Raft 实际上是一个一致性算法的一种实现,和Paxos等价,但是在实现上,简化了一些,并且更加易用。
一致性(consensus)
分布式存储系统通常通过维护多个副本来进行容错,提高系统的可用性。要实现此目标,就必须要解决分布式存储系统的最核心问题:维护多个副本的一致性。
首先需要解释一下什么是一致性(consensus),它是构建具有容错性(fault-tolerant)的分布式系统的基础。 在一个具有一致性的性质的集群里面,同一时刻所有的结点对存储在其中的某个值都有相同的结果,即对其共享的存储保持一致。集群具有自动恢复的性质,当少数结点失效的时候不影响集群的正常工作,当大多数集群中的结点失效的时候,集群则会停止服务(不会返回一个错误的结果)。
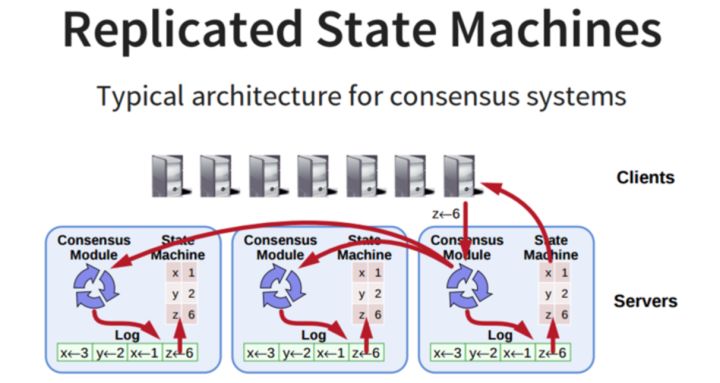
一致性协议就是用来干这事的,用来保证即使在部分(确切地说是小部分)副本宕机的情况下,系统仍然能正常对外提供服务。一致性协议通常基于replicated state machines,即所有结点都从同一个state出发,都经过同样的一些操作序列(log),最后到达同样的state。
对于一致性,一致的程度不同大体可以分为强、弱、最终一致性三类。
- 强一致性: 对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。比如小明更新V0到V1,那么小华读取的时候也应该是V1。
- 弱一致性: 如果能容忍后续的部分或者全部访问不到,则是弱一致性。比如小明更新VO到V1,可以容忍那么小华读取的时候是V0。
- 最终一致性: 如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。比如小明更新VO到V1,可以使得小华在一段时间之后读取的时候是V0。
raft协议实现的是多副本数据的强一致性。
RSM复制状态机(replicated state machine)
上面讲到了RSM,我们先来了解一下,一个分布式的复制状态机系统由多个复制单元组成,每个复制单元均是一个状态机,它的状态保存在一组状态变量中,状态机的变量只能通过外部命令来改变。简单理解的话,可以想象成是一组服务器,每个服务器是一个状态机,服务器的运行状态只能通过一行行的命令来改变。每一个状态机存储一个包含一系列指令的日志,严格按照顺序逐条执行日志中的指令,如果所有的状态机都能按照相同的日志执行指令,那么它们最终将达到相同的状态。因此,在复制状态机模型下,只要保证了操作日志的一致性,我们就能保证该分布式系统状态的一致性。
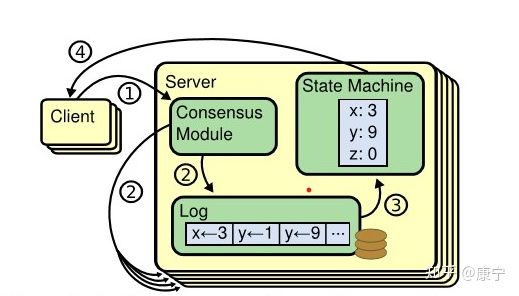
在上图中,服务器中的一致性模块(Consensus Modle)接受来自客户端的指令,并写入到自己的日志中,然后通过一致性模块和其他服务器交互,确保每一条日志都能以相同顺序写入到其他服务器的日志中,即便服务器宕机了一段时间。一旦日志命令都被正确的复制,每一台服务器就会顺序的处理命令,并向客户端返回结果。
系统中每个结点有三个组件:
- 状态机: 当我们说一致性的时候,实际就是在说要保证这个状态机的一致性。状态机会从log里面取出所有的命令,然后执行一遍,得到的结果就是我们对外提供的保证了一致性的数据
- Log: 保存了所有修改记录
- 一致性模块: 一致性模块算法就是用来保证写入的log的命令的一致性,这也是raft算法核心内容
为了让一致性协议变得简单可理解,Raft协议主要使用了两种策略。
- 一是将复杂问题进行分解,在Raft协议中,一致性问题被分解为:leader election、log replication、safety三个简单问题;
- 二是减少状态空间中的状态数目。
下面我们详细看一下Raft协议是怎样设计的。
基础概念
状态
Raft协议的每个副本都会处于三种状态之一:Leader、Follower、Candidate。
- Leader:所有请求的处理者,Leader副本接受client的更新请求,本地处理后再同步至多个其他副本;
- Follower:请求的被动更新者,从Leader接受更新请求,然后写入本地日志文件
- Candidate:如果Follower副本在一段时间内没有收到Leader副本的心跳,则判断Leader可能已经故障,此时启动选主过程,此时副本会变成Candidate状态,直到选主结束。
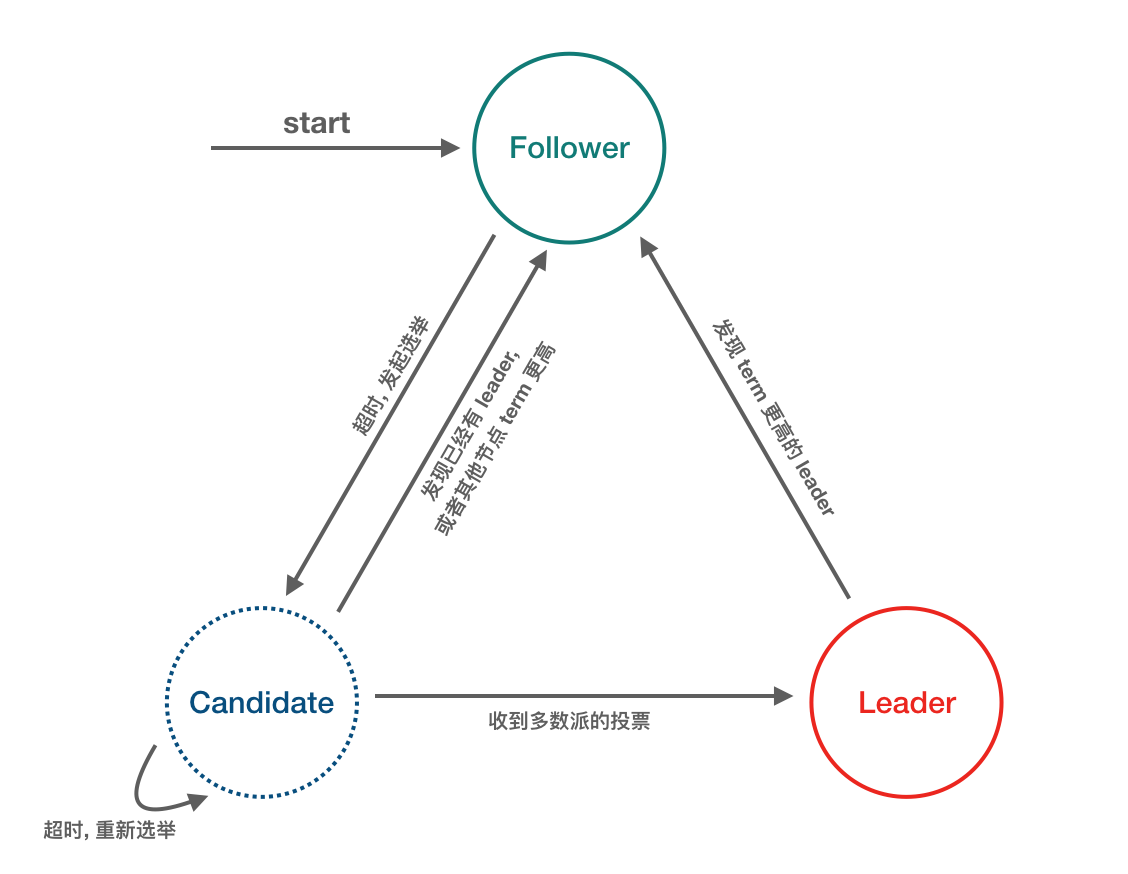
集群刚启动时,所有节点都是follower,之后在time out信号的驱使下,follower会转变成candidate去拉取选票,获得大多数选票后就会成为leader,这时候如果其他候选人发现了新的leader已经诞生,就会自动转变为follower;而如果另一个time out信号发出时,还没有选举出leader,将会重新开始一次新的选举。可见,time out信号是促使角色转换得关键因素,类似于操作系统中得中断信号。
term
在Raft协议中,将时间分成了一些任意长度的时间片,称为term,term使用连续递增的编号的进行识别,如下图所示:
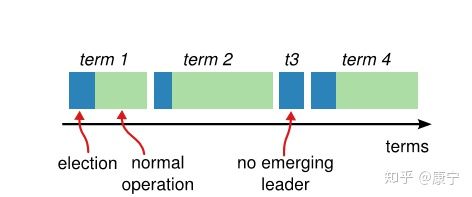
每一个term都从新的选举开始,candidate们会努力争取称为leader。一旦获胜,它就会在剩余的term时间内保持leader状态,在某些情况下(如term3)选票可能被多个candidate瓜分,形不成多数派,因此term可能直至结束都没有leader,下一个term很快就会到来重新发起选举。
term也起到了系统中逻辑时钟的作用,每一个server都存储了当前term编号,在server之间进行交流的时候就会带有该编号,如果一个server的编号小于另一个的,那么它会将自己的编号更新为较大的那一个;如果leader或者candidate发现自己的编号不是最新的了,就会自动转变为follower;如果接收到的请求的term编号小于自己的当前term将会拒绝执行。
其实就是这个server处于什么时间段的状态,然后用于对比,来处理当前的状态。
传输协议
server之间的交流是通过RPC进行的。只需要实现两种RPC就能构建一个基本的Raft集群:
- RequestVote RPC:它由选举过程中的candidate发起,用于拉取选票
- AppendEntries RPC:它由leader发起,用于复制日志或者发送心跳信号。


基本原理
Leader election
Raft通过心跳机制发起leader选举。节点都是从follower状态开始的,如果收到了来自leader或candidate的RPC,那它就保持follower状态,避免争抢成为candidate。Leader会发送空的AppendEntries RPC作为心跳信号来确立自己的地位,如果follower一段时间(election timeout)没有收到心跳,它就会认为leader已经挂了,发起新的一轮选举。
选举发起后
- Follower将自己维护的current_term_id加1。
- 然后将自己的状态转成Candidate
- 它会首先投自己一票,然后发送RequestVoteRPC消息(带上current_term_id) 给 其它所有server
这个过程会有三种结果:
- 自己被选成了主。当收到了majority的投票后,状态切成Leader,并且定期给其它的所有server发心跳消息(不带log的AppendEntriesRPC)以告诉对方自己是current_term_id所标识的term的leader。每个term最多只有一个leader,term id作为logical clock,在每个RPC消息中都会带上,用于检测过期的消息。当一个server收到的RPC消息中的rpc_term_id比本地的current_term_id更大时,就更新current_term_id为rpc_term_id,并且如果当前state为leader或者candidate时,将自己的状态切成follower。如果rpc_term_id比本地的current_term_id更小,则拒绝这个RPC消息。
- 别人成为了主。如1所述,当Candidator在等待投票的过程中,收到了大于或者等于本地的current_term_id的声明对方是leader的AppendEntriesRPC时,则将自己的state切成follower,并且更新本地的current_term_id。
- 没有选出主。当投票被平均瓜分,没有任何一个candidate收到了majority的vote时,没有leader被选出。这种情况下,每个candidate等待的投票的过程就超时了,接着candidates都会将本地的current_term_id再加1,发起RequestVoteRPC进行新一轮的leader election。
投票策略:
- 每个节点只会给每个term投一票,具体的是否同意和后续的Safety有关。
- 当投票被瓜分后,所有的candidate同时超时,然后有可能进入新一轮的票数被瓜分,为了避免这个问题,Raft采用一种很简单的方法:每个Candidate的election timeout从150ms-300ms之间随机取,那么第一个超时的Candidate就可以发起新一轮的leader election,带着最大的term_id给其它所有server发送RequestVoteRPC消息,从而自己成为leader,然后给他们发送心跳消息以告诉他们自己是主。
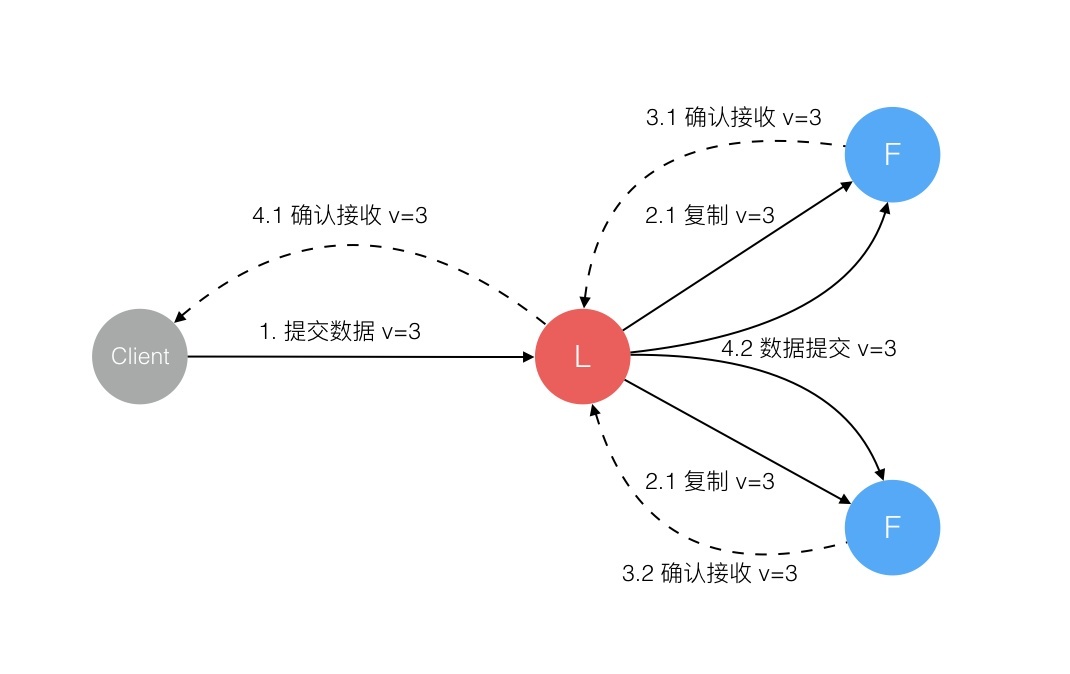
Log Replication
一旦leader被选举成功,就可以对客户端提供服务了。客户端提交每一条命令都会被按顺序记录到leader的日志中,每一条命令都包含term编号和顺序索引的结构体log entry,然后向其他节点并行发送AppendEntries RPC用以复制命令(如果命令丢失会不断重发),当复制成功也就是大多数节点成功复制后,leader就会提交命令,即执行该命令并且将执行结果返回客户端,raft保证已经提交的命令最终也会被其他节点成功执行。leader会保存有当前已经提交的最高日志编号。顺序性确保了相同日志索引处的命令是相同的,而且之前的命令也是相同的。当发送AppendEntries RPC时,会包含leader上一条刚处理过的命令,接收节点如果发现上一条命令不匹配,就会拒绝执行。
日志冲突
在这个过程中可能会出现一种特殊故障:如果leader崩溃了,它所记录的日志没有完全被复制,会造成日志不一致的情况,follower相比于当前的leader可能会丢失几条日志,也可能会额外多出几条日志,这种情况可能会持续几个term。如下图所示:
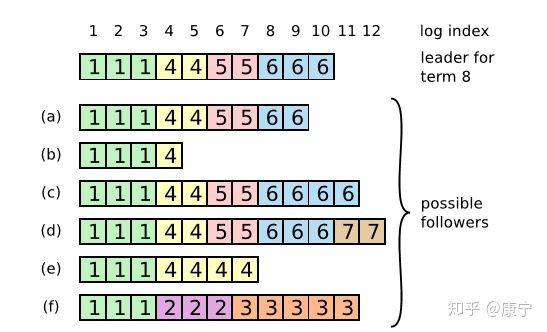
在上图中,框内的数字是term编号,a、b丢失了一些命令,c、d多出来了一些命令,e、f既有丢失也有增多,这些情况都有可能发生。比如f可能发生在这样的情况下:f节点在term2时是leader,在此期间写入了几条命令,然后再提交之前崩溃了,在之后的term3种它很快重启并再次成为leader,又写入了几条日志,在提交之前又崩溃了,等他苏醒过来时新的leader来了,就形成了上图情形。
因此,需要有一种机制来让leader和follower对log达成一致,在Raft中,leader通过强制follower复制自己的日志来解决上述日志不一致的情形,那么冲突的日志将会被重写。为了让日志一致,先找到最新的一致的那条日志(如f中索引为3的日志条目),然后把follower之后的日志全部删除,leader再把自己在那之后的日志一股脑推送给follower,这样就实现了一致。而寻找该条日志,可以通过AppendEntries RPC,该RPC中包含着下一次要执行的命令索引,如果能和follower的当前索引对上,那就执行,否则拒绝,然后leader将会逐次递减索引,直到找到相同的那条日志。
leader会为每个follower维护一个nextIndex,表示leader给各个follower发送的下一条log entry在log中的index,初始化为leader的最后一条log entry的下一个位置。leader给follower发送AppendEntriesRPC消息,带着(term_id, (nextIndex-1)), term_id即(nextIndex-1)这个槽位的log entry的term_id,follower接收到AppendEntriesRPC后,会从自己的log中找是不是存在这样的log entry,如果不存在,就给leader回复拒绝消息,然后leader则将nextIndex减1,再重复,知道AppendEntriesRPC消息被接收。
然而这样也还是会有问题,比如某个follower在leader提交时宕机了,也就是少了几条命令,然后它又经过选举成了新的leader,这样它就会强制其他follower跟自己一样,使得其他节点上刚刚提交的命令被删除,导致客户端提交的一些命令被丢失了,下面一节内容将会解决这个问题。Raft通过为选举过程添加一个限制条件,解决了上面提出的问题,该限制确保leader包含之前term已经提交过的所有命令。Raft通过投票过程确保只有拥有全部已提交日志的candidate能成为leader。由于candidate为了拉选票需要通过RequestVote RPC联系其他节点,而之前提交的命令至少会存在于其中某一个节点上,因此只要candidate的日志至少和其他大部分节点的一样新就可以了, follower如果收到了不如自己新的candidate的RPC,就会将其丢弃.
还可能会出现另外一个问题, 如果命令已经被复制到了大部分节点上,但是还没来的及提交就崩溃了,这样后来的leader应该完成之前term未完成的提交. Raft通过让leader统计当前term内还未提交的命令已经被复制的数量是否半数以上, 然后进行提交.
日志压缩
随着日志大小的增长,会占用更多的内存空间,处理起来也会耗费更多的时间,对系统的可用性造成影响,因此必须想办法压缩日志大小。Snapshotting是最简单的压缩方法,系统的全部状态会写入一个snapshot保存起来,然后丢弃截止到snapshot时间点之前的所有日志。Raft中的snapshot内容如下图所示:
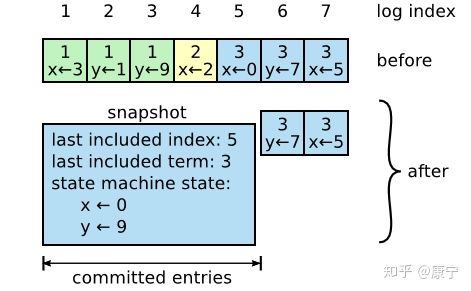
每一个server都有自己的snapshot,它只保存当前状态,如上图中的当前状态为x=0,y=9,而last included index和last included term代表snapshot之前最新的命令,用于AppendEntries的状态检查。
Snapshot中包含以下内容:
- 日志元数据,最后一条commited log entry的 (log index, last_included_term)。这两个值在Snapshot之后的第一条log entry的AppendEntriesRPC的consistency check的时候会被用上,之前讲过。一旦这个server做完了snapshot,就可以把这条记录的最后一条log index及其之前的所有的log entry都删掉。
- 系统状态机:存储系统当前状态(这是怎么生成的呢?)
虽然每一个server都保存有自己的snapshot,但是当follower严重落后于leader时,leader需要把自己的snapshot发送给follower加快同步,此时用到了一个新的RPC:InstallSnapshot RPC。follower收到snapshot时,需要决定如何处理自己的日志,如果收到的snapshot包含有更新的信息,它将丢弃自己已有的日志,按snapshot更新自己的状态,如果snapshot包含的信息更少,那么它会丢弃snapshot中的内容,但是自己之后的内容会保存下来。RPC的定义如下:

Safety
哪些follower有资格成为leader?
Raft保证被选为新leader的节点拥有所有已提交的log entry,这与ViewStamped Replication不同,后者不需要这个保证,而是通过其他机制从follower拉取自己没有的提交的日志记录 这个保证是在RequestVoteRPC阶段做的,candidate在发送RequestVoteRPC时,会带上自己的最后一条日志记录的term_id和index,其他节点收到消息时,如果发现自己的日志比RPC请求中携带的更新,拒绝投票。日志比较的原则是,如果本地的最后一条log entry的term id更大,则更新,如果term id一样大,则日志更多的更大(index更大)。
哪些日志记录被认为是commited?
leader正在replicate当前term(即term 2)的日志记录给其它Follower,一旦leader确认了这条log entry被majority写盘了,这条log entry就被认为是committed。如图a,S1作为当前term即term2的leader,log index为2的日志被majority写盘了,这条log entry被认为是commited leader正在replicate更早的term的log entry给其它follower。图b的状态是这么出来的。
对协议的一点修正
在实际的协议中,需要进行一些微调,这是因为可能会出现下面这种情况:
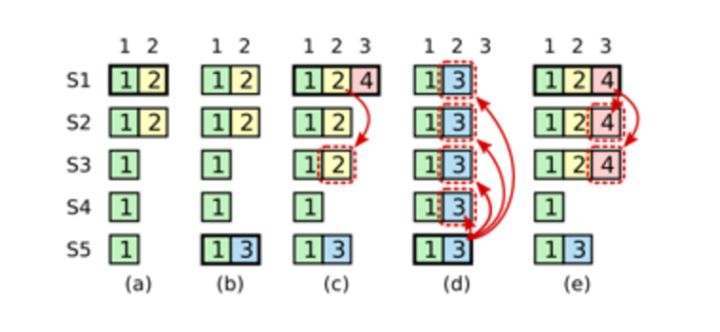
- 在阶段a,term为2,S1是Leader,且S1写入日志(term, index)为(2, 2),并且日志被同步写入了S2;
- 在阶段b,S1离线,触发一次新的选主,此时S5被选为新的Leader,此时系统term为3,且写入了日志(term, index)为(3, 2);
- S5尚未将日志推送到Followers变离线了,进而触发了一次新的选主,而之前离线的S1经过重新上线后被选中变成Leader,此时系统term为4,此时S1会将自己的日志同步到Followers,按照上图就是将日志(2, 2)同步到了S3,而此时由于该日志已经被同步到了多数节点(S1, S2, S3),因此,此时日志(2,2)可以被commit了(即更新到状态机);
- 在阶段d,S1又很不幸地下线了,系统触发一次选主,而S5有可能被选为新的Leader(这是因为S5可以满足作为主的一切条件:1. term = 3 > 2, 2. 最新的日志index为2,比大多数节点(如S2/S3/S4的日志都新),然后S5会将自己的日志更新到Followers,于是S2、S3中已经被提交的日志(2,2)被截断了,这是致命性的错误,因为一致性协议中不允许出现已经应用到状态机中的日志被截断。
为了避免这种致命错误,需要对协议进行一个微调:
只允许主节点提交包含当前term的日志
针对上述情况就是:即使日志(2,2)已经被大多数节点(S1、S2、S3)确认了,但是它不能被Commit,因为它是来自之前term(2)的日志,直到S1在当前term(4)产生的日志(4, 3)被大多数Follower确认,S1方可Commit(4,3)这条日志,当然,根据Raft定义,(4,3)之前的所有日志也会被Commit。此时即使S1再下线,重新选主时S5不可能成为Leader,因为它没有包含大多数节点已经拥有的日志(4,3)。
实战
raft在etcd中的实现
etcd 是一个被广泛应用于共享配置和服务发现的分布式、一致性的 kv 存储系统。作为分布式 kv,其底层使用的 是 raft 算法来实现多副本数据的强一致复制,etcd-raft 作为 raft 开源实现的杰出代表,在设计上,将 raft 算法逻辑和持久化、网络、线程等完全抽离出来单独实现,充分解耦,在工程上,实现了诸多性能优化,是 raft 开源实践中较早的工业级的实现,很多后来的 raft 实践者都直接或者间接的参考了 ectd-raft 的设计和实现,算是 raft 实现的一个典范。
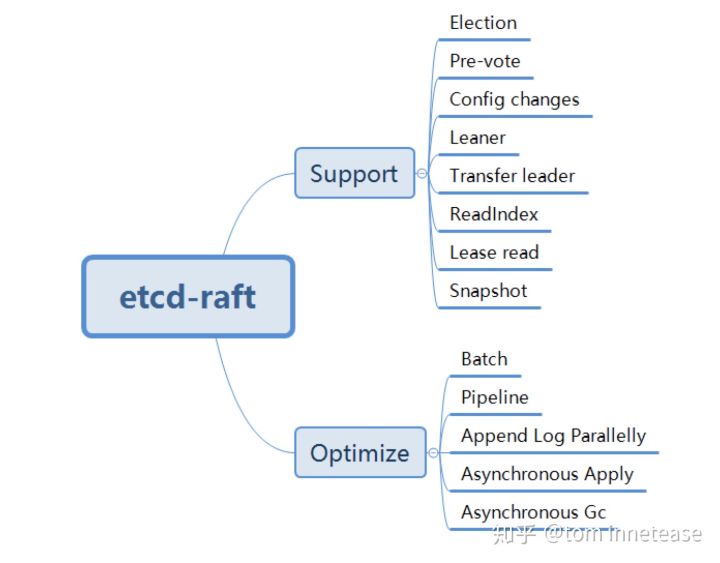
功能支持:
- Election(vote):选举
- Pre-vote:在发起 election vote 之前,先进行 pre-vote,可以避免在网络分区的情况避免反复的 election 打断当前 leader,触发新的选举造成可用性降低的问题
- Config changes:配置变更,增加,删除节点等
- Leaner:leaner 角色,仅参与 log replication,不参与投票和提交的 Op log entry,增加节点时,复制追赶 使用 leader 角色
- Transfer leader:主动变更 Leader,用于关机维护,leader 负载等
- ReadIndex:优化 raft read 走 Op log 性能问题,每次 read Op,仅记录 commit index,然后发送所有 peers heartbeat 确认 leader 身份,如果 leader 身份确认成功,等到 applied index >= commit index,就可以返回 client read 了
- Lease read:通过 lease 保证 leader 的身份,从而省去了 ReadIndex 每次 heartbeat 确认 leader 身份,性能更好,但是通过时钟维护 lease 本身并不是绝对的安全
- snapshot:raft 主动生成 snapshot,实现 log compact 和加速启动恢复,install snapshot 实现给 follower 拷贝数据等
从功能上,etcd-raft 完备的实现了 raft 几乎所需的功能。
性能优化:
- Batch:网络batch发送、batch持久化 Op log entries到WAL
- Pipeline:Leader 向 Follower 发送 Message 可以 pipeline 发送的(相对的 ping-pong 模式发送和接收)(pipeline 是grpc的一重要特性)
- Append Log Parallelly:Leader 发送 Op log entries message 给 Followers 和 Leader 持久化 Op log entries 是并行的
- Asynchronous Apply:由单独的 coroutine(协程) 负责异步的 Apply
- Asynchronous GC:WAL 和 snapshot 文件会分别开启单独的 coroutine 进行 GC
etcd-raft 几乎实现了 raft 大论文和工程上该有的性能优化,实际上 ReadIndex 和 Lease Read 本身也算是性能优化。
架构设计
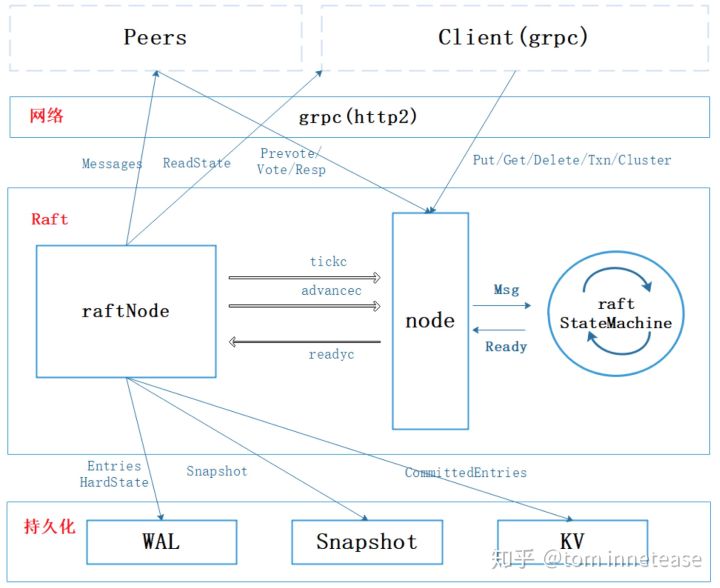
如上图,整个 etcd-server 的整体架构,其主要分为三层:
网络层
图中最上面一层是网络层,负责使用 grpc 收发 etcd-raft 和 client 的各种 messages,etcd-raft 会通过网络层收发各种 message,包括 raft append entries、vote、client 发送过来的 request,以及 response 等等,其都是由 rpc 的 coroutine 完成(PS:可以简单理解所有 messages 都是通过网络模块异步收发的)。
持久化层
图中最下面一层是持久化层,其提供了对 raft 各种数据的持久化存储,WAL - 持久化 raft Op log entries;Snapshot - 持久化 raft snapshot;KV - raft apply 的数据就是写入 kv 存储中,因为 etcd 是一个分布式的 kv 存储,所以,对 raft 来说,applied 的数据自然也就是写入到 kv 中。
Raft 层
中间这一层就是 raft 层,也是 etcd-raft 的核心实现。etcd 设计上将 raft 算法的逻辑和持久化、网络、线程(实际上是 coroutine)等完全解耦成一个单独的模块,拍脑袋思考下,将网络、持久化层抽离出来,并不难,但是如何将 raft 算法逻辑和网络、持久化、coroutine 完成解耦呢 ?
其核心的思路就是将 raft 所有算法逻辑实现封装成一个 StateMachine,也就是图中的 raft StateMachine,注意和 raft 复制状态机区别,这里 raft StateMachine 只是对 raft 算法的多个状态 (Leader、Follower、Candidate 等),多个阶段的一种代码实现,类似网络处理实现中也会通过一个 StateMachine 来实现网络 message 异步不同阶段的处理。
为了更加形象,这里以 client 发起 一个 put kv request 为例子,来看看 raft StateMachine 的输入、运转和输出,这里以 Leader 为例,分为如下阶段:
- 第一阶段:client 发送一个 put kv request 给 etcd server,grpc server 解析后,生成一个 Propose Message作为 raft StateMachine 输入,如果你驱动 raft StateMachine 运转,就会生成两个输出,一个需要写入 WAL 的 Op log entry,2 条发送给另外两个副本的 Append entries Msg,输出会封装在 Ready 结构中
- 第二阶段:如果把第一阶段的输出 WAL 写到了盘上,并且把 Append entries Msg 发送给了其他两个副本,那么两个副本会收到 Append entries Msg,持久化之后就会给 Leader 返回 Append entries Response Msg,etcd server 收到 Msg 之后,依然作为输入交给 raft StateMachine 处理,驱动 StateMachine 运转,如果超过大多数 response,那么就会产生输出:已经 commit 的 committed entries
- 第三阶段:外部将上面 raft StateMachine 输出 committed entries 拿到后,然后就可以返回 client put kv success 的 response 了
通过上面的例子展示了 raft StateMachine 输入,输出,运转的情况,尽管已经有了网络层和持久化层,但是,显然还缺少很多其的模块,例如:coroutine 驱动状态机运转,coroutine 将驱动网络发 message 和 持久化写盘等,下面介绍的raft 层的三个小模块就是完成这些事情的:
raft StateMachine
就是一个 raft 算法的逻辑实现,其输入统一被抽象成了 Msg,输出则统一封装在 Ready 结构中。
node(raft StateMachine 接口 - 输入+运转)
node 模块提供了如下功能:
- raft StateMachine 和外界交互的接口,就是提供ectd使用一致性协议算法的接口,供上层向 raft StateMachine 提交 request,也就是输入,已上面例子的 put kv request 为例,就是通过func (n *node) Propose(ctx context.Context, data []byte)接口向 raft StateMachine 提交一个 Propose,这个接口将用户请求转换成 raft StateMachine 认识的 MsgProp Msg,并通过 Channel 传递给驱动 raft StateMachine 运转的 coroutine;
- 提供驱动 raft 运转的 coroutine,其负责监听在各个 Msg 输入 Channel 中,一旦收到 Msg 就会调用 raft StateMachine 处理 Msg 接口 func (r *raft) Step(m pb.Message) 得到输出 Ready 结构,并将 Channel 传递给其他 coroutine 处理
raftNode(处理 raft StateMachine 输出 Ready)
raftNode 模块会有一个 coroutine,负责从处理 raft StateMachine 的输出 Ready 结构,该持久化的调用持久化的接口持久化,该发送其他副本的,通过网络接口发送给其他副本,该 apply 的提交给其他 coroutine apply。
交互架构
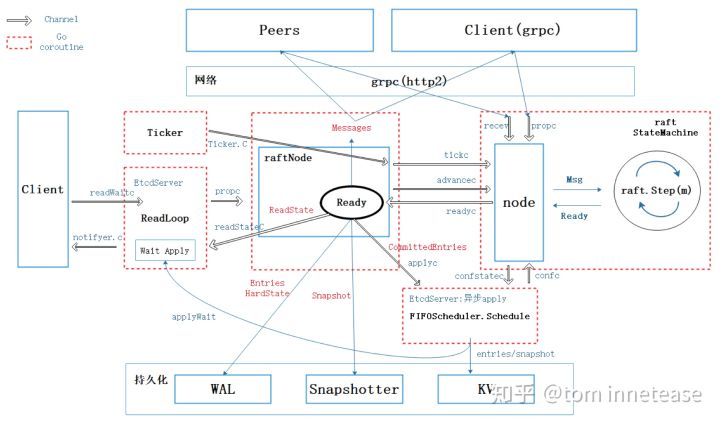
其中红色虚线框起来的代表一个 coroutine,下面将对各个协程的作用基本的描述
- Ticker:golang 的 Ticker struct 会定期触发 Tick 滴答时钟,etcd raft 的都是通过滴答时钟往前推进,从而触发相应的 heartbeat timeout 和 election timeout,从而触发发送心跳和选举。
- ReadLoop:这个 coroutine 主要负责处理 Read request,负责将 Read 请求通过 node 模块的 Propose 提交给 raft StateMachine,然后监听 raft StateMachine,一旦 raft StateMachine 完成 read 请求的处理,会通过 readStateC 通知 ReadLoop coroutine 此 read 的commit index,然后 ReadLoop coroutine 就可以根据当前 applied index 的推进情况,一旦 applied index >= commit index,ReadLoop coroutine 就会 Read 数据并通过网络返回 client read response
- raftNode:raftNode 模块会有一个 coroutine 负责处理 raft StateMachine 的输出 Ready,上文已经描述了,这里不在赘述
- node:node 模块也会有一个 coroutine 负责接收输入,运行状态机和准备输出,上文已经描述,这里不在赘述
- apply:raftNode 模块在 raft StateMachine 输出 Ready 中已经 committed entries 的时候,会将 apply 逻辑放在单独的 coroutine 处理,这就是 Async apply。
- GC:WAL 和 snapshot 的 GC 回收也都是分别在两个单独的 coroutine 中完成的。etcd 会在配置文中分别设置 WAL 和 snapshot 文件最大数量,然后两个 GC 后台异步 GC
代码分析
Etcd将raft协议实现为一个library,然后本身作为一个应用使用它。当然,可能是为了推广它所实现的这个library,etcd还额外提供了一个叫raftexample的示例程序,向用户展示怎样在它所提供的raft library的基础上构建出一个分布式的KV存储引擎。
我们来看看raft library,其实也就是raft层的实现。
$ tree --dirsfirst -L 1 -I '*test*' -P '*.go'
.
├── raftpb
├── doc.go
├── log.go
├── log_unstable.go
├── logger.go
├── node.go
├── progress.go
├── raft.go
├── rawnode.go
├── read_only.go
├── status.go
├── storage.go
└── util.go
我们来详细说明
raftpb
Raft中的序列化是借助于Protocol Buffer来实现的,这个文件夹就定义了需要序列化的几个数据结构,比如Entry和Message。
1、Entry
从整体上来说,一个集群中的每个节点都是一个状态机,而raft管理的就是对这个状态机进行更改的一些操作,这些操作在代码中被封装为一个个Entry。
// https://github.com/etcd-io/etcd/blob/v3.3.10/raft/raftpb/raft.pb.go#L203
type Entry struct {
Term uint64
Index uint64
Type EntryType
Data []byte
}
- Term:选举任期,每次选举之后递增1。它的主要作用是标记信息的时效性,比方说当一个节点发出来的消息中携带的term是2,而另一个节点携带的term是3,那我们就认为第一个节点的信息过时了。
- Index:当前这个entry在整个raft日志中的位置索引。有了Term和Index之后,一个log entry就能被唯一标识。
- Type:当前entry的类型,目前etcd支持两种类型:EntryNormal和EntryConfChange,EntryNormal代表当前Entry是对状态机的操作,EntryConfChange则代表对当前集群配置进行更改的操作,比如增加或者减少节点。
- Data:一个被序列化后的byte数组,代表当前entry真正要执行的操作,比方说如果上面的Type是EntryNormal,那这里的Data就可能是具体要更改的key-value pair,如果Type是EntryConfChange,那Data就是具体的配置更改项ConfChange。raft算法本身并不关心这个数据是什么,它只是把这段数据当做log同步过程中的payload来处理,具体对这个数据的解析则有上层应用来完成。
2、Message
Raft集群中节点之间的通讯都是通过传递不同的Message来完成的,这个Message结构就是一个非常general的大容器,它涵盖了各种消息所需的字段。
// https://github.com/etcd-io/etcd/blob/v3.3.10/raft/raftpb/raft.pb.go#L239
type Message struct {
Type MessageType
To uint64
From uint64
Term uint64
LogTerm uint64
Index uint64
Entries []Entry
Commit uint64
Snapshot Snapshot
Reject bool
RejectHint uint64
Context []byte
}
Type:当前传递的消息类型,它的取值有很多个,但大致可以分成两类:
- Raft 协议相关的,包括心跳MsgHeartbeat、日志MsgApp、投票消息MsgVote等。
- 上层应用触发的(没错,上层应用并不是通过api与raft库交互的,而是通过发消息),比如应用对数据更改的消息MsgProp(osal)。
所有的 Msg 在 bp.Message 中详细定义,下面给出所有的 message 类型并且依次介绍:
const ( MsgHup MessageType = 0 // 本地消息:选举,可能会触发 pre-vote 或者 vote MsgBeat MessageType = 1 // 本地消息:心跳,触发放给 peers 的 Msgheartbeat MsgProp MessageType = 2 // 本地消息:Propose,触发 MsgApp MsgApp MessageType = 3 // 非本地:Op log 复制/配置变更 request MsgAppResp MessageType = 4 // 非本地:Op log 复制 response MsgVote MessageType = 5 // 非本地:vote request MsgVoteResp MessageType = 6 // 非本地:vote response MsgSnap MessageType = 7 // 非本地:Leader 向 Follower 拷贝 Snapshot,response Message 就是 MsgAppResp,通过这个值告诉 Leader 继续复制后面的日志 MsgHeartbeat MessageType = 8 // 非本地:心跳 request MsgHeartbeatResp MessageType = 9 // 非本地:心跳 response MsgUnreachable MessageType = 10 // 本地消息:EtcdServer 通过这个消息告诉 raft 状态某个 Follower 不可达,让其发送 message方式由 pipeline 切成 ping-pong 模式 MsgSnapStatus MessageType = 11 // 本地消息:EtcdServer 通过这个消息告诉 raft 状态机 snapshot 发送成功还是失败 MsgCheckQuorum MessageType = 12 // 本地消息:CheckQuorum,用于 Lease read,Leader lease MsgTransferLeader MessageType = 13 // 本地消息:可能会触发一个空的 MsgApp 尽快完成日志复制,也有可能是 MsgTimeoutNow 出 Transferee 立即进入选举 MsgTimeoutNow MessageType = 14 // 非本地:触发 Transferee 立即进行选举 MsgReadIndex MessageType = 15 // 非本地:Read only ReadIndex MsgReadIndexResp MessageType = 16 // 非本地:Read only ReadIndex response MsgPreVote MessageType = 17 // 非本地:pre vote request MsgPreVoteResp MessageType = 18 // 非本地:pre vote response )不同类型的消息会用到下面不同的字段:
- To, From分别代表了这个消息的接受者和发送者。
- Term:这个消息发出时整个集群所处的任期。
- LogTerm:消息发出者所保存的日志中最后一条的任期号,一般MsgVote会用到这个字段。
- Index:日志索引号。如果当前消息是MsgVote的话,代表这个candidate最后一条日志的索引号,它跟上面的LogTerm一起代表这个candidate所拥有的最新日志信息,这样别人就可以比较自己的日志是不是比candidata的日志要新,从而决定是否投票。
- Entries:需要存储的日志。
- Commit:已经提交的日志的索引值,用来向别人同步日志的提交信息。
- Snapshot:一般跟MsgSnap合用,用来放置具体的Snapshot值。
- Reject,RejectHint:代表对方节点拒绝了当前节点的请求(MsgVote/MsgApp/MsgSnap…)
log_unstable.go
log_unstable顾名思义,unstable数据结构用于还没有被用户层持久化的数据,它维护了两部分内容snapshot和entries:
// https://github.com/etcd-io/etcd/blob/v3.3.10/raft/log_unstable.go#L23
type unstable struct {
// the incoming unstable snapshot, if any.
snapshot *pb.Snapshot
// all entries that have not yet been written to storage.
entries []pb.Entry
offset uint64
logger Logger
}
- entries代表的是要进行操作的日志
- snapshot代表快照数据
两者的关系是相辅相成的,共同组成了全部的数据,如下图
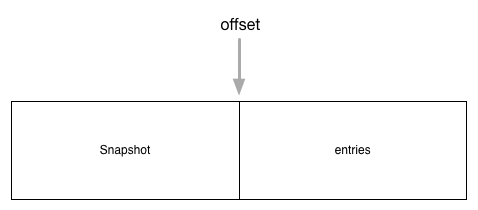
这里的前半部分是快照数据,而后半部分是日志条目组成的数组entries,另外unstable.offset成员保存的是entries数组中的第一条数据在raft日志中的索引,即第i条entries在raft日志中的索引为i + unstable.offset。在同步的时候,如果entries日志不能完全同步,就需要使用到snapshot。
storage.go
这个文件定义了一个Storage接口,因为etcd中的raft实现并不负责数据的持久化,所以它希望上面的应用层能实现这个接口,以便提供给它查询log的能力。
另外,这个文件也提供了Storage接口的一个内存版本的实现MemoryStorage,这个实现同样也维护了snapshot和entries这两部分,他们的排列跟unstable中的类似,也是snapshot在前,entries在后。
log.go
这边主要实现raftLog,这个结构体承担了raft日志相关的操作。
raftLog由以下成员组成:
- storage Storage:前面提到的存放已经持久化数据的Storage接口。
- unstable unstable:前面分析过的unstable结构体,用于保存应用层还没有持久化的数据。
- committed uint64:保存当前提交的日志数据索引。
- applied uint64:保存当前传入状态机的数据最高索引。
raftLog结构体中,几部分数据的排列如下图所示
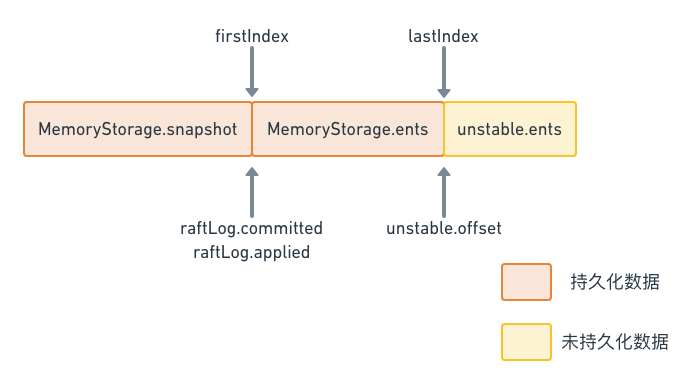
这个数据排布的情况,可以从raftLog的初始化函数中看出来:
// https://github.com/etcd-io/etcd/blob/v3.3.10/raft/log.go#L45
// newLog returns log using the given storage. It recovers the log to the state
// that it just commits and applies the latest snapshot.
func newLog(storage Storage, logger Logger) *raftLog {
if storage == nil {
log.Panic("storage must not be nil")
}
log := &raftLog{
storage: storage,
logger: logger,
}
firstIndex, err := storage.FirstIndex()
if err != nil {
panic(err) // TODO(bdarnell)
}
lastIndex, err := storage.LastIndex()
if err != nil {
panic(err) // TODO(bdarnell)
}
log.unstable.offset = lastIndex + 1
log.unstable.logger = logger
// Initialize our committed and applied pointers to the time of the last compaction.
log.committed = firstIndex - 1
log.applied = firstIndex - 1
return log
}
从这里的代码可以看出,raftLog的两部分,持久化存储和非持久化存储,它们之间的分界线就是lastIndex,在此之前都是Storage管理的已经持久化的数据,而在此之后都是unstable管理的还没有持久化的数据。
progress.go
Leader通过Progress这个数据结构来追踪一个follower的状态,并根据Progress里的信息来决定每次同步的日志项。这里介绍三个比较重要的属性:
// https://github.com/etcd-io/etcd/blob/v3.3.10/raft/progress.go#L37
// Progress represents a follower’s progress in the view of the leader. Leader maintains
// progresses of all followers, and sends entries to the follower based on its progress.
type Progress struct {
Match, Next uint64
State ProgressStateType
ins *inflights
}
- 用来保存当前follower节点的日志状态的属性
- Match:保存目前为止,已复制给该follower的日志的最高索引值。如果leader对该follower上的日志情况一无所知的话,这个值被设为0。
- Next:保存下一次leader发送append消息给该follower的日志索引,即下一次复制日志时,leader会从Next开始发送日志。 在正常情况下,Next = Match + 1,也就是下一个要同步的日志应当是对方已有日志的下一条。
- State属性用来保存该节点当前的同步状态,它会有一下几种取值
- ProgressStateProbe 探测状态,当follower拒绝了最近的append消息时,那么就会进入探测状态,此时leader会试图继续往前追溯该follower的日志从哪里开始丢失的。在probe状态时,leader每次最多append一条日志,如果收到的回应中带有RejectHint信息,则回退Next索引,以便下次重试。在初始时,leader会把所有follower的状态设为probe,因为它并不知道各个follower的同步状态,所以需要慢慢试探。
- ProgressStateReplicate 当leader确认某个follower的同步状态后,它就会把这个follower的state切换到这个状态,并且用pipeline的方式快速复制日志。leader在发送复制消息之后,就修改该节点的Next索引为发送消息的最大索引+1。
- ProgressStateSnapshot 接收快照状态。当leader向某个follower发送append消息,试图让该follower状态跟上leader时,发现此时leader上保存的索引数据已经对不上了,比如leader在index为10之前的数据都已经写入快照中了,但是该follower需要的是10之前的数据,此时就会切换到该状态下,发送快照给该follower。当快照数据同步追上之后,并不是直接切换到Replicate状态,而是首先切换到Probe状态。
- ins属性用来做流量控制,因为如果同步请求非常多,再碰上网络分区时,leader可能会累积很多待发送消息,一旦网络恢复,可能会有非常大流量发送给follower,所以这里要做flow control。它的实现有点类似TCP的滑动窗口,这里不再赘述。
Progress其实也是个状态机,下面是它的状态转移图:
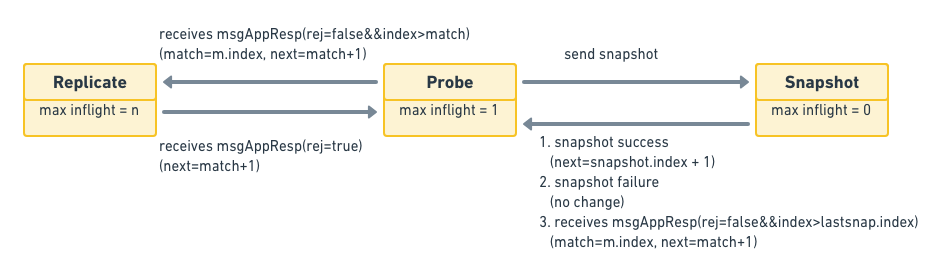
raft.go
raft协议的具体实现就在这个文件里。这其中,大部分的逻辑是由Step函数驱动的。
// https://github.com/etcd-io/etcd/blob/v3.3.10/raft/raft.go#L752
func (r *raft) Step(m pb.Message) error {
//...
switch m.Type {
case pb.MsgHup:
//...
case pb.MsgVote, pb.MsgPreVote:
//...
default:
r.step(r, m)
}
}
Step的主要作用是处理不同的消息,调用不同的处理函数,step属性是一个函数指针,根据当前节点的不同角色,指向不同的消息处理函数:stepLeader/stepFollower/stepCandidate。与它类似的还有一个tick函数指针,根据角色的不同,也会在tickHeartbeat和tickElection之间来回切换,分别用来触发定时心跳和选举检测。
node.go
node其实就是消息通道,or-select-channel组成的事件循环。
node的主要作用是应用层(etcdserver)和共识模块(raft)的衔接。将应用层的消息传递给底层共识模块,并将底层共识模块共识后的结果反馈给应用层。所以它的初始化函数创建了很多用来通信的channel,然后就在另一个goroutine里面开始了事件循环,不停的在各种channel中倒腾数据。
// https://github.com/etcd-io/etcd/blob/v3.3.10/raft/node.go#L286
for {
select {
case m := <-propc:
r.Step(m)
case m := <-n.recvc:
r.Step(m)
case cc := <-n.confc:
// Add/remove/update node according to cc.Type
case <-n.tickc:
r.tick()
case readyc <- rd:
// Cleaning after result is consumed by application
case <-advancec:
// Stablize logs
case c := <-n.status:
// Update status
case <-n.stop:
close(n.done)
return
}
}
输入(msg):propc和recvc中拿到的是从上层应用传进来的消息,这个消息会被交给raft层的Step函数处理。
所有的外部处理请求经过 raft StateMachine 处理都会首先被转换成统一抽象的输入 Message(Msg),Msg 会通过 raft.Step(m) 接口完成 raft StateMachine 的处理,Msg 分两类:
- 本地 Msg,term = 0,这种 Msg 并不会经过网络发送给 Peer,只是将 Node 接口的一些请求转换成 raft StateMachine 统一处理的抽象 Msg,这里以 Propose 接口为例,向 raft 提交一个 Op 操作,其会被转换成 MsgProp,通过 raft.Step() 传递给 raft StateMachine,最后可能被转换成给 Peer 复制 Op log 的 MsgApp Msg;(即发送给本地peer的消息)
- 非本地 Msg,term 非 0,这种 Msg 会经过网络发送给 Peer;这里以 Msgheartbeat 为例子,就是 Leader 给 Follower 发送的心跳包。但是这个 MsgHeartbeat Msg 是通过 Tick 接口传入的,这个接口会向 raft StateMachine 传递一个 MsgBeat Msg,raft StateMachine 处理这个 MsgBeat 就是向复制组其它 Peer 分别发送一个 MsgHeartbeat Msg
具体的类型我们在上面的结构体定义的时候已经说明过了。
输出(ready):readyc这个channel对外通知有数据要处理了,并将这些需要外部处理的数据打包到一个Ready结构体中,其实就是底层消息传递到应用层。
由于 etcd 的网络、持久化模块和 raft 核心是分离的,所以当 raft 处理到某一些阶段的时候,需要输出一些东西,给外部处理,例如 Op log entries 持久化,Op log entries 复制的 Msg 等;以 heartbeat 为例,输入是 MsgBeat Msg,经过状态机状态化之后,就变成了给复制组所有的 Peer 发送心跳的 MsgHeartbeat Msg;在 ectd 中就是通过一个 Ready 的数据结构来封装当前 Raft state machine 已经准备好的数据和 Msg 供外部处理。
我们来看看这个Ready结构
// https://github.com/etcd-io/etcd/blob/v3.3.10/raft/node.go#L52
// Ready encapsulates the entries and messages that are ready to read,
// be saved to stable storage, committed or sent to other peers.
// All fields in Ready are read-only.
type Ready struct {
// The current volatile state of a Node.
// SoftState will be nil if there is no update.
// It is not required to consume or store SoftState.
*SoftState
// The current state of a Node to be saved to stable storage BEFORE
// Messages are sent.
// HardState will be equal to empty state if there is no update.
pb.HardState
// ReadStates can be used for node to serve linearizable read requests locally
// when its applied index is greater than the index in ReadState.
// Note that the readState will be returned when raft receives msgReadIndex.
// The returned is only valid for the request that requested to read.
ReadStates []ReadState
// Entries specifies entries to be saved to stable storage BEFORE
// Messages are sent.
Entries []pb.Entry
// Snapshot specifies the snapshot to be saved to stable storage.
Snapshot pb.Snapshot
// CommittedEntries specifies entries to be committed to a
// store/state-machine. These have previously been committed to stable
// store.
CommittedEntries []pb.Entry
// Messages specifies outbound messages to be sent AFTER Entries are
// committed to stable storage.
// If it contains a MsgSnap message, the application MUST report back to raft
// when the snapshot has been received or has failed by calling ReportSnapshot.
Messages []pb.Message
// MustSync indicates whether the HardState and Entries must be synchronously
// written to disk or if an asynchronous write is permissible.
MustSync bool
}
Ready 是 raft 状态机和外面交互传递的核心数据结构,其包含了一批更新操作
SoftState:当前 node 的状态信息,主要记录了 Leader 是谁 ?当前 node 处于什么状态,是 Leader,还是 Follower,用于更新 etcd server 的状态
// SoftState provides state that is useful for logging and debugging. // The state is volatile and does not need to be persisted to the WAL. type SoftState struct { Lead uint64 // must use atomic operations to access; keep 64-bit aligned. RaftState StateType } type StateType uint64 var stmap = [...]string{ "StateFollower", "StateCandidate", "StateLeader", "StatePreCandidate", }pb.HardState: 包含当前节点见过的最大的 term,以及在这个 term 给谁投过票,以及当前节点知道的commit index,这部分数据会持久化
type HardState struct { Term uint64 protobuf:"varint,1,opt,name=term" json:"term" Vote uint64 protobuf:"varint,2,opt,name=vote" json:"vote" Commit uint64 protobuf:"varint,3,opt,name=commit" json:"commit" XXX_unrecognized []byte json:"-" }ReadStates:用于返回已经确认 Leader 身份的 read 请求的 commit index
Messages: 需要广播给所有peers的消息
CommittedEntries:已经commit了,还没有apply到状态机的日志
Snapshot:需要持久化的快照
应用程序得到这个Ready之后,需要:
- 将HardState, Entries, Snapshot持久化到storage。
- 将Messages广播给其他节点。
- 将CommittedEntries(已经commit还没有apply)应用到状态机。
- 如果发现CommittedEntries中有成员变更类型的entry,调用node.ApplyConfChange()方法让node知道。
- 最后再调用node.Advance()告诉raft,这批状态更新处理完了,状态已经演进了,可以给我下一批Ready让我处理。
基本实现
投票流程
1、首先,在node的大循环里,有一个会定时输出的tick channel,它来触发raft.tick()函数,根据上面的介绍可知,如果当前节点是follower,那它的tick函数会指向tickElection。tickElection的处理逻辑是给自己发送一个MsgHup的内部消息,Step函数看到这个消息后会调用campaign函数,进入竞选状态。
// tickElection is run by followers and candidates after r.electionTimeout.
func (r *raft) tickElection() {
r.electionElapsed++
if r.promotable() && r.pastElectionTimeout() {
r.electionElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgHup})
}
}
func (r *raft) Step(m pb.Message) error {
//...
switch m.Type {
case pb.MsgHup:
r.campaign(campaignElection)
}
}
2、campaign则会调用becomeCandidate把自己切换到candidate模式,并递增Term值。然后再将自己的Term及日志信息发送给其他的节点,请求投票。
func (r *raft) campaign(t CampaignType) {
//...
r.becomeCandidate()
// Get peer id from progress
for id := range r.prs {
//...
r.send(pb.Message{Term: term, To: id, Type: voteMsg, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx})
}
}
3、另一方面,其他节点在接受到这个请求后,会首先比较接收到的Term是不是比自己的大,以及接受到的日志信息是不是比自己的要新,从而决定是否投票。在对应节点的step函数中有对投票请求这种消息的处理逻辑。
func (r *raft) Step(m pb.Message) error {
//...
switch m.Type {
case pb.MsgVote, pb.MsgPreVote:
// We can vote if this is a repeat of a vote we've already cast...
canVote := r.Vote == m.From ||
// ...we haven't voted and we don't think there's a leader yet in this term...
(r.Vote == None && r.lead == None) ||
// ...or this is a PreVote for a future term...
(m.Type == pb.MsgPreVote && m.Term > r.Term)
// ...and we believe the candidate is up to date.
if canVote && r.raftLog.isUpToDate(m.Index, m.LogTerm) {
r.send(pb.Message{To: m.From, Term: m.Term, Type: voteRespMsgType(m.Type)})
} else {
r.send(pb.Message{To: m.From, Term: r.Term, Type: voteRespMsgType(m.Type), Reject: true})
}
}
}
4、最后当candidate节点收到投票回复后,就会计算收到的选票数目是否大于所有节点数的一半,如果大于则自己成为leader,并昭告天下,否则将自己置为follower,同样是在即自己的step的逻辑中处理投票恢复的消息逻辑。
func (r *raft) Step(m pb.Message) error {
//...
switch m.Type {
case myVoteRespType:
gr := r.poll(m.From, m.Type, !m.Reject)
switch r.quorum() {
case gr:
if r.state == StatePreCandidate {
r.campaign(campaignElection)
} else {
r.becomeLeader()
r.bcastAppend()
}
case len(r.votes) - gr:
r.becomeFollower(r.Term, None)
}
}
put kv 请求
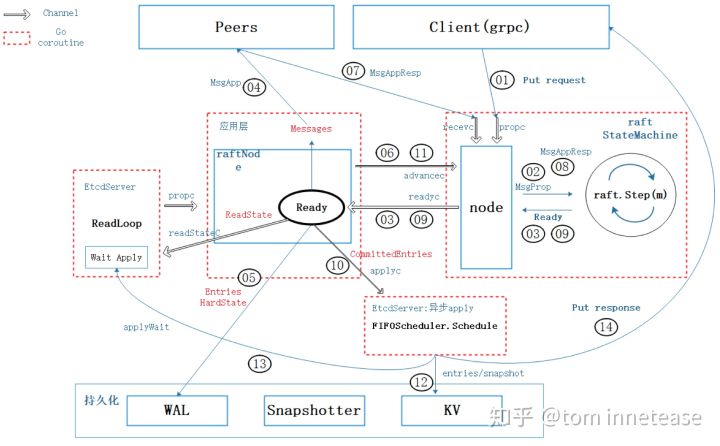
- client 通过 grpc 发送一个 Put kv request,etcd server 的 rpc server 收到这个请求,通过 node 模块的 Propose 接口提交,node 模块的Propose方法将这个 Put kv request 转换成 raft StateMachine 认识的 MsgProp Msg 并通过 propc Channel 传递给 node 模块的 coroutine;
- node 模块 coroutine 监听在 propc Channel 中,收到 MsgProp Msg 之后,通过 raft.Step(Msg) 接口将其提交给 raft StateMachine 处理;
- raft StateMachine 处理完这个 MsgProp Msg 会产生 1 个 Op log entry 和 2 个发送给另外两个副本的 Append entries 的 MsgApp messages,node 模块会将这两个输出打包成 Ready,然后通过 readyc Channel 传递给 raftNode 模块的 coroutine;
- raftNode 模块的 coroutine 通过 readyc 读取到 Ready,首先通过网络层将 2 个 append entries 的 messages 发送给两个副本(PS:这里是异步发送的);
- raftNode 模块的 coroutine 自己将 Op log entry 通过持久化层的 WAL 接口同步的写入 WAL 文件中
- raftNode 模块的 coroutine 通过 advancec Channel 通知当前 Ready 已经处理完,请给我准备下一个 带出的 raft StateMachine 输出Ready;
- 其他副本的返回 Append entries 的 response: MsgAppResp message,会通过 node 模块的接口经过 recevc Channel 提交给 node 模块的 coroutine;
- node 模块 coroutine 从 recev Channel 读取到 MsgAppResp,然后提交给 raft StateMachine 处理。node 模块 coroutine 会驱动 raft StateMachine 得到关于这个 committedEntires,也就是一旦大多数副本返回了就可以 commit 了,node 模块 new 一个新的 Ready其包含了 committedEntries,通过 readyc Channel 传递给 raftNode 模块 coroutine 处理;
- raftNode 模块 coroutine 从 readyc Channel 中读取 Ready结构,然后取出已经 commit 的 committedEntries 通过 applyc 传递给另外一个 etcd server coroutine 处理,其会将每个 apply 任务提交给 FIFOScheduler 调度异步处理,这个调度器可以保证 apply 任务按照顺序被执行,因为 apply 的执行是不能乱的;
- raftNode 模块的 coroutine 通过 advancec Channel 通知当前 Ready 已经处理完,请给我准备下一个待处理的 raft StateMachine 输出Ready;
- FIFOScheduler 调度执行 apply 已经提交的 committedEntries
- AppliedIndex 推进,通知 ReadLoop coroutine,满足 applied index>= commit index 的 read request 可以返回;
- 调用网络层接口返回 client 成功。
上面主要是leader的一个流程,其实还是有fallow,整体一个流程总结
1、一个写请求一般会通过调用node.Propose开始,Propose方法将这个写请求封装到一个MsgProp消息里面,发送给自己处理。
2、消息处理函数Step无法直接处理这个消息,它会调用那个小写的step函数,来根据当前的状态进行处理。
如果当前是follower,那它会把这个消息转发给leader。
func stepFollower(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgProp:
//...
m.To = r.lead
r.send(m)
}
}
3、Leader收到这个消息后(不管是follower转发过来的还是自己内部产生的)会有两步操作 - 将这个消息添加到自己的log里 - 向其他follower广播这个消息
func stepLeader(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgProp:
//...
if !r.appendEntry(m.Entries...) {
return ErrProposalDropped
}
r.bcastAppend()
return nil
}
}
4、在follower接受完这个log后,会返回一个MsgAppResp消息。
5、当leader确认已经有足够多的follower接受了这个log后,它首先会commit这个log,然后再广播一次,告诉别人它的commit状态。这里的实现就有点像两阶段提交了。
func stepLeader(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgAppResp:
//...
if r.maybeCommit() {
r.bcastAppend()
}
}
}
// maybeCommit attempts to advance the commit index. Returns true if
// the commit index changed (in which case the caller should call
// r.bcastAppend).
func (r *raft) maybeCommit() bool {
//...
mis := r.matchBuf[:len(r.prs)]
idx := 0
for _, p := range r.prs {
mis[idx] = p.Match
idx++
}
sort.Sort(mis)
mci := mis[len(mis)-r.quorum()]
return r.raftLog.maybeCommit(mci, r.Term)
}
状态转换
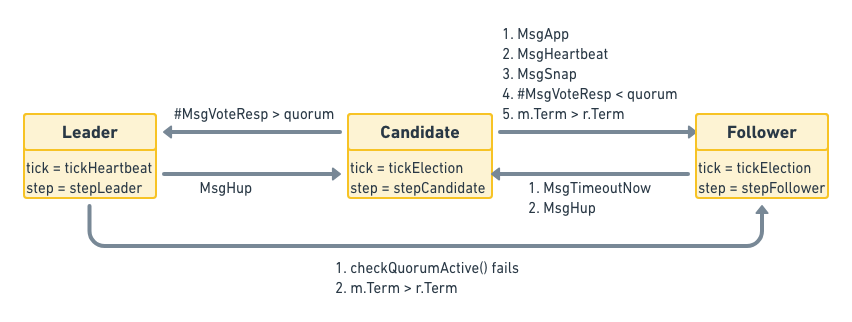
etcd-raft StateMachine 封装在 raft struct 中,其状态转换如下图:
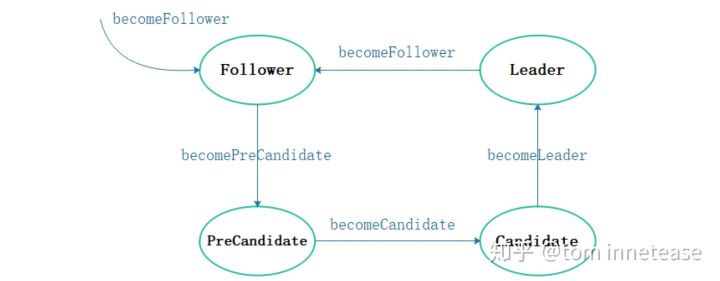
上图中就是对应的状态转化接口
func (r *raft) becomeFollower(term uint64, lead uint64)
func (r *raft) becomePreCandidate()
func (r *raft) becomeCandidate()
func (r *raft) becomeLeader()
etcd将请求数据都转化为msg,然后通过step接口进行处理,我们来看一下step接口
func (r *raft) Step(m pb.Message) error {
r.step(r, m)
}
在调用的step接口中,会针对不同的state调用不同的函数,如下,其中 stepCandidate 会处理 PreCandidate 和 Candidate 两种状态
func stepFollower(r *raft, m pb.Message) error
func stepCandidate(r *raft, m pb.Message) error
func stepLeader(r *raft, m pb.Message) error
我们简单看一下stepCandidate,对各种 Msg 进行处理
func stepCandidate(r *raft, m pb.Message) error {
......
switch m.Type {
case pb.MsgProp:
r.logger.Infof("%x no leader at term %d; dropping proposal", r.id, r.Term)
return ErrProposalDropped
case pb.MsgApp:
r.becomeFollower(m.Term, m.From) // always m.Term == r.Term
r.handleAppendEntries(m)
case pb.MsgHeartbeat:
r.becomeFollower(m.Term, m.From) // always m.Term == r.Term
r.handleHeartbeat(m)
case pb.MsgSnap:
r.becomeFollower(m.Term, m.From) // always m.Term == r.Term
r.handleSnapshot(m)
case myVoteRespType:
......
case pb.MsgTimeoutNow:
r.logger.Debugf("%x [term %d state %v] ignored MsgTimeoutNow from %x", r.id, r.Term, r.state, m.From)
}
return nil
}
核心模块
1、node 模块,对应一个 coroutine
其实就是我们说的node的功能,负责raft和应用层的交互,也就是那个for-select-channel的coroutine。
2、raftNode 模块:也会有一个 coroutine
主要完成的工作是把 raft StateMachine 处理的阶段性输出 Ready 拿来处理,该持久化的通过持久化接口写入盘中,该发送给 Peer 的通过网络层发送给 Peers 等。
func (r *raftNode) start(rh *raftReadyHandler) {
go func() {
defer r.onStop()
islead := false
for {
select {
// 监听 Ticker 事件,并通知 raft StateMachine
case <-r.ticker.C:
r.tick()
// 监听待处理的 Ready,并处理
case rd := <-r.Ready():
......
// 这部分处理 Ready 的逻辑下面单独文字描述
......
// 通知 raft StateMachine 运转,返回新的待处理的 Ready
r.Advance()
case <-r.stopped:
return
}
}
}()
}
raftNode 模块的 cortoutine 核心就是处理 raft StateMachine 的 Ready,下面将用文字单独描述,这里仅考虑Leader 分支,Follower 分支省略:
- 取出 Ready.SoftState 更新 EtcdServer 的当前节点身份信息(leader、follower….)等
- 取出 Ready.ReadStates(保存了 commit index),通过 raftNode.readStateC 通道传递给 EtcdServer 处理 read 的 coroutine
- 取出 Ready.CommittedEntires 封装成 apply 结构,通过 raftnode.applyc 通道传递给 EtcdServer 异步 Apply 的 coroutine,并更新 EtcdServer 的 commit index
- 取出 Ready.Messages,通过网络模块 raftNode.transport 发送给 Peers
- 取出 Ready.HardState 和 Entries,通过 raftNode.storage 持久化到 WAL 中
- (Follower分支)取出 Ready.snapshot(Leader 发送过来的),(1)通过 raftNode.storage 持久化 Snapshot 到盘中的 Snapshot,(2)通知异步 Apply coroutine apply snapshot 到 KV 存储中,(3)Apply snapshot 到 raftNode.raftStorage 中(all raftLog in memory)
- 取出 Ready.entries,append 到 raftLog 中
- 调用 raftNode.Advance 通知 raft StateMachine coroutine,当前 Ready 已经处理完,可以投递下一个准备好的 Ready 给 raftNode cortouine 处理了(raft StateMachine 中会删除 raftLog 中 unstable 中 log entries 拷贝到 raftLog 的 Memory storage 中)