到某个CPU的可执行队列中。于是被唤醒的进程将有机会被调度执行。
而进程从TASK_RUNNING状态变为非TASK_RUNNING状态,则有两种途径:
- 响应信号而进入TASK_STOPED状态、或TASK_DEAD状态;
- 执行系统调用主动进入TASK_INTERRUPTIBLE状态(如nanosleep系统调用)、或TASK_DEAD状态(如exit系统调用);或由于执行系统调用需要的资源得不到满足,而进入TASK_INTERRUPTIBLE状态或TASK_UNINTERRUPTIBLE状态(如select系统调用)。
显然,这两种情况都只能发生在进程正在CPU上执行的情况下。
空间
- 内核空间—专门给内核用的,内核可以和硬件进行交互(0-TASK_SIZE)
- 用户空间—专门给用户进程用的,用户进程不可以和硬件进行交互,内核对用户空间进行分配(TASK_SIZE-2(32/64)次方)
两个空间合成了机器的虚拟内存,根据机器的位数不同,分别使用0-2的32/64次方来表示虚拟内存的地址,内核和用户的地址是以TASK_SIZE来分界的,TASK_SIZE根据不同的系统数值也不同,
Linux的虚拟地址空间范围为0~4G,Linux内核将这4G字节的空间分为两部分, 将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF)供内核使用,称为“内核空间”。而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF)供各个进程使用,称为“用户空间。因为每个进程可以通过系统调用进入内核,因此,Linux内核由系统内的所有进程共享。于是,从具体进程的角度来看,每个进程可以拥有4G字节的虚拟空间。
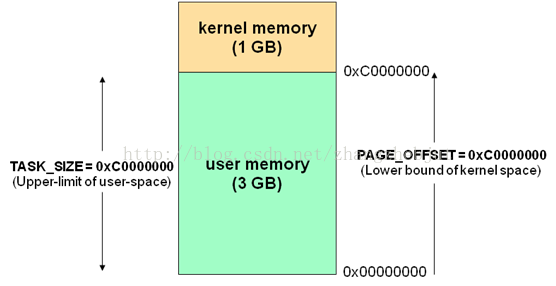
1.用户进程只能分配到这个用户的用户空间。
2.不同的进程之间是相互不可见的,不会互相干扰。
3.内核划分分配虚拟内存,cpu划分物理内存,虚拟内存和物理内存是相互映射的。
系统调用
系统调用就是让用户空间和内核空间交互的一座桥梁,用户进程在用户空间是不能操作计算机硬件的,但是内核空间中却可以,所以内核开放来一些接口来给用户来操作,这些接口就是系统调用,
每一种语言都对系统调用做好了封装,比如go中syscall。
多线程并发
线程的并发在java中得到了很好的应用和封装,当然c中也是可以实现的,只不过一开始用c/c++的时候比较倾向于子进程的使用。
线程相对于进程相对开销小,提高的并发量,最多并发到1万,可见极大的提高了承受的能力。我们可以简单的看一下线程的并发。
目前还有很多网站的并发使用的就是线程并发的能力在支持,并且能够满足要求,但是随着用户并发量越来越大,需要能够支持更加强大的并发能力,这个时候可以看一下协程并发。
goroutine并发
go是天生为并发而生的,能够轻轻松松达到百万级的轻量并发,可见其并发承受能力之强,具体的并发可以看goroutine,我们这边主要看一下并发的使用以及其能力情况。
简单的并发
一般用于启动多协程来处理后端数据业务,类似于多线程处理数据,直接使用for循环并发一定数量的goroutine,然后对数据进行处理,如果是处理同一个数据,则需要使用锁,通过传递参数,还可以对业务进行分通道处理
使用这种并发方式我们没法控制goroutine产生数量,如果处理程序稍微耗时,在单机万级十万级qps请求下,goroutine大规模爆发,内存暴涨,处理效率会很快下降甚至引发程序崩溃。
我想,作为golang拥趸的Gopher们一定都使用过它的net/http标准库,我们常用的go的net/http库就是这种使用方式,很多人都说用golang写web server完全可以不用借助第三方的web framework,仅用net/http标准库就能写一个高性能的web server,的确,我也用过它写过web server,简洁高效,性能表现也相当不错,除非有比较特殊的需求否则一般的确不用借助第三方web framework,但是天下没有白吃的午餐,net/http为啥这么快?
其实每次处理业务都是启动了一个新的goroutine去执行处理逻辑,而且这是在一个无限循环体里面,所以意味着,每来一个请求它就会开一个goroutine去处理,相当任性粗暴啊…,不过有Go调度器背书,一般来说也没啥压力,然而,如果,我是说如果哈,突然一大波请求涌进来了(比方说黑客搞了成千上万的肉鸡DDOS你,没错!就这么倒霉!),这时候,就很成问题了,他来10w个请求你就要开给他10w个goroutine,来100w个你就要老老实实开给他100w个,线程调度压力陡升,内存爆满,再然后,你就跪了…,也就是我们上面说的,崩溃,正常使用没有问题,归功于go强大的调度性能和goroutine的资源消耗。但是危险存在着。
在这边也对我们这边的系统做了一个压测,看看到底能爆发到什么程度,是不是和360推送的京东并发一样强大,360消息推送的数据如下,可见单机并发可以达到100W:
16台机器,标配:24个硬件线程,64GB内存
Linux Kernel 2.6.32 x86_64
单机80万并发连接,load 0.2~0.4,CPU 总使用率 7%~10%,内存占用20GB (res)
目前接入的产品约1280万在线用户
2分钟一次GC,停顿2秒 (1.0.3 的 GC 不给力,直接升级到 tip,再次吃螃蟹)
15亿个心跳包/天,占大多数。
京东云消息推送系统
(团队人数:4)
单机并发tcp连接数峰值118w
内存占用23G(Res)
Load 0.7左右
心跳包 4k/s
gc时间2-3.x s
我们的数据:
8核16G内存
Linux promespreapp03 2.6.32-279.19.1.el6_sn.11.x86_64 #10 SMP Tue May 16 20:11:22 CST 2017 x86_64 x86_64 x86_64 GNU/Linux
[root@promesdevapp02 ants]# vi ants_benchmark_test.go
[root@promesdevapp02 ants]# go test -bench="Goroutine$" -benchmem=true -run=none
goos: linux
goarch: amd64
pkg: github.com/panjf2000/ants
BenchmarkGoroutine-8 20 170688713 ns/op 32741982 B/op 155597 allocs/op
PASS
ok github.com/panjf2000/ants 6.189s
[root@promesdevapp02 ants]# go test -bench="AntsPool$" -benchmem=true -run=none
goos: linux
goarch: amd64
pkg: github.com/panjf2000/ants
BenchmarkAntsPool-8 10 107166741 ns/op 1076056 B/op 8851 allocs/op
PASS
ok github.com/panjf2000/ants 1.265s
[root@promesdevapp02 ants]# vi ants_benchmark_test.go
[root@promesdevapp02 ants]# go test -bench="Goroutine$" -benchmem=true -run=none
goos: linux
goarch: amd64
pkg: github.com/panjf2000/ants
BenchmarkGoroutine-8 1 4251624524 ns/op 492471736 B/op 1678022 allocs/op
PASS
ok github.com/panjf2000/ants 4.487s
[root@promesdevapp02 ants]# go test -bench="AntsPool$" -benchmem=true -run=none
goos: linux
goarch: amd64
pkg: github.com/panjf2000/ants
BenchmarkAntsPool-8 1 1059289888 ns/op 11469768 B/op 91975 allocs/op
PASS
ok github.com/panjf2000/ants 1.069s
[root@promesdevapp02 ants]# vi ants_benchmark_test.go
[root@promesdevapp02 ants]# go test -bench="Goroutine$" -benchmem=true -run=none
*** Test killed: ran too long (10m0s).
signal: segmentation fault (core dumped)
FAIL github.com/panjf2000/ants 607.204s
[root@promesdevapp02 ants]# go test -bench="AntsPool$" -benchmem=true -run=none
goos: linux
goarch: amd64
pkg: github.com/panjf2000/ants
BenchmarkAntsPool-8 1 10892840360 ns/op 14485872 B/op 114421 allocs/op
PASS
ok github.com/panjf2000/ants 10.904s
[root@promesdevapp02 ants]#
对应的是10W,100W,1000W的是否使用线程池的操作所消耗的资源的对比
内存 cpu
10W Nopool 32M
pool(20W) 1M
100W Nopool 490M
pool(20W) 11M
1000W Nopool 16G完全被被消耗,崩溃
pool(20W) 15M cpu不是性能瓶颈,最高就是100w的并发占用了70%
上面是直接使用goroutine的资源消耗,但是正常还要结合http来处理
单CPU测试
package main
import (
"fmt"
"log"
"net/http"
"runtime"
)
func main() {
// 限制为1个CPU
runtime.GOMAXPROCS(1)
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "Hello, world.")
})
log.Fatal(http.ListenAndServe(":8080", nil))
}
共测试五次,五次结果分别如下:(cpu 50%)
ab -c 100 -n 5000 http://127.0.0.1:8080/
Requests per second: 8427.78 [#/sec] (mean)
Requests per second: 7980.73 [#/sec] (mean)
Requests per second: 7509.63 [#/sec] (mean)
Requests per second: 8242.47 [#/sec] (mean)
Requests per second: 8898.19 [#/sec] (mean)
多CPU测试
因为是在同一台机器上测试的,所以限制使用的CPU数为机器的CPU数减一。
package main
import (
"fmt"
"log"
"net/http"
"runtime"
)
func main() {
// 限制为CPU的数量减一
runtime.GOMAXPROCS( runtime.NumCPU() - 1 )
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "Hello, world.")
})
log.Fatal(http.ListenAndServe(":8080", nil))
}
golang的多CPU ab测试结果,共测试5次,结果如下:
$ ab -c 100 -n 5000 http://127.0.0.1:8080/(65%)
Requests per second: 14391.80 [#/sec] (mean)
Requests per second: 14307.09 [#/sec] (mean)
Requests per second: 14285.31 [#/sec] (mean)
Requests per second: 15182.34 [#/sec] (mean)
Requests per second: 14020.53 [#/sec] (mean)
可见go的并发性能很高,但是会有崩溃的风险,最好使用工作池,直接goroutine正常使用于不是很频繁的api调用。例如探针,一般处理万级的请求。
工作池+job队列
这种使用方式,先启动一定数量的goroutine,使用channel,让当前goroutine处于阻塞状态,当有task往通道里传输,然后进行处理
将请求放入队列,通过一定数量(例如CPU核心数)goroutine组成一个worker池(pool),workder池中的worker读取队列执行任务
工作者工作协程,挂入调度器,取Job,执行Job,周而复始
调度器,从Job队列取Job,分配给工作者,周而复始
web响应里,模拟了客户的请求-Job,并将此Job放入Job队列,只有有客户端请求,就周而复始的工作
正常使用使用于大规模的并发请求场景,可以处理百万级请求(通过benchmark来调优参数)
10M的并发连接挑战意味着什么:
1千万的并发连接数
100万个连接/秒——每个连接以这个速率持续约10秒
10GB/秒的连接——快速连接到互联网。
1千万个数据包/秒——据估计目前的服务器每秒处理50K的数据包,以后会更多。过去服务器每秒可以处理100K的中断,并且每一个数据包都产生中断。
10微秒的延迟——可扩展服务器也许可以处理这个规模,但延迟可能会飙升。
10微秒的抖动——限制最大延迟
并发10核技术——软件应支持更多核的服务器。通常情况下,软件能轻松扩展到四核。服务器可以扩展到更多核,因此需要重写软件,以支持更多核的服务器。
异步处理
这种使用方式,将一定数量的goroutine启动处理,留一个channenl返回,使用select读取channel中的数据,完成处理
大并发场景
数据打点,文件上传
场景描述
在一些场景下,有大规模请求(十万或百万级qps),我们处理的请求可能不需要立马知道结果,例如数据的打点,文件的上传等等。这时候我们需要异步化处理。常用的方法有使用resque、MQ、RabbitMQ等。这里我们在Golang语言里进行设计实践。
方案以及演进
1、直接使用goroutine
在Go语言原生并发的支持下,我们可以直接使用一个goroutine(如下方式)去并行处理这个请求。但是,这种方法明显有些不好的地方,我们没法控制goroutine产生数量,如果处理程序稍微耗时,在单机万级十万级qps请求下,goroutine大规模爆发,内存暴涨,处理效率会很快下降甚至引发程序崩溃。
...
go handle(request)
...
2、goroutine协同带缓存的管道
我们定义一个带缓存的管道;
var queue = make(chan job, MAX_QUEUE_SIZE)
然后起一个协程处理管道传来的请求;
go func(){
for {
select {
case job := <-queue:
job.Do(request)
case <- quit:
return
}
}
}()
接收请求,发送job进行处理
job := &Job{request}
queue <- job
这种方法使用了缓冲队列一定程度上了提高了并发,但也是治标不治本,大规模并发只是推迟了问题的发生时间。当请求速度远大于队列的处理速度时,缓冲区很快被打满,后面的请求一样被堵塞了。
3、job队列+工作池
只用缓冲队列不能解决根本问题,这时候我们可以参考一下线程池的概念,定一个工作池(协程池),来限定最大goroutine数目。每次来新的job时,从工作池里取出一个可用的worker来执行job。这样一来即保障了goroutine的可控性,也尽可能大的提高了并发处理能力。
工作池实现
首先,我们定义一个job的接口, 具体内容由具体job实现;
type Job interface {
Do() error
}
然后定义一下job队列和work池类型,这里我们work池也用golang的channel实现。
// define job channel
type JobChan chan Job
// define worker channer
type WorkerChan chan JobChan
我们分别维护一个全局的job队列和工作池。
var (
JobQueue JobChan
WorkerPool WorkerChan
)
worker的实现。每一个worker都有一个job channel,在启动worker的时候会被注册到work pool中。启动后通过自身的job channel取到job并执行job。
type Worker struct {
JobChannel JobChan
quit chan bool
}
func (w *Worker) Start() {
go func() {
for {
// regist current job channel to worker pool
WorkerPool <- w.JobChannel
select {
case job := <-w.JobChannel:
if err := job.Do(); err != nil {
fmt.printf("excute job failed with err: %v", err)
}
// recieve quit event, stop worker
case <-w.quit:
return
}
}
}()
}
实现一个分发器(Dispatcher)。分发器包含一个worker的指针数组,启动时实例化并启动最大数目的worker,然后从job全局队列中不断取job选择可用的worker,然后将这个job仍向这个worker的channel中去,然后这个worker来执行job。
type Dispatcher struct {
Workers []*Worker
quit chan bool
}
func (d *Dispatcher) Run() {
for i := 0; i < MaxWorkerPoolSize; i++ {
worker := NewWorker()
d.Workers = append(d.Workers, worker)
worker.Start()
}
for {
select {
case job := <-JobQueue:
go func(job Job) {
jobChan := <-WorkerPool
jobChan <- job
}(job)
// stop dispatcher
case <-d.quit:
return
}
}
}
完整的实例源码
package main
import (
"net/http"
"fmt"
)
type Job struct {
request string
}
func (j *Job)Handle(){
fmt.Println("test")
}
type worker struct {
work JobChan
quit chan bool
}
func (w *worker)start(i int) {
fmt.Println("start worker:",i)
go func(i int) {
for {
fmt.Println("add free worklist")
workList <- w.work
select {
case Task := <- w.work:
fmt.Println("worker",i,"handle job .....")
Task.Handle()
fmt.Println("worker",i,"handle over .....")
case <- w.quit:
return
}
}
}(i)
}
type schedule struct {
workers []*worker
quit chan bool
}
func newWorker() *worker {
workchan := make(chan Job,1)
return &worker{work:workchan}
}
func (s *schedule)schedule() {
workList = make(chan JobChan,10)
fmt.Println("start pool")
for i := 0; i < 10; i++ {
w := newWorker()
s.workers = append(s.workers,w)
w.start(i)
}
for {
fmt.Println("get task and get worker")
select {
case job := <-queue:
go func(job Job) {
fmt.Println("get worker")
jobChan := <-workList
fmt.Println("insert task into job")
jobChan <- job
}(job)
// stop dispatcher
case <-s.quit:
return
}
}
}
//define type queue and work
type JobChan chan Job
type WorkChan chan JobChan
var queue JobChan
var workList WorkChan
func newschedule() schedule {
fmt.Println("newschedule")
return schedule{}
}
func init(){
s := newschedule()
go s.schedule()
}
func main() {
fmt.Println("main")
queue = make(chan Job,1024)
http.HandleFunc("/metrics", func(w http.ResponseWriter, r *http.Request) {
job := Job{"test"}
queue <- job
})
fmt.Println("start sueccess and listen at 9000!!")
http.ListenAndServe("localhost:9000",nil)
}
邮件状态跟踪
场景描述
邮件状态跟踪,有很多办法来跟踪这些状态的改变。不外乎通过定期的轮询或者系统通知来得到状态的变化。这两种方法都有它们的优缺点。对邮件这个产品来说,让用户尽快收到新的邮件是一个考量指标。邮件的轮询会产生大概每秒5万个HTTP请求,其中60%的请求会返回304状态(表示邮箱没有变化)。因此,为了减少服务器的负荷并加速邮件的接收,我们决定重写一个publisher-subscriber服务(这个服务通常也会称作bus,message broker或者event-channel)。这个服务负责接收状态更新的通知,然后还处理对这些更新的订阅。
架构
旧的架构。浏览器(Browser)会定期轮询API服务来获得邮件存储服务(Storage)的更新。
新的架构。浏览器(Browser)和通知API服务(notificcation API)建立一个WebSocket连接。通知API服务会发送相关的订阅到Bus服务上。当收到新的电子邮件时,存储服务(Storage)向Bus发送一个通知,Bus又将通知发送给相应的订阅者。API服务为收到的通知找到相应的连接,然后把通知推送到用户的浏览器。
我们今天就来讨论一下这个API服务(也可以叫做WebSocket服务)。在开始之前,我想提一下这个在线服务处理将近3百万个连接。
惯用的做法(The idiomatic way)
首先,我们看一下不做任何优化会如何用Go来实现这个服务的部分功能。在使用net/http 实现具体功能前,让我们先讨论下我们将如何发送和接收数据。这些数据是定义在WebSocket协议之上的(例如JSON对象),我们在下文中会成他们为packet。
我们先来实现Channel 结构,它包含相应的逻辑来通过WebScoket连接发送和接收packet。
Channel结构
// Packet represents application level data.
type Packet struct {
...
}
// Channel wraps user connection.
type Channel struct {
conn net.Conn // WebSocket connection.
send chan Packet // Outgoing packets queue.
}
func NewChannel(conn net.Conn) *Channel {
c := &Channel{
conn: conn,
send: make(chan Packet, N),
}
go c.reader()
go c.writer()
return c
}
这里我要强调的是读和写这两个goroutines。每个goroutine都需要各自的内存栈。栈的初始大小由操作系统和Go的版本决定,通常在2KB到8KB之间。我们之前提到有3百万个在线连接,如果每个goroutine栈需要4KB的话,所有连接就需要24GB的内存。这还没算上给Channel 结构,发送packet用的ch.send 和其它一些内部字段分配的内存空间。
接下来看一下I/O goroutines的“reader”的实现:
func (c *Channel) reader() {
// We make a buffered read to reduce read syscalls.
buf := bufio.NewReader(c.conn)
for {
pkt, _ := readPacket(buf)
c.handle(pkt)
}
}
这里我们使用了bufio.Reader ,每次都会在buf 大小允许的范围内尽量读取多的字节,从而减少read() 系统调用的次数。在无限循环中,我们期望会接收到新的数据,请记住之前这句话:期望接收到新的数据。我们之后会讨论到这一点。
我们把packet的解析和处理逻辑都忽略掉了,因为它们和我们要讨论的优化不相关。不过buf 值得我们的关注:它的缺省大小是4KB。这意味着所有连接将消耗掉额外的12 GB内存。“writer”也是类似的情况:
func (c *Channel) writer() {
// We make buffered write to reduce write syscalls.
buf := bufio.NewWriter(c.conn)
for pkt := range c.send {
_ := writePacket(buf, pkt)
buf.Flush()
}
}
我们在待发送packet的c.send channel上循环将packet写到缓存(buffer)里,细心的读者肯定已经发现,这又是额外的4KB内存。3百万个连接会占用12GB的内存。
接下来我们看一下http的实现,我们已经有了一个简单的Channel 实现,现在我们需要一个WebSocket连接。
注:如果你不知道WebSocket是怎么工作的,那么这里值得一提的是客户端是通过一个叫升级(Upgrade)请求的特殊HTTP机制来建立WebSocket的。在成功处理升级请求以后,服务端和客户端使用TCP连接来交换二进制的WebSocket帧(frames)。
import (
"net/http"
"some/websocket"
)
http.HandleFunc("/v1/ws", func(w http.ResponseWriter, r *http.Request) {
conn, _ := websocket.Upgrade(r, w)
ch := NewChannel(conn)
//...
})
请注意这里的http.ResponseWriter 结构包含bufio.Reader 和bufio.Writer (各自分别包含4KB的缓存)。它们用于*http.Request 初始化和返回结果。
不管是哪个WebSocket,在成功回应一个升级请求之后,服务端在调用responseWriter.Hijack() 之后会接收到一个I/O缓存和对应的TCP连接。
注:有时候我们可以通过net/http.putBufio{Reader,Writer} 调用把缓存释放回net/http 里的sync.Pool 。
这样,这3百万个连接又需要额外的24GB内存。
所以,为了这个什么都不干的程序,我们已经占用了72GB的内存!
优化
我们来回顾一下前面介绍的用户连接的工作流程。在建立WebSocket之后,客户端会发送请求订阅相关事件(我们这里忽略类似ping/pong 的请求),接下来,在整个连接的生命周期里,客户端可能就不会发送任何其它数据了,连接的生命周期可能会持续几秒钟到几天。
所以在大部分时间里,Channel.reader() 和Channel.writer() 都在等待接收和发送数据。与它们一起等待的是各自分配的4 KB的I/O缓存。
现在,我们发现有些地方是可以做进一步优化的,对吧?
1、使用Netpoll
你还记得Channel.reader() 的实现使用了bufio.Reader.Read() 吗?bufio.Reader.Read() 又会调用conn.Read() 。这个调用会被阻塞以等待接收连接上的新数据。如果连接上有新的数据,Go的运行环境(runtime)就会唤醒相应的goroutine让它去读取下一个packet。之后,goroutine会被再次阻塞来等待新的数据。我们来研究下Go的运行环境是怎么知道goroutine需要被唤醒的。
如果我们看一下conn.Read() 的实现,就会看到它调用了net.netFD.Read() :
// net/fd_unix.go
func (fd *netFD) Read(p []byte) (n int, err error) {
//...
for {
n, err = syscall.Read(fd.sysfd, p)
if err != nil {
n = 0
if err == syscall.EAGAIN {
if err = fd.pd.waitRead(); err == nil {
continue
}
}
}
//...
break
}
//...
}
Go使用了sockets的非阻塞模式。EAGAIN表示socket里没有数据了但不会阻塞在空的socket上,OS会把控制权返回给用户进程。
这里它首先对连接文件描述符进行read() 系统调用。如果read() 返回的是EAGAIN 错误,运行环境就是调用pollDesc.waitRead() :
// net/fd_poll_runtime.go
func (pd *pollDesc) waitRead() error {
return pd.wait('r')
}
func (pd *pollDesc) wait(mode int) error {
res := runtime_pollWait(pd.runtimeCtx, mode)
//...
}
如果继续深挖,我们可以看到netpoll的实现在Linux里用的是epoll而在BSD里用的是kqueue。我们的这些连接为什么不采用类似的方式呢?只有在socket上有可读数据时,才分配缓存空间并启用读数据的goroutine。
在github.com/golang/go上,有一个关于 暴露(export) netpoll函数的请求,于是我们可以干掉goroutines
假设我们用Go语言实现了netpoll。我们现在可以避免创建Channel.reader() 的goroutine,取而代之的是从订阅连接里收到新数据的事件。
ch := NewChannel(conn)
// Make conn to be observed by netpoll instance.
poller.Start(conn, netpoll.EventRead, func() {
// We spawn goroutine here to prevent poller wait loop
// to become locked during receiving packet from ch.
go Receive(ch)
})
// Receive reads a packet from conn and handles it somehow.
func (ch *Channel) Receive() {
buf := bufio.NewReader(ch.conn)
pkt := readPacket(buf)
c.handle(pkt)
}
Channel.writer() 相对容易一点,因为我们只需在发送packet的时候创建goroutine并分配缓存。
func (ch *Channel) Send(p Packet) {
if c.noWriterYet() {
go ch.writer()
}
ch.send <- p
}
注意,这里我们没有处理write() 系统调用时返回的EAGAIN 。我们依赖Go运行环境去处理它。这种情况很少发生。如果需要的话我们还是可以像之前那样来处理。
从ch.send 读取待发送的packets之后,ch.writer() 会完成它的操作,最后释放goroutine的栈和用于发送的缓存。通过避免这两个连续运行的goroutine所占用的I/O缓存和栈内存,我们已经节省了48GB。
2、控制资源-Goroutine池
大量的连接不仅仅会造成大量的内存消耗。在开发服务端的时候,我们还不停地遇到竞争条件(race conditions)和死锁(deadlocks)。随之而来的是所谓的自我分布式阻断攻击(self-DDOS)。在这种情况下,客户端会悍然地尝试重新连接服务端而把情况搞得更加糟糕。
举个例子,如果因为某种原因我们突然无法处理ping/pong 消息,这些空闲连接就会不断地被关闭(它们会以为这些连接已经无效因此不会收到数据)。然后客户端每N秒就会以为失去了连接并尝试重新建立连接,而不是继续等待服务端发来的消息。
在这种情况下,比较好的办法是让负载过重的服务端停止接受新的连接,这样负载均衡器(例如nginx)就可以把请求转到其它的服务端上去。
撇开服务端的负载不说,如果所有的客户端突然(很可能是因为某个bug)向服务端发送一个packet,我们之前节省的48 GB内存又将会被消耗掉。因为这时我们又会和开始一样给每个连接创建goroutine并分配缓存。
可以用一个goroutine池来限制同时处理packets的数目。下面的代码是一个简单的实现:
package gopool
func New(size int) *Pool {
return &Pool{
work: make(chan func()),
sem: make(chan struct{}, size),
}
}
func (p *Pool) Schedule(task func()) error {
select {
case p.work <- task:
case p.sem <- struct{}{}:
go p.worker(task)
}
}
func (p *Pool) worker(task func()) {
defer func() { <-p.sem }
for {
task()
task = <-p.work
}
}
我们使用netpoll的代码就变成下面这样:
pool := gopool.New(128)
poller.Start(conn, netpoll.EventRead, func() {
// We will block poller wait loop when
// all pool workers are busy.
pool.Schedule(func() {
Receive(ch)
})
})
现在我们不仅要等可读的数据出现在socket上才能读packet,还必须等到从池里获取到空闲的goroutine。
同样的,我们修改下Send() 的代码:
pool := gopool.New(128)
func (ch *Channel) Send(p Packet) {
if c.noWriterYet() {
pool.Schedule(ch.writer)
}
ch.send <- p
}
这里我们没有调用go ch.writer() ,而是想重复利用池里goroutine来发送数据。 所以,如果一个池有N 个goroutines的话,我们可以保证有N 个请求被同时处理。而N + 1 个请求不会分配N + 1 个缓存。goroutine池允许我们限制对新连接的Accept() 和Upgrade() ,这样就避免了大部分DDoS的情况。
3、零拷贝升级(Zero-copy upgrade)
之前已经提到,客户端通过HTTP升级(Upgrade)请求切换到WebSocket协议。下面显示的是一个升级请求:
GET /ws HTTP/1.1
Host: mail.ru
Connection: Upgrade
Sec-Websocket-Key: A3xNe7sEB9HixkmBhVrYaA==
Sec-Websocket-Version: 13
Upgrade: websocket
HTTP/1.1 101 Switching Protocols
Connection: Upgrade
Sec-Websocket-Accept: ksu0wXWG+YmkVx+KQR2agP0cQn4=
Upgrade: websocket
我们接收HTTP请求和它的头部只是为了切换到WebSocket协议,而http.Request 里保存了所有头部的数据。从这里可以得到启发,如果是为了优化,我们可以放弃使用标准的net/http 服务并在处理HTTP请求的时候避免无用的内存分配和拷贝。
举个例子,http.Request 包含了一个叫做Header的字段。标准net/http 服务会将请求里的所有头部数据全部无条件地拷贝到Header字段里。你可以想象这个字段会保存许多冗余的数据,例如一个包含很长cookie的头部。
我们如何来优化呢?
WebSocket实现
不幸的是,在我们优化服务端的时候所有能找到的库只支持对标准net/http 服务做升级。而且没有一个库允许我们实现上面提到的读和写的优化。为了使这些优化成为可能,我们必须有一套底层的API来操作WebSocket。为了重用缓存,我们需要类似下面这样的协议函数:
func ReadFrame(io.Reader) (Frame, error)
func WriteFrame(io.Writer, Frame) error
如果我们有一个包含这样API的库,我们就按照下面的方式从连接上读取packets:
// getReadBuf, putReadBuf are intended to
// reuse *bufio.Reader (with sync.Pool for example).
func getReadBuf(io.Reader) *bufio.Reader
func putReadBuf(*bufio.Reader)
// readPacket must be called when data could be read from conn.
func readPacket(conn io.Reader) error {
buf := getReadBuf()
defer putReadBuf(buf)
buf.Reset(conn)
frame, _ := ReadFrame(buf)
parsePacket(frame.Payload)
//...
}
简而言之,我们需要自己写一个库。
github.com/gobwas/ws
ws 库的主要设计思想是不将协议的操作逻辑暴露给用户。所有读写函数都接受通用的io.Reader 和io.Writer 接口。因此它可以随意搭配是否使用缓存以及其它I/O的库。
除了标准库net/http 里的升级请求,ws 还支持零拷贝升级。它能够处理升级请求并切换到WebSocket模式而不产生任何内存分配或者拷贝。ws.Upgrade() 接受io.ReadWriter (net.Conn 实现了这个接口)。换句话说,我们可以使用标准的net.Listen() 函数然后把从ln.Accept() 收到的连接马上交给ws.Upgrade() 去处理。库也允许拷贝任何请求数据来满足将来应用的需求(举个例子,拷贝Cookie 来验证一个session)。
下面是处理升级请求的性能测试:标准net/http 库的实现和使用零拷贝升级的net.Listen() :
BenchmarkUpgradeHTTP 5156 ns/op 8576 B/op 9 allocs/op
BenchmarkUpgradeTCP 973 ns/op 0 B/op 0 allocs/op
使用ws 以及零拷贝升级为我们节省了24 GB的空间。这些空间原本被用做net/http 里处理请求的I/O缓存。
回顾
让我们来回顾一下之前提到过的优化:
一个包含缓存的读goroutine会占用很多内存。方案: netpoll(epoll, kqueue);重用缓存。
一个包含缓存的写goroutine会占用很多内存。方案: 在需要的时候创建goroutine;重用缓存。
存在大量连接请求的时候,netpoll不能很好工作。方案: 重用goroutines并且限制它们的数目。
net/http 对升级到WebSocket请求的处理不是最高效的。方案: 在TCP连接上实现零拷贝升级。
下面是服务端的大致实现代码:
import (
"net"
"github.com/gobwas/ws"
)
ln, _ := net.Listen("tcp", ":8080")
for {
// Try to accept incoming connection inside free pool worker.
// If there no free workers for 1ms, do not accept anything and try later.
// This will help us to prevent many self-ddos or out of resource limit cases.
err := pool.ScheduleTimeout(time.Millisecond, func() {
conn := ln.Accept()
_ = ws.Upgrade(conn)
// Wrap WebSocket connection with our Channel struct.
// This will help us to handle/send our app's packets.
ch := NewChannel(conn)
// Wait for incoming bytes from connection.
poller.Start(conn, netpoll.EventRead, func() {
// Do not cross the resource limits.
pool.Schedule(func() {
// Read and handle incoming packet(s).
ch.Recevie()
})
})
})
if err != nil {
time.Sleep(time.Millisecond)
}
}
结论
在程序设计时,过早优化是万恶之源。
上面的优化是有意义的,但不是所有情况都适用。举个例子,如果空闲资源(内存,CPU)与在线连接数之间的比例很高的话,优化就没有太多意义。当然,知道什么地方可以优化以及如何优化总是有帮助的。
最终,原先每个连接平均占用 65KB的内存, 优化后只占10KB的内存,优化效果明显。
性能问题
我们先看两个用Go做消息推送的案例实际处理能力
60消息推送的数据:
16台机器,标配:24个硬件线程,64GB内存 Linux Kernel 2.6.32 x86_64
单机80万并发连接,load 0.2~0.4,CPU 总使用率 7%~10%,内存占用20GB (res)
目前接入的产品约1280万在线用户
2分钟一次GC,停顿2秒 (1.0.3 的 GC 不给力,直接升级到 tip,再次吃螃蟹)
15亿个心跳包/天,占大多数。
京东云消息推送系统(团队人数:4):
单机并发tcp连接数峰值118w,内存占用23G(Res),Load 0.7左右
心跳包 4k/s
gc时间2-3.x s
可以看出来性能很强劲。再来看看go中一些性能测试:
1、管道chan吞吐极限10,000,000,单次Put,Get耗时大约100ns/op,无论是采用单Go程,还是多Go程并发(并发数:100, 10000, 100000),耗时均没有变化,Go内核这对chan进行优化。
解决之道:在系统设计时,避免使用管道chan传递主业务数据,避免将业务流程处理流程分割到对个Go程中执行,这样做减少chan传输耗时,和Go程调度耗时,性能会有很大的提升。
案例分析:nsq和nats都是实时消息队列,nsq在客户端端和服务端大量使用chan转发消息,导致性能不佳,只有100,000/s;而nats服务端在分发消息流程中,没有使用chan,只在客户端接收时使用chan,性能可达到1,000,000/s。
2、互斥锁Mutex在单Go程时Lock,Unlock耗时大约20ns/op,但是采用多Go程时,性能急剧下降,并发越大耗时越长,在Go1.5并发数达到1024耗时900ns/op,Go1.6优化到300ns/op,究其原因,是构建在CPU的原子操作之上,抢占过于频繁将导致,消耗大量CPU时钟,进而CPU多核无法并行。
解决之道:采用分区,将需要互斥保护的数据,分成多个固定分区(建议是2的整数倍,如256),访问时先定位分区(不互斥),这样就可降低多个Go程竞争1个数据分区的概率。
案例分析:Golang的Go程调度模块,在管理大量的Go程,使用的就是数据分区。
3、select异步操作在单管道时耗时120ns/op,但是随着管道数增加,性能线性下降,每增加1个管道增加100ns/op,究其原因,slelect时当chan数超过1后,Go内部是创建一个Go程,有它每1ms轮训的方式检查每个chan是否可用,而不是采用事件触发。
解决之道:在select中避免使用过多的管道chan分支,或者把无法用到的chan置为nil;解决select超时,避免使用单独的超时管道,应与数据返回管道共享。
案例分析:nsq和nats都是实时消息队列,由于nsq大量使用chan,这就必然导致大量使用select对多chan操作,结果是性能不高。
4、Go调度性能低下,当出现1,000,000Go程时,Go的调度器的性能急剧下降。
解决之道:避免动态创建Go程,服务端收到数据并处理的流程中,避免使用chan传递业务数据,这样会引起Go程调度。
案例分析:nsq和nats都是实时消息队列,由于nsq大量使用chan,这就必然导致在服务过程中,引起Go调度,结果是性能不高。
5、defer性能不高,每次defer耗时100ns,,在一个func内连续出现多次,性能消耗是100ns*n,累计出来浪费的cpu资源很大的。
解决之道:除了需要异常捕获时,必须使用defer;其它资源回收类defer,可以判断失败后,使用goto跳转到资源回收的代码区。
6、内存管理器性能低下,申请16字节的内存,单次消耗30ns,64字节单次消耗70ns,随着申请内存尺寸的增长,耗时会迅速增长。加上GC的性能在1.4, 1.5是都不高,直到1.6, 1.7才得到改善。
解决之道:建议使用pool,单次Put,Get的耗时大约在28ns,在并发情况下可达到18ns,比起每次创建,会节省很多的CPU时钟。