几乎所有的系统(我们通常都是APM:应用系统监控)都可以通过是三个方面来构建三维一体立体化监控体系。
总体架构
立体化监控分三个维度,三种相互辅助的完整监控体系。
- Metrics: 可以用于服务告警
- Logging: 用于调试发现问题
- Tracing: 用于调试发现问题
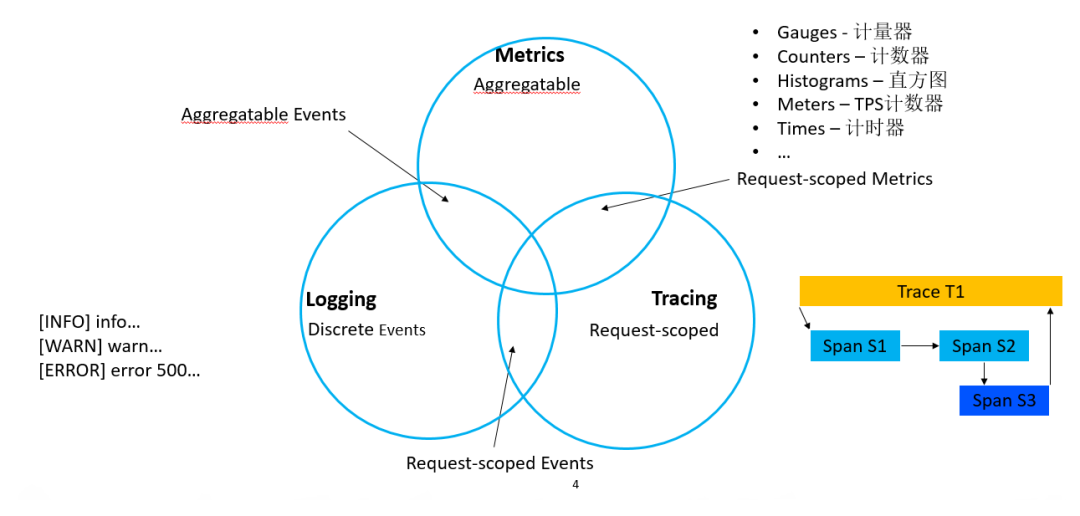
不同的指标表示不同维度的监控,构成一个完成的监控体系。
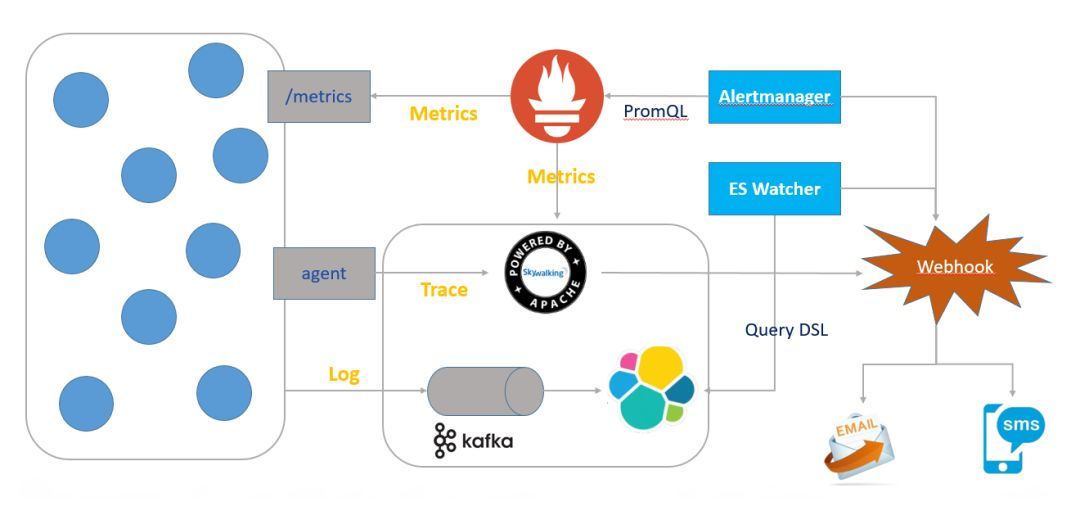
监控分类
Metrics
metrics就是指标监控,通过定义的指标来表示资源的使用情况或者状态等。针对这一类监控,我们通常使用时序数据库来做图表面展示,我们常用的监控系统有prometheus生态,zabbix等,目前来说时序更加符合监控的需求,无论重数据的存储到数据的使用上都是时序数据库有优势。
Logging
log就是日志监控,采集日志,进行处理,存储,展示,重日志中获取到运行的信息,我们通常用的日志系统有EFK生态。
Tracing
trace就是调用链监控,即一次完整的事务调用请求。比方说一个用户的下单请求,经过层层服务预处理,到支付服务成功,数据落库,成功返回,这就是一条完整的 Trace 。Trace 最大的特点就是它含有上下文环境,通常来说会由一个唯一的 ID 来进行标识。一个 Trace 内可能有多个不同的事务 (Transaction) 以及标志事件 (Event) 组成。我们通常使用的是[Skywalking](),CNCF推荐的是[jaeger]()。
对比结合
三种对比
- metrics监控前期的搭建难度适中,后期维护比较简单,在出现问题的时候,灵敏度比较高,比较容易发现问题,发出告警,但是在排查问题的只有表面的数据,不能找到具体的根因。
- log监控前期的搭建难度比较低,现在搭建一套ELK已经很成熟了,后期维护比较高,因为日志的数据量都是巨大的,在出现问题的时候,灵敏度比较适中,不是太容易发现问题,发出告警,主要在排查问题的进行查看。
- trace监控前期的搭建难度很高,后期维护也比较适中,在出现问题的时候,灵敏度很低,不容易发现问题,发出告警,但是在排查问题的时候能找到具体的根因,主要是用于排查问题。
结合
一般系统出问题的时候,都是metrics先发现问题,发出告警,然后我们去查看日志查看问题,查看trace来定位到具体的原因。
监控分层
在不同的层面都可以使用上面三种监控类型进行监控,结合起来完成每一层完整的监控体系。
从底到上分为:基础设施监控、系统层监控、应用层监控、业务层监控、端用户体验监控
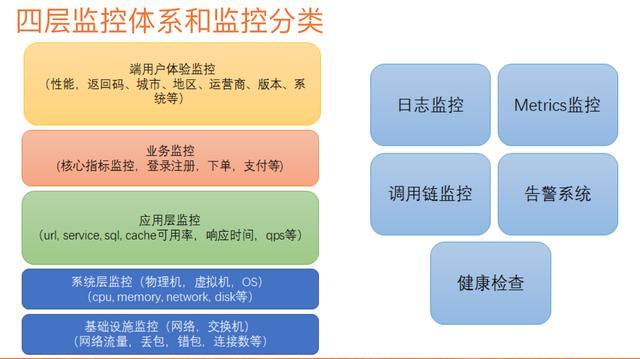
- 端侧监控主要是用调用链监控,来监控一些调用延迟,错误等,比如听云。
- 业务层监控主要是用metrics监控,日志监控,来监控注册登陆转化订单数据,这些业务的错误情况下还需要通过日志来进行排查。
- 应用层其实也就是我们的服务层了,需要通过三位一体化的监控,形成完整的监控体系,来监控一些调用延迟错误。
- 系统层就是底层基础设施的监控,一些系统的指标日志。