script_exporter探针是一个自研发的探针,通过脚本执行shell命令获取机器指标并且按着配置规范进行返回,最后转化为时序数据库的标准格式用于系统的监控。
设计
探针设计
架构
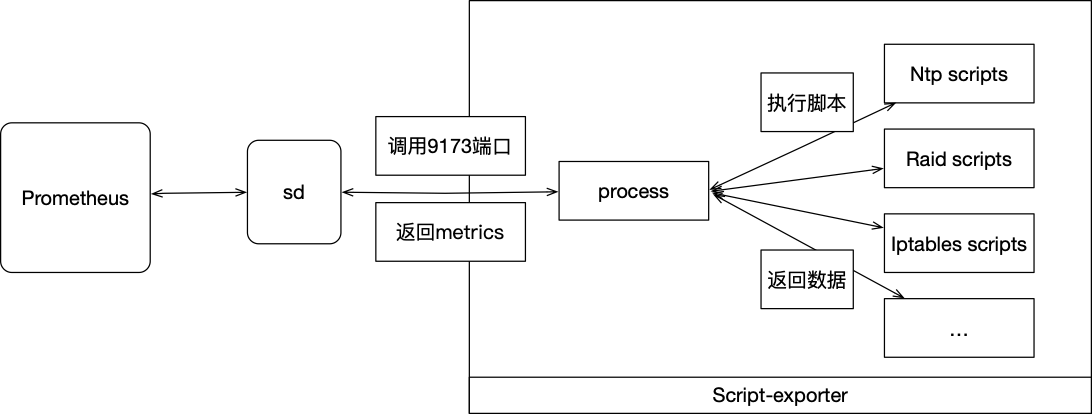
我们通过下面的配置来讲解使用方法
全局配置文件script-exporter.yml
scriptconfigpath: /Users/chunyinjiang/jcy/work/go_workspace/prometheus/script_exporter-sn-1.0.0/src/github.com/promes/script_exporter/scriptconfig
reload: 20s
说明:
- scriptconfigpath是对应类型的服务的配置文件的存放路径,默认在当前目录下的scriptconfig这个目录下
- reload是自动热加载的定时时间,配置就开启定时器,配置自动加载。关于重载这边说明一下使用
- 配置reload表示开启,配置的value就是定时重载的时间
- value可以配置h,m,s等时间单位,支持自动解析,也可以不加单位,默认时间单位为s
- 定时器可以重新加载自己的定时时间,当配置文件中的reload发生改变的时候,可以自动更新配置和自己的定时时间
- 在运行过程中,定时器删除和新增,也就是直接新增或者删除reload,需要给这个进程传递一个HUP信号
- 服务的配置文件的路径下文件可以动态加载,加载方式有两种,一个直接传递HUP信号,一个是设置定时器自动重新加载
服务配置文件ntp_exporter.yml
ntp:
cmd: './script/checkntp.sh'
split: "|"
service: "ntp"
metrics:
- client:
type: "label"
description: "client type"
- status:
type: "gauge"
description: "client status"
- synchronize:
type: "gauge"
description: "whether time synchronize or not"
- offset:
type: "gauge"
description: "time offset"
说明
- cmd表示执行的脚本,建议最好用绝对路径,正常情况下,我们把脚本存放在当前的script目录下
- spilt表示返回数据的分隔符,用于数据解析,正常使用“|”
- service表示当前配置属于的服务类型,对应采集参数。
- ntp是自定义的一个域,一个脚本对应的执行结果和指标名的定义都在这个域下面,同时也是指标名或者标签名的前缀
- metrics是定义对应指标名和指标里的标签
- 每个指标模块有三部分组成,对应的是对脚本一个返回值的处理
- 首先是指标名或者标签名的后半部分,比如offset,加上前缀就会采集一个指标ntp_offset,比如client,就会有一个标签ntp_client,这边特别说明一下标签会在当前域中的所有的指标里加上。
- type表示类型,目前支持:
- “label”标签,
- “gauge”可以增加减少的变量
- “count”只能增加的变量
- description表示描述,表示对当前指标或者标签的说明
使用
指标可配置:
- 指标名为域名+metrics中的key,是对应的域的拼接,最总形成最后的指标名,在采集结果中展示。
- 指标值是cmd执行返回的结果,必须和配置中的metrics中的list一一可对应,否则不显示。
- 返回值可指定分隔符,默认为空格,可以使用spilt进行配置
- 返回value:
- int /String
- 支持counter,label,gauge
- 返回数值int直接使用counter,guage
- 返回string直接使用label
- list
- 返回list,循环处理
- int /String
默认采集指标
- 脚本执行是否成功,指标名制定为scrpit_success
- 脚本执行时间,指标名制定为scrpit_duration
- 默认采集指标默认制定标签(namespace=”域”)
指标展示
上面配置执行探针指标如下:
# HELP ntp_offset time offset
# TYPE ntp_offset gauge
ntp_offset{ntp_client="ntpdate"} -0.020493
# HELP ntp_status client status
# TYPE ntp_status gauge
ntp_status{ntp_client="ntpdate"} 1
# HELP ntp_synchronize whether time synchronize or not
# TYPE ntp_synchronize gauge
ntp_synchronize{ntp_client="ntpdate"} 0
# HELP raid_group_metrics raid next start time
# TYPE raid_group_metrics gauge
raid_group_metrics{raid_group_id="0/0",raid_group_status="Optl",raid_group_strategy="RAWBC",raid_group_type="HDD"} 1
raid_group_metrics{raid_group_id="0/1",raid_group_status="Optl",raid_group_strategy="RAWBD",raid_group_type="HDD"} 1
# HELP raid_nextstarttime raid next start time
# TYPE raid_nextstarttime gauge
raid_nextstarttime{raid_delay="168",raid_mode="Auto",raid_state="Stopped",raid_type="pr"} 7
raid_nextstarttime{raid_delay="672",raid_mode="Concurrent",raid_state="Stopped",raid_type="cc"} 0
# HELP raid_reset_metrics whether raid reset or not
# TYPE raid_reset_metrics gauge
raid_reset_metrics{raid_reset_key="resetadapter"} 0
# HELP scrpit_duration Displays time about run script
# TYPE scrpit_duration gauge
scrpit_duration{namespace="ntp"} 0.266784932
scrpit_duration{namespace="raid"} 0.02776845
scrpit_duration{namespace="raid_group"} 0.077789637
scrpit_duration{namespace="raid_reset"} 0.003795185
# HELP scrpit_success Displays whether or not the script run success
# TYPE scrpit_success gauge
scrpit_success{namespace="ntp"} 1
scrpit_success{namespace="raid"} 1
scrpit_success{namespace="raid_group"} 1
scrpit_success{namespace="raid_reset"} 1
部署设计
架构
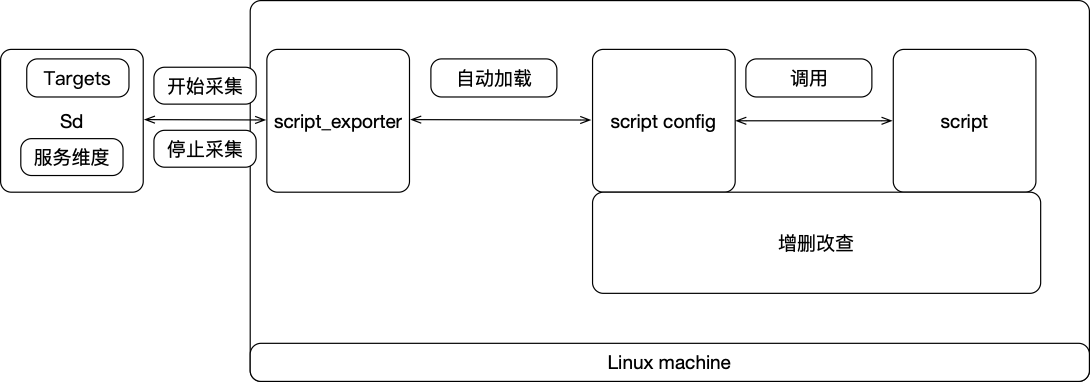
设计说明:
- 探针只有一个,脚本和脚本配置文件单独存放,提供增加,删除,修改接口,这样可以动态的通过对脚本和脚本配置文件的处理,来实现所有脚本的服务的动态上下线
- 同时只有一个探针进程,不会出现同是脚本监控的采集部署多个探针进程,消耗机器资源
- 功能模块
- 上传脚本文件接口,可以是窗口,或者文件按钮
- 上传配置文件接口,可以是窗口,或者文件按钮
- 开始采集,不动脚本和配置,使用服务发现。
- 停止采集,不动脚本和配置,使用服务发现。
- 生成子配置文件—后期可以考虑配置自动生成(设置指标相关规则)
- 自动加载,信号和定时器两种方式
使用
1、安装
- 拉去脚本和配置文件到指定的目录
- reload
2、卸载
- 删除脚本和配置文件
- reload
3、开始采集
- 使用服务发现,改变注册信息(粒度到脚本,都是脚本的附加属性)
- prometheus更新配置
4、停止采集
- 使用服务发现,改变注册信息(粒度到脚本,都是脚本的附加属性)
- prometheus更新配置
5、采集频率
consul注册增加采集频率目录,consul-template按目录生成不同的json文件,promehteus使用不同job来设定好采集频率,进行采集。
6、脚本数量
脚本数量有以下因素决定:
- 超时时间
目前prometheus默认拉去数据的超时时间为10S(可配置),探针执行脚本设计的超时时间为1S(可配置),所以考虑到异常情况,脚本全部执行失败,保证prometheus获取数据,所以正常情况下,一个job保持9个脚本的,以此类推,在超时时间上,一个job脚本的数量取决于探针和数据库的超时时间。所有脚本的数量取决于job数量和机器性能资源压力。
特殊场景:ntp同步宕机的时间源的情况,会出现长达4S的脚本执行时间,所以服务监控脚本设计为5S超时时间,这边需要调整prometheus默认拉去数据的超时时间为60S(可配置),每个job可配置11个脚本。
- 性能
资源消耗这一块还没有压测,目前在满足超时时间的情况下机器的各项数据上没有什么压力。
1.27-2.12这段时间在一台物理机上跑了ntp和raid,目前没有发现错误情况,资源消耗如下图
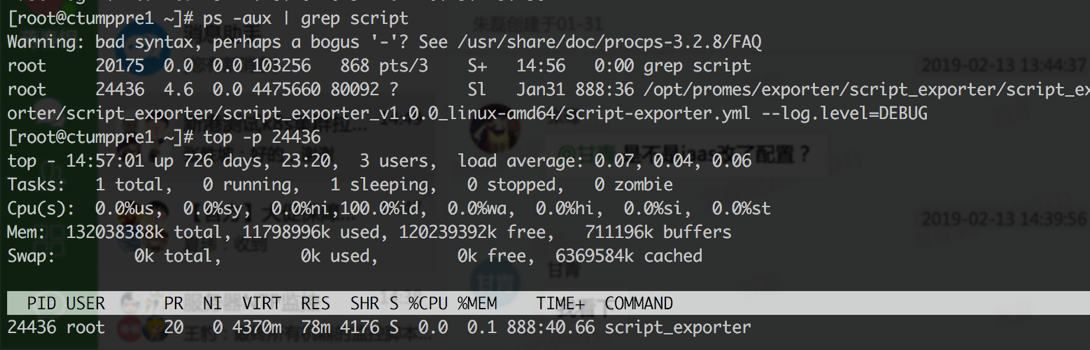

注册
服务维度
直接使用参数targets来指定服务,,数据用“,”隔开。例如 http://10.37.2.191:9173/metrics?targets=raid
只是raid服务相关的返回
# HELP raid_group_metrics whether get raid group info or not
# TYPE raid_group_metrics gauge
raid_group_metrics{raid_group_id="0/0",raid_group_status="Optl",raid_group_strategy="RAWBC",raid_group_type="HDD"} 1
raid_group_metrics{raid_group_id="0/1",raid_group_status="Optl",raid_group_strategy="RAWBD",raid_group_type="HDD"} 1
# HELP raid_metrics whether get raid info or not
# TYPE raid_metrics gauge
raid_metrics{raid_state="Stopped",raid_type="CC"} 1
raid_metrics{raid_state="Stopped",raid_type="PR"} 1
# HELP raid_reset_metrics whether raid reset or not
# TYPE raid_reset_metrics gauge
raid_reset_metrics{raid_reset_key="resetadapter"} 0
# HELP scrpit_duration Displays time about run script
# TYPE scrpit_duration gauge
scrpit_duration{namespace="raid"} 0.017630159
scrpit_duration{namespace="raid_group"} 0.036695585
scrpit_duration{namespace="raid_reset"} 0.00264489
# HELP scrpit_success Displays whether or not the script run success
# TYPE scrpit_success gauge
scrpit_success{namespace="raid"} 1
scrpit_success{namespace="raid_group"} 1
scrpit_success{namespace="raid_reset"} 1
脚本维度
使用两个参数来控制targets和scripts,数据用“,”隔开。例如 http://10.37.2.191:9173/metrics?targets=raid&&scripts=cc_pr_info.sh
只返回raid服务下的cc_pr_info.sh脚本执行的返回值
# HELP raid_metrics whether get raid info or not
# TYPE raid_metrics gauge
raid_metrics{raid_state="Stopped",raid_type="CC"} 1
raid_metrics{raid_state="Stopped",raid_type="PR"} 1
# HELP scrpit_duration Displays time about run script
# TYPE scrpit_duration gauge
scrpit_duration{namespace="raid"} 0.017308263
# HELP scrpit_success Displays whether or not the script run success
# TYPE scrpit_success gauge
scrpit_success{namespace="raid"} 1
问题
1、大量僵死进程
先解释一些概念
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
僵死进程的父进程被kill掉,就会变成孤儿进程,被系统回收。
1.僵尸进程:前文已经对僵尸进程的定义进行了说明。那么defunct进程只是在process table(进程表项)里有一个记录,其他的资源没有占用,除非你的系统的process个数已经快超过限制了,zombie进程不会有更多的坏处。
2.产生原因:在子进程终止后到父进程调用wait()前的时间里,子进程被称为zombie;
具体a. 子进程结束后向父进程发出SIGCHLD信号,父进程默认忽略了它
b. 父进程没有调用wait()或waitpid()函数来等待子进程的结束
c. 网络原因有时会引起僵尸进程;
如何防止僵尸进程
(1) 让僵尸进程成为孤儿进程,由init进程回收;(手动杀死父进程)
(2) 调用fork()两次;
(3) 捕捉SIGCHLD信号,并在信号处理函数中调用wait函数;
1.调用过程中一定要注意:创建句柄一定要释放,正常在创建的时候直接defer,否则没有调用wait,直接return,就会使得调用的进程失去父进程而变成僵尸进程,以后在任何地方调用子进程的时候都要注意,sndp探针就是一个实例
bashCmd := exec.CommandContext(ctx, scriptType,str[0:]…) defer bashCmd.Wait()
代码编辑问题
//var flag = true
//for _, value := range res {
// if len(value) != len(script.Metrics) {
// flag = false
// }
//}
//if !flag {
// log.Errorf("response array the number of row UnMatch")
// return nil, errors.New("response array the number of row UnMatch")
//}
res是[][]string,当返回time=“2018-11-28T16:24:01+08:00” level=debug msg=“parse res in string array: [[]]“使用range还是会进入,赋值flag为false,所以return
平台
目前在监控mycat,ntp等服务中使用的就是这种方式。