容器网络的建立和控制是一种结合了network namespace、iptables、linux网桥、route table等多种Linux内核技术的综合方案,在宿主机和容器内分别创建虚拟接口,并让它们彼此连通。
- network namespace:主要提供了关于网络资源的隔离,在网络栈中,包括网卡(Network Interface)、回环设备(Loopback Device)、路由表(Routing Table)和 iptables 规则、IPv4和IPv6协议栈、/proc/net目录、/sys/class/net目录、端口(socket)等。
- linux Bridge:功能相当于物理交换机,为连在其上的设备(容器)转发数据帧。如docker0网桥。
- iptables:主要为容器提供NAT以及容器网络安全。
- veth pair:两个虚拟网卡组成的数据通道。在Docker中,用于连接Docker容器和Linux Bridge。一端在容器中作为eth0网卡,另一端在Linux Bridge中作为网桥的一个端口。
基础理论
在顶层设计中,Docker 网络架构由 3 个主要部分构成:CNM、Libnetwork 和驱动。
- CNM 是设计标准。在 CNM 中,规定了 Docker 网络架构的基础组成要素。
- Libnetwork 是 CNM 的具体实现,并且被 Docker 采用,Libnetwork 通过 Go 语言编写,并实现了 CNM 中列举的核心组件。
- 驱动通过实现特定网络拓扑的方式来拓展该模型的能力。
CNM
Docker 网络架构的设计规范是 CNM。CNM 中规定了 Docker 网络的基础组成要素,完整内容见GitHub。
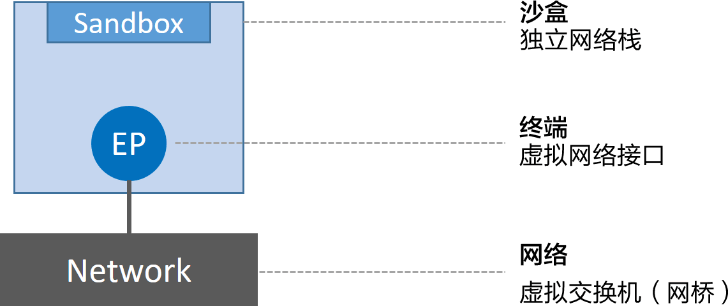
CNM 定义了 3 个基本要素:沙盒(Sandbox)、终端(Endpoint)和网络(Network)。
- 沙盒是一个独立的网络栈。其中包括以太网接口、端口、路由表以及 DNS 配置。可以看为一个独立的nanmespace。
- 终端就是虚拟网络接口。就像普通网络接口一样,终端主要职责是负责创建连接。在 CNM 中,终端负责将沙盒连接到网络。可以看作我们使用的veth pair对。
- 网络是 802.1d 网桥(类似大家熟知的交换机)的软件实现。因此,网络就是需要交互的终端的集合,并且终端之间相互独立。可以看作我们docker0网桥。
下图展示了 3 个组件是如何连接的。
Docker 环境中最小的调度单位就是容器,而 CNM 也恰如其名,负责为容器提供网络功能。
下图展示了 CNM 组件是如何与容器进行关联的——沙盒被放置在容器内部,为容器提供网络连接。
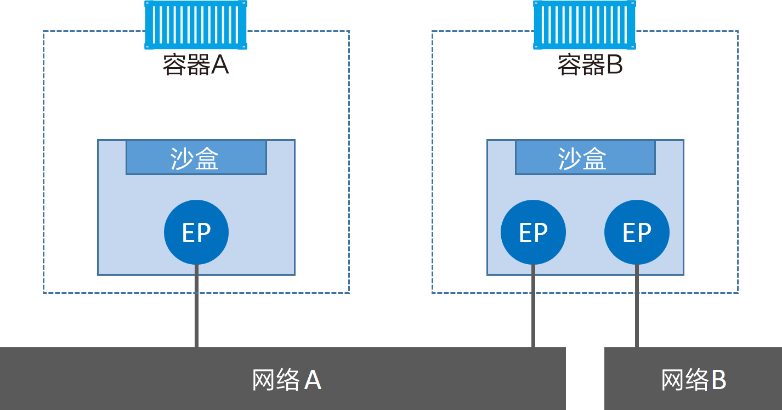
容器 A 只有一个接口(终端)并连接到了网络 A。容器 B 有两个接口(终端)并且分别接入了网络 A 和网络 B。容器 A 与 B 之间是可以相互通信的,因为都接入了网络 A。但是,如果没有三层路由器的支持,容器 B 的两个终端之间是不能进行通信的。
需要重点理解的是,终端与常见的网络适配器类似,这意味着终端只能接入某一个网络。因此,如果容器需要接入到多个网络,就需要多个终端。
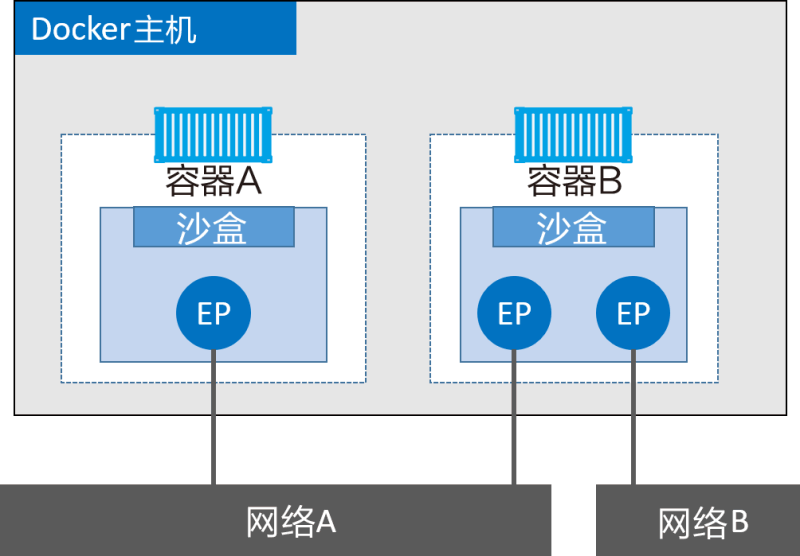
下图对前面的内容进行拓展,加上了 Docker 主机。虽然容器 A 和容器 B 运行在同一个主机上,但其网络堆栈在操作系统层面是互相独立的,这一点由沙盒机制保证。
Libnetwork
CNM 是设计规范文档,Libnetwork 是标准的实现。Libnetwork 是开源的,采用 Go 语言编写,它跨平台(Linux 以及 Windows),并且被 Docker 所使用。
在 Docker 早期阶段,网络部分代码都存在于 daemon 当中。daemon 变得臃肿,并且不符合 UNIX 工具模块化设计原则,即既能独立工作,又易于集成到其他项目,所以,Docker 将该网络部分从 daemon 中拆分,并重构为一个叫作 Libnetwork 的外部类库。
现在,Docker 核心网络架构代码都在 Libnetwork 当中。Libnetwork 实现了 CNM 中定义的全部 3 个组件。此外它还实现了本地服务发现(Service Discovery)、基于 Ingress 的容器负载均衡,以及网络控制层和管理层功能。
服务发现(Service Discovery)
其底层实现是利用了 Docker 内置的 DNS 服务器,为每个容器提供 DNS 解析功能。
我们通过一个实例来了解如何使用dns做服务发现的
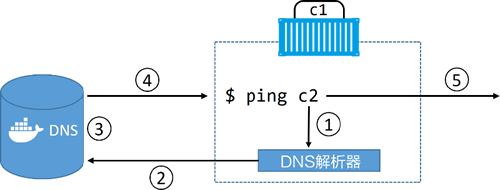
1) ping c2 命令调用本地 DNS 解析器,尝试将“c2”解析为具体 IP 地址。每个 Docker 容器都有本地 DNS 解析器。
2) 如果本地解析器在本地缓存中没有找到“c2”对应的 IP 地址,本地解析器会向 Docker DNS 服务器发起一个递归查询。本地服务解析器是预先配置好并知道 Docker DNS 服务器细节的。
3) Docker DNS 服务器记录了全部容器名称和 IP 地址的映射关系,其中容器名称是容器在创建时通过 –name 或者 –net-alias 参数设置的。这意味着 Docker DNS 服务器知道容器“c2”的 IP 地址。
4) DNS 服务返回“c2”对应的 IP 地址到“c1”本地 DNS 解析器。之所以会这样是因为两个容器位于相同的网络当中,如果所处网络不同则该命令不可行。
5) ping 命令被发往“c2”对应的 IP 地址。
每个启动时使用了 –name 参数的 Swarm 服务或者独立的容器,都会将自己的名称和 IP 地址注册到 Docker DNS 服务。这意味着容器和服务副本可以通过 Docker DNS 服务互相发现。
但是,服务发现是受网络限制的。这意味着名称解析只对位于同一网络中的容器和服务生效。如果两个容器在不同的网络,那么就不能互相解析。
驱动
如果说 Libnetwork 实现了控制层和管理层功能,那么驱动就负责实现数据层。比如,网络连通性和隔离性是由驱动来处理的,驱动层实际创建网络对象也是如此,其关系如下图所示。
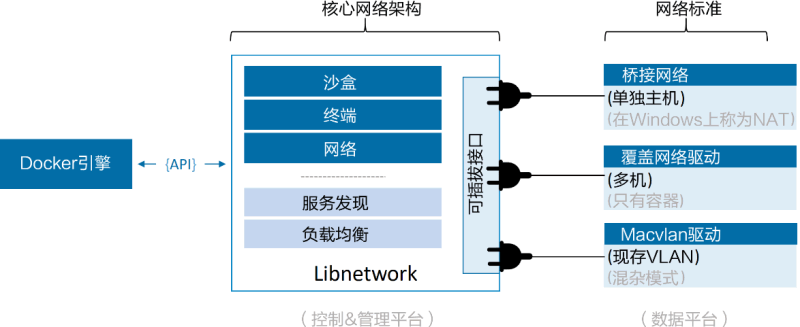
Docker 封装了若干内置驱动,通常被称作原生驱动或者本地驱动。
在 Linux 上包括 Bridge、Overlay 以及 Macvlan,在 Windows 上包括 NAT、Overlay、Transport 以及 L2 Bridge。
第三方也可以编写 Docker 网络驱动。这些驱动叫作远程驱动,例如 Calico、Contiv、Kuryr 以及 Weave。
每个驱动都负责其上所有网络资源的创建和管理。举例说明,一个叫作“prod-fe-cuda”的覆盖网络由 Overlay 驱动所有并管理。这意味着 Overlay 驱动会在创建、管理和删除其上网络资源的时候被调用。
为了满足复杂且不固定的环境需求,Libnetwork 支持同时激活多个网络驱动。这意味着 Docker 环境可以支持一个庞大的异构网络。
基本概念
主机网络
可以声明直接使用宿主机的网络栈(–net=host),即:不开启 Network Namespace,这样就和主机使用同一个网络。
像这样直接使用宿主机网络栈的方式,虽然可以为容器提供良好的网络性能,但也会不可避免地引入共享网络资源的问题,比如端口冲突。所以,在大多数情况下,我们都希望容器进程能使用自己 Network Namespace 里的网络栈,即:拥有属于自己的 IP 地址和端口。
桥接网络
桥接网络(Bridge Network),在同一宿主机上的多个容器可以连接到同一桥接网络来实现彼此网络通信,之前提到了Docker默认的虚拟网桥为docker0,当然也可以创建自定义的网络生成新的虚拟网桥,而将容器连接到的该虚拟网桥上形成的网络称为桥接网络。在运行容器时可指定–net=bridge使用桥接模式,将容器桥接到宿主机的虚拟网桥上,从虚拟网桥的空闲网段中划分出一个子网私有IP分配给该容器。
这里的网桥起到的是虚拟交换机的作用,它是一个工作在数据链路层(Data Link)的设备,主要功能是根据 MAC 地址学习来将数据包转发到网桥的不同端口(Port)上,它会维护一个 CAM 表即交换机通过 MAC 地址学习维护的端口和 MAC 地址的对应表。
桥接网络的基本实现下面我们详细说明。
这边的桥接网络其实是我们的单机容器网络,也是我们跨主网络通信的基础,在单层网络中,直接是通过二层的mac通信的,docker0和宿主机的eth0也是直连的,所以我们可以直接访问主机以及和主机相关连的其他主机,因为我们会在容器中配置二层路由, 如果是跨主通信,也就是不同docker0之间的通信,我们会有一条默认的网关路由,意思就是我们只要跨主也就是跨网端通信就要走网关,删除这条路由就会no route,并不会广播走二层来通信。
所以默认二层三层两条路由。
跨主通信的路由
$ ip route
default via 10.168.0.1 dev eth0
100.96.0.0/16 dev flannel0 proto kernel scope link src 100.96.1.0
100.96.1.0/24 dev docker0 proto kernel scope link src 100.96.1.1
10.168.0.0/24 dev eth0 proto kernel scope link src 10.168.0.2
覆盖网络
重叠网络(Overly Network,也有的译成叠加或覆盖网络),在物理网络之上,通过软件定义网络(Software Defined Network, SDN) 创建虚拟网络抽象,使得应用之间在逻辑上彼此隔离,但共享相同的底层物理网络,同时简化网络管理。
重叠网技术的基本思路是在互联网承载层和应用层之间增加一个中间层,结合IP承载网技术,为上层业务和应用提供有针对性的服务,对已有的应用和业务进行适当控制,是对现有互联网体系架构的系统性修补。在软件定义网络领域中,重叠网络的实现大多采用隧道(Tunneling)技术实现,它可以基于现行的IP网络进行叠加部署,消除传统二层网络的限制,如VXLAN、NVGRE等,都是基于隧道原理实现网络通信,利用叠加在三层网络之上的虚拟网络传递二层数据包,实现了可以跨越三层物理网络进行通信的二层逻辑网络,突破了传统二层网络中存在的物理位置受限、VLAN数量有限等障碍,大幅度降低管理成本和运营风险。
在Docker 1.9之后的版本中,Docker官方集成了重叠网络的特性支持,用户可以在Swarm中使用它或者将其作为Compose工具。通过创建虚拟网络并将其连接到容器上,可实现多个主机上容器相互通信,并且能够实现不同的应用程序或者应用程序不同部分的相互隔离。
Docker网络方式
Docker 的子网络是可插拔的,默认支持几种驱动程序,提供核心网络功能。
- bridge: 默认的网络驱动。当你的应用程序需要在单独的容器中运行时,通常会使用桥接网络。
- host: 对于独立容器,和主机之间没有网络隔离,直接使用主机的网络。 host 仅适用于 Docker 17.06 以及更高版本的 swarm 服务。
- container模式网络 使用–net =container:指定容器名,可以多个容器共用一个网络
- none: 容器禁用所有网络。通常与自定义网络驱动一起使用。 none 对于 swarm 服务不可用。
- overlay: Overlay 将多个 Docker 守护进程连接在一起,并且可以在 swarms 服务内部相互通信。还可以使用 Overlay 网络在 swarm 服务和独立容器之间通信,或者在不同的 Docker 守护进程上两个独立容器之间通信。该策略无需在这些容器之间在操作系统级别路由。
- macvlan: Macvlan 网络允许你为容器分配 MAC 地址,使其显示为网络上的物理设备。Docker 守护程序通过 MAC 地址将流量路由到容器。 macvlan 一般用于处理希望可以连接到屋里网络的陈旧的应用程序,而不是通过 Docker 的主机网络来路由。
- 网络插件: 你可以使用 Docker 安装和使用第三方插件。在 DockerHub 或者第三方的供应商可以找到可用的插件。
可以在docker run时通过–net参数来指定容器的网络配置。
bridge模式
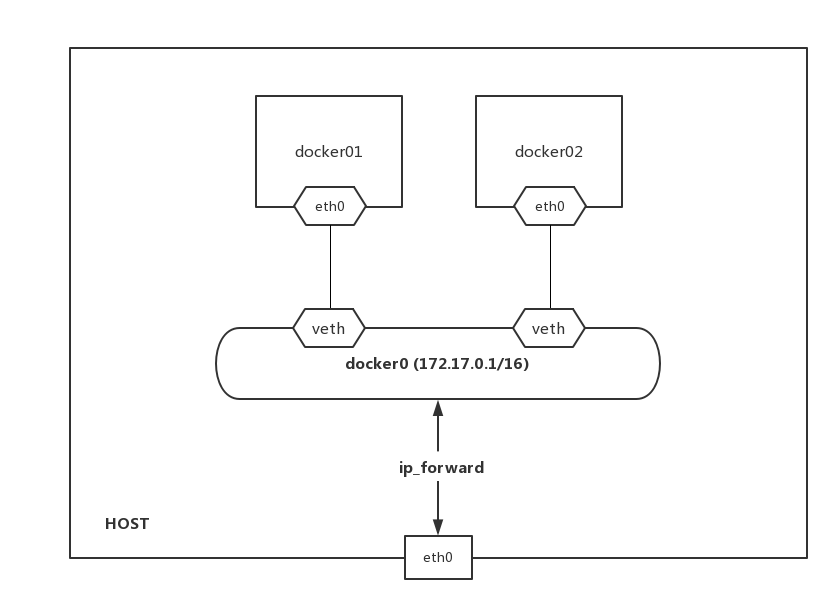
使用–net=bridge指定,为默认模式,连接到默认的网桥docker0,docker0是虚拟网桥,使用软件技术模拟的一套内部网络。我们此模式会为每个容器分配一个独立的网络命名空间,使用该设置可以看到在容器中创建了eth0。
当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上,默认地址172.17.0.0/16的地址。
从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。在主机上创建一对虚拟网卡veth pair设备,Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0(容器的网卡),另一端放在主机中,以vethxxx这样类似的名字命名,并将这个网络设备加入到docker0网桥中。可以通过brctl show命令查看。所以Docker创建一个容器的时候,会执行如下操作:
- 创建一对虚拟接口,即veth pair,分别放到宿主机和容器中;
- 主机一端桥接到默认的docker0或指定网桥上,具有一个唯一的名字,如veth0ac844e;
- 另一端放到新容器中,并修改名字为eth0,该接口只在容器的命名空间可见;
- 从网桥可用地址段中获取一个空闲地址分配给容器的eth0,并配置默认路由到桥接网卡veth0ac844e。
结构图
实例
# docker run --name b1 -it --network bridge --rm busybox:latest 默认使用桥接模式,使用docker0虚拟网桥,创建一对虚拟接口eth0和veth
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:02
inet addr:172.17.0.2 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:acff:fe11:2/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:12 errors:0 dropped:0 overruns:0 frame:0
TX packets:6 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1016 (1016.0 B) TX bytes:508 (508.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
/ # ping 10.11.55.5 正常访问宿主机
PING 10.11.55.5 (10.11.55.5): 56 data bytes
64 bytes from 10.11.55.5: seq=0 ttl=64 time=0.292 ms
/ # exit
连接在同一个网桥上的IP都是相互通的。但是对于不同的网桥,哪怕是在一台主机上也是不通的,如下
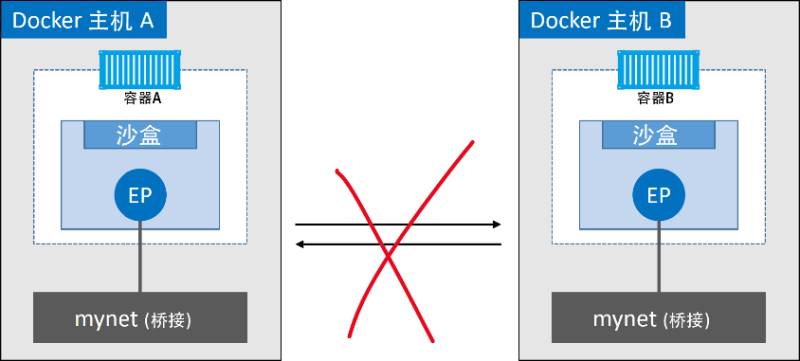
我们在看主机的网络
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 52:54:00:69:06:60 brd ff:ff:ff:ff:ff:ff
inet 172.16.0.6/20 brd 172.16.15.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe69:660/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:74:13:f5:ff brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:74ff:fe13:f5ff/64 scope link
valid_lft forever preferred_lft forever
当运行一个容器时,我们可以看到在docker主机上多了一个网卡(vethd579570@if38),而且master指向docker0
# docker run -d -P --net=bridge nginx:1.9.1
59abbf7dbeedf974349fd971970300e311d4ff56aef7e17f8071ec84e8b8e795
# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 52:54:00:69:06:60 brd ff:ff:ff:ff:ff:ff
inet 172.16.0.6/20 brd 172.16.15.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe69:660/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:74:13:f5:ff brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:74ff:fe13:f5ff/64 scope link
valid_lft forever preferred_lft forever
39: vethd579570@if38: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 7e:79:90:55:97:1d brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::7c79:90ff:fe55:971d/64 scope link
valid_lft forever preferred_lft forever
因为bridge模式是Docker的默认设置,所以你也可以使用docker run -d -P nginx:1.9.1。如果你没有使用-P(发布该容器暴露的所有端口)或者-p
host_port:container_port(发布某个特定端口),IP数据包就不能从宿主机之外路由到容器中。
这时候我们在查看该容器的网络信息(ip地址和网关)。发现它的ip地址和docker0一个网段,网关则是docker0的地址
[root@VM_0_6_centos ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
59abbf7dbeed nginx:1.9.1 "nginx -g 'daemon of…" About a minute ago Up About a minute 0.0.0.0:32771->80/tcp, 0.0.0.0:32770->443/tcp competent_cori
[root@VM_0_6_centos ~]# docker inspect -f {{".NetworkSettings.Networks.bridge.IPAddress"}} 59abbf7dbeed
172.17.0.2
[root@VM_0_6_centos ~]# docker inspect -f {{".NetworkSettings.Networks.bridge.Gateway"}} 59abbf7dbeed
172.17.0.1
我们也可以使用自定义桥接网络,创建
$ docker network create my-net
可以指定子网,IP地址范围,网关和其他选项。然后我们就可以将容器连接到这个网桥上
//未启动
# docker create --name my-nginx \
> --network my-net \
> --publish 8080:80 \
> nginx:latest
//已启动
# docker network connect my-net my-nginx
删除
$ docker network disconnect my-net my-nginx
$ docker network rm my-net
桥接网络适用于在同一个 Docker 守护程序的主机容器进行通信,对于跨机器或者集群通信需要使用其他网络。
host模式
使用–net=host指定,那么这个容器将不会获得一个独立的Network Namespace,Docker使用的网络和宿主机的一样的Network Namespace,该方式创建出来的容器,可以看到主机上所有的网络设备,容器中对这些设备有全部的访问权限。
因此,使用这个选项的时候要非常小心,在非隔离的环境中使用host模式是不安全的,如果进一步的使用–privileged=true,容器可以直接配置主机的网络堆栈。
结构图

实例
# docker run --name b2 -it --network host --rm busybox:latest
/ # ifconfig -a 和宿主机一样
docker0 Link encap:Ethernet HWaddr 02:42:41:C4:5D:6E
inet addr:172.17.0.1 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:41ff:fec4:5d6e/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:90 errors:0 dropped:0 overruns:0 frame:0
TX packets:26 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:5903 (5.7 KiB) TX bytes:2381 (2.3 KiB)
eth0 Link encap:Ethernet HWaddr 00:0C:29:AB:D2:DA
inet addr:10.11.55.5 Bcast:10.11.55.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:feab:d2da/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:3913 errors:0 dropped:0 overruns:0 frame:0
TX packets:3327 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:354314 (346.0 KiB) TX bytes:919096 (897.5 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
可以看出来和主机一摸一样。
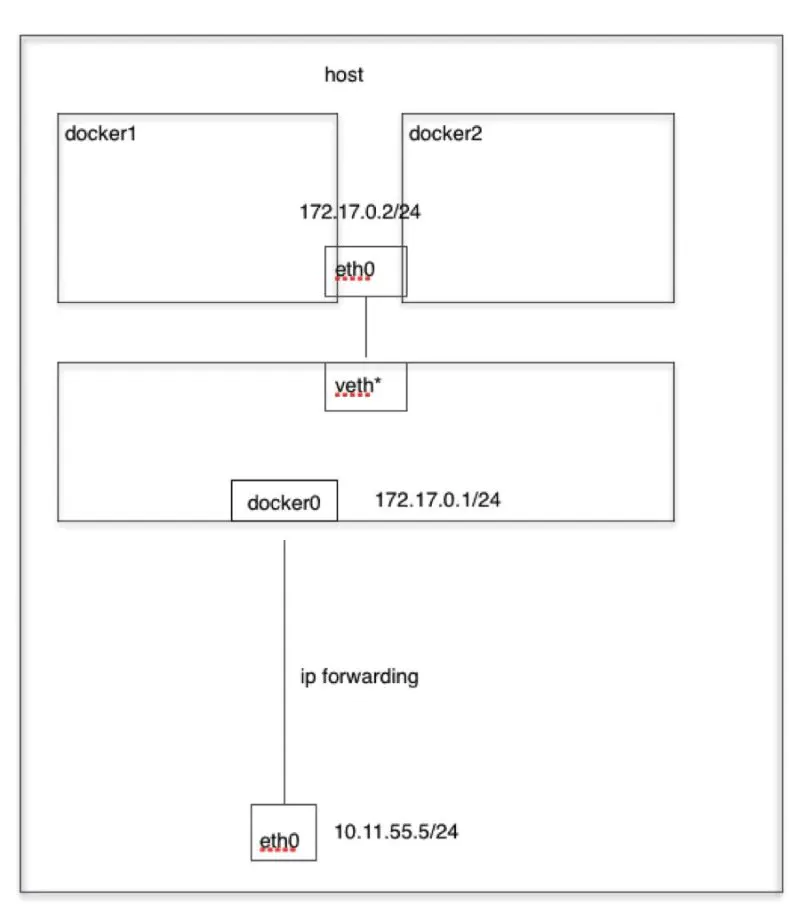
container模式
使用–net=container:CONTAINER_ID/CONTAINER_NAME指定,多个容器使用共同的网络,即两者的网络完全相同,将新建容器的进程放到一个已存在容器的网络栈中,新容器进程有自己的文件系统、进程列表和资源限制,但会和已存在的容器共享IP地址和端口等网络资源,两者进程可以直接通过 环回接口 通信。
结构图
实例
在一个终端,使用bridge网络模式启动容器b1
[root@along ~]# docker run --name b1 -it --rm busybox:latest
/ # ifconfig b1的ip为172.17.0.2
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:02
inet addr:172.17.0.2 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:acff:fe11:2/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:6 errors:0 dropped:0 overruns:0 frame:0
TX packets:6 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:508 (508.0 B) TX bytes:508 (508.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # echo "hello world b1" > /tmp/index.html
/ # httpd -h /tmp/ 在b1上启动httpd服务
/ # netstat -nutl
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 :::80 :::* LISTEN
在另一个终端使用Container 网络模式创建容器b2
# docker run --name b2 -it --network container:b1 --rm busybox:latest
/ # ifconfig -a b2的ip和b1一样
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:02
inet addr:172.17.0.2 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:acff:fe11:2/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8 errors:0 dropped:0 overruns:0 frame:0
TX packets:8 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:648 (648.0 B) TX bytes:648 (648.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # wget -O - -q 127.0.0.1 b1启动的httpd服务,在b2上直接访问
hello world b1
/ # ls /tmp/ 但是文件系统并不共享,只共享网络
none模式
使用–net=none指定,使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个Docker容器没有网卡、IP、路由等信息,只有lo 网络接口。需要我们自己为Docker容器添加网卡、配置IP等。
不参与网络通信,运行于此类容器中的进程仅能访问本地回环接口;仅适用于进程无须网络通信的场景中,例如:备份、进程诊断及各种离线任务等。
结构图

实例
# docker run --name b1 -it --network none --rm busybox:latest
/ # ifconfig
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
/ # exit
overlay
用户自定义模式主要可选的有三种网络驱动:bridge、overlay、macvlan。bridge驱动用于创建类似于前面提到的bridge网络;overlay和macvlan驱动用于创建跨主机的网络。
overlay网络就是在上面基本概念解说过的覆盖网络,就是在已有网络基础之上应用之下构建的一层单独通信的网络,使得容器能够点对点通信,至于真正的通过是通过三次网络进行的,我们不必关心。
我们先举个例子来加深理解
首先在在 Swarm 模式下有两个节点如下
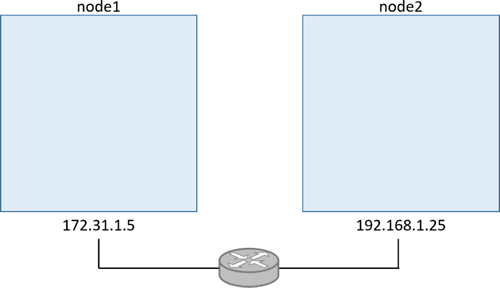
node1 节点上运行 docker swarm init 命令使其成为管理节点,然后在 node2 节点上运行 docker swarm join 命令来使其成为工作节点。
现在创建一个名为 uber-net 的覆盖网络。
$ docker network create -d overlay uber-net
c740ydi1lm89khn5kd52skrd9
刚刚创建了一个崭新的覆盖网络,能连接 Swarm 集群内的所有主机,在node1上使用docker network ls可以看到刚刚创建的overlay网络,如果在 node2 节点上运行 docker network ls 命令,就会发现无法看到 uber-net 网络。这是因为只有当运行中的容器连接到覆盖网络的时候,该网络才变为可用状态。这种延迟生效策略通过减少网络梳理,提升了网络的扩展性。
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
ddac4ff813b7 bridge bridge local
389a7e7e8607 docker_gwbridge bridge local
a09f7e6b2ac6 host host local
ehw16ycy980s ingress overlay swarm
2b26c11d3469 none null local
c740ydi1lm89 uber-net overlay swarm
只要将服务连接到覆盖网络就好,我们新建一个Docker 服务会包含两个副本(容器),一个运行 node1 节点上,一个运行在 node2 节点上。这样会自动将 node2 节点接入 uber-net 网络。
$ docker service create --name test \
--network uber-net \
--replicas 2 \
现在使用 ping 命令来测试覆盖网络。如下图所示,在两个独立的网络中分别有一台 Docker 主机,并且两者都接入了同一个覆盖网络。目前在每个节点上都有一个容器接入了覆盖网络。测试一下两个容器之间是否可以 ping 通。
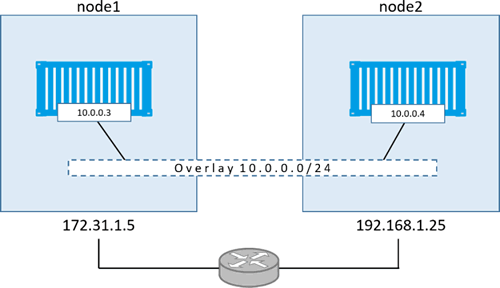
由图可知,一个二层覆盖网络横跨两台主机,并且每个容器在覆盖网络中都有自己的 IP 地址。这意味着 node1 节点上的容器可以通过 node2 节点上容器的 IP 地址 10.0.0.4 来 ping 通,该 IP 地址属于覆盖网络。尽管两个节点分属于不同的二层网络,还是可以直接 ping 通。
根据实例我们来看看overlay的原理,Docker 使用 VXLAN 隧道技术创建了虚拟二层覆盖网络。所以,在详解之前,先快速了解一下 VXLAN。
在 VXLAN 的设计中,允许用户基于已经存在的三层网络结构创建虚拟的二层网络。
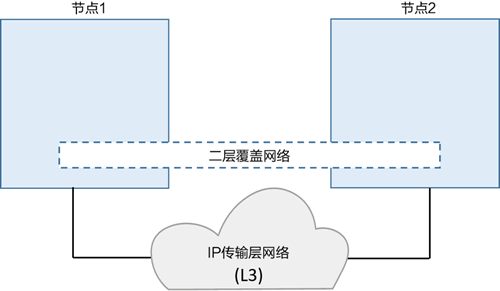
VXLAN 的美妙之处在于它是一种封装技术,能使现存的路由器和网络架构看起来就像普通的 IP/UDP 包一样,并且处理起来毫无问题。
为了创建二层覆盖网络,VXLAN 基于现有的三层 IP 网络创建了隧道。小伙伴可能听过基础网络(Underlay Network)这个术语,它用于指代三层之下的基础部分。
VXLAN 隧道两端都是 VXLAN 隧道终端(VXLAN Tunnel Endpoint, VTEP)。VTEP 完成了封装和解压的步骤,以及一些功能实现所必需的操作,如下图所示。
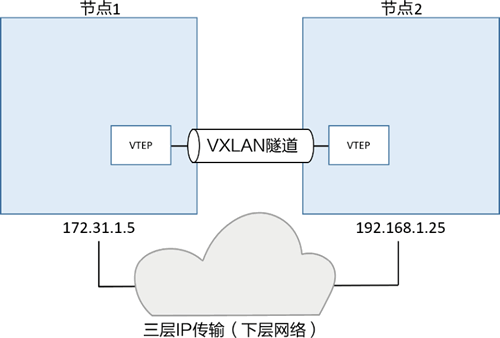
在前面的示例中,读者通过 IP 网络将两台主机连接起来。每个主机运行了一个容器,之后又为容器连接创建了一个 VXLAN 覆盖网络。
为了实现上述场景,在每台主机上都新建了一个 Sandbox(网络命名空间)。正如前文所讲,Sandbox 就像一个容器,但其中运行的不是应用,而是当前主机上独立的网络栈。
在 Sandbox 内部创建了一个名为 Br0 的虚拟交换机(又称做虚拟网桥)。同时 Sandbox 内部还创建了一个 VTEP,其中一端接入到名为 Br0 的虚拟交换机当中,另一端接入主机网络栈(VTEP)。
在主机网络栈中的终端从主机所连接的基础网络中获取到 IP 地址,并以 UDP Socket 的方式绑定到 4789 端口。不同主机上的两个 VTEP 通过 VXLAN 隧道创建了一个覆盖网络,如下图所示。
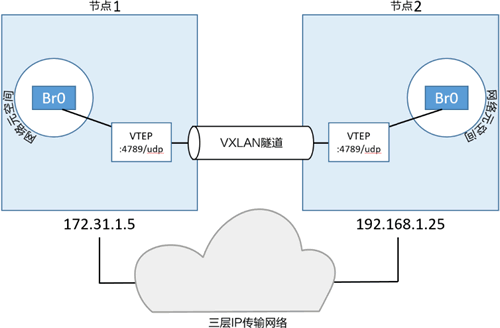
这是 VXLAN 上层网络创建和使用所必需的。
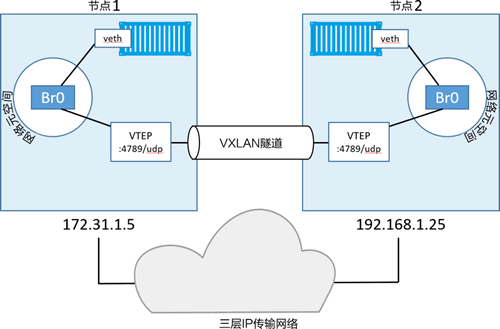
接下来每个容器都会有自己的虚拟以太网(veth)适配器,并接入本地 Br0 虚拟交换机。目前拓扑结构如下图所示,虽然是在主机所属网络互相独立的情况下,但这样能更容易看出两个分别位于不同主机上的容器之间是如何通过 VXLAN 上层网络进行通信的。
我们再来看一下上面ping通的过程
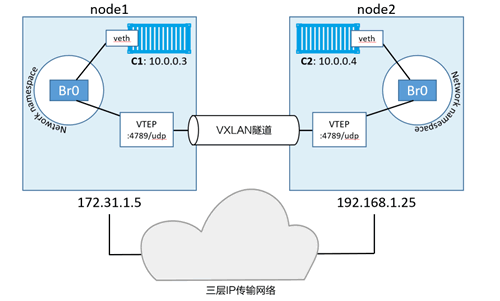
C1 发起 ping 请求,目标 IP 为 C2 的地址 10.0.0.4。该请求的流量通过连接到 Br0 虚拟交换机 veth 接口发出。虚拟交换机并不知道将包发送到哪里,因为在虚拟交换机的 MAC 地址映射表(ARP 映射表)中并没有与当前目的 IP 对应的 MAC 地址。
所以虚拟交换机会将该包发送到其上的全部端口。连接到 Br0 的 VTEP 接口知道如何转发这个数据帧,所以会将自己的 MAC 地址返回。这就是一个代理 ARP 响应,并且虚拟交换机 Br0 根据返回结果学会了如何转发该包。接下来虚拟交换机会更新自己的 ARP 映射表,将 10.0.0.4 映射到本地 VTEP 的 MAC 地址上。
现在 Br0 交换机已经学会如何转发目标为 C2 的流量,接下来所有发送到 C2 的包都会被直接转发到 VTEP 接口。VTEP 接口知道 C2,是因为所有新启动的容器都会将自己的网络详情采用网络内置 Gossip 协议发送给相同 Swarm 集群内的其他节点。
交换机会将包转发到 VTEP 接口,VTEP 完成数据帧的封装,这样就能在底层网络传输。具体来说,封装操作就是把 VXLAN Header 信息添加以太帧当中。
VXLAN Header 信息包含了 VXLAN 网络 ID(VNID),其作用是记录 VLAN 到 VXLAN 的映射关系。每个 VLAN 都对应一个 VNID,以便包可以在解析后被转发到正确的 VLAN。
封装的时候会将数据帧放到 UDP 包中,并设置 UDP 的目的 IP 字段为 node2 节点的 VTEP 的 IP 地址,同时设置 UDP Socket 端口为 4789。这种封装方式保证了底层网络即使不知道任何关于 VXLAN 的信息,也可以完成数据传输。
当包到达 node2 之后,内核发现目的端口为 UDP 端口 4789,同时还知道存在 VTEP 接口绑定到该 Socket。所以内核将包发给 VTEP,由 VTEP 读取 VNID,解压包信息,并根据 VNID 发送到本地名为 Br0 的连接到 VLAN 的交换机。在该交换机上,包被发送给容器 C2。
Macvlan
Macvlan通过为容器提供 MAC 和 IP 地址,让容器在物理网络上成为“一等公民”,无须端口映射或者额外桥接,可以直接通过主机接口(或者子接口)访问容器接口。
Macvlan 的缺点是需要将主机网卡(NIC)设置为混杂模式(Promiscuous Mode),这在大部分公有云平台上是不允许的。
实例
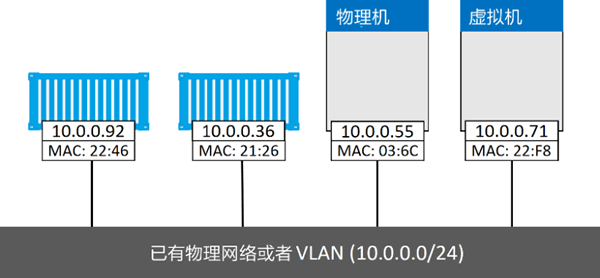
假设有一个物理网络,其上配置了两个 VLAN——VLAN 100:10.0.0.0/24 和 VLAN 200:192.168.3.0/24,如下图所示。

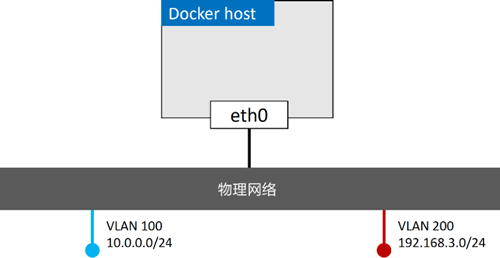
接下来,添加一个 Docker 主机并连接到该网络,如下图所示。
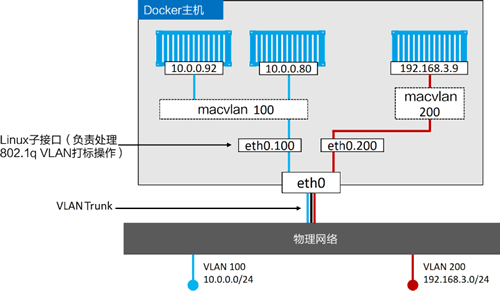
下面的命令会创建一个名为 macvlan100 的 Macvlan 网络,该网络会连接到 VLAN 100。
$ docker network create -d macvlan \
--subnet=10.0.0.0/24 \
--ip-range=10.0.00/25 \
--gateway=10.0.0.1 \
-o parent=eth0.100 \
macvlan100
该命令会创建 macvlan100 网络以及 eth0.100 子接口。macvlan100 网络已为容器准备就绪,执行以下命令将容器部署到该网络中。
$ docker container run -d --name mactainer1 \
--network macvlan100 \
alpine sleep 1d
当前配置如下图所示。但是切记,下层网络(VLAN 100)对 Macvlan 的魔法毫不知情,只能看到容器的 MAC 和 IP 地址。在该基础之上,mactainer1 容器可以 ping 通任何加入 VLAN 100 的系统,并进行通信。
网络插件
网络插件主要是解决的跨主机的通信,就像overlay和macvlan解决的问题一样,基本也适用于k8s的网络实现,网络插件基本都是支持k8s网络实现,可以查看k8s网络实现。
总结
- 当需要在同一个 Docker 主机上多个容器通信时,使用用户定义的 bridge网络 。
- 当网络堆栈不应与 Docker 主机隔离时(但是你希望隔离容器的其他方面),使用 host 网络 。
- 当需要在不同的 Docker 主机上多个容器互通时,*使用 Overlay 网络*,或者使用 swarm 服务多个应用一起工作时。
- 当你从 VM 迁移业务时,需要容器看起来像网络上的物理主机时,每个都有唯一的 MAC 地址,*使用 Macvlan 网络*。
- 第三方的网络插件 允许将 Docker 与专用网络堆栈集成。
其实这些方式都是早期在使用docker时候的网络设置,后来都使用了编排工具,比如k8s,都有相应的解决方案。