map是我们经常使用的一种数据结构,也是很重要的一种数据结构,我们来详细的了解一下map。
map
map就是k/v的映射,map持有对底层数据结构的引用。如果将map传递给函数,其对map的内容做了改变,则这些改变对于调用者是可见的。
map的实现
所有的Map底层一般都是使用数组+链表的hashmap来实现,会借用哈希算法辅助。对于给定的 key,一般先进行 hash 操作,然后相对哈希表的长度取模,将 key 映射到指定的链表中。
Golang的map正常是使用哈希表作为底层实现
- hashtable是一种根据key,key在通过hash函数来对应的数组的数据。
- hashmap是hashtable使用拉链法实现的一种方式,数组+链表的实现方式
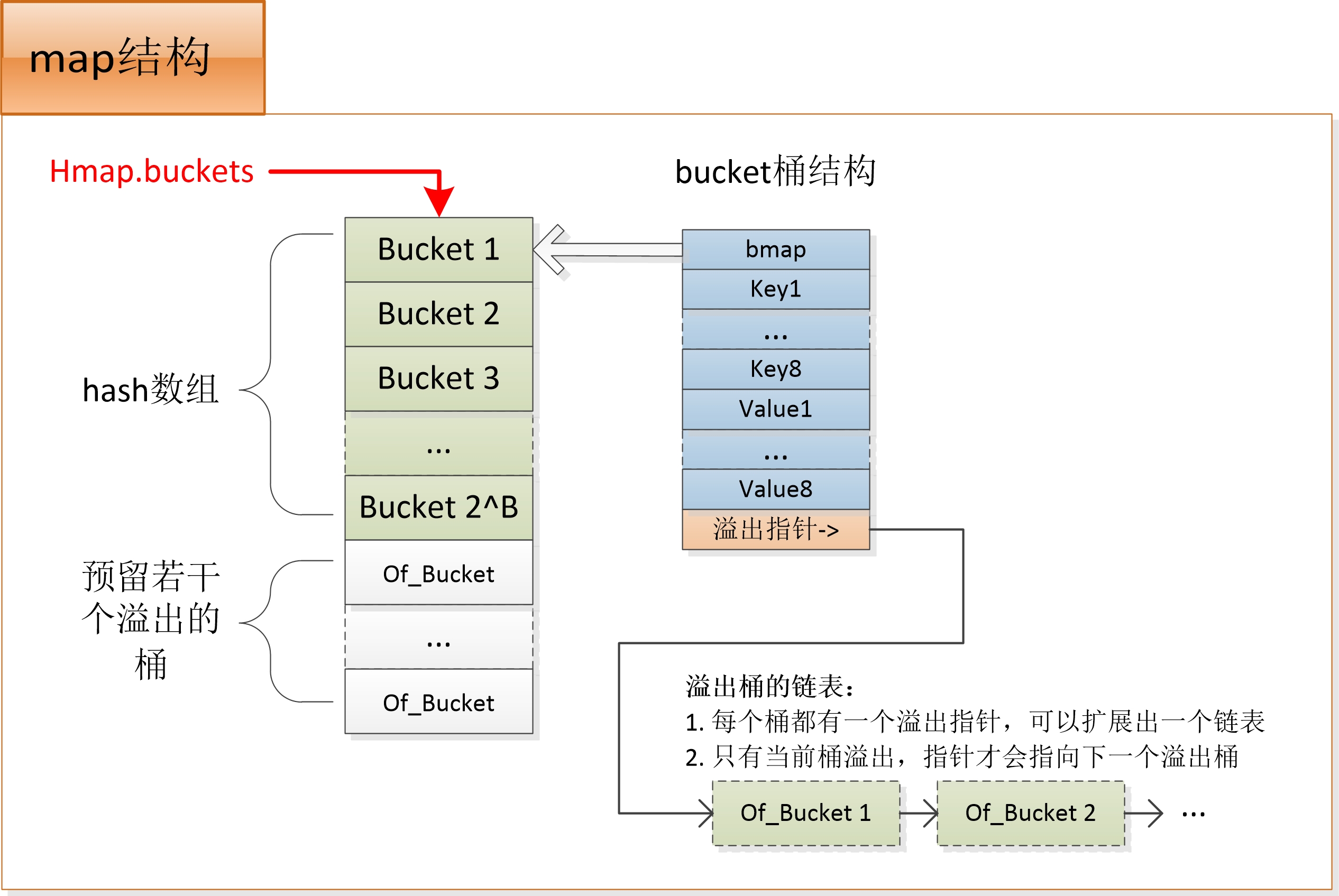
正常情况下,golang使用数组+桶(buckets)来实现,默认每个桶的数量是8个,在超出8个的情况下,新增一个桶,使用链表连接起来,这是时候就变成了hash数组 + 桶 + 溢出的桶链表了。
其实map不是并发安全的,也是因为hashmap不是并发安全的,实现并发安全的几种方式,可以参考并发安全。
数据结构
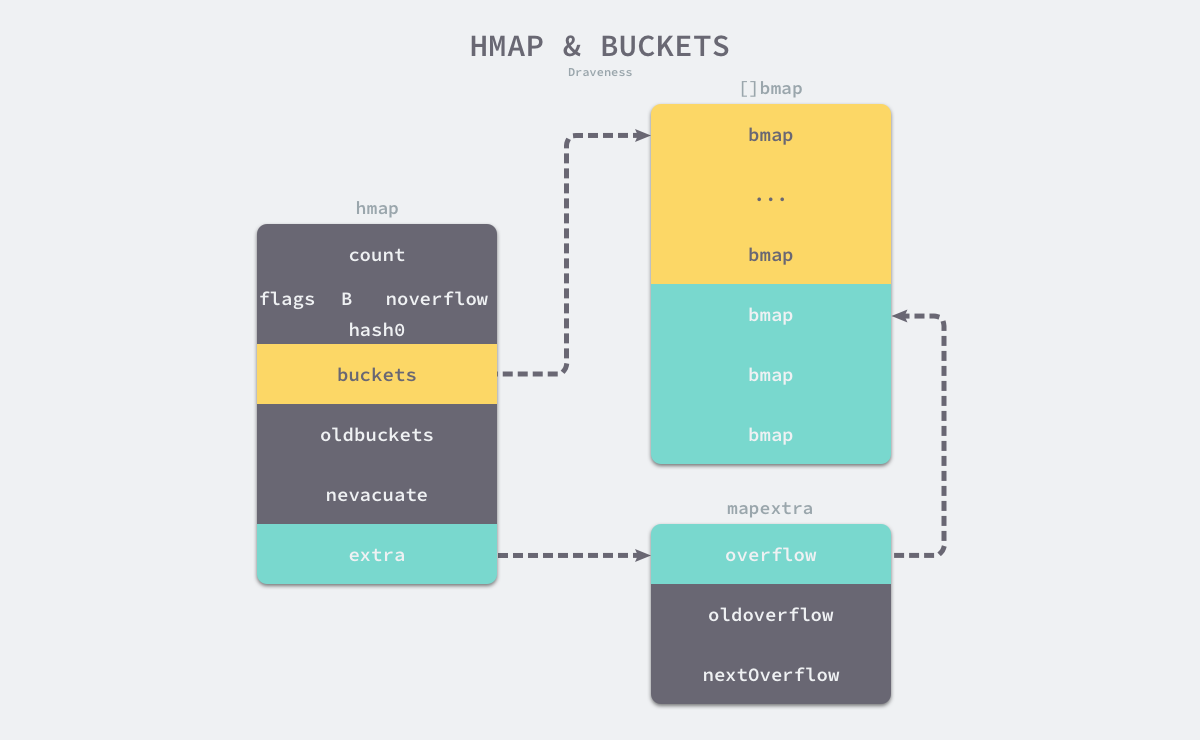
map数据结构由runtime/map.go/hmap定义:
hmap
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
- count 表示当前哈希表中的元素数量;类似于
buckets[count] - B表示当前哈希表持有的buckets数量,但是因为哈希表中桶的数量都2的倍数,所以该字段会存储对数,也就是 len(buckets) == 2^B;类似于
buckets[2^B] - hash0 是哈希的种子,它能为哈希函数的结果引入随机性,这个值在创建哈希表时确定,并在调用哈希函数时作为参数传入;
- oldbuckets 是哈希在扩容时用于保存之前 buckets 的字段,它的大小是当前 buckets 的一半;
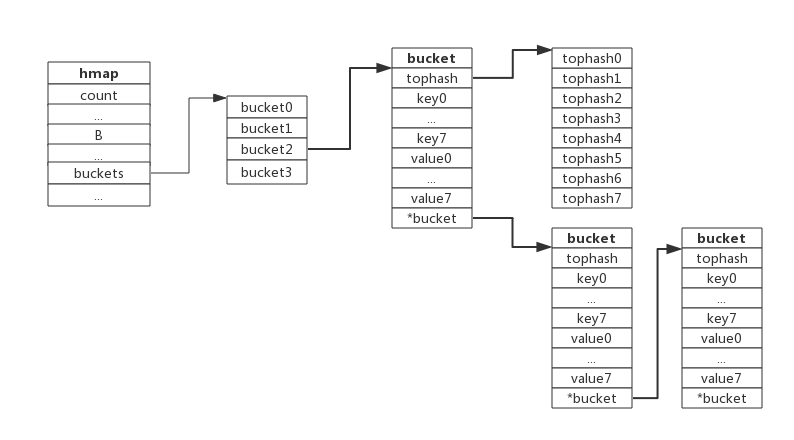
bmap
type bmap struct {
tophash [8]uint8 //存储哈希值的高8位
//data和overflow并不是在结构体中显示定义的,而是直接通过指针运算进行访问的。
data byte[1] //key value数据:key/key/key/.../value/value/value...
overflow *bmap //溢出bucket的地址
}
- tophash是个长度为8的数组,哈希值相同的键(准确的说是哈希值低位相同的键)存入当前bucket时会将哈希值的高位存储在该数组中,以方便后续匹配。
- data区存放的是key-value数据,存放顺序是key/key/key/…value/value/value,如此存放是为了节省字节对齐带来的空间浪费。
- overflow 指针指向的是下一个bucket,据此将所有冲突的键连接起来。
我们能根据编译期间的 cmd/compile/internal/gc.bmap 函数对它的结构重建:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
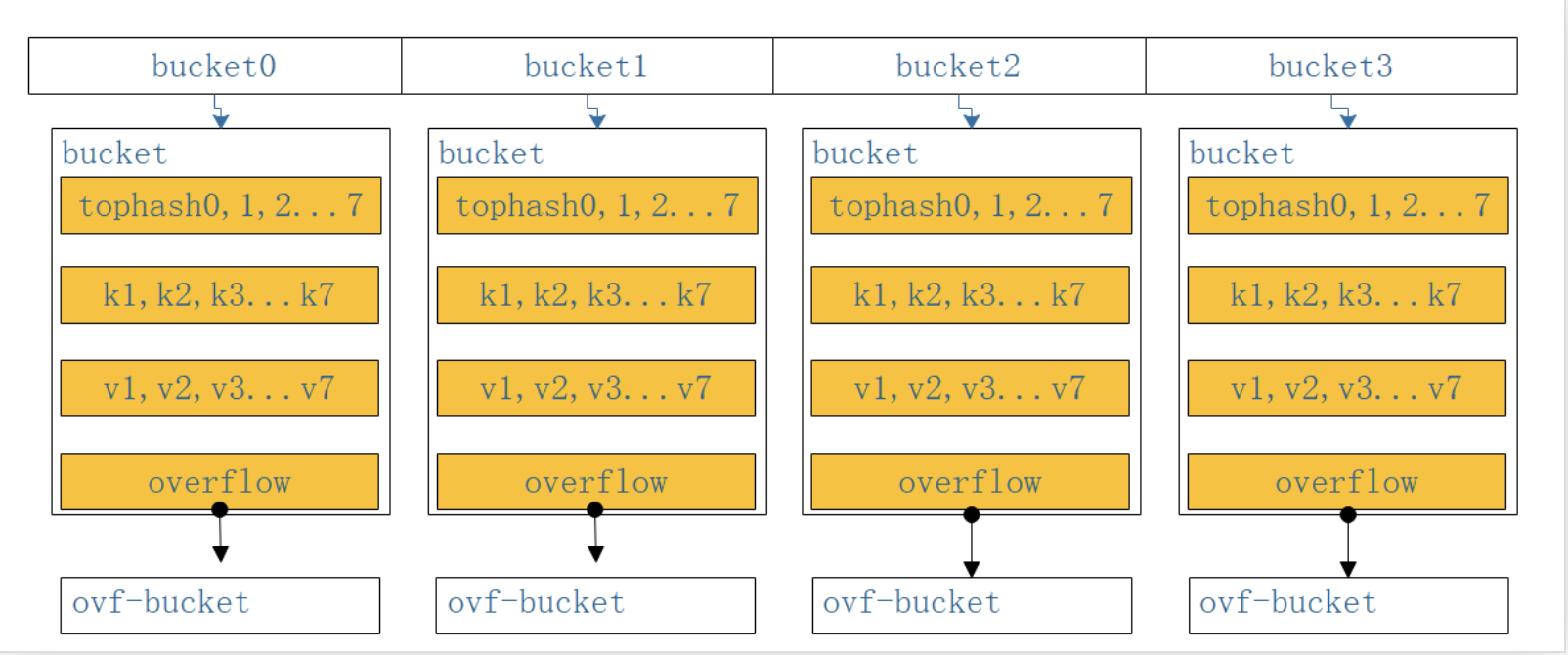
如下图:
基本机制
负载因子和rehash
负载因子用于衡量一个哈希表冲突情况,公式为:
负载因子 = 键数量/bucket数量
例如,对于一个bucket数量为4,包含4个键值对的哈希表来说,这个哈希表的负载因子为1.
哈希表需要将负载因子控制在合适的大小,超过其阀值需要进行rehash,也即键值对重新组织:
- 哈希因子过小,说明空间利用率低
- 哈希因子过大,说明冲突严重,存取效率低
每个哈希表的实现对负载因子容忍程度不同,比如Redis实现中负载因子大于1时就会触发rehash,而Go则在在负载因子达到6.5时才会触发rehash,因为Redis的每个bucket只能存1个键值对,而Go的bucket可能存8个键值对,所以Go可以容忍更高的负载因子。
map的删除机制
采用的是惰性删除的策略,打上一个empty的标记,实际上并没有删除,也不会释放内存,还可以在后面进行复用,这样做主要为了解决遍历过程的溢出问题,因为是用数组实现的。实现迭代安全
map的扩容机制
- 增量扩容
当负载因子大于6.5也即平均每个bucket存储的键值对达到6.5个,就新建一个bucket,新的bucket长度是原来的2倍,然后旧bucket数据搬迁到新的bucket。
考虑到如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,Go采用逐步搬迁策略,即每次访问map时都会触发一次搬迁,每次搬迁2个键值对。
扩容流程
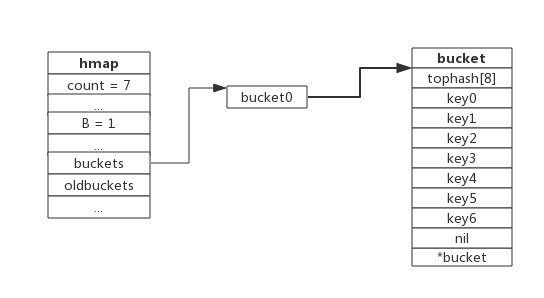
当前map存储了7个键值对,只有1个bucket。此地负载因子为7。再次插入数据时将会触发扩容操作,扩容之后再将新插入键写入新的bucket。
当第8个键值对插入时,将会触发扩容,扩容后示意图如下:
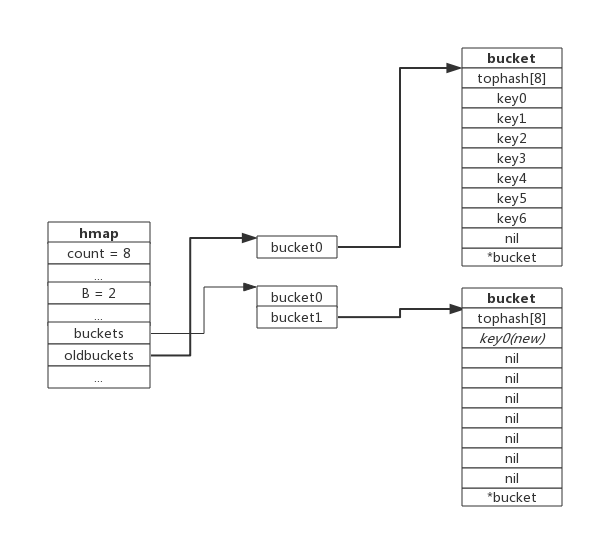
hmap数据结构中oldbuckets成员指身原bucket,而buckets指向了新申请的bucket。新的键值对被插入新的bucket中。 后续对map的访问操作会触发迁移,将oldbuckets中的键值对逐步的搬迁过来。当oldbuckets中的键值对全部搬迁完毕后,删除oldbuckets。
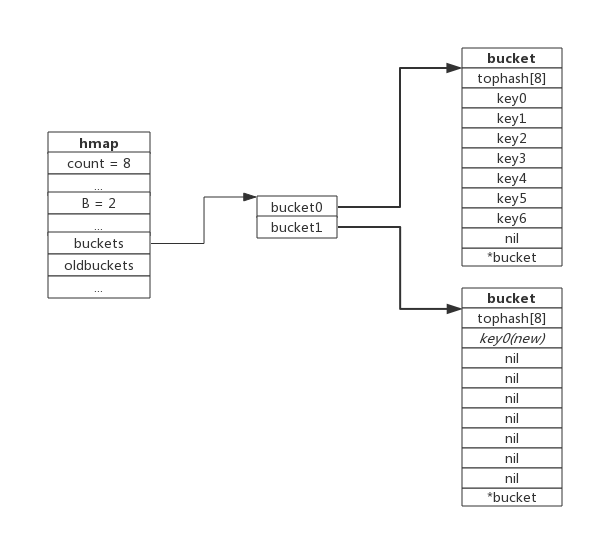
- 等量扩容
实际上并不是扩大容量,buckets数量不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。
map的缩容机制
溢出的桶数量noverflow>=32768(1<<15)或者>=hash数组大小。
但是缩容并不会释放已经占用的空间,真的要释放空间,就新建一个map进行迁移
什么时候转化为红黑树
在golang中没有转化为红黑树,就是正常的扩容使用数组,在java中超过8个桶,就会转化为红黑树,和查询次数也即是时间复杂度有关,因为Map中桶的元素初始化是数组保存的,其查找性能是O(n),而树结构能将查找性能提升到O(log(n))。当数组长度很小的时候,即使遍历,速度也非常快,但是当链表长度不断变长,肯定会对查询性能有一定的影响,所以才需要转成树。有利于减少查询的次数
8个桶这个其实是概率统计出来的,8最合适。golang中的桶有8个kv应该是也是这个道理。
map并发安全
Go 原生的 map 数据类型是非并发安全的,在go1.9开始发布了sync.map是线程安全的。
我们先看看基于原生map的基础上加mutex实现并发安全。
map+mutex
在golang1.9以前,我们都是使用读写锁(sync.RWMutex)来实现并发安全,比如
package beego
import (
"sync"
)
type BeeMap struct {
lock *sync.RWMutex
bm map[interface{}]interface{}
}
func NewBeeMap() *BeeMap {
return &BeeMap{
lock: new(sync.RWMutex),
bm: make(map[interface{}]interface{}),
}
}
//Get from maps return the k's value
func (m *BeeMap) Get(k interface{}) interface{} {
m.lock.RLock()
defer m.lock.RUnlock()
if val, ok := m.bm[k]; ok {
return val
}
return nil
}
// Maps the given key and value. Returns false
// if the key is already in the map and changes nothing.
func (m *BeeMap) Set(k interface{}, v interface{}) bool {
m.lock.Lock()
defer m.lock.Unlock()
if val, ok := m.bm[k]; !ok {
m.bm[k] = v
} else if val != v {
m.bm[k] = v
} else {
return false
}
return true
}
// Returns true if k is exist in the map.
func (m *BeeMap) Check(k interface{}) bool {
m.lock.RLock()
defer m.lock.RUnlock()
if _, ok := m.bm[k]; !ok {
return false
}
return true
}
func (m *BeeMap) Delete(k interface{}) {
m.lock.Lock()
defer m.lock.Unlock()
delete(m.bm, k)
}
我们在项目中经常使用的方式:通过数组、map、sync.RWMutex来实现原生map的并发读写(采用map数组,把key hash到相应的map,每个map单独加锁以降低锁的粒度)
sync.map
那么golang sync.map是如何实现并发安全的呢?
简单总结就是使用了用空间换时间(多存储一份map作为缓存,减少锁的使用)的思想来实现来一个高效的并发安全。主要下面的函数接口实现
- Load:读取指定 key 返回 value
- Store: 存储(增或改)key-value
- Delete: 删除指定 key
4种操作:读key、增加key、更新key、删除key的基本流程,其实在代码中只有上面三个函数实现
- 读key:先到read中读取,如果有则直接返回结果,如果没有就加锁,再次检查read是否存在,因为刚刚是无锁读,如果没有,则到dirty加锁中读取,如果有返回结果并更新miss数(用于数据迁移),这边在read这边设置了一个amended,如果为true则表明当前read只读map的数据不完整,dirty map中包含部分数据,这边决定了刚刚上一步是否执行到dirty中查找
- 更新key(增加key):其实更新和增加使用的是同一个函数store,首先查找read中是否存在,如果存在直接更新,如果没有就加锁,再次检查read是否存在,因为刚刚是无锁读,如果不存在,同样有上面的判断是否是全量数据,不是就继续到dirty中查找,找到了就更新,找不到就新建一个存储,就是新增key
- 删除key:先到read中看看有没有,如果有p标记为nil,如果没有则到dirty中直接删除(同样有数据全不全的判断)
源码详解解读
数据结构分析
Map
type Map struct { mu Mutex // read是一个readOnly的指针,里面包含了一个map结构,就是我们说的只读map对该map的元素的访问 // 不需要加锁,只需要通过atomic加载最新的指针即可 read atomic.Value // readOnly // dirty包含部分map的键值对,如果要访问需要进行mutex获取 // 最终dirty中的元素会被全部提升到read里面的map中 dirty map[interface{}]*entry // misses是一个计数器用于记录从read中没有加载到数据 // 尝试从dirty中进行获取的次数,从而决定将数据从dirty迁移到read的时机 misses int }readOnly
只读map,对该map元素的访问不需要加锁,但是该map也不会进行元素的增加,元素会被先添加到dirty中然后后续再转移到read只读map中,通过atomic原子操作不需要进行锁操作
type readOnly struct { // m包含所有只读数据,不会进行任何的数据增加和删除操作 // 但是可以修改entry的指针因为这个不会导致map的元素移动 m map[interface{}]*entry // 标志位,如果为true则表明当前read只读map的数据不完整,dirty map中包含部分数据 amended bool }entry
entry是sync.Map中值得指针,如果当p指针指向expunged这个指针的时候,则表明该元素被删除,但不会立即从map中删除,如果在未删除之前又重新赋值则会重用该元素
type entry struct { // 指向元素实际值得指针 p unsafe.Pointer // *interface{} }p 有三种状态:
- p == nil: 键值已经被删除,且 m.dirty == nil
- p == expunged: 键值已经被删除,但 m.dirty!=nil 且 m.dirty 不存在该键值(expunged 实际是空接口指针)
- 键值对存在,存在于 m.read.m 中,如果 m.dirty!=nil 则也存在于 m.dirty
数据存储
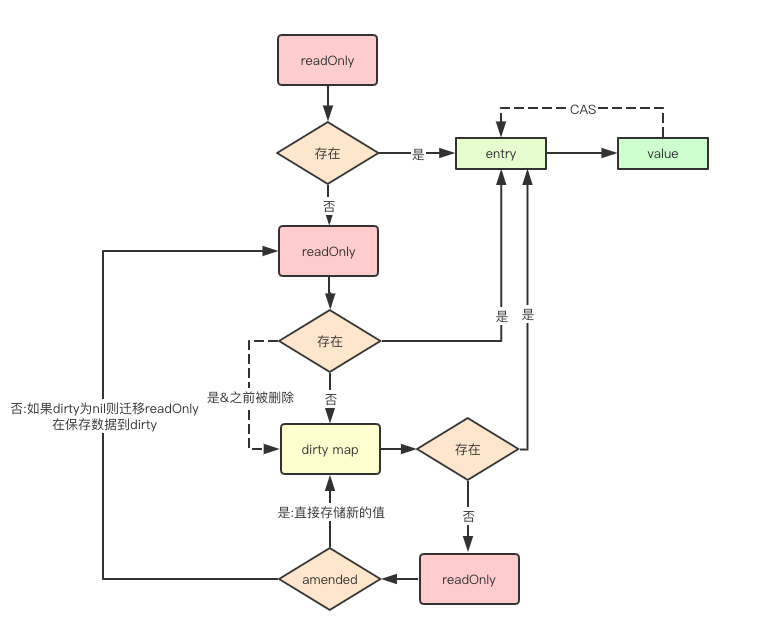
元素存在read
元素如果存储在只读map中,则只需要获取entry元素,然后修改其p的指针指向新的元素就可以了。
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
这边其实有两点需要特别说明的
- map不是并发安全的,这边为什么可以直接修改呢,因为这边使用atomic中的CAS的乐观思想来实现乐观锁,实现并发安全。
- cas就是实现了对比并交互,这个操作是用来实现乐观锁这种思路的,乐观锁并不是真正的锁,它用版本好来标记数据是否被修改,如果被修改则重试。
- 怎么同步到dirty中去,entry是一个指向实际值的地址,所以read和dirty是共享地址的。所以就一起改了
元素存在dirty中
如果元素存在dirty中其实同read map逻辑一样,只需要修改对应元素的指针即可
} else if e, ok := m.dirty[key]; ok {
// 如果已经在dirty中就会直接存储
e.storeLocked(&value)
}
这边有两点需要说明
- read中是有一个标识amended来判断,如果为true则表明当前read只读map的数据不完整,dirty map中包含部分数据,才会进来查询。
- 在加锁之后,还是需要重read中查询一次的,查到就直接修改,因为是一开始的查询是无锁读,存在并发安全问题,可能在这段未加锁的时间内数据发生了改变。
元素不存在
如果元素之前不存在当前Map中则需要先将其存储在dirty map中,同时将amended标识为true,即当前read中的数据不全,有一部分数据存储在dirty中
// 如果当前不是在修正状态
if !read.amended {
// 新加入的key会先被添加到dirty map中, 并进行read标记为不完整
// 如果dirty为空则将read中的所有没有被删除的数据都迁移到dirty中
m.dirtyLocked()
m.read.Store(readOnly{m: read.m, amended: true})
}
m.dirty[key] = newEntry(value)
源码
func (m *Map) Store(key, value interface{}) {
read, _ := m.read.Load().(readOnly)
// 如果 read 里存在,则尝试存到 entry 里
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
// 如果上一步没执行成功,则要分情况处理
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
// 和 Load 一样,重新从 read 获取一次
if e, ok := read.m[key]; ok {
// 情况 1:read 里存在
if e.unexpungeLocked() {
// 如果 p == expunged,则需要先将 entry 赋值给 dirty(因为 expunged 数据不会留在 dirty)
m.dirty[key] = e
}
// 用值更新 entry
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok {
// 情况 2:read 里不存在,但 dirty 里存在,则用值更新 entry
e.storeLocked(&value)
} else {
// 情况 3:read 和 dirty 里都不存在
if !read.amended {
// 如果 amended == false,则调用 dirtyLocked 将 read 拷贝到 dirty(除了被标记删除的数据)
m.dirtyLocked()
// 然后将 amended 改为 true
m.read.Store(readOnly{m: read.m, amended: true})
}
// 将新的键值存入 dirty
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}
func (e *entry) tryStore(i *interface{}) bool {
for {
p := atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
//原子操作cas
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
return true
}
}
}
func (e *entry) unexpungeLocked() (wasExpunged bool) {
return atomic.CompareAndSwapPointer(&e.p, expunged, nil)
}
func (e *entry) storeLocked(i *interface{}) {
atomic.StorePointer(&e.p, unsafe.Pointer(i))
}
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
// 判断 entry 是否被删除,否则就存到 dirty 中
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := atomic.LoadPointer(&e.p)
for p == nil {
// 如果有 p == nil(即键值对被 delete),则会在这个时机被置为 expunged
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
return true
}
p = atomic.LoadPointer(&e.p)
}
return p == expunged
}
在数据存储里其实还有数据迁移的逻辑
当read多次都没有命中数据,达到阈值,表示这个cache命中率太低,这时直接将整个read用dirty替换掉,然后dirty又重新置为nil,下一次再添加一个新key的时候,会触发一次read到dirty的复制,这样二者又保持了一致。
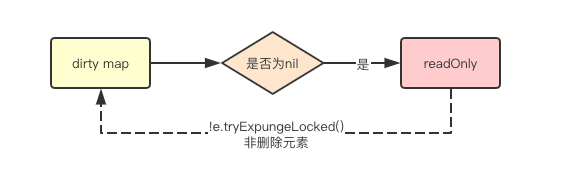
在刚初始化和将所有元素迁移到read中后,dirty默认都是nil元素,而此时如果有新的元素增加,则需要先将read map中的所有未删除数据先迁移到dirty中
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
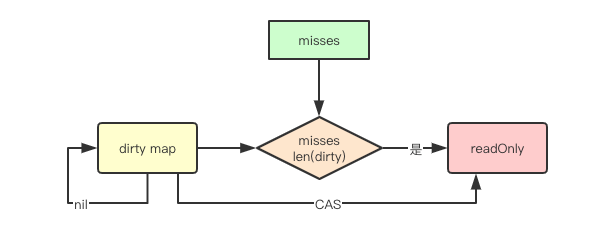
当持续的从read访问穿透到dirty中后,也就是上面的miss值大于dirty存储数据的长度,就会触发一次从dirty到read的迁移,这也意味着如果我们的元素读写比差比较小,其实就会导致频繁的迁移操作,性能其实可能并不如rwmutex等实现
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
数据查询
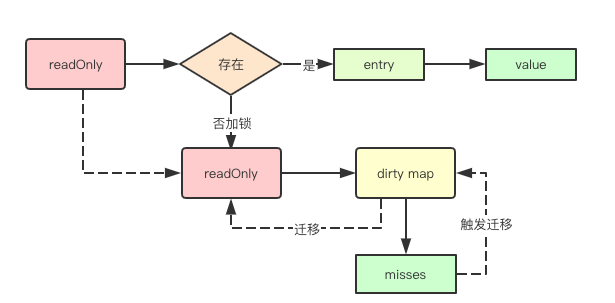
关于amended标识的使用,和存储是一样的
数据在read
Load数据的时候回先从read中获取,如果此时发现元素,则直接返回即可
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
数据在dirty
加锁后会尝试从read和dirty中读取,同时进行misses计数器的递增,如果满足迁移条件则会进行数据迁移
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
// 这里将采取缓慢迁移的策略
// 只有当misses计数==len(m.dirty)的时候,才会将dirty里面的数据全部晋升到read中
m.missLocked()
}
源码
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
// 首先尝试从 read 中读取 readOnly 对象
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 如果不存在则尝试从 dirty 中获取
if !ok && read.amended {
m.mu.Lock()
// 由于上面 read 获取没有加锁,为了安全再检查一次
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// 确实不存在则从 dirty 获取
if !ok && read.amended {
e, ok = m.dirty[key]
// 调用 miss 的逻辑
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
// 从 entry.p 读取值
return e.load()
}
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
// 当 miss 积累过多,会将 dirty 存入 read,然后 将 amended = false,且 m.dirty = nil
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
数据删除
- 如果数据在read中,则就直接修改entry的标志位指向删除的指针即可,如果当前read中数据不全,则需要进行dirty里面的元素删除尝试,
- 如果存在就直接从dirty中删除即可
源码
func (m *Map) Delete(key interface{}) {
m.LoadAndDelete(key)
}
// LoadAndDelete 作用等同于 Delete,并且会返回值与是否存在
func (m *Map) LoadAndDelete(key interface{}) (value interface{}, loaded bool) {
// 获取逻辑和 Load 类似,read 不存在则查询 dirty
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
m.missLocked()
}
m.mu.Unlock()
}
// 查询到 entry 后执行删除
if ok {
// 将 entry.p 标记为 nil,数据并没有实际删除
// 真正删除数据并被被置为 expunged,是在 Store 的 tryExpungeLocked 中
return e.delete()
}
return nil, false
}
设计思想
自动扩缩容
在Mutex和RWMutex实现的并发安全的map中map随着时间和元素数量的增加、删除,容量会不断的递增,在某些情况下比如在某个时间点频繁的进行大量数据的增加,然后又大量的删除,其map的容量并不会随着元素的删除而缩小,而在sync.Map中,当进行元素从dirty进行提升到read map的时候会进行重建,可以实现自动扩缩容。
读写分离
并发访问map读的主要问题其实是在扩容的时候,可能会导致元素被hash到其他的地址,那如果我的读的map不会进行扩容操作,就可以进行并发安全的访问了,而sync.map里面正是采用了这种方式,对增加元素通过dirty来进行保存
无锁读
通过read只读和dirty写map将操作分离,其实就只需要通过原子指令对read map来进行读操作而不需要加锁了,从而提高读的性能
写加锁
上面提到增加元素操作可能会先增加大dirty写map中,那针对多个goroutine同时写,其实就需要进行Mutex加锁了
延迟提升
上面提到了read只读map和dirty写map, 那就会有个问题,默认增加元素都放在dirty中,那后续访问新的元素如果都通过 mutex加锁,那read只读map就失去意义,sync.Map中采用一直延迟提升的策略,进行批量将当前map中的所有元素都提升到read只读map中从而为后续的读访问提供无锁支持
惰性删除
惰性删除是并发设计中一中常见的设计,比如删除某个个链表元素,如果要删除则需要修改前后元素的指针,而采用惰性删除,则通常只需要给某个标志位设定为删除,然后在后续修改中再进行操作,sync.Map中也采用这种方式,通过给指针指向某个标识删除的指针,从而实现惰性删除
我觉得最重要的就是实现了读写分离,加锁分离,从而实现了空间换取时间的快速处理。read相当于dirty的缓存,read是原子操作,不需要加锁,快速,dirty可以延迟提升,就和缓存数据库做缓存是一个道理,包括热点数据的提升。
应用场景
由以上方法可得知,无论是读操作,还是更新操作,亦或者删除操作,都会先从read进行操作,因为read的读取更新不需要锁,是原子操作,这样既做到了并发安全,又做到了尽量减少锁的争用,虽然采用的是空间换时间的策略,通过两个冗余的map,实现了这一点,但是底层存的都是指针类型,所以对于空间占用,也是做到了最大程度的优化。 但是同时也可以得知,当存在大量写操作时,会导致read中读不到数据,依然会频繁加锁,同时dirty升级为read,整体性能就会很低,所以sync.Map更加适合大量读、少量写的场景。