apiserver是集群的核心,是k8s中最重要的组件,因为它是实现声明式api的关键。
kubernetes API server的核心功能是提供了kubernetes各类资源对象(pod、RC 、service等)的增、删、改、查以及watch等HTTP Rest接口。
接口
本地端口
- 用于http请求
- 默认8080,可以通过启动参数“–insecure-port”修改
- 默认ip为localhost,可以通过启动参数“–insecure-bind-address”来修改
- 不需要认证或者授权
安全端口
- 用于https请求
- 默认端口6443,可以通过启动参数“–secure-port”修改
- 默认ip为非本地网络接口,可以通过启动参数“–bind-address”来修改
- 需要认证或者授权
- 默认不启动
api
我们可以通过三种方式来访问apiserver提供的接口
REST API
1、版本和资源对象
curl localhost:8080/api #查看kubernetes API的版本信息
curl localhost:8080/api/v1 #查看kubernetes API支持的所有的资源对象
2、具体的资源操作
首先要找到具体的资源
localhost:8080/api/v1/资源对象(ns,pod,service)然后不同的资源需要不同的处理
3、proxy接口
kubernetes API server还提供了一类很特殊的rest接口—proxy接口,这个结构就是代理REST请求,即kubernetes API server把收到的rest请求转发到某个node上的kubelet守护进程的rest端口上,由该kubelet进程负责相应。
node
masterIP:8080/api/v1/proxy/nodes/{node_name}/pods #某个节点下所有pod信息
masterIP:8080/api/v1/proxy/nodes/{node_name}/stats #某个节点内物理资源的统计信息
masterIP:8080/api/v1/proxy/nodes/{node_name}/spec #某个节点的概要信息
pod
masterIP:8080/api/v1/proxy/namespaces/{namespace}/pods/{pod_name}/{path:*} #访问pod的某个服务接口
masterIP:8080/api/v1/proxy/namespaces/{namespace}/pods/{pod_name} #访问pod
service
masterIP:8080/api/v1/proxy/namespaces/{namespace}/services/{service_name}
在master的 API Server 进程同时提供了 swagger-ui 的访问地址:http://
各种语言的client lib
也就是对上面api接口的封装。
使用各种编程语言的Kubernetes API的客户端库,主要包括两类:
- 官方支持的Kubernetes客户端库
- 社区维护的客户端库
其实编程主要是走client的库,已经封装好了,不需要具体调用对于的api。
- 官方
- Go:github.com/kubernetes/client-go/
- Python:github.com/kubernetes-client/python/
- Java:github.com/kubernetes-client/java
- dotnet:github.com/kubernetes-client/csharp
- JavaScript:github.com/kubernetes-client/javascript
- 社区
- Go:github.com/ericchiang/k8s
命令行kubectl
kubectl的原理是将输入的转化为REST API来调用,将返回结果输出。只是对REST API的一种封装,可以说是apiserver的一个客户端
常规使用:
kubectl [command] [options]
1、command
help 帮助命令,可以查找所有的命令,在我们不会用的适合,要学会使用这个命令。
kubectl helpget 获取信息
kubectl get podescribe 获取相关的详细信息,很多的资源信息都可以在这边获取,比如node的资源分配和使用
kubectl describe po rc-nginx-2-btv4jcreate 创建
kubectl create -f rc-nginx.yamlreplace 更新替换
kubectl replace -f rc-nginx.yamlpatch 如果一个容器已经在运行,这时需要对一些容器属性进行修改,又不想删除容器,或不方便通过replace的方式进行更新。kubernetes还提供了一种在容器运行时,直接对容器进行修改的方式,就是patch命令.
kubectl patch pod rc-nginx-2-kpiqt -p '{"metadata":{"labels":{"app":"nginx-3"}}}'edit edit提供了另一种更新resource源的操作
kubectl edit po rc-nginx-btv4j 上面命令的效果等效于: kubectl get po rc-nginx-btv4j -o yaml >> /tmp/nginx-tmp.yaml vim /tmp/nginx-tmp.yaml /*do some changes here */ kubectl replace -f /tmp/nginx-tmp.yamlDelete 删除
kubectl delete -f rc-nginx.yaml kubectl delete po rc-nginx-btv4j kubectl delete po -lapp=nginx-2logs 显示日志,跟docker的logs命令类似。如果要获得tail -f 的方式,也可以使用-f选项。
kubectl logs rc-nginx-2-kpiqtrolling-update 滚动更新.
kubectl rolling-update rc-nginx-2 -f rc-nginx.yaml, 这个还提供如果在升级过程中,发现有问题还可以中途停止update,并回滚到前面版本 kubectl rolling-update rc-nginx-2 —rollbackscale 扩容缩容
kubectl scale rc rc-nginx-3 —replicas=4cp将文件直接拷进容器内
kubectl cp 文件 pod:路径 kubectl cp ./test.war logtestjbossforone-7b89dd5c9-297pf:/opt/wildfly/standalone/deploymentsexec进入某个容器
kubectl exec filebeat-27 -c container -n namespaces sh以上都是常用的,其他的可以使用时通过help去使用
2、options
- -n=–namespace 指定命名空间
- 其他的可以通过kubectl options来查看使用
apiserver的作用和原理
集群内通信
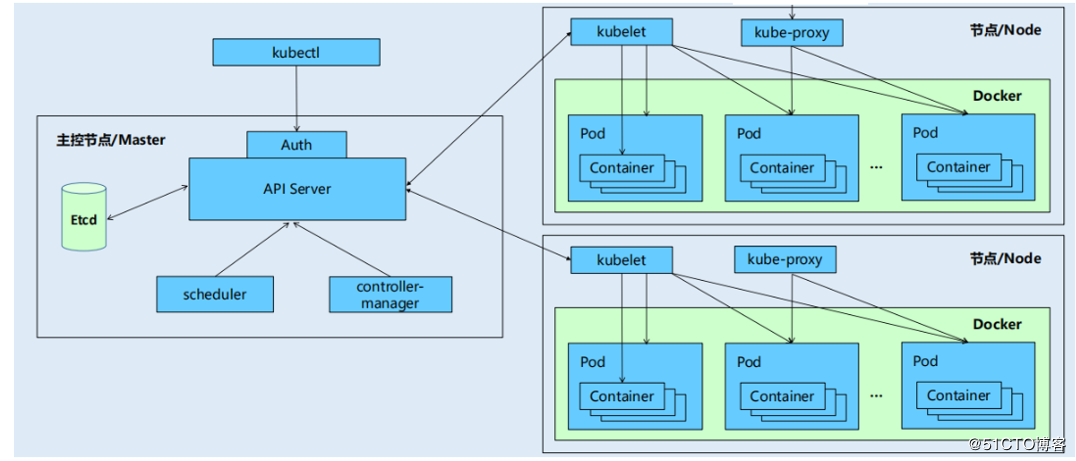
apiserver 作为统一入口,任何对数据的操作都必须经过 apiserver。apiserver负责各个模块之间的通信,集群里的功能模块通过apiserver将信息存入到etcd中,Etcd 存储集群的数据信息,其他模块通过apiserver读取这些信息,实现来模块之间的交互。
- 场景一(kubelet和API Server):每个node节点上的kubelet每个一个时间周期,就会调用一次API Server的REST接口报告自身的状态,API Server接受到这些信息后,将节点信息更新到etcd中。还有,kubelet也通过API Server的Watch接口(读取etcd的数据)监听Pod信息,如果监听到新的Pod副本被调用绑定到本节点,则执行pod对应的容器的创建和启动;如果监听到Pod的删除操作,则删除本节点上相应的Pod容器;如果检测到修改操作,则kubelet会相应的修改本节点的Pod的容器。
- 场景二(kube-controller-manager和API Server):kube-controller-manager中的Node Controller模块通过API Server模块提供的WATCH接口(读取etcd的数据),实时监控Node信息。并做相应的处理。
- 场景三(scheduler和API Server):当Scheduler通过API Server的Watch接口(读取etcd的数据)监听到新建Pod副本的信息后,它会检索所有符合该Pod要求的Node列表,开始执行Pod调度逻辑,调度成功后将Pod绑定到目标节点上。
这里多的功能模块都会频繁的使用API Server,而且API Server这个服务也是如此的重要,长时间的压力工作,会不会容器挂掉。 而且k8s只是以http协议进行通信,没有使用中间件,我能想到的通常的实现都是
- 组件作为客户端直接访问apiserver,这样apiserver肯定是扛不住的,也达不到实时性的要求。
- apiserver通知组件,如何保证消息可靠和大量并发占用问题。
k8s通过list-watch机制和缓存来解决上述问题
- List-watch是K8S统一的异步消息处理机制,保证了消息的实时性,可靠性,顺序性,性能等等,我会在下面详细说明这个机制,其实我们在每个组件中使用的informer模块就是基于这个机制的。
- k8s为了缓解集群各模块对API Server的访问压力,各模块之间都采用了缓存机制。各个模块定时的从API Server获取制定资源对象信息,并缓存到本地,这样各个功能模块先从本地获取资源对象信息,本地没有时再访问API Server。
list watch 机制解析
list watch 机制在整个k8s中经常使用的,下图是一个典型的rc创建过程的示意图。
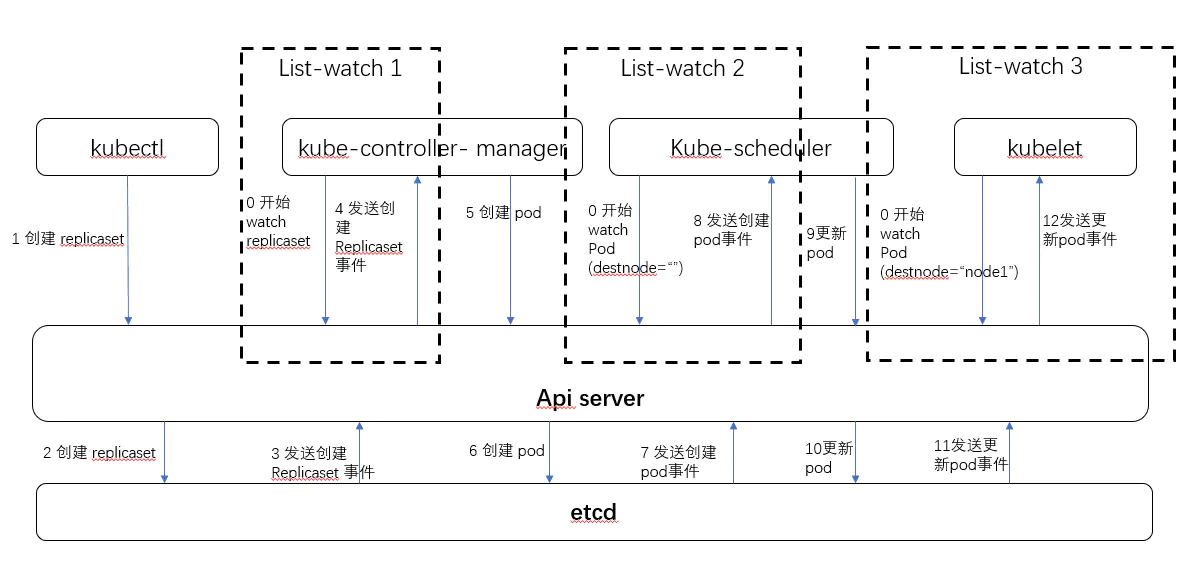
可见组件控制器,调度器,kubelet都使用了apiserver提供的list-watch机制。我们在上面也说了集群内的通信的三个场景都是使用了这种模式。在这里表现为api server 通过etcd的watch 接口监听资源的变更情况,当事件发生时 etcd 会通知 api server 比如上图的3,7,11步骤, api server 模仿etcd 提供了watch 机制, 当事件发生时,通知对应的组件 比如上图0 表示最开始进行watch 监控。
list-watch 有两部分组成,分别是 list 和 watch。list 非常好理解,就是调用资源的 list API 罗列资源,基于 HTTP 短链接实现;watch 则是调用资源的 watch API 监听资源变更事件,基于 HTTP 长链接实现
基本原理

这是一副简单的整体架构的原理图,我们先来看看client-go提供的基本组件
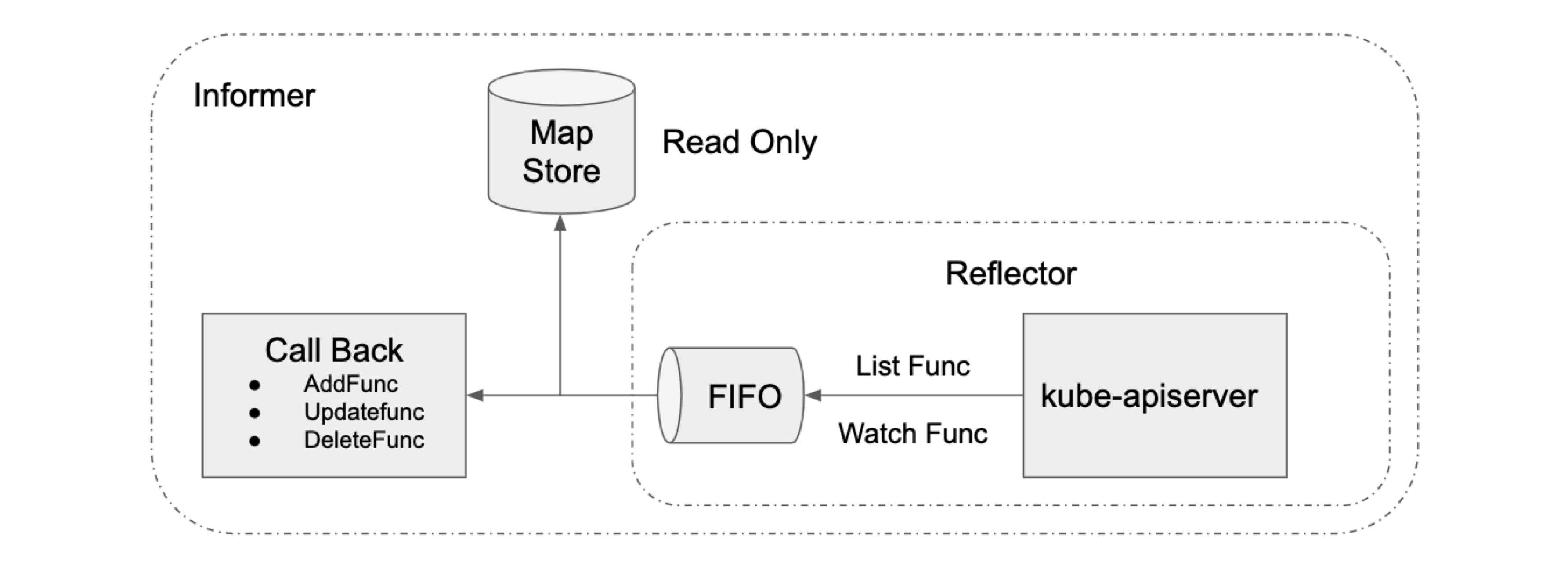
- reflector用来watch特定的k8s API资源。具体的实现是通过ListAndWatch的方法,watch可以是k8s内建的资源或者是自定义的资源。当reflector通过watch API接收到有关新资源实例存在的通知时,它使用相应的列表API获取新创建的对象,并将其放入watchHandler函数内的Delta Fifo队列中。
- informer从Delta Fifo队列中弹出对象。执行此操作的功能是processLoop。Informer,其实就是一个带有本地缓存和索引机制的、可以注册 EventHandler 的 client。
- Indexer和store,索引器提供对象的索引功能。典型的索引用例是基于对象标签创建索引。 Indexer可以根据多个索引函数维护索引。Indexer使用线程安全的数据存储来存储对象及其键。 在Store中定义了一个名为MetaNamespaceKeyFunc的默认函数,该函数生成对象的键作为该对象的
/ 组合。
client-go中提供NewIndexerInformer函数可以创建Informer 和 Indexer。
我们就先以pod控制器为例,来说明这个过程,在workequeue队列之后就是控制循环,我们正常开发的逻辑,控制循环在控制器中已经详细说明了,这里就不说了。

- Informer 在初始化时,Reflector 会先 List API 获得所有的 Pod
- Reflect 拿到全部 Pod 后,会将全部 Pod 放到 Store 中
- 如果有人调用 Lister 的 List/Get 方法获取 Pod, 那么 Lister 会直接从 Store 中拿数据
- Informer 初始化完成之后,Reflector 开始 Watch Pod,监听 Pod 相关 的所有事件;如果此时 pod_1 被删除,那么 Reflector 会监听到这个事件
- Reflector 将 pod_1 被删除 的这个事件发送到 DeltaFIFO
- DeltaFIFO 首先会将这个事件存储在自己的数据结构中(实际上是一个 queue),然后会直接操作 Store 中的数据,删除 Store 中的 pod_1
- DeltaFIFO 再 Pop 这个事件到 Controller 中
- Controller 收到这个事件,会触发 Processor 的回调函数
这个过程中我们需要详细理解list接口和watch接口,我们依然以pod资源为例
list
List接口的实现就是简单的请求然后返回就是一组pod:podlist。
watch
watch接口的api一般就是带上watch=true,表示采用HTTP 长连接持续监听pod 相关事件,每当有事件来临,返回一个WatchEvent。
watch接口是基于Chunked transfer encoding(分块传输编码)来实现接受apiserver发来的资源变更事件。
当客户端调用 watch API 时,apiserver 在 response 的 HTTP Header 中设置 Transfer-Encoding 的值为 chunked,表示采用分块传输编码,客户端收到该信息后,便和服务端该链接,并等待下一个数据块,即资源的事件信息。
比如我们使用watch接口来接受数据
$ curl -i http://{kube-api-server-ip}:8080/api/v1/watch/pods?watch=yes
HTTP/1.1 200 OK
Content-Type: application/json
Transfer-Encoding: chunked
Date: Thu, 02 Jan 2019 20:22:59 GMT
Transfer-Encoding: chunked
{"type":"ADDED", "object":{"kind":"Pod","apiVersion":"v1",...}}
{"type":"ADDED", "object":{"kind":"Pod","apiVersion":"v1",...}}
{"type":"MODIFIED", "object":{"kind":"Pod","apiVersion":"v1",...}}
List-watch机制满足异步消息的系统
- 消息可靠性:保证消息不丢失,list获取全量数据,watch获取增量数据 list API 可以查询当前的资源及其对应的状态(即期望的状态),客户端通过拿期望的状态和实际的状态进行对比,纠正状态不一致的资源。Watch API 和 apiserver 保持一个长链接,接收资源的状态变更事件并做相应处理。如果仅调用 watch API,若某个时间点连接中断,就有可能导致消息丢失,所以需要通过 list API 解决消息丢失的问题。从另一个角度出发,我们可以认为 list API 获取全量数据,watch API 获取增量数据。虽然仅仅通过轮询 list API,也能达到同步资源状态的效果,但是存在开销大,实时性不足的问题。
- 消息实时性:list-watch 机制下,每当 apiserver 的资源产生状态变更事件,都会将事件及时的推送给客户端,从而保证了消息的实时性。给定的 Kubernetes 服务器只会保留一定的时间内发生的历史变更列表。 使用 etcd3 的集群默认保存过去 5 分钟内发生的变更。
- 消息顺序性:K8S 在每个资源的事件中都带一个 resourceVersion 的标签,这个标签是递增的数字,所以当客户端并发处理同一个资源的事件时,它就可以对比 resourceVersion(新、旧两个api对象的 ResourceVersion 如果是一样的,Informer 就不需要对这个更新事件再做进一步的处理了。) 来保证最终的状态和最新的事件所期望的状态保持一致。
- 高性能:watch 作为异步消息通知机制,复用一条长链接,保证实时性的同时也保证了性能。
事件去重
这里的事件去重只是指如果针对某个资源的事件重复被触发,则就只会保留相同事件最后一个事件作为后续处理,后面的workqueue队列也会去重。

连接复用

k8s中一些控制器可能会关注多种资源,比如Deployment可能会关注Pod和replicaset,为了避免每个控制器都独立的去与apiserver建立链接,k8s中抽象了sharedInformer的概念,即共享的informer, 也就是同一资源只建立一个链接。
informer
Informer,其实就是一个带有本地缓存和索引机制的、可以注册 EventHandler 的 client。
K8S 的 informer 模块封装 list-watch API,用户只需要指定资源,编写事件处理函数,AddFunc, UpdateFunc 和 DeleteFunc 等。如下图所示,informer 首先通过 list API 罗列资源,然后调用 watch API 监听资源的变更事件,并将结果放入到一个 FIFO 队列,队列的另一头有协程从中取出事件,并调用对应的注册函数处理事件。Informer 还维护了一个只读的 Map Store 缓存,主要为了提升查询的效率,降低 apiserver 的负载。
Informer是Client-go中的一个核心工具包。在Kubernetes源码中,如果Kubernetes的某个组件,需要List/Get Kubernetes中的Object,在绝大多 数情况下,会直接使用Informer实例中的Lister()方法(该方法包含 了 Get 和 List 方法),而很少直接请求Kubernetes API。所以我们可以说Informer最基本 的功能就是List/Get Kubernetes中的Object。
我们在以前手写控制器的时候,我们会在main函数中通过创建informer来获取对应的lister
kubeClient, err := kubernetes.NewForConfig(cfg)
...
networkClient, err := clientset.NewForConfig(cfg)
...
networkInformerFactory := informers.NewSharedInformerFactory(networkClient, ...)
controller := NewController(kubeClient, networkClient,
networkInformerFactory.Samplecrd().V1().Networks())
go networkInformerFactory.Start(stopCh)
- new一个client
- new一个factory
- start
这时候,如果我们要获取lister(),就可以直接通过informer来获取
poflister := networkInformerFactory.Core().V1().Pods().Lister()
poflister.List(labels.Nothing())
poflister.Pods("kube-system").Get("kube-dns")
poflister.Pods("kube-system").List(labels.Nothing())
workqueue
每个controller都需要有一个工作队列。从event handler触发的事件会先放入工作队列,然后由controller的ProcessItem函数取出来,其实这个只是一个namespace和name,交给我们控制循环进行协调,也就是我们核心开发的业务逻辑。
Workqueue是一个去重队列,内部除了items列表外还带有processing和dirty set记录,用来实现同一个资源对象的多次事件触发,入队列后会去重,不会被多个多个worker同时处理。
基本实现

client-go的队列中包含了一个队列和两个set
- items队列
- Dirty Set
- Processing Set
通过以下的几个规则来实现了去重,解决了并发处理的问题。
- 首先进入“Dirty Set”,检查是否已经存在同一个target的request,如果存在直接丢弃,不会允许多个指向同一resource的相同request存在于Dirty Set。
- 上面经过去重的队列依次进入队列(这边只是重Dirty Set复制一份到队列中,原来的还存在),但是在对应的request在Processing Set,则不能入队列
- Reconcile loop取出一个request(A)开始处理并将该request放入Processing Set并且从Dirty Set中移除。
- reconcile loop处理结束后,重Processing Set中删除request,这时Dirty Set中的相同resource的request就可以进入队列了。
这样就解决了去重的问题,还解决了同一个对象并发处理的顺序问题,只不过可能和原来请求的顺序不太一致,相同资源的请求被delay了,但是不影响最终结果,也实现了无锁的操作。
总结

apiserver的内部结构
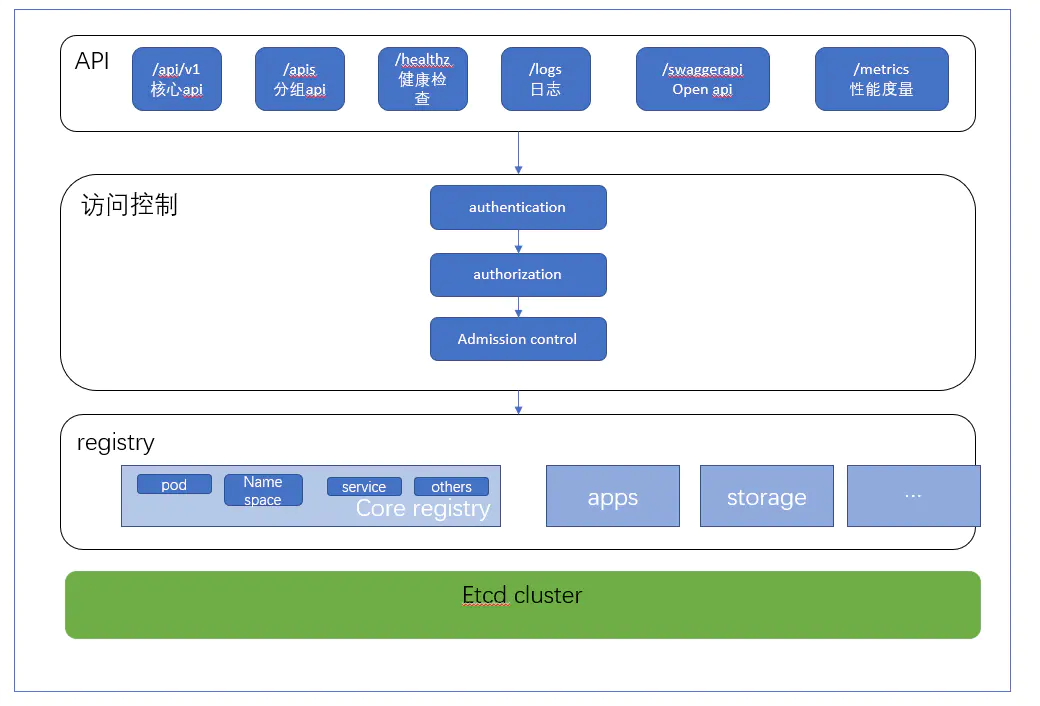
- api层: 主要提供对外的 rest api
- 访问控制层: 验证身份与鉴权,根据配置的各种资源访问许可逻辑(Adminssion control) ,判断是否允许访问
- 注册表层: K8S 将所有对象都保存在registry 中, 针对 registry 中的各种资源对象, 都定义对象类型, 如何创建资源对象, 如何转换不同版本, 以及如何将资源编码和解码为json 或protobuf 格式进行存储.
- etcd 数据库: 用于持久化存储资源对象.
listwatch源码解析
Informer源码解析
源码解析
apiserver是一套基于restful类型的接口,我们来通过源码解析看服务的启动和实现
看源码,先了解kubernetes的源码结构,cmd是入口,pkg是主要实现。
看apiserver的入口文件kubernetes/cmd/kube-apiserver/apiserver.go,比较简单,主要是初始化一些结构,然后调用run来实现apiserver的启动。
func main() {
rand.Seed(time.Now().UnixNano())
command := app.NewAPIServerCommand()
// TODO: once we switch everything over to Cobra commands, we can go back to calling
// utilflag.InitFlags() (by removing its pflag.Parse() call). For now, we have to set the
// normalize func and add the go flag set by hand.
// utilflag.InitFlags()
logs.InitLogs()
defer logs.FlushLogs()
if err := command.Execute(); err != nil {
os.Exit(1)
}
}
然后主要在run函数中实现。