搜索系统在我们日常生活中经常使用,比如baidu,google等,我们来看看其架构和原理。
全网搜索引擎架构
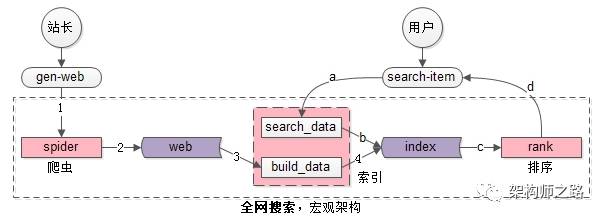
核心系统主要分为三部分:
- spider爬虫系统
- search&index建立索引与查询索引系统
- 一部分用于生成索引数据build_index
- 一部分用于查询索引数据search_index
- rank打分排序系统
核心数据主要分为两部分:
- web网页库
- index索引数据
核心流程:
写入
- spider把互联网网页抓过来
- spider把互联网网页存储到网页库中(这个对存储的要求很高,要存储几乎整个“万维网”的镜像)
- build_index从网页库中读取数据,完成分词
- build_index生成倒排索引
检索
- search_index获得用户的搜索词,完成分词
- search_index查询倒排索引,获得“字符匹配”网页,这是初筛的结果
- rank对初筛的结果进行打分排序
- rank对排序后的第一页结果返回
比如baidu,google就是全网搜索引擎架构,我们来看一下百度如何实现实时搜索十五分钟内的新闻的?
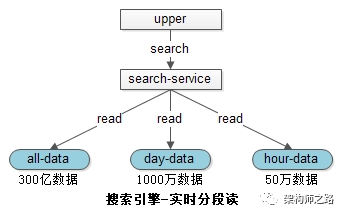
首先任何对数据的更新,并不会实时修改索引,一旦产生碎片,会大大降低检索效率。既然索引数据不能实时修改,如何保证最新的网页能够被索引到呢?
就是采用了将索引分为全量库、日增量库、小时增量库。比如
- 300亿数据在全量索引库中
- 1000万1天内修改过的数据在天库中
- 50万1小时内修改过的数据在小时库中
当有查询请求发生时,会同时查询各个级别的索引,将结果合并,得到最新的数据:
- 全量库是紧密存储的索引,无碎片,速度快
- 天库是紧密存储,速度快
- 小时库数据量小,速度也快
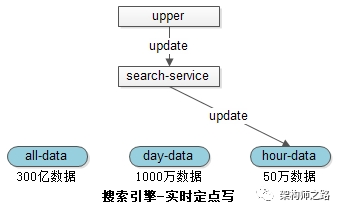
当有修改请求发生时,只会操作最低级别的索引,例如小时库。
数据库的同步
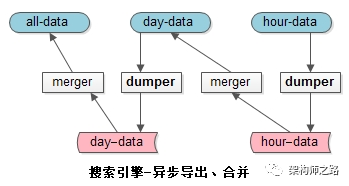
- dumper:将在线的数据导出
- merger:将离线的数据合并到高一级别的索引中去
- 小时库,一小时一次,合并到天库中去;
- 天库,一天一次,合并到全量库中去;
- 这样就保证了小时库和天库的数据量都不会特别大;
- 如果数据量和并发量更大,还能增加星期库,月库来缓冲。
数据的写入和读取都是实时的,所以58同城能够检索到1秒钟之前发布的帖子,即使全量库有300亿的数据。百度也能搜索到十五分钟内的数据。
站内搜索引擎架构
全网搜索需要spider要被动去抓取数据,站内搜索是内部系统生成的数据,例如“发布系统”会将生成的帖子主动推给build_data系统,看似“很小”的差异,架构实现上难度却差很多:全网搜索如何“实时”发现“全量”的网页是非常困难的,而站内搜索容易实时得到全部数据。
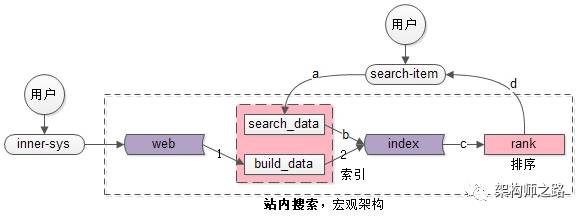
spider和search&index是相对工程的系统,rank是和业务、策略紧密、算法相关的系统,搜索体验的差异主要在此,而业务、策略的优化是需要时间积累的。
- Google的体验比Baidu好,根本在于前者rank牛逼
- 国内互联网公司短时间要搞一个体验超越Baidu的搜索引擎,是很难的,真心需要时间的积累
搜索原理
核心数据结构
正排索引(forward index)
由key查询实体的过程,是正排索引。比如
- 用户表:t_user(uid, name, passwd, age, sex),由uid查询整行的过程,就是正排索引查询。
- 网页库:t_web_page(url, page_content),由url查询整个网页的过程,也是正排索引查询。
举个例子,假设有3个网页:
url1 -> “我爱北京”
url2 -> “我爱到家”
url3 -> “到家美好”
这是一个正排索引Map
分词
分词就是将基本的词进行拆分,比如将上面的内容进行分词:
url1 -> {我,爱,北京}
url2 -> {我,爱,到家}
url3 -> {到家,美好}
这是一个分词后的正排索引Map
倒排索引(inverted index)
由item查询key的过程,是倒排索引。比如上面的网页进行倒排
分词后倒排索引:
我 -> {url1, url2}
爱 -> {url1, url2}
北京 -> {url1}
到家 -> {url2, url3}
美好 -> {url3}
由检索词item快速找到包含这个查询词的网页Map
正排索引和倒排索引是spider和build_index系统提前建立好的数据结构,为什么要使用这两种数据结构,是因为它能够快速的实现“用户网页检索”需求(业务需求决定架构实现)
基本搜索原理
假设搜索词是“我爱”,原理如下
- 分词,“我爱”会分词为{我,爱},时间复杂度为O(1)
每个分词后的item,从倒排索引查询包含这个item的网页list
,时间复杂度也是O(1): 我 -> {url1, url2} 爱 -> {url1, url2}求list
的交集,就是符合所有查询词的结果网页,对于这个例子,{url1, url2}就是最终的查询结果
核心就在于如何求两个子集的交集
- 循环遍历,土办法,时间复杂度O(n*n)
- 有序list求交集,拉链法,时间复杂度O(n)
- 分桶并行优化,多线程并行
- bitmap再次优化,大大提高运算并行度,时间复杂度O(n)
- 跳表skiplist,时间复杂度为O(log(n))
这些都是搜索引擎中常用的求交集的方法,可见搜索引擎中算法使用还是比较多的,其实引擎基本都是算法的天下。
搜索架构演进
原始阶段-LIKE
直接通过数据看的like关键词进行模糊匹配,能够快速满足业务需求,显然效率低,每次需要全表扫描,计算量大,并发高时cpu容易100%,而且不支持分词,很多查询不了。
初级阶段-全文索引
正常数据库查询的时候,我们一般都会想到给数据库建索引,然后用于查询,但是这情况情况也存在一些问题。
- 只适用于MyISAM
- 由于全文索引利用的是数据库特性,搜索需求和普通CURD需求耦合在数据库中:检索需求并发大时,可能影响CURD的请求;CURD并发大时,检索会非常的慢;
- 数据量达到百万级别,性能还是会显著降低,查询返回时间很长,业务难以接受
- 比较难水平扩展
中级阶段-开源外置索引
外置索引的核心思路是:索引数据与原始数据分离,前者满足搜索需求,后者满足CURD需求,通过一定的机制(双写,通知,定期重建)来保证数据的一致性。
Solr,Lucene,ES都是常见的开源方案。比如ES“封装一个接口友好的服务,屏蔽底层复杂性”
- ES是一个以Lucene为内核来实现搜索功能,提供REStful接口的服务
- ES能够支持很大数据量的信息存储,支持很高并发的搜索请求
- ES支持集群,向使用者屏蔽高可用/可扩展/负载均衡等复杂特性
ES完全能满足10亿数据量,5k吞吐量的常见搜索业务需求,强烈推荐。
高级阶段-自研搜索引擎
当数据量进一步增加,达到10亿、100亿数据量;并发量也进一步增加,达到每秒10万吞吐;业务个性也逐步增加的时候,就需要自研搜索引擎了,定制化实现搜索内核了。比如58同城的E-search,等等。
到了定制化自研搜索引擎的阶段,超大数据量、超高并发量为设计重点,为了达到“无限容量、无限并发”的需求,架构设计需要重点考虑“扩展性”,力争做到:增加机器就能扩容(数据量+并发量)。