关于数据结构的一些基础总结。
总结
https://github.com/azl397985856/leetcode
基本数据结构
逻辑结构:是指数据元素之间的逻辑关系,从逻辑关系上描述信息。
存储结构(又称物理结构):数据结构在计算机中的表示(又称映像)。
按物理结构分为顺序结构和链式结构,在计算机上只有这两种存储方式。其实还有一种特殊的,就是散点集合,数据之间没有关系的。我们一般描述的都是数据之间有关系的。
按逻辑结构进行分为我们常说的散点集合,线性数据结构和非线性数据结构(树状数据结构和网状数据结构)。这个是我们常规使用的方式,其实数据结构就是那几种。
散点集合
就是正常的set集合,数据之间没有什么关系。
集合结构中的数据元素除了 同属于一个集合外,它们之间没有其他关系。 各个数据元素是”平等’的,它们的共同属性是”同属于一个集合”。数据结构中的集合关系就类似于数学中的集合。
在物理结构上也是单独存在的点,没有什么关系。
线性数据结构
线性表
数组
数组其实是一段连续的内存,通过唯一索引下标(由于地址也是连续的,所以下标根据地址循序来就行,不需要存)来获取对应内存的值。
数组可以说是最基本的数据结构,可以实现很多的复杂的数据结构,比如队列,栈,树,图等,只不过有些数据结构使用数组会造成很多的资源空间的浪费。选择使用了链式来实现,在计算机中就是这两种基本结构。
0、数组寻址的原理
内存分为了堆内存和栈内存,当初始化数组时,堆内存分配相应大小的连续的内存块,并将第一个内存块的地址放入栈内存中存储。这样读取数据的时候取第0个就是首地址的内存中的数据,第1个就是首地址+1的内存块中数据。其余删除与写入操作与读取类似。
当定义一个数组a时,编译器根据指定的元素个数和元素的类型分配确定大小(元素类型大小×元素个数)的一块内存,并把这块内存的名字命名为 a,名字 a 一旦与这块内存匹配就不能再改变。其中,a[0]、a[1]、a[2]、a[3] 与 a[4] 都为 a 的元素,但并非元素的名字(数组的每一个元素都是没有名字的)。
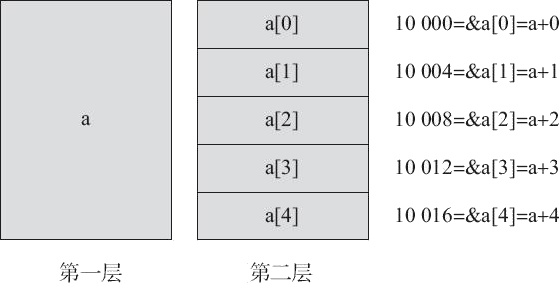
在 32 位系统中,由于 int 类型的数据占 4 字节单元,因此该数组 a 在内存中共占据连续的 4×5=20 字节单元,依次保存 a[0]、a[1]、a[2]、a[3] 与 a[4] 共 5 个元素。如果这里假设元素 a[0] 的地址是 10000,则元素 a[1] 的地址是 10000+1×4=10004; 元素 a[2] 的地址是 10000+2×4=10008; 元素 a[3] 的地址是 10000+3×4=10012; 元素 a[4] 的地址是 10000+4×4=10016。
由此可见,数组的存储具有如下特点:
索引从 0 开始。
数组在内存中占据连续的字节单元。
数组占据的字节单元数等于数组元素个数乘以该数组所属数据类型的数据占据的字节单元数(元素个数乘以元素类型大小)。
数组元素按顺序连续存放。
1、代码表示
[]int
2、经典应用
两数之和(暴力遍历,找到相加相等返回index,还可以使用map)
func twoSum(nums []int, target int) []int { var index []int for i:=0;i<len(nums);i++{ temp := target - nums[i] for j:=0;j<len(nums);j++{ if j!=i{ if temp == nums[j]{ index = append(index,i) index = append(index,j) return index } } } } return index }
3、golang中数组array和slice的实现
golang数组也是一样的,一段连续的内存,连续的地址来实现来数组的存储,但是Go语言的数组又不同于C语言或者其他语言的数组,C语言的数组变量是指向数组第一个元素的指针;而Go语言的数组是一个值,Go语言中的数组是值类型,一个数组变量就表示着整个数组,意味着Go语言的数组在传递的时候,传递的是原数组的拷贝。
slice就是一个指向数组的指针。
稀疏数组
稀疏数组就是我们在使用数组来存储数据结构的时候,数组中有很多的空间是浪费的,比如一个二维数组中只存储来几个数字,我们可以将有数据的的位置的坐标和数值用我们正常的数组来存储,这样可以节省很多的空间,这个数组就是稀疏数组,其实这也是压缩的一种方式。
1、实现即应用,用于存储压缩数据(定义一个结构体存储数据的位置和值,然后存放到数组中去)
package main
import (
"fmt"
)
type ValNode struct {
row int
col int
val int
}
func main() {
//一、先创建一个原始数组
var chessMap [11][11]int
chessMap[1][2] = 1 //黑子
chessMap[2][3] = 2 //蓝子
//输出原始数组
for _, v := range chessMap {
for _, v2 := range v {
fmt.Printf("%d\t", v2)
}
fmt.Println()
}
//二、转成稀疏数组
//1、遍历chessMap,如果发现有一个元素的值不为0,创建一个node结构体
//2、将其放入到对应的切片中即可
var sparseArr []ValNode
//标准的一个稀疏数组应该还有一个记录元素的二维数组的规模(行和列,默认值)
//创建一个ValNode值节点
valNode := ValNode{
row: 11,
col: 11,
val: 0,
}
sparseArr = append(sparseArr, valNode)
//遍历
for i, v := range chessMap {
for j, v2 := range v {
if v2 != 0 {
//创建一个ValNode值节点
valNode := ValNode{
row: i,
col: j,
val: v2,
}
sparseArr = append(sparseArr, valNode)
}
}
}
//输出稀疏数组
fmt.Println("当前的稀疏数组是:")
for i, valNode := range sparseArr {
fmt.Printf("%d: %d %d %d\n", i, valNode.row, valNode.col, valNode.val)
}
//三、恢复原始的数组
//1、这里使用稀疏数组恢复
//2、先创建一个原始数组
var chessMap2 [11][11]int
//遍历稀疏数组(文件的每一行)
for i, valNode := range sparseArr {
if i != 0 { //跳过第一行的数据
chessMap2[valNode.row][valNode.col] = valNode.val
}
}
//输出chessMap2
fmt.Println("恢复后的原始数据:")
for _, v := range chessMap2 {
for _, v2 := range v {
fmt.Printf("%d\t", v2)
}
fmt.Println()
}
}
2、压缩过程
package main
import (
"bufio"
"fmt"
"log"
"os"
"strconv"
"strings"
)
type nodeval struct {
row int
col int
val interface{}
}
//文件读取转成原始数据
func ReadData(filename string) {
file, err := os.OpenFile(filename, os.O_RDONLY, 0666)
if err != nil {
log.Fatalf("%s", err)
}
defer file.Close()
bfrd := bufio.NewReader(file)
var index = 0
var arr [][]int
for {
line, err := bfrd.ReadBytes('\n')
if err != nil {
break
}
index++
temp := strings.Split(string(line), " ")
row, _ := strconv.Atoi(temp[0])
col, _ := strconv.Atoi(temp[1])
value, _ := strconv.Atoi(temp[2])
if index == 1 {
for i := 0; i < row; i++ {
var arr_temp []int
for j := 0; j < col; j++ {
arr_temp = append(arr_temp, value)
}
arr = append(arr, arr_temp)
}
}
if index != 1 {
arr[row][col] = value
}
}
// 打印数据
fmt.Println("从磁盘读取后的数据")
for _, v := range arr {
for _, v1 := range v {
fmt.Printf("%d\t", v1)
}
fmt.Println()
}
}
func main() {
var chessmap [11][11]int
chessmap[1][2] = 1
chessmap[2][3] = 2
// 看看原始数据
for _, v := range chessmap {
for _, v1 := range v {
fmt.Printf("%d\t", v1)
}
fmt.Println()
}
// 转成稀疏数据
var sparseArr []nodeval
// 数据规模
sparseArr = append(sparseArr, nodeval{
row: 11,
col: 11,
val: 0,
})
//稀疏数组
for row, val := range chessmap {
for col, val1 := range val {
if val1 != 0 {
sparseArr = append(sparseArr, nodeval{
row: row,
col: col,
val: val1,
})
}
}
}
// 稀疏数组存盘
filepath := "c:/test.txt"
file, err := os.OpenFile(filepath, os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
}
defer file.Close()
writer := bufio.NewWriter(file)
for _, node := range sparseArr {
str := fmt.Sprintf("%d %d %d \n", node.row, node.col, node.val)
writer.WriteString(str)
}
writer.Flush()
// 稀疏数据从磁盘读取转换成原始数据
ReadData(filepath)
}
- 将这个稀疏数组,存盘
- 打开这个文件,恢复原始数组
稀疏矩阵
其实就是上面转化的矩阵,在矩阵中,若数值为0的元素数目远远多于非0元素的数目,并且非0元素分布没有规律时,则称该矩阵为稀疏矩阵;与之相反,若非0元素数目占大多数时,则称该矩阵为稠密矩阵。定义非零元素的总数比上矩阵所有元素的总数为矩阵的稠密度。
1、代码
其实就是一个二维数组
2、经典应用
- 稀疏矩阵的一个典型应用就是稀疏数组,用于数据的压缩存储。在上面已经实现。
对称矩阵
对称矩阵(Symmetric Matrices)是指以主对角线为对称轴,各元素对应相等的矩阵。 在线性代数中,对称矩阵是一个方形矩阵,其转置矩阵和自身相等
1、对称矩阵是一个方阵,即就是行和列长度相等
2、对称矩阵中的所有元素都是相互对称的,即就是矩阵的下三角和上三角是对称的
常规矩阵
常规矩阵就是一个矩阵,矩阵(Matrix)是一个按照长方阵列排列的复数或实数集合。
1、代码
其实就是一个二维数组,在二维数组上的算法的应用还是比较多的
[][]int
2、经典应用
矩阵转置(矩阵反转)(矩阵的转置是指将矩阵的主对角线翻转,交换矩阵的行索引与列索引。所以只要获取一列重下往上的数据,放到对应的行中就可以,依次类推)
func transpose(A [][]int) [][]int { // 867. 转置矩阵 if len(A) == 0 { return A } rlength := len(A) // 转置矩阵的长 rwidth := len(A[0]) // 转置矩阵的宽 results := make([][]int, rwidth) // 返回转置矩阵 for i := 0; i < rwidth; i++ { // 分配二维矩阵空间 results[i] = make([]int, rlength) } for r, row := range A { // 遍历当前矩阵 for c, _ := range row { results[c][r] = A[r][c] } } return results }矩阵旋转(90度,就是先转置也就是沿着主对角线反转,在上下反转,就是进行对应位置值的互换)
func rotate(matrix [][]int) { n := len(matrix) // 水平翻转 for i := 0; i < n/2; i++ { matrix[i], matrix[n-1-i] = matrix[n-1-i], matrix[i] } // 主对角线翻转 for i := 0; i < n; i++ { for j := 0; j < i; j++ { matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j] } } }其实这个原理还是源于一个规律:对于矩阵中第 ii 行的第 jj 个元素,在旋转后,它出现在倒数第 ii 列的第 jj 个位置。根据这个原理我们本身就能解决
func rotate(matrix [][]int) { n := len(matrix) tmp := make([][]int, n) for i := range tmp { tmp[i] = make([]int, n) } for i, row := range matrix { for j, v := range row { tmp[j][n-1-i] = v } } copy(matrix, tmp) // 拷贝 tmp 矩阵每行的引用 }矩阵螺旋输出(模拟路径,当需要边缘或在之前走过的点的时候,方向就顺时针旋转一下。定义方向指针和四个方向的走过的数据)
func spiralOrder(matrix [][]int) []int { if len(matrix) == 0 || len(matrix[0]) == 0 { return []int{} } rows, columns := len(matrix), len(matrix[0]) visited := make([][]bool, rows) for i := 0; i < rows; i++ { visited[i] = make([]bool, columns) } var ( total = rows * columns order = make([]int, total) row, column = 0, 0 directions = [][]int{[]int{0, 1}, []int{1, 0}, []int{0, -1}, []int{-1, 0}} directionIndex = 0 ) for i := 0; i < total; i++ { order[i] = matrix[row][column] visited[row][column] = true nextRow, nextColumn := row + directions[directionIndex][0], column + directions[directionIndex][1] if nextRow < 0 || nextRow >= rows || nextColumn < 0 || nextColumn >= columns || visited[nextRow][nextColumn] { directionIndex = (directionIndex + 1) % 4 } row += directions[directionIndex][0] column += directions[directionIndex][1] } return order }最小路径和(动态规划,求出所有的矩阵节点的最小路径和)
func minPathSum(grid [][]int) int { colume := len(grid[0]) row := len(grid) dp := make([][]int,row) for i:=0;i<row;i++{ dp[i]=make([]int, colume) } dp[0][0] = grid[0][0] for i:=1;i<row;i++{ dp[i][0] = dp[i-1][0] + grid[i][0] } for i:=1;i<colume;i++{ dp[0][i] = dp[0][i-1] + grid[0][i] } for i:=1;i<row;i++{ for j:=1;j<colume;j++{ dp[i][j] = min(dp[i-1][j],dp[i][j-1]) + grid[i][j] } } return dp[row-1][colume-1] } func min(a,b int)int{ if a < b { return a } return b }扫雷
给定一个代表游戏板的二维字符矩阵。 ’M’ 代表一个未挖出的地雷,’E’ 代表一个未挖出的空方块,’B’ 代表没有相邻(上,下,左,右,和所有4个对角线)地雷的已挖出的空白方块,数字(’1’ 到 ‘8’)表示有多少地雷与这块已挖出的方块相邻,’X’ 则表示一个已挖出的地雷。
现在给出在所有未挖出的方块中(’M’或者’E’)的下一个点击位置(行和列索引),根据以下规则,返回相应位置被点击后对应的面板:
- 如果一个地雷(’M’)被挖出,游戏就结束了- 把它改为 ’X’。
- 如果一个没有相邻地雷的空方块(’E’)被挖出,修改它为(’B’),并且所有和其相邻的未挖出方块都应该被递归地揭露。
- 如果一个至少与一个地雷相邻的空方块(’E’)被挖出,修改它为数字(’1’到’8’),表示相邻地雷的数量。
- 如果在此次点击中,若无更多方块可被揭露,则返回面板。
模拟
- 当前点击的是「未挖出的地雷」,我们将其值改为 X 即可。
- 当前点击的是「未挖出的空方块」,我们需要统计它周围相邻的方块里地雷的数量 cnt(即 M 的数量)。如果 cnt 为零,即执行规则 22,此时需要将其改为 B,且递归地处理周围的八个未挖出的方块,递归终止条件即为规则 44,没有更多方块可被揭露的时候。否则执行规则 33,将其修改为数字即可。
实现
var dirX = []int{0, 1, 0, -1, 1, 1, -1, -1} var dirY = []int{1, 0, -1, 0, 1, -1, 1, -1} func updateBoard(board [][]byte, click []int) [][]byte { x, y := click[0], click[1] if board[x][y] == 'M' { board[x][y] = 'X' } else { dfs(board, x, y) } return board } func dfs(board [][]byte, x, y int) { cnt := 0 for i := 0; i < 8; i++ { tx, ty := x + dirX[i], y + dirY[i] if tx < 0 || tx >= len(board) || ty < 0 || ty >= len(board[0]) { continue } // 不用判断 M,因为如果有 M 的话游戏已经结束了 if board[tx][ty] == 'M' { cnt++ } } if cnt > 0 { board[x][y] = byte(cnt + '0') } else { board[x][y] = 'B' for i := 0; i < 8; i++ { tx, ty := x + dirX[i], y + dirY[i] // 这里不需要在存在 B 的时候继续扩展,因为 B 之前被点击的时候已经被扩展过了 if tx < 0 || tx >= len(board) || ty < 0 || ty >= len(board[0]) || board[tx][ty] != 'E' { continue } dfs(board, tx, ty) } } }
hash表
链表
其实链表也是一种基本的数据结构,因为在计算机中只有两种存储方式,所以这两种数据可以说是数据结构的基本单位,可以实现很多的复杂的数据结构,比如队列,栈,树,图等,其实大多数都是使用链表来实现的。
单链表
1、头节点和头指针
头结点:
头结点是加在单链表之前附设的一个头结点。
头结点的数据域一般不存储任何信息,也可以存放一些关于线性表的长度的附加信息。
头结点的指针域存放指向第一个结点的指针(即第一个结点的存储位置)。
头结点不一定是链表的必要元素。
头指针:
头指针是指链表指向第一个结点的指针,若链表有头结点,则是指向头结点的指针。
头指针具有标识作用,所以常用头指针冠以链表的名字(指针变量的名字)。
无论链表是否为空,头指针均不为空。
头指针是链表的必要元素。
单链表中最后一个结点的指针域为空(NULL)。
2、代码
//数据
type Object interface{}
//节点
type Node struct {
data Object
next *Node
}
//初始化一个链表就是新建一个头节点,链表的主要操作还是增删改查。
var head Node = Node{Data: nil, next: nil}
//我们还可以建立一个链表的结构体来实现
type List struct{
mutex *sync.RWMutex
Size uint
Head *Node
Tail *Node
}
//初始化就是
func (list *List) Init() {
(*list).size = 0 // 此时链表是空的
(*list).head = nil // 没有车头
(*list).tail = nil // 没有车尾
}
3、经典应用
两数相加(两个数用链表表示,按位相加,主要是超过十进制各种情况的考虑)
/** * Definition for singly-linked list. * type ListNode struct { * Val int * Next *ListNode * } */ func addTwoNumbers(l1 *ListNode, l2 *ListNode) *ListNode { l := &ListNode{} head := l var up = 0 for l1 != nil && l2 != nil { tmp := new(ListNode) tmp.Val = (l1.Val +l2.Val + up) % 10 up = (l1.Val +l2.Val + up) / 10 l.Next = tmp l = l.Next l1 = l1.Next l2 = l2.Next } for l1 != nil { tmp := new(ListNode) tmp.Val = (l1.Val + up) % 10 up = (l1.Val + up) / 10 l.Next = tmp l = l.Next l1 = l1.Next } for l2 != nil { tmp := new(ListNode) tmp.Val = (l2.Val + up) % 10 up = (l2.Val + up) / 10 l.Next = tmp l = l.Next l2 = l2.Next } if up != 0 { tmp := new(ListNode) tmp.Val = up l.Next = tmp } return head.Next }链表反转(新定义两个指针进行遍历改变真正的指向)
/** * Definition for singly-linked list. * type ListNode struct { * Val int * Next *ListNode * } */ func reverseList(head *ListNode) *ListNode { if head == nil { return nil } pre,cur := head,head.Next for cur != nil{ temp := cur.Next cur.Next = pre pre = cur cur = temp } return pre }链表部分反转(找到反转的位置,保留一个不反转的节点和反转的头节点,然后就是定义两个指针来反转,最后连接)
/** * Definition for singly-linked list. * type ListNode struct { * Val int * Next *ListNode * } */ func reverseBetween(head *ListNode, m int, n int) *ListNode { if head == nil { return head } dummy := &ListNode{Val: 0, Next: head} // 找到需要反转节点在链表中的索引 firstIndex, endIndex := m-1, n-1 // pre 指向需要反转节点的前一个节点 var pre *ListNode = dummy for i := 1; i <= m - 1; i++ { pre = pre.Next } // newHead 节点指向反转部分完成后的头节点 var newHead *ListNode // cur 指向反转部分完成前的下一个节点 cur := pre.Next for cur != nil && firstIndex <= endIndex { temp := cur.Next cur.Next = newHead newHead = cur cur = temp firstIndex++ } // 关键点在于 pre 节点的下一个节点是反转后的最后那个节点,需要与 cur 节点进行连接 // 然后 pre 节点与反转后的 newHead 节点进行连接 pre.Next.Next, pre.Next = cur, newHead return dummy.Next }寻找链表相交点(开两个指针分别遍历这两个链表,在第一次遍历到尾部的时候,指向另一个链表头部继续遍历,这样会抵消长度差。如果链表有相交,那么会在中途相等,返回相交节点;如果链表不相交,那么最后会 nil == nil,返回 nil;)
func getIntersectionNode(headA, headB *ListNode) *ListNode { curA,curB := headA,headB for curA != curB { if curA == nil { // 如果第一次遍历到链表尾部,就指向另一个链表的头部,继续遍历,这样会抵消长度差。如果没有相交,因为遍历长度相等,最后会是 nil == nil curA = headB } else { curA = curA.Next } if curB == nil { curB = headA } else { curB = curB.Next } } return curA }链表合并(遍历两个链表,将较小的数字插入到新链表中)
func mergeTwoLists(l1 *ListNode, l2 *ListNode) *ListNode { prehead := &ListNode{} result := prehead for l1 != nil && l2 != nil { if l1.Val < l2.Val { prehead.Next = l1 l1 = l1.Next }else{ prehead.Next = l2 l2 = l2.Next } prehead = prehead.Next } if l1 != nil { prehead.Next = l1 } if l2 != nil { prehead.Next = l2 } return result.Next }链表分区(双指针法,把大于x的值放入到一个链表中,小于x的值放到一个链表中,都是按着原来的顺序,然后把两张表相连接)
func partition(head *ListNode, x int) *ListNode { l1 := &ListNode{Val:0} l2 := &ListNode{Val:0} l1_pre := l1 l2_pre := l2 for head != nil { if head.Val < x { l1.Next = &ListNode{Val: head.Val} l1 = l1.Next } else { l2.Next = &ListNode{Val: head.Val} l2 = l2.Next } head = head.Next } l1_pre = l1_pre.Next l2_pre = l2_pre.Next if l1_pre == nil { return l2_pre } result := l1_pre for l1_pre.Next != nil { l1_pre = l1_pre.Next } l1_pre.Next = l2_pre return result }复杂链表的复制(深度拷贝)
浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存。但深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象。
先复制节点,在重新变量找到random的节点
/** * Definition for a Node. * type Node struct { * Val int * Next *Node * Random *Node * } */ func copyRandomList(head *Node) *Node { if head == nil { return nil } newHead := Node{ Val: head.Val, Next: nil, Random: nil, } p := head.Next pre := &newHead for p != nil { newNode := &Node{ Val: p.Val, Next: nil, Random: nil, } pre.Next = newNode p = p.Next pre = pre.Next } p = head newP := &newHead for p != nil { if p.Random != nil { step := findStep(head, p.Random) newP.Random = target(&newHead, step) } p = p.Next newP = newP.Next } return &newHead } //确定从头结点到目标节点所经过的节点数 func findStep(head, target *Node) int { p := head step := 0 for p != target { p = p.Next step++ } return step } //返回从头结点开始,走step步所到达的节点 func target(head *Node, step int) *Node { p := head for step > 0 { p = p.Next step-- } return p }在第一种方法的基础上,通过将老节点和新节点相互对应的关系保存在map中,来找到random的节点
/** * Definition for a Node. * type Node struct { * Val int * Next *Node * Random *Node * } */ func copyRandomList(head *Node) *Node { if head == nil { return nil } newHead := Node{ Val: head.Val, Next: nil, Random: nil, } p := head.Next pre := &newHead connection := make(map[*Node]*Node) connection[head] = pre for p != nil { newNode := &Node{ Val: p.Val, Next: nil, Random: nil, } pre.Next = newNode connection[p] = newNode p = p.Next pre = pre.Next } p = head newP := &newHead for p != nil { if p.Random != nil { newP.Random = connection[p.Random] } p = p.Next newP = newP.Next } return &newHead }
双向链表
在单链表的每个结点中,再设置一个指向其前驱结点的指针域。所以在双向链表中的结点都有两个指针域,一个指向直接后继,另一个指向直接前驱。
1、代码表示
// 节点数据
type DoubleObject interface{}
// 双链表节点
type DoubleNode struct {
Data DoubleObject
Prev *DoubleNode
Next *DoubleNode
}
//初始化依然是建立一个head节点
var head Node = Node{Data: nil, Prev: nil,Next: nil,}
// 双链表
type DoubleList struct{
mutex *sync.RWMutex
Size uint
Head *DoubleNode
Tail *DoubleNode
}
//初始化和单链表也是一致的
2、经典应用
二叉搜索树转换双向循环链表,主要是下面三块
- 构建二叉搜索树
- 中序遍历
中序遍历二叉搜索树是从小到大的循序,在每个节点的改变指针的指向,左指针表示双链表向前指,右指针表示双链表向后指
package main import "fmt" //将BST转化为双向循环链表,不允许新建节点 //为防止歧义,左指针表示双链表向前指,右指针表示双链表向后指 type TreeNode struct { Val int Left *TreeNode Right *TreeNode } var pre *TreeNode //必须在全局变量上才可以实现 //其实就是中序遍历 func treeToDoublyList(root *TreeNode) *TreeNode { if root == nil { return root } helper(root) //处理首位指针 head, tail := root, root for head.Left != nil { head = head.Left } for tail.Right != nil { tail = tail.Right } head.Left = tail tail.Right = head return head } //中序遍历 func helper(root *TreeNode) { if root == nil { return } helper(root.Left) //改变指针 if pre != nil { root.Left = pre pre.Right = root } //获取当前节点 pre = root helper(root.Right) } func main() { root := &TreeNode{4, nil, nil} node1 := &TreeNode{2, nil, nil} node2 := &TreeNode{5, nil, nil} node3 := &TreeNode{1, nil, nil} node4 := &TreeNode{3, nil, nil} root.Left = node1 root.Right = node2 node1.Left = node3 node1.Right = node4 //上面是比较直观的,我们也可以使用二叉搜索树的特性来构建一颗二叉搜索树,具体可以看二叉搜索树。 head := treeToDoublyList(root) tail := head.Left //从头开始遍历 for i := 0; i <= 9; i++ { fmt.Printf("%d\t", head.Val) head = head.Right } //从尾开始遍历 for i := 0; i <= 9; i++ { fmt.Printf("%d\t", tail.Val) tail = tail.Left } }
3、标准库list的实现
就是定义好了如上的结构体,实现了双向链表,写好了增删改查的api,就是标准库的实现。
静态链表
静态链表就是不使用指针,而使用下标来实现单链表。
用数组描述的链表叫做静态链表。C语言中,让数组的元素都是由两个数据域组成,data和cur。数组的每个下标都对应着一个data和一个cur。数据域data,用来存放数据元素,也就是要处理的数据;而cur相当于单链表中的next指针,存放该元素的后继在数据中的下标,把cur叫游标。另外,数组的第一个和最后一个元素作为特殊元素处理,不存数据。数组的第一个元素,即下标为0的元素的cur存放备用链表(未被使用的数组元素)第一个结点的下标,而数组的最后一个元素的cur则存放第一个有数值的元素的下标,相当于单链表中的头结点的作用。
在高级语言的今天,基本上不实用了。
代码
//静态链表节点
type Node struct{
data string
cursor int
}
基本不实用了,了解一下就好
循环链表
将单链表中终端结点的指针端由空指针改为指向头结点,就是整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表。
循环链表和单链表的主要差异就在于循环的判断条件上,原来是判断p->next是否为空,现在则是判断p->nex不等于头结点,则循环未结束。不在需要head节点
为了用O(1)的时间由链表指针访问到最后一个结点,可以采用这样的方法:不使用头指针(head),而是用指向终端结点的尾指针来表示循环链表,此时查找开始结点和终端结点都很方便了。即终端结点用尾指针rear指示,而头结点就是rear->next,开始结点就是rear->next->next。
双向链表也可以有循环链表,即对于某一结点p,它的后继的前驱是它自己,它的前驱的后继还是它自己:p->next->prior = p = p->prior->next。
1、代码实现
其实循环链表的的单还是双的结构体都是正常的一样的,只不过最后操作的时候需要形成一个循环,就是指向头指针,至于初始化,可以指向自己,可以不指向自己。
单链
//数据
type Object interface{}
//节点
type CNode struct {
data Object
next *CNode
}
//正常初始化
var head CNode = Node{Data: nil, next: nil}
//定一个结构体,这种属于正常使用,会带链表的大小
type CList struct {
size uint64 // 车厢数量
head *CNode // 车头
}
//初始化
func (cList *CList) Init() {
lst := *cList
lst.size = 0 // 没车厢
lst.head = nil // 没车头
}
双链
//结点
type Node struct {
Data ElemType
Pre *Node
Next *Node
}
//链表
type List struct {
First *Node
Last *Node
Size int
}
//工厂函数
func CreateList() *List {
s := new(Node)
s.Next, s.Pre = s, s
return &List{s, s, 0}
}
2、经典应用
判断链表中是否有环
map(key重复说明有环)
func hasCycle(head *ListNode) bool { // hash表 hash := make(map[*ListNode]int) // 开一个哈希表记录该节点是否已经遍历过,值记录节点索引 for head != nil { if _,ok := hash[head]; ok { // 该节点遍历过,形成了环 return true } hash[head] = head.Val // 记录该节点已经遍历过 head = head.Next } return false }快慢指针一(快指针一次走两步,慢指针一次走一步,如果链表有环,那么两个指针始终会相遇。)
func hasCycle(head *ListNode) bool { // 快慢指针。假如爱有天意,那么快慢指针终会相遇 if head == nil { return false } fastHead := head.Next // 快指针,每次走两步 for fastHead != nil && head != nil && fastHead.Next != nil { if fastHead == head { // 快慢指针相遇,表示有环 return true } fastHead = fastHead.Next.Next head = head.Next // 慢指针,每次走一步 } return false }快慢指针二(两个指针,一个一步步遍历,一个每次重头开始遍历,出现步数不一样的时候就存在环。)
/** * Definition for singly-linked list. * type ListNode struct { * Val int * Next *ListNode * } */ func hasCycle(head *ListNode) bool { quick,slow := head,head n,m := 0,0 for { if quick == nil { return false } if quick.Next != nil { quick = quick.Next n++ }else{ return false } for{ if slow.Val == quick.Val{ if m==n { slow = head m = 0 break }else{ return true } }else{ slow = slow.Next m++ } } } }
3、ring库的实现
就是一个双向循环链表的实现,封装了很多的API,就是标准库的实现。
栈
栈是数据按照后进先出 LIFO(Last-In-First-Out) 原则组成的集合。添加和移除元素都是在栈顶进行,类比书堆,不能在栈底增删元素。
其实栈就是一种特殊的线性表,只不过遵守着特殊的规则,可以使用数组和链表来实现。
链表实现方式
在golang中有标准库list,所以可以省去了链表的定义和创建模块。
1、代码
//栈
type Stack struct {
list *list.List
lock *sync.RWMutex
}
//初始化
func NewStack() *Stack {
list := list.New()
l := &sync.RWMutex{}
return &Stack{list, l}
}
2、实例
package main
import (
"container/list"
"sync"
)
type Stack struct {
list *list.List
lock *sync.RWMutex
}
func NewStack() *Stack {
list := list.New()
l := &sync.RWMutex{}
return &Stack{list, l}
}
func (stack *Stack) Push(value interface{}) {
stack.lock.Lock()
defer stack.lock.Unlock()
stack.list.PushBack(value)
}
func (stack *Stack) Pop() interface{} {
stack.lock.Lock()
defer stack.lock.Unlock()
e := stack.list.Back()
if e != nil {
stack.list.Remove(e)
return e.Value
}
return nil
}
func (stack *Stack) Peak() interface{} {
e := stack.list.Back()
if e != nil {
return e.Value
}
return nil
}
func (stack *Stack) Len() int {
return stack.list.Len()
}
func (stack *Stack) Empty() bool {
return stack.list.Len() == 0
}
实例简化
import "container/list"
// 初始化
queue := list.New()
stack := list.New()
// 入队 入栈
queue.PushBack(123)
stack.PushBack(123)
// 出队 出栈 返回的数据是结构类型 Value 需要断言成相应的类型
num1 = queue.Front()
queue.Remove(num1)
num2 = queue.Back()
stack.Remove(num2)
3、正常编码使用中,我都会直接用list来生产对应的栈和队列,其实list的实现也是上面我们使用的链表,所以我们可以使用链表原生实现。
package main
import (
"sync"
)
type (
Stack struct {
top *node
length int
lock *sync.RWMutex
}
node struct {
value interface{}
prev *node
}
)
// Create a new stack
func NewStack() *Stack {
return &Stack{nil, 0, &sync.RWMutex{}}
}
// Return the number of items in the stack
func (this *Stack) Len() int {
return this.length
}
// View the top item on the stack
func (this *Stack) Peek() interface{} {
if this.length == 0 {
return nil
}
return this.top.value
}
// Pop the top item of the stack and return it
func (this *Stack) Pop() interface{} {
this.lock.Lock()
defer this.lock.Unlock()
if this.length == 0 {
return nil
}
n := this.top
this.top = n.prev
this.length--
return n.value
}
// Push a value onto the top of the stack
func (this *Stack) Push(value interface{}) {
this.lock.Lock()
defer this.lock.Unlock()
n := &node{value, this.top}
this.top = n
this.length++
}
数组实现方式
在实际项目中不要这么使用,这么做会带来内存泄漏的风险。那么这个场景用来干啥呢,刷刷 leetcode 题还是蛮方便的。一般来说会用链表来实现队列和栈,当然 golang 内置的 container/list 库提供了双向链表的数据结构。我们用这个也是很方便的。
1、代码
type ItemStack struct {
items []Item
lock sync.RWMutex
}
// New creates a new ItemStack
func NewStack() *ItemStack {
s := &ItemStack{}
s.items = []Item{}
return s
}
2、实例
package stack
import (
"github.com/cheekybits/genny/generic"
"sync"
)
type Item generic.Type
type ItemStack struct {
items []Item
lock sync.RWMutex
}
// 创建栈
func (s *ItemStack) New() *ItemStack {
s.items = []Item{}
return s
}
// 入栈
func (s *ItemStack) Push(t Item) {
s.lock.Lock()
s.items = append(s.items, t)
s.lock.Unlock()
}
// 出栈
func (s *ItemStack) Pop() *Item {
s.lock.Lock()
item := s.items[len(s.items)-1]
s.items = s.items[:len(s.items)-1 ]
s.lock.Unlock()
return &item
}
3、经典应用
用队列实现栈
栈和队列都是用list实现的,本身提供了这些功能,就简单了,这个主要是一个思想,满足队列的特性,需要将最上面的值放到队头,栈实现队列也是一个原理,将队头放在栈顶。
import "container/list" type stack struct{ *list.List } func Init()stack{ return stack{list.New()} } func(s *stack)peek() int{ if s.Len() == 0 { return -1 } return s.Back().Value.(int) } func(s *stack)push(x int){ s.PushBack(x) } func(s *stack)pop()int { if s.Len() == 0 { return -1 } v := s.Back() s.Remove(v) return v.Value.(int) }栈是否是合法的出栈顺序
模拟入栈出栈,按序列匹配出栈,看是否能得到这个序列,可以用list库,但是没有ide的时候可能使用slice更加好写一点。
import "container/list" type stack struct{ *list.List } func Init()stack{ return stack{list.New()} } func(s *stack)peek() int{ if s.Len() == 0 { return -1 } return s.Back().Value.(int) } func(s *stack)push(x int){ s.PushBack(x) } func(s *stack)pop()int { if s.Len() == 0 { return -1 } v := s.Back() s.Remove(v) return v.Value.(int) } func validateStackSequences(pushed []int, popped []int) bool { lpush := len(pushed) lpop := len(popped) if lpush == 0 { if lpop == 0 { return true } return false } stack := Init() var index = 0 for i:=0;i<lpush;i++{ stack.push(pushed[i]) for stack.peek() == popped[index] { stack.pop() index++ if index == lpop { return true } } } return false }获取最小值
单独用一个栈来存储这个最小值,必须要是栈,因为在弹出的时候,可能弹出最小值,需要知道下一个最小值。
type MinStack struct { stack []int minstack []int } /** initialize your data structure here. */ func Constructor() MinStack { return MinStack{stack: make([]int, 0), minstack: make([]int, 0)} } func (this *MinStack) Push(x int) { this.stack = append(this.stack, x) if len(this.stack) == 1 { this.minstack = append(this.minstack, x) } else { if this.minstack[len(this.minstack)-1] >= x { this.minstack = append(this.minstack, x) } } } func (this *MinStack) Pop() { if len(this.stack) == 0 { return } if this.stack[len(this.stack)-1] == this.minstack[len(this.minstack)-1] { this.minstack = this.minstack[:len(this.minstack)-1] } this.stack = this.stack[:len(this.stack)-1] } func (this *MinStack) Top() int { return this.stack[len(this.stack)-1] } func (this *MinStack) GetMin() int { return this.minstack[len(this.minstack)-1] } /** * Your MinStack object will be instantiated and called as such: * obj := Constructor(); * obj.Push(x); * obj.Pop(); * param_3 := obj.Top(); * param_4 := obj.GetMin(); */计算器
中缀表达式转后缀表达式计算,转换有规则,计算有规则,详解看附录-计算器。
队列
队列是数据按照先进先出 FIFO(First-In-First-Out) 原则组成的集合,类比排队,在队列任一端添加元素,从对应的另一端删除元素。
其实队列也是一种特殊的线性表,数据结构和栈是一样的,只不过遵守着不同的特殊的规则,可以使用数组和链表来实现。
链表实现方式
这个也可以直接使用标准库的list来实现,减去了链表的定义和创建
1、代码
// Queue 队列信息
type Queue struct{
list *list.List
lock *sync.RWMutex
}
// Init 队列初始化
func (q *Queue)Init() {
list := list.New()
l := &sync.RWMutex{}
return &Queue{list, l}
}
数组实现方式
1、代码
type ItemQueue struct {
items []Item
lock sync.RWMutex
}
2、实例
package queue
import (
"github.com/cheekybits/genny/generic"
"sync"
)
type Item generic.Type
type ItemQueue struct {
items []Item
lock sync.RWMutex
}
// 创建队列
func (q *ItemQueue) New() *ItemQueue {
q.items = []Item{}
return q
}
// 如队列
func (q *ItemQueue) Enqueue(t Item) {
q.lock.Lock()
q.items = append(q.items, t)
q.lock.Unlock()
}
// 出队列
func (q *ItemQueue) Dequeue() *Item {
q.lock.Lock()
item := q.items[0]
q.items = q.items[1:len(q.items)]
q.lock.Unlock()
return &item
}
// 获取队列的第一个元素,不移除
func (q *ItemQueue) Front() *Item {
q.lock.Lock()
item := q.items[0]
q.lock.Unlock()
return &item
}
// 判空
func (q *ItemQueue) IsEmpty() bool {
return len(q.items) == 0
}
// 获取队列的长度
func (q *ItemQueue) Size() int {
return len(q.items)
}
3、channel的实现
我们一般都不需要自己去创建队列了,大部分都是使用封装好的通信机制channel
channel是使用循环链表做缓存,中间有两个队列,分别是接受和发送,满了就会阻塞,我们可以看原生实现。
4、经典应用
用栈实现队列,和用队列实现栈是一个思想
type MyQueue struct { *list.List } /** Initialize your data structure here. */ func Constructor() MyQueue { return MyQueue{list.New()} } /** Push element x to the back of queue. */ func (this *MyQueue) Push(x int) { this.PushBack(x) } /** Removes the element from in front of queue and returns that element. */ func (this *MyQueue) Pop() int { if this.Len() == 0 { return -1 } v := this.Front() this.Remove(v) return v.Value.(int) } /** Get the front element. */ func (this *MyQueue) Peek() int { if this.Len() == 0 { return -1 } return this.Front().Value.(int) } /** Returns whether the queue is empty. */ func (this *MyQueue) Empty() bool { return this.Len() == 0 } /** * Your MyQueue object will be instantiated and called as such: * obj := Constructor(); * obj.Push(x); * param_2 := obj.Pop(); * param_3 := obj.Peek(); * param_4 := obj.Empty(); */
循环队列
循环队列其实也就是循环表,只不过我们有这么一个概念,了解一下。
1、代码
数组
结构定义
type MyCircularQueue struct { arr []int front int rear int maxCap int }- 队空的判断条件是this.front == this.rear,队满的判断条件是(this.rear+1)%this.maxCap == this.front,通过%cap来完成rear循环的
- 队满时,tail指向的位置上没有存储数据,会浪费一个空间,所以arr的大小为k+1
完整实例
type MyCircularQueue struct { arr []int front int rear int maxCap int } /** Initialize your data structure here. Set the size of the queue to be k. */ func Constructor(k int) MyCircularQueue { return MyCircularQueue{ arr: make([]int, k+1), front: 0, rear: -1, maxCap: k+1, } } /** Insert an element into the circular queue. Return true if the operation is successful. */ func (this *MyCircularQueue) EnQueue(value int) bool { if this.IsFull() { return false } this.rear = (this.rear + 1) % this.maxCap this.arr[this.rear] = value return true } /** Delete an element from the circular queue. Return true if the operation is successful. */ func (this *MyCircularQueue) DeQueue() bool { if this.IsEmpty() { return false } this.front = (this.front + 1) % this.maxCap return true } /** Get the front item from the queue. */ func (this *MyCircularQueue) Front() int { if this.IsEmpty() { return -1 } return this.arr[this.front] } /** Get the last item from the queue. */ func (this *MyCircularQueue) Rear() int { if this.IsEmpty() { return -1 } return this.arr[this.rear] } /** Checks whether the circular queue is empty or not. */ func (this *MyCircularQueue) IsEmpty() bool { return this.front-1 == this.rear } /** Checks whether the circular queue is full or not. */ func (this *MyCircularQueue) IsFull() bool { return (this.rear+2)%this.maxCap == this.front } /** * Your MyCircularQueue object will be instantiated and called as such: * obj := Constructor(k); * param_1 := obj.EnQueue(value); * param_2 := obj.DeQueue(); * param_3 := obj.Front(); * param_4 := obj.Rear(); * param_5 := obj.IsEmpty(); * param_6 := obj.IsFull(); */链表
结构其实就是循环链表
type queueNode struct { val int next *queueNode } type MyCircularQueue struct { header *queueNode tail *queueNode len int capacity int }完整实例
type queueNode struct { val int next *queueNode } type MyCircularQueue struct { header *queueNode tail *queueNode len int capacity int } /** Initialize your data structure here. Set the size of the queue to be k. */ func Constructor(k int) MyCircularQueue { return MyCircularQueue{ header: nil, tail: nil, len: 0, capacity: k, } } /** Insert an element into the circular queue. Return true if the operation is successful. */ func (this *MyCircularQueue) EnQueue(value int) bool { if this.len >= this.capacity { return false } if this.len == 0 { this.header = &queueNode{ val: value, next: nil, } this.tail = this.header } else { this.tail.next = &queueNode{ val: value, next: nil, } this.tail=this.tail.next } this.len++ return true } /** Delete an element from the circular queue. Return true if the operation is successful. */ func (this *MyCircularQueue) DeQueue() bool { if this.len == 0 { return false } this.header = this.header.next this.len-- return true } /** Get the front item from the queue. */ func (this *MyCircularQueue) Front() int { if this.len == 0 { return -1 } return this.header.val } /** Get the last item from the queue. */ func (this *MyCircularQueue) Rear() int { if this.len == 0 { return -1 } return this.tail.val } /** Checks whether the circular queue is empty or not. */ func (this *MyCircularQueue) IsEmpty() bool { if this.len == 0 { return true } return false } /** Checks whether the circular queue is full or not. */ func (this *MyCircularQueue) IsFull() bool { if this.len == this.capacity { return true } return false } /** * Your MyCircularQueue object will be instantiated and called as such: * obj := Constructor(k); * param_1 := obj.EnQueue(value); * param_2 := obj.DeQueue(); * param_3 := obj.Front(); * param_4 := obj.Rear(); * param_5 := obj.IsEmpty(); * param_6 := obj.IsFull(); */
2、经典应用
3、channel的实现
channel带缓存的其实也是一个循环队列。
字符串
字符串其实就是[]string,字符串在这边单独列出来,主要是使用上比较广泛,比较经典的就是字符串匹配问题。
BF算法
就是我们的暴力匹配方法,循环遍历,也是我们的常规思维,第一个匹配上再匹配第二个,匹配不上在向后移动
func IndexFind(s, sep string) int {
for i := 0; i < len(s); i++ {
if s[i] == sep[0] {
is := true
j := 0
for ; j < len(sep); j++ {
if sep[j] != s[i+j] {
is = false
break
}
}
if is {
return i
}
}
}
return -1
}
KMP算法
就是减少回溯,在我们匹配不上的时候知道下一步去哪边匹配,而不是一步一步的去匹配,主要是如何移位的问题,要么全移动,要么移动匹配位
KMP算法的主要原理如下:
s为目标文本, 长度为m
p为搜索词,长度为n
假设p[i]与s[x]匹配失败,那么p[i-1]与s[x-1]是匹配成功的, 则试图找到一个索引 j, 使得p[0:j]=p[i-j-1:i-1]其中p[0:j] 包含p[j],其实就是构建前缀数组(其实就是已经匹配过的字符串p[:i])每一个位置的字符串的前缀和后缀公共部分的最大长度,不包括字符串本身,否则最大长度始终是字符串本身)
如果有则s[x]继续与p[j+1]进行比较, 相当于搜索词移动i-j-1位(移动位置=已匹配的字符数 - 对应的部分匹配值)
无则s[x]与p[0]比较. (具体代码实现时无可以表示为-1, 这样+1 后正好为0) 相当于搜索词移动i位
func findIdx(dst string) int{
str := dst[0:len(dst)-1] #输入ABCD,我们看的是D前面的元素,所以去掉最后一个字符,然后分隔字符串判断是否相等
if len(str) == 0 {
return -1
}
if len(str) == 1 {
return 0
}
cn := 0
for i:=len(str)/2;i>0;i--{
if str[0:i] == str[len(str)-i:] {
cn = i #因为是从中间开始向两边移动,所以第一个相等的字符串长度最长
break
}
}
return cn
}
func search(src,dst string,next []int) int{
var s_idx,d_idx,idx int
for ;s_idx<=len(src)&&d_idx < len(dst);{
if d_idx == -1|| src[s_idx] == dst[d_idx] {
s_idx++
d_idx++
}else{
d_idx = next[d_idx]
}
}
if d_idx == len(dst) {
idx = s_idx - d_idx
}else{
idx = -1
}
return idx
}
func main(){
src := "BBC ABCDAB ABCDABCDABDE"
dst := "ABCDABD"
var next []int
for i:=1;i<=len(dst);i++ {
next = append(next,findIdx(dst[0:i]))
}
fmt.Println(next)
fmt.Println(search(src,dst,next))
}
Rabin-Karp算法
假设匹配文本的长度为M,目标文本的长度为N
- 计算匹配文本的hash值
- 计算目标字符串中每个长度为M的子串的hash值(需要计算N-M+1次)
- 比较hash值, 如果hash值不同,字符串必然不匹配,如果hash值相同,还需要使用朴素算法(BF)再次判断
还有一些其他的算法,可以了解一下。
- BM:BM算法,基于好后缀和坏字符规则(重后向前匹配,匹配到一个字符不匹配,查看匹配的字符串中根本没有这个字符,就可以直接移到这个字符的下一位进行匹配,如果有就移到对应的匹配位)
- Horspool:基于坏字符规则的算法,BM的简化版
- Sunday:基于坏字符规则的算法,Horspool的进化版
经典应用
最长不重复字符串
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。滑动窗口在左边发现这个最新字符时,就将左边移动到这个index继续遍历,并且比较这个重复的字符串的长度,获取最大的不重复字符串。
func lengthOfLongestSubstring(s string) int { if len(s) == 1 { return 1 } var j = 0 var maxLength = 0 for i:=1;i<len(s);i++{ index := strings.Index(s[j:i],string(s[i])) if index == -1 { if i-j +1 > maxLength{ maxLength = i-j +1 } }else{ j = j+index+1 if i-j +1 > maxLength{ maxLength = i-j +1 } } } return maxLength }
string库的实现
string的contain函数使用了rk算法。string查找使用了BF和RK算法,根据长度shortStringLen来决定使用什么算法,shortStringLen 大小根据机器来决定
var shortStringLen int
func init() {
if cpu.X86.HasAVX2 {
shortStringLen = 63
} else {
shortStringLen = 31
}
}
rk算法在hash的时候使用了E进制,还有这个数16777619
非线型数据结构
树状数据结构
树
它是由n(n>0)个有限节点组成一个具有层次关系的集合。
- 每个节点有零个或多个子节点;
- 没有父节点的节点称为根节点;
- 每一个非根节点有且只有一个父节点;
- 除了根节点外,每个子节点可以分为多个不相交的子树;
二叉树
每个节点最多含有两个子树的树称为二叉树。
1、代码表示
//节点
type Node struct {
Val int
Left *Node
Right *Node
}
//初始化
var root tree.Node
root = tree.Node{Value: 3}
root.Left = &tree.Node{}
root.Right = &tree.Node{5, nil, nil}
root.Right.Left = new(tree.Node)
root.Left.Right = tree.CreateNode(2)
root.Right.Left.SetValue(4)
2、遍历
深度优先遍历(DFS):(Depth-First-Search)它沿着树的深度遍历树的节点,尽可能深的搜索树的分支。
前序–根左右
/** * Definition for a binary tree node. * type TreeNode struct { * Val int * Left *TreeNode * Right *TreeNode * } */ var result []int func preorderTraversal(root *TreeNode) []int { result = []int{} dfs(root) return result } func dfs(root *TreeNode){ if root != nil { result = append(result,root.Val) dfs(root.Left) dfs(root.Right) } }中序–左根右
/** * Definition for a binary tree node. * type TreeNode struct { * Val int * Left *TreeNode * Right *TreeNode * } */ var result []int func inorderTraversal(root *TreeNode) []int { result = []int{} dfs(root) return result } func dfs(root *TreeNode){ if root != nil { dfs(root.Left) result = append(result,root.Val) dfs(root.Right) } }后序–左右根
/** * Definition for a binary tree node. * type TreeNode struct { * Val int * Left *TreeNode * Right *TreeNode * } */ var result []int func postorderTraversal(root *TreeNode) []int { result = []int{} dfs(root) return result } func dfs(root *TreeNode){ if root != nil { dfs(root.Left) dfs(root.Right) result = append(result,root.Val) } }
其实在矩阵中也是可以使用DFS,比如
var ( dx = []int{1, 0, 0, -1} dy = []int{0, 1, -1, 0} ) func floodFill(image [][]int, sr int, sc int, newColor int) [][]int { currColor := image[sr][sc] if currColor != newColor { dfs(image, sr, sc, currColor, newColor) } return image } func dfs(image [][]int, x, y, color, newColor int) { if image[x][y] == color { image[x][y] = newColor for i := 0; i < 4; i++ { mx, my := x + dx[i], y + dy[i] if mx >= 0 && mx < len(image) && my >= 0 && my < len(image[0]) { dfs(image, mx, my, color, newColor) } } } }将指定格子颜色以及周围可连接到的最后的节点先换成新的颜色,然后回溯遍历过的一个个换成新的颜色,这既是DFS算法。所以深度优先搜索就是重发生点开始遍历,进行不断递归回溯。
广度优先遍历(BFS):BFS(Breadth-First-Search)是从根节点开始,沿着树(图)的宽度遍历树(图)的节点。
层序–按层,有两种方式
1、BFS,遍历当前层的所有子节点,放入队列中,先进先出来获取数组
func levelOrder(root *TreeNode) [][]int { var result [][]int if root == nil { return result } // 定义一个双向队列 queue := list.New() // 头部插入根节点 queue.PushFront(root) // 进行广度搜索 for queue.Len() > 0 { var current []int listLength := queue.Len() for i := 0; i < listLength; i++ { // 消耗尾部 // queue.Remove(queue.Back()).(*TreeNode):移除最后一个元素并将其转化为TreeNode类型 node := queue.Remove(queue.Back()).(*TreeNode) current = append(current, node.Val) if node.Left != nil { //插入头部 queue.PushFront(node.Left) } if node.Right != nil { queue.PushFront(node.Right) } } result = append(result, current) } return result }2、DFS,记录层数
func levelOrder(root *TreeNode) [][]int { return dfs(root, 0, [][]int{}) } func dfs(root *TreeNode, level int, res [][]int) [][]int { if root == nil { return res } if len(res) == level { res = append(res, []int{root.Val}) } else { res[level] = append(res[level], root.Val) } res = dfs(root.Left, level+1, res) res = dfs(root.Right, level+1, res) return res }
其实在矩阵中也是可以使用BFS,比如
var ( dx = []int{1, 0, 0, -1} dy = []int{0, 1, -1, 0} ) func floodFill(image [][]int, sr int, sc int, newColor int) [][]int { currColor := image[sr][sc] if currColor == newColor { return image } n, m := len(image), len(image[0]) queue := [][]int{} queue = append(queue, []int{sr, sc}) image[sr][sc] = newColor for i := 0; i < len(queue); i++ { cell := queue[i] for j := 0; j < 4; j++ { mx, my := cell[0] + dx[j], cell[1] + dy[j] if mx >= 0 && mx < n && my >= 0 && my < m && image[mx][my] == currColor { queue = append(queue, []int{mx, my}) image[mx][my] = newColor } } } return image }将指定格子颜色以及周围可连接到的节点先换成新的颜色,然后在遍历这些连接节点,依次重复这两个步骤,就是BFS算法。所以广度优先搜索就是重头开始,一层层进行搜索。
比如求二进制矩阵中的最短路径:在一个 N × N 的方形网格中,每个单元格有两种状态:空(0)或者阻塞(1),求一条从左上角到右下角、长度最短的畅通路径,就可以使用BFS算法。
首先定义方向矩阵,访问矩阵,最短路径矩阵,最短是最先被访问的,然后按方向去遍历,返回最短路径矩阵节点
(1)BFS的问题一般都会选用队列方式实现; (2)代码模板如下: void BFS() { 定义队列; 定义备忘录,用于记录已经访问的位置; 判断边界条件,是否能直接返回结果的。 将起始位置加入到队列中,同时更新备忘录。 while (队列不为空) { 获取当前队列中的元素个数。 for (元素个数) { 取出一个位置节点。 判断是否到达终点位置。 获取它对应的下一个所有的节点。 条件判断,过滤掉不符合条件的位置。 新位置重新加入队列。 } } }代码
func shortestPathBinaryMatrix(grid [][]int) int { dirs := [][]int{{-1, 0}, {-1, 1}, {0, 1}, {1, 1}, {1, 0}, {1, -1}, {0, -1}, {-1, -1}} R := len(grid) C := len(grid[0]) visited := make([][]bool, 0) // 是否遍历过 for range make([]int, R) { // 初始化空的 visited 二维数组 visited = append(visited, make([]bool, C)) } dis := make([][]int, 0) // 到每个顶点的最短路径长度 for range make([]int, R) { dis = append(dis, make([]int, C)) } if grid[0][0] == 1 { // 起始点阻塞 return -1 } if R == 1 && C == 1 { return 1 } //BFS var queue []int // 申请一个队列 queue = append(queue, 0) // 队列添加起始点0 visited[0][0] = true // 起始点已经遍历过了 dis[0][0] = 1 // 起始点记录 for len(queue) > 0 { // 只要队列不为空就继续执行循环 cur := queue[0] // 取出队首元素顶点 queue = queue[1:] // 移除队首元素顶点 curx, cury := cur/C, cur%C // 一维坐标转二维坐标 for d := 0; d < 8; d++ { // 查看顶点周围8个方向的相邻顶点 nextx := curx + dirs[d][0] // 周围8个方向坐标差值 nexty := cury + dirs[d][1] // 相邻顶点坐标(nextx, nexty) // 合法 && 没有被访问过 && 没有被阻塞 if inArea(nextx, nexty, R, C) && !visited[nextx][nexty] && grid[nextx][nexty] == 0 { queue = append(queue, nextx*C+nexty) // 二维坐标转一维坐标入队 visited[nextx][nexty] = true // 记录这个顶点已经被访问过 dis[nextx][nexty] = dis[curx][cury] + 1 // 到该顶点的路径是从cur顶点+1 if nextx == R-1 && nexty == C-1 { // 如果(nextx,nexty)是终点 return dis[nextx][nexty] // 返回到该顶点的距离 } } } } return -1 } func inArea(x, y, R, C int) bool { return x >= 0 && x < R && y >= 0 && y < C }其实是一种动态规划的思想。
3、实例
上面的方式一般都是一起实现的,可以直接重实例中看出来
package tree
import (
"fmt"
)
type TreeNode struct {
ID int
Val int
Left *TreeNode
Right *TreeNode
}
func PreOrder(root *TreeNode) {
if root != nil {
fmt.Printf("%d ", root.Val)
PreOrder(root.Left)
PreOrder(root.Right)
}
}
func InOrder(root *TreeNode) {
if root != nil {
InOrder(root.Left)
fmt.Printf("%d ", root.Val)
InOrder(root.Right)
}
}
func PostOrder(root *TreeNode) {
if root != nil {
PostOrder(root.Left)
PostOrder(root.Right)
fmt.Printf("%d ", root.Val)
}
}
package main
import (
"fmt"
"go_code/data_structure/tree"
)
func main() {
node7 := &tree.TreeNode{
ID: 7,
Val: 7,
Left: nil,
Right: nil,
}
node6 := &tree.TreeNode{
ID: 6,
Val: 6,
Left: nil,
Right: nil,
}
node5 := &tree.TreeNode{
ID: 5,
Val: 5,
Left: nil,
Right: nil,
}
node4 := &tree.TreeNode{
ID: 4,
Val: 4,
Left: nil,
Right: nil,
}
node3 := &tree.TreeNode{
ID: 3,
Val: 3,
Left: node6,
Right: node7,
}
node2 := &tree.TreeNode{
ID: 2,
Val: 2,
Left: node4,
Right: node5,
}
node1 := &tree.TreeNode{
ID: 1,
Val: 1,
Left: node2,
Right: node3,
}
fmt.Println("先序遍历")
tree.PreOrder(node1)
fmt.Println()
fmt.Println("中序遍历")
tree.InOrder(node1)
fmt.Println()
fmt.Println("后序遍历")
tree.PostOrder(node1)
}
4、经典应用
路径之和
DFS,一种是遍历到一条路径上的一个数字,就用sum减去这个数字,最后看剩余值和最后一个值是否相等,还有一种思路就是把每个路径的和加起来,最后进行对比,都需要用到DFS,都要用到递归
//减法 /** * Definition for a binary tree node. * type TreeNode struct { * Val int * Left *TreeNode * Right *TreeNode * } */ func hasPathSum(root *TreeNode, sum int) bool { if root == nil { return false } if root.Left == nil && root.Right == nil { return sum == root.Val } return hasPathSum(root.Left,sum - root.Val)||hasPathSum(root.Right,sum - root.Val) } //加法 func hasPathSum(root *TreeNode, sum int) bool { if root == nil { return false } queNode := []*TreeNode{} queVal := []int{} queNode = append(queNode, root) queVal = append(queVal, root.Val) for len(queNode) != 0 { now := queNode[0] queNode = queNode[1:] temp := queVal[0] queVal = queVal[1:] if now.Left == nil && now.Right == nil { if temp == sum { return true } continue } if now.Left != nil { queNode = append(queNode, now.Left) queVal = append(queVal, now.Left.Val + temp) } if now.Right != nil { queNode = append(queNode, now.Right) queVal = append(queVal, now.Right.Val + temp) } } return false }还有相对变化,比如求出具体路径等,就需要进行节点存储。
最近公共祖先
最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
如果pq同时位于左边,或者右边,则第一个找到的就是公共祖先,如果分别位于左右子数,那么他们的根就是公共祖先,对于子数依然成立
/** * Definition for TreeNode. * type TreeNode struct { * Val int * Left *ListNode * Right *ListNode * } */ func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode { if root == p || root == q || root == nil { return root } left := lowestCommonAncestor(root.Left,p,q) right := lowestCommonAncestor(root.Right,p,q) if left == nil { return right }else if right == nil { return left }else{ return root } }侧面观察二叉树
层序遍历求第一个或者最后一个节点
二叉树最下深度
求二叉树的深度使用深度优先搜索就可以,只要进行前序遍历,求出所有的深度,然后求出最小值就可以
/** * Definition for a binary tree node. * type TreeNode struct { * Val int * Left *TreeNode * Right *TreeNode * } */ func minDepth(root *TreeNode) int { if root == nil { return 0 } if root.Left == nil && root.Right == nil { return 1 } minD := math.MaxInt32 if root.Left != nil{ minD = min(minD,minDepth(root.Left)) } if root.Right != nil{ minD = min(minD,minDepth(root.Right)) } return minD + 1 } func min(x,y int)int { if x>y { return y } return x }二叉树反转
递归回溯,先交互节点,然后交换子树。
/** * Definition for a binary tree node. * type TreeNode struct { * Val int * Left *TreeNode * Right *TreeNode * } */ func invertTree(root *TreeNode) *TreeNode { if root == nil { return nil } left := invertTree(root.Left) right := invertTree(root.Right) root.Left = right root.Right = left return root }
5、完全二叉树和满二叉树
- 满二叉树—深度为K则结点个数2^k-1
- 完全二叉树—重根开始编号,层序可以按顺序的获取所有的值,完全二叉树可以说是为了堆而存在的
其实计算机中只有两种存储方式,一个顺序一个是链式,所以树是可以使用数组来存储的,当然这样会浪费很多的空间,所以一般都是使用链式来存储的,但是如果是完全二叉树,使用数组存储就比较好来,不浪费。
堆
最大堆:根结点的键值是所有堆结点键值中最大者,且每个结点的值都比其孩子的值大。
最小堆:根结点的键值是所有堆结点键值中最小者,且每个结点的值都比其孩子的值小。
构建最大堆,最小堆,也就是堆的初始化,首先重倒数第二层进行遍历,它的子节点2k+1,2k+2如果比根节点大,就进行交换,当然交换后如果子节点由树还是需要进行对比交换,直到满足堆的特性,由底想上,最后最大的就在顶上,
1、经典应用
寻找最大k个数
构建最大堆,获取根节点,然后再构建最大堆,正常是这种排序方式,当然针对这个题目,可以使用构建k大小的堆(当然这边用的是堆排序,也可以使用其他的排序方法来解决这个问题,但是在数据量比较大的时候堆排序比较快),这边是直接使用了golang的heap,如果想要自己实现堆,可以参考算法排序的堆排序中堆的构建。
func getLeastNumbers(arr []int, k int) []int { if k==0 || k>len(arr){ return []int{} } h := &intHeap{} heap.Init(h) for _,v:=range(arr){ if h.Len()<k{ heap.Push(h, v) }else{ if (*h)[0]>v{ heap.Pop(h) heap.Push(h, v) } } } res:=[]int{} for h.Len()>0{ res = append(res, heap.Pop(h).(int)) } return res } type intHeap []int func (h intHeap) Len() int { return len(h) } func (h intHeap) Less(i, j int) bool { return h[i] > h[j] } func (h intHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] } func (h *intHeap) Push(x interface{}) { // Push 使用 *h,是因为 // Push 增加了 h 的长度 *h = append(*h, x.(int)) } func (h *intHeap) Pop() interface{} { // Pop 使用 *h ,是因为 // Pop 减短了 h 的长度 res := (*h)[len(*h)-1] *h = (*h)[:len(*h)-1] return res }寻找中位数
构建一个最大堆一个最小堆
线索二叉树
就是在二叉树中有很多的节点是空的,我们是不是能把他利用起来,作为指向前驱后继,这样能完善树的不知道前驱的缺陷,很大程度的提高了查询的效率。但是这种只有在中序的情况才能进行线索化,主要是因为左根右的结构可以允许在相隔的节点上有空间进行操作。
结点结构中增加两个标志域LTag和RTag。LTag=0时,lchild域指示结点的左孩子,LTag=1时,lchild域指示结点的前驱;RTag=0时,rchild域指示结点的右孩子,RTag=1时,rchild域指示结点的后继。
这样定义的好处是既可以从第一个结点起顺后继进行遍历,也可以从最后一个结点起顺前驱进行遍历。便于查找。
1、代码
//二叉树的二叉线索存储表示
typedef BiThrNode struct{
TElemType data,
lchild,rchild BiThrNode, /* 左右孩子指针 */
LTag,RTag int; /* 左右标志 */定义
}
构建线索二叉树是对树进行中序遍历线索化的过程。
2、经典应用
二叉查找树
Binary Search Tree 「BST」
二叉查找树又称排序二叉树,二叉排序树,二叉搜索树,就是所有的左节点都小于根节点,所有的右节点都大于根节点,且左子树和右子树也同样为二叉搜索树。这样中序遍历就是一个有序数组,在用于查找的时候类似于二分查找,能够减少查询次数,快速的查到数据。
这个算法的查找效率很高,但是如果使用这种查找方法要首先创建树,确保树的左分支的值小于右分支的值,所有的右节点都大于根节点。
0、使用场景
会出现斜树这种极端场景,这个时候效率极差,所以使用不多
1、代码
构建二叉查找树
func NewTree(arr []int) *Tree{
// 先在内存中构造 二叉树
tree := new(Tree)
for i, v := range arr {
Insert(tree, v, i)
}
return tree
}
// 节点结构
type Node struct {
Value, Index int // 元素的值和在数组中的位置
Left, Right *Node
}
// 树结构
type Tree struct {
Root *Node
}
// 把数组的的元素插入树中
func Insert(tree *Tree, value, index int){
if nil == tree.Root {
tree.Root = newNode(value, index)
}else {
InsertNode(tree.Root, newNode(value, index))
}
}
// 把新增的节点插入树的对应位置
func InsertNode(root, childNode *Node) {
// 否则,先和根的值对比
if childNode.Value <= root.Value {
// 如果小于等于跟的值,则插入到左子树
if nil == root.Left {
root.Left = childNode
}else {
InsertNode(root.Left, childNode)
}
}else{
// 否则,插入到右子树
if nil == root.Right {
root.Right = childNode
}else {
InsertNode(root.Right, childNode)
}
}
}
func newNode(value, index int) *Node {
return &Node{
Value: value,
Index: index,
}
}
然后再用所查数据和每个节点的父节点比较大小,查找最适合的范围。依次比较,查找出对应的值。
func BSTsearch(tree *Tree, key int) int{
// 开始二叉树查找目标key
return searchKey(tree.Root, key)
}
// 在构建好的二叉树中,从root开始往下查找对应的key 返回其在数组中的位置
func searchKey(root *Node, key int) int {
if nil == root {
return -1
}
if key == root.Value {
return root.Index
}else if key < root.Value {
// 往左子树查找
return searchKey(root.Left, key)
}else {
// 往右子树查找
return searchKey(root.Right, key)
}
}
2、经典应用
- 上面用于查找,类似于二分查找的就是最经典的应用
合法二叉树
中序遍历看是否按有大到小的顺序
/** * Definition for a binary tree node. * type TreeNode struct { * Val int * Left *TreeNode * Right *TreeNode * } */ func isValidBST(root *TreeNode) bool { arr := []int{} midorder(root,&arr) for i:=1;i<len(arr);i++{ if arr[i] <= arr[i-1] { return false } } return true } func midorder(root *TreeNode,arr *[]int){ if root != nil { midorder(root.Left,arr) *arr = append(*arr,root.Val) midorder(root.Right,arr) } }修剪二叉搜索树
dfs中序遍历,如果小于最小值,则砍掉所有的左子树,如果大于最大值,则砍掉所有的右子树,如果在这个区间就赋值给原来的节点。
/** * Definition for a binary tree node. * type TreeNode struct { * Val int * Left *TreeNode * Right *TreeNode * } */ func trimBST(root *TreeNode, L int, R int) *TreeNode { if root != nil { if root.Val < L {//太小 修剪 ,包括左子树全部砍掉 return trimBST(root.Right,L,R) } if root.Val > R {//太大 修剪,包括右子树全部砍掉 return trimBST(root.Left,L,R) } root.Left = trimBST(root.Left,L,R)//没问题的修剪左子树 root.Right = trimBST(root.Right,L,R)//没问题的修剪右子树 } return root }
哈夫曼树(最优二叉树)
最优二叉树就是在权为wl,w2,…,wn的n个叶子所构成的所有二叉树中,带权路径长度最小(即代价最小)的二叉树称为最优二叉树或哈夫曼树。
树的带权路径长度:所有叶子结点的带权路径长度之和,记为WPL。这个小,反应的是查询的效率高。
最优二叉树主要在每个连接之间加一个权重,可以减少遍历的次数。从而提高查询的效率。
比如给定4个叶子结点a,b,c和d,分别带权7,5,2和4。构造如下图所示的三棵二叉树(还有许多棵),它们的带权路径长度分别为:
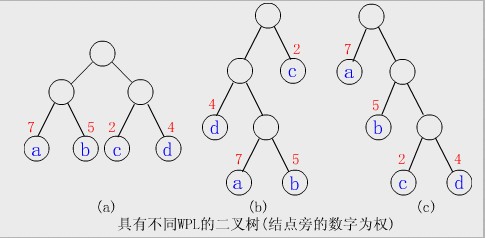
(a)WPL=7*2+5*2+2*2+4*2=36
(b)WPL=7*3+5*3+2*1+4*2=46
(c)WPL=7*1+5*2+2*3+4*3=35
其中©树的WPL最小,可以验证,它就是哈夫曼树。
构建哈夫曼树
先获取最小的两个点作为子节点,对应的和就是父节点,然后再取出最小的一个点和这个和进行比较,小就作为左节点和这个和最和一个新的树,反之则作为右节点,这样构造的出来的WPL最小,就是一个哈夫曼树,也是最优二叉树
1、代码
//节点
type BNode struct {
key string
value float64
ltree, rtree *BNode
}
这种树不存在初始化,和二叉查找树一样,是对已经有的节点进行构造哈夫曼树,构造规则,先获取最小的两个点作为子节点,对应的和就是父节点,然后再取出最小的一个点和这个和进行比较,小就作为左节点和这个和最和一个新的树,反之则作为右节点,这样构造的就是一个哈夫曼树,也是最优二叉树。
2、构造哈夫曼树
package main
import (
"fmt"
"errors"
"os"
)
type BNode struct {
key string
value float64
ltree, rtree *BNode
}
func getMinNodePos(treeList []*BNode) (pos int, err error) {
if len(treeList) == 0 {
return -1, errors.New("treeList length is 0")
}
pos = -1
for i, _ := range treeList {
if pos < 0 {
pos = i
continue
}
if treeList[pos].value > treeList[i].value {
pos = i
}
}
return pos, nil
}
func get2MinNodes(treeList []*BNode) (node1, node2 *BNode, newlist []*BNode) {
if len(treeList) < 2 {
}
pos, err := getMinNodePos(treeList)
if nil != err {
return nil, nil, treeList
}
node1 = treeList[pos]
newlist = append(treeList[:pos], treeList[pos + 1 :]...)
pos, err = getMinNodePos(newlist)
if nil != err {
return nil, nil, treeList
}
node2 = newlist[pos]
newlist = append(newlist[:pos], newlist[pos + 1 :]...)
return node1, node2, newlist
}
func makeHuffmanTree(treeList []*BNode) (tree *BNode, err error) {
if len(treeList) < 1 {
return nil, errors.New("Error : treeList length is 0")
}
if len(treeList) == 1 {
return treeList[0], nil
}
lnode, rnode, newlist := get2MinNodes(treeList)
newNode := new(BNode)
newNode.ltree = lnode
newNode.rtree = rnode
newNode.value = newNode.ltree.value + newNode.rtree.value
newNode.key = newNode.ltree.key + newNode.rtree.key;
newlist = append(newlist, newNode)
return makeHuffmanTree(newlist)
}
func main() {
keyList := []byte {'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'}
valueList := []float64 {0.12, 0.4, 0.29, 0.90, 0.1, 1.1, 1.23, 0.01}
treeList := []*BNode {}
for i, x := range keyList {
n := BNode{key:string(x), value:valueList[i]}
treeList = append(treeList, &n)
}
tree, err := makeHuffmanTree(treeList)
if nil != err {
fmt.Println(err.Error())
}
//TODO you can make it yourself
//showTree(tree)
}
构建来哈夫曼树,一般都是根据查询的次数来确定权重,权重大的肯定查询多,所以放在最上面,每次都能很快的查询到,虽然没有排序,但是根据数据预判,提高了查询的效率。
3、哈夫曼编码
哈夫曼编码是可变字长编码(VLC)的一种,Huffman于1952年提出的编码方法, 该方法完全依据字符出现概率来构造异字头的平均长度最短的码字, 有时称之为最佳编码,一般就叫做Huffman编码
哈夫曼树也是为了哈夫曼编码的构建的,主要目的是根据使用频率来最大化节省字符(编码)的存储空间。
比如有A,B,C,D,E五个字符,出现的频率(即权值)分别为5,4,3,2,1,那么我们需要构建一个哈夫曼树,左子树用0来表示,右子树用1来表示,然后对其进行编码,如下图
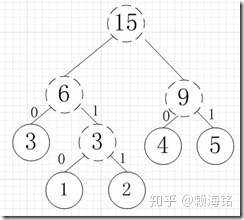
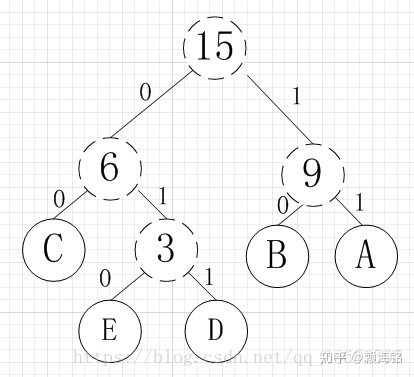
所以各字符对应的编码为:A->11,B->10,C->00,D->011,E->010
霍夫曼编码是一种无前缀编码。解码时不会混淆。其主要应用在数据压缩,加密解密等场合。
如果考虑到进一步节省存储空间,就应该将出现概率大(占比多)的字符用尽量少的0-1进行编码,也就是更靠近根(节点少),这也就是最优二叉树-哈夫曼树。
4、经典应用
AVL树(二叉平衡树)
AVL树(二叉平衡树)是带有平衡条件的二叉查找树。
平衡条件:其每个节点的左子树和右子树的高度最多相差 1 的二叉查找树。(空树的高度为 -1)。
AVL树保证了树两边的深度差不多,这样在查找的时候,可以减少查找次数,不会出现一边树很深,需要查询很多次数的特殊情况,提高了查询的效率,当插入时有可能会破坏平衡条件,我们通过旋转(rotation)来进行修正。
0、应用场景
由于维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树.当然,如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树.
Windows NT内核中广泛存在.
1、代码结构
type AVL struct {
value int //值
height int //深度
left *AVL //左子树
right *AVL //右子树
}
2、旋转
保持平衡才是AVL树的特点,如何旋转才能保持平衡,我们先来看看不平衡的情况
不平衡只有这四种情况,我们有四种旋转方式如上图所示
- RR旋转:左单旋转:就是第一种情况,需要将最上面一个节点左旋下来。
- LL旋转:右单旋转:就是第二种情况,需要将最上面一个节点右旋下来。
- RL旋转:先右旋转后左旋转,就是第三种情况,需要将最下面一个节点先右旋成RR类型,然后再将RR进行左旋。
- LR旋转:先左旋转后右旋转,就是第三种情况,需要将最下面一个节点先左旋成LL类型,然后再将LL进行右旋。
具体实现,这个我们通过实例来说明
package main
import "fmt"
type AVL struct {
value int //值
height int //深度
left *AVL //左子树
right *AVL //右子树
}
//查找元素
func (t *AVL) Search(value int) bool {
if t == nil {
return false
}
compare := value - t.value
if compare < 0 {
return t.left.Search(value)
}else if compare > 0 {
return t.right.Search(value)
}else {
return true
}
}
func (t *AVL) leftRotate() *AVL { //左旋转
headNode := t.right
t.right = headNode.left
headNode.left = t
//更新结点高度
t.height = max(t.left.getHeight(),t.right.getHeight()) + 1
headNode.height = max(headNode.left.getHeight(),headNode.right.getHeight()) + 1
return headNode
}
func (t *AVL) rightRotate() *AVL { //右旋转
headNode := t.left
t.left = headNode.right
headNode.right = t
//更新结点高度
t.height = max(t.left.getHeight(),t.right.getHeight()) +1
headNode.height = max(headNode.left.getHeight(),headNode.right.getHeight()) + 1
return headNode
}
func (t *AVL) rightThenLeftRotate() *AVL { //右旋转,之后左旋转
//以失衡点右结点先右旋转
sonHeadNode := t.right.rightRotate()
t.right = sonHeadNode
//再以失衡点左旋转
return t.leftRotate()
}
func (t *AVL) LeftThenRightRotate() *AVL { //左旋转,之后右旋转
//以失衡点左结点先左旋转
sonHeadNode := t.left.leftRotate()
t.left = sonHeadNode
//再以失衡点左旋转
return t.rightRotate()
}
func (t *AVL) adjust() *AVL {
if t.right.getHeight() - t.left.getHeight() == 2 {
if t.right.right.getHeight() > t.right.left.getHeight() {
t = t.leftRotate()
}else {
t = t.rightThenLeftRotate()
}
}else if t.left.getHeight() - t.right.getHeight() == 2 {
if t.left.left.getHeight() > t.left.right.getHeight() {
t = t.rightRotate()
} else {
t = t.LeftThenRightRotate()
}
}
return t
}
//添加元素
func (t *AVL) Insert(value int) *AVL {
if t == nil {
newNode := AVL{value,1,nil,nil}
return &newNode
}
if value < t.value {
t.left = t.left.Insert(value)
t = t.adjust()
}else if value > t.value{
t.right = t.right.Insert(value)
t = t.adjust()
}else {
fmt.Println("the node exit")
}
t.height = max(t.left.getHeight(),t.right.getHeight()) + 1
return t
}
/*删除元素
*1、如果被删除结点只有一个子结点,就直接将A的子结点连至A的父结点上,并将A删除
*2、如果被删除结点有两个子结点,将该结点右子数内的最小结点取代A。
*3、查看是否平衡,该调整调整
*/
func (t *AVL) Delete(value int) *AVL {
if t ==nil {
return t
}
compare := value - t.value
if compare < 0 {
t.left = t.left.Delete(value)
}else if compare > 0{
t.right = t.right.Delete(value)
}else { //找到结点,删除结点()
if t.left != nil && t.right != nil {
t.value = t.right.getMin()
t.right = t.right.Delete(t.value)
} else if t.left !=nil {
t = t.left
}else {//只有一个右孩子或没孩子
t = t.right
}
}
if t != nil {
t.height = max(t.left.getHeight(),t.right.getHeight()) + 1
t = t.adjust()
}
return t
}
//按顺序获得树中元素
func (t *AVL) getAll() []int {
values := []int{}
return addValues(values,t)
}
//将一个节点加入切片中
func addValues(values []int,t *AVL) []int {
if t != nil {
values = addValues(values,t.left)
values = append(values,t.value)
fmt.Println(t.value,t.height)
values = addValues(values,t.right)
}
return values
}
//查找子树最小值
func (t *AVL) getMin() int {
if t == nil {
return -1
}
if t.left == nil {
return t.value
} else {
return t.left.getMin()
}
}
//查找子树最大值
func (t *AVL) getMax() int {
if t == nil {
return -1
}
if t.right == nil {
return t.value
} else {
return t.right.getMax()
}
}
//查找最小结点
func (t *AVL) getMinNode() *AVL {
if t == nil {
return nil
}else {
for t.left != nil {
t = t.left
}
}
return t
}
//查找最大结点
func (t *AVL) getMaxNode() *AVL {
if t == nil {
return nil
}else {
for t.right != nil {
t = t.right
}
}
return t
}
//得到树高
func (t *AVL) getHeight() int {
if t == nil {
return 0
}
return t.height
}
func max(a int,b int) int{
if a > b {
return a
}else {
return b
}
}
func main() {
bsTree := AVL{100,1,nil,nil}
newTree := bsTree.Insert(60)
newTree = bsTree.Insert(120)
newTree = bsTree.Insert(110)
newTree = bsTree.Insert(130)
newTree = bsTree.Insert(105)
fmt.Println(newTree.getAll())
newTree.Delete(110)
fmt.Println(newTree.getAll())
}
3、经典应用
一个二叉查找树是否是平衡二叉树
直接对比左子树和右子树的高度差是否大于1,并且每一个子树都满足这种情况
/** * Definition for a binary tree node. * type TreeNode struct { * Val int * Left *TreeNode * Right *TreeNode * } */ func isBalanced(root *TreeNode) bool { if root == nil { return true } if abs(hight(root.Left) - hight(root.Right)) <= 1 && isBalanced(root.Left) && isBalanced(root.Right){ return true } return false } func hight(root *TreeNode) int { if root == nil { return 0 } return max(hight(root.Left),hight(root.Right)) + 1 } func max(x,y int)int { if x > y { return x } return y } func abs(x int)int { if x < 0 { return x * -1 } return x }一个升序链表转化为一颗二叉平衡树
因为升序,所以找到中间节点为根节点,这样左右数量均衡,依次类推,便可取巧构建一颗二叉平衡树,当然这个是针对升序链表,如果是正常数组还是需要上面的方法进行构建,需要对应的旋转。
/** * Definition for singly-linked list. * type ListNode struct { * Val int * Next *ListNode * } */ /** * Definition for a binary tree node. * type TreeNode struct { * Val int * Left *TreeNode * Right *TreeNode * } */ func sortedListToBST(head *ListNode) *TreeNode { return buildTree(head,nil) } func buildTree(head,tail *ListNode) *TreeNode{ if head == tail { return nil } mid := getMid(head,tail) root := &TreeNode{Val:mid.Val} root.Left = buildTree(head,mid) root.Right = buildTree(mid.Next,tail) return root } func getMid(left,right *ListNode) *ListNode{ if left == right { return nil } fast := left slow := left for fast != right && fast.Next != right { fast = fast.Next.Next slow = slow.Next } return slow }
红黑树
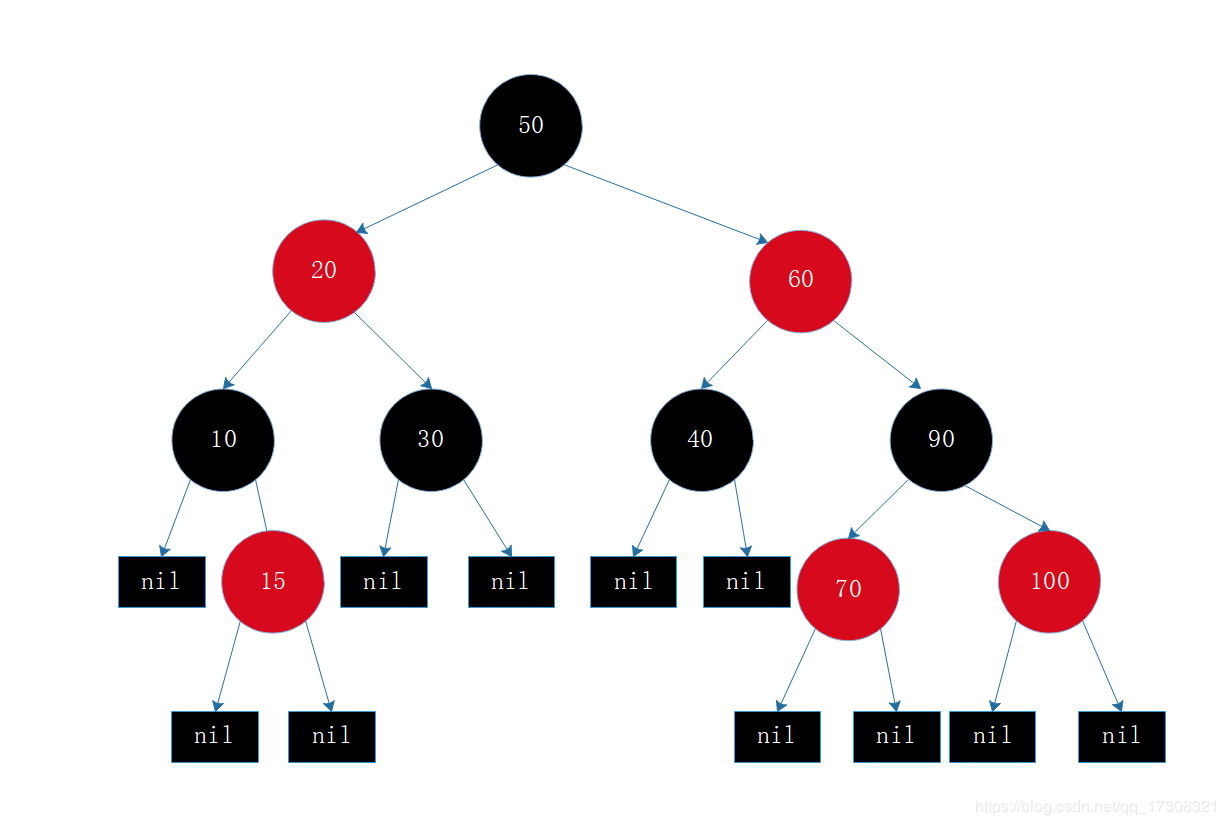
Red-Black Tree 「RBT」
红黑树是一种基于二叉查找树的数据结构,是一种自平衡的二叉搜索树,它包含了二叉搜索树的特性,同时具备以下性质:
- 所有节点的颜色不是红色就是黑色。
- 根节点是黑色。
- 每个叶子节点都是黑色的空节点(nil)。
- 每个红色节点的两个子节点都是黑色。(从每个叶子到根节点的所有路径上不能有两个连续的红色节点)
- 从任一节点到其叶子节点的所有路径上都包含相同数目的黑节点。
可见红黑树是通过颜色来保持自平衡的,红黑树有两大操作,一个是我们在二叉平衡树中的旋转,还有一个就是标色,符合上面的规则。
0、使用场景
它是一种弱平衡二叉树(由于是若平衡,可以推出,相同的节点情况下,AVL树的高度低于红黑树),相对于要求严格的AVL树来说,它的旋转次数变少,所以对于搜索,插入,删除操作多的情况下,我们就用红黑树.
- 广泛用于C++的STL中,map和set都是用红黑树实现的.
- 著名的linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块,进程的虚拟内存区域都存储在一颗红黑树上,每个虚拟地址区域都对应红黑树的一个节点,左指针指向相邻的地址虚拟存储区域,右指针指向相邻的高地址虚拟地址空间.
- IO多路复用epoll的实现采用红黑树组织管理sockfd,以支持快速的增删改查.
- ngnix中,用红黑树管理timer,因为红黑树是有序的,可以很快的得到距离当前最小的定时器.
- java中TreeMap的实现.
能用平衡树的地方,就可以用红黑树。用红黑树之后,读取略逊于AVL,维护强于AVL。设计红黑树的目的,就是解决平衡树的维护起来比较麻烦的问题,红黑树,读取略逊于AVL,维护强于AVL,每次插入和删除的平均旋转次数应该是远小于平衡树。
1、代码
const (
// RED 红树设为true
RED bool = true
// BLACK 黑树设为false
BLACK bool = false
)
// RBNode 红黑树
type RBNode struct {
value int64
color bool
left, right, parent *RBNode
}
type RBTree struct {
root *RBNode
}
2、红黑树
我们直接通过实例来看具体的构建和实现
package main
import(
"log"
)
const (
RED = true
BLACK = false
)
//-----------------------------------
//Item interface
//
type Item interface {
Less(than Item) bool
}
type Int int
func (x Int) Less(than Item) bool {
log.Println(x, " ", than.(Int))
return x < than.(Int)
}
type Uint32 uint32
func (x Uint32) Less(than Item) bool {
log.Println(x, " ", than.(Uint32))
return x < than.(Uint32)
}
type String string
func (x String) Less(than Item) bool {
log.Println(x, " ", than.(String))
return x < than.(String)
}
//-----------------------------------
type Node struct {
Parent *Node
Left *Node
Right *Node
color bool
Item
}
type Rbtree struct {
NIL *Node
root *Node
count uint64
}
func New() *Rbtree{
node := &Node{nil, nil, nil, BLACK, nil}
return &Rbtree{
NIL : node,
root : node,
count : 0,
}
}
func less(x, y Item) bool {
return x.Less(y)
}
// Left Rotate
func (rbt *Rbtree) LeftRotate(no *Node) {
// Since we are doing the left rotation, the right child should *NOT* nil.
if no.Right == rbt.NIL {
return
}
// | |
// X Y
// / \ left rotate / \
// α Y -------------> X γ
// / \ / \
// β γ α β
rchild := no.Right
no.Right = rchild.Left
if rchild.Left != rbt.NIL {
rchild.Left.Parent = no
}
rchild.Parent = no.Parent
if no.Parent == rbt.NIL {
rbt.root = rchild
} else if no == no.Parent.Left {
no.Parent.Left = rchild
} else {
no.Parent.Right = rchild
}
rchild.Left = no
no.Parent = rchild
}
// Right Rotate
func (rbt *Rbtree) RightRotate(no *Node) {
if no.Left == rbt.NIL {
return
}
// | |
// X Y
// / \ right rotate / \
// Y γ -------------> α X
// / \ / \
// α β β γ
lchild := no.Left
no.Left = lchild.Right
if lchild.Right != rbt.NIL {
lchild.Right.Parent = no
}
lchild.Parent = no.Parent
if no.Parent == rbt.NIL {
rbt.root = lchild
} else if no == no.Parent.Left {
no.Parent.Left = lchild
} else {
no.Parent.Right = lchild
}
lchild.Right = no
no.Parent = lchild
}
func (rbt *Rbtree) Insert(no *Node) {
x := rbt.root
var y *Node = rbt.NIL
for x != rbt.NIL {
y = x
if less(no.Item, x.Item) {
x = x.Left
} else if less(x.Item, no.Item) {
x = x.Right
} else {
log.Println("that node already exist")
}
}
no.Parent = y
if y == rbt.NIL {
rbt.root = no
} else if less(no.Item, y.Item) {
y.Left = no
} else {
y.Right = no
}
rbt.count++
rbt.insertFixup(no)
}
func (rbt *Rbtree) insertFixup(no *Node) {
for no.Parent.color == RED {
if no.Parent == no.Parent.Parent.Left {
y := no.Parent.Parent.Right
if y.color == RED {
//
// 情形 4
log.Println("TRACE Do Case 4 :", no.Item)
no.Parent.color = BLACK
y.color = BLACK
no.Parent.Parent.color = RED
no = no.Parent.Parent //循环向上自平衡.
} else {
if no == no.Parent.Right {
//
// 情形 5 : 反向情形
// 直接左旋转 , 然后进行情形3(变色->右旋)
log.Println("TRACE Do Case 5 :", no.Item)
if no == no.Parent.Right {
no = no.Parent
rbt.LeftRotate(no)
}
}
log.Println("TRACE Do Case 6 :", no.Item)
no.Parent.color = BLACK
no.Parent.Parent.color = RED
rbt.RightRotate(no.Parent.Parent)
}
} else { //为父父节点右孩子情形,和左孩子一样,改下转向而已.
y := no.Parent.Parent.Left
if y.color == RED {
no.Parent.color = BLACK
y.color = BLACK
no.Parent.Parent.color = RED
no = no.Parent.Parent
} else {
if no == no.Parent.Left {
no = no.Parent
rbt.RightRotate(no)
}
no.Parent.color = BLACK
no.Parent.Parent.color = RED
rbt.LeftRotate(no.Parent.Parent)
}
}
}
rbt.root.color = BLACK
}
func LeftRotateTest(){
var i10 Int = 10
var i12 Int = 12
rbtree := New()
x := &Node{rbtree.NIL, rbtree.NIL, rbtree.NIL, BLACK, i10}
rbtree.root = x
y := &Node{rbtree.root.Right, rbtree.NIL, rbtree.NIL, RED, i12}
rbtree.root.Right = y
log.Println("root : ", rbtree.root)
log.Println("left : ", rbtree.root.Left)
log.Println("right : ", rbtree.root.Right)
rbtree.LeftRotate(rbtree.root)
log.Println("root : ", rbtree.root)
log.Println("left : ", rbtree.root.Left)
log.Println("right : ", rbtree.root.Right)
}
func RightRotateTest(){
var i10 Int = 10
var i12 Int = 12
rbtree := New()
x := &Node{rbtree.NIL, rbtree.NIL, rbtree.NIL, BLACK, i10}
rbtree.root = x
y := &Node{rbtree.root.Right, rbtree.NIL, rbtree.NIL, RED, i12}
rbtree.root.Left = y
log.Println("root : ", rbtree.root)
log.Println("left : ", rbtree.root.Left)
log.Println("right : ", rbtree.root.Right)
rbtree.RightRotate(rbtree.root)
log.Println("root : ", rbtree.root)
log.Println("left : ", rbtree.root.Left)
log.Println("right : ", rbtree.root.Right)
}
func ItemTest(){
var itype1 Int = 10
var itype2 Int = 12
log.Println(itype1.Less(itype2))
var strtype1 String = "sola"
var strtype2 String = "ailumiyana"
log.Println(strtype1.Less(strtype2))
}
func InsertTest(){
rbtree := New()
rbtree.Insert(&Node{rbtree.NIL, rbtree.NIL, rbtree.NIL, RED, Int(10)})
rbtree.Insert(&Node{rbtree.NIL, rbtree.NIL, rbtree.NIL, RED, Int(9)})
rbtree.Insert(&Node{rbtree.NIL, rbtree.NIL, rbtree.NIL, RED, Int(8)})
rbtree.Insert(&Node{rbtree.NIL, rbtree.NIL, rbtree.NIL, RED, Int(6)})
rbtree.Insert(&Node{rbtree.NIL, rbtree.NIL, rbtree.NIL, RED, Int(7)})
log.Println("rbtree counts : ", rbtree.count)
log.Println("------ ", rbtree.root.Item)
log.Println("----", rbtree.root.Left.Item, "---", rbtree.root.Right.Item)
log.Println("--", rbtree.root.Left.Left.Item, "-", rbtree.root.Left.Right.Item)
}
func main() {
log.Println(" ---- main ------ ")
LeftRotateTest()
RightRotateTest()
ItemTest()
InsertTest()
}
3、经典应用
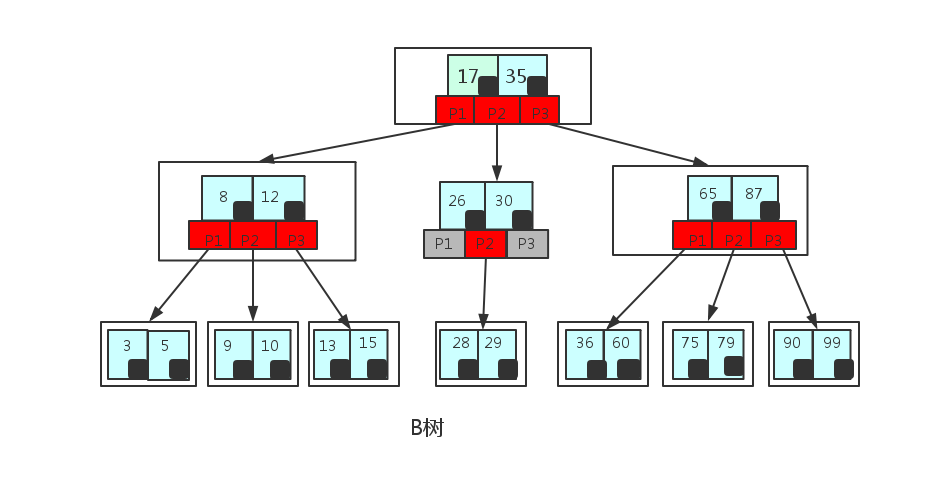
B树
B树也称B-树,它是一颗多路平衡查找树。我们描述一颗B树时需要指定它的阶数,阶数表示了一个结点最多有多少个孩子结点,一般用字母m表示阶数。当m取2时,就是我们常见的二叉搜索树。 一颗m阶的B树定义如下:
- 每个结点最多有m-1个关键字。
- 根结点最少可以只有1个关键字。
- 非根结点至少有Math.ceil(m/2)-1个关键字。
- 每个结点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
- 所有叶子结点都位于同一层,或者说根结点到每个叶子结点的长度都相同。
条件:
- 根节点至少有2个子节点
- 每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m
- 每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m
- 所有的叶子结点都位于同一层
- 每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划
1、实例
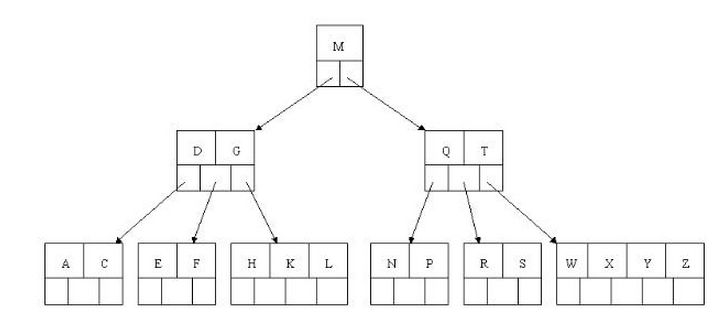
查找E
- 获取根节点的关键字进行比较,当前根节点关键字为M,E<M(26个字母顺序),所以往找到指向左边的子节点(二分法规则,左小右大,左边放小于当前节点值的子节点、右边放大于当前节点值的子节点);
- 拿到关键字D和G,D<E<G 所以直接找到D和G中间的节点;
- 拿到E和F,因为E=E 所以直接返回关键字和指针信息(如果树结构里面没有包含所要查找的节点则返回null);
B+树
B+树是应文件系统所需而产生的一种B树的变形树,B+树是B树的一个升级版,相对于B树来说B+树更充分的利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分法查找。
条件:
- 有k个子结点的结点必然有k个关键字
- 非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中
- 树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录
典型应用场景:Mysql数据库的索引类型 - B+索引
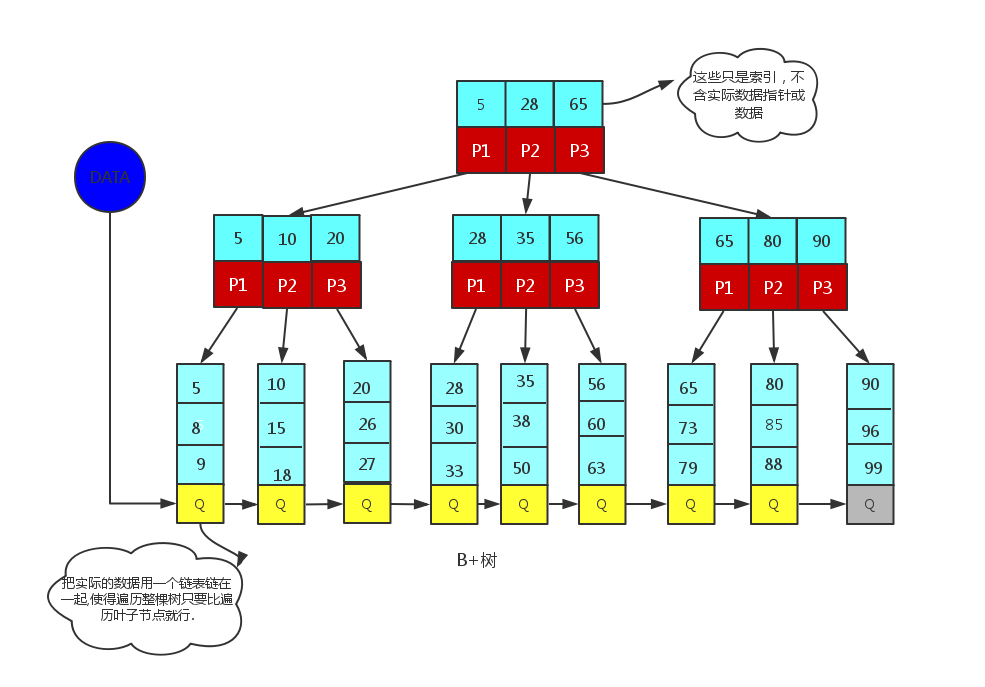
0、应用场景
B和B+树主要用在文件系统以及数据库做索引.比如Mysql;
- 红黑树多用在内部排序,即全放在内存中的,STL的map和set的内部实现就是红黑树。
- B+树多用于外存上时,B+也被成为一个磁盘友好的数据结构。
B*树
B*树是B+树的变种,相对于B+树他们的不同之处如下:
首先是关键字个数限制问题,B+树初始化的关键字初始化个数是cei(m/2),b*树的初始化个数为(cei(2⁄3*m))
B+树节点满时就会分裂,而B*树节点满时会检查兄弟节点是否满(因为每个节点都有指向兄弟的指针),如果兄弟节点未满则向兄弟节点转移关键字,如果兄弟节点已满,则从当前节点和兄弟节点各拿出1/3的数据创建一个新的节点出来;
在B+树的基础上因其初始化的容量变大,使得节点空间使用率更高,而又存有兄弟节点的指针,可以向兄弟节点转移关键字的特性使得B*树额分解次数变得更少;
常规树和森林
主要还是将常规树和森林转化为二叉树来进行操作。
1、树转化二叉树
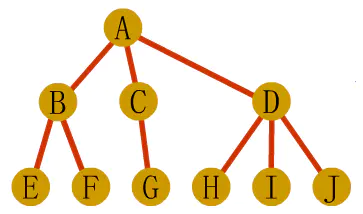
第一步:在树中所有兄弟结点间加一条连线
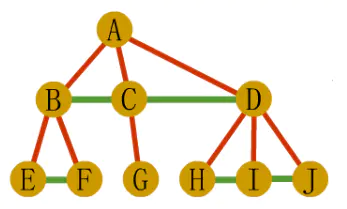
第二步:对每个结点,除了保留与最左边孩子的连线外,去掉该结点其他孩子的连线
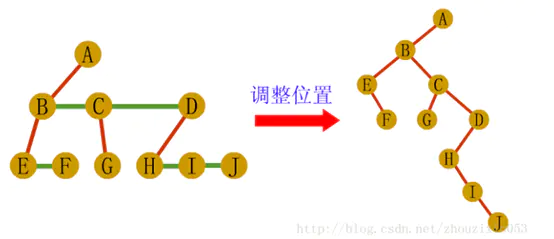
第三步:调整位置
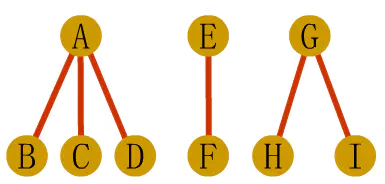
2、森林转化为二叉树
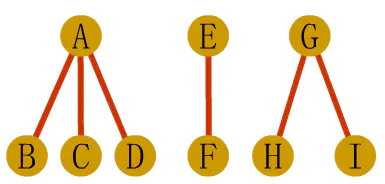
第一步:先将森林中的每棵树变为二叉树
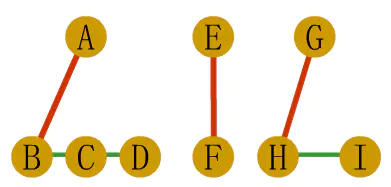
第二步:将各二叉树的根节点从左到右连在一起,形成二叉树
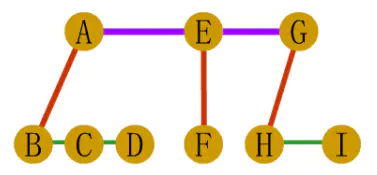
第三步,调整位置
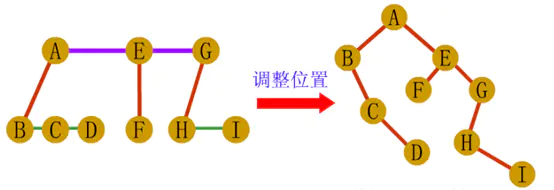
当然是都可以逆向转化的。
网状数据结构
图
图就是网状数据结构,有顶点和边组成。可以分为有向图和无向图,连通图和非连通图,有权图和无权图,这些分类也可以组合, 比如有向无环图(DAG)。
- 无向图:若顶点Vi到顶点Vj之间的边没有方向,则称这条边为无向边(Edge),用无序偶对(Vi,Vj)来表示。如果图中任意两个顶点之间的边都是无向边,则称该图为无向图
- 有向图:若从顶点Vi到Vj的边有方向,则称这条边为有向边,也称为弧(Arc)。用有序偶来表示,Vi称为弧尾,Vj称为弧头。如果图中任意两个顶点之间的边都是有向边,则称为有向图
- 连通图和非连通图:在无向图中,如果从顶点A到顶点B有路径,则称A和B是连通的。如果对于图中任意两个顶点Vi和Vj都是能够连通的,则称该图是连通图。反之则是非连通图。
- 连通形成环的叫有环图
- 节点与节点之间的边上存在一定的“权值”,叫有权图
图的存储结构
- 邻接矩阵-也就是一个二维数组记录这顶点与顶点之间的连接数据,还有一个数组记录着顶点数据
- 邻接表,我认为就是一张哈希表,有数组和链表组成,数组记录着顶点,链表记录这连接的顶点
- 还有十字链表和邻接多重表,简单了解一下,前者对有向图进行了优化,后者对无向图进行了优化。
拓扑排序
给定一个包含 n个节点的有向图 G,我们给出它的节点编号的一种排列,如果满足:对于图 G 中的任意一条有向边 (u, v),u在排列中都出现在 v 的前面。 那么称该排列是图 G 的「拓扑排序」。
图是一个很复杂的数据结构,但是很多高端的算法都是用的图结构,有时间可以深入研究一下。
1、代码
type Node struct {
value int
}
type Graph struct {
nodes []*Node // 节点集
edges map[Node][]*Node // 邻接表表示的无向图
lock sync.RWMutex // 保证线程安全
}
2、实例
// 增加节点
func (g *Graph) AddNode(n *Node) {
g.lock.Lock()
defer g.lock.Unlock()
g.nodes = append(g.nodes, n)
}
// 增加边
func (g *Graph) AddEdge(u, v *Node) {
g.lock.Lock()
defer g.lock.Unlock()
// 首次建立图
if g.edges == nil {
g.edges = make(map[Node][]*Node)
}
g.edges[*u] = append(g.edges[*u], v) // 建立 u->v 的边
g.edges[*v] = append(g.edges[*v], u) // 由于是无向图,同时存在 v->u 的边
}
// 输出图
func (g *Graph) String() {
g.lock.RLock()
defer g.lock.RUnlock()
str := ""
for _, iNode := range g.nodes {
str += iNode.String() + " -> "
nexts := g.edges[*iNode]
for _, next := range nexts {
str += next.String() + " "
}
str += "\n"
}
fmt.Println(str)
}
// 输出节点
func (n *Node) String() string {
return fmt.Sprintf("%v", n.value)
}
3、遍历
图的遍历主要就是这两种遍历思想,深度优先搜索使用递归方式,需要栈结构辅助实现。广度优先搜索需要使用队列结构辅助实现。
4、经典应用
课程表
使用拓扑排序
func canFinish(numCourses int, prerequisites [][]int) bool { var ( edges = make([][]int, numCourses) visited = make([]int, numCourses) result []int valid = true dfs func(u int) ) dfs = func(u int) { visited[u] = 1 for _, v := range edges[u] { if visited[v] == 0 { dfs(v) if !valid { return } } else if visited[v] == 1 { valid = false return } } visited[u] = 2 result = append(result, u) } for _, info := range prerequisites { edges[info[1]] = append(edges[info[1]], info[0]) } for i := 0; i < numCourses && valid; i++ { if visited[i] == 0 { dfs(i) } } return valid }重新安排行程
使用dfs,先构建图的邻接表,然后将[][]string转化为邻接表进行dfs,由于回溯,所以要变向。
func findItinerary(tickets [][]string) []string { var ( m = map[string][]string{} res []string ) for _, ticket := range tickets { src, dst := ticket[0], ticket[1] m[src] = append(m[src], dst) } for key := range m { sort.Strings(m[key]) } var dfs func(curr string) dfs = func(curr string) { for { if v, ok := m[curr]; !ok || len(v) == 0 { break } tmp := m[curr][0] m[curr] = m[curr][1:] dfs(tmp) } res = append(res, curr) } dfs("JFK") for i := 0; i < len(res)/2; i++ { res[i], res[len(res) - 1 - i] = res[len(res) - 1 - i], res[i] } return res }
其他数据结构
并查集
并查集是一种树型的数据结构,用于处理一些不相交集(Disjoint Sets)的合并及查询问题。
有一个联合-查找算法(Union-find Algorithm)定义了两个用于此数据结构的操作:
Find:确定元素属于哪一个子集。它可以被用来确定两个元素是否属于同一子集。
Union:将两个子集合并成同一个集合。
合并的时候会有集中优化的方式来合并保证树不是太高,减少查询的次数,提高查询的性能。
经典应用
交换字符串中的元素
并查集+连通图+排序
type Djset struct{ Parent []int Rank []int } func newDjset(n int) Djset { parent := make([]int, n) rank := make([]int, n) for i := 0; i < n; i++ { parent[i] = i rank[i] = 0 } return Djset{parent, rank} } func (ds Djset) Find(x int) int { if ds.Parent[x] != x { ds.Parent[x] = ds.Find(ds.Parent[x]) } return ds.Parent[x] } func (ds Djset) Merge(x, y int) { rx := ds.Find(x) ry := ds.Find(y) if rx != ry { if ds.Rank[rx] < ds.Rank[ry] { rx, ry = ry,rx } ds.Parent[ry] = rx; if ds.Rank[rx] == ds.Rank[ry] { ds.Rank[rx] += 1 } } } func smallestStringWithSwaps(s string, pairs [][]int) string { n := len(s) ds := newDjset(n) rs := make([]byte, n) for _, v := range(pairs) { ds.Merge(v[0], v[1]) } um := make(map[int][]int) for i := 0; i < n; i++ { um[ds.Find(i)] = append(um[ds.Find(i)], i) } for _, v := range(um) { c := make([]int, len(v)) copy(c, v) sort.Slice(v, func(i, j int) bool { return s[v[i]] < s[v[j]] }) for i := 0; i < len(c); i++ { rs[c[i]] = s[v[i]] } } return string(rs) }
附录
用栈实现计算器
计算后缀表达式的代码实现
func calculate(postfix string) int {
stack := stack.ItemStack{}
fixLen := len(postfix)
for i := 0; i < fixLen; i++ {
nextChar := string(postfix[i])
// 数字:直接压栈
if unicode.IsDigit(rune(postfix[i])) {
stack.Push(nextChar)
} else {
// 操作符:取出两个数字计算值,再将结果压栈
num1, _ := strconv.Atoi(stack.Pop())
num2, _ := strconv.Atoi(stack.Pop())
switch nextChar {
case "+":
stack.Push(strconv.Itoa(num1 + num2))
case "-":
stack.Push(strconv.Itoa(num1 - num2))
case "*":
stack.Push(strconv.Itoa(num1 * num2))
case "/":
stack.Push(strconv.Itoa(num1 / num2))
}
}
}
result, _ := strconv.Atoi(stack.Top())
return result
}
现在只需知道如何将中缀转为后缀,再利用栈计算即可。
中缀表达式转后缀表达式
从左到右逐个字符遍历中缀表达式,输出的字符序列即是后缀表达式:
- 遇到数字直接输出
- 遇到运算符则判断:
- 栈顶运算符优先级更低则入栈,更高或相等则直接输出
- 栈为空、栈顶是 ( 直接入栈
- 运算符是 ) 则将栈顶运算符全部弹出,直到遇见 )
- 中缀表达式遍历完毕,运算符栈不为空则全部弹出,依次追加到输出
转换的代码实现
// 中缀表达式转后缀表达式
func infix2ToPostfix(exp string) string {
stack := stack.ItemStack{}
postfix := ""
expLen := len(exp)
// 遍历整个表达式
for i := 0; i < expLen; i++ {
char := string(exp[i])
switch char {
case " ":
continue
case "(":
// 左括号直接入栈
stack.Push("(")
case ")":
// 右括号则弹出元素直到遇到左括号
for !stack.IsEmpty() {
preChar := stack.Top()
if preChar == "(" {
stack.Pop() // 弹出 "("
break
}
postfix += preChar
stack.Pop()
}
// 数字则直接输出
case "0", "1", "2", "3", "4", "5", "6", "7", "8", "9":
j := i
digit := ""
for ; j < expLen && unicode.IsDigit(rune(exp[j])); j++ {
digit += string(exp[j])
}
postfix += digit
i = j - 1 // i 向前跨越一个整数,由于执行了一步多余的 j++,需要减 1
default:
// 操作符:遇到高优先级的运算符,不断弹出,直到遇见更低优先级运算符
for !stack.IsEmpty() {
top := stack.Top()
if top == "(" || isLower(top, char) {
break
}
postfix += top
stack.Pop()
}
// 低优先级的运算符入栈
stack.Push(char)
}
}
// 栈不空则全部输出
for !stack.IsEmpty() {
postfix += stack.Pop()
}
return postfix
}
// 比较运算符栈栈顶 top 和新运算符 newTop 的优先级高低
func isLower(top string, newTop string) bool {
// 注意 a + b + c 的后缀表达式是 ab + c +,不是 abc + +
switch top {
case "+", "-":
if newTop == "*" || newTop == "/" {
return true
}
case "(":
return true
}
return false
}
倒排索引
理解正向索引和反向索引,也就是我们说的倒排索引
正向索引,将文件包含哪些词作为存储,到文件中去寻找一些词,需要先找到文件,然后再看有没有这些词
反向索引,将包含这些词的文件作为一个存储,找到这个词就知道哪些文件包含这些词了。