Apache Kafka由著名职业社交公司LinkedIn开发,最初是被设计用来解决LinkedIn公司内部海量日志传输等问题。Kafka使用Scala语言编写,于2011年开源并进入Apache孵化器,2012年10月正式毕业,现在为Apache顶级项目。Kafka是一个分布式数据流平台,具有高吞吐、低延迟、高容错等特点。
Kafka简介
基本术语
消息message
先不管其他的,我们使用Kafka这个消息系统肯定是先关注消息这个概念,在Kafka中,每一个消息由键、值和一个时间戳组成(key、value和timestamp)
主题topic
Kafka集群存储同一类别的消息流称为主题
主题会有多个订阅者(0个1个或多个),当主题发布消息时,会向订阅者推送记录
日志 offset
针对每一个主题,Kafka集群维护了一个像下面这样的分区日志offset:
这些分区位offset于不同的服务器上,每一个分区可以看做是一个结构化的提交日志offset,每写入一条记录都会记录到其中一个分区并且分配一个唯一地标识其位置的数字称为偏移量offset
Kafka集群会将发布的消息保存一段时间,不管是否被消费。例如,如果设置保存天数为2天,那么从消息发布起的两天之内,该消息一直可以被消费,但是超过两天后就会被丢弃以节省空间。其次,Kafka的数据持久化性能很好,所以长时间存储数据不是问题
分区 Partition
每个topic可以有一个或多个partition(分区)。分区是在物理层面上的,不同的分区对应着不同的数据文件。Kafka使用分区支持物理上的并发写入和读取,从而大大提高了吞吐量
Kafka中采用分区的设计有几个目的。一是可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二,分区可以作为并行处理的单元,稍后会谈到这一点
Log的分区被分布到集群中的多个服务器上。每个服务器处理它分到的分区。根据配置每个分区还可以复制到其它服务器作为备份容错。 每个分区有一个leader,零或多个follower。Leader处理此分区的所有的读写请求,而follower被动的复制数据。如果leader宕机,其它的一个follower会被推举为新的leader。 一台服务器可能同时是一个分区的leader,另一个分区的follower。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
生产者 producer
生产者往某个Topic上发布消息。生产者还可以选择将消息分配到Topic的哪个节点上。最简单的方式是轮询分配到各个分区以平衡负载,也可以根据某种算法依照权重选择分区
消费者 consumer
Kafka有一个消费者组的概念,生产者把消息发到的是消费者组,在消费者组里面可以有很多个消费者实例。
消费者组 Consumer Group
一个消费者组可以包含一个或多个消费者。使用多分区+多消费者方式可以极大提高数据下游的处理速度。
节点 Broker
消息队列中常用的概念,在Kafka中指部署了Kafka实例的服务器节点。
安装部署
单机
1、安装jdk
以oracle jdk为例,下载地址http://java.sun.com/javase/downloads/index.jsp
yum -y install jdk-8u141-linux-x64.rpm
2、下载解压
下载地址:http://kafka.apache.org/downloads,如0.10.1.0版本的Kafka下载
wget http://apache.fayea.com/kafka/0.10.1.0/kafka_2.11-0.10.1.0.tgz
tar -xvf kafka_2.11-0.10.1.0.tgz
cd kafka_2.11-0.10.1.0
修改配置
[root@localhost ~]# grep -Ev "^#|^$" /data/kafka/config/server.properties
broker.id=0
delete.topic.enable=true
listeners=PLAINTEXT://192.168.15.131:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/data
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.flush.interval.messages=10000
log.flush.interval.ms=1000
log.retention.hours=168
log.retention.bytes=1073741824
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.15.131:2181,192.168.15.132:2181,192.168.15.133:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
提示:其他主机将该机器的kafka目录拷贝即可,然后需要修改broker.id、listeners地址。有关kafka配置文件参数,参考:http://orchome.com/12;
3、安装Zookeeper
Kafka需要Zookeeper的监控,所以先要安装Zookeeper。
wget http://apache.forsale.plus/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz
tar zxf zookeeper-3.4.9.tar.gz
mv zookeeper-3.4.9 /data/zk
修改配置文件内容如下所示:
[root@localhost ~]# cat /data/zk/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zk/data/zookeeper
dataLogDir=/data/zk/data/logs
clientPort=2181
maxClientCnxns=60
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=zk01:2888:3888
server.2=zk02:2888:3888
server.3=zk03:2888:3888
参数说明:
- server.id=host:port:port:表示了不同的zookeeper服务器的自身标识,作为集群的一部分,每一台服务器应该知道其他服务器的信息。用户可以从“server.id=host:port:port” 中读取到相关信息。
在服务器的data(dataDir参数所指定的目录)下创建一个文件名为myid的文件,这个文件的内容只有一行,指定的是自身的id值。比如,服务器“1”应该在myid文件中写入“1”。这个id必须在集群环境中服务器标识中是唯一的,且大小在1~255之间。这一样配置中,zoo1代表第一台服务器的IP地址。第一个端口号(port)是从follower连接到leader机器的 端口,第二个端口是用来进行leader选举时所用的端口。所以,在集群配置过程中有三个非常重要的端口:clientPort:2181、port:2888、port:3888。
如果想更换日志输出位置,除了在zoo.cfg加入”dataLogDir=/data/zk/data/logs”外,还需要修改zkServer.sh文件,大概修改方式地方在125行左右,内容如下:
125 ZOO_LOG_DIR="$($GREP "^[[:space:]]*dataLogDir" "$ZOOCFG" | sed -e 's/.*=//')"
126 if [ ! -w "$ZOO_LOG_DIR" ] ; then
127 mkdir -p "$ZOO_LOG_DIR"
128 fi
在启动服务之前,还需要分别在zookeeper创建myid,方式如下:
echo 1 > /data/zk/data/zookeeper/myid
启动服务
/data/zk/bin/zkServer.sh start
验证服务
查看相关端口号
[root@localhost ~]# ss -lnpt|grep java
LISTEN 0 50 :::34442 :::* users:(("java",pid=2984,fd=18))
LISTEN 0 50 ::ffff:192.168.15.133:3888 :::* users:(("java",pid=2984,fd=26))
LISTEN 0 50 :::2181 :::* users:(("java",pid=2984,fd=25))
###查看zookeeper服务状态
[root@localhost ~]# /data/zk/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zk/bin/../conf/zoo.cfgMode: follower
4、Kafka目录介绍
- /bin 操作kafka的可执行脚本,还包含windows下脚本
- /config 配置文件所在目录
- /libs 依赖库目录
- /logs 日志数据目录,目录kafka把server端日志分为5种类型,分为:server,request,state,log-cleaner,controller
5、启动Kafka
在每台服务器上进入Kafka目录,分别执行以下命令:
bin/kafka-server-start.sh config/server.properties &
检测2181与9092端口
netstat -tunlp|egrep "(2181|9092)"
tcp 0 0 :::2181 :::* LISTEN 19787/java
tcp 0 0 :::9092 :::* LISTEN 28094/java
说明:
Kafka的进程ID为28094,占用端口为9092
QuorumPeerMain为对应的zookeeper实例,进程ID为19787,在2181端口监听
6、单机连通性测试
启动2个XSHELL客户端,一个用于生产者发送消息,一个用于消费者接受消息。
运行producer,随机敲入几个字符,相当于把这个敲入的字符消息发送给队列。
bin/kafka-console-producer.sh --broker-list 192.168.153.118:9092 --topic test
说明:早版本的Kafka,–broker-list 192.168.1.181:9092需改为–zookeeper 192.168.1.181:2181
运行consumer,可以看到刚才发送的消息列表。
bin/kafka-console-consumer.sh --zookeeper 192.168.153.118:2181 --topic test --from-beginning
注意:
producer,指定的Socket(192.168.1.181+9092),说明生产者的消息要发往kafka,也即是broker
consumer, 指定的Socket(192.168.1.181+2181),说明消费者的消息来自zookeeper(协调转发)
上面的只是一个单个的broker,下面我们来实验一个多broker的集群。
集群
搭建一个多个broker的伪集群,刚才只是启动了单个broker,现在启动有3个broker组成的集群,这些broker节点也都是在本机上。
1、为每一个broker提供配置文件
然后修改各个服务器的配置文件:进入Kafka的config目录,修改server.properties
# brokerid就是指各台服务器对应的id,所以各台服务器值不同
broker.id=0
# 端口号,无需改变
port=9092
# 当前服务器的IP,各台服务器值不同
host.name=192.168.0.10
# Zookeeper集群的ip和端口号
zookeeper.connect=192.168.0.10:2181,192.168.0.11:2181,192.168.0.12:2181
# 日志目录
log.dirs=/home/www/kafka-logs
我们先看看config/server0.properties配置信息:
broker.id=0
listeners=PLAINTEXT://:9092
port=9092
host.name=192.168.1.181
num.network.threads=4
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=5
num.recovery.threads.per.data.dir=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
log.cleaner.enable=false
zookeeper.connect=192.168.1.181:2181
zookeeper.connection.timeout.ms=6000
queued.max.requests =500
log.cleanup.policy = delete
说明:
broker.id为集群中唯一的标注一个节点,因为在同一个机器上,所以必须指定不同的端口和日志文件,避免数据被覆盖。
在上面单个broker的实验中,为什么kafka的端口为9092,这里可以看得很清楚。
kafka cluster怎么同zookeeper交互的,配置信息中也有体现。
那么下面,我们仿照上面的配置文件,提供2个broker的配置文件:
server2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
port=9094
host.name=192.168.1.181
num.network.threads=4
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs2
num.partitions=5
num.recovery.threads.per.data.dir=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
log.cleaner.enable=false
zookeeper.connect=192.168.1.181:2181
zookeeper.connection.timeout.ms=6000
queued.max.requests =500
log.cleanup.policy = delete
2、启动所有的broker
命令如下:
bin/kafka-server-start.sh config/server0.properties & #启动broker0
bin/kafka-server-start.sh config/server1.properties & #启动broker1
bin/kafka-server-start.sh config/server2.properties & #启动broker2
查看2181、9092、9093、9094端口
netstat -tunlp|egrep "(2181|9092|9093|9094)"
tcp 0 0 :::9093 :::* LISTEN 29725/java
tcp 0 0 :::2181 :::* LISTEN 19787/java
tcp 0 0 :::9094 :::* LISTEN 29800/java
tcp 0 0 :::9092 :::* LISTEN 29572/java
一个zookeeper在2181端口上监听,3个kafka cluster(broker)分别在端口9092,9093,9094监听。
3、创建topic
bin/kafka-topics.sh --create --topic topic_1 --partitions 1 --replication-factor 3 \--zookeeper localhost:2181
bin/kafka-topics.sh --create --topic topic_2 --partitions 1 --replication-factor 3 \--zookeeper localhost:2181
bin/kafka-topics.sh --create --topic topic_3 --partitions 1 --replication-factor 3 \--zookeeper localhost:2181
查看topic创建情况:
bin/kafka-topics.sh --list --zookeeper localhost:2181
test
topic_1
topic_2
topic_3
[root@atman081 kafka_2.10-0.9.0.0]# bin/kafka-topics.sh --describe --zookeeper localhost:2181
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:topic_1 PartitionCount:1 ReplicationFactor:3 Configs:
Topic: topic_1 Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic:topic_2 PartitionCount:1 ReplicationFactor:3 Configs:
Topic: topic_2 Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic:topic_3 PartitionCount:1 ReplicationFactor:3 Configs:
Topic: topic_3 Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
第一个行显示所有partitions的一个总结,以下每一行给出一个partition中的信息,如果我们只有一个partition,则只显示一行。
leader 是在给出的所有partitons中负责读写的节点,每个节点都有可能成为leader
replicas 显示给定partiton所有副本所存储节点的节点列表,不管该节点是否是leader或者是否存活。
isr 副本都已同步的的节点集合,这个集合中的所有节点都是存活状态,并且跟leader同步
4、模拟客户端发送,接受消息
发送消息
bin/kafka-console-producer.sh --topic topic_1 --broker-list 192.168.1.181:9092,192.168.1.181:9093,192.168.1.181:9094
接收消息
bin/kafka-console-consumer.sh --topic topic_1 --zookeeper 192.168.1.181:2181 --from-beginning
需要注意,此时producer将topic发布到了3个broker中,现在就有点分布式的概念了。
5、kill some broker
kill broker(id=0)
首先,我们根据前面的配置,得到broker(id=0)应该在9092监听,这样就能确定它的PID了。
broker0没kill之前topic在kafka cluster中的情况
bin/kafka-topics.sh --describe --zookeeper localhost:2181
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:topic_1 PartitionCount:1 ReplicationFactor:3 Configs:
Topic: topic_1 Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic:topic_2 PartitionCount:1 ReplicationFactor:3 Configs:
Topic: topic_2 Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic:topic_3 PartitionCount:1 ReplicationFactor:3 Configs:
Topic: topic_3 Partition: 0 Leader: 2 Replicas: 0,2,1 Isr: 2,1,0
kill之后,再观察,做下对比。很明显,主要变化在于Isr,以后再分析
bin/kafka-topics.sh --describe --zookeeper localhost:2181
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: -1 Replicas: 0 Isr:
Topic:topic_1 PartitionCount:1 ReplicationFactor:3 Configs:
Topic: topic_1 Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1
Topic:topic_2 PartitionCount:1 ReplicationFactor:3 Configs:
Topic: topic_2 Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2
Topic:topic_3 PartitionCount:1 ReplicationFactor:3 Configs:
Topic: topic_3 Partition: 0 Leader: 2 Replicas: 0,2,1 Isr: 2,1
测试下,发送消息,接受消息,是否收到影响。
发送消息
bin/kafka-console-producer.sh --topic topic_1 --broker-list 192.168.1.181:9092,192.168.1.181:9093,192.168.1.181:9094
接收消息
bin/kafka-console-consumer.sh --topic topic_1 --zookeeper 192.168.1.181:2181 --from-beginning
可见,kafka的分布式机制,容错能力还是挺好的~
Kafka常用命令
1、新建一个主题
bin/kafka-topics.sh --create --zookeeper hxf:2181,cfg:2181,jqs:2181,jxf:2181,sxtb:2181 --replication-factor 2 --partitions 2 --topic test
test有两个复制因子和两个分区
2、查看新建的主题
bin/kafka-topics.sh --describe --zookeeper hxf:2181,cfg:2181,jqs:2181,jxf:2181,sxtb:2181 --topic test
2.8.8版本
./kafka-create-topic.sh --partition 1 --replica 1 --zookeeper localhost:2181 --topic test
./kafka-list-topic.sh --zookeeper localhost:2181
我们来看一下查询的结果
[root@dx3 bin]# ./kafka-topics.sh --describe --zookeeper localhost:2183 --topic test
Topic:test PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,2,1
Topic: test Partition: 1 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: test Partition: 2 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
其中第一行是所有分区的信息,下面的每一行对应一个分区
Leader:负责某个分区所有读写操作的节点
Replicas:复制因子节点
Isr:存活节点
所以这个Kafka集群一共三个节点,test这个Topic, 编号为0的Partition,Leader在broker.id=0这个节点上,副本在broker.id为0 1 2这个三个几点,并且所有副本都存活,并跟broker.id=0这个节点同步
3、查看Kafka所有的主题
bin/kafka-topics.sh --list --zookeeper hxf:2181,cfg:2181,jqs:2181,jxf:2181,sxtb:2181
4、在终端发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
5、在终端接收(消费)消息
bin/kafka-console-consumer.sh --zookeeper hxf:2181,cfg:2181,jqs:2181,jxf:2181,sxtb:2181 --bootstrap-server localhost:9092 --topic test --from-beginning
我们正常情况下不会使用自带的命令行进行数据的发送和消费,我们都是使用第三方库进行客户端包括生产者和消费者的编码,实现业务的正常使用。
原理
先举一个例子
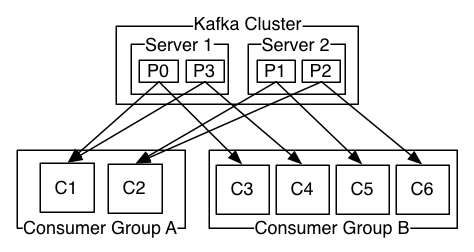
Kafka集群有两台服务器,四个分区,此外有两个消费者组A和B,消费者组A具有2个消费者实例C1-2,消费者B具有4个消费者实例C3-6
例如此时我们创建了一个主题test,有两个分区,分别是Server1的P0和Server2的P1,假设此时我们通过test发布了一条消息,那么这条消息只会发到P0或P1其中之一,也就是消息只会发给其中的一个分区
分区接收到消息后会记录在分区日志中,记录的方式我们讲过了,就是通过offset,分区中的消息都是以k-v形式存在。k表示offset,称之为偏移量,一个64位整型的唯一标识,offset代表了Topic分区中所有消息流中该消息的起始字节位置。 v就是实际的消息内容,正因为有这个偏移量的存在,所以一个分区内的消息是有先后顺序的,即offset大的消息比offset小的消息后到。但是注意,由于消息随机发往主题的任意一个分区,因此虽然同一个分区的消息有先后顺序,但是不同分区之间的消息就没有先后顺序了,那么如果我们要求消费者顺序消费主题发的消息那该怎么办呢,此时只要在创建主题的时候只提供一个分区即可
讲完了主题发消息,接下来就该消费者消费消息了,假设上面test的消息发给了分区P0,此时从图中可以看到,有两个消费者组,那么P0将会把消息发到哪个消费者组呢?从图中可以看到,P0把消息既发给了消费者组A也发给了B,但是A中消息仅被C1消费,B中消息仅被C3消费。这就是我们要讲的,主题发出的消息会发往所有的消费者组,而每一个消费者组下面可以有很多消费者实例,这条消息只会被他们中的一个消费掉。
在多分区的情况下如何保证有序性呢?
- 1、kafka分布式的单位是partition,同一个partition用一个write ahead log组织,记录的offset,所以可以保证FIFO的顺序。
- 2、不同partition之间不能保证顺序。但是绝大多数用户都可以通过message key来定义,因为同一个key的message可以保证只发送到同一个partition,比如说key是user id,table row id等等,所以同一个user或者同一个record的消息永远只会发送到同一个partition上,保证了同一个user或record的顺序。
- 3、消费出来自己根据一些数据进行排序,比如时间。
核心API
Kafka具有4个核心API:
- Producer API:用于向Kafka主题发送消息。
- Consumer API:用于从订阅主题接收消息并且处理这些消息。
- Streams API:作为一个流处理器,用于从一个或者多个主题中消费消息流然后为其他主题生产消息流,高效地将输入流转换为输出流。
- Connector API:用于构建和运行将Kafka主题和已有应用或者数据系统连接起来的可复用的生产者或消费者。例如一个主题到一个关系型数据库的连接能够捕获表的任意变化。
KAFKA吞吐量大的原因
1、消息顺序写入磁盘,并且批量处理。
KAFKA维护一个Topic中的分区log,以顺序追加的方式向各个分区中写入消息,每个分区都是不可变的消息队列。分区中的消息都是以k-v形式存在。
- k表示offset,称之为偏移量,一个64位整型的唯一标识,offset代表了Topic分区中所有消息流中该消息的起始字节位置。
- v就是实际的消息内容,每个分区中的每个offset都是唯一存在的,所有分区的消息都是一次写入,在消息未过期之前都可以调整offset来实现多次读取。
我们知道现在的磁盘大多数都还是机械结构(SSD不在讨论的范围内),如果将消息以随机写的方式存入磁盘,就会按柱面、磁头、扇区的方式进行(寻址过程),缓慢的机械运动(相对内存)会消耗大量时间,导致磁盘的写入速度只能达到内存写入速度的几百万分之一,为了规避随机写带来的时间消耗,KAFKA采取顺序写的方式存储数据。
新来的消息只能追加到已有消息的末尾,并且已经生产的消息不支持随机删除以及随机访问,但是消费者可以通过重置offset的方式来访问已经消费过的数据。
即使顺序读写,过于频繁的大量小I/O操作一样会造成磁盘的瓶颈,所以KAFKA在此处的处理是把这些消息集合在一起批量发送,这样减少对磁盘IO的过度读写,而不是一次发送单个消息。
2、标准化二进制消息格式
尤其是在负载比较高的情况下无效率的字节复制影响是显着的。为了避免这种情况,KAFKA采用由Producer,broker和consumer共享的标准化二进制消息格式,这样数据块就可以在它们之间自由传输,无需转换,降低了字节复制的成本开销。
同时,KAFKA采用了MMAP(Memory Mapped Files,内存映射文件)技术。很多现代操作系统都大量使用主存做磁盘缓存,一个现代操作系统可以将内存中的所有剩余空间用作磁盘缓存,而当内存回收的时候几乎没有性能损失。
由于KAFKA是基于JVM的,并且任何与Java内存使用打过交道的人都知道两件事:
- 对象的内存开销非常高,通常是实际要存储数据大小的两倍;
- 随着数据的增加,java的垃圾收集也会越来越频繁并且缓慢。
基于此,使用文件系统,同时依赖页面缓存就比使用其他数据结构和维护内存缓存更有吸引力:
- 不使用进程内缓存,就腾出了内存空间,可以用来存放页面缓存的空间几乎可以翻倍。
- 如果KAFKA重启,进行内缓存就会丢失,但是使用操作系统的页面缓存依然可以继续使用。
可能有人会问KAFKA如此频繁利用页面缓存,如果内存大小不够了怎么办?
KAFKA会将数据写入到持久化日志中而不是刷新到磁盘。实际上它只是转移到了内核的页面缓存。
利用文件系统并且依靠页缓存比维护一个内存缓存或者其他结构要好,它可以直接利用操作系统的页缓存来实现文件到物理内存的直接映射。完成映射之后对物理内存的操作在适当时候会被同步到硬盘上。
3、页缓存技术
为了优化读写性能,Kafka利用了操作系统本身的Page Cache,就是利用操作系统自身的内存而不是JVM空间内存。这样做的好处有:
- 避免Object消耗:如果是使用 Java 堆,Java对象的内存消耗比较大,通常是所存储数据的两倍甚至更多。
- 避免GC问题:随着JVM中数据不断增多,垃圾回收将会变得复杂与缓慢,使用系统缓存就不会存在GC问题
相比于使用JVM或in-memory cache等数据结构,利用操作系统的Page Cache更加简单可靠。首先,操作系统层面的缓存利用率会更高,因为存储的都是紧凑的字节结构而不是独立的对象。其次,操作系统本身也对于Page Cache做了大量优化,提供了 write-behind、read-ahead以及flush等多种机制。再者,即使服务进程重启,系统缓存依然不会消失,避免了in-process cache重建缓存的过程。
通过操作系统的Page Cache,Kafka的读写操作基本上是基于内存的,读写速度得到了极大的提升。
4、零拷贝
如下所示,数据从磁盘传输到socket要经过以下几个步骤:
- 操作系统将数据从磁盘读入到内核空间的页缓存
- 应用程序将数据从内核空间读入到用户空间缓存中
- 应用程序将数据写回到内核空间到socket缓存中
- 操作系统将数据从socket缓冲区复制到网卡缓冲区,以便将数据经网络发出
这里有四次拷贝,两次系统调用,这是非常低效的做法。如果使用sendfile,只需要一次拷贝就行
linux操作系统 “零拷贝” 机制使用了sendfile方法, 允许操作系统将数据从Page Cache 直接发送到网络,只需要最后一步的copy操作将数据复制到 NIC 缓冲区, 这样避免重新复制数据 。
通过这种 “零拷贝” 的机制,Page Cache 结合 sendfile 方法,Kafka消费端的性能也大幅提升。这也是为什么有时候消费端在不断消费数据时,我们并没有看到磁盘io比较高,此刻正是操作系统缓存在提供数据。
5、批量压缩
在很多情况下,系统的瓶颈不是CPU或磁盘,而是网络带宽,对于需要在广域网上的数据中心之间发送消息的数据流水线尤其如此。所以数据压缩就很重要。可以每个消息都压缩,但是压缩率相对很低。所以KAFKA使用了批量压缩,即将多个消息一起压缩而不是单个消息压缩。
KAFKA允许使用递归的消息集合,批量的消息可以通过压缩的形式传输并且在日志中也可以保持压缩格式,直到被消费者解压缩。
KAFKA支持Gzip和Snappy压缩协议。
6、批量读写
Kafka数据读写也是批量的而不是单条的。
除了利用底层的技术外,Kafka还在应用程序层面提供了一些手段来提升性能。最明显的就是使用批次。在向Kafka写入数据时,可以启用批次写入,这样可以避免在网络上频繁传输单个消息带来的延迟和带宽开销。假设网络带宽为10MB/S,一次性传输10MB的消息比传输1KB的消息10000万次显然要快得多。
KAFKA数据可靠性深度解读
KAFKA的消息保存在Topic中,Topic可分为多个分区,为保证数据的安全性,每个分区又有多个Replia。
多分区的设计的特点:
- 为了并发读写,加快读写速度;
- 是利用多分区的存储,利于数据的均衡;
- 是为了加快数据的恢复速率,一但某台机器挂了,整个集群只需要恢复一部分数据,可加快故障恢复的时间。
每个Partition分为多个Segment,每个Segment有.log和.index 两个文件,每个log文件承载具体的数据,每条消息都有一个递增的offset,Index文件是对log文件的索引,Consumer查找offset时使用的是二分法根据文件名去定位到哪个Segment,然后解析msg,匹配到对应的offset的msg。
Partition recovery过程
每个Partition会在磁盘记录一个RecoveryPoint,,记录已经flush到磁盘的最大offset。当broker 失败重启时,会进行loadLogs。首先会读取该Partition的RecoveryPoint,找到包含RecoveryPoint的segment及以后的segment, 这些segment就是可能没有完全flush到磁盘segments。然后调用segment的recover,重新读取各个segment的msg,并重建索引。每次重启KAFKA的broker时,都可以在输出的日志看到重建各个索引的过程。
数据同步
Producer和Consumer都只与Leader交互,每个Follower从Leader拉取数据进行同步。
如上图所示,ISR是所有不落后的replica集合,不落后有两层含义:距离上次FetchRequest的时间不大于某一个值或落后的消息数不大于某一个值,Leader失败后会从ISR中随机选取一个Follower做Leader,该过程对用户是透明的。
当Producer向Broker发送数据时,可以通过request.required.acks参数设置数据可靠性的级别。
此配置是表明当一次Producer请求被认为完成时的确认值。特别是,多少个其他brokers必须已经提交了数据到它们的log并且向它们的Leader确认了这些信息。
典型的值:
- 0: 表示Producer从来不等待来自broker的确认信息。这个选择提供了最小的时延但同时风险最大(因为当server宕机时,数据将会丢失)。
- 1:表示获得Leader replica已经接收了数据的确认信息。这个选择时延较小同时确保了server确认接收成功。
- -1:Producer会获得所有同步replicas都收到数据的确认。同时时延最大,然而,这种方式并没有完全消除丢失消息的风险,因为同步replicas的数量可能是1。如果你想确保某些replicas接收到数据,那么你应该在Topic-level设置中选项min.insync.replicas设置一下。
仅设置 acks= -1 也不能保证数据不丢失,当ISR列表中只有Leader时,同样有可能造成数据丢失。要保证数据不丢除了设置acks=-1,还要保证ISR的大小大于等于2。
具体参数设置:
- request.required.acks:设置为-1 等待所有ISR列表中的Replica接收到消息后采算写成功。
- min.insync.replicas: 设置为>=2,保证ISR中至少两个Replica。
- Producer:要在吞吐率和数据可靠性之间做一个权衡。
KAFKA作为现代消息中间件中的佼佼者,以其速度和高可靠性赢得了广大市场和用户青睐,其中的很多设计理念都是非常值得我们学习的,本文所介绍的也只是冰山一角,希望能够对大家了解KAFKA有一定的作用。
Kafka的应用场景
Kafka用作消息系统
Kafka流的概念与传统企业消息系统有什么异同?
传统消息系统有两个模型:队列和发布-订阅系统。在队列模式中,每条服务器的消息会被消费者池中的一个所读取;而发布-订阅系统中消息会广播给所有的消费者。这两种模式各有优劣。队列模式的优势是可以将消息数据让多个消费者处理以实现程序的可扩展,然而这就导致其没有多个订阅者,只能用于一个进程。发布-订阅模式的好处在于数据可以被多个进程消费使用,但是却无法使单一程序扩展性能
Kafka中消费者组的概念同时涵盖了这两方面。对应于队列的概念,Kafka中每个消费者组中有多个消费者实例可以接收消息;对应于发布-订阅模式,Kafka中可以指定多个消费者组来订阅消息
相对传统消息系统,Kafka可以提供更强的顺序保证
Kafka用作存储系统
任何发布消息与消费消息解耦的消息队列其实都可以看做是用来存放发布的消息的存储系统,而Kafka是一个非常高效的存储系统
写入Kafka的数据会被存入磁盘并且复制到集群中以容错。Kafka允许生产者等待数据完全复制并且确保持久化到磁盘的确认应答
Kafka使用的磁盘结构扩容性能很好——不管服务器上有50KB还是50TB,Kafka的表现都是一样的
由于能够精致的存储并且供客户端程序进行读操作,你可以把Kafka看做是一个用于高性能、低延迟的存储提交日志、复制及传播的分布式文件系统
Kafka的流处理
仅仅读、写、存储流数据是不够的,Kafka的目的是实现实时流处理。
在Kafka中一个流处理器的处理流程是首先持续性的从输入主题中获取数据流,然后对其进行一些处理,再持续性地向输出主题中生产数据流。例如一个销售商应用,接收销售和发货量的输入流,输出新订单和调整后价格的输出流
可以直接使用producer和consumer API进行简单的处理。对于复杂的转换,Kafka提供了更强大的Streams API。可构建聚合计算或连接流到一起的复杂应用程序
流处理有助于解决这类应用面临的硬性问题:处理无序数据、代码更改的再处理、执行状态计算等
Streams API所依托的都是Kafka的核心内容:使用producer和consumer API作为输入,使用Kafka作为状态存储,在流处理实例上使用相同的组机制来实现容错