高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
基本概念
首先并发中的一些重要概念
- 并发度:指在同一个时间点发起的请求数量,比如 12306 统一在下午两点钟放票,100 个人在下午两点钟同时向 12306 发起请求,此时可以认为并发度为 100。
- 响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
- 吞吐量:单位时间内处理的请求数量。
- TPS:Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。TPS包括一条消息入和一条消息出,加上一次用户数据库访问。(业务TPS = CAPS × 每个呼叫平均TPS)TPS是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值。
- QPS:每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
高并发
那么什么才叫高并发呢?
高并发要根据场景来定义,多高的并发算高并发?对于阿里来说可能几千上万才算高并发,对于普通小公司来说,可能几十上百就算高并发了。
高并发其实是和响应时间有很大关系的,你能把接口的响应时间做到1ms,你一个线程就能有1000QPS!一个服务怎么也能跑200个线程吧,QPS轻松地达到了20万呐!你看看有几个整天把高并发挂嘴上的能做到20万的QPS?可见响应时间是不那么容易快速响应的。
其实高并发的场景多用于web端的请求处理。我们就web常见架构,对于百万级的的QPS怎么进行处理,常见web架构如下
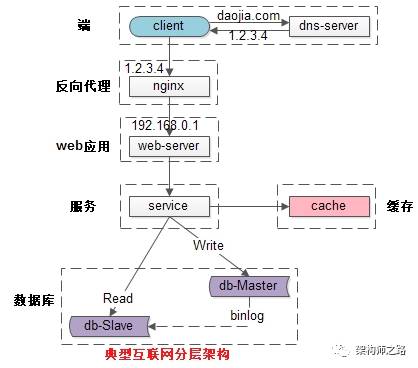
Qps如果不是太高,只要简单的使用上面的进行交互就能满足基本需要。但是如果在QPS达到百万级甚至千万级别的,就会在各种交互组件上出现瓶颈。这个时候就是经验的使用和积累,来使用不同的架构来完成这种需求。
水平扩展
1、反向代理层的水平扩展
反向代理层的水平扩展,是通过“DNS轮询”实现的:dns-server对于一个域名配置了多个解析ip,每次DNS解析请求来访问dns-server,会轮询返回这些ip。
当nginx成为瓶颈的时候,只要增加服务器数量,新增nginx服务的部署,增加一个外网ip,就能扩展反向代理层的性能,做到理论上的无限高并发。
2、站点层的水平扩展
站点层的水平扩展,是通过“nginx”实现的。通过修改nginx.conf,可以设置多个web后端。
当web后端成为瓶颈的时候,只要增加服务器数量,新增web服务的部署,在nginx配置中配置上新的web后端,就能扩展站点层的性能,做到理论上的无限高并发。
3、服务层的水平扩展
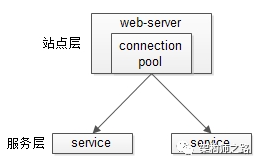
服务层的水平扩展,是通过“服务连接池”实现的。
站点层通过RPC-client调用下游的服务层RPC-server时,RPC-client中的连接池会建立与下游服务多个连接,当服务成为瓶颈的时候,只要增加服务器数量,新增服务部署,在RPC-client处建立新的下游服务连接,就能扩展服务层性能,做到理论上的无限高并发。如果需要优雅的进行服务层自动扩容,这里可能需要配置中心里服务自动发现功能的支持。
4、数据层的水平扩展
在数据量很大的情况下,数据层(缓存,数据库)涉及数据的水平扩展,将原本存储在一台服务器上的数据(缓存,数据库)水平拆分到不同服务器上去,以达到扩充系统性能的目的。
互联网数据层常见的水平拆分方式有这么几种,以数据库为例:按照范围水平拆分,按照哈希水平拆分。
垂直扩展
1、提供每台机器的配置
2、使用多线程thread(正常是线程池)并发,也有使用fork出来多进行的进行处理,这边可以在逻辑里进行业务划分。
3、优化业务,解决哪些很耗时间的操作,for循环什么的,数据库连接次数,
4、数据库的优化,使用缓存数据库,优化数据库正常先对我们写的sql进行优化,可以看执行计划,然后数据库索引进行优化,然后就是分区,分表,分库的各种切分。
其实数据库是很多需求的响应的瓶颈所在,在数据库上花功夫才是重点,一般数据库正常使用情况
mysql 的合理上限不应该超过500万
oracle。20亿数据。 清单
HBase在50000条数据批量写的性能大概是在2s左右,单个查,5-10ms左右
redis qps 500-2000。 几百G
prometheus。 100W。30s 60。200G
5、完善架构,多使用缓存,减少io的交互等。
在互联网业务发展非常迅猛的早期,如果预算不是问题,强烈建议使用“增强单机硬件性能”的方式提升系统并发能力,因为这个阶段,公司的战略往往是发展业务抢时间,而“增强单机硬件性能”往往是最快的方法。京东的架构说了句大并发,大数据下的业务其实还是靠堆机器保证的,我们现在研究的是如何在堆机器的情况下保证业务的连贯性,容错性,可用性。
实践
java
java在web并发中使用很多
JVMJEE容器中运行的JVM参数配置参数的正确使用直接关系到整个系统的性能和处理能力,JVM的调优主要是对内存管理方面的调优,优化的方向分为以下4点:
1.HeapSize 堆的大小,也可以说Java虚拟机使用内存的策略,这点是非常关键的。
2.GarbageCollector 通过配置相关的参数进行Java中的垃圾收集器的4个算法(策略)进行使用。
3.StackSize 栈是JVM的内存指令区,每个线程都有他自己的Stack,Stack的大小限制着线程的数量。
4.DeBug/Log 在JVM中还可以设置对JVM运行时的日志和JVM挂掉后的日志输出,这点非常的关键,根据各类JVM的日志输出才能配置合适的参数。
JDBC针对MySQL的JDBC的参数在之前的文章中也有介绍过,在单台机器或者集群的环境下合理的使用JDBC中的配置参数对操作数据库也有很大的影响。一些所谓高性能的 Java ORM开源框架也就是打开了很多JDBC中的默认参数:
- 1.例如:autoReconnect、prepStmtCacheSize、cachePrepStmts、useNewIO、blobSendChunkSize 等,
- 2.例如集群环境下:roundRobinLoadBalance、failOverReadOnly、autoReconnectForPools、secondsBeforeRetryMaster。
数据库连接池(DataSource)应用程序与数据库连接频繁的交互会给系统带来瓶颈和大量的开销会影响到系统的性能,JDBC连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而再不是重新建立一个连接,因此应用程序不需要频繁的与数据库开关连接,并且可以释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。这项技术能明显提高对数据库操作的性能。
数据存取数据库服务器的优化和数据的存取,什么类型的数据放在什么地方更好是值得去思考的问题,将来的存储很可能是混用的,Cache,NOSQL,DFS,DataBase 在一个系统中都会有。
缓存在宏观上看缓存一般分为2种:本地缓存和分布式缓存
- 1.本地缓存,对于Java的本地缓存而言就是讲数据放入静态(static)的数据结合中,然后需要用的时候就从静态数据结合中拿出来,对于高并发的环境建议使用 ConcurrentHashMap或者CopyOnWriteArrayList作为本地缓存。缓存的使用更具体点说就是对系统内存的使用,使用多少内存的资源需要有一个适当比例,如果超过适当的使用存储访问,将会适得其反,导致整个系统的运行效率低下。
- 2.分布式缓存,一般用于分布式的环境,将每台机器上的缓存进行集中化的存储,并且不仅仅用于缓存的使用范畴,还可以作为分布式系统数据同步/传输的一种手段,一般被使用最多的就是Memcached和Redis。数据存储在不同的介质上读/写得到的效率是不同的,在系统中如何善用缓存,让你的数据更靠近cpu,
并发/多线程在高并发环境下建议开发者使用JDK中自带的并发包(java.util.concurrent),在JDK1.5以后使用java.util.concurrent下的工具类可以简化多线程开发,在java.util.concurrent的工具中主要分为以下几个主要部分:
- 1.线程池,线程池的接口(Executor、ExecutorService)与实现类(ThreadPoolExecutor、 ScheduledThreadPoolExecutor),利用jdk自带的线程池框架可以管理任务的排队和安排,并允许受控制的关闭。因为运行一个线程需要消耗系统CPU资源,而创建、结束一个线程也对系统CPU资源有开销,使用线程池不仅仅可以有效的管理多线程的使用,还是可以提高线程的运行效率。
- 2.本地队列,提供了高效的、可伸缩的、线程安全的非阻塞 FIFO 队列。java.util.concurrent 中的五个实现都支持扩展的 BlockingQueue 接口,该接口定义了 put 和 take 的阻塞版本:LinkedBlockingQueue、ArrayBlockingQueue、SynchronousQueue、PriorityBlockingQueue 和 DelayQueue。这些不同的类覆盖了生产者-使用者、消息传递、并行任务执行和相关并发设计的大多数常见使用的上下文。
拒绝策略介绍
线程池的拒绝策略,是指当任务添加到线程池中被拒绝,而采取的处理措施。 当任务添加到线程池中之所以被拒绝,可能是由于:第一,线程池异常关闭。第二,任务数量超过线程池的最大限制。
线程池共包括4种拒绝策略,它们分别是:AbortPolicy, CallerRunsPolicy, DiscardOldestPolicy和DiscardPolicy。
AbortPolicy -- 当任务添加到线程池中被拒绝时,它将抛出 RejectedExecutionException 异常。
CallerRunsPolicy -- 当任务添加到线程池中被拒绝时,会在线程池当前正在运行的Thread线程池中处理被拒绝的任务。
DiscardOldestPolicy -- 当任务添加到线程池中被拒绝时,线程池会放弃等待队列中最旧的未处理任务,然后将被拒绝的任务添加到等待队列中。
DiscardPolicy -- 当任务添加到线程池中被拒绝时,线程池将丢弃被拒绝的任务。
线程池默认的处理策略是AbortPolicy!
go
go并发是golang语言的核心能力。
并发安全
并发安全是并发中核心需要解决的问题。
高并发需要注意的事情
高并发下一定要减少锁的使用,这边也是channel在go中的重要作用之一。
好的习惯是,稍大的类型存到map都存储指针而不是值。
定义数据结构的时候,减少后面使用的转换
defer是性能杀手,我的原则是能不用尽量避开。
能不在循环内部做的,就不要在循环内存处理
减少内存的频繁分配,减少使用全局锁的可能
设置并发数
常规的并发模型就是我们使用的工作池模型,我们需要了解具体的工作模式,可以量化的分析并发,比如下图是一个典型的工作线程的处理过程
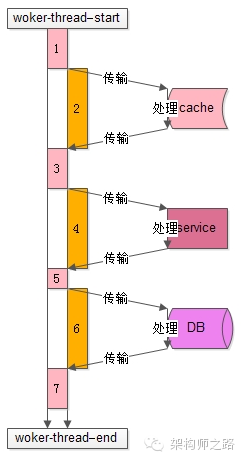
从开始处理start到结束处理end,该任务的处理共有7个步骤:
- 1)从工作队列里拿出任务,进行一些本地初始化计算,例如http协议分析、参数解析、参数校验等
- 2)访问cache拿一些数据
- 3)拿到cache里的数据后,再进行一些本地计算,这些计算和业务逻辑相关
- 4)通过RPC调用下游service再拿一些数据,或者让下游service去处理一些相关的任务
- 5)RPC调用结束后,再进行一些本地计算,怎么计算和业务逻辑相关
- 6)访问DB进行一些数据操作
- 7)操作完数据库之后做一些收尾工作,同样这些收尾工作也是本地计算,和业务逻辑相关
分析整个处理的时间轴,会发现:
- 1)其中1,3,5,7步骤中【上图中粉色时间轴】,线程进行本地业务逻辑计算时需要占用CPU
- 2)而2,4,6步骤中【上图中橙色时间轴】,访问cache、service、DB过程中线程处于一个等待结果的状态,不需要占用CPU,进一步的分解,这个“等待结果”的时间共分为三部分:
- 请求在网络上传输到下游的cache、service、DB
- 下游cache、service、DB进行任务处理
- cache、service、DB将报文在网络上传回工作线程
通过上面的分析,Worker线程在执行的过程中,有一部计算时间需要占用CPU,另一部分等待时间不需要占用CPU,通过量化分析,例如打日志进行统计,可以统计出整个Worker线程执行过程中这两部分时间的比例,例如:
- 1)时间轴1,3,5,7【上图中粉色时间轴】的计算执行时间是100ms
- 2)时间轴2,4,6【上图中橙色时间轴】的等待时间也是100ms
得到的结果是,这个线程计算和等待的时间是1:1,即有50%的时间在计算(占用CPU),50%的时间在等待(不占用CPU):
- 1)假设此时是单核,则设置为2个工作线程就可以把CPU充分利用起来,让CPU跑到100%
- 2)假设此时是N核,则设置为2N个工作现场就可以把CPU充分利用起来,让CPU跑到N*100%
结论:
N核服务器,通过执行业务的单线程分析出本地计算时间为x,等待时间为y,则工作线程数(线程池线程数)设置为 N*(x+y)/x,能让CPU的利用率最大化。
一般来说,非CPU密集型的业务(加解密、压缩解压缩、搜索排序等业务是CPU密集型的业务),瓶颈都在后端数据库,本地CPU计算的时间很少,所以设置几十或者几百个工作线程也都是可能的。